目次
- はじめに
- SQL公式ドキュメント
- SQLの実行順序の確認
- 扱うデータの説明
- SQL(&Python)実行例
- ランダムサンプリング
- Pythonを使ったグラフ化
- その他データ加工、view作成など
- まとめ
- 参考文献、リンクなど
はじめに
会社ではRでデータ取得〜集計&分析までできてしまう環境にいるのでRばかり書いているのですが、近々SQLが必要になりそうなので自分用の備忘録を兼ねて、SQLで色々集計した結果をまとめておきます。
SQL公式ドキュメント集
まずは公式ドキュメント、ということで公式ドキュメントへのリンク集を用意しておきます。
SQLの実行順序
SQLは記述された順序どおりに実行されるわけでなく、以下の順に実行されます。
1. from節 (処理対象テーブルの選択)
2. join処理
3. where節 (絞り込み)
4. group by節 (グループ化)
5. select節
6. having節 (集約後の値を用いた絞り込み)
7. window関数
8. order by節 (ソート)
9. limit節 (絞り込み)
データの説明
今回使うデータはBigQueryのパブリックデータ(Chicago Taxi Data)で、GCPアカウントをもっていなくてもBigQueryのサンドボックスを使って自由にデータ抽出することができます。以下、カラムと内容の説明です。
(BigQueryのサンドボックスについては以前の記事で簡単にまとめました。)
| カラム名 | データ型 | 説明 |
|---|---|---|
| unique_key | STRING | タクシー利用1件ごとのユニークID |
| taxi_id | STRING | タクシーのユニークID |
| trip_start_timestamp | TIMESTAMP | タクシー利用開始時刻(15分間隔で丸めた値) |
| trip_end_timestamp | TIMESTAMP | タクシー利用終了時刻(15分間隔で丸めた値) |
| trip_seconds | INTEGER | タクシー利用時間(秒単位) |
| trip_miles | FLOAT | タクシー利用距離(マイル単位) |
| pickup_census_tract | INTEGER | タクシー利用開始時の道路。なお、プライバシー保護のため、必ずしも全てのデータで入っているわけではない。 |
| dropoff_census_tract | INTEGER | タクシー利用終了時の道路。なお、プライバシー保護のため、必ずしも全てのデータで入っているわけではない。 |
| pickup_community_area | INTEGER | タクシー利用開始時の地域。 |
| dropoff_community_area | INTEGER | タクシー利用終了時の地域。 |
| fare | FLOAT | タクシー利用にかかった運賃 |
| tips | FLOAT | チップ。なお、現金でのチップは記録されていない。 |
| tolls | FLOAT | タクシー利用時の通行料 |
| extras | FLOAT | タクシー利用時の追加料金 |
| trip_total | FLOAT | タクシー利用にかかった費用。(運賃、チップ、通行料、追加料金の合計。) |
| payment_type | STRING | 支払いの種類 |
| company | STRING | タクシー会社 |
| pickup_latitude | FLOAT | タクシー利用開始時の緯度 |
| pickup_longitude | FLOAT | タクシー利用開始時の経度 |
| pickup_location | STRING | タクシー利用開始時の場所 |
| dropoff_latitude | FLOAT | タクシー利用終了時の緯度 |
| dropoff_longitude | FLOAT | タクシー利用終了時の経度 |
| dropoff_location | STRING | タクシー利用終了時の場所 |
実行例
ランダムサンプリング
データの内容確認のため、適当にサンプリングして眺めてみようと思います。
#standardSQL
-- ランダムサンプリング
SELECT
-- chicagoは協定世界時より6時間遅いので6時間遅らせる
TIMESTAMP_SUB(trip_start_timestamp, INTERVAL 6 HOUR) AS chicago_trip_start_timestamp,
EXTRACT(YEAR from TIMESTAMP_SUB(trip_start_timestamp, INTERVAL 5 HOUR)) AS year,
EXTRACT(MONTH from TIMESTAMP_SUB(trip_start_timestamp, INTERVAL 5 HOUR)) AS month,
EXTRACT(DATE from TIMESTAMP_SUB(trip_start_timestamp, INTERVAL 5 HOUR)) AS date,
trip_seconds,
trip_miles,
fare,
tips,
tolls,
extras,
trip_total
FROM
`bigquery-public-data.chicago_taxi_trips.taxi_trips`
-- ランダムに0~1までの値を割り振って、全体の0.1%ほどを抽出する
WHERE
RAND() < 0.001
;
6.7GBを処理し、経過時間は3.6秒ほどでした。
csv形式でダウンロードできるので、ダウンロードします。なお、csvとしてローカルにダウンロードできるのは最大で16000行までのようで、今回のクエリ結果(112472行)のうち16000行だけダウンロードしました。
データの確認
データを見てみます。本来は気の利いたSQLを叩いてデータ確認したり、BigQueryからデータポータルで可視化するのがスムーズなのかと思われますが、今回はPythonを使います。
import pandas as pd
dat = pd.read_csv("/input/random_sample.csv") #先程DLしたデータ
dat.head()
データの中身は以下の通りです。

# データ数確認
dat.shape
# (16000, 11)
# 時間の単位を秒から分に直す
dat["trip_minutes"] = dat["trip_seconds"]/60
# 運賃の単位をセントからドルに直す
dat["fare"] = dat["fare"]/100
# 数値データの確認
dat[["trip_minutes", "trip_miles", "fare", "tips", "tolls", "extras", "trip_total"]].describe().round(2)
基本的な統計量を確認します。
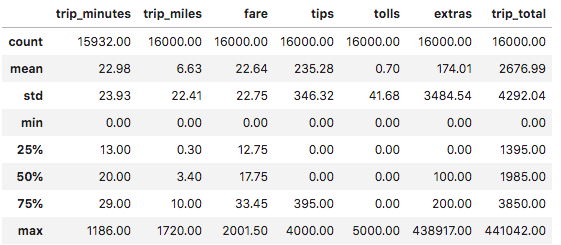
trip_minutesはデータ数が16000未満なので欠損値があるようです。
所要時間と運賃の中央値を見るに、平均的に19分程度の所要時間で運賃は18ドル程度のようです。シカゴに行ったことはないですが、タクシー料金がめちゃくちゃ高い、というわけではないようです。あと、tips、tolls、extrasの中央値が0なので、運賃以外の料金(チップとか)はあまり取られないみたいですね。安心できます。
trip_minutesのNAを除外してから可視化してみます。
# trip_minutesがNAの行を除外
dat_mod = dat[~dat.trip_minutes.isnull()]
# ライブラリのインポート
from matplotlib import pyplot as plt
import seaborn as sns
%matplotlib inline
#グラフテーマの設定、サイズの設定
sns.set(style="whitegrid")
fig = plt.figure(figsize=(10, 7))
# trip_minutesのグラフ
fig.add_subplot(221)
plt.xlim(0, 100)
sns.distplot(dat_mod["trip_minutes"], kde=False, bins=600) #1行1列目
# trip_milesのグラフ
fig.add_subplot(222)
plt.xlim(0, 30)
sns.distplot(dat_mod["trip_miles"], kde=False, bins=800) #1行2列目
# fareのグラフ
fig.add_subplot(223)
plt.xlim(0, 100)
sns.distplot(dat_mod["fare"], kde=False, bins=2000) #2行1列目
可視化した結果
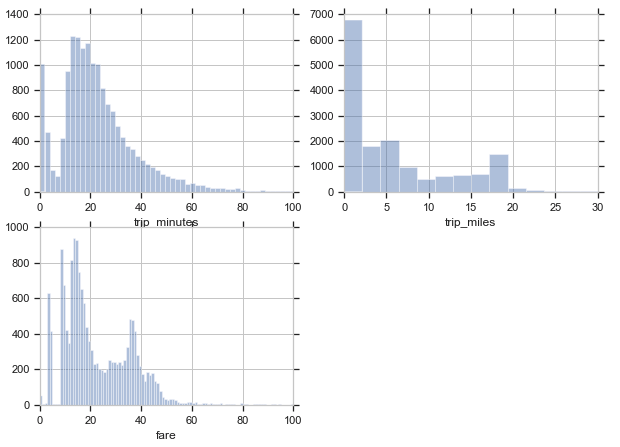
trip_minutesのヒストグラムでは所要時間が0分付近と20分付近でデータ数が多くなっています。
また、trip_milesのヒストグラムから、移動距離については、大半のデータが0mile〜20mileの範囲内に入るようです。
一応、SQLを叩いて元データについて所要時間が0分のデータがどれくらいあるか確認してみます。
#standardSQL
-- 不自然なデータ(乗車時間が0秒あるいは移動距離が0mile)がどれくらいあるか確認
-- trip_seconds, trip_milesがnullの値を除外して再度集計
SELECT
COUNT(*) AS record_count,
-- trip_secondsが0の場合は0のままにし、それ以外では5分間隔の値に加工
CASE
WHEN trip_seconds = 0
THEN 0
ELSE TRUNC((trip_seconds/60)/5*5) -- TRUNC()はX以下の最も近い整数を返す
END AS trip_minutes,
-- trip_milesが0の場合は0のままにし、それ以外では5mile間隔に加工
CASE
WHEN trip_miles = 0 THEN 0
ELSE TRUNC(trip_miles/5)*5
END AS trip_miles_cat,
ROUND(MIN(fare)) AS min_fare,
ROUND(AVG(fare)) AS avg_fare,
ROUND(MAX(fare)) AS max_fare
FROM
`bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE
trip_seconds IS NOT NULL
AND trip_miles IS NOT NULL
GROUP BY
trip_minutes, trip_miles_cat
ORDER BY
trip_minutes ASC, trip_miles_cat ASC
;
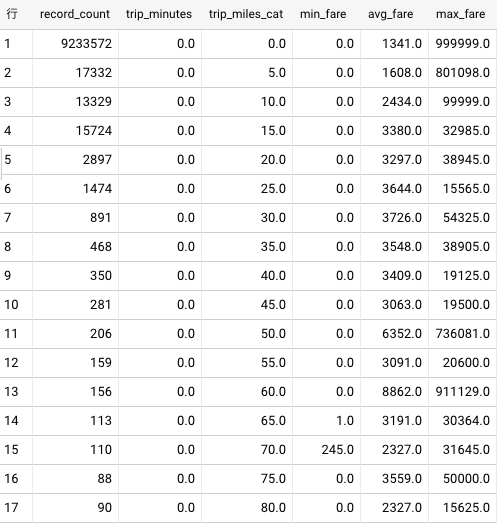
結構ありました。
所要時間が0分近いデータが多い理由はわかりませんが(本当に5分未満の利用だったのかもしれませんが)、ほとんど乗っていないのにタクシー利用データとして使うのは不適切ではないかと思われるので、ひとまずこれ以降では所要時間5分以上のデータをタクシー利用データとして使うことにします。
次に所要時間と移動距離の関係も見ておきます。先程のランダムサンプリングしたデータを用いてPythonで可視化します。
# trip_minutesとtrip_milesの関係を確認
fig = plt.figure(figsize=(10, 7))
ax = sns.scatterplot(x=dat_mod.trip_miles, \
y=dat_mod.trip_minutes)
ax.set_xlim(0, 30)
ax.set_ylim(0, 200)
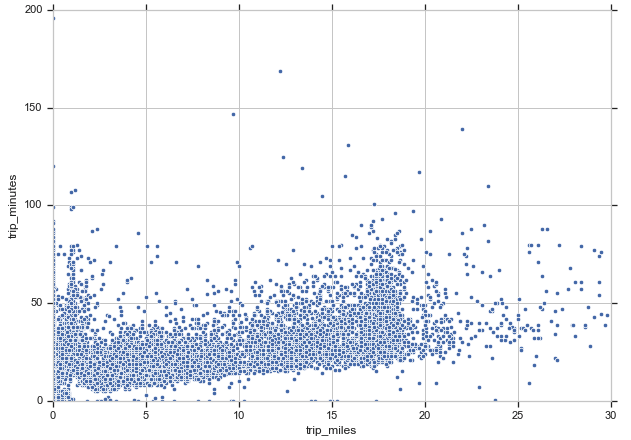
移動距離が伸びるにつれて所要時間が増えるものの、一部、同じ移動距離でも所要時間に幅がある箇所があるようです。利用頻度が高く渋滞しているエリアのデータなのかもしれません。
ここまでランダムサンプリングしたデータを眺めましたが(本来は分析の目的に合わせて更に色々な軸で眺めることと思いますが)、ここからはSQLの練習を兼ねて適当にデータ抽出をしてみます。
時間帯別での1mileあたり所要時間
#standardSQL
-- 時間帯別での1マイルあたり所要時間
-- 所要時間が5分以上のデータに絞って集計
SELECT
COUNT(*) AS record_count,
-- シカゴの時刻は協定世界時より6時間遅いため、6時間引いて現地時間に直す
EXTRACT(hour from TIMESTAMP_SUB(trip_start_timestamp, INTERVAL 5 HOUR)) AS trip_start_hour,
-- 1マイルあたりの所要時間
ROUND(AVG((trip_seconds/60)/trip_miles)) AS minutes_per_mile_avg
FROM
`bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE
trip_seconds >= 60*5
AND trip_miles > 0
GROUP BY
trip_start_hour
ORDER BY
trip_start_hour ASC
;
データ抽出結果
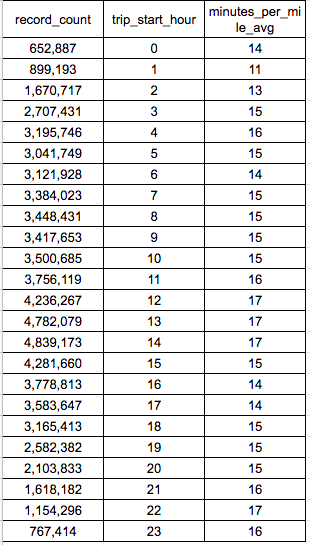
12時〜14時、22時は1mileあたりの平均所要時間が長いです。この時間帯は道路が混み合うのかもしれません。
時間帯別での1回利用あたり移動距離、運賃
#standardSQL
-- 時間帯別での1回利用あたり移動距離、運賃
-- 所要時間が5分以上のデータに絞って集計
SELECT
COUNT(*) AS record_count,
-- シカゴは協定世界時より6時間遅いため、6時間引いて現地時間に直す
EXTRACT(hour from TIMESTAMP_SUB(trip_start_timestamp, INTERVAL 6 HOUR)) AS trip_start_hour,
-- タクシー利用1回あたりの移動距離
ROUND(AVG(trip_miles)) AS trip_miles_avg,
-- タクシー利用1回あたりの運賃
-- 単位をセントからドルに直す
ROUND(AVG(fare/100)) AS fare_avg
FROM
`bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE
trip_seconds >= 60*5
AND trip_miles > 0
GROUP BY
trip_start_hour
ORDER BY
trip_start_hour ASC
;
データ抽出結果
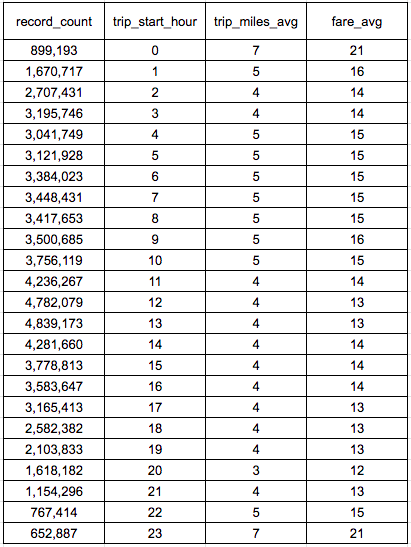
たいていの時間帯で移動距離は4、5mileほど、運賃は13〜16ドルほどなのですが、23時、0時台のデータだけ移動距離と運賃がやや高くなっています。終電に間に合わなくなった人がタクシーを仕方なく使う羽目になり、移動距離、運賃ともに他の時間より高くなっているのかもしれません。
viewの作成
毎回やるような処理を都度書くのが面倒な場合はviewを作成しておくのが便利かと思われるので、練習を兼ねてviewを作成してみます。
#standardSQL
-- 毎回やりそうなデータ加工を済ませたviewを作成
-- viewの名前はprojectIDとdataset名をコロンでつなぎ、table名をつける
CREATE OR REPLACE VIEW `projectID.dataset_name.table_name` AS -- projectIDとdataset名をコロンでつなぐ
(SELECT
unique_key,
trip_start_timestamp,
-- 協定世界時をシカゴ時間に直す
DATETIME(trip_start_timestamp, "America/Chicago") AS datetime_chicago,
EXTRACT(month from DATETIME(trip_start_timestamp, "America/Chicago")) AS month_chicago,
DATE(trip_start_timestamp, "America/Chicago") AS date_chicago,
TIME(trip_start_timestamp, "America/Chicago") AS time_chicago,
trip_miles,
trip_miles*1.6 AS trip_km, -- 距離の単位をkmに変更
ROUND((trip_seconds/60)/trip_miles) AS minutes_per_mile, -- 1mileあたりの所要時間
trip_seconds/60 AS trip_minutes,
trip_seconds/(60*60) AS trip_hour
FROM
`bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE
trip_seconds >= 5*60
AND trip_seconds <= 60*60
AND trip_miles > 0
AND trip_miles <= 20)
;
これで以下のようなviewが作成され、1つのテーブルであるかのように使えます。

タクシー乗車地点別、1マイルあたり移動するのにかかる時間
エリアによって混み具合が違うと思うので、エリアごとにどれくらい所要時間が変わるのか見てみようと思います。ただし、「どのエリアを走っていたか」というデータはないので、代わりにタクシー利用開始時の地域(pickup_community_area(数値データ))を使って集計してみます。
#standardSQL
-- タクシー利用開始地点別での、1マイルあたり所要時間の平均値
SELECT
taxi_data.pickup_community_area,
COUNT(*) AS record_count,
ROUND(AVG(view_data.minutes_per_mile), 2) AS minutes_per_mile_avg
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` AS taxi_data
INNER JOIN `projectID.dataset_name.table_name` AS view_data -- 先程作成したview
ON taxi_data.unique_key = view_data.unique_key
WHERE
taxi_data.pickup_community_area IS NOT NULL
GROUP BY
taxi_data.pickup_community_area
ORDER BY
minutes_per_mile_avg ASC
;
データ抽出結果(一部抜粋)
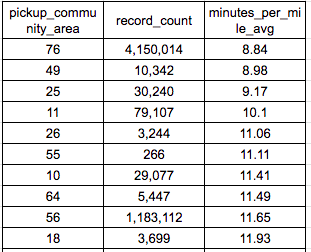
散布図で見てみます。
#taxi_minutes_per_mile.csvは、抽出結果をcsvでDLしたもの
taxi_duration = pd.read_csv("/input/taxi_minutes_per_mile.csv")
fig = plt.figure(figsize=(20, 10.5))
sns.barplot(x = "pickup_community_area",
y = "minutes_per_mile_avg",
data = taxi_duration, color = "gray")
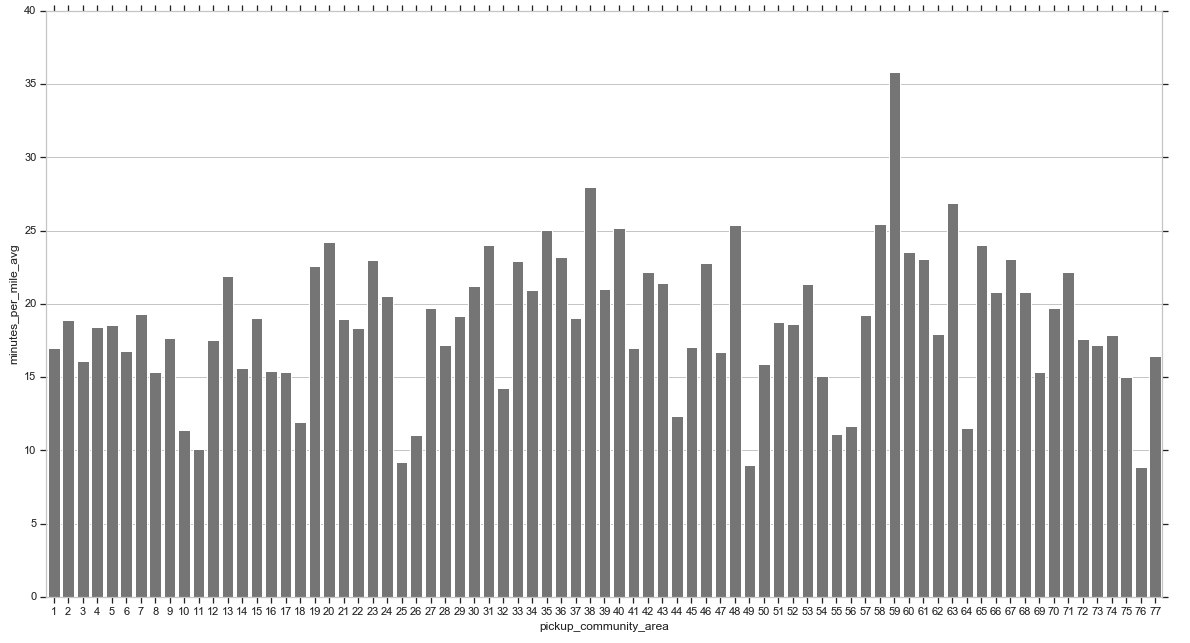
乗車場所(pickup_community_area)によって、1mileあたりの平均所要時間はまちまちなようです。早ければ10分、遅ければ25分といったところでしょうか。1箇所だけ、1mileあたり35分ほどかかる場所もあるようです。
タクシー会社ごとの月次売上
タクシー会社別で、月次の売上推移を出してみます。chicago taxi datasetには2013年〜2017年4月までのデータが入っていますが、ひとまず2016年の1年間での売上推移について集計することにします。
会社ごとに月単位でGROUP BYすれば良いのですが、その場合売上が0の月は集計結果に出ないことになります。今回は売上が0の月があっても1行残るように集計したいので、単なるGROUP BYでなく配列を利用することにします。
#standardSQL
-- 会社名のユニークなリスト
WITH company_list AS (
SELECT
DISTINCT taxi_data.company
FROM
`bigquery-public-data.chicago_taxi_trips.taxi_trips` AS taxi_data
INNER JOIN `projectID.dataset_name.table_name` AS view_data -- 先程作ったviewとjoin
ON taxi_data.unique_key = view_data.unique_key
WHERE
taxi_data.company IS NOT NULL
AND taxi_data.trip_total IS NOT NULL
AND EXTRACT(year from view_data.date_chicago) = 2016
),
-- 1〜12の連番を作成し、会社名ごとに紐づけ
company_monthly_list AS (
SELECT *
FROM
company_list
CROSS JOIN (SELECT GENERATE_ARRAY(1, 12, 1) AS month) -- 1〜12までの連番を作成
),
-- 1〜12の連番は配列のままでは集計できないため、UNNESTする
company_monthly_list_mod AS (
SELECT
company,
month
FROM
company_monthly_list,
UNNEST(month) AS month
),
-- 会社ごとの月次の売上を集計
company_sales AS (
SELECT
taxi_data.company AS company,
view_data.month_chicago AS month,
SUM(taxi_data.trip_total) AS sales
FROM
`bigquery-public-data.chicago_taxi_trips.taxi_trips` AS taxi_data
INNER JOIN `projectID.dataset_name.table_name` AS view_data
ON taxi_data.unique_key = view_data.unique_key
WHERE
taxi_data.company IS NOT NULL
AND taxi_data.trip_total IS NOT NULL
AND EXTRACT(year from view_data.date_chicago) = 2016
GROUP BY
taxi_data.company,
view_data.month_chicago
ORDER BY
taxi_data.company,
view_data.month_chicago ASC
),
-- 月次売上と累積売上を集計し、売上がない月は0が入るよう修正
company_monthly_sales AS (
SELECT
company_list.company AS company,
company_list.month AS month,
company_sales.sales AS sales,
-- 累積売上を見たい場合はwindow関数を使う
SUM(company_sales.sales)
OVER (
PARTITION BY
company_sales.company
ORDER BY
company_sales.month
ROWS BETWEEN
UNBOUNDED PRECEDING AND CURRENT ROW
) AS company_cumulative_sales
FROM
company_monthly_list_mod AS company_list
LEFT JOIN company_sales
ON company_list.company = company_sales.company
AND company_list.month = company_sales.month
ORDER BY
company_list.company,
company_list.month)
SELECT
company,
month,
COALESCE(sales, 0) AS sales, -- 売上がNULLの行に0を代入
COALESCE(company_cumulative_sales, 0) AS company_cumulative_sales -- 累積売上がNULLの行に0を代入
FROM
company_monthly_sales
;
ややゴリ押しなクエリになってしまった気もしますが、今回は動いたので良しとします。速度面、スキャンデータ量の面で効率の良いクエリを書くことは今後の課題ですね。
データ抽出結果(一部抜粋)
会社ごとに月次の売上が集計できていますが、会社名の先頭の数字が気になります。
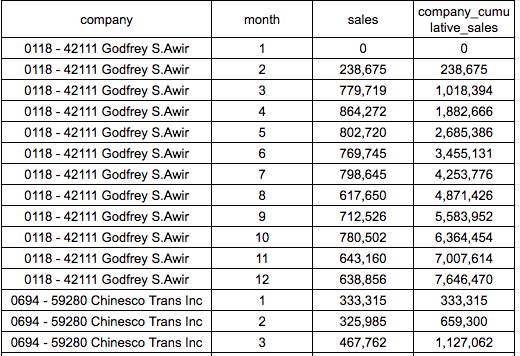
以下、Pythonで結果を細かく見てみます。
# BigQueryで抽出したタクシー会社ごとの月次売上データ
company_sales = pd.read_csv("/input/company_monthly_sales.csv")
# データ数確認
company_sales.shape
# (648, 4)
#運賃がセントだと分かりづらいのでドルに直す
company_sales["sales"] = company_sales["sales"]/100
company_sales["company_cumulative_sales"] = company_sales["company_cumulative_sales"]/100
#会社名の表記の修正
company_sales["company"] = company_sales.company.str.lower() #小文字変換
company_sales["company"] = company_sales.company.str.replace("[0-9]+ - [0-9]+ - |[0-9]+ - [0-9]+ |[0-9]+ - | inc| inc.", "") #先頭にある数字の除去、表記ゆれの修正
company_sales["company"] = company_sales.company.str.replace("c & d cab co.|cd cab co", "c&d cab co") #表記ゆれの修正
#タクシー会社ごとの売上げランキング
sales_ranking = pd.pivot_table(
data = company_sales,
values = "sales",
aggfunc = "sum",
index = "company").sort_values("sales", ascending=False)
#上位5社を表示
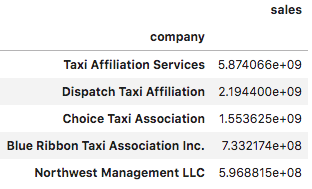
sales_ranking.head()
シカゴにおけるタクシー利用での売上上位は以下の5社で、売上TOPは「Taxi Affiliation Services」でした。
続いて、グラフ化してみます。
#行名を削除して列に追加
sales_ranking = sales_ranking.reset_index()
#上位5社に絞る
company_sales_top5 = company_sales[company_sales.company.isin(sales_ranking.company[0:5])]
#月次の売上推移のグラフ化
fig = plt.figure(figsize=(10, 7))
ax = sns.lineplot(x="month", y="sales",
hue="company", style="company",
data=company_sales_top5,
linewidth=2.5)
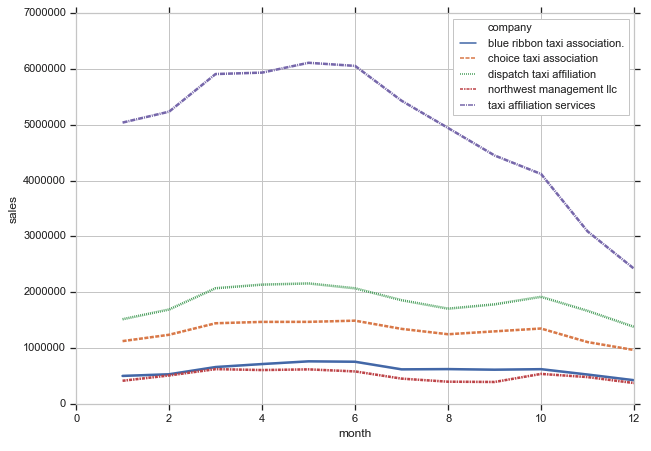
Taxi Affiliation Servicesだけ飛び抜けて売上が高いですが、4月〜6月の売上が高く、10月から12月にかけて売上が落ちるという特徴はどの会社でも似ています。それにしても、Taxi Affiliation Servicesの落ち込み具合は激しいですね。タクシー業界にUberが参入した影響なのかもしれません。
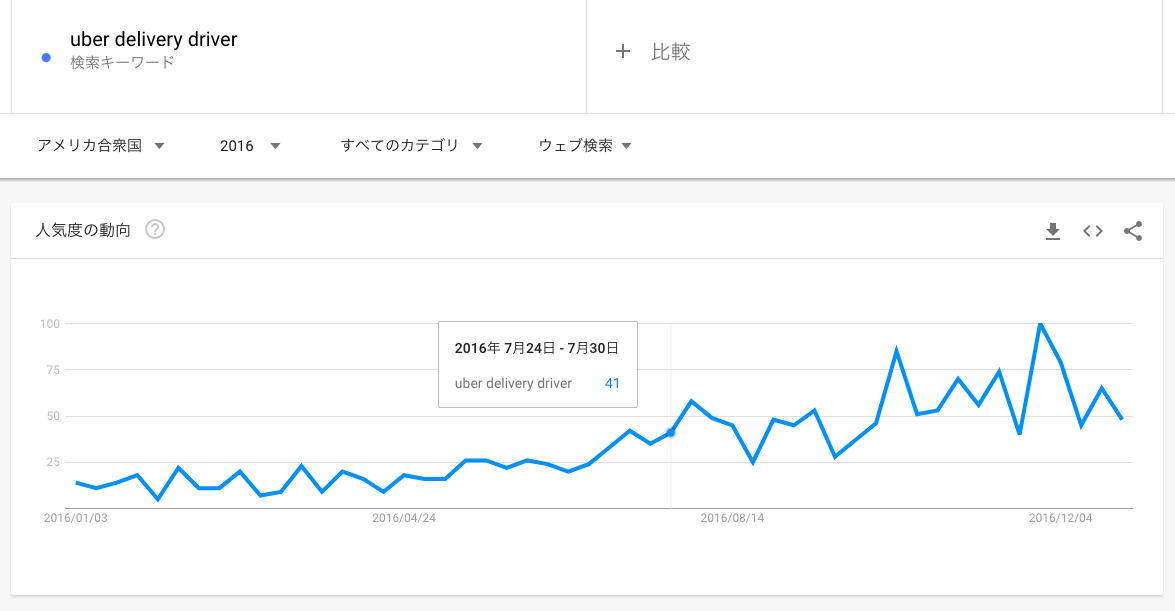
実際、「Uber delibery driver」という検索クエリのアメリカにおける推移を見ると、2016年7月頃から伸びているようです。
まとめ
色々手を動かしてみて、BigQueryの速さを実感するとともに、SQLで細かい集計をすることの大変さが身にしみました。細かい集計についてはやはりPythonやRのほうが簡単に記述できるように思います。また、同じ処理でもクエリの書き方は複数通りあると思いますが、今後は速度やスキャンデータ量の観点でより効率的なクエリをかけるようにしたいと思いました。