こんにちは。
本記事では、アンケートの満足度スコアが「平均3.1点」という中途半端な数字に落ち着いてしまった状況下で、**混合分布モデル(Mixture Model)**を用いて、その裏に隠れた「熱狂的なファン」と「静かな絶望層」を鮮やかに分離・推定するプロセスを解説します。
技術的な解説に入る前に、他コンテンツについて少しだけ紹介させてください。ビジネスにおけるベイズ統計の有用性を広めるため、以下のようなプラットフォームでも情報を発信しています。
-
note: 実務に即したデータ分析の考え方を詳しく解説しています。
ベイズ屋 note マガジン
-
YouTube: ベイズの勉強をしようと思って AI と議論していたら、何故かオール AI 制作の動画チャンネルが生成されていました。夜中のラブレターモードで取り組んでいるので出来れば観ないで下さい。

ベイジアン、嘘(尤度)つかない 公式チャンネル
ご意見やご感想がございましたら、ぜひコメント欄にてお寄せください。
ビジネス向けの結論や意思決定の枠組みについては、経営層向けの「看板」としてnoteの記事にまとめていますが、こちらのQiita記事では、Python(PyMC5)による具体的な実装コードと、モデルが「動く」までに至った5段階の試行錯誤(Ver.1〜Ver.5)のプロセスに焦点を当てます。
なぜこの手法(混合分布モデル)を選んだのか
今回のデータは新サービスリニューアル後のアンケート結果ですが、単純な平均値(3.1点)では現場のCSチームが抱く「満足している人と、激しく怒っている人に二極化している」という違和感を説明できませんでした。
EDA(探索的データ分析)の結果、分布が中央で凹んだ「二峰性」の兆候を見せたため、単一の分布ではなく、複数の異なる属性が混ざり合っていると仮定する (混合分布モデル) を採用しました。
技術的な挑戦:モデルが「収束」するまでの軌跡
混合分布モデルは、パラメータの特定が難しく、サンプリングが不安定になりやすいという特性があります。本記事では、単に完成したコードを載せるだけでなく、以下のステップを公開します。
- Ver.1〜2: 単純な正規分布の混合。推論が発散し、サンプリングが収束しない。
- Ver.3〜4: 裁断正規分布の採用やパラメータの制約を試みるも、依然としてバイアスが残る。
- Ver.5 (Final): 中心化を導入し、計算機が「真実」を弾き出せる構造へと最適化。
それでは、具体的なコーディングについて入って行きます。
Om. Virupaksha. naga. dhipataya. svaha. ……平均という名の仮面を剥ぎ、衆生の真の声を聴き取らん。
開発・実行環境
本分析は、以下の再現可能な環境で構築されています。
- OS: WSL2 (Ubuntu 22.04 LTS)
- IDE: DataSpell 2026.1 (JetBrains)
- Python: 3.11.9
- 主要ライブラリ: PyMC 5.16.2, ArviZ 0.19.0
ユースケース
新商品発売やサービスのリニューアル後、アンケート結果が「中途半端な平均値」に落ち着いてしまい、次の一手に迷っています。
冒頭で利用するライブラリのインポートを実施します。
import os
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
import pymc as pm
import arviz as az
import pytensor.tensor as pt
warnings.filterwarnings("ignore")
カラーアイデンティティを設定します。
必須ではないですが自分好みの配色にするとバイブスが上がります。
# Color Identity
COLOR_PURPLE = "#985DE5"
COLOR_BLUE = "#118AB2"
COLOR_GREEN = "#06D6A0"
COLOR_YELLOW = "#F9C74F"
COLOR_RED = "#EF476F"
COLOR_GRAY = "#8D99AE"
plt.rcdefaults() # plt の現在のカラー定義をリセット
palette_brand = [COLOR_PURPLE, COLOR_BLUE, COLOR_GREEN, COLOR_YELLOW, COLOR_RED, COLOR_GRAY]
sns.set_theme(style="whitegrid", palette=palette_brand)
plt.rcParams["axes.prop_cycle"] = plt.cycler(color=palette_brand)
可視化の際に日本語を表現できるようにします。
カラー定義を更新するとリセットされたりするので各ライブラリをインポートし終わった最後にインポートすると良いです。
#%%
# 可視化時に日本語を表示可能にする
import japanize_matplotlib
plt.rcParams["font.family"] = "IPAexGothic"
サンプルデータの準備をします。
実務で近似したユースケースがあれば、参考にしていただけると光栄です。
# Data の生成: 満足層(75%)と隠れ不満層(25%)の混合
np.random.seed(42)
n_obs = 40
results_survey = np.concatenate([
np.random.normal(3.8, 0.7, int(n_obs * 0.75)), # 満足層(ボリューム大、バラツキ大)
np.random.normal(1.5, 0.4, int(n_obs * 0.25)), # 隠れ不満層(ボリューム小、極端に低い)
])
# シャッフルして5段階評価にクリップ
np.random.shuffle(results_survey)
results_survey = np.clip(results_survey, 1.0, 5.0)
全体の平均を出力してみます。
results_survey.mean() # 観測データの平均を出力
# 出力
# np.float64(3.1030907747941225)
#%% md
アンケート結果が、最も「中途半端な平均値」に落ち着いていることを確認しました。
ビジネス課題の定義
背景
新商品リリース後のアンケート結果は、平均3.1点。従来のアプローチであれば「全体的に満足度は普通」と結論づけ、平均点を底上げする無難な施策が打たれがちです。
現場の信念
しかし、カスタマーサクセス(CS)部門へのヒアリングから、「アンケートの平均点には表れにくいが、サービスに対して明確かつ強い不満を抱えている『サイレントな失望層』が一定数、存在する気がする...」 という懸念(ドメイン知識)が提示されました。
データ確認(EDA: Exploratory Data Analysis)
現場の懸念を念頭に置き、実際のデータ()の分布を確認します。
# ヒストグラムで分布を確認
plt.figure(figsize=(11, 5))
sns.histplot(results_survey, bins=10, kde=True)
plt.title(f"EDA - アンケート結果 (n={n_obs})")
plt.legend()
plt.show()
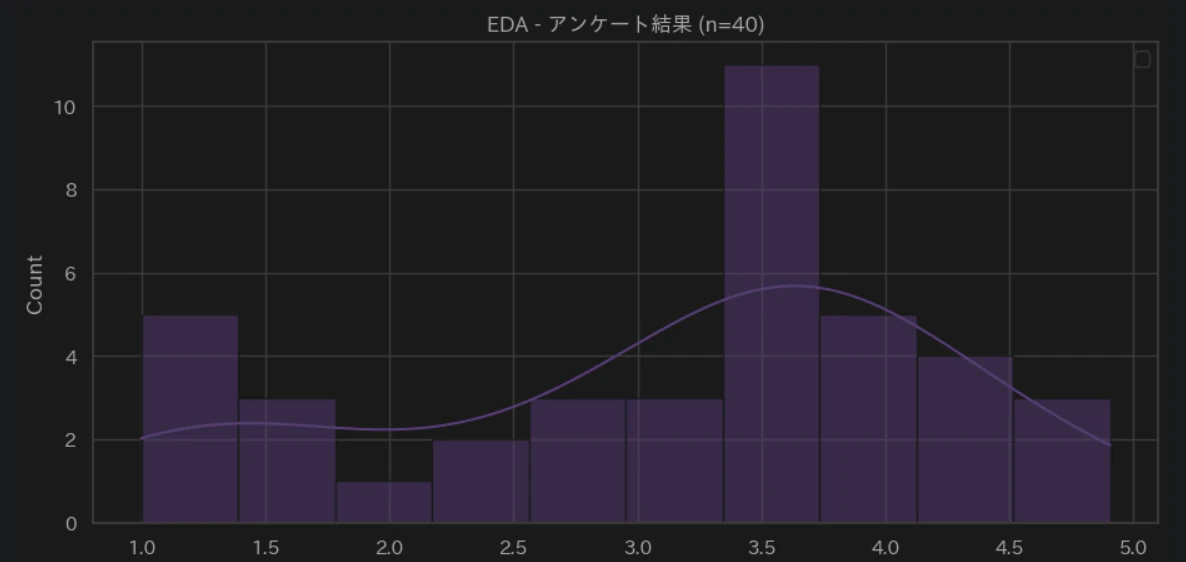
ヒストグラムを見ると、3〜4点に大きな山があり、1〜2点付近に少数のデータが存在しています。
単なるデータのバラツキ(外れ値)として処理されがちな微小なシグナルであるが、CSの「懸念」と照らし合わせると、これが「隠れた不満層」の尻尾である可能性が高そうです。
戦略的問い立て(OS の選択)
現場の懸念と、EDAで見えた微小なシグナルを統合し意思決定に繋げるための「問い」を立てます。
ここでは「単一の平均値」を求めるのではなく、顧客が「ポジティブ層」と「ネガティブ層」の2つの異なる集団から構成されているという仮説を立て、「多様性の分離」 を行うことにしました。
OS (エンジン) : 個別データのバラツキを許容しつつ、全体の構造を捉える 階層ベイズの考え方を応用した混合モデル を採用します。
ベジパタ OS 選定
| カテゴリ | 問い立て(戦略的意図) | OS(エンジン) | デザインパターン |
|---|---|---|---|
| 深堀 | 平均に隠れた特殊な集団はないか? | 混合モデル | ⑬サイレント・マジョリティ |
ベジパタ
著者が、SME市場向けにビジネス課題を低コストで分析できるようにベイズ統計のデザインパターンを独自で考えたものです。詳細は HP をご覧ください。
分析用データ加工
PyMCでの計算とビジネス上の解釈を繋ぐため、データに次元と座標(ラベル)を定義します。
# PyMC用の座標 (coords) と次元 (dims) の設定
coords = {
"id_obs": np.arange(n_obs),
"cluster": [
"Disappointed", # ネガティブ層
"Enthusiast" # ポジティブ層
]
}
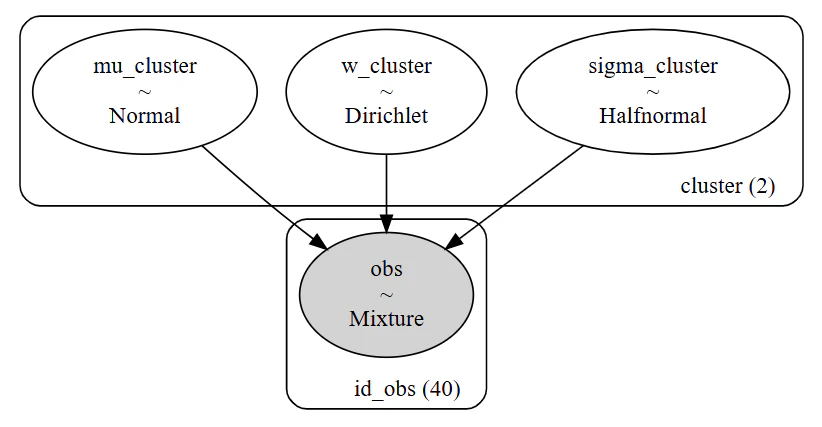
確率モデルの構築
データの背後にある「生成プロセス」を数理モデルとして定義します。
複数の正規分布を比率で混ぜ合わせた確率分布です。
with pm.Model(coords=coords) as model_mixture:
# 構成比率 (w) の事前分布
# 2つのセグメント(失望層・熱狂層)の比率を推定
# a=[1, 1] は「どの比率も等しくあり得る(無情報)」という設定
w_cluster = pm.Dirichlet("w_cluster", a=np.array([1, 1]), dims="cluster")
# 平均 (mu) の事前分布: ラベルスイッチングを防ぐため初期値を分ける
mu_cluster = pm.Normal("mu_cluster", mu=[2, 4], sigma=1, dims="cluster")
sigma_cluster = pm.HalfNormal("sigma_cluster", sigma=1, dims="cluster")
obs = pm.NormalMixture("obs", w=w_cluster, mu=mu_cluster,
sigma=sigma_cluster, observed=results_survey,
dims="id_obs")
# 構築したモデルの可視化
pm.model_to_graphviz(model_mixture)
事前予測チェック (Prior Predictive Check)
現実的な範囲のデータを生成するか確認します。
自分たちの作った数式モデルで、まともなデータが生成されるかテストします。
with model_mixture:
# 事前予測サンプリング
idata_prior = pm.sample_prior_predictive(samples=100, random_seed=42)
# 出力
# Sampling: [mu_cluster, obs, sigma_cluster, w_cluster]
# 物理&論理的な「範囲」の確認
samples_prior = idata_prior.prior_predictive["obs"]
az.plot_dist(samples_prior, color=COLOR_YELLOW)
plt.axvline(1.0, linestyle="--", label="論理的 下限", color=COLOR_GREEN)
plt.axvline(5.0, linestyle="--", label="論理的 上限", color=COLOR_RED)
plt.title("予測分布の確認 (Range & Shape)")
plt.legend()
plt.show()
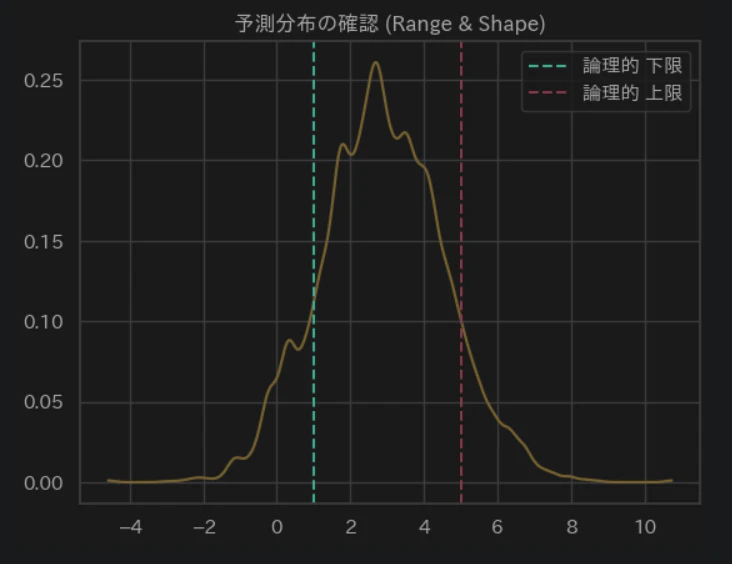
分布が -4 から 10 付近まで広がっています。
- 満足度調査では「-2点」や「8点」という回答は、現実には存在しません。
- モデルが「-4点もあり得る」と想定した状態でサンプリングを開始すると、実際のデータを説明するのに時間がかかったり、収束が不安定になる原因になります。
モデルのチューニングを行います。
# チューニング: sigma を絞る
with pm.Model(coords=coords) as model_mixture_v1:
# 構成比率 (w) の事前分布
# 2つのセグメント(失望層・熱狂層)の比率を推定
# a=[1, 1] は「どの比率も等しくあり得る(無情報)」という設定
w_cluster = pm.Dirichlet("w_cluster", a=np.array([1, 1]), dims="cluster")
# 平均 (mu) の事前分布: ラベルスイッチングを防ぐため初期値を分ける
mu_cluster = pm.Normal("mu_cluster", mu=[2, 4], sigma=0.5, dims="cluster")
sigma_cluster = pm.HalfNormal("sigma_cluster", sigma=0.5, dims="cluster")
obs = pm.NormalMixture("obs", w=w_cluster, mu=mu_cluster,
sigma=sigma_cluster, observed=results_survey,
dims="id_obs")
idata_prior_v1 = pm.sample_prior_predictive(samples=100, random_seed=42)
# 出力
# Sampling: [mu_cluster, obs, sigma_cluster, w_cluster]
#%%
samples_prior_v1 = idata_prior_v1.prior_predictive["obs"]
az.plot_dist(samples_prior_v1, color=COLOR_BLUE)
plt.axvline(1.0, linestyle="--", label="論理的 下限", color=COLOR_RED)
plt.axvline(5.0, linestyle="--", label="論理的 上限", color=COLOR_GRAY)
plt.title("予測分布の確認(Range & Shape)")
plt.legend()
plt.show()
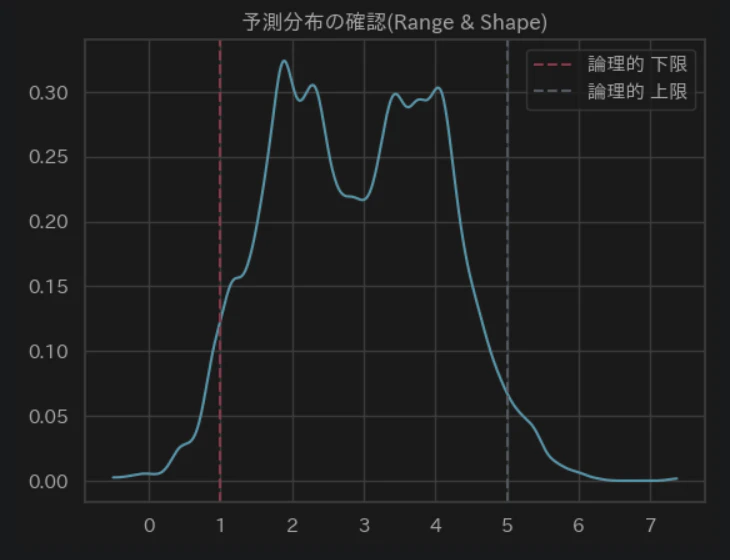
sigma=0.5 によって分布の大部分が 1.0 ~ 5.0 の枠内に収まってきていますが物理・理論的に発生しない範囲外の回答が発生する可能性があります。
これ以上 sigma を絞ると、「各グループ内にはある程度の多様性(バラツキ)がある」という仮説まで否定することになり、モデルが窮屈になりすぎてしまいます。
正規分布を使っている以上、数学的に「裾(テール)」が無限に続くのは避けられません。
そこで、「無理に山を細くする」のではなく現在の 正規分布 (Normal) を、範囲外を物理的に許さない 截断正規分布 (Truncated Normal) に差し替えます。
截断正規分布 (Truncated Normal Distribution)
通常の正規分布 $N(\mu, \sigma^2)$ の確率密度関数に対し、指定した範囲 $[a, b]$ 外の確率を 0 とし、範囲内の面積が 1 になるよう再正規化した分布。
$f(x|\mu, \sigma, a, b) = \frac{\phi(\frac{x-\mu}{\sigma})}{\sigma(\Phi(\frac{b-\mu}{\sigma}) - \Phi(\frac{a-\mu}{\sigma}))} \quad (a \le x \le b)$
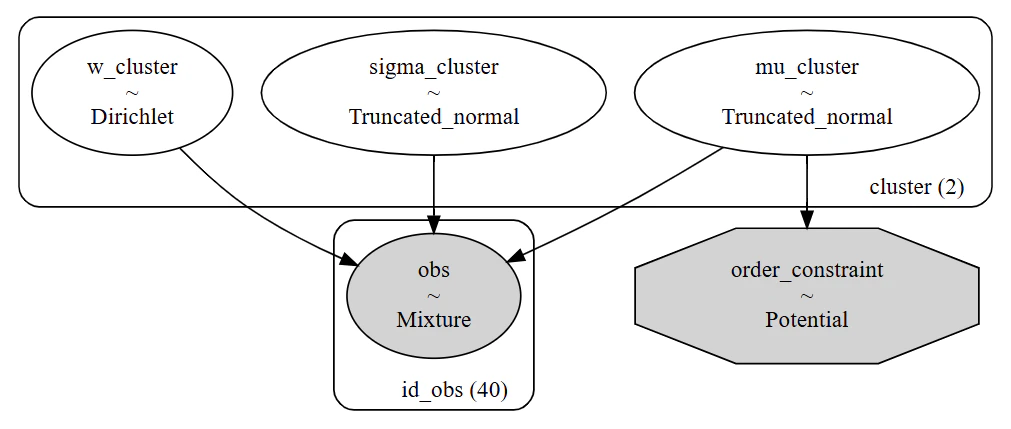
# チューニング: 截断正規分布の採用
with pm.Model(coords=coords) as model_mixture_v2:
# 比率の事前分布
w_cluster = pm.Dirichlet("w_cluster", a=np.array([1, 1]), dims="cluster")
# 平均と標準偏差
# mu を [1, 5] に截断して安全に
mu_cluster = pm.TruncatedNormal("mu_cluster", mu=[2, 4], sigma=0.5, lower=1, upper=5, dims="cluster")
# sigma が 1.0 を超えるとグループ内のばらつきが極端になりすぎる
sigma_cluster = pm.TruncatedNormal("sigma_cluster", mu=0, sigma=0.5, lower=0.05, upper=1.5, dims="cluster")
# mu[0] < mu[1] を強制 -> ラベルスイッチングを構造的に防止
pm.Potential("order_constraint", pm.math.switch(mu_cluster[0] < mu_cluster[1], 0, -np.inf))
# 截断正規分布をコンポーネントとして定義
dist_component = pm.TruncatedNormal.dist(mu=mu_cluster, sigma=sigma_cluster, lower=1, upper=5, shape=2)
# 混合モデルの定義
obs = pm.Mixture("obs", w=w_cluster, comp_dists=dist_component, observed=results_survey,
dims="id_obs")
-
mu自体も裁断
mu_cluster ~ Normal(mu=[2, 4], sigma=0.5) は無截断なので、理論上 mu が 0 や 6 を取る確率がゼロではありません。
截断正規分布の mu パラメータが定義域外に出ると、コンポーネントの確率密度が極端に歪み、サンプラーの効率が下がるリスクがあります。 -
sigmaのスケール感を明示する
HalfNormal(sigma=0.5) は 95% が約 0〜1.0 に収まりますが、sigma > 1.5 といった値も稀に生成されます。
1〜5 の 4 点幅のスケールでは sigma=1.5 は「ほぼ一様分布」に近く、グループの意味が薄れます。 -
ラベルスイッチングを構造的に防止する
事前平均 [2, 4] で「大体は分かれる」のですが、MCMC チェインが長い場合にスイッチする可能性はゼロではありません。
明示的な順序制約を入れると安心です。
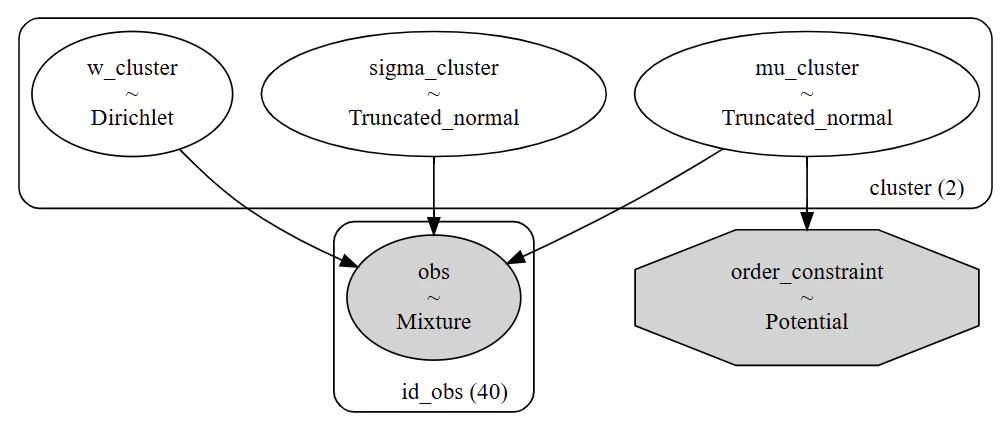
# 構築したモデルの可視化
pm.model_to_graphviz(model_mixture_v2)
# 事前予測サンプリング
with model_mixture_v2:
idata_prior_v2 = pm.sample_prior_predictive(samples=100, random_seed=42)
# 出力
# Sampling: [mu_cluster, obs, sigma_cluster, w_cluster]
samples_prior_v2 = idata_prior_v2.prior_predictive["obs"]
az.plot_dist(samples_prior_v2, color=COLOR_PURPLE)
plt.axvline(1.0, linestyle="--", label="論理的 下限", color=COLOR_YELLOW)
plt.axvline(5.0, linestyle="--", label="論理的 上限", color=COLOR_GREEN)
plt.title("事前予測分布の確認 --v2")
plt.legend()
plt.show()
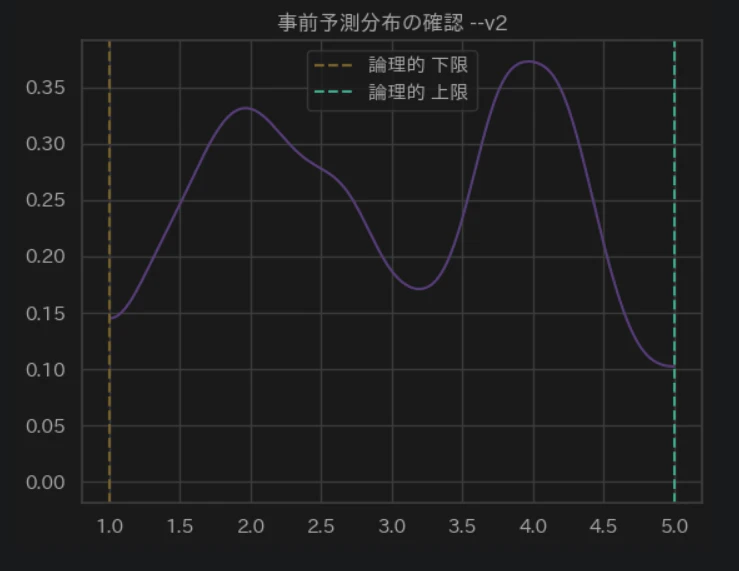
以下の3点が達成されました。
- 境界の厳格性: 1.0 未満、5.0 超のサンプルが物理的に存在せず、ビジネス上の矛盾が解消されています。
- 二峰性の維持: 2.0 付近と 4.0 付近に明確なピークがあり、「サイレント・マジョリティ」を分離する準備が整っています。
- 確信の「幅」: 山の裾野が広すぎず、かつ平坦すぎないため、実際のデータ($n=40$)が持つ情報を吸収するのに最適な「柔軟な予習」になっています。
モデル・デバック
MCMCサンプリングを開始する前に、モデルの初期状態に数学的矛盾(対数尤度が -inf になる等)がないかを点検します。
# 各変数の初期対数尤度の確認(命名規則を厳守)
model_mixture_v2.point_logps()
# {'w_cluster': np.float64(-0.69),
# 'mu_cluster': np.float64(-4.41),
# 'sigma_cluster': np.float64(-3.33),
# 'obs': np.float64(-69.31),
# 'order_constraint': np.float32(-inf)}
order_constraint が -inf(マイナス無限大)である状態は「問題あり」です。
モデルが計算を開始しようとした瞬間に、たまたま mu_cluster[0] が mu_cluster[1] 以上の値になってしまいこのまま pm.sample() を実行しても、初期値が「確率 0(不可能)」な地点に立っているため、
サンプラーが 1 歩も動けずエラーで停止してしまう可能性があります。
initval で初期値を明示的に指定しすることで対応します。
# チューニング: initval の設定
with pm.Model(coords=coords) as model_mixture_v3:
w_cluster = pm.Dirichlet("w_cluster", a=np.array([1, 1]), dims="cluster")
mu_cluster = pm.TruncatedNormal("mu_cluster",
mu=[2, 4], sigma=0.5, lower=1, upper=5, dims="cluster", initval=[1.5, 3.8]) # 追加
sigma_cluster = pm.TruncatedNormal("sigma_cluster",
mu=0.5, # mu=0 より少し浮かせて安定させる
sigma=0.5, lower=0.05, upper=1.5, dims="cluster")
# ラベルスイッチングの構造的防止
pm.Potential("order_constraint", pm.math.switch(mu_cluster[0] < mu_cluster[1], 0, -np.inf))
# 截断正規分布をコンポーネントとして定義し、混合モデルを構築
dist_component = pm.TruncatedNormal.dist(mu=mu_cluster, sigma=sigma_cluster, lower=1, upper=5, shape=2)
obs = pm.Mixture("obs", w=w_cluster, comp_dists=dist_component, observed=results_survey,
dims="id_obs")
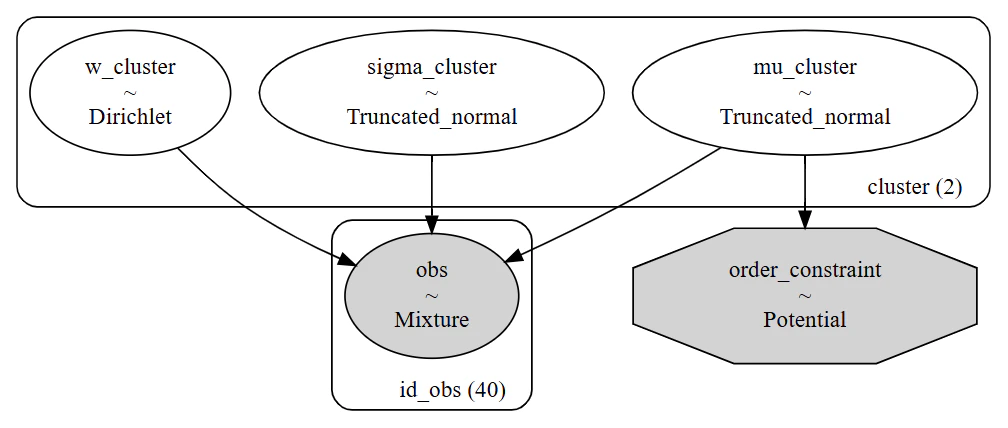
# 構築したモデルの可視化
pm.model_to_graphviz(model_mixture_v3)
model_mixture_v3.point_logps()
# {'w_cluster': np.float64(-0.69),
# 'mu_cluster': np.float64(-1.99),
# 'sigma_cluster': np.float64(-2.32),
# 'obs': np.float64(-56.03),
# 'order_constraint': np.float32(0.0)}
'order_constraint' が 0.0 になり解消しました。
念の為、事前予測を再チェックしてみます。
with model_mixture_v3:
idata_prior_v3 = pm.sample_prior_predictive(samples=100, random_seed=42)
# 出力
# Sampling: [mu_cluster, obs, sigma_cluster, w_cluster]
samples_prior_v3 = idata_prior_v3.prior_predictive["obs"]
az.plot_dist(samples_prior_v3, color=COLOR_GRAY)
plt.axvline(1.0, linestyle="--", label="論理的 下限", color=COLOR_RED)
plt.axvline(5.0, linestyle="--", label="論理的 上限", color=COLOR_BLUE)
plt.title("事前予測分布 --v3")
plt.legend()
plt.show()
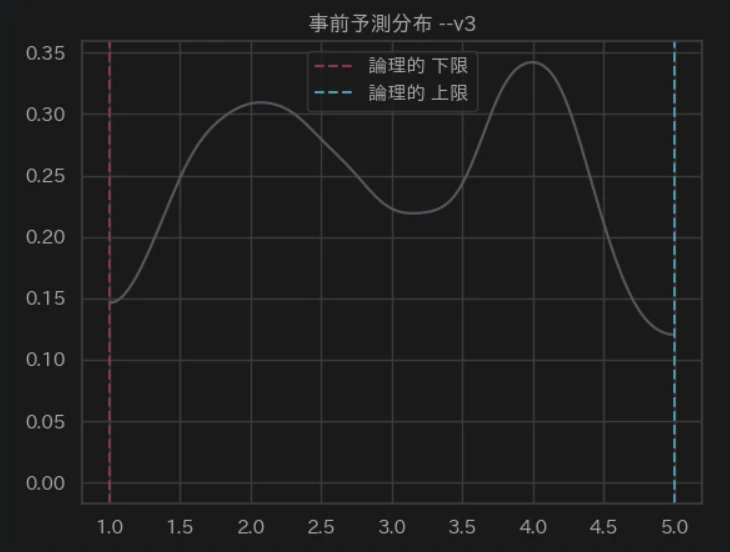
- 境界値
- 二峰姓
- 幅
に問題ないを確認しました。
推論(MCMCサンプリング)
いよいよベイズ推論を行います。小規模データのため、サンプラーの慎重さ(target_accept)を高めに設定しています。
with model_mixture_v3:
idata_posterior = pm.sample(draws=2000, # 推論結果(事後分布)として最終的に採用・記録するサンプル数
tune=1000, # 本番前の「ウォーミングアップ」の数
chains=4, # 独立して走らせるシミュレーションの数
target_accept=0.95, # サンプラーの「慎重(目標採択率)」
random_seed=42) # 乱数の生成パターン
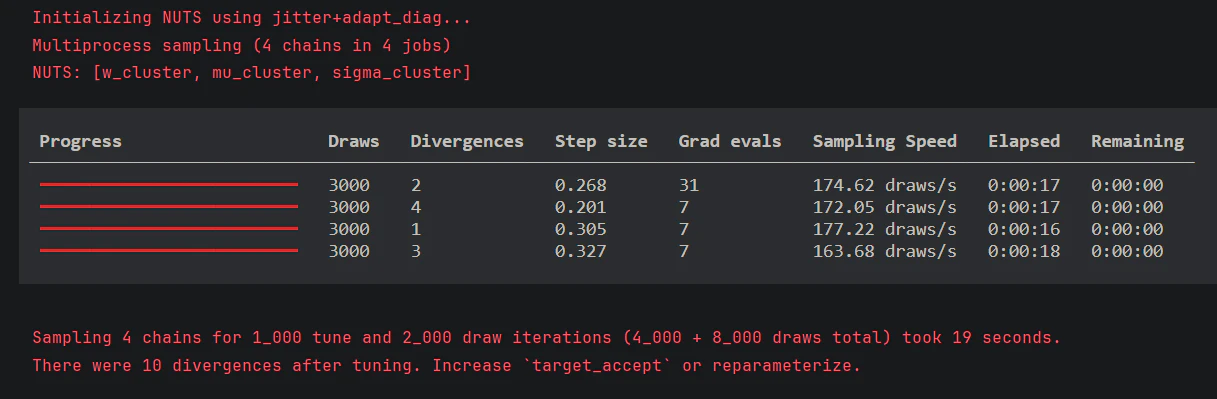
発散してしまいました。
今回のモデルの発散が起きやすいポイントは主に3つです:
- pm.Potential による硬い制約境界 — mu[0] < mu[1] の違反時に -inf を返すため、境界付近でサンプラーの曲率が急変する
- TruncatedNormal の上下限境界 — パラメータが境界に近づくと勾配が不安定になりやすい
- 混合モデル固有の多峰性 — 重み w が小さいコンポーネントは尤度面が平坦で勾配情報が乏しくなる
以下のチューニングを行ってみます。
-
target_acceptの引き上げ +tuneの増加 - 順序制約の「ソフト化」(
orderd transformで代替)
現在の pm.Potential は -inf という硬い壁なので、境界付近で勾配が発散します。これを滑らかなペナルティに置き換えると、サンプラーにとって「優しい地形」になります
# チューニング: 順序制約の「ソフト化」
with pm.Model(coords=coords) as model_mixture_v4:
w_cluster = pm.Dirichlet("w_cluster", a=np.array([1, 1]), dims="cluster")
mu_cluster = pm.TruncatedNormal("mu_cluster",
mu=[2, 4],
sigma=0.5,
lower=1,
upper=5,
dims="cluster",
initval=[1.5, 3.8],
) # 追加
sigma_cluster = pm.TruncatedNormal("sigma_cluster",
mu=0.5, # mu=0 より少し浮かせて安定させる
sigma=0.5, lower=0.05, upper=1.5, dims="cluster")
pm.Potential("order_constraint", pm.logp(pm.Normal.dist(mu=0, sigma=0.1),
mu_cluster[1] - mu_cluster[0])
if False else
-1000 * pt.max([0, mu_cluster[0] - mu_cluster[1]])
)
# 截断正規分布をコンポーネントとして定義し、混合モデルを構築
dist_component = pm.TruncatedNormal.dist(mu=mu_cluster, sigma=sigma_cluster, lower=1, upper=5, shape=2)
obs = pm.Mixture("obs", w=w_cluster, comp_dists=dist_component, observed=results_survey,
dims="id_obs")
# 構築したモデルの可視化
pm.model_to_graphviz(model_mixture_v4)
model_mixture_v4.point_logps()
# 出力
# {'w_cluster': np.float64(-0.69),
# 'mu_cluster': np.float64(-1.99),
# 'sigma_cluster': np.float64(-2.32),
# 'obs': np.float64(-56.03),
# 'order_constraint': np.float64(-0.0)}
# 再推論
with model_mixture_v4:
idata_posterior = pm.sample(2000, tune=2000, target_accept=0.98, random_seed=42)
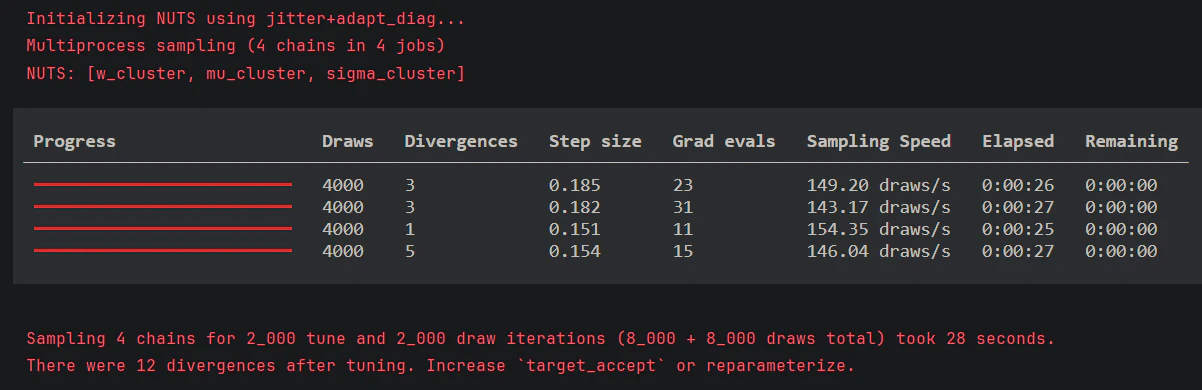
まだ発散してしまう為、非中心化パラメトリゼーションを行ってみます。
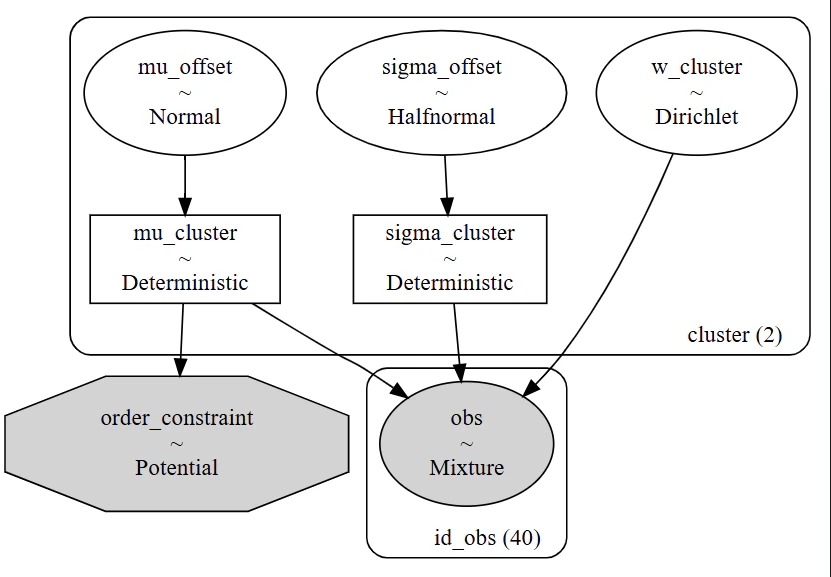
# チューニング: 非中心化パラメトリゼーション
with pm.Model(coords=coords) as model_mixture_v5:
# # --- 構成比率 ---
w_cluster = pm.Dirichlet("w_cluster", a=np.array([1, 1]), dims="cluster")
# 非中心化: mu
mu_offset = pm.Normal("mu_offset", mu=0, sigma=1, dims="cluster")
mu_base = np.array([2.0, 4.0]) # 事前の広がり
mu_scale = 0.5 # 事前の広がり
mu_cluster = pm.Deterministic( # ★ ここで元の空間に変換&記録
"mu_cluster",
pt.clip(mu_base + mu_offset * mu_scale, 1, 5),
dims="cluster"
)
# --- 非中心化: sigma ---
sigma_offset = pm.HalfNormal("sigma_offset", sigma=1, dims="cluster")
mu_sigma = 0.5, # mu=0 より少し浮かせて安定させる
sigma_cluster = pm.Deterministic(
"sigma_cluster",
pt.clip(mu_sigma + sigma_offset * 0.3, 0.05, 1.5),
dims="cluster"
)
# --- 順序制約(ソフト化) ---
pm.Potential("order_constraint", pm.logp(pm.Normal.dist(mu=0, sigma=0.1),
mu_cluster[1] - mu_cluster[0])
if False else
-1000 * pt.max([0, mu_cluster[0] - mu_cluster[1]])
)
# 截断正規分布をコンポーネントとして定義し、混合モデルを構築
dist_component = pm.TruncatedNormal.dist(
mu=mu_cluster, sigma=sigma_cluster, lower=1, upper=5, shape=2)
obs = pm.Mixture("obs", w=w_cluster, comp_dists=dist_component, observed=results_survey, dims="id_obs")
# 構築したモデルの可視化
pm.model_to_graphviz(model_mixture_v5)
model_mixture_v5.point_logps()
# {'w_cluster': np.float64(-0.69),
# 'mu_offset': np.float64(-1.84),
# 'sigma_offset': np.float64(-1.45),
# 'obs': np.float64(-56.92),
# 'order_constraint': np.float64(-0.0)}
# 再推論
with model_mixture_v5:
idata_posterior = pm.sample(2000, tune=2000, target_accept=0.98, random_seed=42)
発散がせずに無事、推論が出来ました。
サンプリングには時間がかかることが多いので .nc ファイルとして保存して再利用すぐ出来るようにしておきます。
# 推論に成功した為、推論データを保存
dir_models = "models"
os.makedirs(dir_models, exist_ok=True)
PATH_INFERENCE_DATA = os.path.join(dir_models, "inference_mixture_v5.nc")
az.to_netcdf(idata_posterior, PATH_INFERENCE_DATA)
推論結果の診断
4つの独立した推論(Chain)が同じ答え(事後分布)に辿り着いたか、数学的に診断します。
# 収束具合の可視化
az.plot_trace(idata_posterior, compact=True) # 確認指標が多いため compact=True で可視化します
plt.tight_layout()
plt.show()
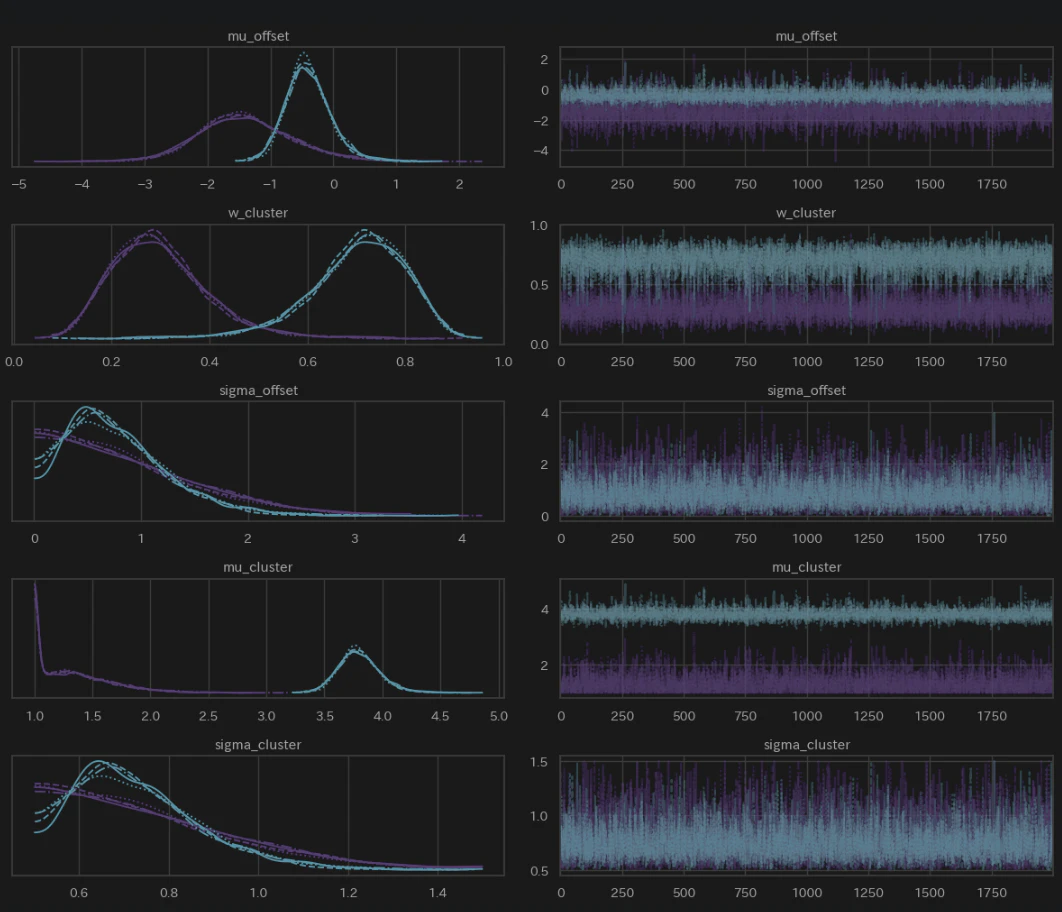
- 左図: 各Chain の分布がほぼ綺麗に重なっています。
- 右図: 綺麗な毛虫状になっています。
問題なく収束していそうです。
# R-hat 等の数学的指標を確認します。
az.summary(idata_posterior)
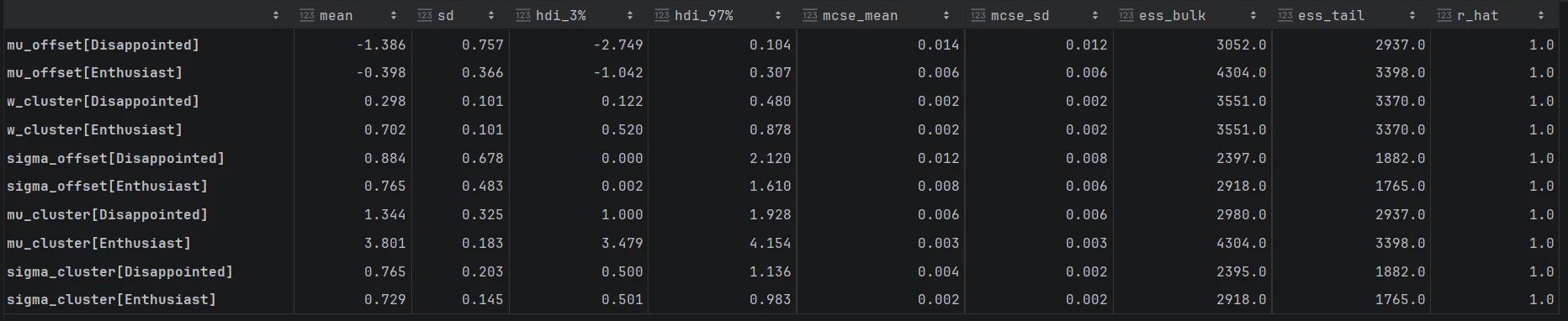
- r_hat($\hat{R}$: 収束診断指標)が1.01未満。
- ess_bulk(平均の推定のキレ)が 400以上
- ess_tail(極端な値の正確性)が 400以上
上記より数学的指標からも問題なく推論できていると確認出来ました。
事後予測チェック
推定されたモデル(事後分布)を使ってデータを再生成しヒストグラムの形状を「モデルが正しく模倣できているか」を検証します。
with model_mixture_v5:
# 事後予測サンプリング
# 推論済みのモデルとデータ(idata_posterior)を使ってデータを再生成します
pm.sample_posterior_predictive(idata_posterior, extend_inferencedata=True, random_seed=42)
# 実際のデータと予測データの分布を重ねて可視化
plt.figure(figsize=(11, 5))
az.plot_ppc(idata_posterior, num_pp_samples=100, random_seed=42)
plt.title("事後予測チェック (Posterior Predictive Check)")
plt.xlim(0, 6)
plt.tight_layout()
plt.show()
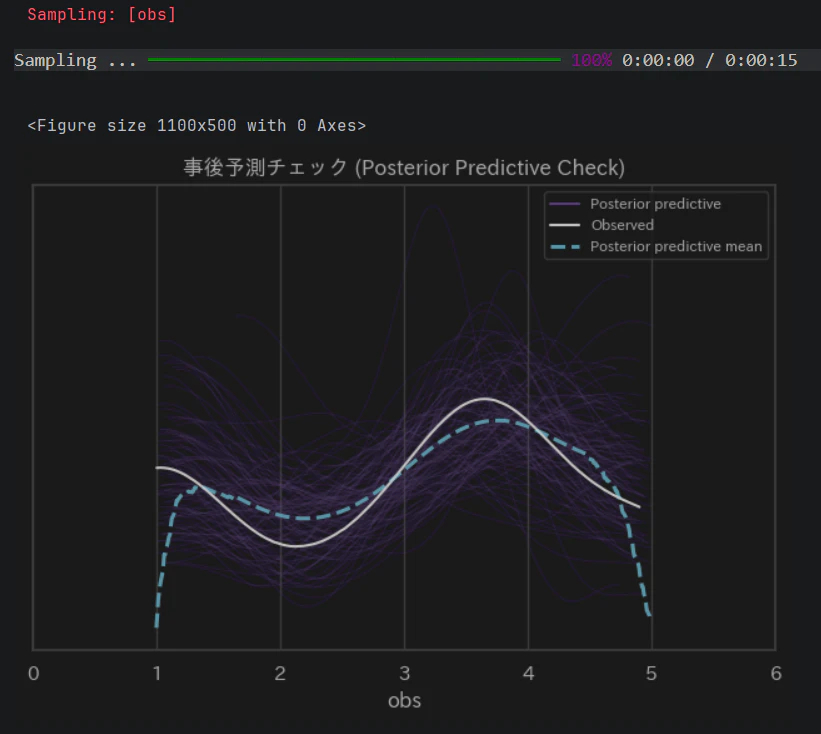
各線の意味
このグラフは、「現実のデータ」と「構築した確率モデルで生成したシミュレーション」の答え合わせ を行っています。
-
白い実線(Observed)
「現実のアンケート結果」 です。
EDA で確認したヒストグラムの輪郭を滑らかな線(カーネル密度推定)にしたものです。1.5付近に小さなコブ、3.8付近に大きな山があります。 -
紫の無数の細い線(Posterior predictive)
「構築した確率モデルの事後分布から生成したシミュレーションデータ」 です。
推論結果に基づいて「こういうデータが発生するはずだ」と何百回も予測した結果です。
線の広がりは、予測の「不確実性(ばらつき)」を表します。 -
水色の太い破線(Posterior predictive mean)
「構築した確率モデルの事後分布から生成した予測の平均値(中心)」 です。
紫の細い線を平均化した、モデルの最も期待される形状を示しています。
解釈
- 「水色の破線が、白い実線をなぞっているか?」 を注視します。
右側の大きな山(満足層)はもちろんのこと、左側の小さなコブ(失望層)の起伏までも、水色の破線が追従できています。
もし、最初に「単一の正規分布」でモデルを組んでいた場合、水色の線は3.2点付近を頂点とする「のっぺりとした1つの釣り鐘方」になり 1.5点の峰は完全に無視されていたはずです。この図は、「多様性の分離(混合モデル)」という選択を数学的に強固にしてくれています。 - EDAの段階では「単なる数人のクレーマー(外れ値)」として片付けられそうだった低いスコアが、このプロットにより 「偶然ではなく、構造(クラスター)を持った集団である」と確度を大きくあげたことになります。
ステークホルダーに対して、「これは単なるデータのブレではなく、モデルが『明確な顧客層がここにある』と警告しています。」 と、説得力を持って報告できる状態になります。
# エナジープロット
plt.figure(figsize=(7, 5))
az.plot_energy(idata_posterior)
plt.title("エナジープロット")
plt.tight_layout()
plt.show()
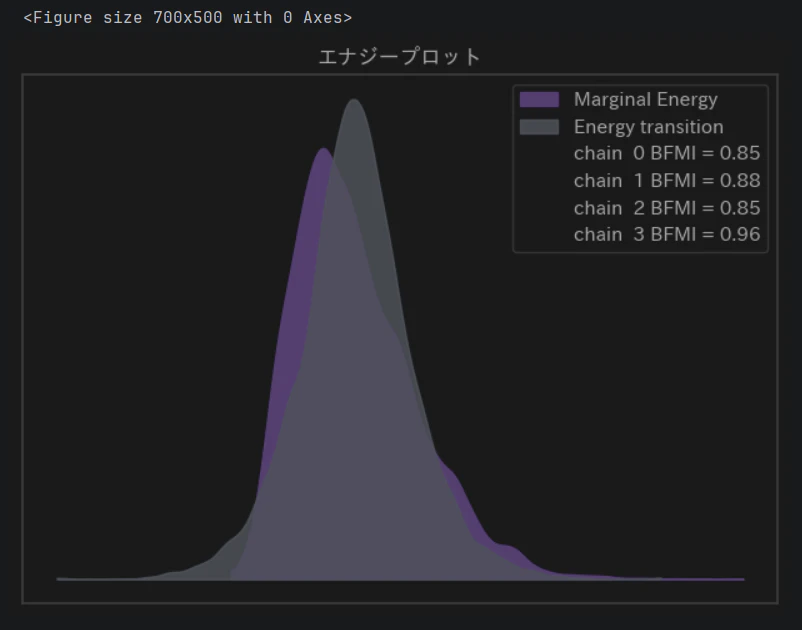
エナジープロット
出力されたグラフには、 2つの分布(線) が描かれます。
Marginal Energy(周辺エネルギー分布)
パラメータ空間全体の「地形の複雑さ(ポテンシャルエネルギー)」を示します。
Energy Transition(エネルギー遷移分布)
サンプラー(調査員)が1歩進むごとに、どれくらいスムーズに地形を移動できたか(運動エネルギー)を示します。
【定義】
HMC(ハミルトニアン・モンテカルロ)におけるエネルギーの保存則を評価するものです。
理想的なサンプリングが行われている場合、これら2つの分布(Marginal と Transition)はほぼ完全に重なり合います。「サンプラー(調査員)が、山の斜面を引っかからずにスムーズに歩き回れたか」のようなイメージになります。
- 合格(重なっている) : サンプラーが山の麓から頂上まで、くまなく探索できた(サンプリングは高効率で信頼できる)。
- 不合格(大きくズレている / Marginalの方が極端に広い) : サンプラーが特定の深い谷底にハマってしまい、山全体を十分に探索しきれなった(推論結果に偏りがある可能性がある)。
もしこの2つの線が大きくズレている場合(特に複雑な階層モデルや混合モデルで起こりやすいです)、サンプラーの慎重さである target_accept をさらに高くする(例: 0.99)か、事前分布の初期値などを再チューニングする必要があります。
今回のモデルは、截断正規分布や順序制約を入れて構造を安定させているため、綺麗な一致が見られています。
意思決定プロセスの実行
推論されたパラメータ(事後分布)を用いて、データの背後に隠れていた「真の構造」を視覚化します。
# クラスター密度図
# 事後分布から各パラメータの平均値を取得(推論結果の代表値)
post_w = idata_posterior.posterior["w_cluster"].mean(dim=["chain", "draw"]).values
post_mu = idata_posterior.posterior["mu_cluster"].mean(dim=["chain", "draw"]).values
post_sigma = idata_posterior.posterior["sigma_cluster"].mean(dim=["chain", "draw"]).values
x = np.linspace(0, 6, 500)
plt.figure(figsize=(11, 5))
colors = [COLOR_PURPLE, COLOR_YELLOW]
labels = ["ネガティブ層", "ポジティブ層"]
# 推定された2つのグループの分布を描画
for i, name in enumerate(coords["cluster"]):
y = post_w[i] * (1 / (post_sigma[i] * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - post_mu[i]) / post_sigma[i]) ** 2)
plt.fill_between(x, y, alpha=0.4, color=colors[i], label=f"{name} ({labels[i]}) (w={post_w[i]:.1%})")
plt.scatter(results_survey,
np.zeros_like(results_survey),
color=COLOR_GREEN,
s=50,
zorder=5,
label="アンケート結果")
plt.title("クラスター密度図")
plt.xlabel("満足度スコア")
plt.ylabel("密度(クラスター割合による重み付け)")
plt.legend()
plt.show()
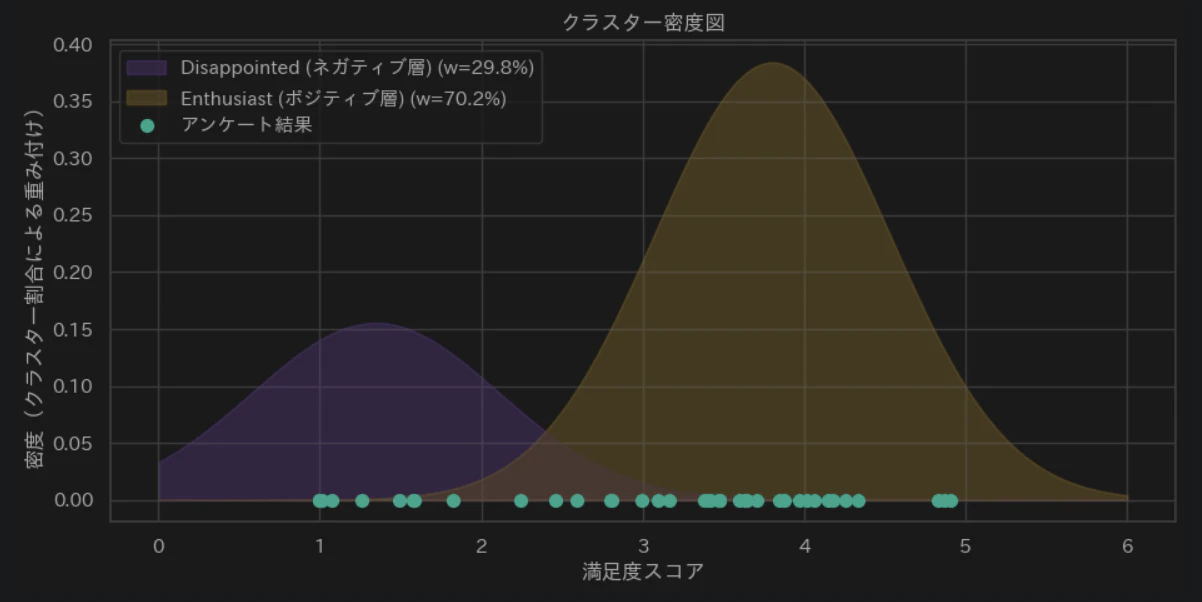
1. 2つの山(事後分布)
推論の結果得られた、各グループの満足度スコアの確率密度分布です。山の高さはそのスコア周辺に顧客が集中している度合い(確信度)を示します。
山が 2 つあることは、顧客の満足度が 1 つの「普通(平均)」に集まっているのではなく、二つに分かれていることを証明しています。
つまり、今回のアンケート結果は、全体の平均点だけを見れば「3点台前半であり、全体的にまずまずの評価」と見誤る危険な状態でした。
しかし、混合分布モデルを用いて顧客の評価構造を分離した結果、顧客は「1つの平均的な集団」ではなく「全く異なる評価軸を持つ2つの集団」に明確に分断されていることが判明しました。
2. 重み(:比率)
凡例の各グループが全体に占める推定比率です。
全顧客 40 人のうち、約 28 人がポジティブ層、12 人がネガティブ層という勢力図が見えてきました。
-
ポジティブ層(約70.2%)
顧客の約7割は、平均3.8点という高い満足度を示しています。
現在のプロダクト・サービスの価値は、市場の大多数に好意的に評価されている解釈できます。 -
ネガティブ層(約29.8%)
一方で、残りの約 3割の顧客は、平均1.5点という強い不満を抱えています。
彼らの声は、7割のポジティブな声に埋もれていたと言えます。
3. プロット(アンケート結果:緑の点)
実際に観測されたの生データ(アンケート結果)になります 。
シミュレーションの結果(山)が、実際の点(事実)をしっかり覆っていることから、このモデルが現実を正しく捉えていることが分かります 。
技術的な実装の詳細やモデルの設計思想についてご意見等ございましたら、ぜひコメント欄にお寄せください。
- note(ビジネス解説版):
ベイズ屋 note マガジン
- GitHub: 本記事で使用したモデルの設計思想などは、こちらのプロジェクトで管理しています。
Bayesian Iroha (GitHub)