この記事では画像編集や合成を簡単にできるFLUX.1 Kontext devモデルをComfyUIで使う方法について説明します。
はじめに
この前ComfyUIによるFLUX.1の入門の記事を投稿しました。
その後は追加の便利な機能の使い方を紹介しました。
今回はその続きとしてもっと新しくてやばいFLUX.1 Kontextを紹介したいと思います。
FLUX.1 Kontextは2025年5月29日に公開した、指示の言葉(プロンプト)で1枚の画像を編集したり、2枚以上の画像を合成したりするモデルです。
FLUX.1 fillも画像を編集するのに使えますが、使い方は違います。FLUX.1 fillがマスクを塗ってその部分を修正するのに対し、FLUX.1 Kontextはマスクなんて必要なくて、何を修正したいか言葉で指示するだけで修正できるのでとても便利です。できた結果もFLUX.1 fillより綺麗に見えます。
ただしFLUX.1 fillよりもFLUX.1 Kontextの方が処理が重くて時間がかかりますし、適切なプロンプトを書かないと全く効果がないので、使い方や目的によってはFLUX.1 fillの代わりになれないところもあります。
他のFLUX.1モデルと同様に、FLUX.1 Kontextも有料のモデルと、ダウンロードして自由にモデルをローカルで実行できるモデルがあります。有料版にはFLUX.1 Kontext proとFLUX.1 Kontext maxにありますが、今回紹介するのは一般オープン版であるFLUX.1 Kontext devです。有料版は使ったことないが、無料のdevでも十分に既に凄いです。何よりローカルで動かせるので使い勝手がいいです。
前の記事と同様に今回もComfyUIでの使い方を説明します。
ComfyUIでのFLUX.1 Kontext devの導入
ComfyUIではFLUX.1 Kontext devを使うためのワークフローのテンプレートが準備されているので、これを使うと便利です。
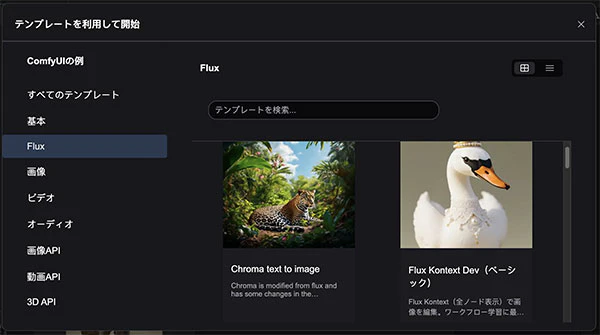
テンプレートを選択したら足りないモデルが表示されて、すぐダウンロードできます。

基本的にVAEもCLIPもFLUX.1 devと同じなので、FLUX.1 devを使っている人ならそのまま使っていいです。
ここでは追加で必要なのはFLUX.1 Kontext devのモデルです。テンプレートの中で使われているのは既に軽量化のfp8版です。このリンクからもダウンロードできます。
-
flux1-dev-kontext_fp8_scaled.safetensors
(ファイル名はなぜかflux1-kontext-devではなくflux1-dev-kontextになっていますが、まあどっちでもいいでしょう)
一応もし本来のfp16モデルが欲しいならこのリンクからダウンロードできますが、基本的にあまり必要なくてfp8でいいと思います。
又GGUF版とnunchaku版もあります。
FLUX.1 Kontext devはかなり時間かかるので、nunchaku版をおすすめします。
テンプレートのワークフローはこのようになります。

これはちょっと複雑ですね。実はこのワークフローは1枚のみの画像を編集する場合と2枚を使う場合も使えるように作られているようですが、これは逆にわかりにくい気がします。
だからわかりやすいようにまず私は1枚のみ使う場合から説明します。2枚の場合はその後別で解説します。
1枚の画像を思い通りに改造する
まず私なりにワークフローを作り直したらこんな感じになります。
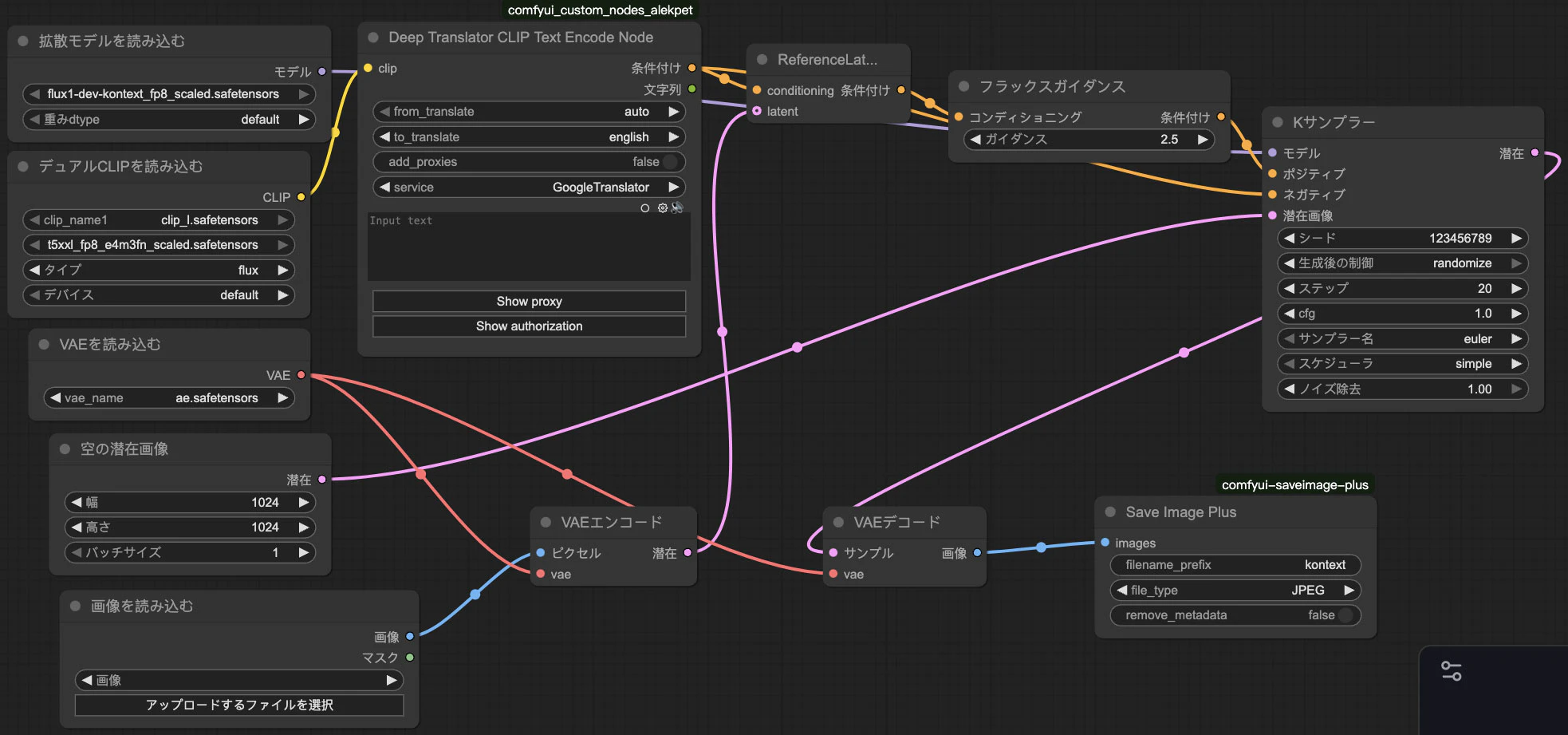
jsonでワークフローを書くとこうなります。
{
"1": {
"inputs": {
"unet_name": "flux1-dev-kontext_fp8_scaled.safetensors",
"weight_dtype": "default"
},
"class_type": "UNETLoader"
},
"2": {
"inputs": {
"clip_name1": "clip_l.safetensors",
"clip_name2": "t5xxl_fp8_e4m3fn_scaled.safetensors",
"type": "flux",
"device": "default"
},
"class_type": "DualCLIPLoader"
},
"3": {
"inputs": {
"vae_name": "ae.safetensors"
},
"class_type": "VAELoader"
},
"4": {
"inputs": {
"width": 1024,
"height": 1024,
"batch_size": 1
},
"class_type": "EmptyLatentImage"
},
"5": {
"class_type": "LoadImage"
},
"6": {
"inputs": {
"from_translate": "auto",
"to_translate": "english",
"add_proxies": false,
"proxies": "",
"auth_data": "",
"service": "GoogleTranslator",
"text": "",
"Show proxy": "proxy_hide",
"Show authorization": "authorization_hide",
"clip": ["2", 0]
},
"class_type": "DeepTranslatorCLIPTextEncodeNode"
},
"7": {
"inputs": {
"pixels": ["5", 0],
"vae": ["3", 0]
},
"class_type": "VAEEncode"
},
"8": {
"inputs": {
"conditioning": ["6", 0],
"latent": ["7", 0]
},
"class_type": "ReferenceLatent"
},
"9": {
"inputs": {
"guidance": 2.5,
"conditioning": ["8", 0]
},
"class_type": "FluxGuidance"
},
"10": {
"inputs": {
"seed": 123456789,
"steps": 20,
"cfg": 1,
"sampler_name": "euler",
"scheduler": "simple",
"denoise": 1,
"model": ["1", 0],
"positive": ["9", 0],
"negative": ["6", 0],
"latent_image": ["4", 0]
},
"class_type": "KSampler"
},
"11": {
"inputs": {
"samples": ["10", 0],
"vae": ["3", 0]
},
"class_type": "VAEDecode"
},
"12": {
"inputs": {
"filename_prefix": "kontext",
"file_type": "JPEG",
"remove_metadata": false,
"images": ["11", 0]
},
"class_type": "SaveImagePlus"
}
}
以前の記事と同様、今回もComfyUI_Custom_Nodes_AlekPetのDeepTranslatorCLIPTextEncodeNodeとcomfyui-saveimage-plusのSaveImagePlusノードを本来のCLIPTextEncodeとSaveImageの代わりに使っています。
DeepTranslatorCLIPTextEncodeNodeを使うことで日本語でプロンプトを書くことができるので便利です。
ワークフローは基本的にFLUX.1 fillと似た形ですね。ただし個別で空の潜在画像ノードが必要です。出力の画像のサイズは入力画像と違うサイズにすることもできます。適切に指定のサイズに合うように書き換えられるので便利です。ただし1枚画像を編集したい場合は基本的にその1枚の入力画像と同じサイズを指定するのは一番簡単で安全です。
今回は例としてこの画像を使います。これはQwen-Imageモデルで生成されてWan2.2で改善されたものです。

この画像のサイズは1184×880なので、空の潜在画像サイズもそれに合わせます。
そして試しに「胡蝶を全部消す」というプロンプトを入力して実行します。
そうしたら結果はこうなります。

飛んでいる胡蝶は本当に綺麗さっぱり消えましたね。FLUX.1 Kontextその画像の中でどれが胡蝶というものか理解して、それだけ消してくれます。しかも胡蝶がいたところは適切に背景で埋められます。これは凄いですね。
更にただの削除するだけでなく、例えば何かで置き換えることもできます。
例えば「パンダをカピバラに置き換える」と入力します。

本当にカピバラっぽい?のが出てきますね。ただパンダの代わりということでどこかパンダっぽい感じが残っていますね。カピバラとパンダが合体したような感じかもしれません。このようにFLUX.1 Kontextは元あった要素をできるだけ保持しながら新しいものに置き換えるのです。
要素を追加することもできます。例えば「空にたくさん飛行機が飛んでいる」と。

色だけ変えることも。例えば「少女の髪の色を薄緑にする。少女の服装の色を薄桃色にする」と。

なんかこんな感じだと遠い空を飛んでいるよりも、近くにある玩具の飛行機っぽいですね。胡蝶も勝手に削除されています。そうしないと飛行機が入れられないからでしょうね。
次は場所を変えるなど。例えば「場所はハロン湾」と。

なんか後ろはハロン湾っぽくなったような気が……。いや違うと思います。でもそれっぽい。
画風変換もできます。例えば「8ビット」とだけ入力して。

綺麗な8ビット風画像になりましたね。
このように色々な形で画像を思い通り編集することができます。微妙なところも多いのですが、これもプロンプトの書き方次第で改善できます。
アウトペイントみたいな使い方
以上の例は出力サイズを入力画像のサイズと同じにしたが、違うサイズを指定することでアウトペイントみたいなことができます。
例えばこの画像を使います。これもQwen-Imageで生成されたものです。

この画像のサイズは1024×1024ですが、全身を見たいので出力サイズを1024×2048にして、「薄桃色の靴を履く少女」とプロンプト入力します。
結果。

本当に下半身が作られますね。実はただ「全身を表示する」など書いただけでもAIが想像して適切に下半身が生成されますが、私達が想像したのと全然違う可能性があります。具体的な指示を書いたらそれに合わせてもらえます。
FLUX.1 fillもこのようなアウトペイントはできますが、できた結果はFLUX.1 Kontextは圧倒的に優れます。もうアウトペイントするならFLUX.1 Kontextを使うしかないくらい。
FluxKontextImageScaleノードに関して
テンプレートを見たら実はFluxKontextImageScaleというノードが入っています。このノードの説明はこう書いてあります。
このノードは、入力画像のアスペクト比に基づいて、Lanczosアルゴリズムを使用してFlux Kontextモデルのトレーニング時に使用された最適なサイズに画像をスケーリングします。大きなサイズの画像を入力すると、モデルの出力品質が低下したり、出力に複数の被写体が表示されるなどの問題が発生する可能性があるため、このノードは特に有用です。
そのサイズも書いてあります。
| 広さ | 高さ | アスペクト比 |
|---|---|---|
| 672 | 1568 | 0.429 |
| 688 | 1504 | 0.457 |
| 720 | 1456 | 0.494 |
| 752 | 1392 | 0.540 |
| 800 | 1328 | 0.603 |
| 832 | 1248 | 0.667 |
| 880 | 1184 | 0.743 |
| 944 | 1104 | 0.855 |
| 1024 | 1024 | 1.000 |
| 1104 | 944 | 1.170 |
| 1184 | 880 | 1.345 |
| 1248 | 832 | 1.500 |
| 1328 | 800 | 1.660 |
| 1392 | 752 | 1.851 |
| 1456 | 720 | 2.022 |
| 1504 | 688 | 2.186 |
| 1568 | 672 | 2.333 |
つまりこのノードはFLUX.1 Kontextの訓練データに近いサイズに画像を変換するので、これを使った方が一番いい結果は期待できるということです。しかしそれは自分が欲しいサイズとは限らないのです。知らずにこのノードを入れたら勝手に違うサイズに変換されてしまいます。
更にアスペクト比も変わる可能性があります。例えば1024×2048pxの画像を入力したら、このように一番アスペクト比が0.5に近い720×1456サイズにリサイズされますが、そのアスペクト比は0.494であり、微妙だけど変わってしまいます。
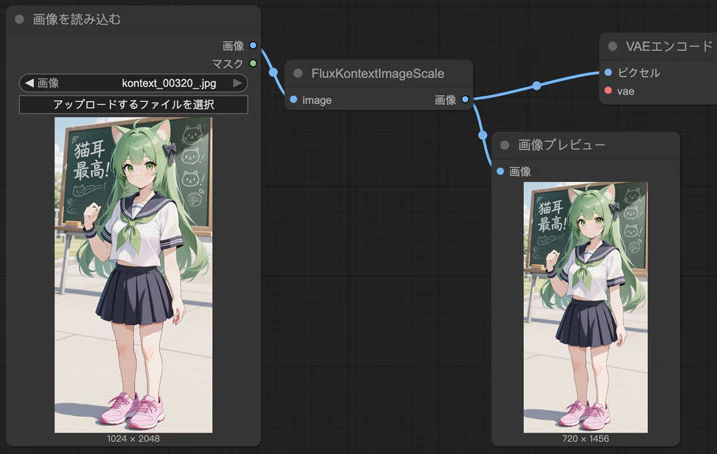
それに画像の解像度が落ちるからもう一度拡大しても綺麗にはならないでしょう。だからこれが気になるならこのノードを入れては駄目です。
ということで基本的にただ1枚の画像を編集したい場合はFluxKontextImageScaleノードを使わない方がいいですね。
ただし2枚から合成したい場合はFluxKontextImageScaleノードが重要になります。
2枚の画像から合成する
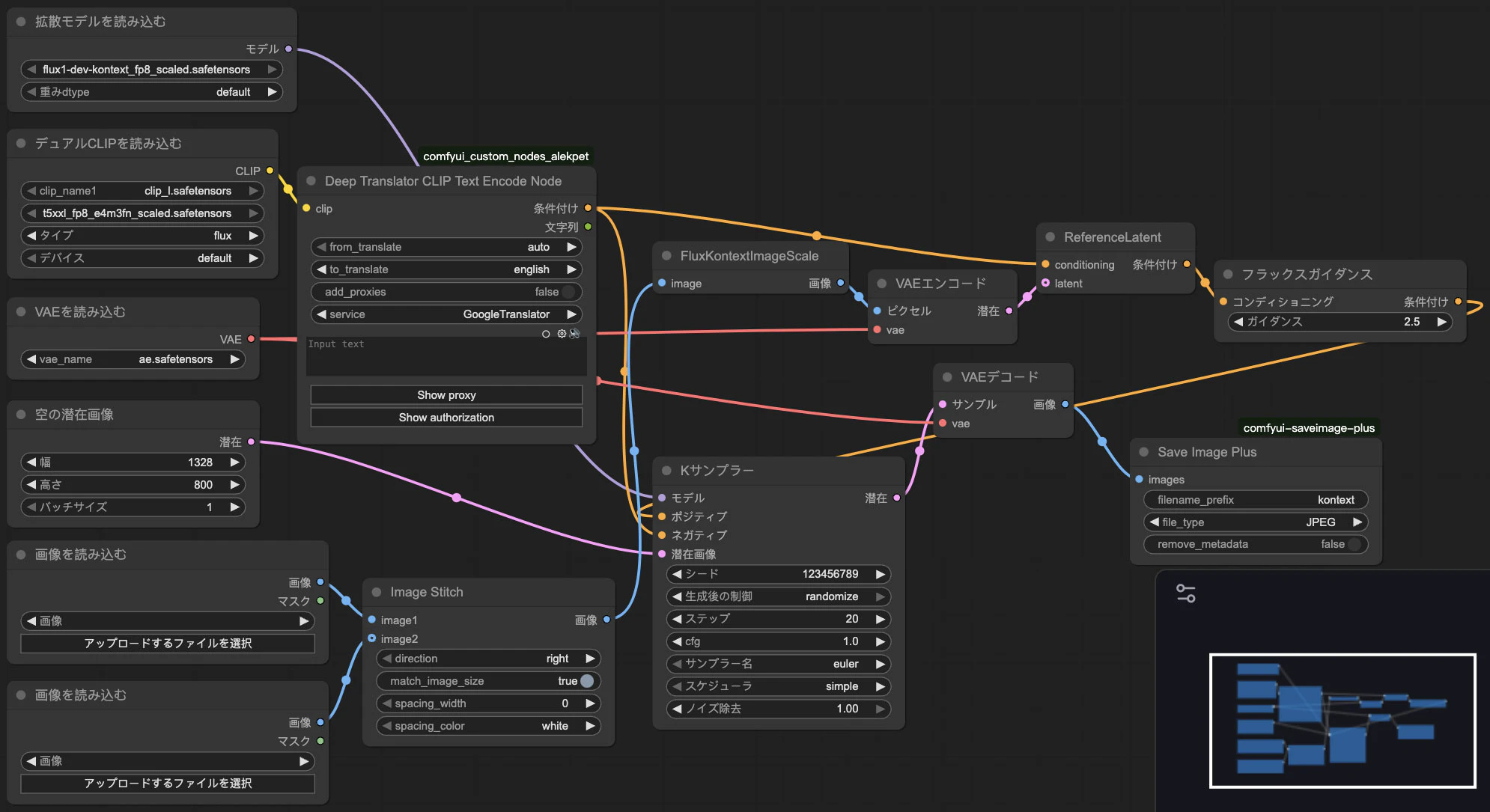
次は2枚から画像わ合成する方法について説明します。その場合のワークフローはこのようになります。
{
"1": {
"inputs": {
"unet_name": "flux1-dev-kontext_fp8_scaled.safetensors",
"weight_dtype": "default"
},
"class_type": "UNETLoader"
},
"2": {
"inputs": {
"clip_name1": "clip_l.safetensors",
"clip_name2": "t5xxl_fp8_e4m3fn_scaled.safetensors",
"type": "flux",
"device": "default"
},
"class_type": "DualCLIPLoader"
},
"3": {
"inputs": {
"vae_name": "ae.safetensors"
},
"class_type": "VAELoader"
},
"4": {
"inputs": {
"width": 1328,
"height": 800,
"batch_size": 1
},
"class_type": "EmptyLatentImage"
},
"5": {
"class_type": "LoadImage"
},
"6": {
"class_type": "LoadImage"
},
"7": {
"inputs": {
"from_translate": "auto",
"to_translate": "english",
"add_proxies": false,
"proxies": "",
"auth_data": "",
"service": "GoogleTranslator",
"text": "",
"Show proxy": "proxy_hide",
"Show authorization": "authorization_hide",
"clip": ["2", 0]
},
"class_type": "DeepTranslatorCLIPTextEncodeNode"
},
"8": {
"inputs": {
"direction": "right",
"match_image_size": true,
"spacing_width": 0,
"spacing_color": "white",
"image1": ["5", 0],
"image2": ["6", 0]
},
"class_type": "ImageStitch"
},
"9": {
"inputs": {
"image": ["8", 0]
},
"class_type": "FluxKontextImageScale"
},
"10": {
"inputs": {
"pixels": ["9", 0],
"vae": ["3", 0]
},
"class_type": "VAEEncode"
},
"11": {
"inputs": {
"conditioning": ["7", 0],
"latent": ["10", 0]
},
"class_type": "ReferenceLatent"
},
"12": {
"inputs": {
"guidance": 2.5,
"conditioning": ["11", 0]
},
"class_type": "FluxGuidance"
},
"13": {
"inputs": {
"seed": 123456789,
"steps": 20,
"cfg": 1,
"sampler_name": "euler",
"scheduler": "simple",
"denoise": 1,
"model": ["1", 0],
"positive": ["12", 0],
"negative": ["7", 0],
"latent_image": ["4", 0]
},
"class_type": "KSampler"
},
"14": {
"inputs": {
"samples": ["13", 0],
"vae": ["3", 0]
},
"class_type": "VAEDecode"
},
"15": {
"inputs": {
"filename_prefix": "kontext",
"file_type": "JPEG",
"remove_metadata": false,
"images": ["14", 0]
},
"class_type": "SaveImagePlus"
}
}
ここで重要なのはImageStitchというノードです。これを使うことで2枚の画像。が左と右でくっつくためのノードです。
例えば今回はこの2枚の画像を使います。これはどれもshuttle 3 diffusionモデルで生成された画像です。


このノードで画像はこんな風にくっつきます。
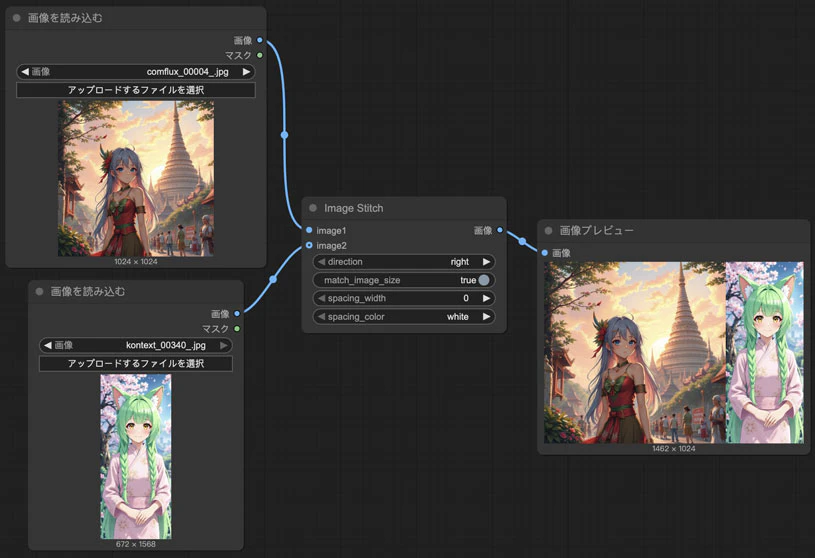
つまり2枚画像から合成したい場合でも、実際の入力は2枚画像ではなく、このようにくっついた画像どす。FLUX.1 Kontextはその中で自分で区別します。
又ここでFluxKontextImageScaleノードも使います。2枚が並ぶとサイズが大きすぎて必要以上に時間がかかってしまうことがあるのでこの場合サイズ変換はおすすめです。
ではサイズは1184×880と指定して、「二人の少女は抱き合っている」というプロンプトで実行してみます。
結果はこんな感じです。

これは本当に凄いですね。二人の顔や服装はそのままで向きやポースは適切に変わって本当に抱き合っているという形になっています。
とい言いたいところですが、実は腕や手の形がおかしくてうまく描かれない場合が多いです。この画像は数十枚生成した中で一番よくできたものを選んだだけ。結局ガチャ性もまだ大きいです。
この二人の間のサイズ関係もバラバラです。くっついた画像で左の少女の方が小さいから小さく描かれた場合は多いが、逆に大きく描かれた場合もあります。
背景に関しては、もし指定したら変えることもできますが、ここでは指示していないので左側の背景そのまま使われています。
この例では2人の人物の合成ですが、その他にも人物と物や動物や場所などもできます。
3枚も試してみる
2枚の場合と同じように、3枚や4枚からの合成もできます。その場合は全部の入力画像をくっつく必要があります。ImageStitchノードを使う場合は2枚ずつしかできないので、3枚があるとImageStitchを2回使う必要があります。ただし画像によっては左と右ばかりくっつくより上と下にした方がいい場合もあるので、適切にくっつき方を考えた方がいいです。
今回は2人の少女の画像に加えこの桜並木の道の画像を3枚目として使ってみます。

こんな形でくっついて入力として使います。

サイズは1184×880でプロンプトは「二人の少女は桜並木で座っている」と入力します。
結果は綺麗に3枚画像の要素が現れます。

ただしたくさん画像を使うと難易度が高くなります。変な形で要素が混ざったり、欲しい要素が無視されたりする場合は多いです。そうならないように適切なプロンプトの書き方は更に重要になります。
編集したい部分変えるインペイント方法
FLUX.1 Kontextを使うと、インペイントの時みたいにマスクを付けなくてもよくて便利だと言われていますが、実際にそううまくいかない場合もあります。
例えばこのような画像です。

この中に似たような猫耳少女3人います。誰か一人だけ修正したい時どのように説明するかは難しいです。「真ん中の少女」や「緑髪の少女」とかで説明してもうまくいかない場合が多いです。
更に空にたくさん鷹が飛んでいます。どれかのみ削除したり修正したりするのは難しいです。こういう時インペイントの方が使いやすいということになりますが、実はFLUX.1 Kontextをインペイントのように使う方法もあります。
ComfyUI公式ではないが、ZenAI-Vietnamよって「FLUX.1 Kontextでインペイントする」ためのノードが作られました。
ただしこのパッケージはComfyUI Managerに登録されていないのので、手動でインストールしかないのです。リポジトリのコードをzipでダウンロードしてComfyUIフォルダの中のcustom_nodesに入れてください。
このパッケージの中にはKontext Inpainting Conditioningというノード1つしかありません。使い方は簡単です。ワークフローはこのようになります。
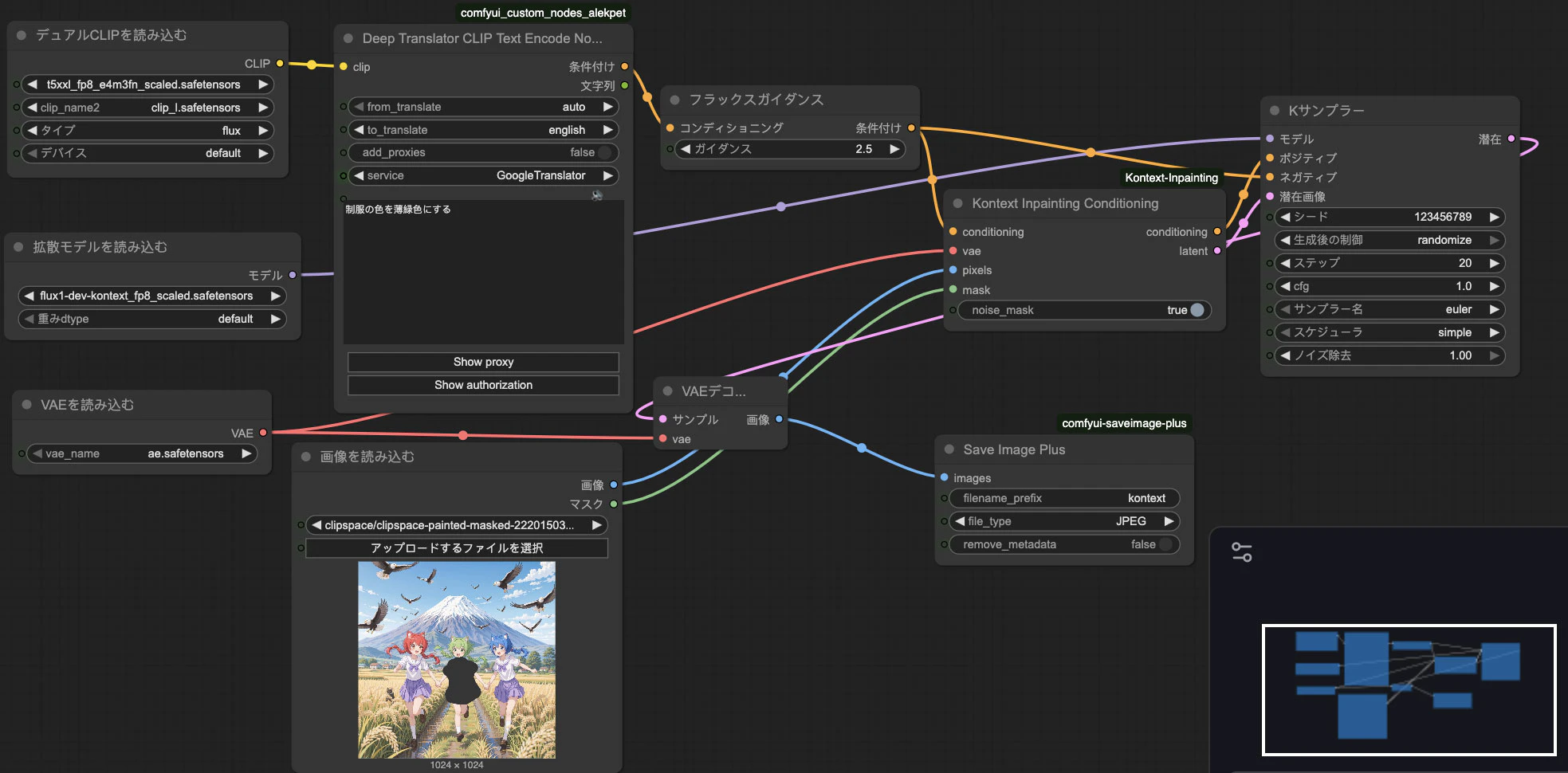
{
"1": {
"inputs": {
"clip_name1": "t5xxl_fp8_e4m3fn_scaled.safetensors",
"clip_name2": "clip_l.safetensors",
"type": "flux",
"device": "default"
},
"class_type": "DualCLIPLoader"
},
"2": {
"inputs": {
"unet_name": "flux1-dev-kontext_fp8_scaled.safetensors",
"weight_dtype": "default"
},
"class_type": "UNETLoader"
},
"3": {
"inputs": {
"vae_name": "ae.safetensors"
},
"class_type": "VAELoader"
},
"4": {
"class_type": "LoadImage"
},
"5": {
"inputs": {
"from_translate": "auto",
"to_translate": "english",
"add_proxies": false,
"proxies": "",
"auth_data": "",
"service": "GoogleTranslator",
"text": "",
"Show proxy": "proxy_hide",
"Show authorization": "authorization_hide",
"clip": ["1", 0]
},
"class_type": "DeepTranslatorCLIPTextEncodeNode"
},
"6": {
"inputs": {
"guidance": 2.5,
"conditioning": ["5", 0]
},
"class_type": "FluxGuidance"
},
"7": {
"inputs": {
"noise_mask": true,
"conditioning": ["6", 0],
"vae": ["3", 0],
"pixels": ["4", 0],
"mask": ["4", 1]
},
"class_type": "Kontext Inpainting Conditioning"
},
"8": {
"inputs": {
"seed": 123456789,
"steps": 20,
"cfg": 1,
"sampler_name": "euler",
"scheduler": "simple",
"denoise": 1,
"model": ["2", 0],
"positive": ["7", 0],
"negative": ["6", 0],
"latent_image": ["7", 1]
},
"class_type": "KSampler"
},
"9": {
"inputs": {
"samples": ["8", 0],
"vae": ["3", 0]
},
"class_type": "VAEDecode"
},
"10": {
"inputs": {
"filename_prefix": "kontext",
"file_type": "JPEG",
"remove_metadata": false,
"images": ["9", 0]
},
"class_type": "SaveImagePlus"
}
}
ここで試しに真ん中の少女だけマスクを付けて「制服の色を薄緑色にする」とプロンプトで実行します。
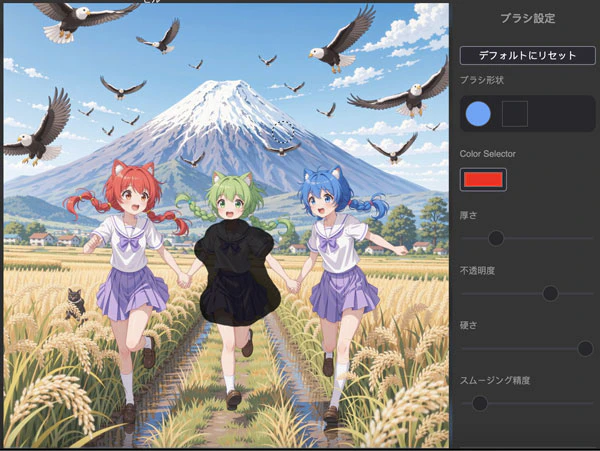
こうやって真ん中の子だけ制服の色が変わります。

FLUX.1 Kontextは本来言葉だけで修正するのですが、修正したいところを明白に指定する場合はそれだけでは難しいですね。こういう時はこのKontext Inpainting Conditioningを使うことでFLUX.1 Kontextとインペイントの強みを合わせて更に強力です。
終わりに
以上FLUX.1 Kontext devの機能と使い方の紹介でした。本当に凄いものですね。
ただしこれを使う時に大事なのは正しく指示するプロンプトです。何が欲しいかうまく説明できたら思い通りにできますが、うまく書けない人はあまり使い熟せないかもしれません。手よりも言葉で画像を編集する時代になったって感じですね。
関係ある話ですが、FLUX.1 Kontextが公開された後2ヶ月経って2025年8月19日に似た機能を持つアリババのQwen-Image-Editも公開されて、よくFLUX.1 Kontextと並べて比較されています。
Qwen-Image-Editの方が指示に忠実するらしいですが、モデルのサイズが大きくてFLUX.1 Kontextより重くて資源を消耗して遅いです。
だからまずはFLUX.1 Kontextで試して、本当に駄目だったらQwen-Image-Editを使う、という使い分けがいいかもしれません。
その他に、近い時期にリリースされて話題になったGoogleのnano-bananaがあって、これは更に優秀な画像編集AIと言われています。ただnano-bananaは非公開モデルであり、モデルのファイルをダウンロードしてComfyUIなどでローカルで実行することはできないので話は大きく違いますね。
今後も他に便利な画像編集AIモデルがたくさん出てくると思います。どうなるか期待してしまいますね。
参考
FLUX.1 Kontextの基本
- FLUX.1 Kontextで同じキャラを描く
- FLUX.1 Kontextでぬいぐるみを抱きしめる画像を作る【kontextを使うときのポイント】
- 画像加工に適したFLUX.1 KontextをAPIで呼び出してImage-to-Imageで画像を変換してみた
- 画像編集の革命:Black Forest Labsの「FLUX.1-Kontext-dev」を徹底解説 - 技術、使い方からライセンスまで
- FLUX.1 Kontext [dev]、スモールビジネスの画像編集を革新!コスト削減と表現力向上に貢献
FLUX.1 KontextをComfyUIで使う例
- 【開発者向け】FLUX.1 Kontext Dev Native ガイド: ComfyUIでの使用手順
- 【FLUX.1 Kontext】ComfyUIで簡単に利用可能!
- FLUX.1 Kontext で画像を生成する
- 【ComfyUI】FLUX.1 Kontext Devを使う方法
- 【革命】ついにきた!FLUX.1 Kontextで画像生成がもっと便利に!ComfyUIを使ってローカルで動かそう
- 【衝撃】LoRAの常識、今日で変わります。Flux Kontextで1枚の画像が"20枚"に増える、魔法のような全自動データセット生成術をご紹介します✨【ComfyUI】
- FLUX1 Kontext(dev)のプロンプトを試してみる!1枚目