fukuoka.exのpiacereです
ご覧いただいて、ありがとうございます ![]()
これまでのコラムは、割とアプリ/SI/Web/データサイエンス寄りのElixirコラムが多かったですが、今回は、毛色を変えて、Elixirコードからネイティブコードをコンパイルできるような、いわゆる「Elixirコンパイラ」をLLVMで作れるか、何回かに分けて、トライしてみようと思います
ちなみに、私はWindows使い…それも「36年の歴史を誇る重度なMS信者※」なので、LLVMもWindowsで動かしていきます
※TwitterやQiitaをご覧のフォロワーの方は、どうも私のことをLinux/mac使いと思い込んでいる方が多いみたいです(無論、仕事や趣味でガンガン使ってますけど)が、私が四六時中も手放さず、どこに行くにも携帯している愛機は、以下Let's note CF-RZ6+Windows 10です ![]()
https://twitter.com/piacere_ex/status/1103520493913567232
大昔、コンパイラ開発も「gcc」では無く「MS-C」でやってましたし、OS開発の動機も、「Windows NT」、つまりWindows 2000/XP/Vista/7/10と、今のWindowsの系譜のご先祖様に心酔して始まってたりします…
…おっと、与太話でコラム埋まってしまうので、この辺で止めておきます
内容が、面白かったり、役に立ったら、「いいね」よろしくお願いします ![]()
Windows用LLVMを使えるようにする
まずは、Windows用LLVMを、一通り動かしていきます
LLVMをインストールする
下記ページから、インストーラをダウンロードします
http://releases.llvm.org/download.html
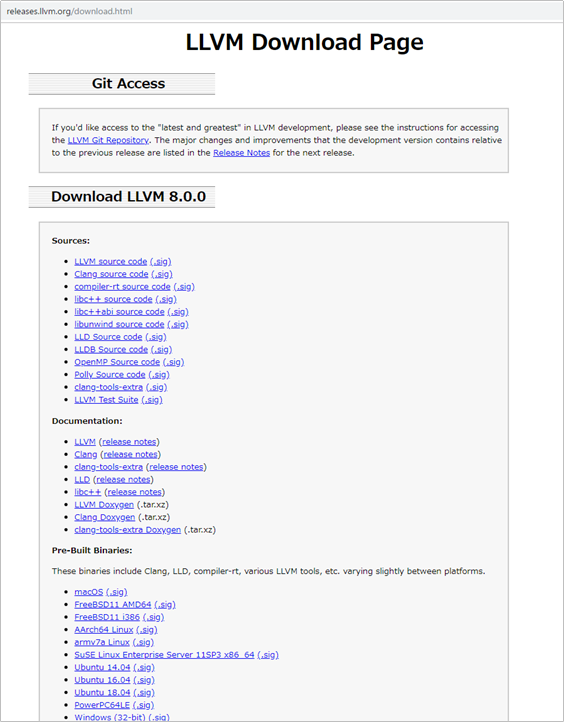
「Windows (64-bit)」をクリックして、Windows用LLVMをダウンロードし、起動します
PATH追加するように設定しておきます
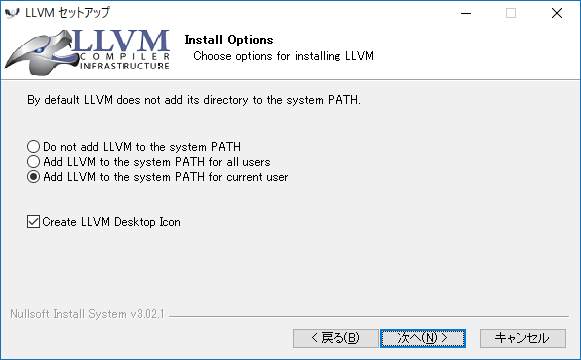
インストール先は、必要あれば、変えてください
LLVM/Clangでインストール後の確認をする
LLVMのインストールが完了したら、コンソールを起動し、clang++コマンドが実行できれば、インストール成功です
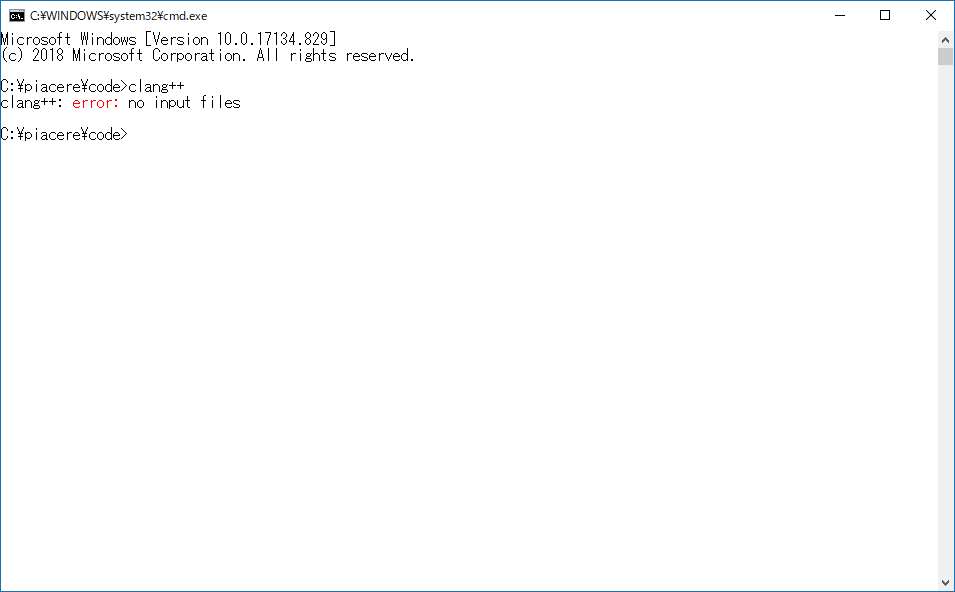
LLVM/ClangでC++コードをコンパイルする
LLVMをいじる前に、C++コードをコンパイルできるか、試しておきます
万が一、Elixirコードから、LLVM IRに変換するのに断念したときの回避策として、ElixirコードからC++コードを生成するパスの担保です(とはいえ、C++の仕様全量をテストする訳では無いので、ひとまずC++コンパイル通るよねレベルですが…)
# include <stdio.h>
int main()
{
prntf( "Hello" );
return 0;
}
コンパイルして、実行します
> clang++ hello.cpp -o hello.exe
> hello
Hello
うまくいきました
LLVM IRを生成してみる
次に、上記C++コードを、LLVM IRに変換してみます
LLVM IRは、LLVMでマシンコードを生成する手前の中間表現(IR:Intermediate Representation)で、これさえ生成できれば、後はLLVMがマシンコード生成(と最適化)をやってくれる、という、便利過ぎるものです
私が25年前に、自分でCコンパイラを作ってたとき、IRのフォーマットも独自で定義していた頃とは、隔世の感あります
では、IRを出力してみましょう
なお「C0」は、最適化無しオプションです
> clang++ hello.cpp -S -emit-llvm -O0
IRは、以下のようになります
「c"Hello\00"」が出力する文字列で、@ main()内では、これを@ printf()で処理しています
また、@ printf()内では、内部で@ _vfprintf_l()が呼ばれており、可変長引数が処理されています(この辺りでウフフってなる方は、Cコンパイラ作った経験ある人、もしくはstdioチョットワカルヒトですね)
; ModuleID = 'hello.cpp'
source_filename = "hello.cpp"
target datalayout = "e-m:w-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-pc-windows-msvc19.14.26433"
%struct._iobuf = type { i8* }
%struct.__crt_locale_pointers = type { %struct.__crt_locale_data*, %struct.__crt_multibyte_data* }
%struct.__crt_locale_data = type opaque
%struct.__crt_multibyte_data = type opaque
$printf = comdat any
$_vfprintf_l = comdat any
$__local_stdio_printf_options = comdat any
$"??_C@_05COLMCDPH@Hello?$AA@" = comdat any
$"?_OptionsStorage@?1??__local_stdio_printf_options@@9@4_KA" = comdat any
@"??_C@_05COLMCDPH@Hello?$AA@" = linkonce_odr dso_local unnamed_addr constant [6 x i8] c"Hello\00", comdat, align 1
@"?_OptionsStorage@?1??__local_stdio_printf_options@@9@4_KA" = linkonce_odr dso_local global i64 0, comdat, align 8
; Function Attrs: noinline norecurse optnone uwtable
define dso_local i32 @main() #0 {
%1 = alloca i32, align 4
store i32 0, i32* %1, align 4
%2 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([6 x i8], [6 x i8]* @"??_C@_05COLMCDPH@Hello?$AA@", i32 0, i32 0))
ret i32 0
}
; Function Attrs: noinline optnone uwtable
define linkonce_odr dso_local i32 @printf(i8*, ...) #1 comdat {
%2 = alloca i8*, align 8
%3 = alloca i32, align 4
%4 = alloca i8*, align 8
store i8* %0, i8** %2, align 8
%5 = bitcast i8** %4 to i8*
call void @llvm.va_start(i8* %5)
%6 = load i8*, i8** %4, align 8
%7 = load i8*, i8** %2, align 8
%8 = call %struct._iobuf* @__acrt_iob_func(i32 1)
%9 = call i32 @_vfprintf_l(%struct._iobuf* %8, i8* %7, %struct.__crt_locale_pointers* null, i8* %6)
store i32 %9, i32* %3, align 4
%10 = bitcast i8** %4 to i8*
call void @llvm.va_end(i8* %10)
%11 = load i32, i32* %3, align 4
ret i32 %11
}
; Function Attrs: nounwind
declare void @llvm.va_start(i8*) #2
; Function Attrs: noinline optnone uwtable
define linkonce_odr dso_local i32 @_vfprintf_l(%struct._iobuf*, i8*, %struct.__crt_locale_pointers*, i8*) #1 comdat {
%5 = alloca i8*, align 8
%6 = alloca %struct.__crt_locale_pointers*, align 8
%7 = alloca i8*, align 8
%8 = alloca %struct._iobuf*, align 8
store i8* %3, i8** %5, align 8
store %struct.__crt_locale_pointers* %2, %struct.__crt_locale_pointers** %6, align 8
store i8* %1, i8** %7, align 8
store %struct._iobuf* %0, %struct._iobuf** %8, align 8
%9 = load i8*, i8** %5, align 8
%10 = load %struct.__crt_locale_pointers*, %struct.__crt_locale_pointers** %6, align 8
%11 = load i8*, i8** %7, align 8
%12 = load %struct._iobuf*, %struct._iobuf** %8, align 8
%13 = call i64* @__local_stdio_printf_options()
%14 = load i64, i64* %13, align 8
%15 = call i32 @__stdio_common_vfprintf(i64 %14, %struct._iobuf* %12, i8* %11, %struct.__crt_locale_pointers* %10, i8* %9)
ret i32 %15
}
declare dso_local %struct._iobuf* @__acrt_iob_func(i32) #3
; Function Attrs: nounwind
declare void @llvm.va_end(i8*) #2
declare dso_local i32 @__stdio_common_vfprintf(i64, %struct._iobuf*, i8*, %struct.__crt_locale_pointers*, i8*) #3
; Function Attrs: noinline nounwind optnone uwtable
define linkonce_odr dso_local i64* @__local_stdio_printf_options() #4 comdat {
ret i64* @"?_OptionsStorage@?1??__local_stdio_printf_options@@9@4_KA"
}
attributes #0 = { noinline norecurse optnone uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-frame-pointer-elim"="false" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #1 = { noinline optnone uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-frame-pointer-elim"="false" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #2 = { nounwind }
attributes #3 = { "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="false" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #4 = { noinline nounwind optnone uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-frame-pointer-elim"="false" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
!llvm.linker.options = !{!0}
!llvm.module.flags = !{!1, !2}
!llvm.ident = !{!3}
!0 = !{!"/FAILIFMISMATCH:\22_CRT_STDIO_ISO_WIDE_SPECIFIERS=0\22"}
!1 = !{i32 1, !"wchar_size", i32 2}
!2 = !{i32 7, !"PIC Level", i32 2}
!3 = !{!"clang version 8.0.0 (tags/RELEASE_800/final)"}
生成されたLLVM IRからマシンコードを生成…できない?…
次に、生成されたLLVM IRを、マシンコードにコンパイルします
LLVM IR(.ll)から、マシンコードへのコンパイルには、llcコマンドでアセンブリコード(.s)に変換し、clang++でアセンブルすればOKです
> llc hello.ll
'llc' は、内部コマンドまたは外部コマンド、
操作可能なプログラムまたはバッチ ファイルとして認識されていません。
おや?llcコマンドが無い!?…
調べてみると、どうやらWindowsは、バイナリインストーラにllcが標準バンドルされていないようです…
Windows用llcコマンドを準備する
ということで、自前でllcコマンドを用意します
LLVMをgit cloneする
LLVMのGithubからソースコードをgit cloneします
https://github.com/llvm/llvm-project/
> git clone https://github.com/llvm/llvm-project/
CMAKEをインストールする
git cloneが、数十分かかる裏で、LLVMをビルドするために必要なCMAKEを並行してインストールします
「Latest Release」配下の「Windows win64-x64 Installer」をクリックして、Windows用CMAKEをダウンロードし、起動します
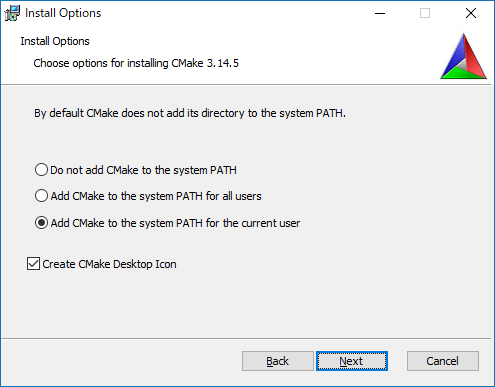
PATH追加するように設定しておきます
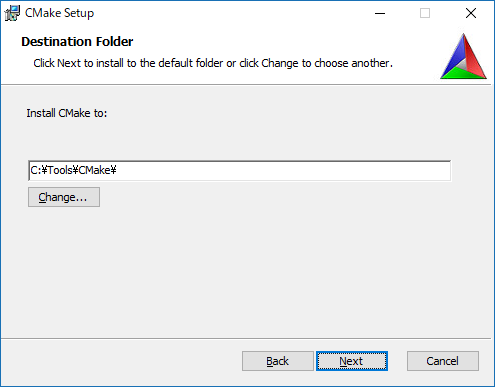
インストール先は、必要あれば、変えてください
「Build Tools for Visual Studio 2017」をインストールする
「Build Tools for Visual Studio 2017」をインストールしていない場合は、以降のビルドがうまく動かない可能性があります
「WindowsのC++ビルド環境を作る~Build Tools for Visual Studio 2017の導入」のコラムを見て、インストールを済ませておいてください
LLVMをCMAKEでビルドする
CMAKEのパスを有効にするために、コンソールを起動し直して、LLVMをgit cloneした場所から、以下コマンドでビルドします(1~2時間かかります)
cd llvm-project
mkdir build
cd build
cmake ../llvm/ -DCMAKE_BUILD_TYPE=Debug
cmake --build .
ビルドしたものにPATHを通す
ビルドが完了すると、llcコマンドができあがっているので、PATHを追加します
場所は、git cloneした配下の「\build\Debug\bin」です
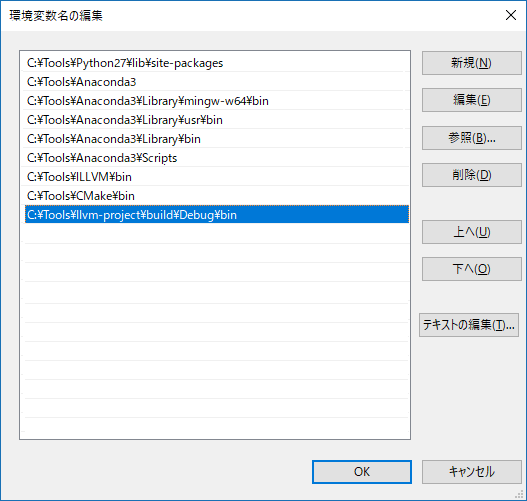
PATH変更を有効にするため、再度コンソールを起動し直してから、llcコマンドが動くことを確認します
>llc --version
LLVM (http://llvm.org/):
LLVM version 9.0.0svn
DEBUG build with assertions.
Default target: i686-pc-windows-msvc
Host CPU: skylake
Registered Targets:
aarch64 - AArch64 (little endian)
aarch64_32 - AArch64 (little endian ILP32)
aarch64_be - AArch64 (big endian)
…
うむ、出だしから、セルフコンパイル的展開が満載で、これはワクワクしますね(え?めんどくさい?) ![]()
いえいえ、20年前は、この100倍は面倒だったので、こんな程度で済む今は「天国」みたいなもんですよ…
ウーン、実に老害発言 ![]()
改めて、生成されたLLVM IRからマシンコードを生成する
llcも用意できたので、改めて、生成されたLLVM IRを、マシンコードにコンパイルします
LLVM IR(.ll)から、マシンコードへのコンパイルには、llcコマンドでアセンブリコード(.s)に変換し、clang++でアセンブルすればOKです
> clang++ -c -emit-llvm hello.cpp
> llc hello.bc
> del hello.exe
> clang++ hello.s -o hello.exe
> hello
Hello
今後は、うまくいきました
LLVM IRの中身を解析する
さて、Elixirコードから、このLLVM IRを生成できれば、上記の手順でマシンコードが生成できるため、このコラムシリーズのゴールである「Elixirコンパイラの作成」≒「ElixirコードからのLLVM IR生成」となる訳です
そのために、まず、LLVM IRの中身を解析します
先ほどのメッセージ出力は、stdioを含んだため、ちょっと複雑なので、以下のような、もっと単純なコードで解析を進めます
int main()
{
int a = 1;
return a + 2;
}
コンパイルして、実行します
なお、「echo %ERRORLEVEL%」は、Linux/macで言う、「echo $?」と同等です
> clang++ add.cpp -o add.exe
> add
> echo %ERRORLEVEL%
3
LLVM IRを出力します
> clang++ add.cpp -S -emit-llvm -O0
; ModuleID = 'add.cpp'
source_filename = "add.cpp"
target datalayout = "e-m:w-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-pc-windows-msvc19.14.26433"
; Function Attrs: noinline norecurse nounwind optnone uwtable
define dso_local i32 @main() #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
store i32 0, i32* %1, align 4
store i32 1, i32* %2, align 4
%3 = load i32, i32* %2, align 4
%4 = add nsw i32 %3, 2
ret i32 %4
}
attributes #0 = { noinline norecurse nounwind optnone uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-frame-pointer-elim"="false" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
!llvm.module.flags = !{!0, !1}
!llvm.ident = !{!2}
!0 = !{i32 1, !"wchar_size", i32 2}
!1 = !{i32 7, !"PIC Level", i32 2}
!2 = !{!"clang version 8.0.0 (tags/RELEASE_800/final)"}
今回のLLVM IRは、シンプルですが、一応、解説です
LLVM IR中、見るべき部分は、ここだけです
define dso_local i32 @main() #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
store i32 0, i32* %1, align 4
store i32 1, i32* %2, align 4
%3 = load i32, i32* %2, align 4
%4 = add nsw i32 %3, 2
ret i32 %4
}
最初の1行は、関数宣言です
2~3行目は、変数の置き場所を「%n」で確保します
4~5行目は、各変数に値を代入するところで、うち5行目は、「a = 1」に該当します
6行目で、この代入したaをロードし、7行目で、aと2を加算します
その計算結果を、8行目で関数の戻り値として返却します
終わり
今回は、LLVM(しかもWindows版、しかも自前ビルド)を使えるようにし、簡単なC++コードのLLVM IRを解析しました
Windowsの場合、C++コンパイラ環境の構築に難儀することが過去は多かったと思いますが、LLVM/Clangの登場により、Linux/macと遜色無い状況になっていて、これはかなりハッピーなことです
「ElixirマクロによるAST生成」とも絡めて作れたらいいなと思います
p.s.「いいね」よろしくお願いします
ページ左上の  や
や  のクリックを、どうぞよろしくお願いします
のクリックを、どうぞよろしくお願いします![]()
ここの数字が増えると、書き手としては「ウケている」という感覚が得られ、連載を更に進化させていくモチベーションになりますので、もっとElixirネタを見たいというあなた、私達と一緒に盛り上げてください!![]()