基礎集計の際によく使うものをメモ、随時更新予定
前準備
from sklearn import datasets
import pandas as pd
from collections import OrderedDict
iris = datasets.load_iris()
df = pd.concat([pd.DataFrame(iris.data,columns=iris.feature_names),pd.DataFrame(iris.target,columns=["species"])],axis=1)
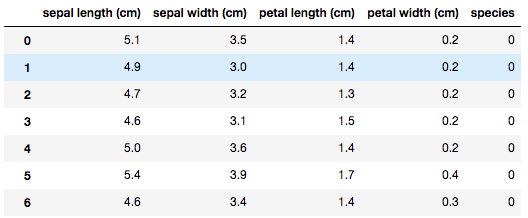
最近のアップデートで、pandasが見やすくなったのは嬉しい
集計
describe
df.describe()
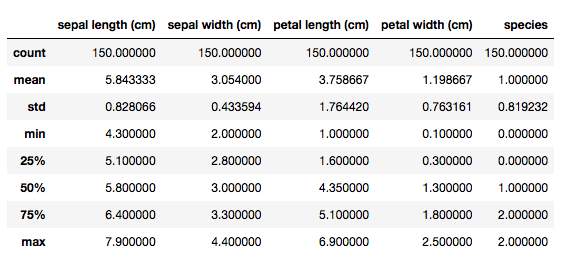
基本統計量は出力できる
df["petal length (cm)"].describe()

Seriesだけでも算出可能
value_counts
df["species"].value_counts()

カウントが可能
get_dummies
pd.get_dummies(df["species"]).ix[[0,1,2,50,51,52,100,101,102]]
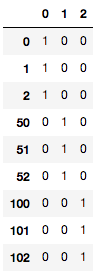
いわゆるダミー変数が作成可能
(見やすいように、インデックスを指定済み)
sort_values
df.sort_values("sepal length (cm)",ascending=False)
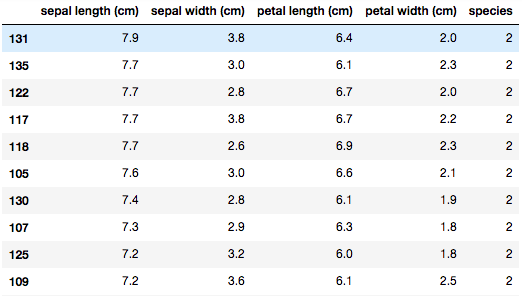
dfのソートが可能(ascendingで昇順降順を指定)
df.sort_values(["sepal length (cm)","sepal width (cm)"],ascending=False)
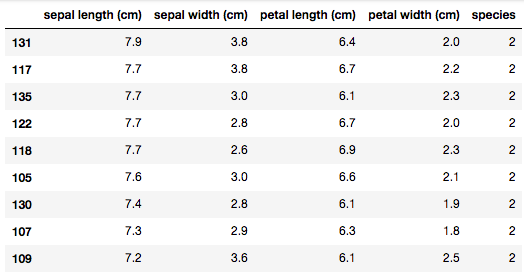
複数指定も可能(優先度は引数のlistのインデックス)
groupby
df_groupby = df.groupby("species",as_index=False)
df_groupby.mean()
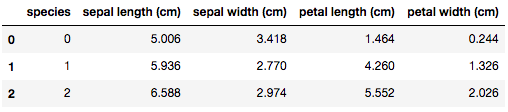
groupbyオブジェクトを再利用できるため、同じような集計を複数かけたいときはgroupbyオブジェクトを変数に格納したほうが早い
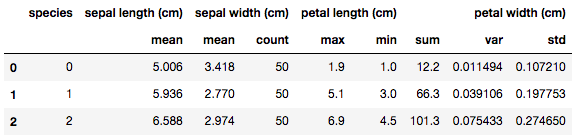
groupby.agg
df_groupby.agg({"sepal length (cm)": "mean",
"sepal width (cm)": ["mean","count"],
"petal length (cm)": ["max","min"],
"petal width (cm)": ["sum","var","std"]})
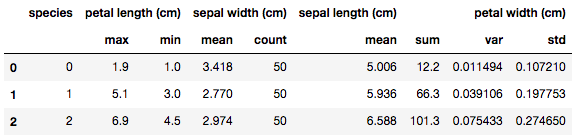
辞書形式で指定することで、カラムごとの個別集計が可能(ただし、一つのカラムに複数の集計を指定した場合、マルチカラムになるため、注意が必要)
また、こちらは順不同になるため、順序を指定したい場合はOrderedDictを利用する
df_groupby.agg(OrderedDict((["sepal length (cm)", "mean"],
["sepal width (cm)", ["mean","count"]],
["petal length (cm)", ["max","min"]],
["petal width (cm)", ["sum","var","std"]])))
to_csv
df.to_csv("test.csv",index=False,encoding="utf8")
pd.read_csv("test.csv")
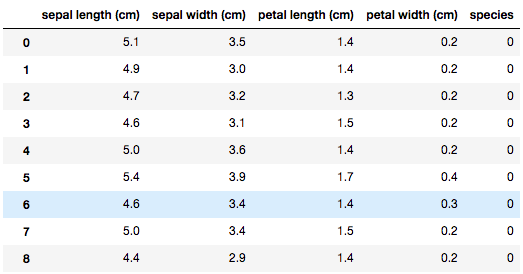
index=Falseにすると、次の読み込みが楽
encodingを指定しないと読み込めない時がある(とくにWindows)
可視化
前準備
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inlineはJupyter内に可視化するためのマジックコマンド
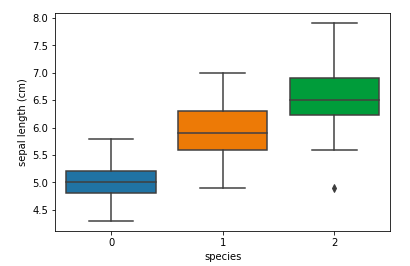
箱ひげ図
sns.boxplot(data=df, x="species", y="sepal length (cm)")
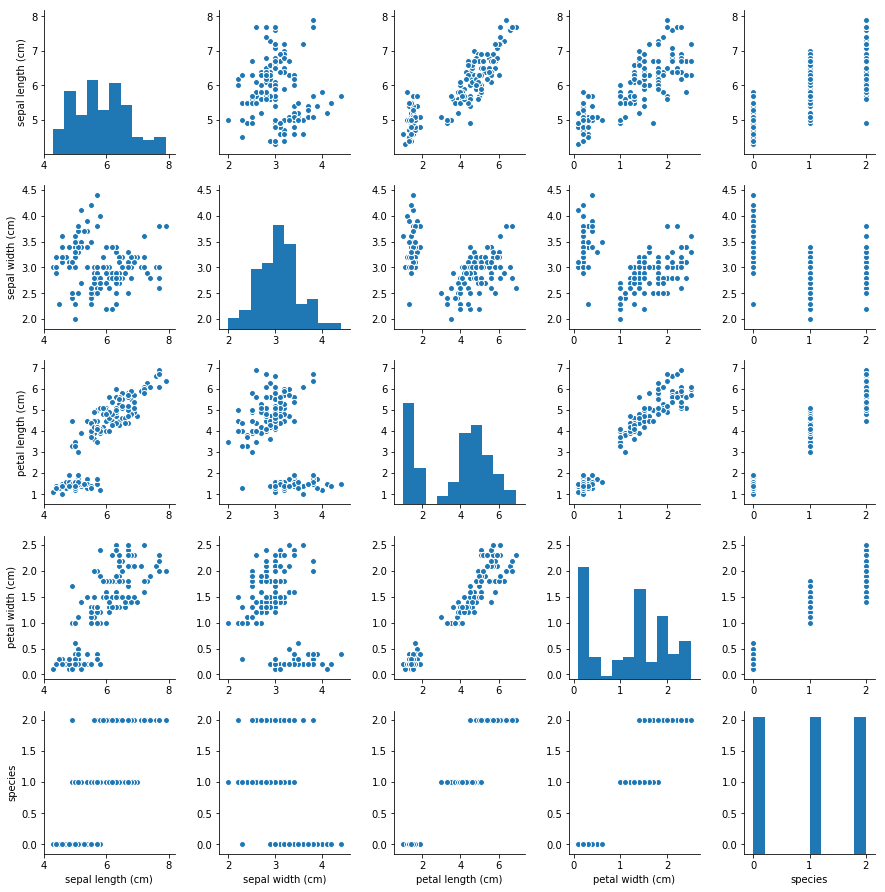
pairplot
sns.pairplot(data=df)
sns.pairplot(data=df, hue="species")
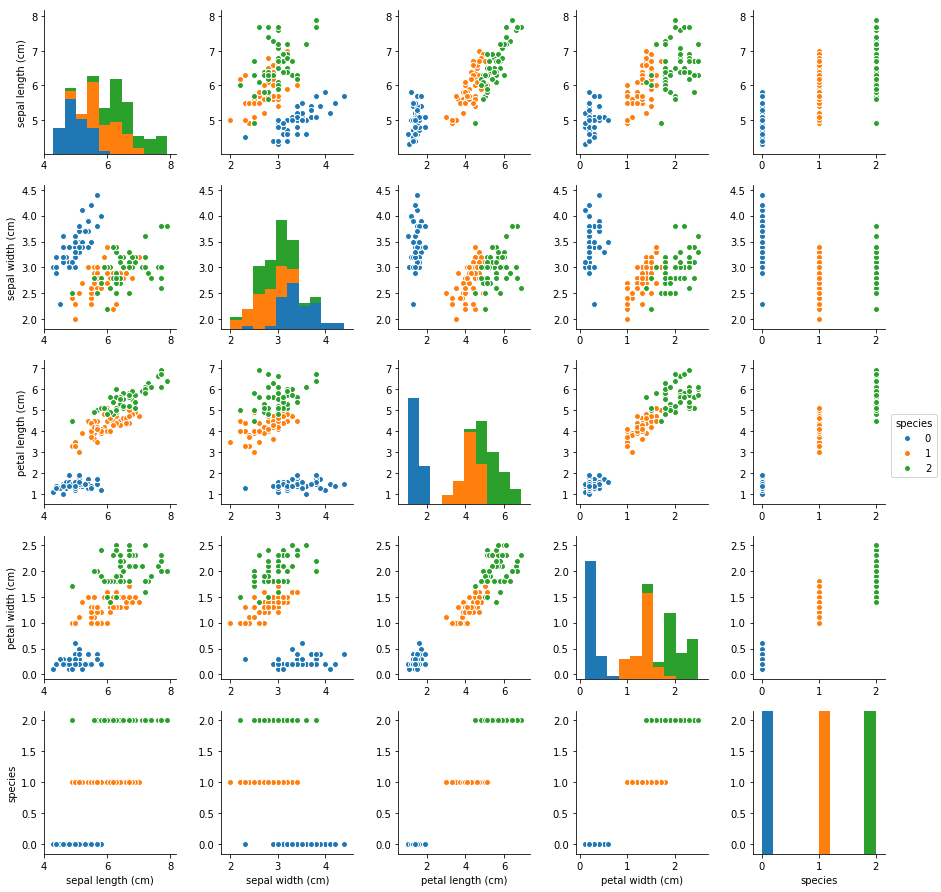
セグメント別に分けることもできる
jointplot
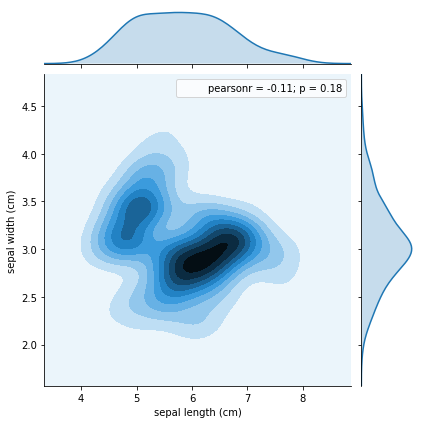
sns.jointplot(data=df, x="sepal length (cm)", y="sepal width (cm)", kind="kde")
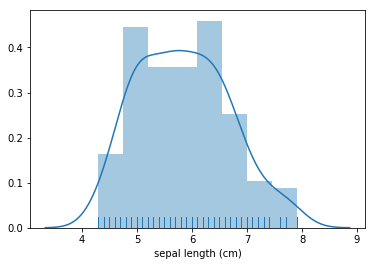
distplot
sns.distplot(df["sepal length (cm)"], rug=True,)