初めに
半年ほど前からDeep Learningを勉強しており、最近は時系列データの分析に興味が湧いて目下勉強中。
以下のサイトで、元Tableau社員の岩橋氏がやっていることを、python/chainerの勉強も兼ねてやってみたいと思います。
URL: Tableauによるデータ理解から始めるディープラーニング
目的:気象データから電力消費量を予測するモデルを作る
- 説明変数:気象データ + α
- 被説明変数:電力消費量
まだまだ初心者のやっていることですので全然スマートなやり方になっていないと思いますので、「こうした方が良いよ」、「このほうが楽できるで!」的なコメント、お待ちしてます(笑)
少し長いですが、読んでいただけると幸いです。
1. データの取得
データは以下の東京電力及び気象庁のサイトからcsvファイルをダウンロードできます。
東京電力: 過去の電力使用実績データのダウンロード
気象庁: 過去の気象データ・ダウンロード
ここから、2018年のデータ(1年分)を取得する。気象データについては
- 気温
- 降水量
- 日照時間
- 全天日射量
- 現地気圧
- 相対温度
を使ってみることにする(岩橋氏の使っているものと同じ)。
データをダウンロードしたら、pandasで読み込んでみましょう。なお、分析にはGoogle Colaboratoryを使用しました。(最初はJupyter labを使用していたのですがグラフの描画に異常に時間がかかったので、途中からGoogle Colaboratoryに変更)
Google Driveの接続
ファイルの読み込みにはGoogle Driveにダウンロードしたcsvファイルをアップロードしておいて、Google Colaboratoryと接続して使用。
まずはライブラリのインポートから。これ以降も必要に応じてライブラリをインポートします(一度に全部インポートしても良いですが、私は手探りでやったのでこの時は必要な時にインポートしました)。
# ライブラリのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
以下のコードを使うとGoogle ColaboratoryとGoogle Driveを連携できます。ググると詳しいやり方が出てくると思いますので、そちらをご参照ください。
参考: ColaboratoryでのGoogle Driveへのマウントが簡単になっていたお話
# Google Driveと接続
from google.colab import drive
drive.mount('/content/drive')
さて、ここまで来たらファイルの読み込みです。下の「xxx」はGoogle Drive上の任意のフォルダ/ファイル名になります。
# ファイルの読み込み/DataFrameの表示
df = pd.read_csv('drive/My Drive/xxx/xxx.csv')
df
2. 前処理1:読み込み >> データの確認 >> データの結合
(a)気象データ
Pythonによる前処理
上述の岩橋氏はTableau(DeskTop/Prep)による前処理や可視化をしているが、今回はPythonの勉強なので、同じ(ような)作業をPythonのみでやってみたいと思う。
まずは、気象庁のHPからダウンロードした気象データ(data.csvとします)について見ていきます。
ちなみに、Excelだと以下のようになっています。必要ない行や列がありますね。
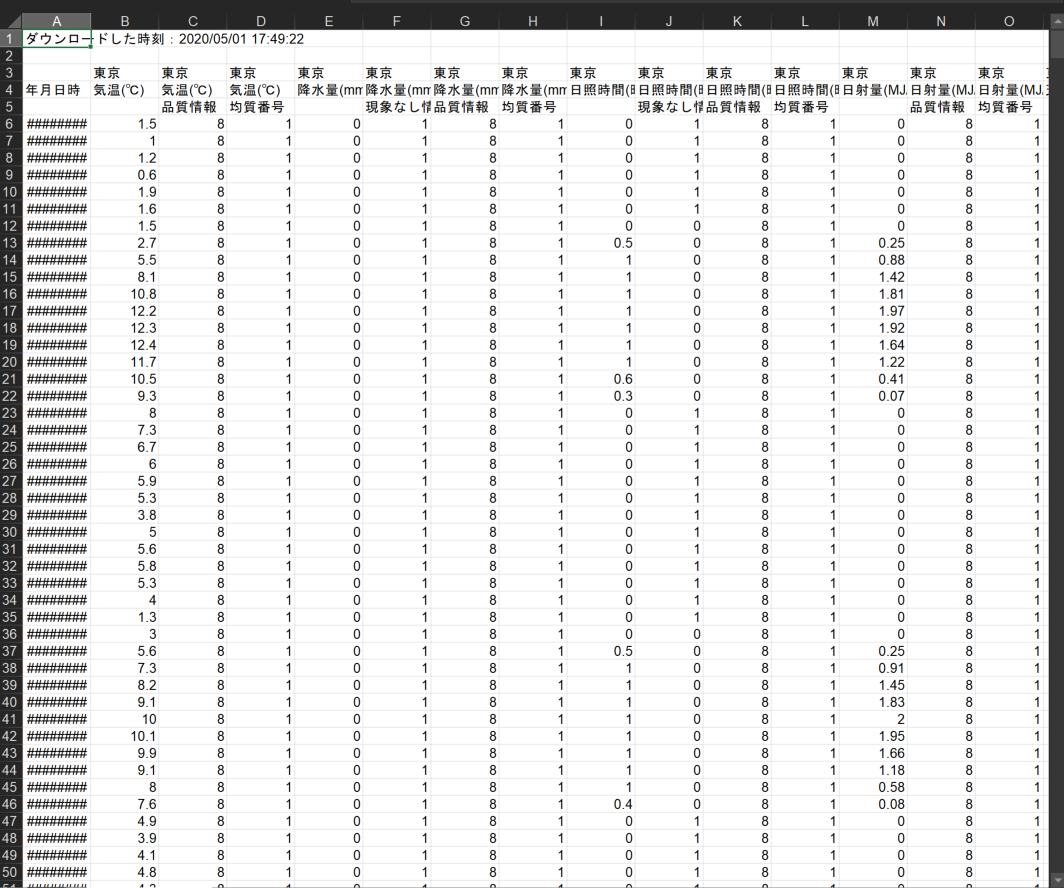
データの整形
このデータセットから使いたい行列を抜き出します。
(ただ、この程度の量のデータセットであったらExcelでいじったほうが楽ちんです。でもここは敢えてpythonで使いたいデータを抽出します(あくまでpythonの勉強です))。
df_weather = pd.read_csv('xxx\weather_data_1_2.csv', header=[0], skiprows=3, engine='python') #,index_col=0
df_weather = df_weather.iloc[1:,[0, 1,4,8,12,18,21]]
df_weather.head()
| 年月日時 | 気温(℃) | 降水量(mm) | 日照時間(時間) | 日射量(MJ/㎡) | 相対湿度(%) | 現地気圧(hPa) |
|---|---|---|---|---|---|---|
| 2018/1/1 1:00:00 | 1.5 | 0.0 | 0.0 | 0.0 | 82.0 | 1009.6 |
| 2018/1/1 2:00:00 | 1.0 | 0.0 | 0.0 | 0.0 | 83.0 | 1009.5 |
| 2018/1/1 3:00:00 | 1.2 | 0.0 | 0.0 | 0.0 | 80.0 | 1009.0 |
| 2018/1/1 4:00:00 | 0.6 | 0.0 | 0.0 | 0.0 | 85.0 | 1008.6 |
| 2018/1/1 5:00:00 | 1.9 | 0.0 | 0.0 | 0.0 | 80.0 | 1008.8 |
と、このような出力になります。
1行目のデータ読み込みの際に、**indexの指定(index_col=)・ヘッダーの指定(header=)・不要な行のスキップ(skiprows)を使って大まかに使いたい形にしてます。2行目で.iloc([])**を使って必要な行・列をとってきています。
次に、列名が日本語だと使いづらいので列名を変更したいと思います。これは、columnsという変数を作ってディクショナリー型で{'変更前','変更後'}というcodeで以下のようにすると一度に変換できます。
# 列名を英語に変換
columns = {'年月日時':'Date_Time',
'気温(℃)':'Temperature',
'降水量(mm)':'Precipitation',
'日照時間(時間)':'Daylighthours',
'日射量(MJ/㎡)':'SolarRadiation',
'相対湿度(%)':'Humidity',
'現地気圧(hPa)':'Airpressure'}
df_weather.rename(columns=columns, inplace=True)
df_weather.head(3)
次にデータ型を確認しましょう。私はいつも以下の3つくらいを確認してます(むしろ他に確認したほうが良いものがあれば教えてください)。
# データ型の確認
print(df_weather.shape)
print(df_weather.dtypes)
print(df_weather.info)
print(df_weather.describe())
複数ファイルの列方向での結合(pd.concat)
気象庁からデータをダウンロードする際、ダウンロードできるデータのサイズが決まっており、1年分のデータをダウンロード数場合には複数回に分けてダウンロードする必要があります(私の場合は、1ファイルに2カ月分のデータしかダウンロードできませんでした)。ですので、複数のファイルをジョインする必要があります。
ここではファイル名をそれぞれ,df_weather1~6とします。
df_weather_integrate = pd.concat([df_weather1, df_weather2, df_weather3, df_weather4, df_weather5, df_weather6],ignore_index=True)
結合後のファイル名をdf_weather_integrated(ちょっと長いですね。。。)として、**pd.concat()**を使って縦方向に6つのファイルを結合しました。
欠損値の確認(.isnull().any / .isnull().sum())
次に欠損値の確認です。欠損値の有無はおなじみの**dataframe.isnull().any()**で確認します。Boolean型(True or False)で返ってきます。
df_weather_integrated.isnull().any()
| 1 | 2 |
|---|---|
| Date_Time | False |
| Temperature | False |
| Precipitation | False |
| Daylighthours | True |
| SolarRadiation | True |
| Humidity | True |
| Airpressure | False |
ここでDaylighthours, SolarRadiation, Humidityの3つに欠損値があることがわかりましたので、それぞれいくつ欠損値があるのか確認しましょう。**.isnull().sum()**で確認します。
df_weather_integrated.isnull().sum()
| 1 | 2 |
|---|---|
| Date_Time | 0 |
| Temperature | 0 |
| Precipitation | 0 |
| Daylighthours | 1 |
| SolarRadiation | 1 |
| Humidity | 27 |
| Airpressure | 0 |
これで気象データの欠損値の数がわかりましたね。後ほど、電力消費量データと一緒に欠損値の処理をしていきます。
(b)電力消費量データ
次に東京電力のHPからダウンロードしてきた電力データを見てみましょう。Excelだと以下のような感じでダウンロードされます。
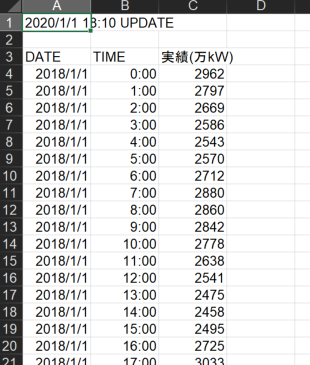
df_Elec = pd.read_csv('xxx\elec_2018.csv',header=[0],skiprows=1, engine='python')
ここでは先ほどと同様にheader, skiprowsで不要な行を取り除いてます。
電力消費量データについても気象データと同様に列名の変更(日本語 >> 英語)・データ型の確認・欠損値の確認をします(詳細は割愛)。
【変換後】
| DATE | TIME | kW | |
|---|---|---|---|
| 0 | 2018/1/1 | 0:00 | 2962 |
| 1 | 2018/1/1 | 1:00 | 2797 |
| 2 | 2018/1/1 | 2:00 | 2669 |
| ・・・ | ・・・ | ・・・ | ・・・ |
ここでお気づきかと思いますが、0行目が2018/1/1 0:00になっています。気象データは2018/1/1 1:00からスタートするので、ここで0行目を削除してインデックスを振り直しておきます。
df_Elec = df_Elec.drop(df_Elec.index[0])
df_Elec =df_Elec.reset_index(drop=True)
df_Elec.head(3)
【再変換後】
| DATE | TIME | kW | |
|---|---|---|---|
| 0 | 2018/1/1 | 1:00 | 2962 |
| 1 | 2018/1/1 | 2:00 | 2797 |
| 2 | 2018/1/1 | 3:00 | 2669 |
| ・・・ | ・・・ | ・・・ | ・・・ |
次に気象データは日付と時間が一つの列に合わさってましたので、電力消費量データの1,2列目を結合して気象データと同じ形になるようにします。ここではpd.to_datetimeで新しい列(DATE_TIME)をdatetime型で作ります。
# DATEとTIMEを結合して、新しくDATE_TIMEを作る
df_Elec['DATE_TIME'] = pd.to_datetime(df_Elec['DATE'] +' '+ df_Elec['TIME'])
df_Elec = df_Elec[['DATE_TIME', 'kW']]
これで、気象データと電力消費量データの結合の準備ができました。それではこの2つのデータを結合させてみましょう。ここでは**pd.merge()**を使っています。
2つのファイルの縦方向の結合(pd.merge)
# 2つのファイルを結合
df = pd.merge(df_weather_integrate, df_Elec ,left_on='Date_Time', right_on='DATE_TIME', how='left')
これで2つのファイルを(横方向)に結合させることができました!ここでこのデータフレームを見てみると、不要な列(DATE_TIME)が残っていたり最終行でkWにNaNがあったりしますので、最後これらを処理していきます。
# 使う行だけ残す
df = df[['Date_Time','Temperature', 'Precipitation', 'Daylighthours', 'SolarRadiation', 'Humidity', 'Airpressure', 'kW']]
# 8759は最終行で電力消費量データと気象データにずれがあるので削除
df.drop(8759,inplace=True)
これでやっとデータ分析できる形になりました!(長かった。。。)
次回は今回前処理したデータをchainerで分析していきたいと思います!
まとめ(備忘)
今回は以下4点をやってみました。
- データ取得
- データの読み込み&確認
- データの整形
- データの結合
次回は、欠損値の処理をやってみたいと思います。