この記事はIDL(Interactive Data Language)とGDL(GNU Data Language)というプログラミング言語を紹介して簡単に使い方を説明します。
なお、読者が他のプログラミング言語を勉強したという前提で書いているので、ここでプログラミングの基本を触れません。
IDLとは
IDLは多分あまり誰も知らないマイナー言語だと思います。qiitaでもIDLの記事は殆ど見かけません。ただし特定の業界ではまだ活躍しているので、知り甲斐知っておいて損はないかもしれません。
インタフェース記述言語(Interface Description Language)も同じく「IDL」と略されますが、これはプログラミング言語ではない、全く別のものであり、混同してはなりません。
qiitaでも「IDL」で検索したらこの2つは混在しているという状態になって困っていますね。
IDLは1977年から生まれてかなり古い歴史を持っています。配列の計算を簡単にできるのは特徴で、それに加えてグラフィックの機能も持っています。
配列の計算はPythonのnumpyやMATLABと似ていますが、IDLはずっと先に生まれて(大体C言語のすぐ後)、あの時代にとってこれは優秀とも言えるでしょう。
古い時代の言語にしては、新時代の言語と似ているところが多い。しかも最初から科学研究を主として作られたので、特に外部ライブラリーをインストールする必要もなく元から必要な関数は充実している。
残念なのは、IDLが有料で使うのにライセンスが必要なので誰も使えるわけではない。これはIDLが人気出ない一番の理由でしょう。
現在は天文業界でまだIDLを使う場面が多少ありますが、どんどんPythonに乗り換えられつつあるから衰退して忘れ去られていくでしょう。
それは仕方ないことですね。有料の上にどの機能もPythonができるから。例えば配列の計算はnumpyで、グラフィックの機能はmatplotlib。更にPythonを使うとpandasやopencvなど便利なモジュールと簡単に連携できますし。
それでも古くから存在しているコードはIDLで書いたものが多いので、少なくとも解読できる程度のIDLの知識が役に立つのです。
私もIDLコードをPythonに書き換えるという作業をしていたので、その段階で習得したのです。
GDLとは
GDL(GNU Data Language)は簡単にいうとIDLの無料版です。IDLが有料なので使うにはライセンスが必要で不便ですが、実はお金を払いたくないなら代わりにGDLを使えばいいという話になります。
GDLを使う時は「IDLを使っている」と認識してもいい。違うのは「GDLはIDLの古いバージョンの機能しか持っていない」ということです。そのせいで新しく追加された関数などは使えません。
ただし一部の新しい関数は実はコードがサイトで公開されているので、自分でダウンロードして追加ライブラリーとして使うことができるから、ちょっと工夫が必要であるものの何とかできる場合が多いです。
この記事で以下説明する内容も全部GDLで実行する結果を使うので、これを読んで興味を持って自分で実行したいならインストールしてすぐできます。
紹介する入門の内容も勿論IDLでもGDLでも同じようにできることなので、違いを認識する必要はありません。
インストールと実行
IDLは有料なので、ここでIDLのインストールに関して触れませんが、GDLのインストール方法は意外と簡単だから誰でもすぐ使用できます。
このリンクからインストール用のファイルをダウンロードして実行したら完了。(Windowsでは.exe、Macでは.dmgファイル)
https://github.com/gnudatalanguage/gdl/releases
PATHを設定して「gdl」を実行したらgdlの対話式シェルでGDLを実行できます。
基本文法
はじめに
まずは定番の挨拶の言葉から
print, 'hallo welt!'
$で始めたらgdlのシェル内からコマンドラインを実行することができます。
例えばこう書いたらpythonを実行することもできます。
$python xxx.py
関数とプロシージャ
IDLでは2つ似ているものがあります。
- 関数(function)
- プロシージャ(procudure)
どれも他の言語の関数に似ていますが、使い方は違います。
例えばprintみたいなのは関数ではなくプロシージャで、使い方はこう:
プロシージャ名, 引数1, 引数2, ...
引数と同等に並んでいるように見えてちょっとわかりにくい気もしますね。
関数の場合、殆どの言語と同様な使い方:
関数名(引数1, 引数2, ...)
似ているようにものが2つあって混同しやすくてややこしいのですが、使い分けを認識する必要があります。
数学の計算などは全部関数なので直感的です。
cos(3.142)
-0.99999994
プロシージャと違って関数は返り値を持つし、重ねたり並べたり複雑に書くこともできます。
プロシージャも関数も、引数の他にキーワードも加えることができる。例えばprintはformatというキーワードで表示する書式を指定できます。
print, 1.2, format='(f11.6)'
1.200000
コメントアウト
IDLのコメントアウトは;を使います。
print, 'koko wa shutsuryoku sareru' ; kono ato wa imi nai
ただし数行のコメントアウトの方法はありません。
変数
変数は宣言する必要なく、すぐ代入して使えます。使える文字はラテン文字のa-zと数字と_。ただし大文字と小文字の区別がありません。数字で始まることはできません。
例:
_aa1 = 10
print, _AA1
結果
10
変数のデータ型は代入の時に自動的に決まります。
IDLの変数名に使えない予約語:
and begin break case common compile_opt continue do else end endcase endelse endfor endforeach endif endrep endswitch endwhile eq for foreach forward_function function ge goto gt if inherits le lt mod ne not of on_ioerror or pro repeat switch then until while xor
データ型を調べる方法
helpプロシージャを使えば変数のデータ型はわかります。
aa = 1
bb = 1.
help, aa
help, bb
help, '1'
AA INT = 1
BB FLOAT = 1.00000
<Expression> STRING = '1'
ここで変数ではない場合<Expression>となります。
数字のデータ型
古い時代の言語と同様にIDLデータ型は基本的に単なる「整数」(int)と「浮動小数点数」(float)ではなく、細かく分けられます。
整数の種類は以下
| データ型 | 範囲 | 例 |
|---|---|---|
| BYTE | 0 ~ 255 | 4B |
| INT | –32,768 ~ 32,767 | 4 |
| UINT | 0 ~ 65535 | 4L |
| LONG | –2,147,483,648 ~ 2,147,483,647 | 4L |
| ULONG | 0 ~ 4,294,967,295 | 4UL |
| LONG64 | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 | 4LL |
| ULONG64 | 0 ~ 18,446,744,073,709,551,615 | 4ULL |
単に数字を書いたら自動的にINT型になりますが、その他にしたい場合B、L、ULなどを付けるのです。それともデータ型の名前と同じ関数を使うことで作ることもできます。
help, 101LL
help, ulong(102)
<Expression> LONG64 = 101
<Expression> ULONG = 102
浮動小数点数は2種類あります。
| データ型 | 範囲 | 例 |
|---|---|---|
| FLOAT | ±1038 | 4. |
| DOUBLE | ±10308 | 4.D |
その他に複素数もあります。
| データ型 | 要素 | 例 |
|---|---|---|
| COMPLEX | (FLOAT, FLOAT) | complex(4,5) |
| DCOMPLEX | (DOUBLE, DOUBLE) | dcomplex(4,5) |
使う例:
sqrt(complex(-2,0))
( 0.0000000, 1.4142135)
データ型の変換
基本的にデータ型と同じ名前の関数を使えば簡単にデータ型を変えられます。ただしINTの場合intではなくfixを使うので注意。
help, float(20)
help, fix('50')
help, string(10000)
<Expression> FLOAT = 20.0000
<Expression> INT = 50
<Expression> STRING = ' 10000'
fix関数はキーワードtypeを付けることでどの型のデータにも変換できます。(付けない場合はINT)
ただし書くのはそのデータ型の番号。各データ型の番号は:
| データ型 | 番号 |
|---|---|
| UNDEFINED | 0 |
| BYTE | 1 |
| INT | 2 |
| LONG | 3 |
| FLOAT | 4 |
| DOUBLE | 5 |
| COMPLEX | 6 |
| STRING | 7 |
| STRUCT | 8 |
| DCOMPLEX | 9 |
| POINTER | 10 |
| OBJREF | 11 |
| UINT | 12 |
| ULONG | 13 |
| LONG64 | 14 |
| ULONG64 | 15 |
例:
x = 1.1
help, fix(x, type=7)
<Expression> STRING = ' 1.10000'
数学の計算
基本的な計算は他の言語と似ています。
| 表記 | 意味 | 例 |
|---|---|---|
| + | たし算 | 1+2 |
| - | ひき算 | 2-1 |
| * | かけ算 | 2*3 |
| / | わり算 | 4/2 |
| ^ | 累乗 | 3^2 |
| mod | 合同式 | 4 mod 3 |
ただし注意するべきはわり算の場合データ型は自動的に整数から小数へ変わりません。
a = 3/2
b = 3/2.
help, a
help, b
A INT = 1
B FLOAT = 1.50000
C言語やJavaScriptみたいに+=と++という書き方も使えます。
a = 2
a += 5
a++
print, a
8
数学関連の関数
よく使う数学関数は大体揃っています。
| 関数 | 意味 |
|---|---|
| abs(x) | 絶対値 |
| floor(x) | x以下の最大整数 |
| ceil(x) | x以上の最小整数 |
| round(x) | xに一番近い整数 |
| sqrt(x) | 平方根 |
| exp(x) | 指数関数 |
| alog(x) | 自然対数 |
| alog2(x) | 底2の対数 |
| alog10(x) | 常用対数 |
| sin(x) cos(x) tan(x) |
三角関数 |
| asin(x) acos(x) atan(x[, y]) |
逆三角関数 |
| sinh(x) cosh(x) tanh(x) |
双曲線関数 |
atanは引数を2つ入れることでatan2みたいな使い方になれます。
論理演算子
面倒なことに、IDLの論理演算子他の言語みたいな==、!=、>、<ではなく、全部ラテン文字で書きます。これは気をつけなければ起こしやすいミスです。
| 演算子 | 意味 | 他の言語 |
|---|---|---|
| eq | 等しい | == |
| ne | 異なる | != |
| le | 等しいかより小さい | <= |
| lt | より小さい | < |
| ge | 等しいかより大きい | >= |
| gt | より大きい | > |
真偽の結果はBYTEというデータ型になって、偽なら0か真なら1という値になります。trueとfalseに表示されることはないのでわかりにくいかもしれません。
help, 1 gt 1
help, 1 eq 1
<Expression> BYTE = 0
<Expression> BYTE = 1
andとorはPythonなどと同じ。
help, (1 eq 1) and (1 gt 1)
help, (1 eq 1) or (1 gt 1)
<Expression> BYTE = 0
<Expression> BYTE = 1
真偽を逆にしたい場合は~を使います。
~(1 lt 2)
~(1 gt 2)
0
1
システム定数
IDLの中で色々よく使う定数が準備されていのですぐ使えます。その定数はどれも!から始めるものです。定数なので勝手に書き換えることはできません。
例えば:
| 変数 | 意味 | データ型 |
|---|---|---|
| !pi | FLOAT型の円周率 | FLOAT |
| !dpi | DOUBLE型の円周率 | DOUBLE |
| !dtor | ラジアン/度 = 0.0174533 | FLOAT |
| !true | 1 | BYTE |
| !false | 0 | BYTE |
| !null | 何もない | UNDEFINED |
| !values.f_nan | FLOAT型のNaN | FLOAT |
| !values.d_nan | DOUBLE型のNaN | DOUBLE |
| !values.f_infinity | FLOAT型の無限大 | FLOAT |
| !values.d_infinity | DOUBLE型の無限大 | DOUBLE |
!trueと!falseはただ数字の0と1ですが、可読性のために使うこともあります。
NaN(Not a Number)はマイナスの数字の平方根を探す時などに現れる値です。
無限大(infinity)はFLOATが0でわる時などに現れる値です。(ただしINTの場合はエラー)
また、!pathなどパス変数も!だが定数ではなく、書き換えられる変数です。
文字列
文字列は' 'か" "で囲むことで作れます。それともstring関数で数字などから作ることもできます。ただしこのまま使うと空白がたくさん付いてくることになります。例えばINTでは長さ8、FLOATは長さ13の文字列となります。
help, string(10)
help, string(10.1)
<Expression> STRING = ' 10'
<Expression> STRING = ' 10.1000'
そうならないようにformatキーワードに書式を入れることができます。(printの時と同様)
help, string(10, format='(i2)')
help, string(10.1, format='(f5.2)')
<Expression> STRING = '10'
<Expression> STRING = '10.10'
ここでの書式はFortranと同じものなので説明は割愛しますが、Fortran関連の記事を参考に:
文字列は+を使うことで連結できます。
s = 'raamen'
print, 'miso'+s
s += 'ya'
print, s
misoraamen
raamenya
IDLでは文字列に使う便利関数がたくさんあります。例えば:
| 関数 | 機能 |
|---|---|
| strlen(s) | 文字列の長さ |
| strpos(s1, s2) | 文字列s1の中での文字列s2の位置を探す |
| strmid(s, i, n) | i-1番目の文字からn字取る |
| strtrim(s) | 前後にある空白を消す |
| strcompress(s) | 全ての空白を消す |
| strcmp(s1, s2) | 2つの文字列を比較する |
| strmatch(s, p) | 文字列sから指定のパターンpを探す |
| strupcase(s) | 大文字に変換する |
| strlowcase(s) | 小文字に変換する |
C言語などみたいに[ ]で文字列の中の文字を取ることはできない。その代わりにstrmidが使われます
s = 'yakisoba'
print, strmid(s, 4, 1)
print, strmid(s, 1, 3)
s
aki
ソースファイルの実行(=プロシージャの使い方)
IDLは基本的に対話式シェルで実行するので、コマンドラインからコードファイルを実行することはできません。その代わりに対話式シェルの中でファイルの名前を打てばプロシージャとして実行することになります。
プロシージャの作り方
IDLソースファイルの拡張子は.proです。これもprocedureの略。
プロシージャのファイルの書き方:
pro ファイル名
実行する内容
end
例えばこういうファイルを保存します。
pro tesuto
print, 'kono procedure wa imi nai'
end
そして対話式シェルでそのファイルの名前で呼び出す。
tesuto
kono procedure wa imi nai
引数がある場合はこう書きます。
pro ファイル名, 引数1, 引数2, ...
実行する内容
end
例:
pro tesuto2, aaa, bbb
print, aaa+bbb
end
実行
tesuto2, 3, 4
7
引数とキーワードの使い分け
以上の引数は書いた順番で値の代入を決める引数であり、「位置引数」と呼びます。その他にも名前付き引数、つまり「キーワード」というものも使えます。その場合こう書きます
pro ファイル名, キーワード1=キーワード1, キーワード2=キーワード2, ...
実行する内容
end
例:
pro tesuto3, a=a, b=b
print, a*b
end
実行
tesuto3, a=4, b=5
20
位置引数とキーワードは一緒に使うことができます。先に位置引数を書いて、その後はキーワード。
pro ファイル名, 位置引数1, ..., キーワード1=キーワード1, ...
実行する内容
end
引数とキーワードの省略
引数もキーワードもどれも省略してもいいですが、その場合keyword_setという関数でその引数やキーワードの値が入力されたかチェックすることが多い。返り値は0(偽)と1(真)。
例えばこんなプロシージャ
pro tesuto4, a
print, keyword_set(a)
end
キーワードが渡された場合
tesuto4, 1
1
キーワードが渡されなかった場合:
tesuto4
0
こんな風に条件分岐と一緒に使うことで引数かキーワードが渡された場合とない場合を使い分けできます。
変数に値を与えるプロシージャ
プロシージャに渡される引数かキーワードはそのプロシージャに値を与える役目の他に、逆にプロシージャの中から値をもらうという形になることもあります。
例えばこんなプロシージャ:
pro tesuto5, ggg
ggg = 'konnichiwa'
end
使う時に:
tesuto5, k
print, k
konnichiwa
つまりここで変数k(プロシージャ内でggg)はプロシージャに渡されたことで文字列をもらったのです。
この場合プロシージャに渡された変数は予め宣言する必要がなく、プロシージャが起動した時点で新しく定義されるのです。
こんな方法は特にPythonの使い手にとって見慣れないかもしれないが、IDLのプロシージャや関数でよく使われるので理解しておかないと悶々としてしまいそうですね。
勿論、既存の変数でもプロシージャ内へ渡されたことで値が変わることもあるので、これも注意。
pro nibai, x
x *= 2
end
使う時に。
x = 3
nibai, x
print, x
6
キーワードの前の「/」(スラッシュ)
これはIDL独特の書き方とも言えるので特に注目したいです。
例えばこんなプロシージャがあります。
pro tesuto6, h=h
print, 'h = ', h
end
このように実行したら
tesuto6, /h
こうなります。
h = 1
これはつまり/hはh=1と同じ意味です。
IDLの中でのプロシージャと関数は、特にキーワードの値が真偽として扱う場合は、こんな使い方をするものが多いので、理解しておく必要があります。
関数の作り方
関数はプロシージャと似ている方法で書けます。同じように.proのファイルに書くことで呼び出せます。
書き方:
function 関数名, 引数1, 引数2, ..., キーワード1=キーワード1, キーワード2=キーワード2, ...
実行したい内容
return 返り値
end
プロシージャとの違いはただproをfunctionに変えることと、returnを書いて返り値わ与えられること。
returnがなくても問題ないが、その場合返り値は0となります。
引数とキーワードの使い方もプロシージャと同じ。
例:
function menseki, hirosa, takasa
return hirosa*takasa
end
実行
menseki(6,7)
42
配列
配列がIDLの一番の長所とも言えるので詳しく説明します。
配列の基本
配列を作る一番基本的に方法は[ ]で囲むことです。
arr = [5,7,5]
中身の要素を使う時にインデックスを[ ]に入れて後ろに書く。ただしインデックスは0から数える。(CやPythonやRubyなどと同様。FortranやMATLABなどと違う)
arr = [2,8,11]
print, arr[0]
2
負の数を使って後ろから数えて指定することもできます。(最後の要素は-1)
arr = [3,5,7,9]
print, arr[-2]
7
:で範囲を指定して一部使うこともできます。
arr = [3,3,4,4,5,5]
print, arr[1:4]
3 4 4 5
注意:Pythonと違って、後ろの数字まで含まれます。先程の例ではPythonなら3 4 4になるはず。
そしてPythonみたいに[:3]、[2:]みたいな書き方はできず、[0:2]、[2:*]と書く必要があります。
ステップで要素を取る場合こう書くこともできます。
arr = [0,1,2,3,4,5]
print, arr[0:*:2]
0 2 4
(Pythonでの[::2]と同じ)
ただしPythonみたいにマイナス値を使うことはできない。[0:*:-1]はエラー。順番を逆にしたいならreverseという関数を使います。
配列をインデックスにして指定の順番の複数の要素を取ることもできます。
arr = [12,13,14,15,16]
print, arr[[1,3]]
13 15
配列の要素の書き換え
このように配列の中の要素を書き換えることもできます。
arr = [2,2,2,2,2,2]
arr[1] = 3
print, arr
arr[2:4] = 5
print, arr
2 3 2 2 2 2
2 3 5 5 5 2
[*]で全ての要素を同じ値にすることもできます
arr = [1,5,9,0]
arr[*] = 2
print, arr
2 2 2 2
二次元以上の配列
[ ]を重ねることで二次元以上の配列も作れます。書く時一行で書くよりも改行した方がいいかもしれないが、その場合最後に$を付ける必要があります。
例:
arr = [[1,0,1],$
[0,5,0],$
[1,0,1]]
print,arr
1 0 1
0 5 0
1 0 1
中身の要素を使う時に[列,行]のように書きます。順番はPythonと逆なので注意。
arr = [[0,1,2],$
[3,4,5],$
[6,7,8]]
print, arr[2,1]
5
ただし一つだけ数字を[ ]に入れる場合は全体から数える順番で要素を取ることになります。
print, arr[7]
7
欲しい列の全ての要素を取りたい場合は[列,*]と書く。
print, arr[2,*]
2
5
8
欲しい行の全ての要素を取りたい場合は[*,行]と書く。
print, arr[*,2]
6 7 8
配列の計算
配列の間の計算はその中の各要素の計算となります。
arr1 = [[1,1,1],$
[2,2,2]]
arr2 = [[2,2,2],$
[5,5,6]]
print,arr1+arr2
3 3 3
7 7 8
ただしサイズが違う場合、小さい方の配列だけの計算になって、そのサイズの配列が返ってくる。(この場合Pythonならエラーだが)
arr1 = [[1,2,3,4,5]]
arr2 = [[10,10]]
print, arr1+arr2
11 12
これは二次元の配列の場合も使えますが、次元と関係ない順番で計算してしまってなんかややこしくなるので、あまり使わない方がいいかも。
arr1 = [[1,2,3],$
[4,5,6]]
arr2 = [[3,3],$
[3,3]]
print, arr1-arr2
-2 -1
0 1
配列と普通の数字の計算もできます。
print, [1,2,3]+2
3 4 5
行列の乗法
二次元以上の配列は#演算子で行列みたいなかけ算ができます。これは普通各要素のかけ算に使う*と違うので注意。
例:
arr1 = [[1,2,3],$
[4,5,6]]
arr2 = [[1,2],$
[3,4],$
[5,6]]
print, arr1#arr2
9 12 15
19 26 33
29 40 51
それともmatrix_multiplyという関数でも同じような計算ができます。
print, matrix_multiply(arr1, arr2)
その他にもmatrix_power関数で正方行列の自分とのかけ算ができます。例えばmatrix_power(arr)はarr#arrと同じ。
配列のデータ型
配列の中身はどのデータ型でもいいが、一つの配列では全部同じデータ型となります。違うものを入れた場合は自動的に同じように変換されます。例えばINTとFLOATが混在したら全部FLOATとなります。
print, [1,2,3.]
1.00000 2.00000 3.00000
helpで中のデータ型を調べることができます。
help, [1,2,3]
<Expression> INT = Array[3]
データ型の変換は単体のデータと同じく、そのデータ型と同じ名前の関数で変換できます。
arr = [1.2,2.3,3.4,4]
arr = long(arr)
print, arr
help, arr
1 2 3 4
<Expression> LONG = Array[4]
配列のサイズを調べる方法
配列のサイズに関する情報はsize関数でできます。
arr = [[0,1,0,1],$
[1,0,1,0],$
[0,1,0,1]]
print, size(arr)
2 4 3 2 12
二次元の配列の場合は数字5つ出てきますが、意味は:
- 配列の次元
- 列の数
- 行の数
- データ型の番号
- 全部の要素の数
一次元の配列なら数字が4つになります。
各軸の数だけ調べたい場合/dimensionsキーワードを付けます。
print, size(arr, /dimensions)
4 3
全ての要素の数だけ調べたいならn_elements関数を使います。
print, n_elements([1,2,3,4])
4
配列を作る関数
[ ]で作る以外に、配列は色んな関数から作成できます。
例えば中身全部0の指定のサイズの配列を作る場合はこれらの関数を使います。
| データ型 | 関数 |
|---|---|
| BYTE | bytarr |
| INT | intarr |
| UINT | uintarr |
| LONG | lonarr |
| ULONG | ulonarr |
| LONG64 | lon64arr |
| ULONG64 | ulon64arr |
| FLOAT | fltarr |
| DOUBLE | DBLARR |
例えば:
print, fltarr(3,2)
0.00000 0.00000 0.00000
0.00000 0.00000 0.00000
値が並ぶ配列が欲しい場合これらの関数を使います。
| データ型 | 関数 |
|---|---|
| BYTE | bindgen |
| INT | indgen |
| UINT | uindgen |
| LONG | lindgen |
| ULONG | ulindgen |
| LONG64 | l64indgen |
| ULONG64 | ul64indgen |
| FLOAT | findgen |
| DOUBLE | dindgen |
例えば:
print, findgen(4,3)
0.00000 1.00000 2.00000 3.00000
4.00000 5.00000 6.00000 7.00000
8.00000 9.00000 10.0000 11.0000
値が並ぶINTの一次元の配列なら[ ]と:でこうやって作ることもできます。
arr1 = [2:6]
print, arr1
arr2 = [3:7:2]
print, arr2
2 3 4 5 6
3 5 7
ある値だらけの配列が欲しい場合replicateを使います。
print, replicate(1.5, 4, 3)
1.50000 1.50000 1.50000 1.50000
1.50000 1.50000 1.50000 1.50000
1.50000 1.50000 1.50000 1.50000
ランダム値で配列を生成することもできます。例えばrandomuは0~1の値を一様分布でランダムします
print, randomu(0, 4, 3)
0.0305810 0.213140 0.299003 0.381139
0.863488 0.133443 0.0734653 0.924736
0.642876 0.135658 0.614181 0.758658
ここでは1つ目の引数はseedの番号で、次からの引数はサイズ。
正規分布ランダム値が欲しい場合randomnを使います。
print, randomn(0, 5, 2)
-0.888299 -0.921606 1.38146 -1.41349 -0.383255
-0.432699 1.26306 1.17744 1.20992 1.76123
配列の再構成に使う関数
| 関数 | 意味 |
|---|---|
| reform | 指定の形に変形する |
| transpose | 転置行列 |
| reverse | 配列の順番を逆にする |
| rotate | 配列を回転する |
| shift | 配列の要素をシフトする |
| sort | 配列の要素の値の順番を返す |
sort関数はただ値の順番を返すだけで、本当に並べ替えるためにはその結果をインデックスに使う必要があります。それを逆にしたいならreverseとも使います。
arr = [4,2,0,6,3]
print, sort(arr)
print, arr[sort(arr)]
print, reverse(arr[sort(arr)])
2 1 4 0 3
0 2 3 4 6
6 4 3 2 0
統計関数
| 関数 | 意味 |
|---|---|
| min | 最小値 |
| max | 最大値 |
| total | 総計 |
| mean | 平均値 |
| median | 中央値 |
| stddev | 標準偏差 |
| variance | 分散 |
どれも二次元以上の配列に使う時にdimensionというキーワードで処理する軸だけの計算を指定することができます。
例:
arr = [[1,2,3],$
[4,5,6],$
[7,8,9]]
print, mean(arr, dimension=2)
4.00000 5.00000 6.00000
dimension=0か指定しない場合は全体を考慮することになって一つだけの数字を返します。
where関数
whereはIDLでよく使われて汎用性が高い関数です。
一番基本な使い方は、条件に合う要素のインデックスを取ること。これを使って指定の条件の要素だけ取ることができます。
arr = [1,8,11,3,14]
print, where(arr gt 7)
print, arr[where(arr gt 7)]
1 2 4
8 11 14
2番目の引数に変数を入れたらその変数はできたインデックスの数を持つ。
arr = [6,7,7,7,8]
print, where(arr eq 7, n_ok)
print, n_ok
1 2 3
3
complementキーワードに変数を入れたら残りの(つまりその変数が条件に反する)インデックスを持つ。
arr = [2,3,3,2,2,1]
print, where(arr eq 2, complement=com)
print, com
0 3 4
1 2 5
どの要素も条件に合わない場合は-1が返ってくる。ただし/nullキーワードを入れたら代わりに!NULLが返ってくる。
arr = [1,2,4]
print, where(arr gt 5)
print, where(arr gt 5, /null)
-1
!NULL
whereの結果をインデックスに使う場合/nullを使った方がいいかもしれません。-1だと最後の要素を取ることになるから、これは望まない結果になるかもしれない。!NULLをインデックスする場合取れる値も!NULLとなります。
arr = [2,3,-2,-3,4]
print, arr[where(arr eq 0)]
print, arr[where(arr eq 0, /null)]
4
!NULL
whereを使って特定の条件の要素だけ書き換えることができます。
arr = [1,2,3,4,5,6]
arr[where(arr gt 3)] = 3
print, arr
1 2 3 3 3 3
この方法は二次元以上の行列にも通用するから便利です。
arr = [[-2,1,-3],$
[3,4,-7],$
[-1,0,4]]
arr[where(arr lt 0)] = 0
print, arr
0 1 0
3 4 0
0 0 4
構造体
IDLはJavaScriptのオブジェクトみたいに構造体を作ることができます。
hito = {namae: 'tarou',$
nenrei: 25,$
shinchou: 166.6}
print, hito
{ tarou 25 166.600}
create_struct関数で作ることもできますが、ちょっとわかりにくいかも。
hito = create_struct('namae', 'tarou',$
'nenrei', 25,$
'shinchou', 166.6)
要素へのアクセスは.を付けるのです。普通の変数みたいに書き換えることもできます。
print, hito.namae
hito.namae = 'momotarou'
print, hito.namae
print, hito.nenrei
tarou
momotarou
25
ただしJavaScriptみたいに最初から存在しない要素は入れられません。
hito.taijuu = 60.
% Tag name: TAIJUU is undefined for STRUCT.
構造体にhelpを使うと中身の詳細まで読めます。
help, hito
** Structure <Anonymous>, 3 tags,memsize =40, data length=11/11:
NAMAE STRING 'tarou'
NENREI INT 25
SHINCHOU FLOAT 166.600
条件分岐
if else while forなど。
if else文
IDLのif文はこう書きます。
if 条件 then begin
条件を満たしたら実行する内容
endif
更にif else文はこう書きます。
if 条件1 then begin
条件1を満たしたら実行する内容
endif else if 条件2 then begin
条件2を満たしたら実行する内容
...
...
endif else if 条件n then begin
条件nを満たしたら実行する内容
endif else begin
どの条件も満たさない場合実行する内容
endelse
ちょっと冗長でわかりにくい気もします。
例:
if a gt b then begin
print, 'a wa ookii'
endif else if a lt b then begin
print, 'b wa ookii'
endif else begin
print, 'gobugobu'
endelse
ただし一行で書ける場合beginとendifとendelseは省略できます。
if 条件 then 真の場合の内容 else 偽の場合の内容
例:
if nedan gt 10000 then print, 'takai' else print, 'yasui'
case文
条件を分けるためにif elseの他にもcase文があります。
使い方:
case 変数 of
値1: begin
変数は値1なら実行したい内容
end
値2: begin
変数は値1なら実行したい内容
end
...
...
値n: begin
変数は値1なら実行したい内容
end
else: begin
変数はどの値でもないなら実行したい内容
end
endcase
ただし内容が1行で書ける場合、beginとendは省略できます。
case 変数 of
値1: 変数は値1なら実行したい内容
値2: 変数は値1なら実行したい内容
...
...
値n: 変数は値1なら実行したい内容
else: 変数はどの値でもないなら実行したい内容
endcase
while do文
ループをするためにwhile do文を使います。
書き方:
while 条件 do begin
実行したいないよう
endwhile
例:
i = 3
while i lt 10 do begin
print, i
i += 2
endwhile
3
5
7
9
ただし一行で書ける内容なら beginとendwhileは省略できます。
while 条件 do 実行したいないよう
例:
i = 5
while i lt 8 do print, i++
5
6
7
repeat until文
repeat until文はwhile doと似ていますが、条件は最後に書くのです。
repeat begin
実行したい内容
endrep until 止める条件
例:
i = 0
repeat begin
i -= 3
print, i
endrep until i lt -7
-3
-6
-9
for do文
for 変数=初期値, 最終値, 各ループで変わる値 do begin
実行する内容
endfor
各ループで変わる値が1である場合は省略できます。
例:
a = 0
for i=1, 4 do begin
a += i
print, a
endfor
1
3
6
10
一行で纏められる場合beginとendforは省略できます。
for 変数=初期値, 最終値, 各ループで変わる値 do 実行する内容
例:
for i=9, 4, -2 do print, i
9
7
5
foreach文
foreach文は配列の要素を一つずつ取ってループするのです。
書き方:
foreach 要素を取る変数, 配列 do begin
実行する内容
endforeach
一行の場合の省略。
foreach 要素を取る変数, 配列 do 実行する内容
例:
arr = [2,5,8]
s = 0
foreach x, arr do begin
s += x
print, 'x = ', x
endforeach
print, 's = ', s
x = 2
x = 5
x = 8
s = 15
break
ループの中で途中で脱出するためにbreakを使います。
例:
i = 2
while 1 do begin
i *= 2
print, i
if (i gt 9) then break
endwhile
4
8
16
continue
continueもbreakと同様な使い方だが、脱出ではなくすぐ次のループへスキップするために使うものです。
for i=1,4 do begin
if (i eq 3) then continue
print, i
endfor
1
2
4
goto文
一応古い言語なのでgoto文も存在するけど、現在あまりおすすめしないものなので、割愛します。
ファイルの読み書き
IDLではこれらのプロシージャでファイルを読み書きできます。
| 関数 | 役目 |
|---|---|
| openr | 既存ファイルを読むために開く |
| openw | 新しいファイルを書くために作る |
| openu | 既存ファイルを読み書きするために開く |
| readf | 開いているファイルを読んで変数に収める |
| printf | 開いているファイルに書く |
| close | 開いているファイルを閉じる |
例えば新しいファイルを作ってその中に何かを書く場合はこのようにします。
openw, 1, 'kaite.txt'
printf, 1, 'omae wa mou kaite iru'
close, 1
まずはopenwファイルを開いて、最後にcloseでファイル。ファイルを閉じなければ出力された文字はまだ反映されません。
ここで数字1は処理するファイルを示す任意の数字であり、全て関連するプロシージャで同じ数字を使います。同時に他のファイルを扱うなら他に数字を付けます。
読み込む時にopenrで開いてreadfで読みます。
s = ''
openr, 1, 'kaite.txt'
readf, 1, s
print, s
close, 1
omae wa mou kaite iru
ここでsは読み込んだ内容を受け取る変数です。ただし注意すべきは、予め変数を文字列型に宣言しておかないとFLOAT型になってしまうこと。つまり適当な文字列を代入すること。ここでは空の文字列''。
逆に言うと、もし読みたいものはFLOATなら予め変数を準備しなくてもいいし、勝手にFLOAT型になる。例えばこんなファイル:
129.3
読み込んでみる。
openr, 1, 'doraefloat.txt'
readf, 1, f
help, f
close, 1
F FLOAT = 129.300
readfは1行ずつ読むから全部読むのにwhile do文を使うことができます。例えばこんなファイル:
1.111
11.11
111.1
実行する。
openr, 1, 'hogefloat.txt'
while ~eof(1) do begin
readf, 1, f
print, f
endwhile
close, 1
1.11100
11.1100
111.100
ここでeofはそのファイルは終わったかどうかをチェックする関数です。
グラフィック機能
IDLはグラフィック機能も持ってグラフを描くことなど可視化することができます。3Dもできます。
例えばグラフを描きたい時こう使います。
x = findgen(1000)/50
y = cos(x)
plot, x, y
そしてこんなグラフができます。地味に見えますが、色々調整して綺麗にすることもできます。
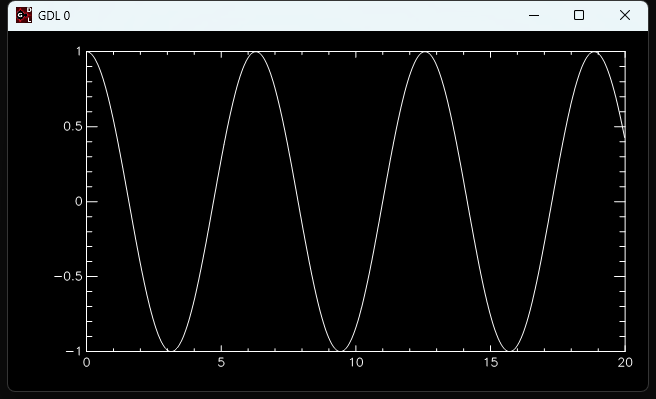
ただし無料のGDLではグラフィック機能が限られるから、この部分は本物のIDLを買わないと色々できません。
その他に詳しいことは割愛しますが、本当にもっと色々できます。
参考
日本語
他のqiitaの記事
英語
その他に、自分は買っていませんが、一応よくできた日本語の書籍もあります。
終わりに
以上はIDLとGDLというプログラミング言語の紹介と入門でした。実際に使う人はあまりいないかもしれませんが、プログラマーとして新たしい言語を知って視野を広げることになもなりますし。
これは自分が忘れないためのメモでもありますが、必要な誰かのために役に立てば幸いです。