クレイジングをする方法を学ぶ
ノック11:データの読み込み
ノック11.py
import pandas as pd
uriage_data=pd.read_csv("uriage.csv")
kokyaku_data=pd.read_excel("kokyaku_daicho.xlsx")
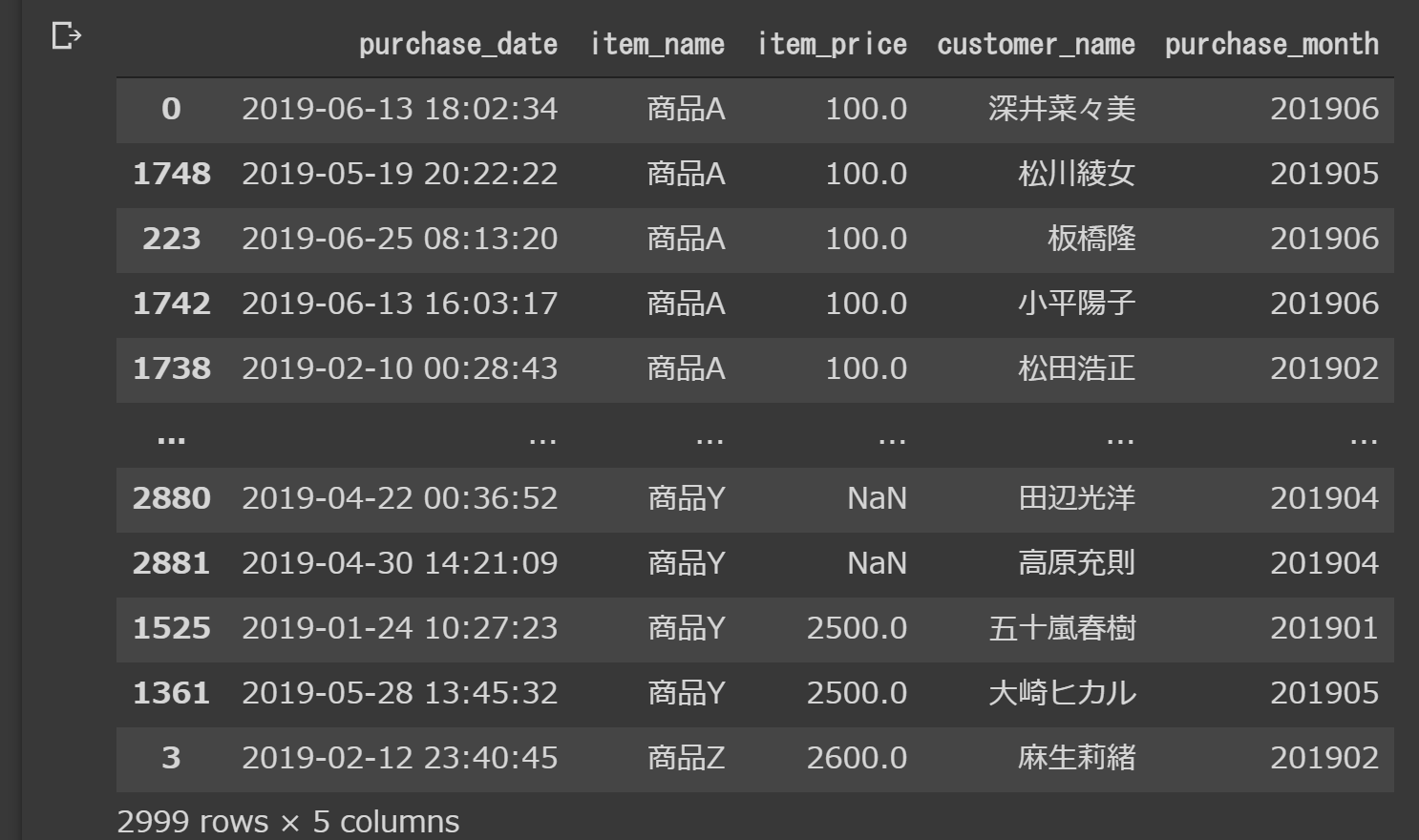
uriage_data

kokyaku_data

ノック12:データの揺れ
ノック12.py
uriage_data["item_name"].head()

ノック12.py
uriage_data["item_price"].head()

ノック13:データ揺れがあるまま集計すると...
ノック13.py
uriage_data["purchase_date"]=pd.to_datetime(uriage_data["purchase_date"])
uriage_data["purchase_month"]=uriage_data["purchase_date"].dt.strftime("%Y%m")
res=uriage_data.pivot_table(index="purchase_month",columns="item_name",aggfunc="size",fill_value=0)
res
fill_value(欠損値を何で埋めるか?)

ノック13.py
res=uriage_data.pivot_table(index="purchase_month",columns="item_name",values="item_price",aggfunc="sum",fill_value=0)
res
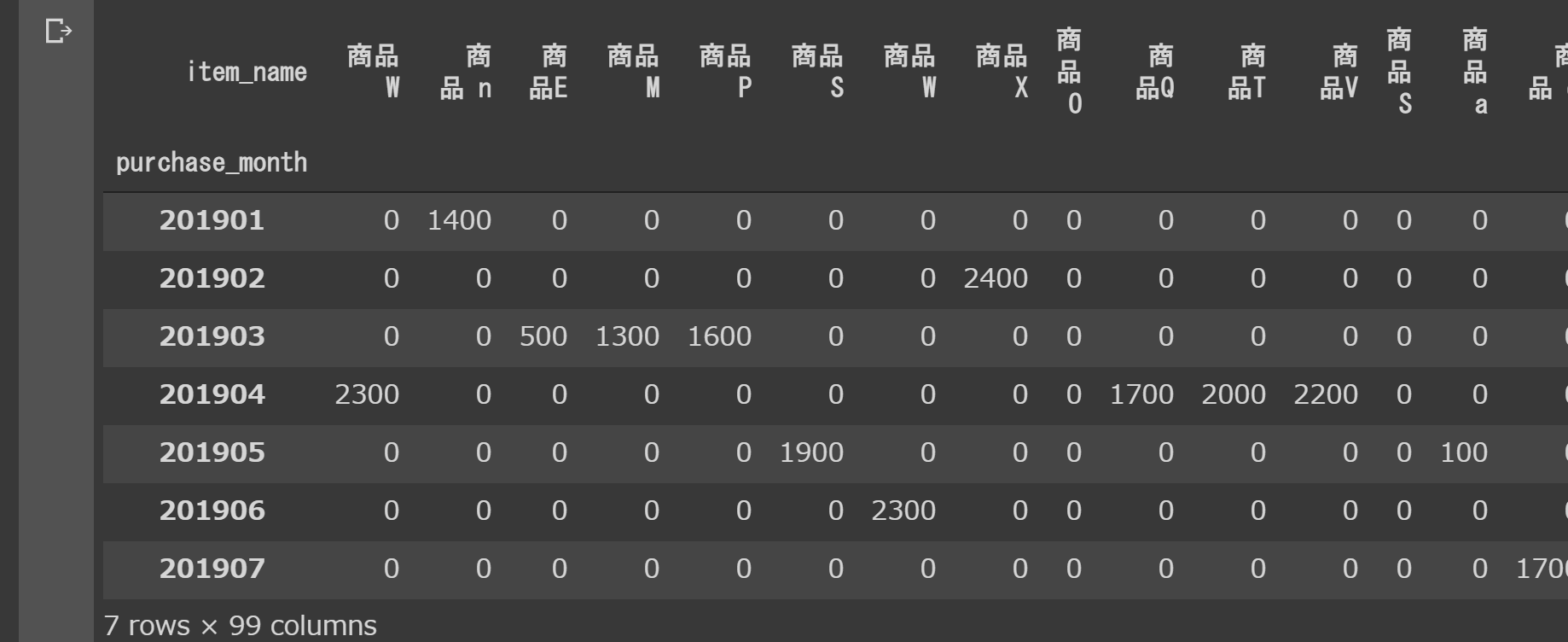
本来26個の商品が99商品に増えてることがわかる!
ノック14:商品名の揺れを補正
ノック14.py
print(len(pd.unique(uriage_data.item_name)))#再確認
>>>99
ノック14.py
uriage_data["item_name"]=uriage_data["item_name"].str.upper()#小文字を大文字へ
uriage_data["item_name"]=uriage_data["item_name"].str.replace(" ","")#半角スペースを除去
uriage_data["item_name"]=uriage_data["item_name"].str.replace(" ","")#全角スペースを除去
uriage_data.sort_values(by=["item_name"],ascending=True)#item_name順にソートする
ノック15:金額欠損値の補完
ノック15.py
uriage_data.isnull().any(axis=0)#item_priceに欠損値があることが分かる

ノック15.py
flg_is_null=uriage_data["item_price"].isnull()#item_priceの中で欠損値がある行を保存
for trg in list(uriage_data.loc[flg_is_null,"item_name"].unique()):#flg_is_nullの中でitem_nameを(商品名の重複を無くして)ループさせる
price=uriage_data.loc[(~flg_is_null) & (uriage_data["item_name"]==trg),"item_price"].max()#~flg_is_nullはflg_is_null==Flase
uriage_data["item_price"].loc[(flg_is_null) & (uriage_data["item_name"]==trg)]=price#item_price列に対して.locを行い、欠損を起こしている対象データを抽出して先ほど生成したpriceを欠損値に代入する
uriage_data.head()

ノック15.py
for trg in list(uriage_data["item_name"].sort_values().unique()):
print(trg+"の最大額:"+str(uriage_data.loc[uriage_data["item_name"]==trg]["item_price"].max())+"の最小額:"+str(uriage_data.loc[uriage_data["item_name"]==trg]["item_price"].min(skipna=False)))#.min(skipna=False)はNaNデータを無視するかを設定する
ノック16:顧客名の揺れを補正
ノック16.py
kokyaku_data["顧客名"].head()

ノック16.py
kokyaku_data["顧客名"]=kokyaku_data["顧客名"].str.replace(" ","")
kokyaku_data["顧客名"]=kokyaku_data["顧客名"].str.replace(" ","")
kokyaku_data["顧客名"].head()

ノック17:日付の揺れを補正
ノック17.py
flg_is_serial=kokyaku_data["登録日"].astype("str").str.isdigit()
flg_is_serial.sum()
>>>22#22件数値型として取り込まれている
**astype()**はデータ型を変更する
**str.isdigit()**は顧客台帳の登録日が数値かどうかを判定する
ノック17.py
# to_timedelta関数を使ってシリアル値を日付型に変換する。
fromSerial=pd.to_timedelta(kokyaku_data.loc[flg_is_serial,"登録日"].astype("float"),unit="D")+pd.to_datetime("1900/01/01")
fromSerial
詳細は以下
https://chusotsu-program.com/pandas-to-timedelta/

ノック17.py
# 日付として取り込まれているデータも、書式統一のために処理
fromString=pd.to_datetime(kokyaku_data.loc[~flg_is_serial,"登録日"])
fromString

ノック17.py
# データを合体
kokyaku_data["登録日"]=pd.concat([fromSerial,fromString])
kokyaku_data

ノック17.py
# 登録年月別に顧客数を集計する
kokyaku_data["登録年月"]=kokyaku_data["登録日"].dt.strftime("%Y%m")
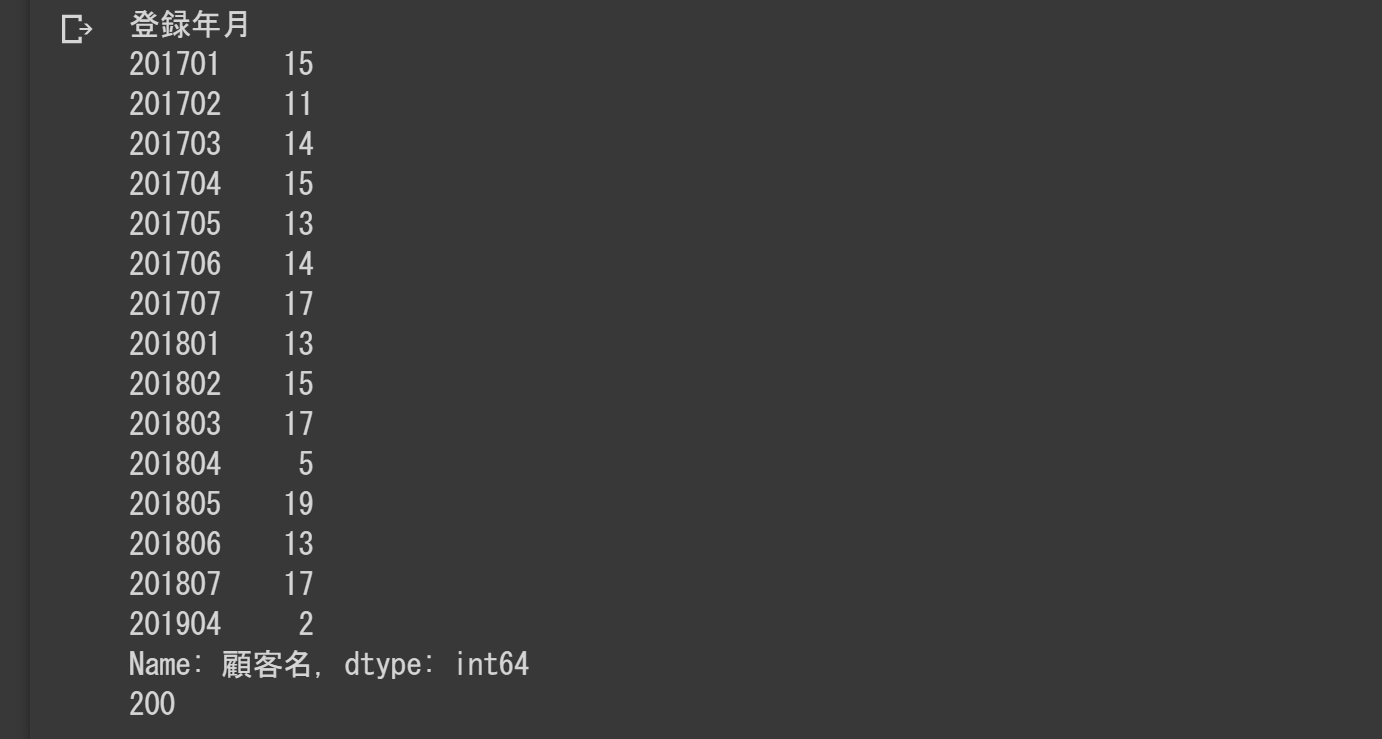
rslt=kokyaku_data.groupby("登録年月").count()["顧客名"]
print(rslt)
print(len(kokyaku_data))
ノック17.py
# データ型統一確認
flg_is_serial=kokyaku_data["登録日"].astype("str").str.isdigit()
flg_is_serial.sum()
>>>0#数値型は0件だと確認できた
ノック18:顧客名をキーに2つのデータを結合
ノック18.py
# ノック18
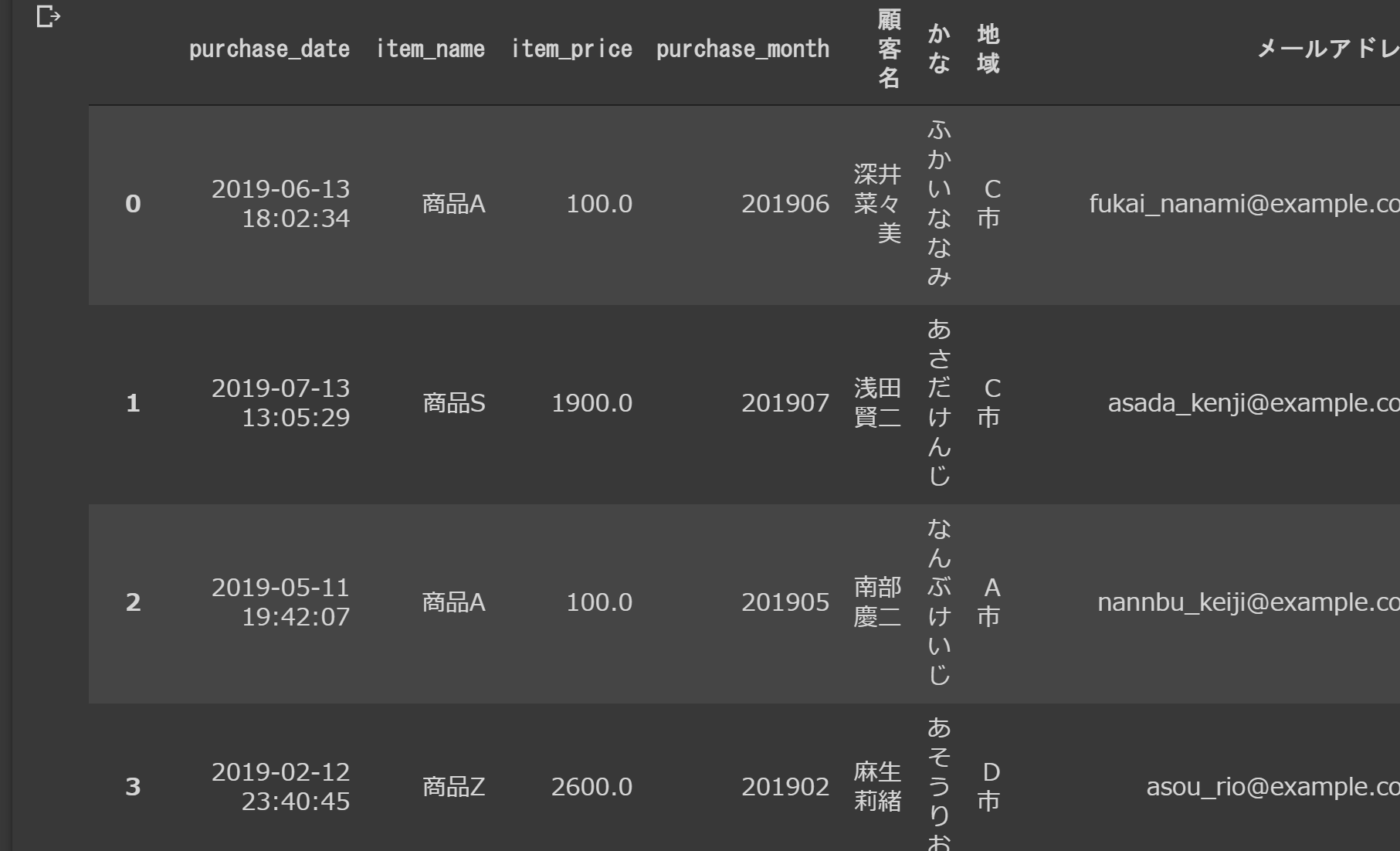
join_data=pd.merge(uriage_data,kokyaku_data,left_on="customer_name",right_on="顧客名",how="left")
join_data=join_data.drop("customer_name",axis=1)
join_data
left_onはuriage_dataに含まれるキーをジョイントキーとする
right_onはkokyaku_dataに含まれるキーをジョイントキーとする
**join_data.drop("customer_name",axis=1)**はcustomer_name列を削除する
ノック19:クレイジングしたデータをダンプする
ノック19.py
# 列の順番を変えて見やすくする
dump_data=join_data[["purchase_date","purchase_month","item_name","item_price","顧客名","かな","地域","メールアドレス","登録日"]]
dump_data

ノック19.py
# dump_data.csvを出力させる
dump_data.to_csv("dump_data.csv",index=False)
ノック20:データを集計する
ノック20.py
byItem=import_data.pivot_table(index="purchase_month",columns="item_name",aggfunc="size",fill_value=0)
byItem

ノック20.py
byPrice=import_data.pivot_table(index="purchase_month",columns="item_name",values="item_price",aggfunc="sum",fill_value=0)
byPrice

ノック20.py
byRegion=import_data.pivot_table(index="purchase_month",columns="地域",aggfunc="size",fill_value=0)
byRegion

ノック20.py
# 集計期間で購入していないユーザをチェック
away_data=pd.merge(uriage_data,kokyaku_data,left_on="customer_name",right_on="顧客名",how="right")
away_data[away_data["purchase_date"].isnull()][["顧客名","メールアドレス","登録日"]]
**away_data["purchase_date"].isnull()**は欠損値があるとTrue
