はじめに
プログラミング未経験者ですが、このたびAidemyさんの講習を受講する機会があり、課題として機械学習を使ったアプリとブログの作成をすることになりました。同じくAidemyさんの課題としてCNN(Convolutional Neural Network)を用いた野菜識別に取り組まれた方のブログを拝見し、私はCNNでキノコを判別する試みを行いました。野山に生えるキノコを見つけたとき、食べられるのか食べられないのか判別できるアプリがあれば…と思ったのがきっかけです。至らぬ点ばかりと思いますが、ご容赦下さい。
参考ブログ:
CNN画像認識で 野菜識別
https://qiita.com/a_tonbo/items/0696fd3fcbdeed4e64cf
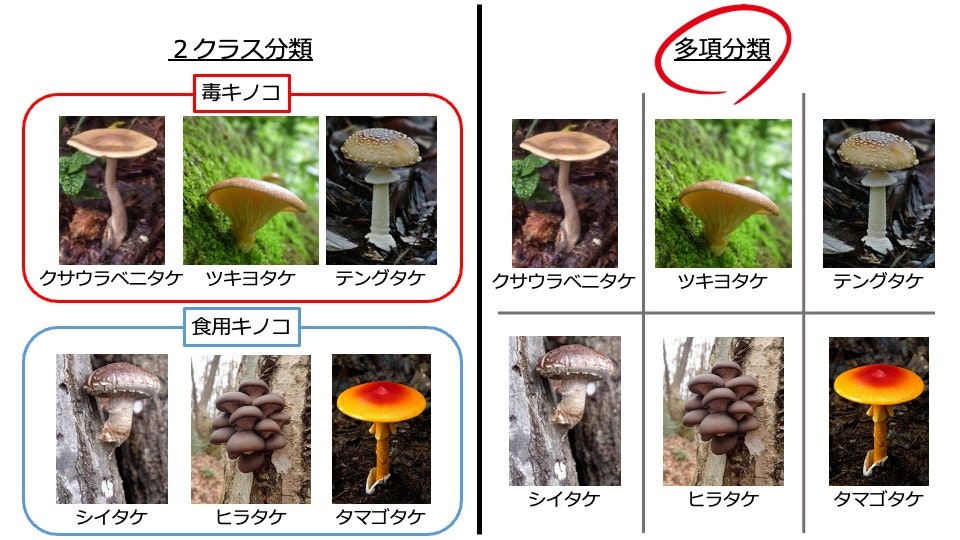
1. 学習対象のキノコ
毒キノコ:クサウラベニタケ・ツキヨタケ・テングタケ
食用キノコ:シイタケ・ヒラタケ・タマゴタケ
厚生労働省のホームページで、食用と間違えやすいため注意喚起されている毒キノコのクサウラベニタケとツキヨタケを選び、それと間違えやすいシイタケとヒラタケを対象に加えました。また、見るからに毒キノコであるテングタケと、それにそっくりですが食べられるタマゴタケも加えてみました。
2. 使用するデータとクラス分類
インターネットから学習対象のキノコ名にヒットするjpeg画像を収集して使用しました。
分類としては、毒キノコと食用キノコの2クラス分類とするか、キノコ名ごとの多項分類とするか迷いましたが、今回はキノコ名ごとの多項分類(6クラス)としました。
3. 実行環境
- Google Colaboratory
- Visual Studio Code
4. 全コード
以下が学習モデル作成の全コードです。
コードを見る
import os #osモジュール(os機能がpythonで扱えるようにする)
import numpy as np #python拡張モジュール
import tensorflow
from PIL import Image #画像処理用
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt #グラフ可視化
from tensorflow.keras.utils import to_categorical #正解ラベルをone-hotベクトルで求める
from tensorflow.keras.layers import Activation, Conv2D, Dense, Dropout, Flatten, Input, MaxPooling2D, BatchNormalization #活性化関数、畳み込み層、全結合層、過学習予防、平滑化、インプット、Maxプーリング、バッチノーマライゼーション
from tensorflow.keras.preprocessing.image import ImageDataGenerator, load_img, array_to_img
from tensorflow.keras.applications.vgg16 import VGG16 #学習済モデル
from tensorflow.keras.models import Model, Sequential #線形モデル
from tensorflow.keras import optimizers #最適化関数
from google.colab import files#モデルの保存
#画像の格納
drive_tsukiyotake = "/content/drive/MyDrive/Colab Notebooks/images/ツキヨタケ/"
drive_hiratake = "/content/drive/MyDrive/Colab Notebooks/images/ヒラタケ/"
drive_siitake = "/content/drive/MyDrive/Colab Notebooks/images/シイタケ/"
drive_kusaurabenitake = "/content/drive/MyDrive/Colab Notebooks/images/クサウラベニタケ/"
drive_tamagotake = "/content/drive/MyDrive/Colab Notebooks/images/タマゴタケ/"
drive_tengutake = "/content/drive/MyDrive/Colab Notebooks/images/テングタケ/"
image_size = 150
#os.listdir() で指定したファイルを取得
path_tsukiyotake = [filename for filename in os.listdir(drive_tsukiyotake) if not filename.startswith('.')]
path_hiratake = [filename for filename in os.listdir(drive_hiratake) if not filename.startswith('.')]
path_siitake = [filename for filename in os.listdir(drive_siitake) if not filename.startswith('.')]
path_kusaurabenitake = [filename for filename in os.listdir(drive_kusaurabenitake) if not filename.startswith('.')]
path_tamagotake = [filename for filename in os.listdir(drive_tamagotake) if not filename.startswith('.')]
path_tengutake = [filename for filename in os.listdir(drive_tengutake) if not filename.startswith('.')]
#画像の中央をトリミングする関数
def crop_center(img, crop_width, crop_height):
img_width, img_height = img.size
return img.crop(((img_width - crop_width) // 2,(img_height - crop_height) // 2,(img_width + crop_width) // 2,(img_height + crop_height) // 2))
#画像を格納するリスト作成
img_tsukiyotake = []
img_hiratake = []
img_siitake = []
img_kusaurabenitake = []
img_tamagotake = []
img_tengutake = []
for i in range(len(path_tsukiyotake)):
#print(drive_tsukiyotake+ path_tsukiyotake[i])
img = Image.open(drive_tsukiyotake+ path_tsukiyotake[i])#画像を読み込む
img_crop_square = crop_center(img, min(img.size), min(img.size))#短辺を基準に正方形にトリミングする
img_croped = img_crop_square.resize((image_size,image_size))#画像をリサイズする
img_tsukiyotake.append(np.asarray(img_croped))#画像配列に画像を加える
for i in range(len(path_hiratake)):
img = Image.open(drive_hiratake+ path_hiratake[i])#画像を読み込む
img_crop_square = crop_center(img, min(img.size), min(img.size))#短辺を基準に正方形にトリミングする
img_croped = img_crop_square.resize((image_size,image_size))#画像をリサイズする
img_hiratake.append(np.asarray(img_croped))#画像配列に画像を加える
for i in range(len(path_siitake)):
img = Image.open(drive_siitake+ path_siitake[i])#画像を読み込む
img_crop_square = crop_center(img, min(img.size), min(img.size))#短辺を基準に正方形にトリミングする
img_croped = img_crop_square.resize((image_size,image_size))#画像をリサイズする
img_siitake.append(np.asarray(img_croped))
for i in range(len(path_kusaurabenitake)):
img = Image.open(drive_kusaurabenitake+ path_kusaurabenitake[i])#画像を読み込む
img_crop_square = crop_center(img, min(img.size), min(img.size))#短辺を基準に正方形にトリミングする
img_croped = img_crop_square.resize((image_size,image_size))#画像をリサイズする
img_kusaurabenitake.append(np.asarray(img_croped))#画像配列に画像を加える
for i in range(len(path_tamagotake)):
img = Image.open(drive_tamagotake+ path_tamagotake[i])#画像を読み込む
img_crop_square = crop_center(img, min(img.size), min(img.size))#短辺を基準に正方形にトリミングする
img_croped = img_crop_square.resize((image_size,image_size))#画像をリサイズする
img_tamagotake.append(np.asarray(img_croped))#画像配列に画像を加える
for i in range(len(path_tengutake)):
img = Image.open(drive_tengutake+ path_tengutake[i])#画像を読み込む
img_crop_square = crop_center(img, min(img.size), min(img.size))#短辺を基準に正方形にトリミングする
img_croped = img_crop_square.resize((image_size,image_size))#画像をリサイズする
img_tengutake.append(np.asarray(img_croped))#画像配列に画像を加える
#np.arrayでXに学習画像を作成
X = np.array(img_tsukiyotake + img_hiratake + img_siitake + img_kusaurabenitake + img_tamagotake + img_tengutake)
#yに正解ラベルを作成
y = np.array([0]*len(img_tsukiyotake) + [1]*len(img_hiratake) + [2]*len(img_siitake) + [3]*len(img_kusaurabenitake) + [4]*len(img_tamagotake) + [5]*len(img_tengutake))
label_num = list(set(y))
# トレーニングデータとテストデータの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
#正解ラベルをone-hotベクトルで求める
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# vgg16のインスタンスの生成
input_tensor = Input(shape=(image_size,image_size, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
#モデルの定義
#転移学習の自作モデルとして下記のコードを作成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(1024, activation="relu"))
top_model.add(BatchNormalization())
top_model.add(Dropout(0.5))
top_model.add(Dense(512, activation='relu'))
top_model.add(BatchNormalization())
top_model.add(Dropout(0.5))
top_model.add(Dense(128, activation='relu'))
top_model.add(BatchNormalization())
top_model.add(Dropout(0.5))
top_model.add(Dense(32, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(6, activation='softmax'))
#vggと自作のtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
#vgg16による特徴抽出部分の重みを19層までに固定(以降に新しい層(top_model)が追加)
for layer in model.layers[:19]:
layer.trainable = False
#訓練課程の設定
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(learning_rate=1e-4, momentum=0.9),
metrics=['accuracy'])
#Data Augmentation
#学習用のImageDataGeneratorクラスの生成
train_datagen = ImageDataGenerator(samplewise_center=True,
samplewise_std_normalization=True, #画像を標準化
# width_shift_range=0.2, #ランダムに水平方向に平行移動する、画像の横幅に対する割合
# height_shift_range=0.2, #ランダムに垂直方向に平行移動する、画像の横幅に対する割合
# zoom_range=0.2, # ランダムにズーム
horizontal_flip=True, # 水平反転
rotation_range=45, # ランダムに回転
vertical_flip=True) # 垂直反転
#テスト用のImageDataGeneratorクラスの生成
test_datagen = ImageDataGenerator(samplewise_center=True,
samplewise_std_normalization=True) #画像を標準化
#学習用バッチの生成
train_generator = train_datagen.flow(X_train, y_train, batch_size=32, seed=0)
#テスト用のバッチの生成
test_generator = test_datagen.flow(X_test, y_test, batch_size=32, seed=0)
# 学習の実行
#グラフ(可視化)用コード
history = model.fit(train_generator, steps_per_epoch=len(X_train)/32, epochs=200, verbose=1, validation_data=test_generator)
score = model.evaluate(test_generator, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
#acc, val_accのプロット
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
#モデルを保存
#resultsディレクトリを作成
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 重みを保存
model.save(os.path.join(result_dir, 'model.h5'))
# データの可視化(検証データの先頭の10枚)
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(X_test[i])
plt.suptitle("10 images of test data",fontsize=20)
plt.show()
#予測(検証データの先頭の10枚)
pred = np.argmax(model.predict(X_test[0:10]), axis=1)
print(pred)
5. 画像収集
スクレイピングを行い、インターネットから検索単語にヒットする画像を収集します。コードは以下のサイトを参考にさせて頂きました。
参考サイト:
【だれでもできる】プログラミングが未経験でも大丈夫。Webから大量画像を収集する方法をわかりやすく解説します。(YouTube動画)
https://www.youtube.com/watch?v=hRB104ik6pQ
画像データをキーワード検索で効率的に収集する方法(Python「icrawler」のBing検索)
https://www.atmarkit.co.jp/ait/articles/2010/28/news018.html
# icrawlerパッケージのインストール
!pip install icrawler
# Bing用クローラーのモジュールをインポート
from icrawler.builtin import BingImageCrawler
# 検索キノコ名のリストリスト
search_words = ["ツキヨタケ", "ヒラタケ", "シイタケ", "クサウラベニタケ", "タマゴタケ", "テングタケ"]
# Bing用クローラーの生成
for i in search_words:
bing_crawler = BingImageCrawler(
downloader_threads=4, # ダウンローダーのスレッド数
storage={'root_dir': i }) # ダウンロード先のディレクトリ名
bing_crawler.crawl(
keyword = i,
max_num=1000) # ダウンロードする画像の最大枚数
目的のキノコの名前を格納したリストを作り、for文を使ってキノコの名前のフォルダ別に画像がダウンロードされるようにしました。ダウンロードする画像数は、思い切って最大の1000枚としました。
6. 画像処理
1. 選別
スクレイピングでダウンロードされた画像をローカルに保存し、写真の選別を行いました。検索名と異なるキノコの画像が想像以上に多数混入しており、選別後の画像数は1つのキノコあたり145〜271枚、6種の合計で1302枚になりました。
最大の問題は、私自身が各キノコを正しく判別できていない可能性が高いことです…。
2. 画像のインポート
Googleドライブをマウントし、選別後の画像を保存したGoogleドライブ上のフォルダを指定します。
その後、ファイルのリストを取得します。
# Googleドライブをマウント
from google.colab import drive
drive.mount('/content/drive')
#画像の格納
drive_tsukiyotake = "/content/drive/MyDrive/Colab Notebooks/images/ツキヨタケ/"
drive_hiratake = "/content/drive/MyDrive/Colab Notebooks/images/ヒラタケ/"
drive_siitake = "/content/drive/MyDrive/Colab Notebooks/images/シイタケ/"
drive_kusaurabenitake = "/content/drive/MyDrive/Colab Notebooks/images/クサウラベニタケ/"
drive_tamagotake = "/content/drive/MyDrive/Colab Notebooks/images/タマゴタケ/"
drive_tengutake = "/content/drive/MyDrive/Colab Notebooks/images/テングタケ/"
image_size = 150
#os.listdir() で指定したファイルを取得
path_tsukiyotake = [filename for filename in os.listdir(drive_tsukiyotake) if not filename.startswith('.')]
path_hiratake = [filename for filename in os.listdir(drive_hiratake) if not filename.startswith('.')]
path_siitake = [filename for filename in os.listdir(drive_siitake) if not filename.startswith('.')]
path_kusaurabenitake = [filename for filename in os.listdir(drive_kusaurabenitake) if not filename.startswith('.')]
path_tamagotake = [filename for filename in os.listdir(drive_tamagotake) if not filename.startswith('.')]
path_tengutake = [filename for filename in os.listdir(drive_tengutake) if not filename.startswith('.')]
3. 切り抜きと画像リストの作成
元の画像が縦長・横長のものが多く、単純に正方形にリサイズすると正しく学習が行われないのではと考え、画像の中央を正方形にトリミングする関数を作成し、画像を格納するリスト作成時に処理するようにしました。その後、目的の画像サイズ(今回は150x150ピクセル)にリサイズしています。
参考サイト:
pythonで生きていく(「それ、pythonでできるよ」-画像の切り出し-)
https://python-climbing.com/image-crop-python/
#画像の中央をトリミングする関数
def crop_center(img, crop_width, crop_height):
img_width, img_height = img.size
return img.crop(((img_width - crop_width) // 2,(img_height - crop_height) // 2,(img_width + crop_width) // 2,(img_height + crop_height) // 2))
image_size = 150
#画像を格納するリスト作成
img_tsukiyotake = []
for i in range(len(path_tsukiyotake)):
#print(drive_tsukiyotake+ path_tsukiyotake[i])
img = Image.open(drive_tsukiyotake+ path_tsukiyotake[i])#画像を読み込む
img_crop_square = crop_center(img, min(img.size), min(img.size))#短辺を基準に正方形にトリミングする
img_croped = img_crop_square.resize((image_size,image_size))#画像をリサイズする
img_tsukiyotake.append(np.asarray(img_croped))#画像配列に画像を加える
4. 画像のラベル付け
キノコ別になっている画像リストをXという一つのリストにまとめ、キノコ名ごとに番号を割り当てます。正解ラベルはone-hot表現(0または1の文字を並べたベクトル)に変換します。学習データとテストデータの分割にはscikit-learnのmodel_selectionモジュールのtrain_test_split()を使用し、学習データ:テストデータ=8:2で分割しました。
#np.arrayでXに学習画像を作成
X = np.array(img_tsukiyotake + img_hiratake + img_siitake + img_kusaurabenitake + img_tamagotake + img_tengutake)
#yに正解ラベルを作成
y = np.array([0]*len(img_tsukiyotake) + [1]*len(img_hiratake) + [2]*len(img_siitake) + [3]*len(img_kusaurabenitake) + [4]*len(img_tamagotake) + [5]*len(img_tengutake))
label_num = list(set(y))
# 学習データとテストデータの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
#正解ラベルをone-hotベクトルで求める
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
7. モデル生成
講習で教わったVGG16を使った転移学習を行いました。
まずvgg16のインスタンスを作成します。
# vgg16のインスタンスの生成
input_tensor = Input(shape=(image_size,image_size, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
自作モデルをtop_modelとして作成し、vgg16モデルと連結させます。
#モデルの定義
#転移学習の自作モデルとして下記のコードを作成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(1024, activation="relu"))
top_model.add(BatchNormalization())
top_model.add(Dropout(0.5))
top_model.add(Dense(512, activation='relu'))
top_model.add(BatchNormalization())
top_model.add(Dropout(0.5))
top_model.add(Dense(128, activation='relu'))
top_model.add(BatchNormalization())
top_model.add(Dropout(0.5))
top_model.add(Dense(32, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(6, activation='softmax'))
#vggと自作のtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
vgg16による特徴抽出部分の重みは更新されると崩れてしまうということで、19層までに固定します。
#vgg16による特徴抽出部分の重みを19層までに固定(以降に新しい層(top_model)が追加)
for layer in model.layers[:19]:
layer.trainable = False
転移学習をする場合の最適化はSGDで行うことがお勧めということで、そのようにコンパイルします。
#訓練課程の設定
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(learning_rate=1e-4, momentum=0.9),
metrics=['accuracy'])
8. 学習画像の水増し(Data Augmentation)
主に過学習を防止する為に、TensorFlow の ImageDataGenerator を使って学習用画像の水増しを行いました。
以下の参考サイトをもとにオンライン拡張を行い、元々の学習用データを水増しすることなしに、ミニバッチごとにランダムな画像が生成されるようにしていますので、学習用画像の枚数自体は1041枚(1302枚の8割)です。
参考サイト:
codExa データ拡張(Data Augmentation)徹底入門!Pythonとkerasでデータ拡張を実装しよう
https://www.codexa.net/data_augmentation_python_keras/
#Data Augmentation
#学習用のImageDataGeneratorクラスの生成
train_datagen = ImageDataGenerator(samplewise_center=True,
samplewise_std_normalization=True, #画像を標準化
# width_shift_range=0.2, #ランダムに水平方向に平行移動する、画像の横幅に対する割合
# height_shift_range=0.2, #ランダムに垂直方向に平行移動する、画像の横幅に対する割合
# zoom_range=0.2, # ランダムにズーム
horizontal_flip=True, # 水平反転
rotation_range=45, # ランダムに回転
vertical_flip=True) # 垂直反転
#テスト用のImageDataGeneratorクラスの生成
test_datagen = ImageDataGenerator(samplewise_center=True,
samplewise_std_normalization=True) #画像を標準化
学習用画像は画像の水増しと標準化を行い、テスト用画像は標準化のみ行います。標準化は、個々の特徴を平均0、分散1にすることで、特徴ごとのデータの分布を近づける手法です。ランダムの水平移動・垂直移動・ズームを行ったところ、むしろ精度が落ちてしまったので、今回はコメントアウトして機能をオフしました。
9. 学習の実行と可視化
学習用バッチとテスト用バッチを作成し、学習と検証を行います。検証結果は正答率(accuracy)で評価し、エポックごとの推移をグラフ化します。
#学習用バッチの生成
train_generator = train_datagen.flow(X_train, y_train, batch_size=32, seed=0)
#テスト用のバッチの生成
test_generator = test_datagen.flow(X_test, y_test, batch_size=32, seed=0)
# 学習の実行
#グラフ(可視化)用コード
history = model.fit(train_generator, steps_per_epoch=len(X_train)/32, epochs=200, verbose=1, validation_data=test_generator)
score = model.evaluate(test_generator, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
#acc, val_accのプロット
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
実際にどの画像に対してどのように判定が行われたか、以下のコードで10枚分を表示させて確認しました。
# データの可視化(検証データの先頭の10枚)
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(X_test[i])
plt.suptitle("10 images of test data",fontsize=20)
plt.show()
#予測(検証データの先頭の10枚)
pred = np.argmax(model.predict(X_test[0:10]), axis=1)
print(pred)
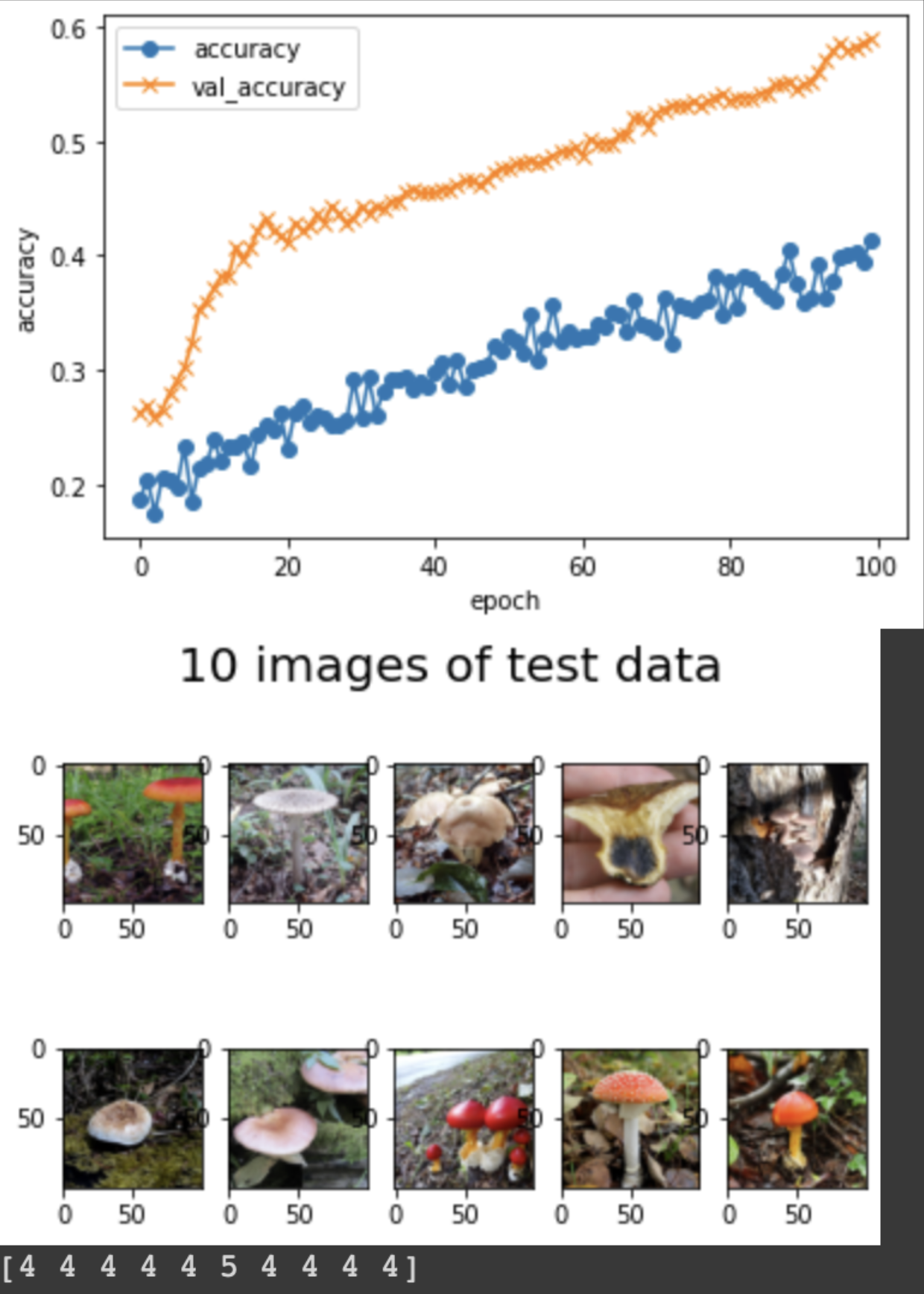
accuracyだけ見ていて精度が少し上がってきたと思っていたら、実際にはタマゴタケ(ラベル4)の判定ばかりしているのに気付きました(以下がその時点の学習結果です)。タマゴタケの画像データの数が他のキノコよりも多かったため、良く分からないキノコをとりあえずタマゴタケと判定することで正答率を上げていたようです。対策として、キノコの種類ごとの画像数が概ね一定になるようにタマゴタケの画像を間引きました。
10. 学習結果の保存
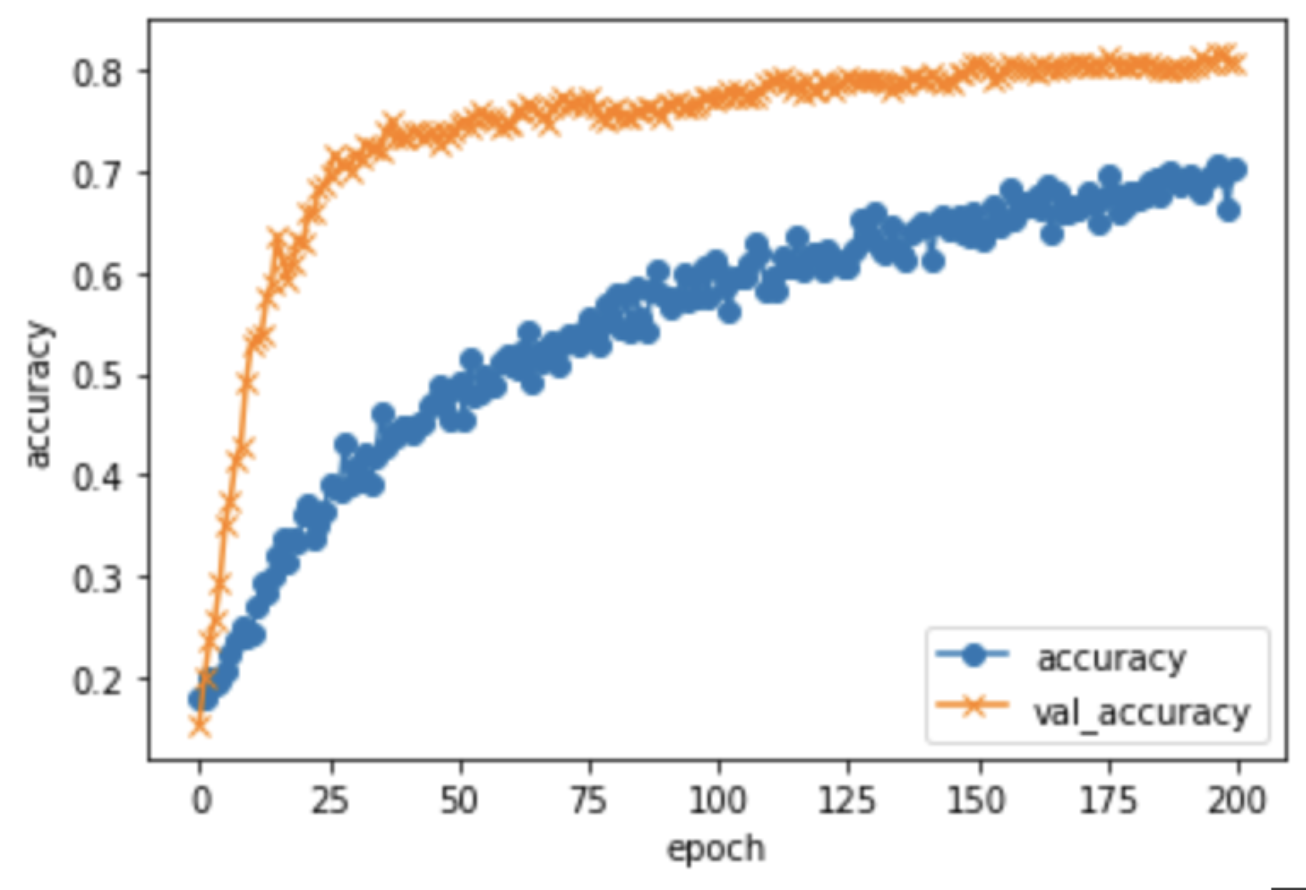
最終的に以下の結果が得られた時点で重みを保存しました。
loss: 0.7882 / val_loss: 0.5454
accuracy: 0.7022 / val_accuracy: 0.8084
#モデルを保存
#resultsディレクトリを作成
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 重みを保存
model.save(os.path.join(result_dir, 'model.h5'))
11. アプリ
作成したwebアプリをHerokuへデプロイして公開しました。よろしければお試し下さい。
テングタケやタマゴタケなどの特徴的なキノコの判別はまずまずの精度ですが、シイタケの傘の部分だけの写真ではテングタケと判別するなど、まだ完璧な精度にはほど遠いようです。
反省とまとめ
当初はなかなか正答率が上がりませんでしたが、image_sizeをある程度大きくすることでの学習効率が上がり正答率が改善したと考えています。それにより学習の計算時間がかなり長くなりましたが、GPUを使うことで大幅に時間を短縮できました。また、実際の判定結果を可視化してチェックすることで、不自然な判定(何でもタマゴタケと判定する誤り)に気付くことができたのもうまくいった点と思います。
さらに改善すべき点としては、まず第一にキノコ画像の正確な選別をすることだと思います。収集した画像の中には、私の目では本当にそのキノコか、あるいはそっくりな別のキノコか悩ましい画像もあり、それらを本当に知識のある人に選別してもらう必要があるように思いました。あとは、講習では習ったものの今回の課題では用いなかったパラメーターチューニングや異なるモデルの評価を行っても、精度が向上するのではないかと思います。
…
本業の合間にのんびり受講していたらあっという間に受講期間が終わりに近づいてしまい、最後は慌てて受講して課題に取り組むことになってしまいました。まだまだ改善の余地はあるように思いますが、一通りデータ収集からデータ整理・学習・評価まで作業してみることで、ようやくコードや機械学習を理解できたような気がしています。今回の受講をきっかけに、別の機械学習モデルにも挑戦してみたいと思います。
最後までご覧下さり、ありがとうございました。