「どこから守ったか」で評価は変わる:空間統計学を活用したキーパーの評価とリスク管理
はじめに
営業エリアの特性、店舗の立地、あるいはスポーツにおけるプレイエリア。ビジネスや分析の現場において「場所(位置)」の情報は、結果を左右する大きな変数です。
単に「何回成功したか」という回数だけの評価では、その裏にある「環境の厳しさ」を見落とす可能性があります。本記事では、プロホッケー(NHL)のゴールテンダー(キーパー)を例に、空間統計学の視点を取り入れた PyMC v5 による分析モデルをご提案します。
PyMC Labs からインスプレーションをいただきました。
Bayesian Spatial Modeling for Evaluating Hockey Goaltending Performance
開発・実行環境
本分析は、以下の再現可能な環境で構築されています。
- OS: WSL2 (Ubuntu)
- IDE: DataSpell 2025.2.3 (JetBrains)
- Python: 3.11.9
- Package Manager: Poetry 2.2.1
1. ビジネス(評価)の課題:空間的な「難易度」の無視
例えば、以下の2人のゴールテンダーを比較する際、セーブ率(阻止率)だけで判断するのは要注意です。
- 選手A: セーブ率 95%(ただし、遠距離からのシュートが大半)
- 選手B: セーブ率 90%(ただし、ゴール至近距離からのシュートを多く防いでいる)
立地条件の良い店舗と悪い店舗の売上をそのまま比較できないのと同様に、「空間的な難易度」 を加味しなければ、真の貢献度は見えてきません。
2. 空間統計学のアプローチ:空間相関と異質性の考慮
本モデルでは、シュートが放たれた座標(x, y)に基づき、エリアごとの「失点リスク」を推定します。ここで重要になるのが以下の概念です。
-
空間相関(Spatial Autocorrelation):
- 【概念】近い場所にあるデータ同士は、互いに似た性質を持ちやすいという統計的な性質です。
- 【直感】「ゴール正面のエリアは、右にずれても左にずれても、やはり危険度は高い」という、地続きの関連性のことです。
この空間的なつながりをモデルに組み込むことで、データの少ない地点(エリア)でも、周囲のデータから「その場所の危険度」を妥当に補間することが可能になります。
3. 実装と分析:PyMC v5 による空間ベイズモデル
今回は、各ショットの位置情報を考慮しつつ、選手ごとの能力を階層的に推定するモデルを構築しました。
モデルの構造図
まずは、本分析で採用した確率モデルの構造をご紹介します。

この図は、個々のシュートの成否(Observed Data)が、選手個人の能力(Individual Effect)と、ショット位置による難易度(Spatial Effect)の両方から影響を受けていることを示しています。このように構造化することで、特定の選手が「たまたま難しい位置からのシュートばかり受けていた」といった環境要因を、統計的に切り分けることが可能になります。
TOP 15 選手の推定結果(94% HDI)
次に、モデルによって推定されたセーブ率の事後分布から、上位15名の選手をピックアップして可視化しました。
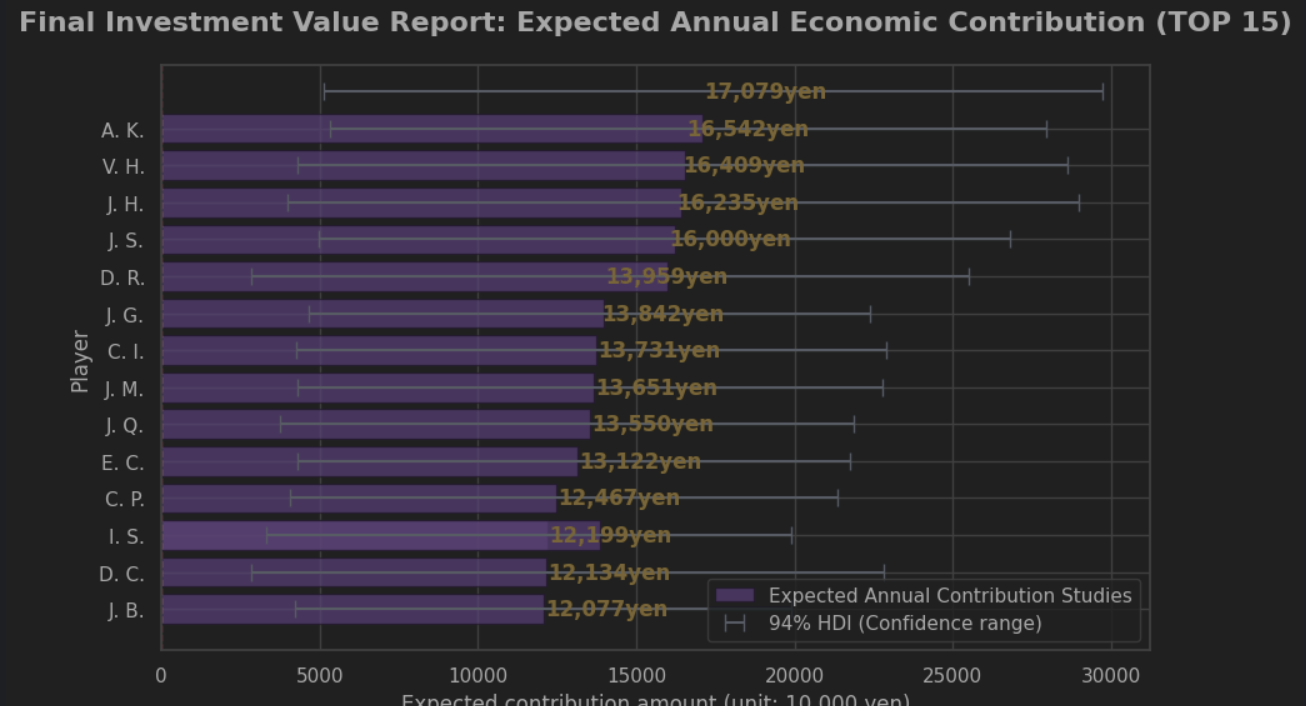
このグラフを解釈する際は、以下の2点に注目することをご提案します。
-
「点」ではなく「幅」で見る:
各選手の能力は一本の線(HDI)として表現されています。この線が短いほど、データが豊富で「推定の信頼度が高い」ことを意味します。逆に線が長い選手は、まだ試行回数が少なく、実力が上振れ・下振れする可能性を秘めていると解釈できます。 -
重なりを確認する:
ランキング上位であっても、多くの選手のHDIが互いに重なり合っていることが分かります。これは、統計的には「現時点では、彼らの実力に明確な差があるとは断定できない」という謙虚な判断材料になります。
4. ビジネスへの応用:エリア特性に応じた最適化
空間統計の考え方は、スポーツ以外でも強力な意思決定の根拠となります。
- エリアマーケティング: 競合店からの距離や人口密度を「空間データ」として扱い、新規出店時の売上予測精度を高める。
- 物流・配送最適化: 配送拠点からの「空間的な偏り」を分析し、配送遅延リスクの高いエリアを事前に特定する。
- 不動産鑑定: 近隣物件の価格(空間相関)を考慮し、個別の物件価値を適正に算出する。
「場所」というバイアスを統計的に取り除く(あるいは活用する)ことで、より公平で納得感のある評価基準を構築できます。
5. 結論:空間を捉え、意思決定の解像度を上げる
数値の背後にある「空間的な構造」を捉えることで、平均値に縛られた分析から脱却できます。階層ベイズと空間統計を組み合わせることで、不確実なデータの中でも「どこにリソースを集中すべきか」が明確になります。
より詳細な分析プロセスや実装コードについては、以下の関連コンテンツも併せてご参照ください。
おわりに
ビジネスベイズの布教活動として経済指標判断での意思決定を支援するための情報を発信しています。
-
GitHub: 本記事で使用したモデルの設計思想などは、こちらのプロジェクトで管理しています。
Bayesian Iroha (GitHub) -
note: 実務に即したデータ分析の考え方を詳しく解説しています。
ベイズ屋 note マガジン -
YouTube: ベイズの勉強をしようと思って AI と議論していたら、何故かオール AI 制作の動画チャンネルが生成されていました。夜中のラブレターモードで取り組んでいるので出来れば観ないで下さい。
ベイジアン、嘘(尤度)つかない 公式チャンネル
ご意見やご感想がございましたら、ぜひコメント欄にてお寄せください。