計量国語学屋さんが使うという『現代日本語書き言葉均衡コーパス』(BCCWJ)を、言語学初心者のぼくも使ってみようと思ってやってみました。
書き言葉を集めたデータベースである BCCWJ を使って、副詞の使われかたを観察します。
前半の今回は、同期と目標、データの取得、解析(前半)について書いていきます。
動機 と 目標
「いきなり」は、古語では形容動詞として使われていたが、現代語の辞書には副詞としか書いていない。しかし「いきなりの腹痛」のように名詞として使われることもあるように見えるのは、いったいどういうことなのだろう。
— ピージェイ Pii Jey (@xiPJ) 2018年11月18日
副詞には、副詞+「の」で 名詞を修飾するものと、そうでないものがある?
— ピージェイ Pii Jey (@xiPJ) 2018年11月18日
🙆🏻♀️ かなりの量、まさかの結果、もしもの時、いつもの店
🙅🏻♀️ もっとの量?
どんな副詞が、〈副詞〉+「の」で 名詞を修飾するのか。疑問が湧いてきました。
副詞というのは、動詞や形容詞を修飾するやつだと言われていますが、オノマトペも副詞だし、なんかいろいろあります。実は、ぼくはまだよく分かっていません。
頭の中で考えていても限界があるので、頭の外のデータを調べてみることにしました。
目標を、次のように設定します。
- 副詞を「『の』で名詞を修飾しやすいもの」と「そうでないもの」に分類する
- それぞれにはどんな(意味などの)違いがあるか考える
『現代日本語書き言葉均衡コーパス』(BCCWJ)のデータを『中納言』で取得する
『現代日本語書き言葉均衡コーパス』(BCCWJ)からのデータの取得には『中納言』を使用しました。『中納言』では、ぽちぽちっとすると、好きな条件で検索結果を取得することができます。
今回は、
① 〈副詞〉
② 〈副詞〉+「の」+〈名詞〉
という2つの条件で検索しました。
検索
『中納言』の検索画面のスクリーンショットです。
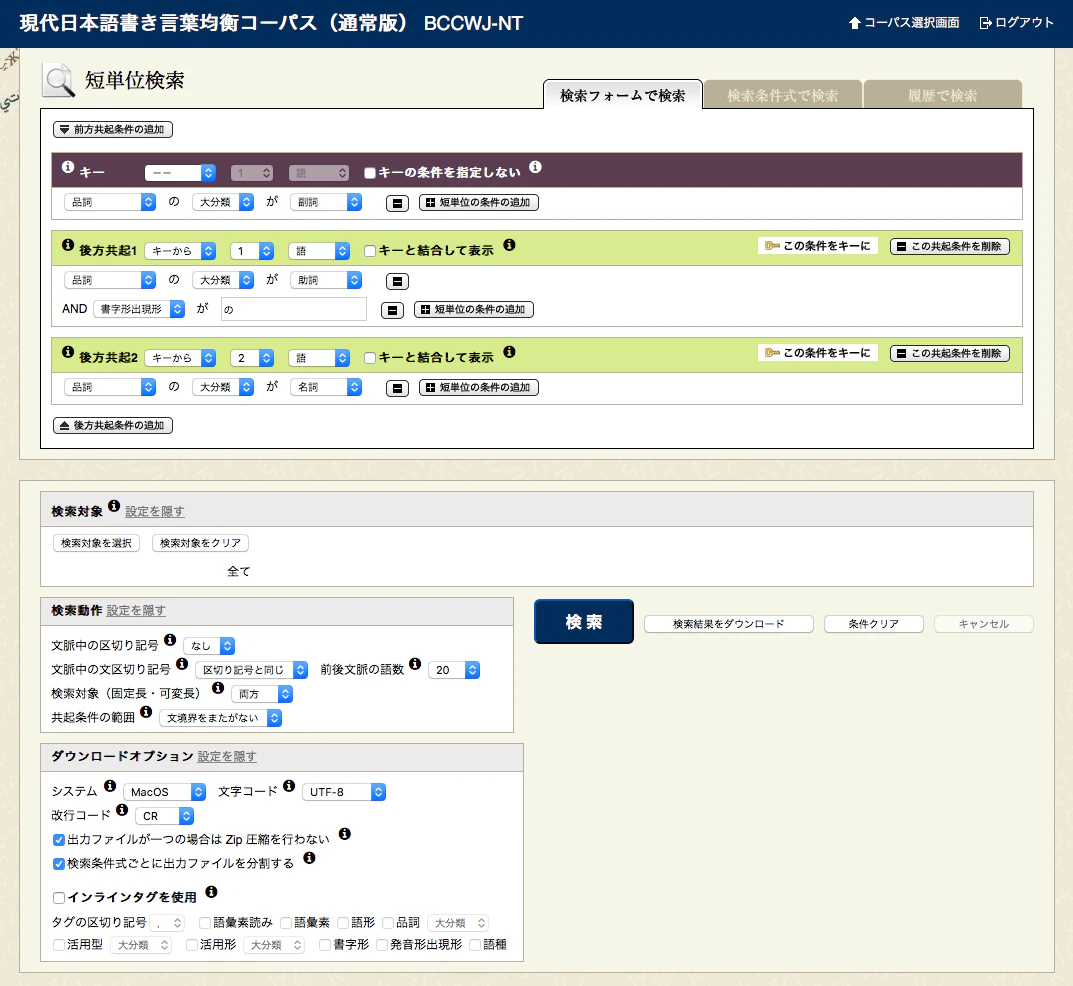
ダウンロードする前に、文字コードを指定しましょう(知らなくてちょっと焦りました)。
データ
テキストファイルの1行目は下のような感じです。
サンプル ID 開始位置 連番 前文脈 キー 後文脈 語彙素読み 語彙素 語彙素細分類 語形 品詞 活用型 活用形 書字形 発音形出現形 語種 原文文字列 レジスター コア 固定長 可変長 執筆者 生年代 性別 ジャンル 書名/出典 副題/分類 巻号 編著者等 出版者 出版年 反転前文脈
検索結果が多い場合には、最終行にこんなことが書いてあります。
100000 件より多くの検索結果が見つかりました。そのうち 100000 件をダウンロードしました。
①〈副詞〉については 100,000 件、②〈副詞〉 + 「の」 + 〈名詞〉については24,073 件のデータを取得することができました。
ところで、この100000 件というのは、ランダムに選ばれたものと考えていいのでしょうか。ちょっと気になりますが、ランダムだと思っておくことにします。
準備
ダウンロードしたテキストファイルは、python で書いたプログラムを使って解析しました。
ヒストグラムと散布図のプロットには、Matplotlib を使用しました。
表記ゆれの統一
ひらがな・漢字・送りがななどの表記違いについて、「語彙素読み_語彙素」が同じものを同じ語としました。
たとえば、
「たいてい」と「大抵」や、「やっぱし」と「やはり」を区別しません。
| キー | 語彙素読み | 語彙素 |
|---|---|---|
| たいてい | タイテイ | 大抵 |
| 大抵 | タイテイ | 大抵 |
| キー | 語彙素読み | 語彙素 |
|---|---|---|
| やっぱし | ヤハリ | 矢張り |
| やはり | ヤハリ | 矢張り |
「まだ」と「いまだ」を区別します。
| キー | 語彙素読み | 語彙素 |
|---|---|---|
| まだ | マダ | 未だ |
| いまだ | イマダ | 未だ |
そして、下記では「語彙素読み_語彙素」が同じものの中で最も多い「キー」を代表として表示しています。
UniDic での副詞
ところで、最初のツイートにある、「もしもの時」の「もしも」や、「いつもの店」の「いつも」は、UniDic では副詞とされていないので、
「もしも」 = 「もし(副詞)」+「も(助詞)」
「いつも」 = 「いつ(代名詞)」+「も(助詞)」
というふうになります。
順位と出現数
足したり引いたりする前に、データの様子を見てみましょう。
① 〈副詞〉
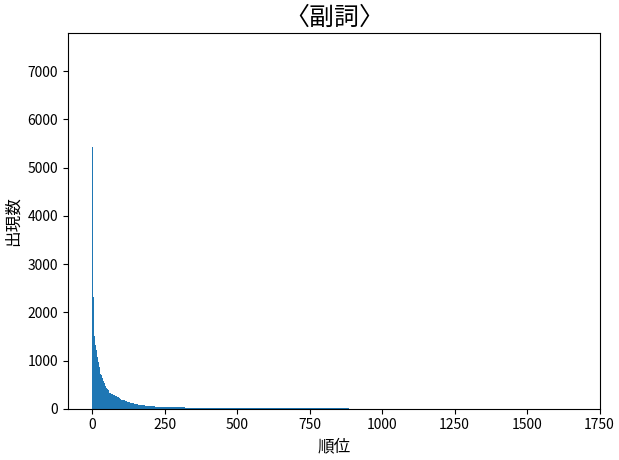
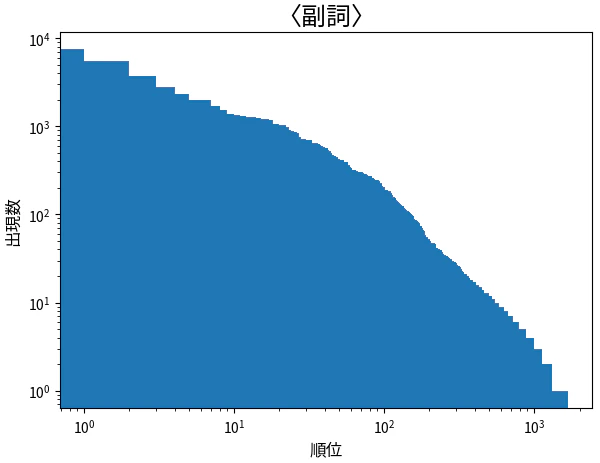
100,000 件の中で、「語彙素読み_語彙素」が異なるものが 1,667 個ありました。上位 10 個は下のようになり、「そうなんですか」の「そう」が一番多かったです。
| 順位 | キー | 出現数 |
|---|---|---|
| 1 | そう | 7415 |
| 2 | どう | 5423 |
| 3 | もう | 3689 |
| 4 | こう | 2758 |
| 5 | よく | 2324 |
| 6 | また | 1987 |
| 7 | まだ | 1984 |
| 8 | 少し | 1689 |
| 9 | すぐ | 1511 |
| 10 | つまり | 1390 |
順位と数のヒストグラムは下のようになりました。
こんなの見たことあるぞ! Zipf の法則ですね。単語全体だけではなく副詞だけでも Zipf の法則に従うんですね。
② 〈副詞〉 + 「の」 + 〈名詞〉
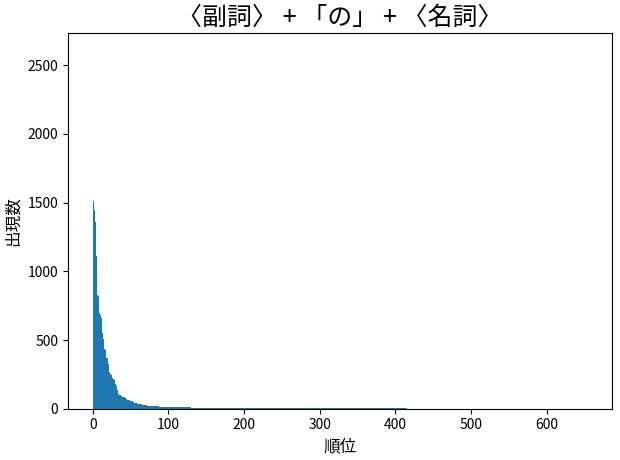
24,073 件の中で、「語彙素読み_語彙素」が異なるものが 653 個ありました。上位 10 個と、順位と数のヒストグラムは下のようになりました。
「初めての経験」「かつての教え子」「一番の宝物」「一層のご活躍」…そんな感じです。
| 順位 | キー | 数 |
|---|---|---|
| 1 | 初めて | 2602 |
| 2 | かつて | 1512 |
| 3 | 一番 | 1443 |
| 4 | 一層 | 1360 |
| 5 | たいてい | 1108 |
| 6 | まったく | 832 |
| 7 | 数多く | 830 |
| 8 | かなり | 823 |
| 9 | 少し | 696 |
| 10 | 突然 | 695 |
後件を指定した場合でも、Zipf っぽくなりました。
解析
後件を指定しない ① 〈副詞〉の場合と、「の」で名詞を修飾する ② 〈副詞〉 + 「の」 + 〈名詞〉 について、相関を見ていきます。
相関プロット
①を縦軸、②を横軸にとって両対数でプロットしたのが、下の図になります。
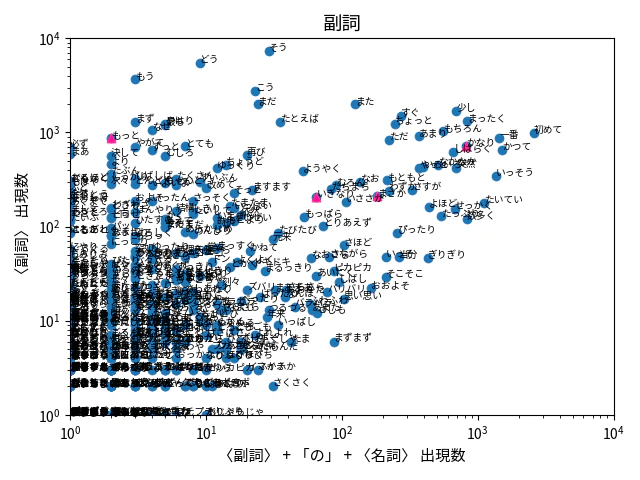
上に行くほど、よく使われています。右に行くほど、「の」で名詞を修飾する場合によく使われています。
右下の領域に分布がないのは、「の」で名詞を修飾する場合があるとき、後件を指定しなくてもゼロになることはないからです。
プロット上での例 (いきなり・かなり・まさか・もっと)
最初に考えていた、いきなり・かなり・まさか・もっと の 4 つについて、上の図に、ピンクの三角で示しました。
「まさか」と「いきなり」は、後件を指定しない場合の出現数では同程度ですが、「の」で名詞を修飾する出現数は「まさか」の方が多く、「まさか」のほうが「の」で名詞を修飾しやすいと分かります。
「の」で名詞を修飾する許容度について、順に並べると次のようになると考えられます。
🙅🏻♀️ もっとの量 < いきなりの腹痛 < かなりの量・まさかの結果 🙆🏻♀️
今後の解析
上の散布図「〈副詞〉 出現数」 対 「〈副詞〉 + 「の」 + 〈名詞〉 出現数」 に条件をかけて、「の」で名詞を修飾するものと、そうでないものを選び出す予定です。