📖 読了時間:約20分
はじめに
皆さんの運用しているシステムで、障害をどのように検知してどのように対応していますか。
実際に運用の現場で「ユーザーからの問い合わせで初めて障害に気づいた」「エラーログを見ても原因が特定できない」「複数のマイクロサービス間でどこがボトルネックになっているのか分からない」こんな経験はありませんか。
そんな課題の1つのアプローチ方法として近年、「オブザーバビリティ」というワードが注目を浴びています。私は普段の業務でオブザーバビリティの導入を推進する立場ですが、認知度の向上と共に相談を受ける件数が少しづつ増えてきました。
オブザーバビリティの中で中核を担うのがApplication Monitoring(アプリケーションモニタリング、以下APM)ですが、APMに限っては「基盤の導入と運用のハードルの高さ」や「開発チームから経営層まで多岐にわたる思考の複雑さ」か難しく感じる方も多いかと思います。
そこで、本記事ではAPMが何故必要とされているのか、どのような仕組みで実現されているのか、そしてOpenTelemetryによる標準的な実装方法について、基盤開発や監視業務に携わる技術リーダーの方々に向けて私の経験や検証結果から解説していきます。ぜひ、導入の検討の足掛かりとしていただければと思います。
本記事の構成:
- Part 1(本記事):【オブザーバビリティ】アプリケーション監視(APM)完全マスター
- Part 2(準備中):OpenTelemetryとSaaSで実現するハイブリッドAPM構成
1. Application Monitoring(APM)とは何か
1.1 Application Monitoringの定義
Application Monitoring(APM:Application Performance Monitoring)とは、アプリケーションのパフォーマンスと可用性を監視し、問題を迅速に検知・診断するための手法です。
従来のインフラ監視ではCPU使用率やメモリ使用量、ネットワークトラフィックなどの「リソース視点」での監視が中心で、アプリケーションの監視はアプリケーションのテキストログやプロセスの監視が中心であったと思います。実際に私もCatalina.outやイベントログの監視を構成したことは多くあります。
APMでは上記の監視とは若干色合いが変わり、以下のような「アプリケーション視点」での監視を行います。
- リクエストの処理時間(レスポンスタイム)
- エラー率と例外の詳細
- 依存関係にあるサービスやデータベースの呼び出し状況
- ユーザーエクスペリエンスの測定
- トランザクションの追跡(分散トレーシング)
1.2 何故Application Monitoringが必要なのか
ここでは実例を踏まえて、APMの必要性を考えてみましょう。ぜひ、皆さんの運用されている身近な環境に置き換えて考えてみてください。なおここで紹介するユースケースは、私の立場上、実際例とは異なる架空の事例であることを明言しておきます。
ケース1:マイクロサービスアーキテクチャでの障害切り分け
あるECサイトで「商品購入時にエラーが発生する」という報告があり、このシステムは以下のようなマイクロサービス構成になっていると仮定します。
- フロントエンドサービス
- 商品サービス
- 在庫サービス
- 決済サービス
- 通知サービス
従来のログベースの監視では、各サービスのログを個別に確認する必要があり、どのサービスが原因なのかを特定するまでに数時間かかります。しかし、APMを導入することで、1つのリクエストが各サービスをどのように通過したかを可視化でき、「決済サービスのデータベース接続でタイムアウトが発生している」ことを数分で特定できるようになります。
ケース2:パフォーマンス劣化の早期発見
あるWebアプリケーションで、特定の時間帯にユーザーから「画面表示が遅い」という苦情が増えているにも関わらず、インフラ監視では、CPU使用率もメモリ使用率も正常範囲内だったと仮定します。
APMを導入して調査をすることで、特定のAPIエンドポイントのレスポンスタイムが通常の10倍になっていることが判明し、さらに詳しく調べると、データベースクエリの実行計画が変わり、非効率なフルスキャンが発生していることが分かります。
このように、インフラが正常でもアプリケーションレベルでは問題が発生しているケースが多々あります。こういった問題の特定には通常かなりの時間がかかる上に、経験値の高いメンバーによる対応が必要になってくるケースが多いです。APMの計装ではこれらの問題を迅速に解決して初見でも対応できるようにしていきます。
ケース3:ビジネス影響の可視化と定量化
APMは技術的な問題解決だけでなく、ビジネス観点での価値も提供します。
あるオンライン予約サイトでは、定期的に「予約完了が遅い」というクレームがありましたが、具体的なビジネス影響は不明だったと仮定します。この時、APMを導入した結果、以下が明らかになります:
発見された事実:
- 毎週金曜日18:00-20:00の予約処理が平均5秒(通常は1秒)
- この時間帯の予約離脱率が35%(通常は10%)
- 月間で相当数の予約機会を失っていることが判明
この定量的なデータにより、経営層は問題の優先度を理解し即座にインフラ増強を承認することで、改善へとつながりユーザーの離脱率を抑えることができます。ここでAPMが提供しているビジネス観点での価値は以下です。
ビジネス観点でのAPMの価値:
- 売上機会の保護:エラーや遅延による離脱を定量化し、改善効果を可視化
- SLA/SLO達成の証明:顧客との契約達成状況を測定し、未達成時に早期検知
- カスタマーエクスペリエンス向上:地域別・デバイス別のユーザー体験を可視化し、優先順位付け
- 経営判断の根拠データ:システム投資の費用対効果を定量的に説明可能
このように、APMは技術部門だけでなく、経営層やビジネス部門にとっても価値のあるツールです。そして、運用チームにとっても、経営層に投資効果を訴えるためのとても重要なツールになることが分かるかと思います。
1.3 オブザーバビリティとの関係
オブザーバビリティは、システムの外部出力(ログ、メトリクス、トレース)から内部状態を推測できる能力を指します。APMは、この3つの柱のうち「トレース」と「メトリクス」を中心に、アプリケーションのオブザーバビリティを実現する重要な手段です。
Gartnerの調査によると、2024年以降、企業のデジタルトランスフォーメーションの進展に伴い、オブザーバビリティへの投資が急増しています。これは、従来の監視手法ではモダンなアプリケーションの複雑性に対応できなくなってきたことの表れだと私は思います。
2. Application Monitoringの仕組み
2.1 分散トレーシングとは
APMの中核を担うのが「分散トレーシング(Distributed Tracing)」です。1つのユーザーリクエストが複数のサービスを通過する経路を追跡し、どこで時間がかかっているのか、どこでエラーが発生しているのかを可視化する技術です。以下基本概念を抑えておいてください。
基本概念:
- Trace(トレース): ユーザーリクエストから始まる一連の処理全体
- Span(スパン): 各処理単位(例:データベースクエリ、API呼び出し)
- ウォーターフォール図: 処理の流れを時系列で表示し、ボトルネックを特定
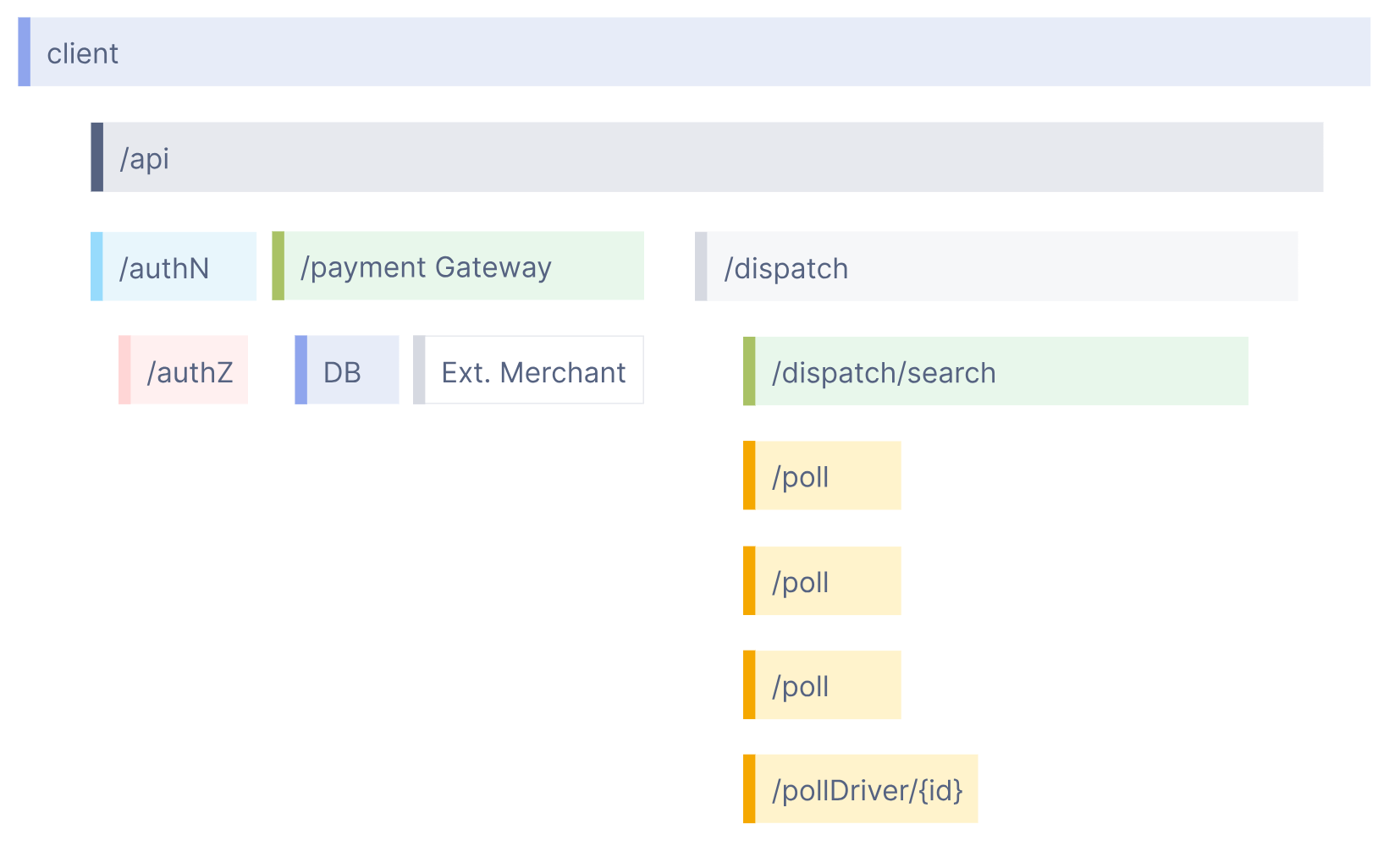
図1の説明: 1つのユーザーリクエスト(Trace)が複数のサービスを通過する様子を時系列で表示しています。各横棒(Span)は個別の処理を示し、長さが処理時間を表します。このフロー図を確認することで、どのサービスで時間がかかっているか(ボトルネック)を把握できます。
従来のログベースの監視では、各サービスのログを個別に確認する必要がありましたが、分散トレーシングでは1つのリクエスト全体を追跡できるため、障害の原因特定が劇的に早くなります。
2.2 OpenTelemetryによる標準化
以前は各ベンダーが独自の計装方法を提供していたため、ベンダー変更時にアプリケーション全体のコード修正が必要でした。この問題を解決するのがOpenTelemetryです。
OpenTelemetryは、APMのための標準規格として業界で広く採用されており、以下を提供します:
- 各プログラミング言語(Java、Python、.NET、Node.jsなど)向けの標準SDK
- 自動計装ライブラリ
- ベンダー中立なデータ送信プロトコル
OpenTelemetryを使用することで、アプリケーションコードはベンダーに依存せず、バックエンドのSaaS製品(Datadog、Dynatrace、New Relicなど)は自由に切り替えられます。これにより、ベンダーロックインを回避し、常に最適なAPMソリューションを選択できる柔軟性が得られます。個人的には、特に拘りがなければOpenTelemetryによる計装をお勧めします。
次の章では、実際の計装方法についてみていきましょう。
3. OpenTelemetryによるAPM実装の基礎
3.1 OpenTelemetryのアーキテクチャ概要
APMを実装する際、OpenTelemetryは以下(図2)の3層アーキテクチャで構成されます。
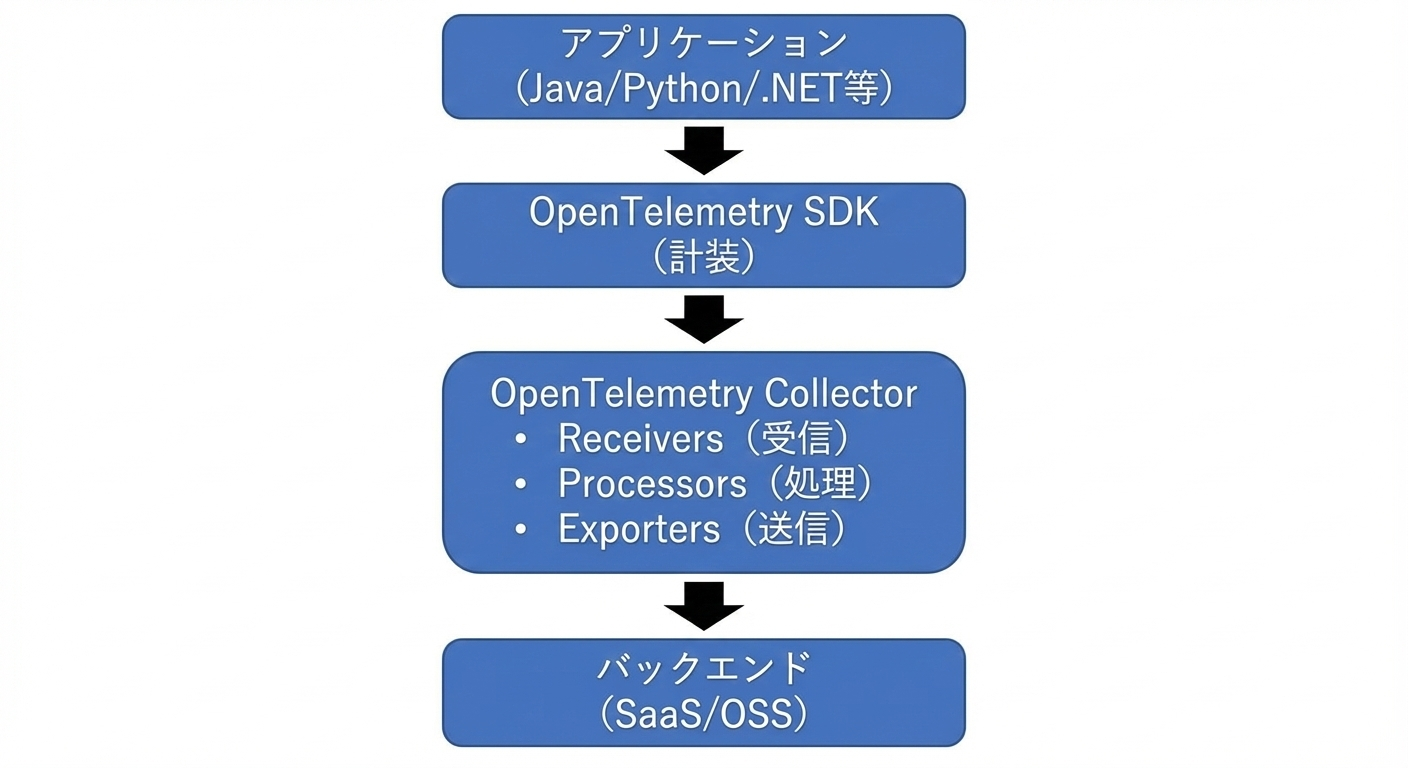
より深いアーキテクチャの内容は以下を参照ください。私も一番最初に以下を読み込んで理解しました:
3.2 計装(Instrumentation)の方法
OpenTelemetryでは、アプリケーションにテレメトリ機能を組み込む「計装」に、自動計装とカスタム計装の2つのアプローチがあります。ここでは、それらのアプローチについて解説していきます。
自動計装(Auto-instrumentation)
コード変更を最小限に、主要フレームワークを自動監視する方法です。通常、使用したいフレームワークが含まれている場合は、最初にこの自動計装から取り組むようにしましょう。
対応フレームワーク(2026/1/12現在):
- Flask、Express、ASP.NET Core、Spring Bootなど。以下のRegistryで使用している言語やライブラリが対応しているか、最新情報を確認してみてください。
- 参考: OpenTelemetry Registry - Instrumentation
自動追跡される機能:
- 基本的な機能として「HTTPリクエスト、データベースクエリ、外部API呼び出し」がサポートされます。実際に使用する際に以下のような仕様について書かれたページをチェックしておきましょう。
- 参考: Flask Instrumentation
Pythonでの自動計装例:
# 必要なパッケージのインストール
pip install opentelemetry-distro
# 自動的にインストルメンテーションライブラリをインストール
opentelemetry-bootstrap -a install
# 既存のFlaskアプリケーションを自動計装して実行(コード変更不要)
export OTEL_PYTHON_LOGGING_AUTO_INSTRUMENTATION_ENABLED=true
opentelemetry-instrument \
--traces_exporter console \
--metrics_exporter console \
--logs_exporter console \
--service_name my-service \
flask run -p 8080
これだけで、既存のFlaskアプリケーション内のHTTPリクエスト、データベースクエリ、外部API呼び出しが自動的に追跡されます。
メリット:
- アプリケーションコードの変更が一切不要
- 導入が簡単で、既存コードへの影響がゼロ
- 主要な技術スタックは標準でカバーされる
- メンテナンス負荷が低い
参考: OpenTelemetry Zero-code Instrumentation (Python)
カスタム計装(Manual instrumentation)
ビジネスロジック固有の処理を手動で追跡する方法です。以下のような想定シナリオにおいて、使用する必要が出てきます。運用していく中で必要があれば都度追加していく運用がいいかと思われます。少し大変ですが、カスタム計装を導入する場合はコードの管理も忘れずに実施しましょう。
想定するビジネスシナリオ:
ECサイトの注文APIを運用しているとします。ユーザーから「たまに注文が遅い」という苦情があり、原因を特定する必要があるケースを考えてみましょう。
自動計装では前述のとおり、以下が追跡されます:
- HTTPリクエスト全体の処理時間(例:
POST /api/orderが2.5秒) - データベースクエリの実行時間
- 外部API呼び出しの時間
しかし、これでは不十分です。理由は以下です:
❌ 自動計装では分からないこと:
- HTTPリクエストとして追跡されるが、それが「在庫確認」なのか「決済処理」なのか、ビジネス的な意味が不明である
- どの処理がボトルネックかは分かるが、どのような条件(高額注文、プレミアム会員など)で遅いのか分からない
- 問題が発生した注文ID、金額などのビジネス情報が記録されない
✅ カスタム計装で解決できること:
- ビジネスプロセス(在庫確認、決済処理など)に意味のある名前を付けて可視化
- 注文金額、顧客ランクなどのビジネス属性で分析
- 特定の条件で発生する問題を特定
Pythonでのカスタム計装例:
from flask import Flask, request
from opentelemetry import trace
app = Flask(__name__)
# Tracerを取得
tracer = trace.get_tracer("ecommerce.order.service")
@app.route('/api/order')
def create_order():
order_id = request.args.get('order_id')
total_amount = int(request.args.get('amount', 1000))
customer_tier = request.args.get('tier', 'standard')
# 【カスタム計装1】在庫確認処理を個別に追跡
# 目的:在庫確認APIの応答時間を測定し、遅延の原因特定
# 理由:自動計装では「何らかのAPI呼び出し」としか見えない
with tracer.start_as_current_span("validate_inventory") as span:
# ビジネス属性を追加して、後で分析可能に
span.set_attribute("order.id", order_id)
span.set_attribute("order.amount", total_amount)
span.set_attribute("customer.tier", customer_tier)
# 在庫確認処理(外部APIまたは在庫サービス呼び出し)
result = validate_and_reserve_inventory(order_id)
# 処理結果も記録
span.set_attribute("inventory.available", result['available'])
# 【カスタム計装2】決済処理を個別に追跡
# 目的:決済サービスの応答時間を測定
# 理由:在庫確認と決済、どちらが遅いか区別するため
with tracer.start_as_current_span("process_payment") as span:
span.set_attribute("payment.amount", total_amount)
span.set_attribute("payment.method", "credit_card")
payment_result = payment_service.charge(total_amount)
# 決済結果を記録(エラー分析に有用)
span.set_attribute("payment.status", payment_result['status'])
return {"status": "success", "order_id": order_id}
この計装により可能になる分析:
-
処理時間の内訳が見える
POST /api/order: 2.5秒 ├─ validate_inventory: 2.0秒 ← ボトルネック発見! └─ process_payment: 0.4秒 -
ビジネス属性でフィルタリング可能
- 「1万円以上の注文だけ遅い」→ 在庫確認の高額商品処理に問題
- 「プレミアム会員だけ遅い」→ 会員ランク判定ロジックに問題
-
特定の注文IDで詳細調査
- トラブル報告があった注文IDで検索
- その注文の全処理フローを可視化
ベストプラクティス:
- 自動計装で基本的な監視を開始
- ユーザー影響が大きい処理のみカスタム計装を追加
- ビジネス上の分析に必要な属性(金額、顧客ランクなど)を記録
- コード規約やレビューチェック項目に追加して、計装を管理
3.3 OpenTelemetry Collectorの役割
OpenTelemetry Collectorは、アプリケーションとバックエンドの間に位置する中間レイヤーです。以下のような機能があり、「OpenTelemetryの基盤設定=Collectorの設定」となります。そして、サンプリング戦略や機密情報のマスキングなど、運用の中で検討の必要な項目がたくさんあります。
ここでは簡単に各機能や設定例を紹介しますが、このセクションについては以下ドキュメントを読むことをお勧めします。
主な機能
1. Receivers(受信)
- アプリケーションからテレメトリデータを受信
- OTLP、Jaeger、Zipkinなど複数のフォーマットに対応
2. Processors(処理)
- データのフィルタリング、変換、サンプリング
- 機密情報のマスキング
- バッチ処理による効率化
3. Exporters(送信)
- 複数のバックエンドに同時送信可能
- Datadog、Dynatrace、Jaeger、Prometheusなど
基本的な設定例
# otel-collector-config.yaml
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
batch:
exporters:
otlp:
endpoint: otelcol:4317
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [otlp]
metrics:
receivers: [otlp]
processors: [batch]
exporters: [otlp]
logs:
receivers: [otlp]
processors: [batch]
exporters: [otlp]
参考: OpenTelemetry Collector Configuration
4. まとめとネクストステップ
4.1 次回予告
Part 2では、以下について詳しく解説します。本記事を読んで、APMの導入に踏み切りたいと思った方はぜひ次の記事も読んでください。
(1月中公開予定)Part 2:OpenTelemetryとSaaSで実現するハイブリッドAPM構成
- なぜハイブリッド構成(OpenTelemetry + SaaS)がベストプラクティスなのか
- ベンダーロックイン回避の具体的な方法
- SaaS製品のAIOpsによる根本原因自動解析
- コスト最適化のサンプリング戦略
- 実践的な導入ステップ
4.2 ネクストステップ
APM導入を検討される方は、まず以下から始めることをお勧めします:
1. 現状の課題を整理する
- 障害対応にどれくらい時間がかかっているか
- 今後のPOCなどの指標にもなってきます。もし、把握できていないのであれば計測の仕方から運用チームのメンバーと検討を進めてください
- 既存の監視では何が見えていないか
- これは普段運用しているチームではなかなか見えず、難しいのでぜひプロにお声掛けください
2. 小さく始める
- 1つのマイクロサービスを選択
- 一度にすべてのサービスに計装する必要はありません。まずは一番障害対応に時間のかかっているマイクロサービスから着手を始めましょう。
- 開発環境でOpenTelemetryの自動計装を試す
- カスタム計装は欲しいと思ったタイミングで構いません。まずは簡単な自動計装から始めることをお勧めします。
- 基本的な分散トレーシングを体験
- Trace情報をSaaSのサービスへ送って、分散トレーシングを体験してみて下さい。想像してなかった改修点が見つかるでしょう。
おわりに
APMの導入は上手く活用の基盤を作れば運用チームの可能性を引き上げてくれます。まずはスモールにぜひ始めて欲しいです。
また、OpenTelemetryでのAPMの導入はここでも紹介した自動計装のおかげでとても手軽なものになっています。特に恐れることはありません。それよりもコード規約やコードのデプロイ手順の中に盛り込んでおくことを忘れないようにしましょう。
分からないことや私にサポートができることがあれば、是非コメントやチャットをください。
参考情報
OpenTelemetry公式ドキュメント
- OpenTelemetry公式サイト
- OpenTelemetry Python
- OpenTelemetry Zero-code Instrumentation (Python)
- OpenTelemetry Registry - Instrumentation
- Flask Instrumentation
- OpenTelemetry Collector Configuration