この記事ではComfyUIの中でFLUX.1を使う方法について説明します。
はじめに
FLUX.1はBlack Forest Labsによって開発された先進的なテキストから画像を生成するAIモデルです。2024年8月に初めてリリースされました。
Stable Diffusionの元コアチームメンバーがFLUX.1の開発に参加しているので、使い方などはStable Diffusionとよく似ていますが、Stable Diffusionより超える高い視覚品質とテキスト理解能力を持っているので、注目を浴びています。
Stable Diffusionと同様に、モデルのファイルをダウンロードして自分のパソコンで思う存分に実行できるだけでなく、モデルを改善して派生モデルを作って再配布することもできます。shuttle 3 diffusionやFLUX.1 krea devなど派生モデルが公開されて、これをダウンロードして使用することで更にいい画像を生成することができます。
FLUX.1を使うと簡単に綺麗な画像を作れます。例えばこんな可愛い猫耳少女。

もっと詳しくは、既に説明している記事が沢山あるので割愛します。ここでは使い方だけ集中していきます。
FLUX.1を使う手段は色々ありますが、一番人気なのはComfyUIです。この記事もその使い方について説明していきます。
前提
この記事はComfyUIの入門ではないので、ComfyUIのインストールや基本な使い方も割愛します。
私は今回ComfyUI Desktopを使っていますが、portable版など他の方法でインストールしても同じように使えるはずです。
ComfyUIは特にパッケージをインストールしなくても基本的にFLUX.1を使うためのノードが整っているので、最新版のComfyUIになっていれば特に追加パッケージをインストールしなくてもすぐ使えます。
もう一つ重要なのは実行するための環境です。今回はAPIではなくローカルで実行するモデルの説明となります。Stable DiffusionよりFLUX.1の方は更にいいスペックが必要なので、SDXLを使っていたパソコンでもFLUX.1が使えないかもしれません。
推奨環境だと、メモリーは32GB以上で、GPUのVRAMは16GB以上だと言われています。
私の使っている環境ではメモリー48GBで、GPUは16GBのVRAMを持つRTX 5060 Tiなのでとりあえず問題なく使えます。ただしVRAMが足りなくて途中で止まることはしばしば起こります。
ただしGGUFという軽量化モデルを使うことでメモリーを節約できてそこまでいいスペックでなくてもギリギリ使えるようになります。その代わりに品質が多少落ちます。
GGUFを使う場合少しワークフローが違ってやや複雑になるので、使い方については後で説明します。
簡単な始め方
ComfyUIによるFLUX.1の使い方は色々あるので、これは混乱の原因でもあります。だからまず一番複雑さが低い方法から紹介したいと思います。
その一番簡単な方法とは、ComfyUIの中で既に準備してあるテンプレートを使うという方法です。
テンプレートを使うにはまず左上にある「ワークフロー」メニューをクリックします。
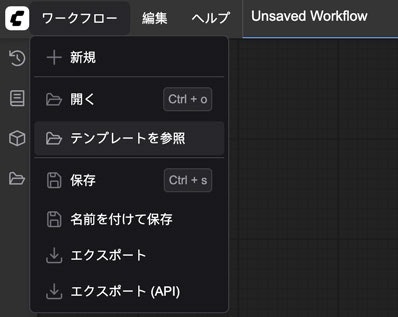
そしてFluxタブを選んだらFLUX.1の色んなテンプレートが選択できます。その中で「Flux Dev」と「Flux Schnell」に注目します。
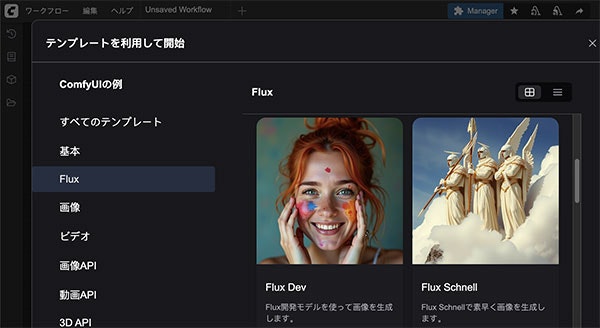
FLUX.1には、pro、dev、schnell版がありますが、モデルをダウンロードして自分のパソコンで実行できるのはdevとschnellのみです。違いに関しては簡単にいうとdevの方はschnellより品質が高いが、schnellの方はdevよりずっと高速で生成できるのです。又ライセンスに関してはschnellの方がdevより自由度高いです。
まずはschnellから紹介します。テンプレートの中で「Flux Schnell」を選んだら、もし初めての場合だと、flux1-schnell-fp8.safetensorsというチェックポイントモデルが必要だと表示されるでしょう。そこでダウンロードをクリックしてすぐダウンロードができて便利です。
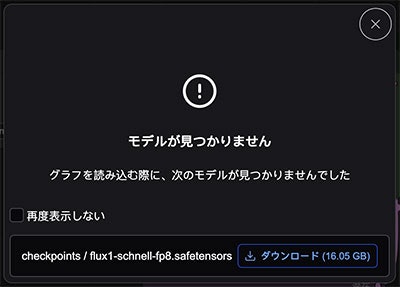
又は手動でダウンロードすることもできます。そしてComfyUI/models/checkpointsフォルダの中に起きます。こちらのリンクからです。
devの方はこちらです。
ワークフローはこのように表示されます。
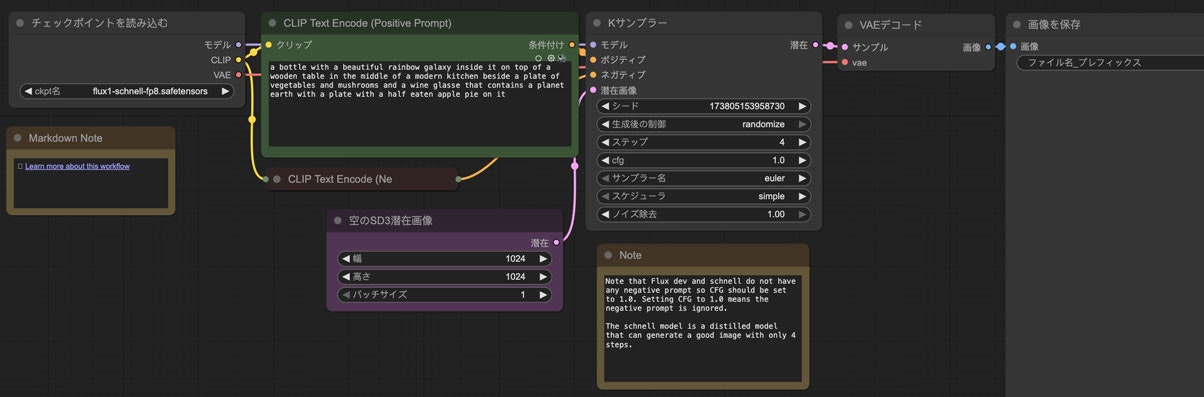
こう見えて本来のStable Diffusionとあまり変わらない形ですね。普段からStable Diffusionを使っている人はすぐ理解できるでしょう。
ただしStable Diffusionと違って、FLUX.1にはネガティブプロンプトが必要ないのです。
このテンプレートでもネガティブプロンプトのノードが縮小されていますね。ネガティブプロンプトを入力しても全然効果がないからです。ポジティブなことだけ書けばいいです。
又実はもっと簡単にすることができます。わざわざ空っぽなプロンプトのノードを作らなくても、ポジティブプロンプトをそのままネガティブに接続すればいいです。こうなります。
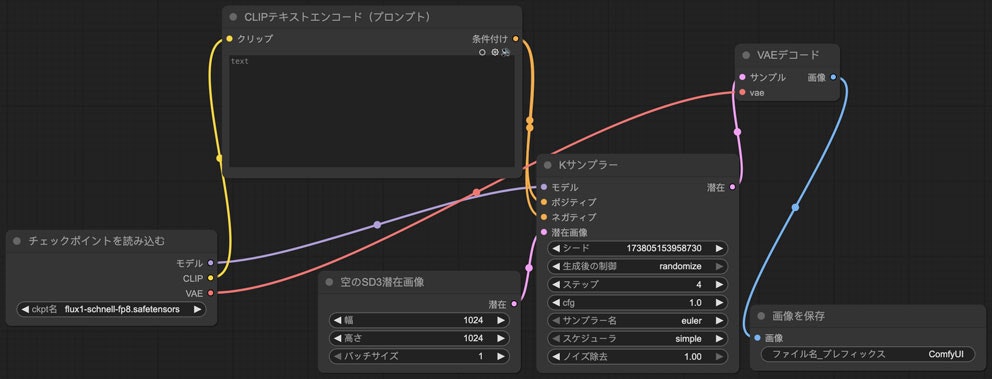
こう見えて違和感を持つかもしれませんが、本当に大丈夫です。こうやってノードが一つ減って、Stable Diffusionの時より簡単に見えますね。
パラメーターの設定に関しては大体Stable Diffusionと同じです。ただしcfgは1.0で固定して、ステップ数に関してはschnellでは4で、devでは20にするのは一般的です。schnellはたった4ステップで生成できるから凄い速いですね。
次は私個人がいつも使っているアレンジも紹介したいです。必ず必要だというわけではないが、私はいつもComfyUI_Custom_Nodes_AlekPetのDeepTranslatorCLIPTextEncodeNodeとcomfyui-saveimage-plusのSaveImagePlusノードを使っています。
DeepTranslatorCLIPTextEncodeNodeは日本語などでプロンプトを書けるために必要なノードです。以前の記事で紹介したことがあります。
SaveImagePlusはpngの代わりにjpgで保存するためのノードです。これも以前の記事で紹介しました。
これは去年から書いた記事なので、内容としてはちょっと古いところがありますが、このノードの使い方は今でもまだ変わっていません。
この2のノードで入れ替えたらこのようなワークフローになります。
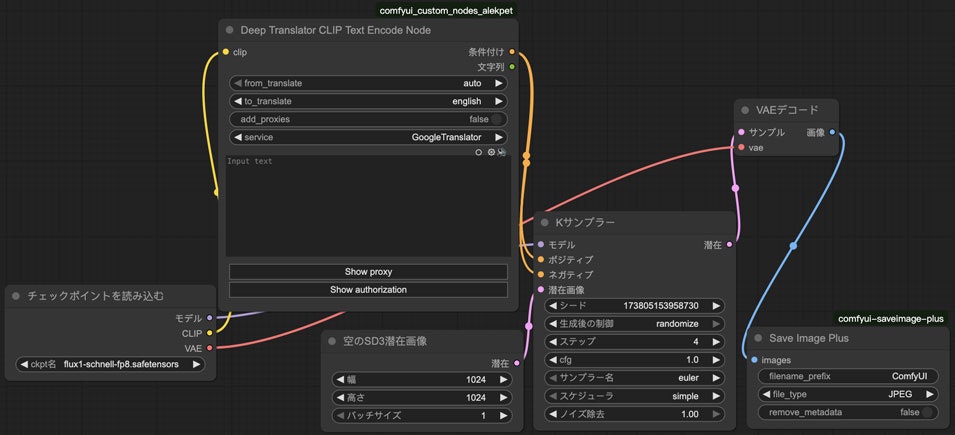
ではこれでワークフローの準備ができたので、早速実行してみたいと思います。試しに青い制服姿の紫色髪のツインテール猫耳少女がアンコールワットの中の桜の下でパンを食べているというプロンプトで実行してみます。
そうしたらこんな画像が生成されます。

何回も試してみましたが、髪型が違ったり、変な形のパンになったり、パンすらなかったり、食べ方がおかしかったりする例もありますが、猫耳や桜や制服やアンコールワットに関しては形のバリエーションが高いものの、どれもそれっぽいです。色に関してはほぼ忠実です。
かかる時間に関しては、私の環境では8秒くらいです。4ステップで済むのだから速いですね。ただし一回目の実行はモデルロードが必要なので、1分以上に時間かかります。その次は速いです。でもComfyUIを再起動したら又ロードする必要があるので、又一回目だけは時間がかかります。
以上のワークフローのAPI版jsonもここに載せておきます。これをコピーして使ってみてもいいです。
{
"1": {
"inputs": {
"ckpt_name": "flux1-schnell-fp8.safetensors"
},
"class_type": "CheckpointLoaderSimple"
},
"2": {
"inputs": {
"width": 1024,
"height": 1024,
"batch_size": 1
},
"class_type": "EmptySD3LatentImage"
},
"3": {
"inputs": {
"from_translate": "auto",
"to_translate": "english",
"add_proxies": false,
"service": "GoogleTranslator",
"text": "",
"clip": ["1", 1]
},
"class_type": "DeepTranslatorCLIPTextEncodeNode"
},
"4": {
"inputs": {
"seed": 123456789,
"steps": 4,
"cfg": 1,
"sampler_name": "euler",
"scheduler": "simple",
"denoise": 1,
"model": ["1", 0],
"positive": ["3", 0],
"negative": ["3", 0],
"latent_image": ["2", 0]
},
"class_type": "KSampler"
},
"5": {
"inputs": {
"samples": ["4", 0],
"vae": ["1", 2]
},
"class_type": "VAEDecode"
},
"6": {
"inputs": {
"filename_prefix": "comflux",
"file_type": "JPEG",
"remove_metadata": false,
"images": ["5", 0]
},
"class_type": "SaveImagePlus"
}
}
FLUX.1-devとガイダンスの話
次はdevについて紹介します。
基本的にschnellのワークフローからこの2つのところだけ変更したらdevが使えます。
- モデルを
flux1-schnell-fp8.safetensorsからflux1-dev-fp8.safetensorsにする - ステップ数を
4から20にする
ただしもしテンプレートからFlux Devをロードしてみたら違いはもう一つあるとわかります。試しにテンプレートをロードしてみましょう。
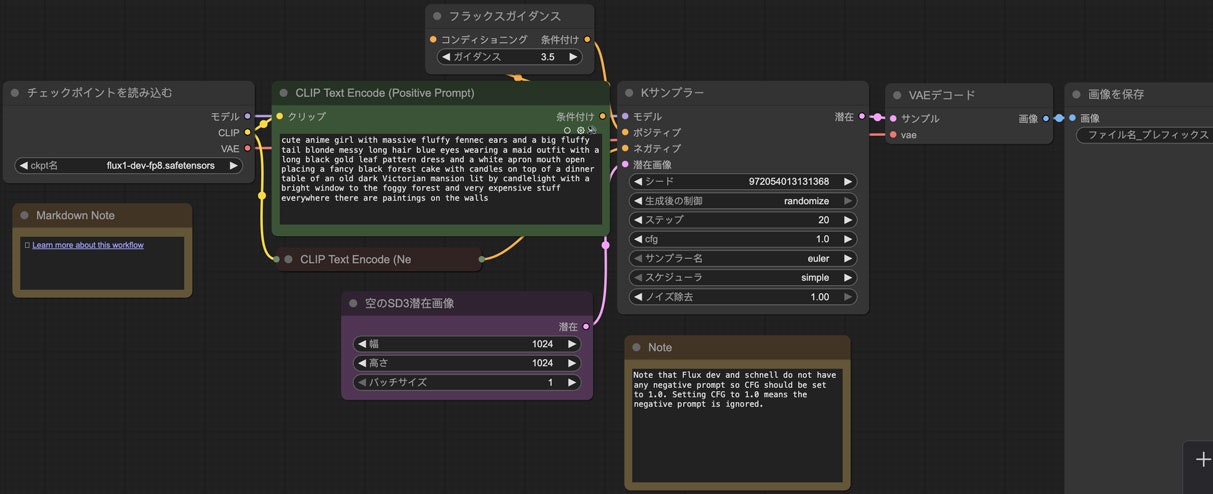
増えてきたのはFluxGuidance(フラックスガイダンス)というノードです。これに関しては後で説明します。
私なりにアレンジしたワークフローではこうなります。
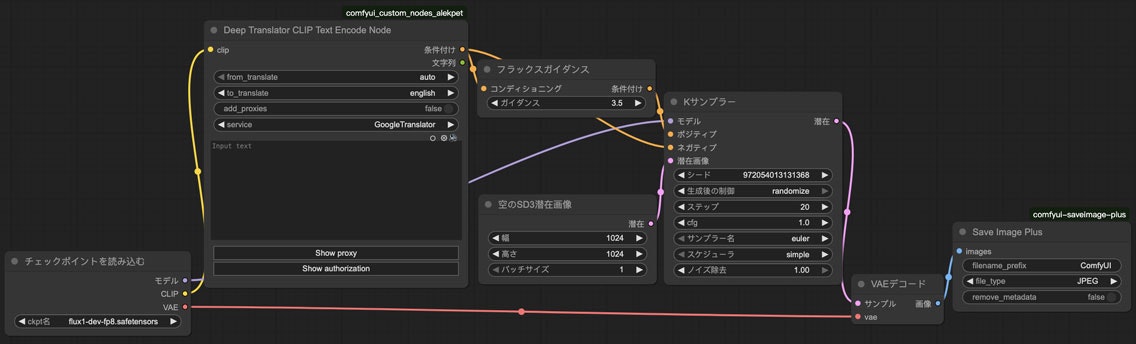
上のschnellの例と同じプロンプトで実行してみたらこんな絵ができます。

schnellよりよくできた感じです。何回も実行して比較してみましたが、devの方は結果がいい傾向にあるのは確かに明らかです。ステップは5倍になるから当然ですね。
schnellは8秒で終わりますが、devは40秒くらいかかります。
次はFluxGuidanceノードについて少し説明します。このノートの中のガイダンス値はStable Diffusionのcfgと似て、どれくらいプロンプトに忠実するかを決めるパラメーター……だという説明があります。ただし私は実際に試したところその違いは微妙で、効果はわかりにくいと感じます。
試しに違い値を比較してみました。
「赤い制服姿の水色ツインテール猫耳少女がアンコールワットの中の桜の下でピッツァを食べている」というプロンプトで試してみたところこんな結果でした。(右下にある数値はガイダンス値)

このようにガイダンス値によって確かに大きな差が見えますが、どう違うか説明は難しいですね。
この比較画像を作るのに使ったワークフローもここに載せておきます。
{
"1": {
"inputs": {
"ckpt_name": "flux1-dev-fp8.safetensors"
},
"class_type": "CheckpointLoaderSimple"
},
"2": {
"inputs": {
"width": 1024,
"height": 1024,
"batch_size": 1
},
"class_type": "EmptySD3LatentImage"
},
"3": {
"inputs": {
"start": 0,
"end": 55.000000000000014,
"step": 7.000000000000002,
"operation": "none",
"decimal_places": 1,
"ignore_first_value": false,
"max_values_per_loop": 128,
"loops": 1,
"ping_pong": false
},
"class_type": "CR Float Range List"
},
"4": {
"inputs": {
"from_translate": "auto",
"to_translate": "english",
"add_proxies": false,
"service": "GoogleTranslator",
"text": "赤い制服姿の水色ツインテール猫耳少女がアンコールワットの中の桜の下でピッツァを食べている",
"Show proxy": "proxy_hide",
"Show authorization": "authorization_hide",
"clip": ["1", 1]
},
"class_type": "DeepTranslatorCLIPTextEncodeNode"
},
"5": {
"inputs": {
"value": ["3", 0],
"format_string": "{:.1f}"
},
"class_type": "JWFloatToString"
},
"6": {
"inputs": {
"guidance": ["3", 0],
"conditioning": ["4", 0]
},
"class_type": "FluxGuidance"
},
"7": {
"inputs": {
"seed": 437,
"steps": 20,
"cfg": 1,
"sampler_name": "euler",
"scheduler": "simple",
"denoise": 1,
"model": ["1", 0],
"positive": ["6", 0],
"negative": ["4", 0],
"latent_image": ["2", 0]
},
"class_type": "KSampler"
},
"8": {
"inputs": {
"samples": ["7", 0],
"vae": ["1", 2]
},
"class_type": "VAEDecode"
},
"9": {
"inputs": {
"text": ["5", 0],
"font_size": 64,
"font": "arial",
"fill_color_hex": "#FFFFFF",
"stroke_color_hex": "#008800",
"stroke_thickness": 0.2,
"padding": 10,
"horizontal_alignment": "right",
"vertical_alignment": "bottom",
"x_shift": 0,
"y_shift": -10,
"line_spacing": 0,
"image": ["8", 0]
},
"class_type": "Text Overlay"
},
"10": {
"inputs": {
"images": ["9", 0]
},
"class_type": "ImageListToImageBatch"
},
"11": {
"inputs": {
"border_width": 3,
"number_of_columns": 3,
"max_cell_size": 512,
"border_red": 0,
"border_green": 0,
"border_blue": 0,
"images": ["10", 0]
},
"class_type": "Create Grid Image from Batch"
},
"12": {
"inputs": {
"filename_prefix": "ComfyUI",
"file_type": "JPEG",
"remove_metadata": false,
"images": ["11", 0]
},
"class_type": "SaveImagePlus"
}
}
このワークフローを実行するために追加で色んなノードのインストールが必要なので、リンクを記載しておきます。
ただしガイダンスのデフォルトは3.5なので、ガイダンス値を3.5にしたい場合はFluxGuidanceノードを省略してもいいです。
又このFluxGuidanceノードはschnellを使う時にも入れても大丈夫ですが、全く効果がありません。ガイダンスが使えるのはdevだけ。
モデルを分けるワークフロー
以上説明したのは一番わかりやすい使い方でしたが、実はここで使ったモデルはComfyUIで簡単に使うために一つのチェックポイントに纏められたものです。本来なら3種のモデルに分けられています。
- unet
- CLIP
- VAE
モデルごとにノードを分けたらワークフローはこうなります。
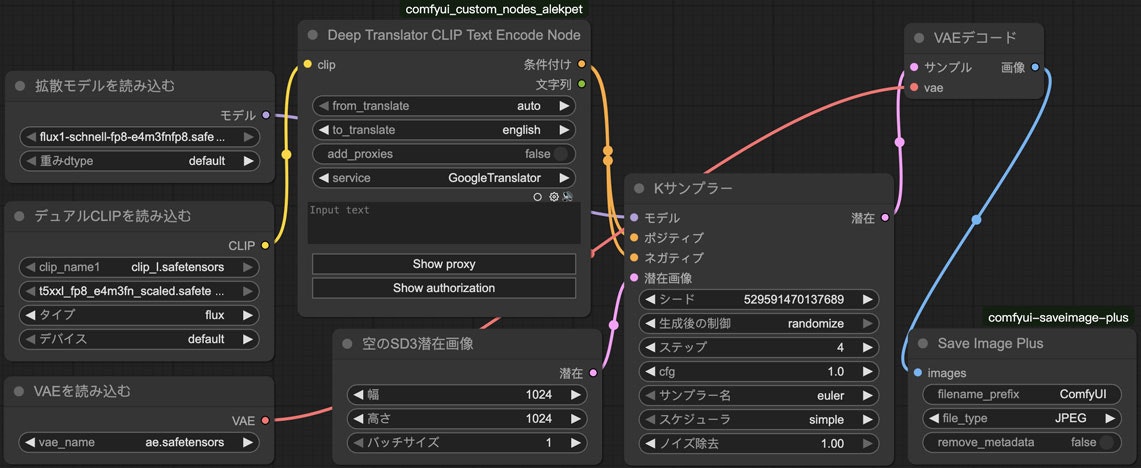
jsonで書くとこうなります。
{
"1": {
"inputs": {
"clip_name1": "clip_l.safetensors",
"clip_name2": "t5xxl_fp8_e4m3fn_scaled.safetensors",
"type": "flux",
"device": "default"
},
"class_type": "DualCLIPLoader"
},
"2": {
"inputs": {
"unet_name": "flux1-schnell-fp8-e4m3fn.safetensors",
"weight_dtype": "default"
},
"class_type": "UNETLoader"
},
"3": {
"inputs": {
"vae_name": "ae.safetensors"
},
"class_type": "VAELoader"
},
"4": {
"inputs": {
"width": 1024,
"height": 1024,
"batch_size": 1
},
"class_type": "EmptySD3LatentImage"
},
"5": {
"inputs": {
"from_translate": "auto",
"to_translate": "english",
"add_proxies": false,
"service": "GoogleTranslator",
"text": "",
"Show proxy": "proxy_hide",
"Show authorization": "authorization_hide",
"clip": ["1", 0]
},
"class_type": "DeepTranslatorCLIPTextEncodeNode"
},
"6": {
"inputs": {
"seed": 529591470137689,
"steps": 4,
"cfg": 1,
"sampler_name": "euler",
"scheduler": "simple",
"denoise": 1,
"model": ["2", 0],
"positive": ["5", 0],
"negative": ["5", 0],
"latent_image": ["4", 0]
},
"class_type": "KSampler"
},
"7": {
"inputs": {
"samples": ["6", 0],
"vae": ["3", 0]
},
"class_type": "VAEDecode"
},
"8": {
"inputs": {
"filename_prefix": "ComfyUI",
"file_type": "JPEG",
"remove_metadata": false,
"images": ["7", 0]
},
"class_type": "SaveImagePlus"
}
}
まずUNETLoader(拡散モデルを読み込む)というノード。これはunetモデルをロードするノードです。
unetモデルはBlack Forest Labsによって公開されたモデルを使うのは基本です。
ただしこれはfp16なので、軽量化モデルもおすすめです。ここではKijaiによるfp8版を使いたいと思います。
fp8は重みパラメーターのビット数を下げて縮小された軽量化モデルです。モデルファイルのサイズも、消耗するメモリーもfp8の方が小さいが、両方試して比較してみたところ大きな違いが見えないので、fp8があればfp8を使っていいと思います。
このモデルをダウンロードしてComfyUI/models/unet又はComfyUI/models/diffusion_modelsフォルダに入れます。
チェックポイントモデルとは名前は同じで混同しやすいが、これはunetモデル(拡散モデル)です。
置く場所も違うので、ワークフローの中ではちゃんと使い分けされています。
仮に間違ってunetモデルをチェックポイントとして使おうとしてもエラーになります。
次はDualCLIPLoader(デュアルCLIPを読み込む)ノードです。
CLIPはFLUX.1の場合2つ同時に使う必要があります。どれもここでダウンロードできます。これはSD3などに使うのと同じモデルです。
まず1つ目はclip_l.safetensorsですが、もう一つは3つ選択肢があります。
t5xxl_fp8_e4m3fn.safetensorsとt5xxl_fp8_e4m3fn_scaled.safetensorsはどっちもfp8でメモリー消耗も同じですが、t5xxl_fp8_e4m3fn_scaled.safetensorsの方がt5xxl_fp8_e4m3fn.safetensorsの改善版なので、基本的にこれを使うことにします。
このモデルをダウンロードしてComfyUI/models/clip又はComfyUI/models/text_encodersフォルダに入れます。
最後はVAELoader(VAEを読み込む)ノードです。VAEは専らこれを使います。
VAEモデルはComfyUI/models/vaeフォルダに置きます。
このようにノードを分けると、それぞれのモデルを個別でダウンロードしなければならなくて、面倒くさくなりますね。
だったら纏めた一つのチェックポイントモデルを使えばいいのではないか?……と思ってしまいますよね。
しかし実際にこのような纏めたモデルが使える場合は限られています。
FLUX.1もStable Diffusionと同様に、モデルを改造して再配布することができて、huggingfaceやcivitaiなどで公開している派生モデルがありますが、そのモデルは主にチェックポイントではなく、unetだけなので、このようなワークフローが必要です。
派生モデルを使う
shuttle 3 diffusion
ここでshuttle 3 diffusionというモデルを紹介したいです。このモデルFLUX.1 schnellを元にして改善したもので、4ステップで生成できますが、その割にはFLUX.1 devに匹敵するほどいい品質です。
モデルはここにダウンロードできます
このモデルをComfyUI/models/unet又はComfyUI/models/diffusion_modelsに置いて、schnellモデルの代わりに入れ替えたらすぐ使えます。
これは上の例のschnellとdevと同じプロンプトで試した生成結果です。

更にわかりやすいようにschnellとshuttle 3 diffusionとdevの結果も並べて比較してみます。

左からはschnell、shuttle 3 diffusion、devの順。どれも同じseedです。プロンプトは以下の4つ。
アニメ、紫色のチャイナ服を着ている緑色ツインテール猫耳少女がアンコールワットの中の桜の下でバイオリンを弾いている
アニメ、桃色市松の制服を着ている赤いツインテール猫耳少女は雪の降っている夜のワットプラケオの中のヤシの下で踊っている
アニメ、白い和服姿の金髪ツインテール猫耳少女は雨の降っているシュエダゴンパゴダの前の松の下でゴルフをやっている
アニメ、花模様の緑色メイド服を着ている桃色ツインテール猫耳少女は秋の万里長城の銀杏の下で微笑みながら大きなアイスクリームを舐めている
結果を見るとshuttle 3 diffusionはschnellより優れるのは明らかですね。devと比べたらスタイルは違う気がして比較しにくいのですが、shuttle 3 diffusionの方が詳細まで描かれるように見えます。devはなぜか背景はあまりはっきり見えないことが多いです。
他にもダウンロードして使えるモデルがあります。まだStable Diffusionほどいっぱいあるわけではないが、今後増えていくでしょう。
FLUX.1 krea dev
もう一つ紹介したいモデルはFLUX.1 krea devです。このモデルはFLUX.1 devと入れ替える形で使えます。元のFLUX.1 devよりも現実に近い画像を生成することが得意と言われていますが、実はアニメ画像を生成してみたところかなり綺麗にできます。
本家のfp16版はここにダウンロードできます。
又はfp8軽量化版を使うこともできます。私もこれを使っています。
上の例と同じプロンプトで生成してみた結果はこれです。devよりも綺麗なのは明らかです。特に背景の詳細はちゃんと描かれています。

実は一番上にある100人の猫耳少女の画像もFLUX.1 krea devで生成されたものです。
blue_pencil-flux1
Stable Diffusionでもよく使われている人気なアニメ系モデルblue_pencilのFLUX.1バージョンです。
fp8版はここからダウンロードできます。
同じプロンプトで生成してみた結果。

本来の複雑なワークフロー
ComfyUIの公式githubリポジトリページを見たら本来のフルバージョンのワークフローを使った画像が乗っています。
schnellの画像をComfyUIにドラッグしたらこのようなワークフローが表示されます。
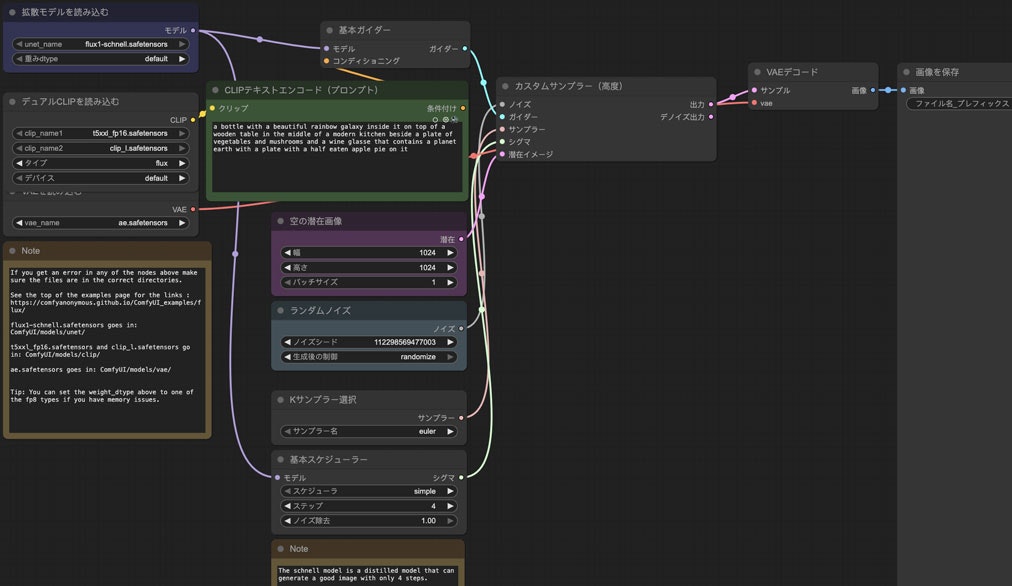
これを私なりにアレンジしたらこうなります。
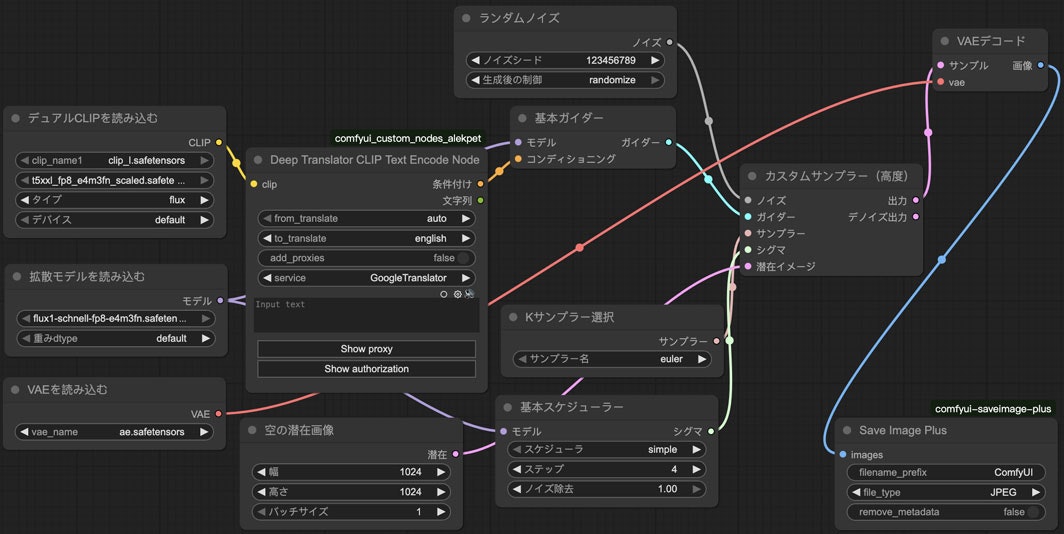
API版のjson。
このワークフローはただモデルを分けるだけでなく、Kサンプラーも分けられるので、随分複雑に見えます。しかしこれはただ本来のKSamplerノードをKSamplerSelect、RandomNoise、BasicScheduler、BasicScheduler、BasicGuider、SamplerCustomAdvancedに分けて、パラメーターもそれぞれのノードで設定することになるだけで、本質は同じです。だから普通にKSamplerを使っても問題ありません。
高度なプロンプトの扱い方
ComfyUIの例で見たら簡単な「Flux Dev」と「Flux Schnell」の他に、「Flux Dev full text to image」「Flux Schnell full text to image」がありますね。
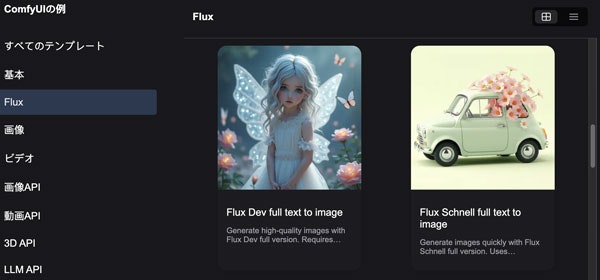
試しに「Flux Schnell full text to image」を選んだらこのようなワークフローになります。
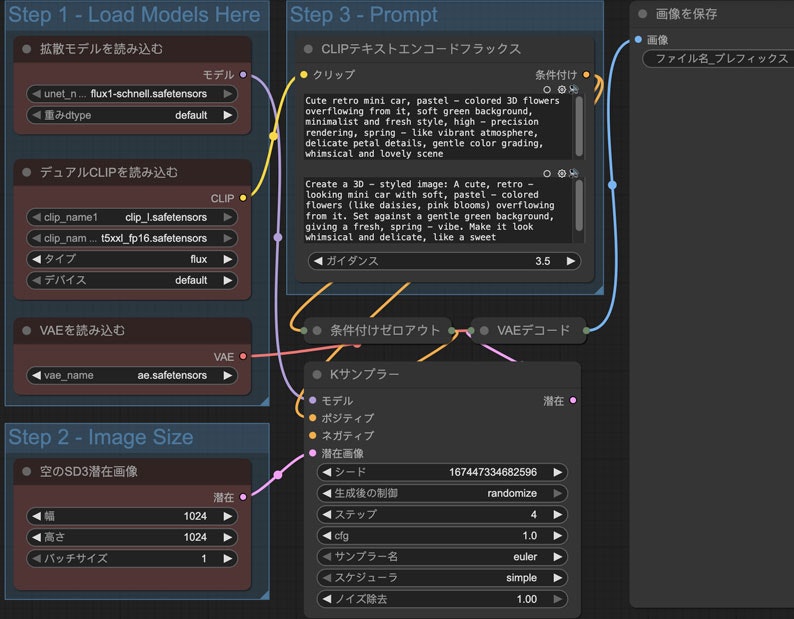
このワークフローは大体上述のモデルを3に分けたワークフローと似ています。モデルもfp8に入れ替えることもできます。ただしプロンプトを入力する部分はCLIPTextEncodeFlux(CLIPテキストエンコードフラックス)ノードになって、その中に2つプロンプトを入れる場所があります。
これはポジティブとネガティブではなく、どちらもポジティブプロンプトです。どのように使い分けをしたらいいかを調べてみたところ、結局違いが微妙で、同じ内容を入れてもいいという人もいます。それだとわざわざ分ける意味ない気もしますね。
自分で試してみたところ本来の一つだけのプロンプトとの違いが微妙でわかりにくいので、多分あまりこれを使う必要ない気がします。
だから私はこれを使わないことにしますが、興味ある方は試して違いを比較してみてもいいと思います。
GGUF軽量化モデルでメモリー節約
fp8の軽量化モデルを使うことでメモリーを節約できますが、それでもスペックがよくないパソコンにとってまだきついかもしれません。その場合は更に軽量化モデルを使った方がいいです。それはGGUF(GPT-Generated Unified Format)モデル。
unetのGGUFモデルはここにダウンロードできます。
派生モデルもGGUF版があります。
又t5-v1_1-xxl-encoderのGGUFモデルもあります。
このリンクに入ってみたら色んなファイルが見えます。各ファイルの違いは軽量化のレベルです。Qの後ろにあるのはビット数です。Q8は8-bitで、あまりfp8と変わらないが、Q2は2-bitとなり、すごい軽いのですが、あまり使い物にならないほど低品質です。
ただしGGUFモデルを使うにはまずそれを読み込むためのノードが必要です。個別でComfyUI-GGUFというパッケージをインストールする必要があります。
ノードのインストールが済んだら、使う時はUnetLoaderGGUFをUnetLoaderの代わりに使って、DualCLIPLoaderGGUFをDualCLIPLoaderの代わりに使います。これでGGUFモデルが使えます。
次は画像の比較をします。devモデルでfp8とQ4_K_SとQ2_Kは比較対象です。

結果を見たところ、Q4はfp8とあまり変わらないが、Q2は明らかに劣りますね。
速度に関してはCLIPの方はt5-v1_1-xxl-encoder-ggufを使うことで僅かに速くなりますが、その一方unetはGGUFを使った方が少し遅くなります。だからもしメモリーの節約が必要ない場合、fp8を使った方がいいと思います。
loraを使う
FLUX.1もStable Diffusionと同様にloraを使うことができます。使い方はほぼ同じです。勿論Stable Diffusionのloraをそのまま使えるわけではなく、FLUX.1のために作られたloraでなければなりません。
FLUX.1-Turbo-Alphaで加速
loraは色んな目的で使われます。例えば少ないステップ数で綺麗に生成できるようにするloraです。その中で人気なのはFLUX.1-Turbo-Alphaというloraです。
ここからダウンロードしてComfyUI/models/loraに置いたら使えます。
このloraを使うと、devのステップ数を20から8にしても綺麗に生成できます。
使う時はただKSamplerノードに入る前のモデルにLoraLoaderModelOnlyノードを挿入するだけで簡単です。
例えばFLUX.1 devで分割ノードの場合、このようなワークフローになります。(ただしFluxGuidanceノードはここで省略)
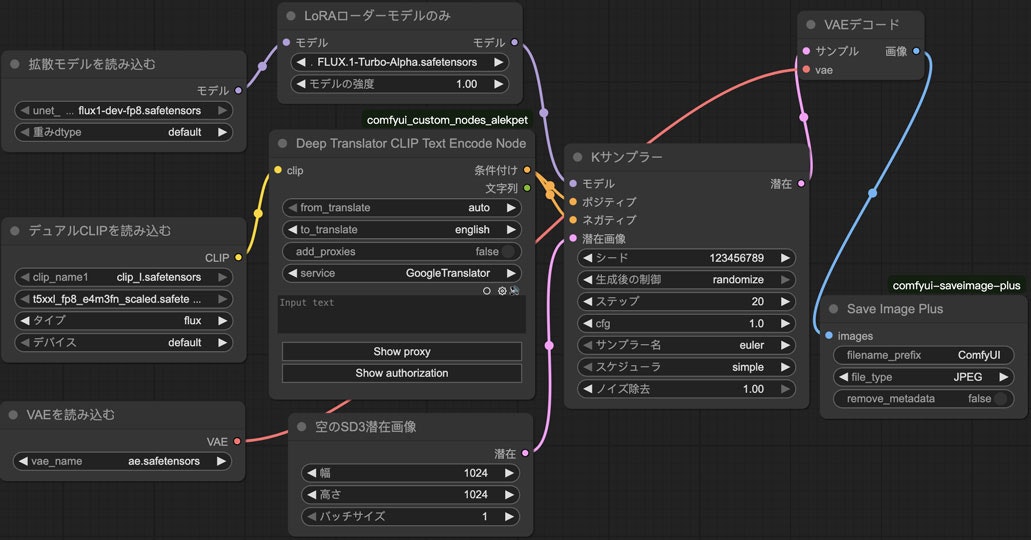
FLUX.1 krea devなどの派生モデルも同様にこのloraを使うことができます。
ではFLUX.1 krea devでFLUX.1-Turbo-Alphaを使う場合と使わない場合の結果を比較してみます。

見たところどれも綺麗であまり変わらないのですね。でもFLUX.1-Turbo-Alphaを使うことで生成時間は半分以下になるので、やはり使いたいですね。
生成結果を比較するの絵を作るのに使ったワークフローのjsonです。
{
"1": {
"inputs": {
"clip_name1": "clip_l.safetensors",
"clip_name2": "t5xxl_fp8_e4m3fn_scaled.safetensors",
"type": "flux",
"device": "default"
},
"class_type": "DualCLIPLoader"
},
"2": {
"inputs": {
"unet_name": "flux1-krea-dev_fp8_scaled.safetensors",
"weight_dtype": "default"
},
"class_type": "UNETLoader"
},
"3": {
"inputs": {
"vae_name": "ae.safetensors"
},
"class_type": "VAELoader"
},
"4": {
"inputs": {
"width": 1024,
"height": 1024,
"batch_size": 1
},
"class_type": "EmptySD3LatentImage"
},
"5": {
"inputs": {
"start": 0,
"end": 4,
"step": 1,
"loops": 1,
"ping_pong": false
},
"class_type": "CR Integer Range List"
},
"6": {
"inputs": {
"seed": 302724320439695
},
"class_type": "CR Seed"
},
"7": {
"inputs": {
"lora_name": "FLUX.1-Turbo-Alpha.safetensors",
"strength_model": 1,
"model": ["2", 0]
},
"class_type": "LoraLoaderModelOnly"
},
"8": {
"inputs": {
"strings": "アニメ、紫色のチャイナ服を着ている緑色ツインテール猫耳少女がアンコールワットの中の桜の下でバイオリンを弾いている\nアニメ、桃色市松の制服を着ている赤いツインテール猫耳少女は雪の降っている夜のワットプラケオの中のヤシの下で踊っている\nアニメ、白い和服姿の金髪ツインテール猫耳少女は雨の降っているシュエダゴンパゴダの前の松の下でゴルフをやっている\nアニメ、花模様の緑色メイド服を着ている桃色ツインテール猫耳少女は秋の万里長城の銀杏の下で微笑みながら大きなアイスクリームを舐めている",
"multiline": false,
"select": ["5", 0]
},
"class_type": "ImpactStringSelector"
},
"9": {
"inputs": {
"from_translate": "auto",
"to_translate": "english",
"add_proxies": false,
"proxies": "",
"auth_data": "",
"service": "GoogleTranslator",
"text": ["8", 0],
"Show proxy": "proxy_hide",
"Show authorization": "authorization_hide",
"clip": ["1", 0]
},
"class_type": "DeepTranslatorCLIPTextEncodeNode"
},
"10": {
"inputs": {
"seed": ["6", 0],
"steps": 20,
"cfg": 1,
"sampler_name": "euler",
"scheduler": "simple",
"denoise": 1,
"model": ["2", 0],
"positive": ["9", 0],
"negative": ["9", 0],
"latent_image": ["4", 0]
},
"class_type": "KSampler"
},
"11": {
"inputs": {
"seed": ["6", 0],
"steps": 8,
"cfg": 1,
"sampler_name": "euler",
"scheduler": "simple",
"denoise": 1,
"model": ["7", 0],
"positive": ["9", 0],
"negative": ["9", 0],
"latent_image": ["4", 0]
},
"class_type": "KSampler"
},
"12": {
"inputs": {
"samples": ["10", 0],
"vae": ["3", 0]
},
"class_type": "VAEDecode"
},
"13": {
"inputs": {
"samples": ["11", 0],
"vae": ["3", 0]
},
"class_type": "VAEDecode"
},
"14": {
"inputs": {
"images_a": ["12", 0],
"images_b": ["13", 0]
},
"class_type": "Image Batch"
},
"15": {
"inputs": {
"images": ["14", 0]
},
"class_type": "ImageListToImageBatch"
},
"16": {
"inputs": {
"border_width": 2,
"number_of_columns": 2,
"max_cell_size": 512,
"border_red": 0,
"border_green": 0,
"border_blue": 0,
"images": ["15", 0]
},
"class_type": "Create Grid Image from Batch"
},
"17": {
"inputs": {
"filename_prefix": "ComfyUI",
"file_type": "JPEG",
"remove_metadata": false,
"images": ["16", 0]
},
"class_type": "SaveImagePlus"
}
}
nunchakuで爆速
* この部分は2025年8月11日に追記
GGUFと似て、nunchakuという軽量化モデルがあります。軽量化であることは同じで使い方も似ていますが、nunchakuの方はGGUFより新しくて効果的な方法です。
GGUFの場合は軽量化しても速度は元のモデルとあまり変わらないが、nunchakuを使うと速度は何倍も上がります。爆速です!
ただしこの方法はインストールが難しくて、環境によって使えない場合もあります。
まずnunchakuを使うためにはパッケージのインストールが必要です。ComfyUI Managerで検索したら見つけるでしょう。
しかし環境次第ではこのままインストールしようとしても恐らく失敗に終わる可能性が高いです。
インストール問題について環境によって違うので解決方法は一括で言えないのですが、私の場合はnunchakuのPythonモジュールのインストールの失敗が原因です。そうなると手動でインストールするしかない。
解決方法としてはnunchaku配布のgithubサイトから今に合うバージョンを探してpipでインストールします。
例えば私の場合はwindows版でPython3.12とtorch2.7なので、これでインストール成功します。
pip install https://github.com/nunchaku-tech/nunchaku/releases/download/v0.3.2/nunchaku-0.3.2+torch2.7-cp312-cp312-win_amd64.whl
今後インストールが簡単に成功できるようになるかもしれませんが、今のところ自分で色々調べて試すしかないです。
インストールが成功してComfyUIを起動したら今回はnunchaku関連のノードが使えるようになるでしょう。
そうしたらまずNunchakuWheelInstallerノードを配置して、右にPreviewAny(プレビュー任意)も配置して繋げます。
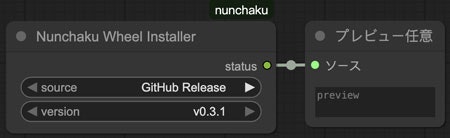
{
"1": {
"inputs": {
"source": "GitHub Release",
"version": "v0.3.1"
},
"class_type": "NunchakuWheelInstaller"
},
"2": {
"inputs": {
"preview": "",
"source": ["1", 0]
},
"class_type": "PreviewAny"
}
}
そして実行してインストール成功と表示されたらこれでnunchakuモデルが使えるようになるでしょう。
nunchakuに使うモデルはnunchaku開発者によってhuggingfaceに公開されています。
例えばFLUX.1 krea devのnunchakuモデルがあります。
ファイルは2つありますが、これは環境によって使い分けする必要があります。
-
svdq-fp4_r32は非Blackwellモデル用(50シリーズの前) -
svdq-int4_r32はBlackwellモデル用(50シリーズより)
どっちを使えばいいかわからない場合はどっちも試して、間違ったらエラーが出てすぐわかるでしょう。
そしてこのモデルを使う時はただ本来のUNETLoaderをNunchakuFluxDiTLoaderに入れ替えるだけです。
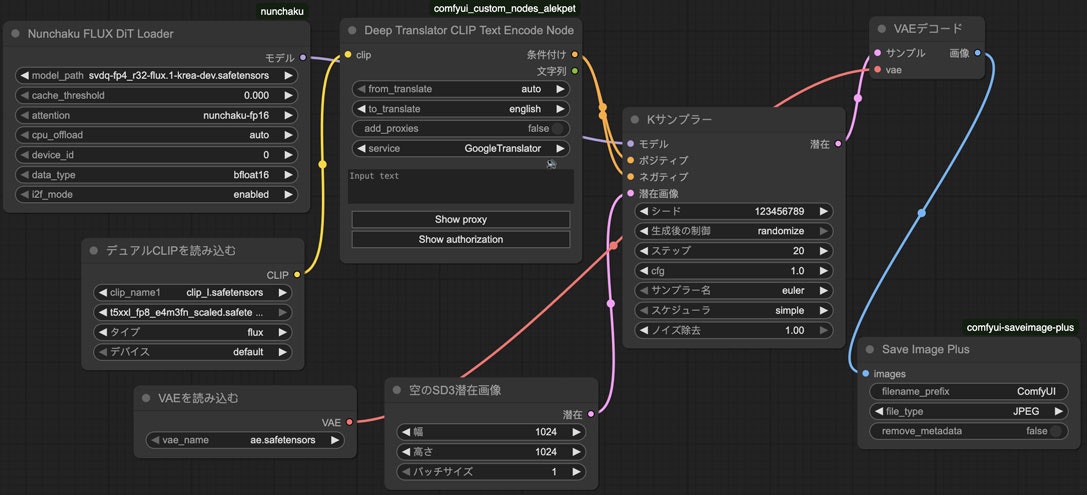
生成できた画像の品質に関してはfp8モデルとの違いは殆ど感じませんが、生成時間は本来の40秒から10秒にまで短縮しました。
ステップ数は20のままなのに、turboを使う8ステップの場合よりも速いです。
ただしnunchakuとturboを同時に使ってみたら品質低下が明らかになるので、nunchakuを使う場合turboを使うべきではないでしょう。使わなくても既に十分に速いですし。
NunchakuFluxDiTLoaderノードの値は既定値のままで問題ないですが、色々調整できます。例えばcache_thresholdは0.12など0より高い数値にしたらもっと速度が上がりますが、品質は下がります。cache_thresholdが0でも十分に速いので、そのままでいいと思います。
FLUX.1 krea devでの生成結果もここに載せておきましょう。

微妙な違いが見えるもののどっちも綺麗に生成できて、どっちがいいかはほぼ判断できませんね。しかし生成速度は4-5倍も違うので、やはりnunchakuを使った方がいいでしょう。
又loraを使う場合NunchakuFluxDiTLoaderとともにNunchakuFluxLoraLoaderは必要です。普段のLoraLoaderModelOnlyを使ってもエラーは出ないが、loraの効果が出ないので注意です。
終わりに
以上FLUX.1の色んな使い方の紹介でした。しかしこれはまだただの基本的なtxt2imgだけですね。その他にもimg2img、inpaint、controlnetなど、Stable Diffusionでもよく使われる機能と同様なものがあります。特に最近話題となったFLUX.1 Kontextはかなり凄いものです。今後これについて書きたいと思います。
inpaintについては次の記事に書きました。
又ComfyUIの他にdiffusersでもFLUX.1が使えます。Stable Diffusionの時私はdiffusersから始めた後ComfyUIを使ったのですが、FLUX.1は逆にComfyUIから試しました。今後diffusersでも使ってみたいと思います。
参考
FLUX.1 @ ComfyUI
- 画像生成AI FLUX.1 をBlack Forest Labs リファレンス実装、Diffusers、ComfyUI で動かしてみた(セルフホスト)
- ComfyUIでFlux AIを使う方法:詳細ガイド
- FLUXメモ
- FLUX.1 : ComfyUI 公式 FLUX.1 dev 用ワークフロー詳細
FLUX.1 @ diffusers
- 画像生成AI FLUX.1 に Diffusers で LoRA を適用してみた
- Stable Diffusionのオリジナル開発陣が発表した画像生成AIモデルFLUX.1([dev]/[schnell])をMacBook(M2)で動かしてみた
- FLUX.1をdiffusers環境下VRAM 16GB以下のGPUで使用する
FLUX.1 krea
- 【ComfyUI】FLUX.1 Krea [dev]がネイティブ対応!ワークフローの使い方
- Flux Krea Dev | 自然なテキストから画像へ
- AIっぽさ」を徹底的に排除した画像生成AIモデル「FLUX.1 Krea [dev]」が登場
GGUF
- ComfyUIでFlux.1のGGUFを試してみる
- ComfyUI FLUX.1 GGUF の使い方
- 【2024年最新】無料で始めるFlux画像生成の爆速化!🖼️ GGUF・NF4モデルで30分→3分へ短縮✨ LoRA・ControlNet対応の量子化テクニック完全解説💡 ComfyUIでVRAM60%節約!MacBookでも使える驚異の高速ワークフロー公開🔥
- 【ComfyUI】Flux.1 [dev]の詳しい使い方 GGUFを使った軽量化も紹介
- ファインチューニングしたモデルをGGUFに変換する。
- GGUF 変換メモ
- LLMをHuggingFace形式からGGUF形式へ変換する
- 【Flux.1】 モデル形式はどれが良い? FP16 / Q_8 / Q_4 / NF4 を徹底比較!
nunchaku
- 【Midjourney終了の真相】もう有料AIは不要。2K画像を"8秒"で無限生成する無料AI「FLUX Krea × Nunchaku」が革命的すぎる…【ComfyUI】
- Flux.1 Krea Dev、GGUF、Nunchaku版ComfyUI完全使用ガイドチュートリアル
その他
- 【初心者歓迎】FLUX.1 dev の使い方❗️LoRA・Controlnetも使える、キング・オブ・画像生成AI『FLUX.1』のベストモデル、[dev]をComfyUIで動かす方法を完全解説❗️〜Stable Diffusion開発陣が贈る最新モデル〜
- Flux.1-devで現場猫の画像を生成しよう
- 画像生成AI「FLUX.1(フラックス)」とは?始め方や使い方、活用例を紹介
- Stable Diffusion WebUI Forge(画像生成AI)でFLUX.1を使用する
- FLUX.1のおすすめモデル6選!Stable Diffusionでの使い方もご紹介
- Flux は 0.1 から 2.0 メガピクセルの解像度を推奨しています