(この記事は Elixir (その2)とPhoenix Advent Calendar 2016 8日目の記事です)
前回は、PhoenixでWebアプリ化して、最後に出現した固有名詞をオウム返しする、多少は言われたことを掴む(文字通り「掴む」だけですが…)貧弱AIを作りましたが、「進撃の巨人」を知らないオールドタイプであることが判明しました ![]()
今回は、MeCabの辞書を差し替え、貧弱AIを現代っ子に進化させた後、文章の構成を解析するための「CaboCha」をElixirで使えるようにします
CaboChaのElixirモジュールは、世に無いようなので、今回作ってみます ![]()
なお、本コラム中の「Elixirの書き方」については、あまり細かく説明をしていないので、「ここの書き方が分からない」とか「この処理が何をしているのかよく分からない」等あれば、コメントいただければ、回答します ![]()
新語辞書に差し替え
「mecab-ipadic-NEologd」という、MeCabの新語辞書をインストールすることで、現在っ子に進化します
Windowsを除いて、パッケージマネージャでインストール可能です ![]()
- Docker(trenpixster/elixir)やUbuntu・・・apt
- CentOSなど・・・yum
- Mac・・・Homebrew
- Windows・・・手動で設定 ※UTF-8で行うため、以下2点の手順を変更する必要があります
- 2の手順は、「 [Recompile SHIFT-JIS Dictionary]」では無く「 [Recompile UTF-8 Dictionary]」を実行
- 4の手順の前に、mecab-dict-compile.cmdの「-t」の「shift-jis」を「UTF-8」に変更
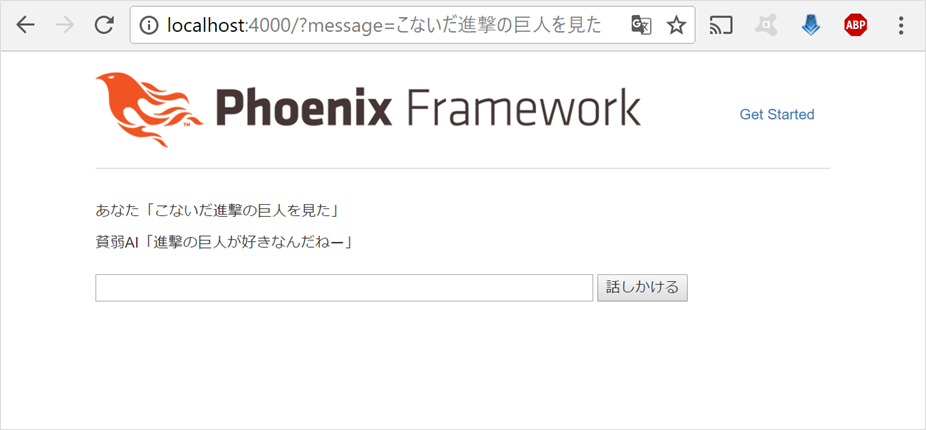
早速、「神撃の巨人」をリトライしてみると...おー、通じるようになった ![]()
CaboChaのインストール
CaboChaを下記の「ダウンロード」からインストールするか、yum等でインストールしてください
CaboCha: https://taku910.github.io/cabocha/
なお、Windows版は、MeCab同様、「UTF-8」を選択してください
CaboChaモジュールの作成
インストールが終わったら、CaboChaを呼び出すモジュールを追加します
defmodule Cabocha do
def view( body ), do: tree( body )
def tree( body ), do: if body == "" || body == nil, do: "", else: "echo #{body} | cabocha" |> execute
def execute( command ) do
command
|> to_char_list
|> :os.cmd
|> to_string
end
end
このモジュールを使って、CaboChaの解析結果をページに追加してみます
<p>あなた「<%= @params[ "message" ] %>」</p>
<p>貧弱AI「<%= MiniAi.listen( @params[ "message" ] ) %>」</p>
<form method="GET" action="/">
<input type="text" name="message" size="60" value="">
<input type="submit" value="話しかける">
</form>
<hr>
<h3>CaboCha解析結果</h3>
<p><pre><%= Cabocha.view( @params[ "message" ] ) %></pre></p>
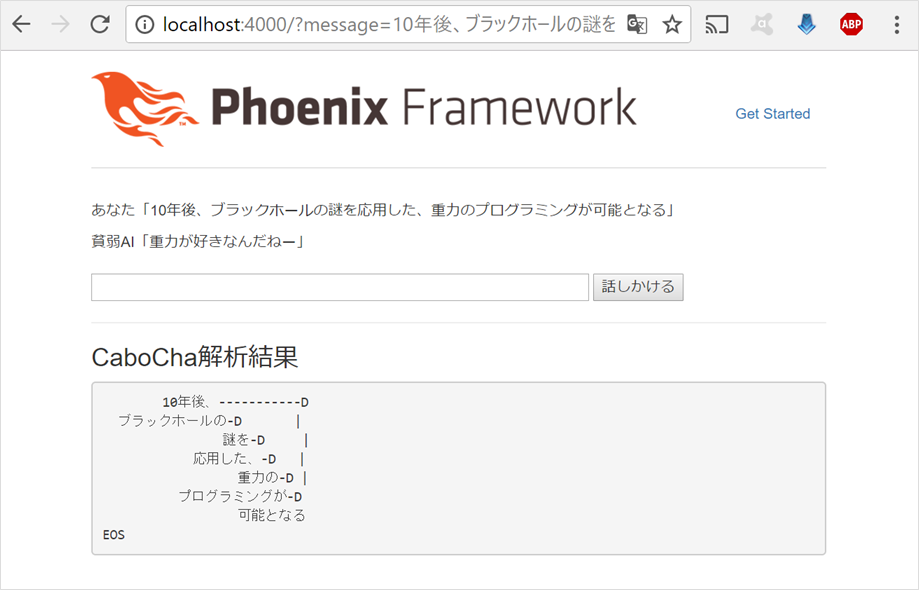
話しかけると、CaboChaでどのように解析されているかが分かります
CaboCha出力をXMLに切り替え
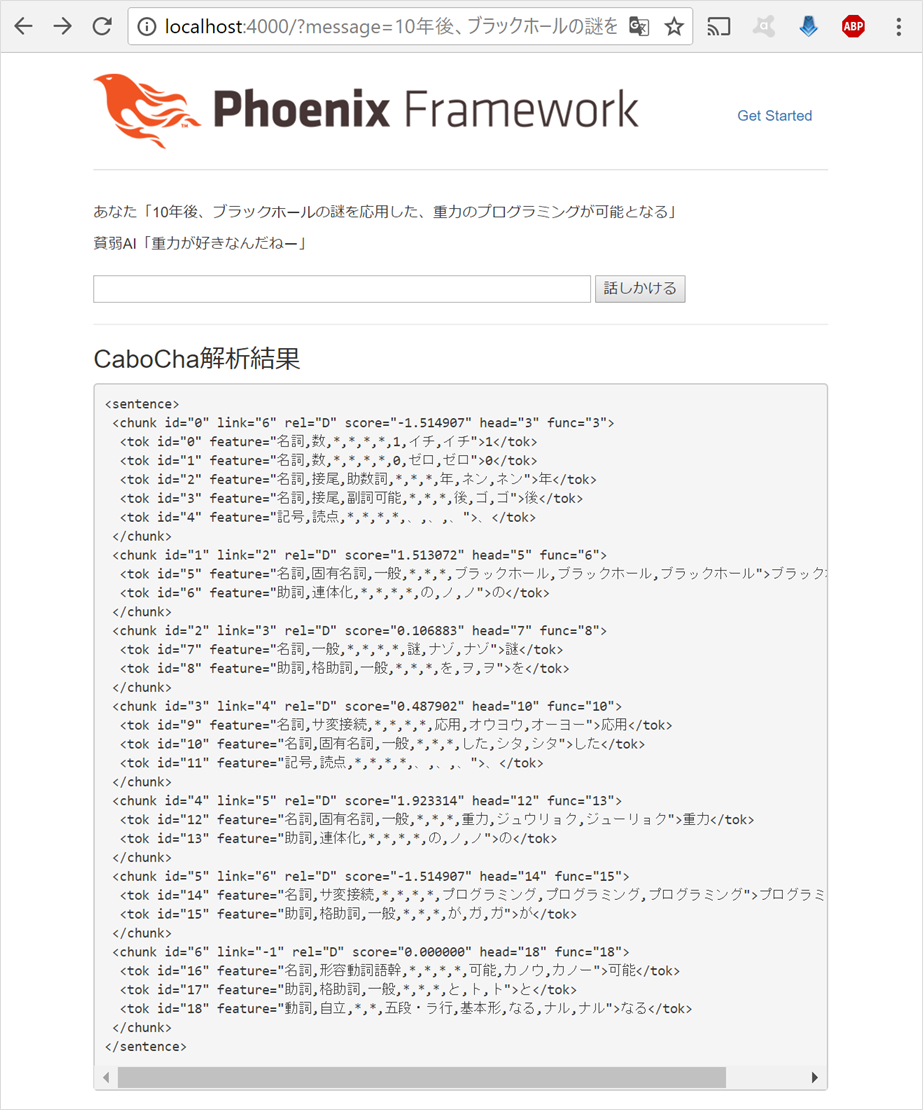
このツリー構造は、見た目は良いですが、このままだとプログラム上からは扱いにくいので、CaboChaのコマンドラインオプション「-f3」を使って、XML出力に切り替えます
defmodule Cabocha do
def view( body ), do: xml( body )
def xml( body ), do: if body == "" || body == nil, do: "", else: "echo #{body} | cabocha -f3" |> execute
…
ブラウズをリロードすると、以下のようなXML表示に切り替わります
CaboCha XMLをパターンマッチしやすい形に変換
XMLのままだと、Elixirで処理しにくいので、「xml_parser」モジュールを使って変換します
mix.exsにxml_parserモジュールのエントリーを追加します
defmodule WebMiniAi.Mixfile do
use Mix.Project
…
defp deps do
[{:phoenix, "~> 1.2.1"},
{:phoenix_pubsub, "~> 1.0"},
{:phoenix_html, "~> 2.6"},
{:phoenix_live_reload, "~> 1.0", only: :dev},
{:gettext, "~> 0.11"},
{:cowboy, "~> 1.0"},
{ :mecab, "~> 1.0" },
{ :xml_parser, "~> 0.1.0" },
]
end
…
iexを、Ctrl+Cを2回押して抜けた後、モジュールを取得します(要ネット接続)
iex>
BREAK: (a)bort (c)ontinue (p)roc info (i)nfo (l)oaded
(v)ersion (k)ill (D)b-tables (d)istribution
# mix deps.get
xml_parser.parseを使って、XMLからパターンマッチしやすい形に変換します
defmodule Cabocha do
def parse( body \\ "10年後、ブラックホールの謎を応用した、重力のプログラミングが可能となる" ) do
case body == "" || body == nil do
true -> ""
false ->
body
|> xml
|> XmlParser.parse
end
end
…
そのままPhoenixで表示できないので、コンソールで確認します
↑
5/8補足:inspect()使えばPhoenix上でも見れます
# iex -S mix phoenix.server
iex> Cabocha.parse
{:sentence, nil,
[{:chunk,
%{func: "3", head: "3", id: "0", link: "6", rel: "D", score: "-1.514907"},
[{:tok, %{feature: "名詞,数,*,*,*,*,1,イチ,イチ", id: "0"}, "1"},
{:tok, %{feature: "名詞,数,*,*,*,*,0,ゼロ,ゼロ", id: "1"}, "0"},
{:tok,
%{feature: "名詞,接尾,助数詞,*,*,*,年,ネン,ネン", id: "2"},
"年"},
{:tok, %{feature: "名詞,接尾,副詞可能,*,*,*,後,ゴ,ゴ", id: "3"},
"後"},
{:tok, %{feature: "記号,読点,*,*,*,*,、,、,、", id: "4"}, "、"}]},
{:chunk,
%{func: "6", head: "5", id: "1", link: "2", rel: "D", score: "1.513072"},
[{:tok,
%{feature: "名詞,固有名詞,一般,*,*,*,ブラックホール,ブラックホール,ブラックホール",
id: "5"}, "ブラックホール"},
…(略)…
{:tok,
%{feature: "動詞,自立,*,*,五段・ラ行,基本形,なる,ナル,ナル",
id: "18"}, "なる"}]}]}
これで、文章の構成を解析できるようになったので、いよいよ次回は、AIらしく、文脈から意味を読み取る(といってもカンタンな解釈ですが)ようなロジックを作っていきます ![]()