この記事ではFLUX.1 Toolsの一つであるFLUX.1 fill devモデルによって画像の一部を修正する方法について説明します。
はじめに
この前の記事ではComfyUIにおけるFLUX.1の使い方の基本について書きました。
今回はその続きとして、よく使われる機能の一つであるインペイントについて説明します。
インペイントについて以前Stable Diffusionでの使い方を説明する記事を書いたことがあります。
Stable Diffusionのインペイントと比べたらやはりFLUX.1の方がうまくできています。特に手の修正とか今までいつも悩んでいた問題です。
FLUX.1の中でもインペイントする方法は色々ありますが、今回紹介するのは開発者であるBlack Forest Labsによって2024年11月に公開されたFLUX.1 Toolsの中のFLUX.1 fillというモデルを使う方法です。
FLUX.1 fillにはAPIでしか使えない有料版のproモデルと、自由にモデルをダウンロードしてローカルで動かせるdevモデルがあります。この記事で説明するのはFLUX.1 fill devの方のみです。
基本的なワークフロー
まず基本のFLUX.1のtxt2imgと同様に、インペイントのワークフローもテンプレートにあります。
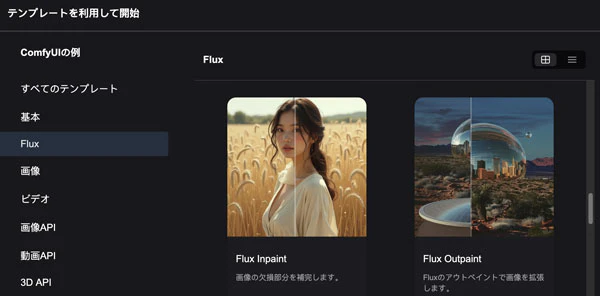
これを選んだら、必要なモデルが表示されます。

基本的にtxt2imgの時と同じなので説明は省略しますが、今回は特にflux1-fill-dev.safetensorsが必要です。
このモデルをダウンロードするのにhuggingfaceにログインする必要があるので、配布サイトにアクセスして手動でダウンロードする必要があります。
又メモリーを節約するためにfp8もおすすめです。私もこれを使っています。試して比べてみたところ違いを感じません。
その他にもGGUFの軽量化版があります。
nunchaku版もあります。これを使ったら爆速になりますね。
テンプレートがロードされたらこんなワークフローは表示されるでしょう。
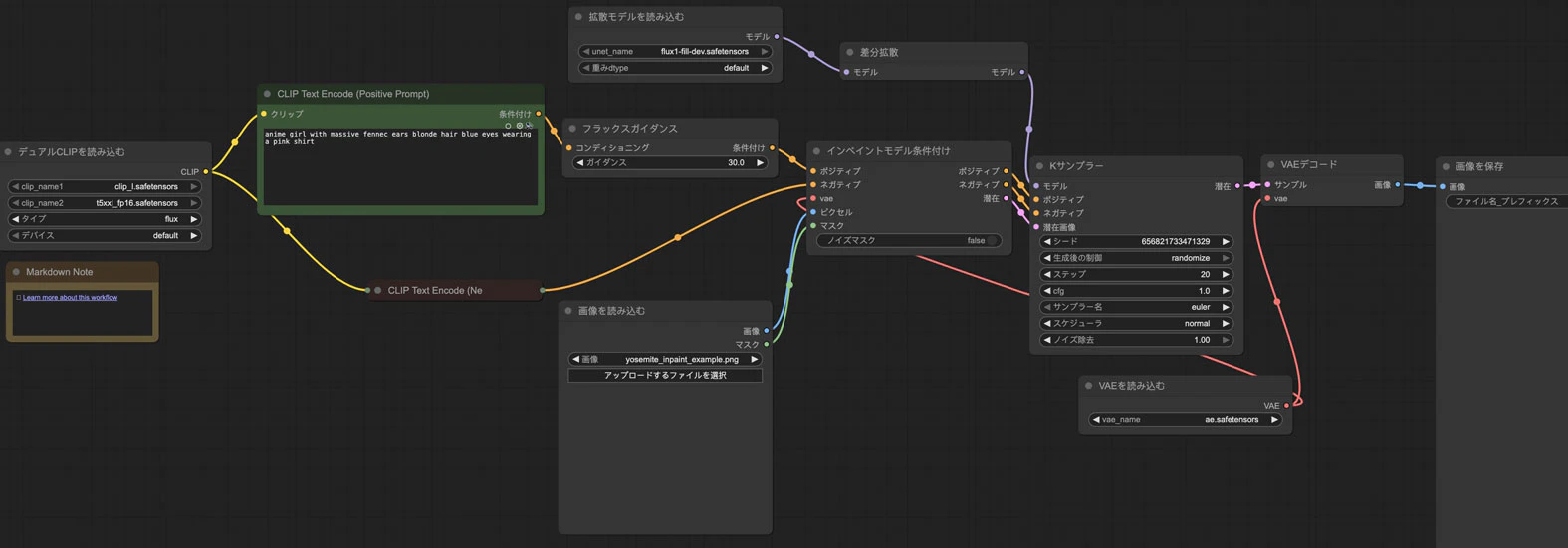
そのワークフローを私なりにアレンジしたらこうなります。

ワークフローのAPI用jsonはこうなります。
{
"1": {
"inputs": {
"unet_name": "flux1-fill-dev-fp8.safetensors",
"weight_dtype": "default"
},
"class_type": "UNETLoader"
},
"2": {
"inputs": {
"clip_name1": "clip_l.safetensors",
"clip_name2": "t5xxl_fp8_e4m3fn_scaled.safetensors",
"type": "flux",
"device": "default"
},
"class_type": "DualCLIPLoader"
},
"3": {
"inputs": {
"vae_name": "ae.safetensors"
},
"class_type": "VAELoader"
},
"4": {
"class_type": "LoadImage"
},
"5": {
"inputs": {
"model": ["1", 0]
},
"class_type": "DifferentialDiffusion"
},
"6": {
"inputs": {
"from_translate": "auto",
"to_translate": "english",
"add_proxies": false,
"proxies": "",
"auth_data": "",
"service": "GoogleTranslator",
"text": "",
"Show proxy": "proxy_hide",
"Show authorization": "authorization_hide",
"clip": ["2", 0]
},
"class_type": "DeepTranslatorCLIPTextEncodeNode"
},
"7": {
"inputs": {
"guidance": 30,
"conditioning": ["6", 0]
},
"class_type": "FluxGuidance"
},
"8": {
"inputs": {
"noise_mask": false,
"positive": ["7", 0],
"negative": ["6", 0],
"vae": ["3", 0],
"pixels": ["4", 0],
"mask": ["4", 1]
},
"class_type": "InpaintModelConditioning"
},
"9": {
"inputs": {
"seed": 123456789,
"steps": 20,
"cfg": 1,
"sampler_name": "euler",
"scheduler": "normal",
"denoise": 1,
"model": ["5", 0],
"positive": ["8", 0],
"negative": ["8", 1],
"latent_image": ["8", 2]
},
"class_type": "KSampler"
},
"10": {
"inputs": {
"samples": ["9", 0],
"vae": ["3", 0]
},
"class_type": "VAEDecode"
},
"11": {
"inputs": {
"filename_prefix": "ComfyUI",
"file_type": "JPEG",
"remove_metadata": false,
"images": ["10", 0]
},
"class_type": "SaveImagePlus"
}
}
入力としてUNETLoader(拡散モデルを読み込む)とDualCLIPLoader(デュアルCLIPを読み込む)とVAELoader(VAEを読み込む)の3つのノードを使うのはtxt2imgの時と同じですが、モデルはFLUX.1 fill devのモデルになります。又ここでLoadImage(画像を読み込む)ノードで画像入力画像を読み込みます。
ここで例としてこの画像を使ってみたいと思います。これはshuttle 3 diffusionモデルによって生成されたものです。

アップロードして右クリックして、Open in MaskEditorを選びます。

このようにマスクを塗ります。
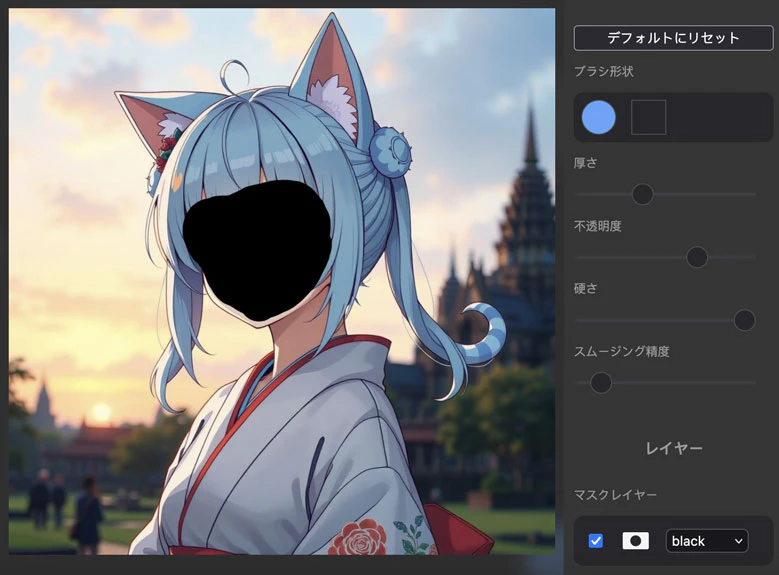
プロンプトはただ簡単に「笑う」と書きます。そして実行したらこんな結果ができます。

よくできていますね。ただし目の色が変わるのは仕方ないことですが、プロンプトの中で色の指定したら好きな色にできます。書いていないから勝手に適当決められます。
又「怒る」と入力したらこうなります。

怒る表情はあまり薄い気がします。何度も試したところどうやら感情の表現は苦手みたいです。これも残念な点だと思います。
修正後の劣化とその対策
以上のワークフローでいい感じに画像修正できるように見えましたが、実はこの修正した画像をよく見たら、マスクの外でも少し元の画像と違うとわかります。ぱっと見してわからないような小さな違いですが、拡大してよく見たらノイズが少し感じられるでしょう。
つまり修正するたびに全体的に劣化が発生します。一回だけ修正したくらいでまだ大丈夫かもしれませんが、何回も繰り返して修正したらぱっと見してもわかるくらい劣化が目立つようになります。
これは画像がVAEによって潜在空間に変換してからもう一度戻すという過程の中で発生したノイズのせいです。VAEを通る以上、これは避けられない問題です。Stable Diffusionもそうですが、FLUX.1の方はこの劣化が目立つます。
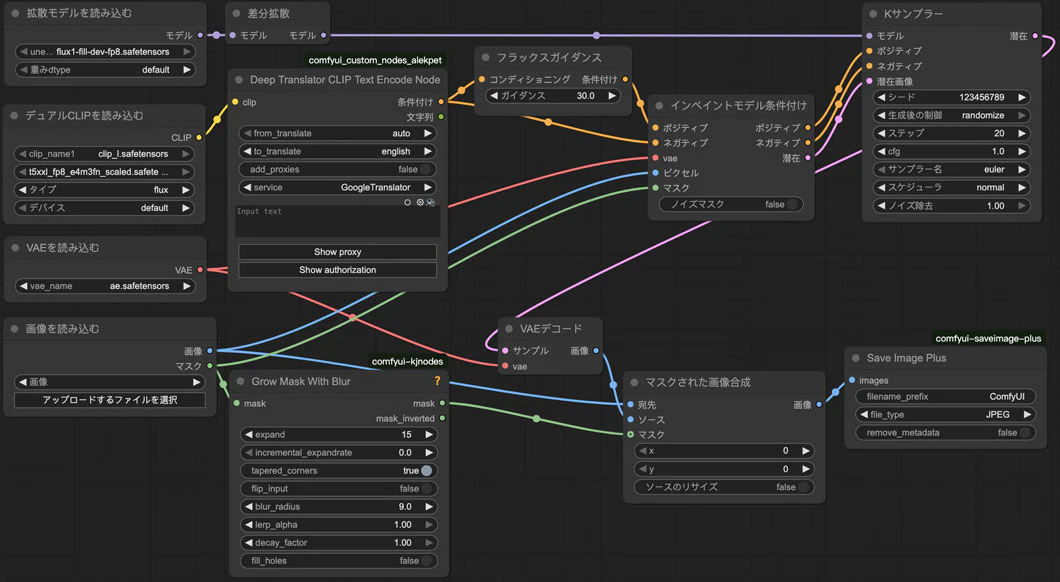
マスク以外の部分の劣化を防ぐために、元の画像を使って合成するしかないでしょう。そう考えて私は対策のためのワークフローを作りました。
このようにワークフローを改善します。
{
"1": {
"inputs": {
"unet_name": "flux1-fill-dev-fp8.safetensors",
"weight_dtype": "default"
},
"class_type": "UNETLoader"
},
"2": {
"inputs": {
"clip_name1": "clip_l.safetensors",
"clip_name2": "t5xxl_fp8_e4m3fn_scaled.safetensors",
"type": "flux",
"device": "default"
},
"class_type": "DualCLIPLoader"
},
"3": {
"inputs": {
"vae_name": "ae.safetensors"
},
"class_type": "VAELoader"
},
"4": {
"class_type": "LoadImage"
},
"5": {
"inputs": {
"model": ["1", 0]
},
"class_type": "DifferentialDiffusion"
},
"6": {
"inputs": {
"from_translate": "auto",
"to_translate": "english",
"add_proxies": false,
"proxies": "",
"auth_data": "",
"service": "GoogleTranslator",
"text": "",
"Show proxy": "proxy_hide",
"Show authorization": "authorization_hide",
"clip": ["2", 0]
},
"class_type": "DeepTranslatorCLIPTextEncodeNode"
},
"7": {
"inputs": {
"expand": 15,
"incremental_expandrate": 0,
"tapered_corners": true,
"flip_input": false,
"blur_radius": 9,
"lerp_alpha": 1,
"decay_factor": 1,
"fill_holes": false,
"mask": ["4", 1]
},
"class_type": "GrowMaskWithBlur"
},
"8": {
"inputs": {
"guidance": 30,
"conditioning": ["6", 0]
},
"class_type": "FluxGuidance"
},
"9": {
"inputs": {
"noise_mask": false,
"positive": ["8", 0],
"negative": ["6", 0],
"vae": ["3", 0],
"pixels": ["4", 0],
"mask": ["4", 1]
},
"class_type": "InpaintModelConditioning"
},
"10": {
"inputs": {
"seed": 123456789,
"steps": 20,
"cfg": 1,
"sampler_name": "euler",
"scheduler": "normal",
"denoise": 1,
"model": ["5", 0],
"positive": ["9", 0],
"negative": ["9", 1],
"latent_image": ["9", 2]
},
"class_type": "KSampler"
},
"11": {
"inputs": {
"samples": ["10", 0],
"vae": ["3", 0]
},
"class_type": "VAEDecode"
},
"12": {
"inputs": {
"x": 0,
"y": 0,
"resize_source": false,
"destination": ["4", 0],
"source": ["11", 0],
"mask": ["7", 0]
},
"class_type": "ImageCompositeMasked"
},
"13": {
"inputs": {
"filename_prefix": "ComfyUI",
"file_type": "JPEG",
"remove_metadata": false,
"images": ["12", 0]
},
"class_type": "SaveImagePlus"
}
}
追加したノードはGrowMaskWithBlurとImageCompositeMasked(マスクされた画像合成)の2つしかないです。
GrowMaskWithBlurノードを使うにはComfyUI-KJNodesパッケージをインストールする必要があります。
https://github.com/kijai/ComfyUI-KJNodes
こうすることでマスクの外は完全に元画像と同じのままにできます。
ただしマスクの境界の辺りは違和感を感じる可能性があります。そこでGrowMaskWithBlurノードのexpandとblur_radiusを適切に調整することをおすすめします。
InpaintModelConditioningノードのnoise_maskとDifferentialDiffusionの話
InpaintModelConditioning(インペイントモデル条件付け)ノードの中にnoise_mask(ノイズマスク)という入力がありますね。
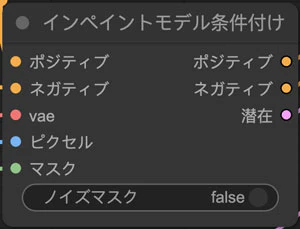
説明を読んでみたら「潜在にマスクを追加し、サンプリングがマスク内のみ行われるようにします。モデルによっては結果が改善されるが、完全に壊れる可能性があります」と書いてあります。テンプレートではfalseになっているので、みんなも殆どfalseのまま使っていると思います。基本的にこれでいいと思いますが、どのような効果があるかきになったので試した見ました。
そしてtrueにして試した結果、falseと比べてtrueの方は結果が悪いのは確かです。特にマスクの境界のところは違和感が生じます。
ただしマスクの外の劣化はtrueの場合はfalseの場合より控えめに見えます。マスク以外の部分をできるだけ元のままにしたい場合はtrueにした方がいいかもしれません。しかし肝心のマスクの部分は逆に悪化するのであまり意味ないかもしれません。それに劣化が少なくなったとはいえ完全にないわけではないのです。上述の方法の方が完全に劣化を阻止できるはずなので、その方がいいでしょう。
又ワークフローの中でDifferentialDiffusion(差分拡散)というノードがありますね。

このノードはただモデルが通るだけで特に調整することはないが、なんのためにあるか気になったので調べてみました。
このノードは拡散モデルのノイズ除去過程を改善するためにあると説明されています。しかし私が試したところ、noise_maskがfalseのままの場合このDifferentialDiffusionノードを外しても結果は全く違いがありません。
noise_maskがtrueの場合は確かに微妙に違いが見えますが、普段はfalseを使うので、結局このノードの挿入の有無で結果が変わることはないと考えられます。
手の修正
画像生成AIにとって、手を描くことは長い間悩んでいる課題ですね。その辺FLUX.1はかなりよくできて、手がおかしくなる確率はStable Diffusionとかに比べて減少していて、自然な手が作りやすくなってきました。そしてFLUX.1 fillでも手を描くことが得意です。
例としてこの画像を使います。

この画像もshuttle 3 diffusionによって生成されたもので可愛く見えますが、残念なところがあります。指は3本しかないのです!そして手は不自然に看板に食い込んでいるように見えます。
これを修正するためにこのようにマスクを塗って、プロンプトに「看板を持つ手」と書きます。
結果きこうです。

ただしうまくいかない場合も多いです。この画像も実は何回も試してその中から一番いい結果を選んだのです。手はAIにとって難しい課題であることに変わりはないが、Stable Diffusionよりうまくいく確率が高いのは明らかです。
又プロンプトは「手」と書かなくてもうまくいく可能性がありますが、ちゃんと書いた方がうまく綺麗な手ができる確率は高いです。
アウトペイント
FLUX.1のテンプレートの中でFlux Inpaintの他にFlux Outpaintがありますね。
アウトペイントは基本的にただ画像にパッティングの部分を作ってそれをマスクにするだけで、本質はインペイントと同じです。
詳しい説明は省きますが、劣化対策も含めてワークフローを組んでみたらこのようになります。
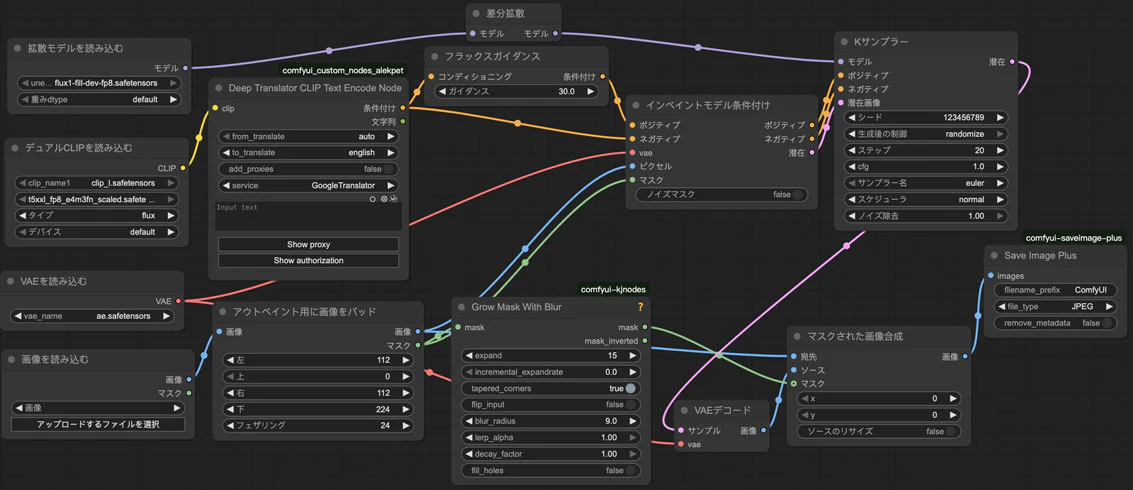
ここでImagePadForOutpaint(アウトペイント用に画像をパッド)ノードで各方向で拡張したいピクセルを指定します。
{
"1": {
"inputs": {
"unet_name": "flux1-fill-dev-fp8.safetensors",
"weight_dtype": "default"
},
"class_type": "UNETLoader"
},
"2": {
"inputs": {
"clip_name1": "clip_l.safetensors",
"clip_name2": "t5xxl_fp8_e4m3fn_scaled.safetensors",
"type": "flux",
"device": "default"
},
"class_type": "DualCLIPLoader"
},
"3": {
"inputs": {
"vae_name": "ae.safetensors"
},
"class_type": "VAELoader"
},
"4": {
"class_type": "LoadImage"
},
"5": {
"inputs": {
"model": ["1", 0]
},
"class_type": "DifferentialDiffusion"
},
"6": {
"inputs": {
"from_translate": "auto",
"to_translate": "english",
"add_proxies": false,
"proxies": "",
"auth_data": "",
"service": "GoogleTranslator",
"text": "",
"Show proxy": "proxy_hide",
"Show authorization": "authorization_hide",
"clip": ["2", 0]
},
"class_type": "DeepTranslatorCLIPTextEncodeNode"
},
"7": {
"inputs": {
"left": 112,
"top": 0,
"right": 112,
"bottom": 224,
"feathering": 24,
"image": ["4", 0]
},
"class_type": "ImagePadForOutpaint"
},
"8": {
"inputs": {
"guidance": 30,
"conditioning": ["6", 0]
},
"class_type": "FluxGuidance"
},
"9": {
"inputs": {
"expand": 15,
"incremental_expandrate": 0,
"tapered_corners": true,
"flip_input": false,
"blur_radius": 9,
"lerp_alpha": 1,
"decay_factor": 1,
"fill_holes": false,
"mask": ["7", 1]
},
"class_type": "GrowMaskWithBlur"
},
"10": {
"inputs": {
"noise_mask": false,
"positive": ["8", 0],
"negative": ["6", 0],
"vae": ["3", 0],
"pixels": ["7", 0],
"mask": ["7", 1]
},
"class_type": "InpaintModelConditioning"
},
"11": {
"inputs": {
"seed": 123456789,
"steps": 20,
"cfg": 1,
"sampler_name": "euler",
"scheduler": "normal",
"denoise": 1,
"model": ["5", 0],
"positive": ["10", 0],
"negative": ["10", 1],
"latent_image": ["10", 2]
},
"class_type": "KSampler"
},
"12": {
"inputs": {
"samples": ["11", 0],
"vae": ["3", 0]
},
"class_type": "VAEDecode"
},
"13": {
"inputs": {
"x": 0,
"y": 0,
"resize_source": false,
"destination": ["7", 0],
"source": ["12", 0],
"mask": ["9", 0]
},
"class_type": "ImageCompositeMasked"
},
"14": {
"inputs": {
"filename_prefix": "ComfyUI",
"file_type": "JPEG",
"remove_metadata": false,
"images": ["13", 0]
},
"class_type": "SaveImagePlus"
}
}
今回はこの画像を例に使います。これはblue_pencil-flux1によって生成されたものです。サイズは800×800px。

そしてImagePadForOutpaintのleft(左)とright(右)を112に、bottom(下)を224にして、プロンプトをここではとりあえず入れないことにします。
生成結果。

花畑と服はうまく拡張されていますね。
終わりに
以上FLUX.1 fill devの使い方の説明でした。他にもFLUX.1はまだ面白い機能を持っています。
特にマスクを作らなくても言葉だけで修正したい部分を指定できるFLUX.1 Kontextは便利です。これについて次の記事で紹介したいと思います。
* この部分は2025年8月30日に追記
FLUX.1 Kontextの記事を投稿しました。これを使うことでFLUX.1 fillよりも画像編集は楽になります。