この記事は、「Elixir Advent Calendar 2017」の25日目です
Merry Xmas!(実に1日遅れですが…) ![]()
Elixir Digitalization Implementors/fukuoka.ex/kokura.ex の piacere です
ご覧いただいて、ありがとうございます ![]()
私は普段、福岡のスタートアップ企業のCTOとして、「ビッグデータ分析+AI・ML開発の統括」と「Elixir・Phoenix/Kerasリードプログラマ」をしながら、福岡Elixirコミュニティ「fukuoka.ex」のMeetUp(偶数月定期開催)やプログラミング入門ハンズオン、もくもく会を主催しています
ちょうど先週末、「fukuoka.ex #4 ~ Elixirのビッグデータ分析~」というテーマでMeetUpを開催したので、そこで扱ったセッションの一部をコラム化してみようと思います
題して、Elixir+Keras=手軽に高速な「データサイエンスプラットフォーム」です
内容が、面白かったり、役に立ったら、「LGTM」よろしくお願いします ![]()
 Advent Calendar、fukuoka.ex1位、Elixir2位達成ヽ(=´▽`=)ノ
Advent Calendar、fukuoka.ex1位、Elixir2位達成ヽ(=´▽`=)ノ
fukuoka.ex Advent Calendar、Webテクノロジーカテゴリで堂々1位 … 各コラムぜひお読みください
https://qiita.com/advent-calendar/2020/fukuokaex
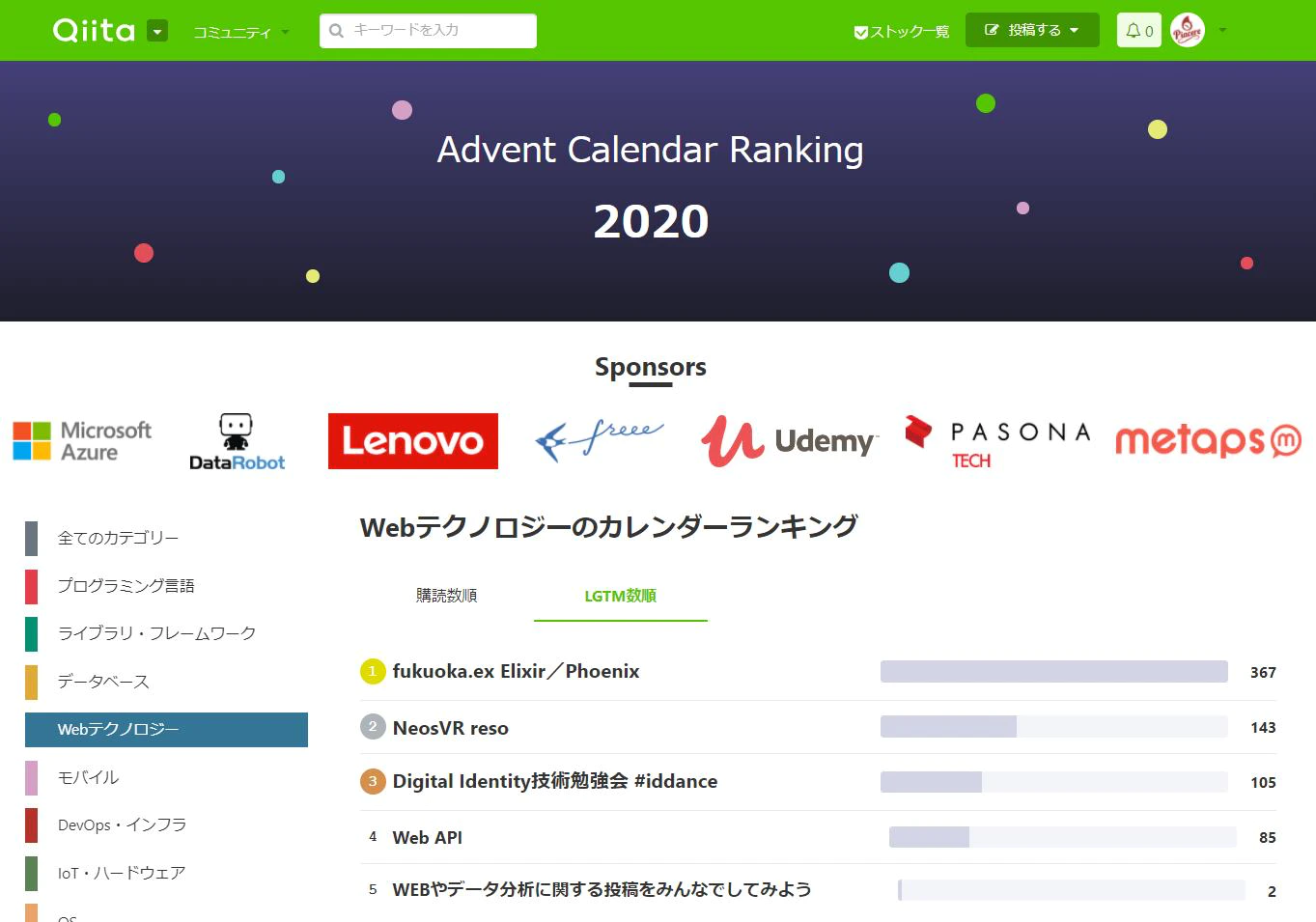
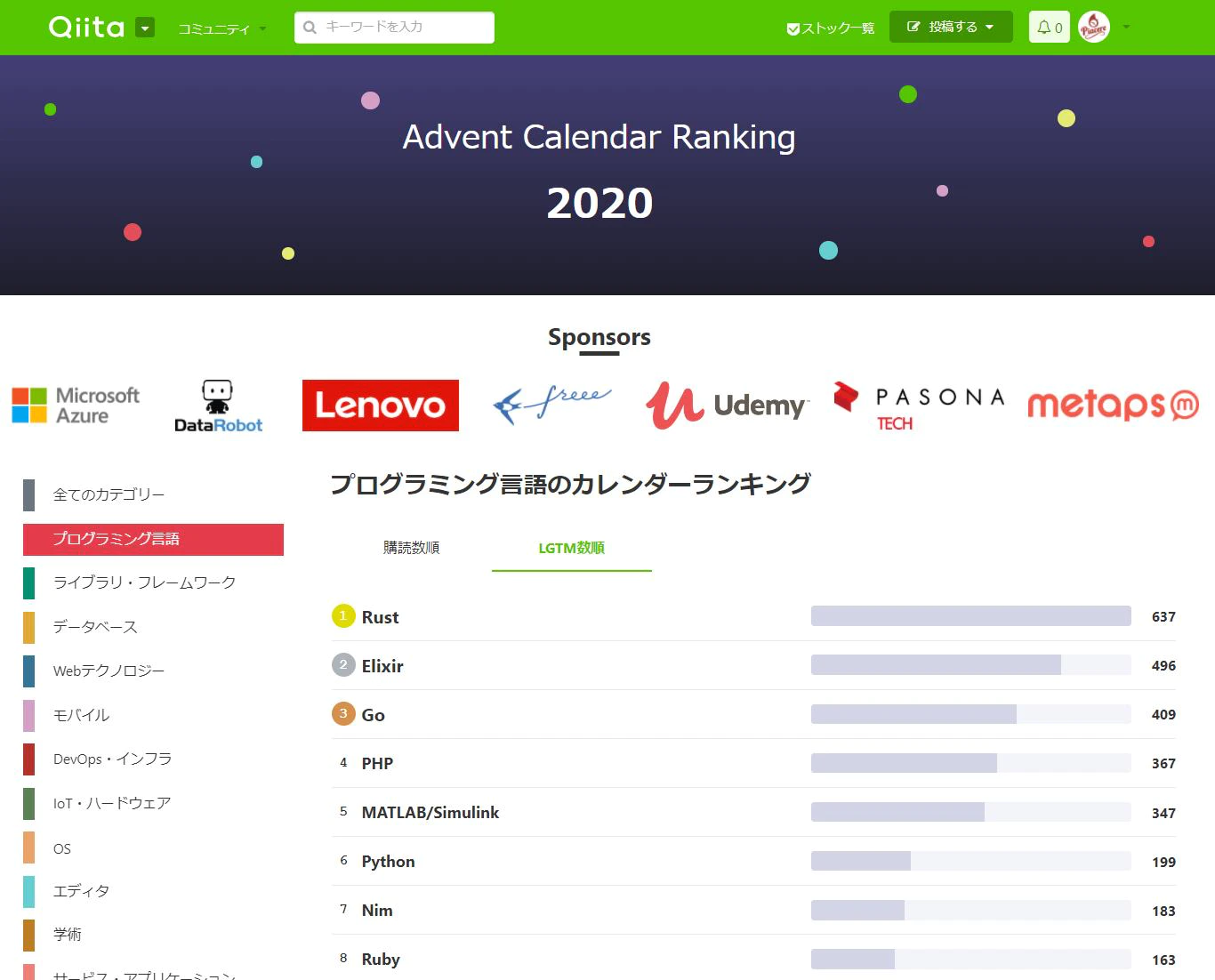
そして、プログラミング言語カテゴリは、1位がRust、2位がElixir、3位がGoとモダン言語揃い踏みでのトップ3、熱いネー![]()
https://qiita.com/advent-calendar/2020/elixir
データが溢れる時代へようこそ
私の別連載のコラムである「重力プログラミング入門」シリーズの後半でも述べている通り、データが入手困難だった時代は終わり、現代は「オープンデータが日常」である技術発展を遂げた、幸せな時代です ![]()
しかし、幾らデータが入手できるようになっても、そのデータを活かすための分析基盤構築のプロセスが重いままでは、せっかくのデータが台無しです
今後、ますます世界に溢れていく無数のデータを分析し、活用していくためには、データ分析基盤そのものを、シチュエーションに合わせて、手早く気軽かつアジャイルに組み立てられることが新たな価値となっていくでしょう ![]()
「データサイエンスプラットフォーム」とは?
Elixirは、様々なデータのパターンマッチ (バイナリデータも含む) が強力で、並行分散処理とマルチコア並列実行をいとも容易く実現できる、データ加工・変換に強みを持つ言語です
Pythonは、数値演算・科学計算・統計・解析のライブラリが豊富で、TensorFlowやKeras等、機械学習のベースプラットフォームとして一躍有名になった言語です
この2つを組み合わせることで、高速データ処理とディープラーニングを両立するデータ分析基盤、名付けて「データサイエンスプラットフォーム」をサクっと構築することが可能となります ![]()
(ちなみに今回は、コラムの長さの関係もあり、あまりKerasや機械学習について、触れるスペースが無いですが、これは今後の実践編コラムにて述べていこうと思いますので、あまり期待しないでください)
それでは実際に構築(5ステップあります)を行っていきましょう ![]()
①Elixirを使えるようにする
Elixirのインストール
Elixirのインストール方法は、この記事を読まれている方には今更な感じではあると思いますが、Elixir入門「第1回:パターンマッチ&パイプでJSONパースアプリをサクっと書いてみる」にて、各種OS・媒体でのインストール方法を簡単に紹介しており、Dockerベースのインストールについては詳細も記載しています

P11の手順に沿って、mix newで、適当なElixirプロジェクトを作成し、作成されたフォルダにcdしてください(このコラム内では、/code/配下に「pyex」というプロジェクトを作成した想定とします)
なお、「iex -S mix」は、まだ実行しないでください

Elixir側「ErlPort」のインストール
ElixirとPythonを繋ぐためのライブラリ、「ErlPort」をインストールする記述を追加します
defmodule Pyex.Mixfile do
…
defp deps do
[
…
{ :erlport, "~> 0.9.8" },
]
end
end
ライブラリをインストールします
mix deps.get
②Pythonを使えるようにする
Anacondaのインストール
Anacondaを使うと、Pythonおよび関連ライブラリのインストールが簡単になります
Anacondaのインストール方法は、AI入門「第3回:数学が苦手でも作って使えるKerasディープラーニング」という別シリーズでも扱っているため、こちらのスライドのP13~P16をご参考ください

Anacondaのインストールが完了後、ターミナルの起動まで終わったら、上記で作成済みのElixirプロジェクト配下に移動します
cd /code/pyex
Python側「ErlPort」のインストール
「ErlPort」のPython側をインストールします
pip install erlport
③ElixirからPythonを呼び出す
lib直下に、呼び出されるPythonコードを準備します
「受け取った値をprintし、10倍して返す」という内容です
def value_receive( value ):
print( "I'm Python...receive {0}".format( value ) )
return value * 10
同じくlib直下に、呼び出し側のElixirコードを準備します
defmodule Pyex do
def value_receive( value ) do
{ :ok, py_exec } = :python.start( [ python_path: 'lib' ] )
result = :python.call( py_exec, :py_sample, :value_receive, [ value ] )
IO.puts "received from python: #{result}"
:python.stop( py_exec )
end
end
ElixirからPythonを呼び出す準備が揃いましたので、iexを起動し、Pythonを呼び出すElixirを叩いてみます
iex -S mix
iex> Pyex.value_receive( 3 )
I'm Python...receive 3
received from python: 30
Python側の処理への数値の引き渡しと、処理後の戻りをElixirで取れました ![]()
今後は、リストを渡し、Python側で集計するコードを双方に追加しましょう
…
def list_receive( list ):
print( "I'm Python...receive {0}".format( list ) )
return sum( list )
defmodule Pyex do
…
def list_receive( list ) when is_list( list ) do
{ :ok, py_exec } = :python.start( [ python_path: 'lib' ] )
result = :python.call( py_exec, :py_sample, :list_receive, [ list ] )
IO.puts "received from python: #{result}"
:python.stop( py_exec )
end
…
実行します
iex> recompile
iex> Pyex.list_receive( [ 1, 2, 3 ] )
I'm Python...receive List([1, 2, 3])
received from python: 6
リスト集計もうまくいきました
Python側のグローバルメソッドだけで無く、オブジェクトも呼び出してみます
(なお、Elixirの文字列をPython側で受け取る場合は、UTF-8へのデコードが必要です)
…
class Sample( object ):
def __init__( self ):
print( " on python: __init__()" )
self.message = "Hello "
def arrange( self, name ):
print( " on python: arrange()" )
return self.message + name.decode( "utf-8" )
defmodule Pyex do
…
def call_class( value ) do
{ :ok, py_exec } = :python.start( [ python_path: 'lib' ] )
object = :python.call( py_exec, :py_sample, :Sample, [] )
result = :python.call( py_exec, :py_sample, :"Sample.arrange", [ object, value ] )
IO.puts "received from python: #{result}"
:python.stop( py_exec )
end
…
実行します
iex> recompile
iex> Pyex.call_class( "World" )
on python: __init__()
on python: arrange()
received from python: Hello World
オブジェクトのメソッド呼出もうまくいきました
④機械学習(Keras)を使えるようにする
ここまでで、ElixirとPythonのやり取りの基本的な部分は確認できたので、次は、Python側に機械学習エンジンである「Keras」をセットアップします
Kerasは、ディープラーニングを実現する機械学習エンジン「TensorFlow」をコアとして動作するラッパーライブラリで、本来、数学を用いて、ニューラルネットワークやディープラーニングを構築する必要があるところの大部分を代行してくれます

Kerasを使わず、TensorFlowそのままでコーディングした場合、「学習」部分を結構なコード量で記述することとなりますが、Kerasを使った場合、とても少ないコード量でシンプルにコーディングできるのが最大の特徴です
TensorFlowとKerasのインストール
上記のコードサンプルを実行したターミナルにて、スライドP17にある通り、TensorFlowとKerasをインストールし、PythonからKerasのimportが成功することを確認してください
Keras単品で機械学習を事前実行する
まず、Keras単品で機械学習できることを事前確認しておきます
サンプルとして、ノイズ入りサイン波を予測するKerasコードをPythonで組みます
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.layers.recurrent import LSTM
from keras.optimizers import Adam
import matplotlib.pyplot as plt
def sin( x, T = 100 ):
return np.sin( 2.0 * np.pi * x / T )
def noisy_sin( T = 100, ampl = 0.05 ):
x = np.arange( 0, 2 * T + 1 )
noise = ampl * np.random.uniform( low = - 1.0, high = 1.0, size = len( x ) )
return sin( x ) + noise
def build_dataset( inputs ):
input = []
expected = []
maxlen = 25
for i in range( len( inputs ) - maxlen ):
input.append( inputs[ i: i + maxlen ] )
expected.append( inputs[ i + maxlen ] )
re_input = np.array( input ).reshape( len( input ), maxlen, 1 )
re_expected = np.array( expected ).reshape( len( input ), 1 )
return re_input, re_expected
def predict():
f = noisy_sin()
input, expected = build_dataset( f )
length_of_sequence = input.shape[ 1 ]
in_out_neurons = 1
n_hidden = 300
model = Sequential()
model.add( LSTM( n_hidden, batch_input_shape =
( None, length_of_sequence, in_out_neurons ), return_sequences = False ) )
model.add( Dense( in_out_neurons ) )
model.add( Activation( "linear" ) )
optimizer = Adam( lr = 0.001 )
model.compile( loss = "mean_squared_error", optimizer = optimizer )
model.fit(input, expected,
batch_size = 500,
epochs = 80,
validation_split = 0.1
)
future_test = input[ 175 ].T
time_length = future_test.shape[ 1 ]
future_result = np.empty( ( 0 ) )
for step2 in range( 400 ):
test_data = np.reshape( future_test, ( 1, time_length, 1 ) )
batch_predict = model.predict( test_data )
future_test = np.delete( future_test, 0 )
future_test = np.append( future_test, batch_predict )
future_result = np.append( future_result, batch_predict )
predicted = model.predict( input )
plt.figure()
plt.plot( range( 0, len( f ) ), f, color = "b", label = "sin" )
plt.plot( range( 25, len( predicted ) + 25 ), predicted, color = "r", label = "predict" )
plt.plot( range( 0 + len( f ), len( future_result ) + len( f ) ), future_result, color = "g", label = "future" )
plt.legend()
plt.show()
if __name__ == "__main__":
predict()
グラフ表示のためのライブラリ「matplotlib」を使っているので、インストールします
なお、macOSだと、matplotlibを使うのに設定ファイルが必要なため、スライドP40を見て、設定を行ってください
pip install matplotlib
Kerasを実行します
python predict_sin.py
Using TensorFlow backend.
Train on 158 samples, validate on 18 samples
Epoch 1/80
(ここにwarningが入ることがあります)
158/158 [==============================] - 2s 15ms/step - loss: 0.4666 - val_loss: 0.1348
Epoch 2/80
158/158 [==============================] - 0s 3ms/step - loss: 0.3060 - val_loss: 0.0533
Epoch 3/80
158/158 [==============================] - 0s 3ms/step - loss: 0.1956 - val_loss: 0.0353
…
Epoch 78/80
158/158 [==============================] - 0s 2ms/step - loss: 0.0012 - val_loss: 0.0014
Epoch 79/80
158/158 [==============================] - 0s 3ms/step - loss: 0.0012 - val_loss: 0.0014
Epoch 80/80
158/158 [==============================] - 0s 3ms/step - loss: 0.0012 - val_loss: 0.0014
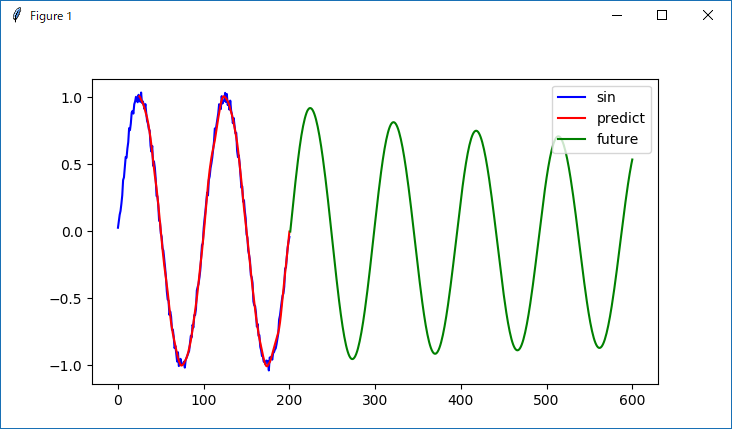
青線が入力データ、赤線が学習結果からの予測、緑線が未来の予測になります
⑤ElixirからKerasを呼び出す
lib直下に、先ほど作った機械学習のPythonコードを呼び出すElixirコードを追加します
defmodule Pyex do
…
def predict() do
{ :ok, py_exec } = :python.start( [ python_path: 'lib' ] )
:python.call( py_exec, :predict_sin, :predict, [] )
:python.stop( py_exec )
end
…
実行します
iex> recompile
iex> Pyex.predict()
Using TensorFlow backend.
Train on 158 samples, validate on 18 samples
Epoch 1/80
(ここにwarningが入ることがあります)
158/158 [==============================] - 2s 15ms/step - loss: 0.4666 - val_loss: 0.1348
Epoch 2/80
158/158 [==============================] - 0s 3ms/step - loss: 0.3060 - val_loss: 0.0533
Epoch 3/80
158/158 [==============================] - 0s 3ms/step - loss: 0.1956 - val_loss: 0.0353
…
Epoch 78/80
158/158 [==============================] - 0s 2ms/step - loss: 0.0012 - val_loss: 0.0014
Epoch 79/80
158/158 [==============================] - 0s 3ms/step - loss: 0.0012 - val_loss: 0.0014
Epoch 80/80
158/158 [==============================] - 0s 3ms/step - loss: 0.0012 - val_loss: 0.0014
ElixirからのKerasによる機械学習の呼出もうまくいきました

データ分析の成功の大半は「データクレンジング」「集計・統合」
ここまでの5ステップで、「データサイエンスプラットフォーム」のベースを手に入れました ![]()
あとは、このプラットフォームをデータ処理部分と、機械学習部分に分担し、実際の分析やデータサイエンスを行っていけばOKですが、事前知識として、「データ分析は80%以上が『データクレンジング』と『集計・統合』によって決まる」ということをお伝えしておきます
データ分析を多少なりともタッチされた方なら、ご存知のことですが、データ分析の元となるデータがキレイであるとは限りません![]()
また、構造化されたデータとも限りません(ログやJSONなどの非構造データを可変長として扱うと、間違いなく死ねれます)
そのため、データ分析がうまくいくか否かの大半は、統計や機械学習をかける前段のデータ処理、つまり「データクレンジング」と「集計・統合」をいかに高速かつ手軽に行えるかが勝負になります ![]()
ここで、Elixirの強みが120%発揮されます
それでは、どのように「データクレンジング」と「集計・統合」をElixirで構成していくか、見ていきましょう
a)データクレンジング
データクレンジングは、以下のような要素で構成されます
- フォーマットの統一
- 不要文字の除去
- 表記揺れの統一
- データ範囲(日時、項目数、データ数、フラグなど)の抽出・除外
- 想定外データの検出
- 項目数の過不足
- 項目の型と値のアンマッチ
- 使用禁止文字の混入
- 必須項目に空文字指定
- キー重複
- データ間の相関性の不整合
- 数値や文字列長が許可範囲外
- 時系列データの抜け
なお、時系列データやテキストデータだけで無い、信号データや画像データの場合は、ノイズ除去 (白色化) や特定周波数帯のカット等が更に含まれてきます(Elixirはバイナリデータの処理もパターンマッチ含め得意です)
データクレンジングをElixirでサクッと作る
実際にElixirで組むと、以下のようなコードになります
cleaned_data = data_filename
|> File.stream!
# データクレンジング
# ①フォーマットの統一
|> Enum.map( &( String.replace( &1, ",", "\t" ) ) ) # CSV→TSV
# ②不要文字の除去
|> Enum.map( &( String.replace( &1, "\r\n", "\n" ) ) ) # 改行除去
|> Enum.map( &( String.replace( &1, "\"", "" ) ) ) # ダブルクォート除去
# ③表記揺れの統一
|> Enum.map( &( String.replace( &1, "(株)", "株式会社" ) ) )
|> Enum.map( &( String.replace( &1, "株)", "株式会社" ) ) )
|> Enum.map( &( String.replace( &1, "(株", "株式会社" ) ) )
# ④データ範囲(日時、項目数、データ数、フラグなど)の抽出・除外
|> Enum.map( &( &1 |> String.split( "\t" ) ) )
|> Enum.filter( Enum.at( &1, 2 - 1 ) == "重度" end ) ) # 2番目の項目が「重度」のみ抽出
# ⑤想定外データの検出
if Enum.count( cleaned_data ) != 12, do: raise "invalid column length" # 項目数の過不足
Enum.each( cleaned_data, &( if Enum.at( &1, 4 - 1 ) == "", do: raise "column3 invalid empty" end ) ) # 4番目の項目が空はエラー
各クレンジング処理とコードが、イコールであり、とても見通しが良いコードになっています
これをオブジェクト指向言語(Java、Go等)で記述すると、ループ指定や配列処理、集約のコード化等で、ゴチャゴチャしたコードになりがちなところを、関数型の強みを活かした、スッキリしたコードで、「処理の本質」のみを記述できるところが、Elixirの非常に魅力的なところです
なお上記は、CSVファイルをインプットとした例ですが、対象は、RDBやRedshift、Hive、インメモリーDB(ETS、mnesia、Redis等)、JSON API…何であっても構いません
Elixirは、強力なパターンマッチと関数処理に裏付けられた「データ変換に強みを持つ言語」でもあるので、バイナリデータ含む、あらゆるデータを混合してインプットしても、最終的に得たいデータの形へと整形していきやすく、この特性が「データサイエンスプラットフォーム」を構成するのに多大な影響を及ぼしています ![]()
なお、この特性は、データ分析だけにとどまらず、多種多様なインプットを併用するようなWebアプリ開発なんかにも威力を発揮しますが、これはまた別のコラムにてご紹介したいと思います ![]()
Flowでデータクレンジングを劇的に性能アップ(数倍レベル)
更に、上記コードをマルチコアCPU活用により、高速な並列処理へとアップグレードすることも簡単にできます
まず、「Flow」をインストールします
defmodule Pyex.Mixfile do
…
defp deps do
[
…
{ :flow, "~> 0.12.0" },
]
end
end
ライブラリをインストールします
mix deps.get
以下、Flow対応したコードです
cleaned_data = data_filename
|> File.stream!
# Flow開始(引数stages:でステージ数を設定することで、更にメモリーを使った高速化が可能)
|> Flow.from_enumerable()
# データクレンジング
# ①フォーマットの統一
|> Flow.map( &( String.replace( &1, ",", "\t" ) ) ) # CSV→TSV
# ②不要文字の除去
|> Flow.map( &( String.replace( &1, "\r\n", "\n" ) ) ) # 改行除去
|> Flow.map( &( String.replace( &1, "\"", "" ) ) ) # ダブルクォート除去
# ③表記揺れの統一
|> Flow.map( &( String.replace( &1, "(株)", "株式会社" ) ) )
|> Flow.map( &( String.replace( &1, "株)", "株式会社" ) ) )
|> Flow.map( &( String.replace( &1, "(株", "株式会社" ) ) )
# ④データ範囲(日時、項目数、データ数、フラグなど)の抽出・除外
|> Flow.map( &( &1 |> String.split( "\t" ) ) )
|> Flow.filter( Enum.at( &1, 2 - 1 ) == "重度" end ) ) # 2番目の項目が「重度」のみ抽出
# Flow終了(ただし、集計・統合をこの後、続けて行うなら、ここで終了にしないこと)
|> Enum.to_list
# ⑤想定外データの検出
if Enum.count( cleaned_data ) != 12, do: raise "invalid column length" # 項目数の過不足
Enum.each( cleaned_data, &( if Enum.at( &1, 4 - 1 ) == "", do: raise "column3 invalid empty" end ) ) # 4番目の項目が空はエラー
行った改修は、「Enum」の箇所を「Flow」に置き換え、Flow開始・終了の行を追加しただけですが、これだけで、マルチコアによる並列処理化され、物理コアx2/論理コアx4程度しか装備していなくても、Enumと比較して、ナント約5倍の性能アップが可能です(後述の集計・統合を通したら6~7倍まで短縮されることもあります) ![]()
物理コアx2/論理コアx4だけでも、これだけ性能アップしますが、もっとコア数が多い…たとえば、AWSの「R4.16xlarge」であれば、64コアもあるため、比べ物にならないレベルで性能が跳ね上がります
また、Flow.from_enumerable()の引数「stages:」でステージ数を最適化すると、メモリーは消費するものの、タスク粒度が小さくなり、より各コアにタスクを分配しやすくなるため、更なる高速化も可能で、もう30%性能アップを上乗せできます(元と比べたら6.5倍の性能アップ、集計・統合を通したら8~9倍の性能アップ) ![]()
たとえば、ステージ数を16段に設定するときは、以下のコードとなります
Flow.from_enumerable( stages: 16 )
b)集計・統合
集計・統合は、以下のような要素で構成されます
SQLで行う「集合」「グルーピング」「ソート」「結合」等の処理をイメージしていただければ近いです
- 件数カウント
- 最大・最小・平均・標準偏差
- 最新日時・最古日時
- 集約・グルーピング・クラスタリング
- 年代別
- 性別
- 年収別
- 地域別
- 業種別
- その他、属性情報別 (デモグラフィック)
- 名寄せ、重複データの削除
- 集計・統合後のデータ範囲の抽出・除外
- 正規化・非正規化・次元変換
- ソート
集計・統合をElixirでサクッと作る
実際にElixirで組むと、以下のようなコードになります(上記のクレンジングの続きになります)
6番目の項目の「出現数」が10以上のものを抽出したクレンジング後データを取得する例になります
…
integrated_data =
cleaned_data
# 集計・統合
# ④集約・グルーピング・クラスタリング
|> Enum.map( &Enum.at( &1, 3 - 1 ) ) # 3番目の項目を抽出
|> Enum.reduce( %{}, fn( name, acc ) # 同値の出現数を集計
-> Map.update( acc, name, 1, &( &1 + 1 ) ) end )
# ⑥集計・統合後のデータ範囲の抽出・除外
|> Enum.filter( &( elem( &1, 1 ) >= 10 ) ) # 出現数が10以上のものだけ抽出
# ⑦正規化・非正規化・次元変換
|> Enum.map( # 3番目の項目に一致するクレンジング後データを連ねる
fn { category, frequency }
->
%{
"category" => category,
"frequency" => frequency,
"originals" => cleaned_data |> Enum.filter( &( Enum.at( &1, 3 - 1 ) == category ) )
}
end )
# ⑧ソート
|> Enum.sort( &( &1[ "frequency" ] > &2[ "frequency" ] ) ) # 出現数の多い順でソート
各集計・統合処理とコードについても、やはりイコールであり、見通しが良く、やりたい処理のみを記述できています
上記の実行結果は、各業種の出現数と、その業種に属する企業情報(クレンジング後)がぶら下がる、以下のような結果になります
[%{"category" => "通信業", "frequency" => 13, "originals" => [
["株式会社xxxxxxxx", "上場", "通信業", "1993-02-02", "19", "xxx@xxxxx.com", "573", "2008-01-09"],
["xxxxxxxx株式会社", "上場", "通信業", "1950-09-16", "2", "xxx@xxxxx.org", "702", "2012-03-30"],
…
%{"category" => "流通業", "frequency" => 12, "originals" => [
["xxxxxxxx株式会社", "非上場", "流通業", "1978-12-17", "32", "xxx@xxx.co.jp", "908", "2012-02-04"],
["株式会社xxxxxxxx", "上場", "流通業", "2006-03-26", "78", "xxx@xxxxx.jp", "573", "2008-01-09"],
…
このように、やりたい処理をひたすら連ねるだけで、データの形や内容を自由に構成できる、このElixirの言語特性が、データ加工・変換には、かなりマッチしていると思います ![]()
なお、全要素のケースはご紹介できないのですが、いずれも「リスト処理の組み合わせ」で実現できることをイメージしてみてください
Flowで集計・統合も劇的に性能アップ
上記コードを、Flowで高速化するのも実に簡単です
…
integrated_data =
cleaned_data
# 集計・統合
# ④集約・グルーピング・クラスタリング
|> Flow.map( &Enum.at( &1, 3 - 1 ) ) # 3番目の項目を抽出
# (Flowを使っているときは、reduceする直前にパーティション化しておく)
|> Flow.partition
|> Flow.reduce( fn -> %{} end, fn( name, acc ) # 同値の出現数を集計
-> Map.update( acc, name, 1, &( &1 + 1 ) ) end )
# ⑥集計・統合後のデータ範囲の抽出・除外
|> Flow.filter( &( elem( &1, 1 ) >= 10 ) ) # 出現数が10以上のものだけ抽出
# ⑦正規化・非正規化・次元変換
|> Flow.map( fn # 3番目の項目に一致するクレンジング後データを連ねる
{ category, frequency }
->
%{
"category" => category,
"frequency" => frequency,
"originals" => cleaned_data |> Enum.filter( &( Enum.at( &1, 3 - 1 ) == category ) )
}
end )
# ⑧ソート
|> Enum.sort( &( &1[ "frequency" ] > &2[ "frequency" ] ) ) # 出現数の多い順でソート
行った改修は、「Enum」の箇所を「Flow」に置き換え、reduceする直前にパーティション化の行を追加しただけで、やはり簡単です
これだけで、元の処理の8~9倍の性能アップが実現できる「Flow」は、凄まじい機能で、Elixirを採用する大きなモチベーションになるのではないでしょうか?(fukuoka.ex #4では、JavaやGoとの同等処理との比較も行い、大半がElixirに可能性を感じていたようです) ![]()
「データクレンジング」と「集計・統合」のパーツ集
「データクレンジング」と「集計・統合」を行う上で、EnumやListのシンプルな標準機能だけでも、かなりのことは実現できるのですが、少しコツがいる処理の幾つかを、パーツという形でご紹介したいと思います ![]()
Enum.map( fn
%{
"id" => ticket_no,
"issueKey" => account_id,
"summary" => title,
"created" => created_at,
"updated" => updated_at,
}
->
%{
"type" => "Backlog",
"account_name" => account_id,
"ticket_no" => ticket_no,
"title" => title,
"url" => "https://xxx.backlog.jp/view/" <> account_id,
"created_at" => created_at,
"updated_at" => updated_at,
}
end )
Enum.into( List.zip( [ map_list1, map_list2 ] ), %{} )
empty_value = ""
keys = map_list
|> List.first
|> Map.delete( match_key )
|> Map.keys
Enum.into( List.zip( [ keys, List.duplicate( empty_value, Enum.count( keys ) ) ] ), %{} )
match_keys = [ "3", "10", "21" ]
match_map_list =
base_map_list
|> Enum.filter( &( match_keys |> Enum.member?( &1[ "id" ] ) ) )
|> Enum.map( &( <ここに加工処理> ) )
nomatch_map_list =
base_map_list
|> Enum.filter( &( !( match_keys |> Enum.member?( &1[ "id" ] ) ) ) )
match_map_list ++ nomatch_map_list
非構造データを扱えるようにする
最後に、非構造データをデータ処理できるレベルに定形化するためのコツをお伝えして、このコラムは終わりにしようと思います
RDBやCSVのような、比較的データの縦横の数が決まっているデータは、中の値はともかく、データの行列としては、扱いやすいため、Elixirでのリスト処理で困ることはあまりありません
一方、JSONやログファイルのような、行も列も可変だったり、そもそも行毎でフォーマットの異なるようなデータは、リスト処理以前に、どうデータを扱えば良いかに困ることがあります ![]()
そんなとき、Elixirには、「Regexd.named_captures()」という、とても心強い味方がいます
たとえば以下のような、あまりキレイとは言えず、項目もバラバラのログがあるとします
2017-09-14 03:46:03.818304, [subtype] bot_message, [username] segment_generate@PB-17
[pretext] [recover] failed to generate segment [fields] <<account>> [id: 99] xxxxxx(株)<<segment>> [id: 5265] マッチング_勤務地_027xxx
<<detail>> [リトライ1 / 2回目] 処理に成功しました。 <!channel>, [channel_id] C2T6xxZP1, [channel_name] <この後情報が延々と続く…>
2017-09-14 04:21:04.931377, [subtype] bot_message, [username] segment_generate@PB-16
[pretext] [critical] failed to generate segment [fields] <<account>> [id: 108] 株式会社xxxxx <<segment>> [id: 6959]
<<detail>> PG::UndefinedTable: ERROR: relation customers_bd_wyna8r_1 does not exist
insert into segments_bd_wyna8r_1__20170914034556(segment_id, visitor_id) select 6959, visitor_id from <この後SQLが長々と続く…>
2017-09-14 04:27:03.598821, [subtype] bot_message, [username] batch(externaldata_import)@SB-01
[pretext] [critical] externaldata_import
…
このログから、エラーの出た顧客ID/顧客名のみを抜き出し、マップリスト化するコードは、こんな感じになります
"any.log"
|> File.stream!
|> Stream.filter( &( String.contains?(
&1, "[pretext] [critical] failed to generate segment" ) ) )
|> Stream.map( &( Regex.named_captures(
~r/<<account>> \[id: (?<accNo>.*)] (?<accName>.*) <<segment>>/, &1 ) ) )
|> Enum.to_list
まず、エラーが出た行のみを抽出し、その中で、顧客ID/顧客名の記述にマッチした場合のみ、顧客ID/顧客名を抜き出し、以下のようなマップリスト化します
[
%{ "accNo" => 42, "accName" => "株式会社xxxxx" },
%{ "accNo" => 69, "accName" => "xxxxx(株)" },
%{ "accNo" => 71, "accName" => "xxxxx株式会社" },
…
]
ここまで定型化できれば、後は、既に述べた「データクレンジング」&「集計・統合」の世界で扱えると思います
また、一度マップリスト化されれば、Elixirでは「関数の引数でのパターンマッチ」も可能となるため、キーの組み合わせ(もしくは値そのもの)でデータ加工・変換をスイッチしたりといった、強力かつ柔軟に扱える魅力も、Elixirならではですね ![]()
なお、JSONデータについては、「Poison」というライブラリを使えば、JSONデータをElixirのマップリストに一発で変換してくれるので、そこからEnumやパターンマッチで必要なデータを絞り込むのが、最初の一歩となります
気軽にデータ分析基盤を構築できれば、もっとデータを活用できる
ビジネスデータはもちろんのこと、今後は、IoTや宇宙観測の発展により、ますます世界には、無数のデータが溢れていきます
データ分析基盤そのものを、今回ご紹介したような「データサイエンスプラットフォーム」をサクっと構築し、様々なシチュエーションや利用シーンに合わせたデータ分析ができることは、とても強い武器となるでしょう
今回は、Elixir Advent Calendarなので、主にElixirに焦点をあて、Elixirでの「データクレンジング」と「集計・統合」が、いかにシンプルかつ簡単で、マルチコアをフル活用することでいとも容易く高速化できるかをお伝えしました
機械学習のパートについては、あまり触れられませんでしたが、こちらはQiitaにも多数のサンプルや例があるので、機械学習の基本的なセットアップができている「データサイエンスプラットフォーム」があれば、サンプルを読み進め、あなたのデータ分析に応用するのは、それほど難しく無いでしょう
またPythonは、純粋な数値演算や統計計算の強みもあります(≒GPUによる超高速な行列演算が可能)し、ディープラーニングエンジン同様、手作りするには難しい科学計算ライブラリも多数ありますので、機械学習に限らないデータ分析も期待できます
数年前であれば、数百万クラスの投資が必要であった、このようなデータ分析基盤の構築が、オープンソースのみで実現してしまうこの凄い時代に「現役のエンジニア・プログラマ」としていられることは、本当に嬉しいことだと思います ![]()

---終わり---
p.s.
ハッシュタグ#fukuokaex にて、fukuoka.ex開催時は参加メンバーがつぶやいており、開催が無いときでも私が頻繁にElixir/Phoenixのネタをつぶやいてますので、ウォッチいただけたら幸いです ![]()