問題
pandasのデータフレームの中の値を並べ替える時によくsort_valuesというメソッドが使われていますね。
使う時普段は並べ替えの基準にしたい列を指定して、その列の値に並べ替えることになります。それ自体はちゃんとできたいます。ただし、もしその列の値は同じだったら、その同じ値の中でどのように並ぶでしょう?
試しにこんな簡単なデータフレームを作ってみます。
import pandas as pd
df = pd.DataFrame([1]*10+[0]*10,columns=['x'])
print(df)
そして並べ替えてみます。
x
0 1
1 1
2 1
3 1
4 1
5 1
6 1
7 1
8 1
9 1
10 0
11 0
12 0
13 0
14 0
15 0
16 0
17 0
18 0
19 0
print(df.sort_values('x'))
結果
x
19 0
17 0
16 0
15 0
14 0
13 0
12 0
11 0
10 0
18 0
0 1
7 1
6 1
5 1
4 1
3 1
2 1
1 1
8 1
9 1
なんかおかしい!
0が1より先であることは正しくて問題ないのですが、左のインデックスを見てください。なぜか勝手に並べ替えられていますね。しかも不規則でなぜこのような並べ方になっているか謎です。
この並びは完全にランダムっていうわけではなく、毎回の実行で結果は同じです。ただし環境によって結果は違うから移行の時に再現性がよくないです。同じパソコンでもPythonのバージョンが違ったりすると結果が違う可能性もあります。
指定した列以外の順番がどうでもいいという場合も多いのですが、気になる場合も多いでしょう。例えばただその列を基準に大きなグループを分けたいだけなどの場合。その時グループ内の順番を保ちたいはずですね。
sort_valuesは便利なメソッドですが、
こういう落とし穴があるということは、留意しておく必要があるのですね。
私は仕事で使っている途中でこの問題に直面してしまって数時間引っかかってしまいました。googleで調べても意外と答えが見つからないです。sort_valuesは一般に使われているのに誰もこのおかしな仕様について言及していません。これは不思議に思っています。
でも暫く頑張って調べ続けたら漸く原因と解決方法を見つけました。
だからこの記事はこれについて説明します。
原因と解決
pandasのsort_valuesは中身ではnumpyのsort関数を使っているようです。だからこれはもともとnumpyからの問題ですね。
numpyのsortにはkindというパラメータがあります。これは並べ替えのアルゴリズムを決めるパラメータです。
そして既定値ではquicksortというアルゴリズムにされているようです。詳しいことは説明されていないが、これは一番早いアルゴリズムだから特に気にしない時にこれを使うのが一番でしょう。
だけどこれを使うとまず順番は不規則に並べ替えられるというのは問題があります。早いけど、結果は不安定という欠点がありますね。
安定な結果が得られるようにkind='mergesort'にすることは勧められています。これを使うことで並べ替えの速度が落ちますが、安定で望ましい結果が得られます。
そしてこれはpandasのsort_valuesの中でも使えます。
上述の問題はこう書けばいいです。
print(df.sort_values('x',kind='mergesort'))
結果
x
10 0
11 0
12 0
13 0
14 0
15 0
16 0
17 0
18 0
19 0
0 1
1 1
2 1
3 1
4 1
5 1
6 1
7 1
8 1
9 1
これで解決!
速度の比較
mergesortにしたら問題が解決できるとわかりましたが、気になるのはやはり速度ですね。名前通りquicksortは早いはずです。規則性を犠牲にしてまでだから。
ではどれくらい違うか具体的に試してみましょう。違う長さのデータフレームで、それぞれ10回やって中央値を取ります。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import time
lis_n = [1000,3000,10000,30000,100000,300000,1000000,3000000,10000000,30000000]
ar_dt1 = np.empty([len(lis_n),10])
ar_dt2 = ar_dt1.copy()
for i,n in enumerate(lis_n):
df = pd.DataFrame(np.random.random(n))
for j in range(10):
t0 = time.time()
df.sort_values(0,kind='quicksort')
ar_dt1[i][j] = time.time()-t0
t0 = time.time()
df.sort_values(0,kind='mergesort')
ar_dt2[i][j] = time.time()-t0
med1 = np.median(ar_dt1,1)
med2 = np.median(ar_dt2,1)
print(pd.DataFrame({'n': lis_n, 'quicksort': med1, 'mergesort': med2}).set_index('n'))
lis_t = [[n]*10 for n in lis_n]
plt.figure(figsize=[6,4],dpi=100)
plt.scatter(lis_t,ar_dt1,10,c='r')
plt.scatter(lis_t,ar_dt2,10,c='b')
plt.plot(lis_t,med1,'--r')
plt.plot(lis_t,med2,'--b')
plt.legend(['quicksort','mergesort'])
plt.loglog()
plt.show()
結果
quicksort mergesort
n
1000 0.000036 0.000059
3000 0.000072 0.000168
10000 0.000520 0.000673
30000 0.001542 0.002100
100000 0.005836 0.008300
300000 0.019773 0.029987
1000000 0.077070 0.126180
3000000 0.285578 0.525177
10000000 1.213288 3.129783
30000000 4.268437 14.231498
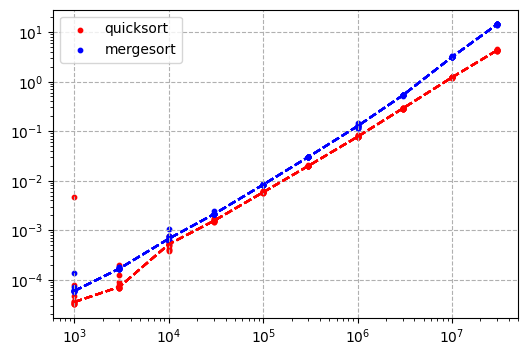
結果から見たら違いは2倍程度ですね。しかもデータフレームのサイズが大きくなるとその差も大きくなる傾向があるようです。データが3000万行の場合は3倍以上時間がかかります。
こう見るとどれくらい安定な結果や再現性が必要かどうか検討する必要があるでしょう。指定した列以外の順番がどうでもいいなら普段のquicksortのままで問題ないはずでそれでいいでしょう。でも他の順番も気になるのなら、やはりmergesortにする必要があるでしょう。
複数列を指定する場合
実は、この問題は実はsort_valuesに一つの列だけ指定した場合だけ発生することです。
複数列を指定する場合、そもそも並べ替えのアルゴリズムは違って、kindの効果はないらしいです。
試しに。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randint(0,2,[20,3]),columns=['x','y','z'])
print(df.sort_values(['x','y']))
結果
x y z
4 0 0 0
6 0 0 0
14 0 0 0
19 0 0 0
0 0 1 0
1 0 1 0
5 0 1 0
13 0 1 0
7 1 0 0
9 1 0 1
10 1 0 1
16 1 0 1
17 1 0 1
2 1 1 0
3 1 1 0
8 1 1 0
11 1 1 0
12 1 1 1
15 1 1 1
18 1 1 1
このように特に何もしなくても、指定された列がどれも同じ行の間は元通り並んでいます。
だからこの問題のもう一つの解決方法は、最初から複数列で並べ替えることです。
もっと読む
pandasのsort_valuesに関する他の記事。