はじめに
薄紅色の柔らかなそよ風が恋しい今日この頃皆様いかがお過ごしでしょうか?
はじめまして。
某総合電機メーカ・某設計部門(機械設計)に属する 六花 牡丹(りっか ぼたん)と申します。
とある事情でこちらのサイトに不定期で記事を載せることがございます。
本記事ではMambaに関するアルゴリズム・数学的な原理に加え、独自に開発した学習・推論コードを示すことで基礎から応用までをカバーしています。
拙筆ではございますが、皆様のお役に立つことを心から願っております。
未熟者故、記事中にて誤記・欠落などが見られることがございます。
もし発見しました場合には、コメント等にてご指摘いただきますようお願い申し上げます。
私は記事を一般に周知する手段を有していないため、もし記事が有用であると判断された場合には、X(旧Twitter)等で拡散していただけますと幸いです。
2024/02/13 追記:
X(旧Twitter)アカウントを作成しました。
六花牡丹のX(Twitter)アカウント
ここで最新の進捗や技術に関する情報(時々近況)を共有していきますので、もしよろしければフォローなどよろしくお願いいたします。
執筆動機
本記事執筆時点(2024年2月初旬)で、Mambaに関する記事があまり存在しないため、技術の周知を行い、もって日本国の科学技術発展に寄与することを目的とする。
対象とする読者
・pythonを用いたプログラミングは最低限行うことが可能である。
・CNNやRNN、Transformerの構造についてはある程度理解している。
・最新のアーキテクチャを用いた研究・開発を行いたい。
次世代のアーキテクチャMambaの徹底解説
MambaはCNNやTransformerのようなネットワークアーキテクチャの一種です。
これまでのネットワークアーキテクチャと同様に、画像データ・文書データを与えた場合に、線形・非線形的な処理を通じて、クラスタリング等を行うことが可能になっています。
本記事では以下の流れに沿って解説を行っていきます。
1.お忙しい方へ(要約)
2.Mambaが生まれた背景
3.Mambaとは?
4.状態空間モデル(SSM)とは?
5.構造化状態空間モデル(S4)の欠点とMambaへの発展
6.Selection Mechanism
7.GPUメモリ構造を意識したアルゴリズム(Algorithm aware of GPU memory structure)
8.シンプルなアーキテクチャ
9.原論文中のグラフの説明とMambaの汎用的かつ高性能な推論能力
10.議論
11.Mambaの今後の研究課題の予想(私的主観)
12.Mambaの最新研究動向(GitHubリポジトリベース)
13.謝辞
14.最後に
参考論文・記事等(リンク)
1.お忙しい方へ
Mambaの概要は次の通りです。*1 *2
1.MambaはAttentionやMLPBlockを持たない簡素化されたアーキテクチャを有します。選択的状態空間モデル(Selective SSM:Selective State Space Model)という新しい構造を用いることで、必要な情報のみに注目し、計算効率の大幅な向上を達成しています。
2.高速な推論(Transformerの約5倍)を可能にするとともに、シーケンス長(トークン数などのこと)の増大に対して、推論コストが線形に増大するという特徴を有します(これまでのモデルでは非線形的な増大がありました)。この性能向上は実データにおける検証で、シーケンス長が1000k(100万)においてまで確認されました。
3.GPUメモリ階層間の移動を最小限化するとともに、ハードウェアに最適化された並列アルゴリズムにより高速な計算が可能になり、要求されるメモリ容量も軽減されます。
4.パラメータ数2.8B以上の場合においてMambaは機能するのか、ハイパーパラメータのチューニング方法はTransformerなどと同じなのか、学習の不安定性はどうなのかといった点に関してはまだ不明であり、今後の研究が待たれます。
5.まだ不明な点も多いですが、様々な角度からの研究によって、Transformerを代替しうる有望なアーキテクチャであるというエビデンスも取得されつつあり、今後Mambaは最先端の研究の中心となる可能性が高いと考えられます。
*1より引用
2.Mambaが生まれた背景
1.Transformerを基盤とするモデルが実応用世界を席巻しているなか、研究者はTransformerを代替しうる新たなアーキテクチャを模索していました。Transformerはデータ間の複雑な関係を捉えられることから、2017年にブレイクスルーを引き起こしましたが、一方でシーケンス長に対する2次的な計算コスト増大やメモリ使用量の大きさが問題となっていました。*3
2.状態空間モデル(SSM:State Space Model)は音声や視覚のような連続的な信号データを含む領域では成功を収めていましたが、テキストや画像のような離散的で情報密度の高いデータのモデル化では性能を発揮していませんでした。*4 *5 *6
以上の背景から、Transformerより精度・計算効率の高いモデルの開発および状態空間モデルのテキスト・画像への応用が望まれていました(実際にはRetNetやRWKVなど新規のアーキテクチャは登場していましたが、Mambaの新規性は他を大きく凌駕するものでした)。
3.Mambaとは?
Mambaは2023年12月1日にAlbert Gu, Tri Daoによって発表された新しいネットワークアーキテクチャです。
基礎となっているのは状態空間モデル(SSM)と呼ばれるモデルであり、このモデルに
1.選択的なメカニズム
2.ハードウェア設計に最適化されたアルゴリズム
3.AttentionやMLPブロックを排した簡素なアーキテクチャ
という3点の新規性を組み込むことでTransformerを凌駕しうるモデルであることを示しました。
発表時点からその潜在的可能性が人工知能研究者の間で大きな話題となり、海外のみならず、日本の研究機関においても研究が進められています。*7
4.状態空間モデル(SSM)とは?*1 *8
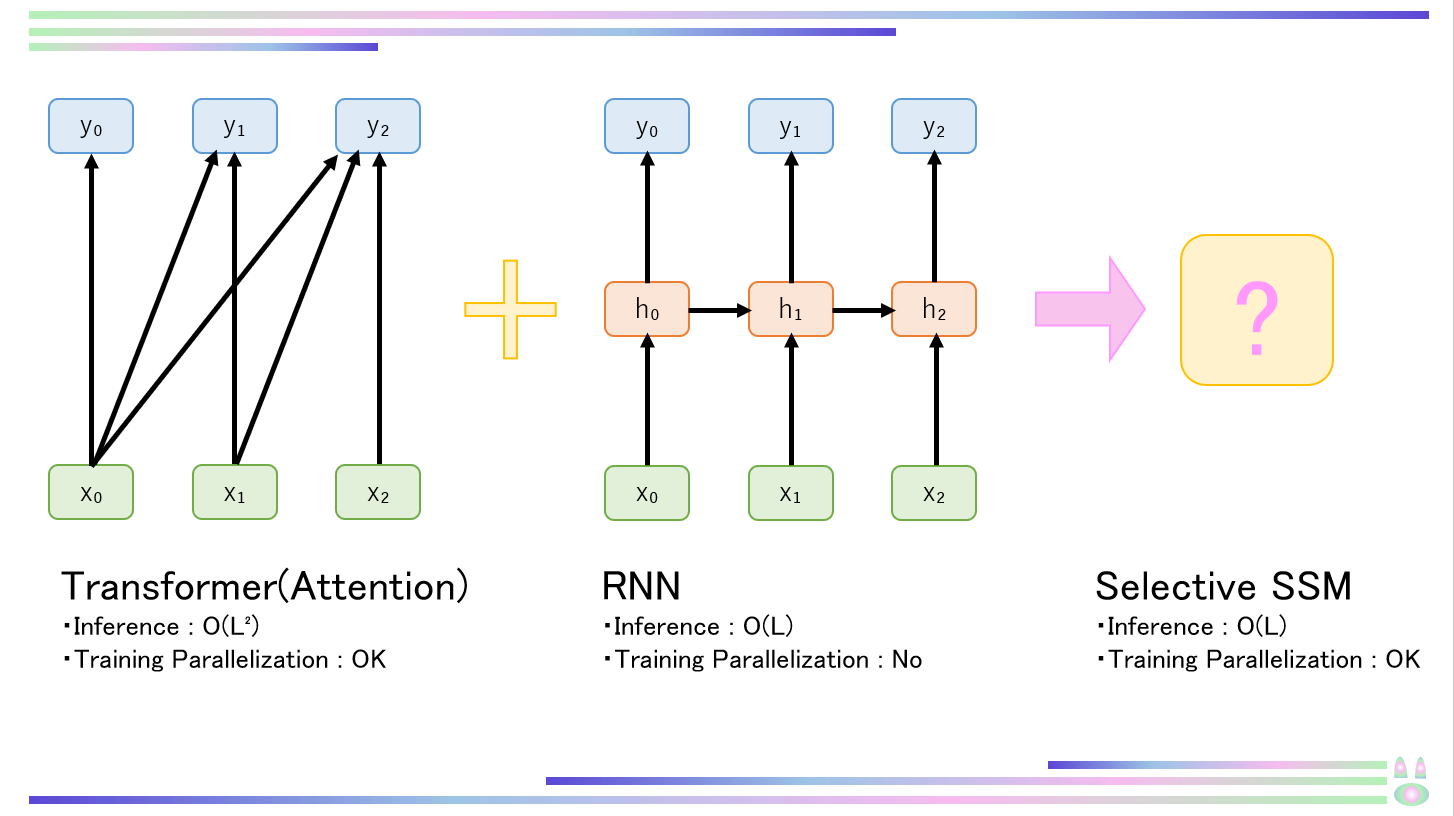
この章では構造化状態空間モデルS4の仕組みを理解し、Mamba(Selective SSM)を理解する足掛かりとします。状態空間モデルとは系列から系列に対する変換器のことです。推論時はRNNのようにO(L)のオーダで動作し、学習時はTransformerのように並列化された処理が可能という2つのモデルのいいとこどりをしたようなモデルです。時系列分析や制御工学で扱われてきた古典的な状態空間モデル*9から着想を得たものであり、リカレントニューラルネットワーク(RNN)と畳み込みニューラルネットワーク(CNN)を組み合わせたものと解釈できます。状態空間モデルは以下のように定式化されます。
\left\{
\begin{array}{l}
h'(t) = Ah(t) + Bx(t) \\
y(t) = Ch(t)
\end{array}
\right.
ここでA,B,Cは入力x(t)に対して不変であることに注意してください(Selective SSMではx(t)に依存するようになります)。状態空間モデルはx→yの連続写像ととらえることができます。
この式は仮想的に対象を連続信号として扱いましたが、言語や画像においては離散化された(discretization)値を取り扱う必要があります。
したがって、上記の式を離散化すると(必要に応じてEuler法による離散化の例をご覧ください)、
\left\{
\begin{array}{l}
h_{t} = \bar{A}h_{t-1} + \bar{B}x_{t} \\
y_{t} = \bar{C}h_{t}
\end{array}
\right.
と変形できます。これにより式は離散的かつ再帰的なものとなります。h₋₁=0として、この式を次数ごとに書き下してわかりやすくすると、
\begin{array}{l}
h_{0} = \bar{A}h_{-1} + \bar{B}x_{0} = \bar{B}x_{0} \qquad y_{0} = \bar{C}h_{0} = \bar{B}\bar{C}x_{0} \\
h_{1} = \bar{A}h_{0} + \bar{B}x_{1} = \bar{B}\bar{A}x_{0} + \bar{B}x_{1} \qquad y_{1} = \bar{C}h_{1} = \bar{C}\bar{B}\bar{A}x_{0} + \bar{C}\bar{B}x_{1} \\
h_{2} = \bar{A}h_{1} + \bar{B}x_{2} = \bar{B}\bar{A}\bar{A}x_{0} + \bar{B}\bar{A}x_{1} + \bar{B}x_{2} \qquad y_{2} = \bar{C}h_{2} = \bar{C}\bar{B}\bar{A}\bar{A}x_{0} + \bar{C}\bar{B}\bar{A}x_{1} + \bar{C}\bar{B}x_{2} \\
y_{k} = \bar{C}h_{k} = \bar{C}\bar{B}\bar{A} ^{k}x_{0} + \bar{C}\bar{B}\bar{A} ^{k-1}x_{1} + ・・・ + \bar{C}\bar{B}x_{k} \\
\end{array}
となり、したがって
y = x * \bar{K} \qquad \bar{K} = \bigl(\bar{C}\bar{B}, \bar{C}\bar{B}\bar{A}, ・・・, \bar{C}\bar{B}\bar{A} ^{k},・・・\bigr)
という式で表すことができます。この式からわかる通り、状態空間モデルは1次元の畳み込みとして表現することができます。訓練時は入力xは事前に知ることができることから、
\bar{K}
は事前計算可能であり、これを用いた畳み込み計算を並列的に扱うことが可能です(畳み込み自体はFFT/iFFT等によって高速化可能なことが知られています)。
以上より、状態空間モデルは1次元の畳み込みとして扱え、かつ高速に計算可能なことが分かりました。
一見通常の状態空間モデルは上手く動作するように思えますが、問題を抱えています。
状態空間モデルにおいて、状態hに過去の情報すべてを記憶させており、
\bar{A}
はh同士(時刻t-1と時刻t)をつなぐ役割を担っています。この値はランダムな初期値からスタートする上手く計算できず、かつ高次においてはk乗の計算を行うため、非常に計算量が大きくなってしまいます。
この問題に対処するために考案されたのがHIPPO行列という良い性質(理論的な強度を維持したまま計算効率を向上させることができる)を有する行列を利用した構造化状態空間モデル(S4)です。HIPPO行列は
\bar{A}_{nk} = -\left\{
\begin{array}{l}
(2n + 1)^ {1/2} * (2k + 1)^ {1/2} \qquad \bigl(n > k \bigr) \\
n + 1 \qquad \bigl(n = k \bigr) \\
0 \qquad \bigl(n < k \bigr)
\end{array}
\right.
と表されます。詳しい導出やHIPPO行列の性質に関しては構造化状態空間モデルの原論文*10をご覧ください。
以上より、系列から系列への変換器であり、かつRNNと同じくO(L)のオーダで推論可能・Transformerのように並列処理可能で、計算効率が非常に高いモデルである、構造化状態空間モデル(S4)が導けました。
構造化状態空間モデル(S4)は行列Aに構造を与えるという点から名づけられており、Mambaにおいても最も一般的な対角構造を取り入れています。*5
5.構造化状態空間モデル(S4)の欠点とMambaへの発展
先の注意点でも述べた通り、構造化状態空間モデル(S4)においては、係数
\bar{A}, \bar{B}, \bar{C}
は入力xに依存しません。そのため動的な推論ができないという欠点を抱えていました(原論文中ではこの性質は線形時間不変性(LTI:Linear Time Invariance)と呼ばれ、LTIのSSMは本質的には線形再帰や畳み込みと同値であると語られています)。それでは、係数を固定化せず、入力xに依存するようにすればいいのではないかと考えるかもしれませんが、それでは畳み込み(並列化)ができなくなってしまいます(入力xに応じてKが変化し、事前計算・並列化が不可能になる)。
そこで筆者らが編み出したのが
Selective CopyingとInduction Headsを組み合わせたSelection Mechanism
畳み込みの並列化の代わりに行われるparallel scan・kernel fusion・活性値の再計算
という手法です。
ここからはMambaの新規性である、Selection MechanismとGPUのメモリ構造を意識したアルゴリズムについて解説していきます。

*1の図をもとに作成
6.Selection Machanism
先でも述べた通り、Selection MechanismはMambaにおける重要な新規的手法であり、Mambaの学術的価値の中心を担っています。基本コンセプトは、RNNにおける文脈圧縮による精度悪化に対処しつつ、Transformer(Attention)の自己回帰的推論が全コンテキストを明示的に保存してしまうという非効率な推論・学習に対処するということです。つまり、Transformerと同様のコンテキストに基づいた高度な推論能力を有しながら、RNNのような効率的な推論をSSMという基盤の上で達成しようとしているのです。
ではそんな夢みたいな所業をどのように達成しているのでしょうか?
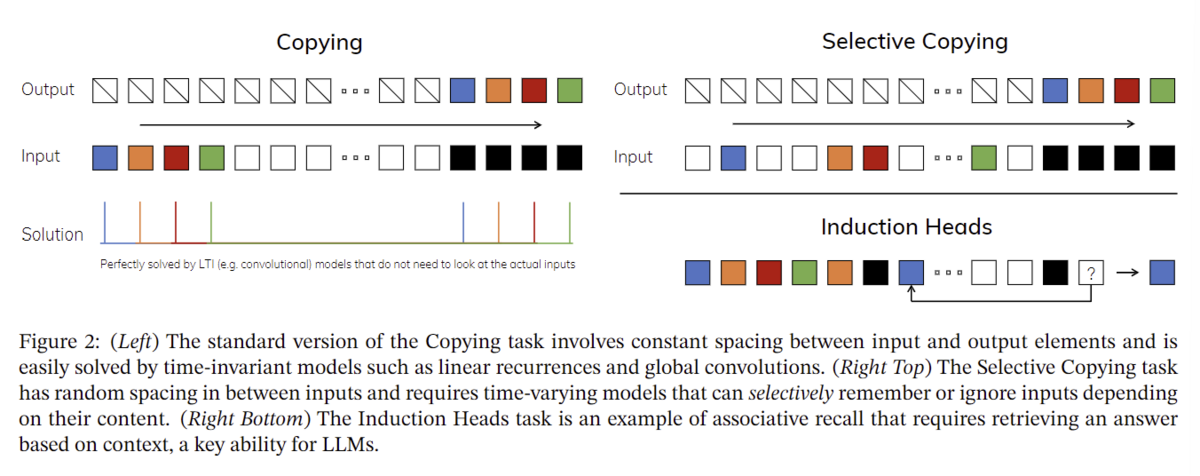
Selection MechanismではSelective Copyingという手法を用いて無関係なノイズトークンをフィルタリングして選択的に内容をコピーし、Induction Headsという手法を用いてそれまでのコンテキストから出現するパターンを予想しています(Induction Heads自体は*11で考案されており、この論文の新規的な手法というわけではありません)。
筆者らが編み出したのはSelective Copyingであり、Induction Heads(Attentionの機械的解釈可能性(リバースエンジニアリング)のために編み出された手法。現在のトークン以前のシーケンスを学習し、同じパターンが出現するかどうかを予測するアルゴリズム(Sequence[A][B]・・・⇨[A]→[B])。)はこの論文において本質的ではないため説明は割愛します。もし気になる方はこの記事の参照にある*11の論文を読んでください。
ここからはSelective Copyingの数学的原理について説明していきます。
まず初めに注意してほしい点としては、Selective Copyingは単一の手法というわけではなく、CNNやRNNを用いたり、様々なパラメータ(4章の行列Aなど)、様々な変換によって実装されるより広範な概念であるということです。
ここでは論文中でより重要な機構であると説明されているRNNのゲーティング機構について説明していきます。
意外に思われる方もいるかもしれませんが、RNNのゲーティング機構はSelection Mechanismの一種であると捉えることができます。
RNNのゲーティング機構と連続時間システムの離散化はすでに確立されている事象のため、説明は割愛します(詳しくは原論文の引用論文を見てください)。
原論文の付録Cではこの記事の参照*12の論文中に示されている0次ホールド離散化公式による漸化式導出に関する式変形を示しつつ下記式を導出しています。


*1より引用(0次ホールド離散化公式を用いた導出過程)
\begin{array}{l}
g_{t} = \sigma(Linear(x_{t})) \\
h_{t} = (1 - g_{t})h_{t-1} + g_{t}x_{t}
\end{array}
この式を見ても正直ピンとこないかもしれませんが、私の作成した下記図を見てください。
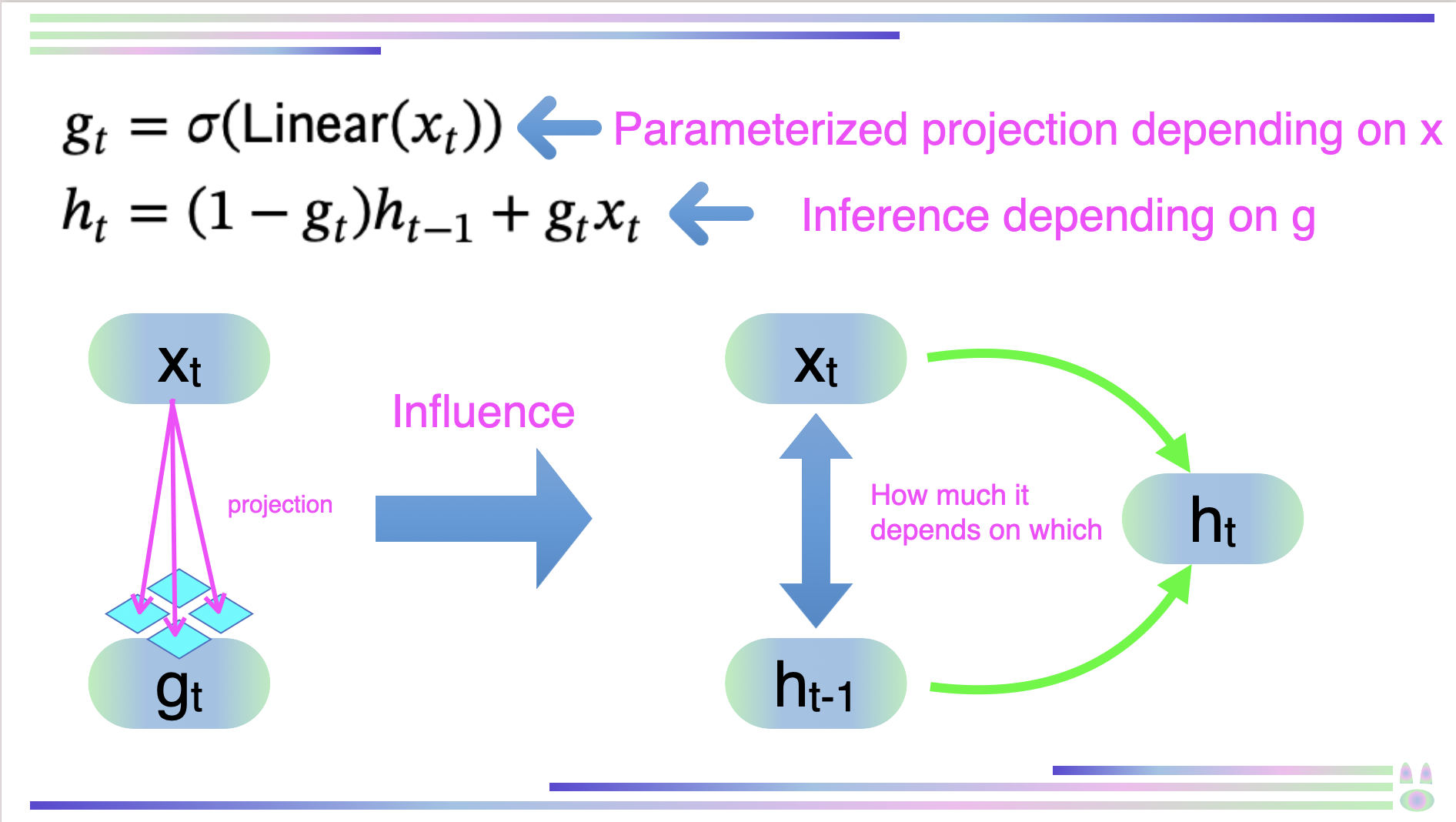
この図で示されている通り、gはxから特定のパラメータにより支配された射影により求められます。このgによってhは
\begin{array}{l}
x_{t} \\
h_{t-1}
\end{array}
の二つのパラメータのうちどちらにどれだけ依存しているか決定されます。
つまり、入力xに依存したパラメータにより入力xと中間状態hのどこをどのくらい反映するかを決定することができ、これにより選択的コピーが達成されます。
原論文中ではSelection Mechanismの各パラメータをどのように解釈すればよいかという点に関して、詳しい言及がなされています。Selection Mechanismは可変間隔によってノイズトークンを選択的にフィルタリングすることが可能であり、この間隔はパラメータの一つとなっています。
∆の解釈も大事になっています。∆は入力xの情報をどれだけ重視するかを表しています。∆が小さければ現在の状態を維持しようとして入力xを無視し、∆が大きければ入力xにより状態hを大きく変化させます。
行列Aは選択的に決定できますが、∆との相互作用を通してモデルに影響を与えるという点に注意が必要です。そのため、∆と同様の効果があると考えられ、∆とAを選択的に決定することでモデルの設定を考えることができます。
行列B, Cは文脈を圧縮し、ノイズトークンをどのように取り除くかという点に影響を与えます。
また、文脈のフィルタリングも可能であり、選択的モデルはいつでも状態をリセットして余計な履歴を取り除くことができるので、原理的にはコンテキストの長さに応じて単調に性能が向上します。
これまでデファクトスタンダードとなっていたTransformerはご存じの通り、文と文の境界を特殊なトークン[SEP]によって識別していました。対してMambaでは文の情報を持ち越したり、恣意的に前の文で生じた状態を境界でリセットすることも可能です。
*1より引用
7.GPUメモリ構造を意識したアルゴリズム(Algorithm aware of GPU memory structure)
ここまで、Mambaの新規性の一つ目であるSelection Mechanismについて説明してきました。
この章では、もう一つの新規性であるGPUメモリ構造を意識したアルゴリズムについて説明していきます。
先でも述べた通り、Mambaではparallel scan・kernel fusion・活性値の再計算という3つの手法を畳み込みの並列化の代わりに用いています。
まずparallel scanについて説明していきます。
parallel scanは一言でいえば、SSMの再帰計算をscanとみなすことで、並列的に扱うことを可能にする技術です(元々PostgreSQL 10で導入されたことで有名なアルゴリズムであり、再帰計算をscanとして扱う以外は特段奇抜なアイデアというわけではありません)。
下記図の通り、入力をペアに分解していき、二分木上で総和を計算していきます。同じ階層に存在するペア同士の計算は並列化可能であることを利用しています。詳しくは*13の記事をご覧になるか、特にPostgreSQL 10の機能について調べてみてください。
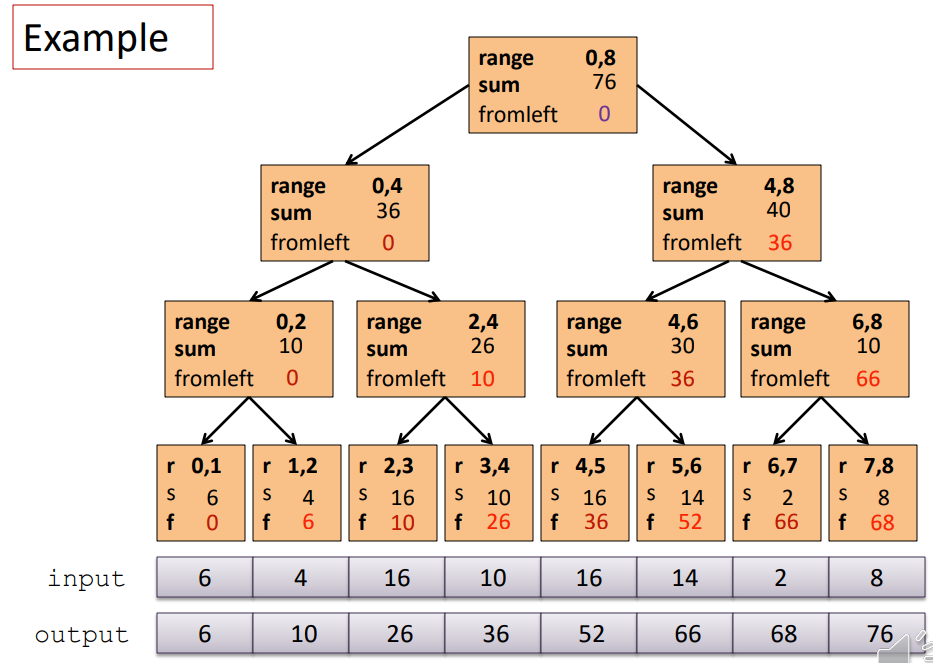
*13より引用
次にkernel fusionと活性値の再計算について説明していきます。
まず初めに理解していただきたい点として、モデルにおける推論・学習のボトルネックはHBMとSRAMという2つのメモリ間の移動にあるということです。
HBM(High Bandwidth Memory)はシリコンダイ積層技術とTSV(Through Silicon Vias)技術(高密度配線と垂直方向のメモリ積層)によって実現した超高速DRAM技術です(従来のDRAMに比べれば)。非常に広い帯域幅により、高いデータ伝送速度を有します。DRAMの一種ということからもわかる通り、HBMはコンデンサの電荷によって記憶を行っています。SRAMはフリップフロップ回路を用いて記憶を行っているメモリであり、キャッシュとして用いられています。DRAMと比較して高速なデータの入出力が可能ですが、一方で内部構造が複雑で高密度に実装できないことから、大容量化には向かないという性質を有します。
以上のことから、GPUメモリにおいては
HBM:大容量・低速
SRAM:小容量・高速
という階層が存在します。基本的にHBMにデータが記憶されており、ここからデータを読みだしますが、同じデータが呼び出された場合などはSRAM(キャッシュ)から自動的にデータを読み出すようにしておき、高速な処理を可能にするように構成されています。
MambaではHBMとSRAM間の移動を最小限化するためにkernel fusion(カーネル(アプリケーションとハードウェアをつなぐオペレーティングシステム(OS)における中心的なシステム)融合)(複数のプログラムをまとめておき、kernelの呼び出し回数を減らす技術のことを一般的に言います)と活性値の再計算を行っています。
具体的には、通常のモデルでは
Scanの入力をHBMで記憶→SRAMで計算→HBMに戻す
という工程ですが、Mambaでは
Scanの入力の構築からSRAMを使う→そのままSRAMで計算
ということを行っているとともに、
活性値(活性化関数を経た後の値)の計算において通常HBMに保存して利用するものをその都度SRAMで計算させること
によってHBMとSRAM間の移動を最小限化しています。
まとめるとSRAMをフル活用することによりHBMに極力データを移動させないようにしています。
以上より、Mambaではparallel scan・kernel fusion・活性値の再計算という3つの手法により計算を高速化していることが分かりました。
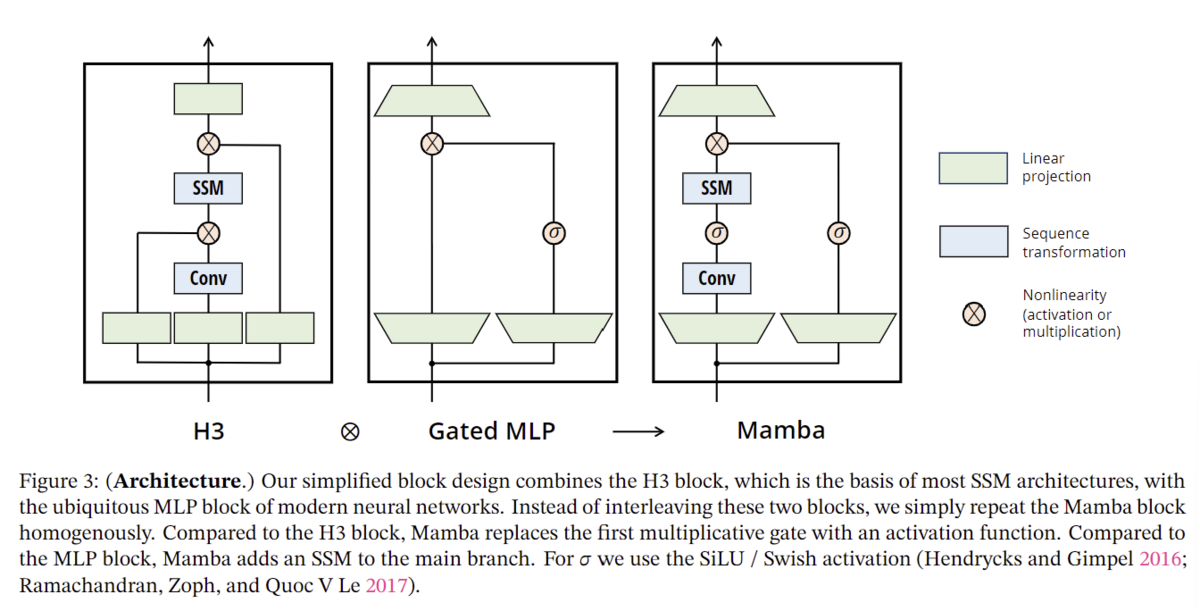
8.シンプルなアーキテクチャ
Mambaの新規性の最後としてAttentionやMLPブロックを排したシンプルなアーキテクチャを説明します。
原論文中に示されている下記の図をご覧ください。
H3は最も有名なSSMを用いたアーキテクチャであり、線形アテンションから着想を得たブロックとMLP(多層パーセプトロン)ブロックから構成されています。
Mambaではこの2つのブロックを均質に積み重ねることによって、アーキテクチャをシンプルにしています。
論文中ではGAU(Gated Attention Unit)から着想を得ていると明かしています。
活性化関数としてはSiLU/Swish、正規化層としてはLayerNorm、層数・パラメータ数はMHA(Multi Heads Attention)の先行例、アーキテクチャとしては残差接続(Residual Network)を用いていますが、私の主観としてはこれらの部分に関してはまだ研究の余地はありそうだと考えており、今後研究対象として論文も発表される可能性もあると考えています。
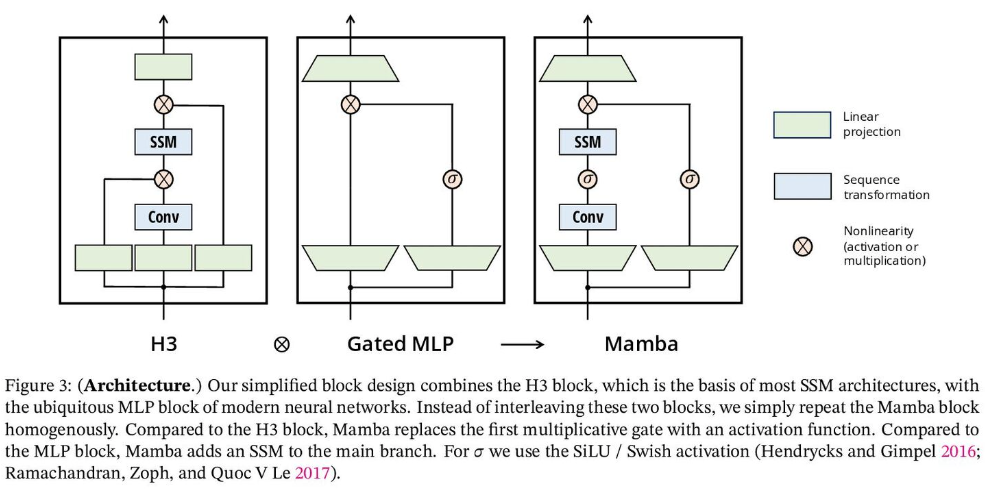
*1より引用
9.原論文中のグラフの説明とMambaの汎用的かつ高性能な推論能力
この章ではグラフ・図表の簡単な説明とMambaの性能に関して考察を行っていきます。
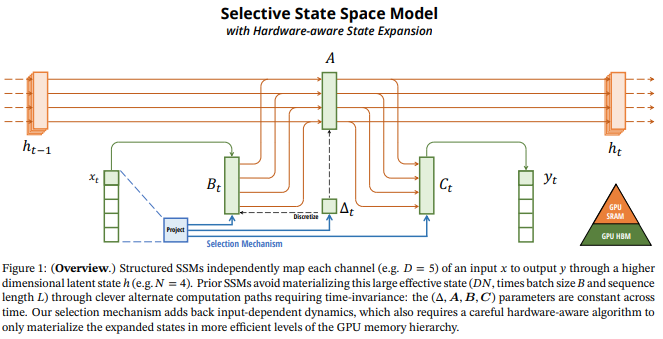
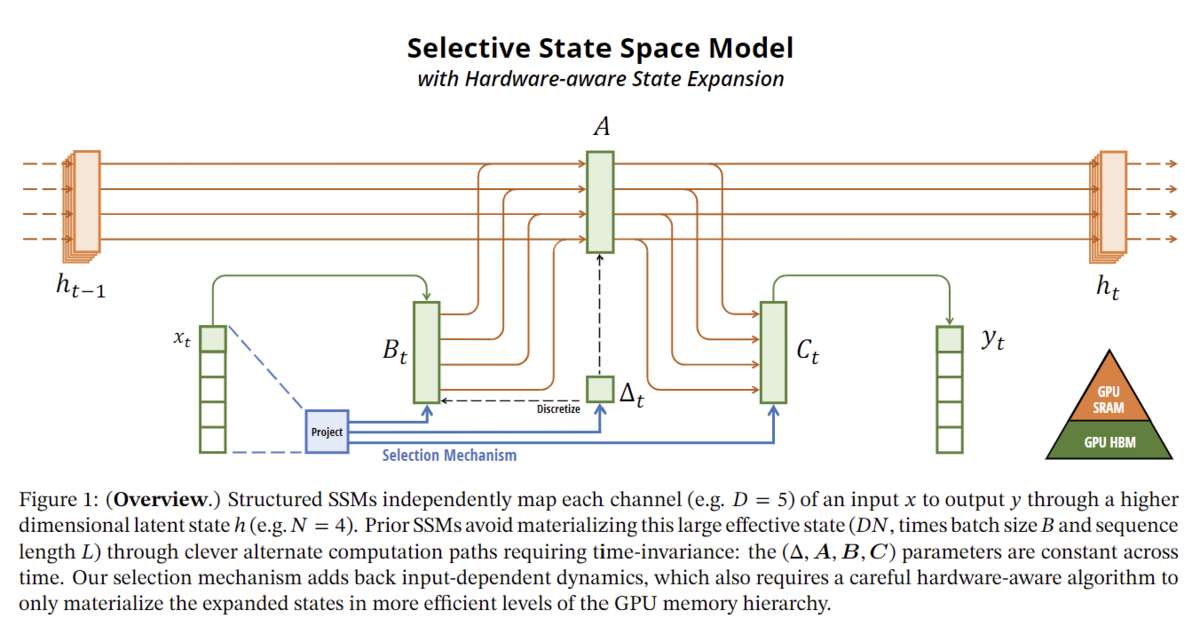
下記図はSelective SSMの模式図であり、Mambaの基礎が視覚的に分かるようになっています(ただし初見だとこの図は何が何だかほぼわからない)。色でHBMとSRAMどちらでどの処理を行っているのかが分かるようになっています。
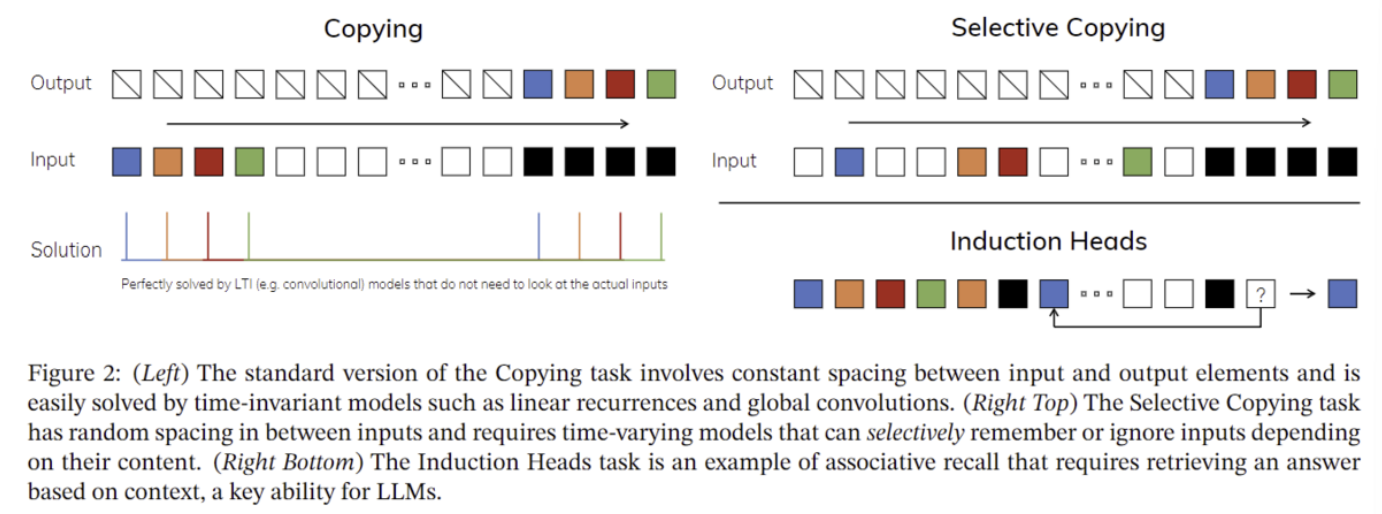
下記図は通常のコピーと選択的コピーの違いを模式的に表した図です。説明に関しては6章あたりを見てください。
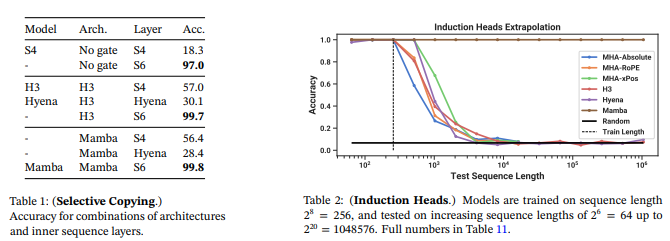
下記図は通常のSSM(S4)とSelective SSMのアルゴリズムの違いを示しています。5章で示した図に説明書きのある方が分かりやすいので、そちらを見てください。

下記図はMambaのアーキテクチャを示した図です。詳しくは8章を見てください。
下記図はSelective CopyingとInduction Headsを用いた際の精度を検討したものです。モデルに限らずSelective Copyingに変更(S4→S6)すると精度が上昇することが示されているとともに、Induction Headsを用いることで途中にあるノイズトークンをフィルタリングでき、Mambaはシーケンス長が1000kにおいても性能を完全に発揮することが示されています。
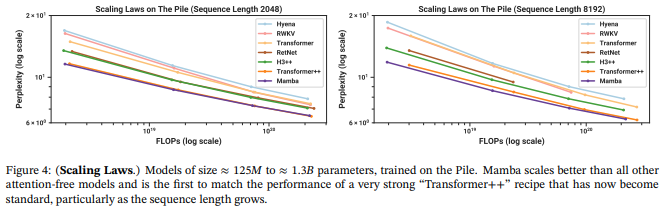
下記図は異なるシーケンス長におけるスケーリング測(モデルのパラメータ数やトレーニングデータ数、学習時の計算量の増大に伴って損失がべき乗測に従って減少するという法則)を確かめています。
この図からMambaは特に長いシーケンス長においてTransformerに匹敵するか上回るモデルであることが示唆されています。
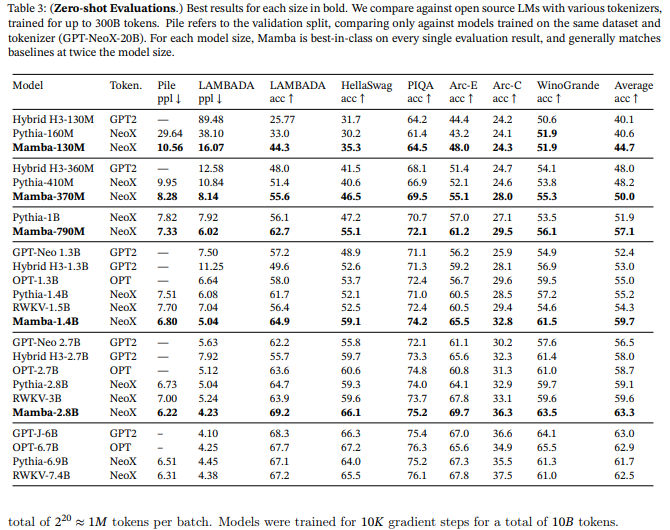
下記図はダウンストリームのゼロショット評価タスクによる結果を示しています。この図から、Mambaと同じトークナイザー、データセット、学習長で学習されているPythiaとRWKVに対して、同じサイズにおいて性能は4ポイント高く、二倍以上のパラメータ数を持つモデルすら上回っていることが示されています(Transformerに対する優位性)。
下記図は最近の言語モデルのDNAモデリングへの応用に触発されてMambaをDNAモデリングタスクに用いた際の評価結果です。DNAは有限の語彙を持つ離散的なトークンのシーケンスから構成されているという点で、言語に例えられており、長距離の依存関係をモデル化する必要があることが知られています。Mambaを用いた場合、シーケンス長が長い場合において特に優位性があることが示されました。
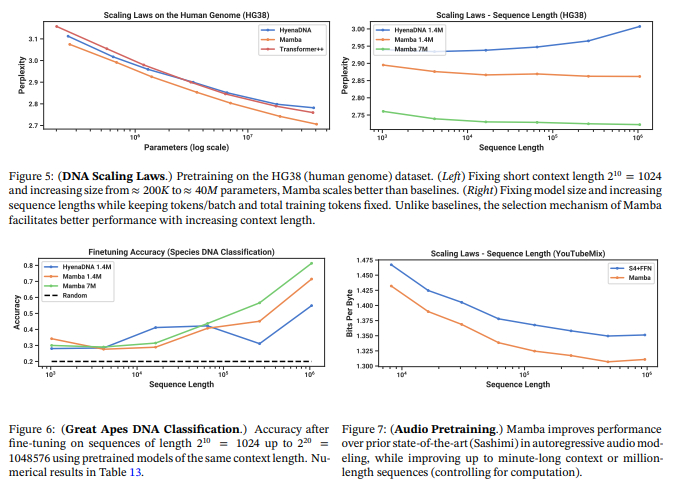
下記図は音声生成タスクに関するMambaの優位性を示したデータです。パラメータ数が小さいMambaで最先端かつ巨大な敵対的生成ネットワーク(GAN:Generative Adversarial Networks)や拡散ベースのモデルを凌駕していることが示されました。
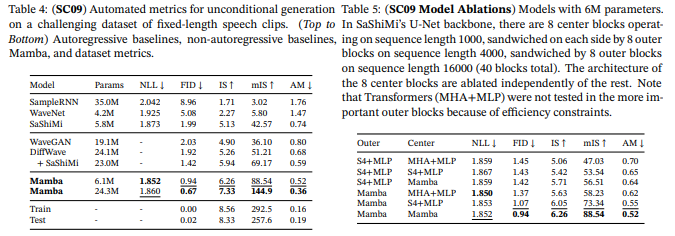
下記図はMambaのScan速度と、エンドツーエンドにおける推論のスループットに関するデータです。
MambaのScanは標準的なPytorchの実装より20~40倍高速であり、Mambaの推論はTransformerの4~5倍高速であることが示されています。
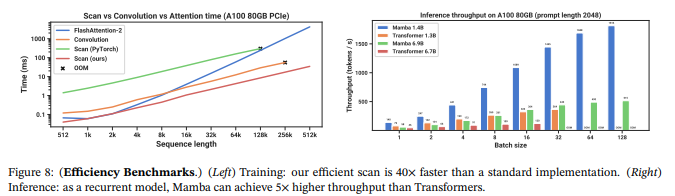
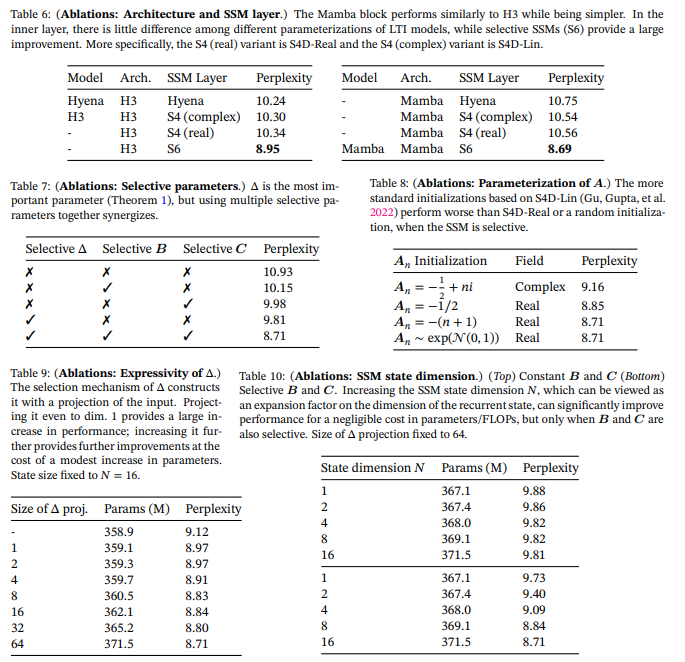
下記表は、SSM層の有効性と各パラメータの重要性を評価したデータです。
Selective SSMではないSSM層は性能が似通っていることが示されています。またSelective SSM(S6)を用いると性能が向上すること示されています。∆は最も重要なパラメータであり、性能に寄与を及ぼしますが、ほかのパラメータと一緒に検討することが必要です。ハードウェア面での効率を考えると行列Aは実数(あとで出てきますが複素数にもなりえます)のほうが適していると結論付けられています。また∆の表現性と性能との関係、状態次元Nと性能との関係についても議論が行われています。
10.議論
状態hには実数と複素数があります。先行するほとんどの状態空間モデルにおいては状態hは複素数であり、これが性能面を支えていると考えられています。しかし、実数の場合でも条件次第ではいい性能を引き出せるという示唆もあります。連続モダリティにおいては複素数が有効ですが、離散モダリティにおいては有効ではないという予想を筆者らは立て、実験に臨んでいます。
その他、SSMの初期化に複素数を用いる、∆のパラメータ化、ハードウェアを意識したアルゴリズムの具体的な手法などについて原論文中では述べられていますが、長くなってしまうため割愛します。詳しくは原論文を読んでください(分量自体はそこまで多くありません)。
11.Mambaの今後の研究課題の予想(私的主観)
1.Selective SSMを核にしたアーキテクチャの再考
Mambaはシンプルな素晴らしいモデルですが、性能向上のためにはアーキテクチャには介入の余地がありそうです。
2.ハイパーパラメータのチューニング方法はTransformerなどと同様であるのか?
3.学習の安定性はどうであるのか?
4.パラメータ数が巨大なモデルも精度を発揮するのか?
5.性能を発揮する最大シーケンス長はどのくらいなのか?(有限or無限?)
6.RAGなどTransformer系で用いられてきた手法のMambaへの応用
7.Mambaの数理的な詳細解析(最近Transformerに関する論文が登場して話題になりました。*14)
12.Mambaの最新研究動向(GitHubリポジトリベース)
1.Mambaモデルの公開
*2のリポジトリにてコードが公開されています。またすでにMambaを扱うためのライブラリも公開されているため、Transformer系と同様の簡易的な実装で扱うことが可能になっています。
例えば、Mamba公式によると
Mamba_ssmサンプルコード
import torch
from mamba_ssm import Mamba
batch, length, dim = 2, 64, 16
x = torch.randn(batch, length, dim).to("cuda")
model = Mamba(
# This module uses roughly 3 * expand * d_model^2 parameters
d_model=dim, # Model dimension d_model
d_state=16, # SSM state expansion factor
d_conv=4, # Local convolution width
expand=2, # Block expansion factor
).to("cuda")
y = model(x)
assert y.shape == x.shape
のように実装されます。(公式実装のため中核的な部分しかなく、このコードを実際に動かすとなると色々な工夫が必要です)
さらにMambaベースのpretrainedモデルがHugging Face(
https://huggingface.co/models?search=Mamba
)にて公開されており、下記のようなコードで学習・推論を行うことが可能です(このコードは私が独自で作成し、動作は確認済みです)。ぜひ独自のモデルを作成してみてください。
なお
ImportError: Using the Trainer with PyTorch requires accelerate>=0.20.1: Please run pip install transformers[torch] or pip install accelerate -U
というエラーが出ることがありますが、その場合はランタイムを再接続してみてください。
このコードは会話データセット(入力とそれに対する望ましい返答の組)を用いてMambaをファインチューニングするためのコードであり、このコードによってMambaを用いたChatが作成できます。動作はgoogle colabにて行うことを前提に設定されており、そのままコピペしても2024/2/8時点では動きます(アウトプットディレクトリだけ変更する必要があります)。なお引用元をどこかに付けていただければ、商用・非商用問わず自由に使用していただいて構いません。コメントアウトを多くしてあるので、初心者でも使いやすいようにしてあります。
2024/2/18追記:
コメントで実行の際にエラーが生じたという目撃例が寄せられたため、私が実行した際のgoogle colabのライブラリのバージョン一覧を示します。
エラーが生じた際は、もしかしたらどこかのバージョンが異なっている場合がございますので、一度ご確認をよろしくお願いいたします。
実行確認の取れた際のgoogle colabのライブラリのバージョン一覧
absl-py==1.4.0
accelerate==0.27.2
aiohttp==3.9.3
aiosignal==1.3.1
alabaster==0.7.16
albumentations==1.3.1
altair==4.2.2
annotated-types==0.6.0
anyio==3.7.1
appdirs==1.4.4
argon2-cffi==23.1.0
argon2-cffi-bindings==21.2.0
array-record==0.5.0
arviz==0.15.1
astropy==5.3.4
astunparse==1.6.3
async-timeout==4.0.3
atpublic==4.0
attrs==23.2.0
audioread==3.0.1
autograd==1.6.2
Babel==2.14.0
backcall==0.2.0
beautifulsoup4==4.12.3
bidict==0.22.1
bigframes==0.20.1
bleach==6.1.0
blinker==1.4
blis==0.7.11
blosc2==2.0.0
bokeh==3.3.4
bqplot==0.12.42
branca==0.7.1
build==1.0.3
CacheControl==0.14.0
cachetools==5.3.2
catalogue==2.0.10
causal-conv1d==1.0.0
certifi==2024.2.2
cffi==1.16.0
chardet==5.2.0
charset-normalizer==3.3.2
chex==0.1.85
click==8.1.7
click-plugins==1.1.1
cligj==0.7.2
cloudpathlib==0.16.0
cloudpickle==2.2.1
cmake==3.27.9
cmdstanpy==1.2.1
colorcet==3.0.1
colorlover==0.3.0
colour==0.1.5
community==1.0.0b1
confection==0.1.4
cons==0.4.6
contextlib2==21.6.0
contourpy==1.2.0
cryptography==42.0.2
cufflinks==0.17.3
cupy-cuda12x==12.2.0
cvxopt==1.3.2
cvxpy==1.3.3
cycler==0.12.1
cymem==2.0.8
Cython==3.0.8
dask==2023.8.1
datascience==0.17.6
datasets==2.17.0
db-dtypes==1.2.0
dbus-python==1.2.18
debugpy==1.6.6
decorator==4.4.2
defusedxml==0.7.1
dill==0.3.8
diskcache==5.6.3
distributed==2023.8.1
distro==1.7.0
dlib==19.24.2
dm-tree==0.1.8
docutils==0.18.1
dopamine-rl==4.0.6
duckdb==0.9.2
earthengine-api==0.1.389
easydict==1.12
ecos==2.0.13
editdistance==0.6.2
eerepr==0.0.4
einops==0.7.0
en-core-web-sm @ https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.7.1/en_core_web_sm-3.7.1-py3-none-any.whl#sha256=86cc141f63942d4b2c5fcee06630fd6f904788d2f0ab005cce45aadb8fb73889
entrypoints==0.4
et-xmlfile==1.1.0
etils==1.6.0
etuples==0.3.9
exceptiongroup==1.2.0
fastai==2.7.14
fastcore==1.5.29
fastdownload==0.0.7
fastjsonschema==2.19.1
fastprogress==1.0.3
fastrlock==0.8.2
filelock==3.13.1
fiona==1.9.5
firebase-admin==5.3.0
Flask==2.2.5
flatbuffers==23.5.26
flax==0.8.1
folium==0.14.0
fonttools==4.48.1
frozendict==2.4.0
frozenlist==1.4.1
fsspec==2023.6.0
future==0.18.3
gast==0.5.4
gcsfs==2023.6.0
GDAL==3.6.4
gdown==4.7.3
geemap==0.30.4
gensim==4.3.2
geocoder==1.38.1
geographiclib==2.0
geopandas==0.13.2
geopy==2.3.0
gin-config==0.5.0
glob2==0.7
google==2.0.3
google-ai-generativelanguage==0.4.0
google-api-core==2.11.1
google-api-python-client==2.84.0
google-auth==2.27.0
google-auth-httplib2==0.1.1
google-auth-oauthlib==1.2.0
google-cloud-aiplatform==1.39.0
google-cloud-bigquery==3.12.0
google-cloud-bigquery-connection==1.12.1
google-cloud-bigquery-storage==2.24.0
google-cloud-core==2.3.3
google-cloud-datastore==2.15.2
google-cloud-firestore==2.11.1
google-cloud-functions==1.13.3
google-cloud-iam==2.14.1
google-cloud-language==2.9.1
google-cloud-resource-manager==1.12.1
google-cloud-storage==2.8.0
google-cloud-translate==3.11.3
google-colab @ file:///colabtools/dist/google-colab-1.0.0.tar.gz#sha256=7b49a8ec5e4d2c9b20d2bf9f5ef7129b9a3d02b2c6e5497e989d74c744ab9fe6
google-crc32c==1.5.0
google-generativeai==0.3.2
google-pasta==0.2.0
google-resumable-media==2.7.0
googleapis-common-protos==1.62.0
googledrivedownloader==0.4
graphviz==0.20.1
greenlet==3.0.3
grpc-google-iam-v1==0.13.0
grpcio==1.60.1
grpcio-status==1.48.2
gspread==3.4.2
gspread-dataframe==3.3.1
gym==0.25.2
gym-notices==0.0.8
h5netcdf==1.3.0
h5py==3.9.0
holidays==0.42
holoviews==1.17.1
html5lib==1.1
httpimport==1.3.1
httplib2==0.22.0
huggingface-hub==0.20.3
humanize==4.7.0
hyperopt==0.2.7
ibis-framework==7.1.0
idna==3.6
imageio==2.31.6
imageio-ffmpeg==0.4.9
imagesize==1.4.1
imbalanced-learn==0.10.1
imgaug==0.4.0
importlib-metadata==7.0.1
importlib-resources==6.1.1
imutils==0.5.4
inflect==7.0.0
iniconfig==2.0.0
install==1.3.5
intel-openmp==2023.2.3
ipyevents==2.0.2
ipyfilechooser==0.6.0
ipykernel==5.5.6
ipyleaflet==0.18.2
ipython==7.34.0
ipython-genutils==0.2.0
ipython-sql==0.5.0
ipytree==0.2.2
ipywidgets==7.7.1
itsdangerous==2.1.2
jax==0.4.23
jaxlib @ https://storage.googleapis.com/jax-releases/cuda12/jaxlib-0.4.23+cuda12.cudnn89-cp310-cp310-manylinux2014_x86_64.whl#sha256=8e42000672599e7ec0ea7f551acfcc95dcdd0e22b05a1d1f12f97b56a9fce4a8
jeepney==0.7.1
jieba==0.42.1
Jinja2==3.1.3
joblib==1.3.2
jsonpickle==3.0.2
jsonschema==4.19.2
jsonschema-specifications==2023.12.1
jupyter-client==6.1.12
jupyter-console==6.1.0
jupyter-server==1.24.0
jupyter_core==5.7.1
jupyterlab_pygments==0.3.0
jupyterlab_widgets==3.0.10
kaggle==1.5.16
kagglehub==0.1.9
keras==2.15.0
keyring==23.5.0
kiwisolver==1.4.5
langcodes==3.3.0
launchpadlib==1.10.16
lazr.restfulclient==0.14.4
lazr.uri==1.0.6
lazy_loader==0.3
libclang==16.0.6
librosa==0.10.1
lida==0.0.10
lightgbm==4.1.0
linkify-it-py==2.0.3
llmx==0.0.15a0
llvmlite==0.41.1
locket==1.0.0
logical-unification==0.4.6
lxml==4.9.4
malloy==2023.1067
mamba-ssm==1.0.1
Markdown==3.5.2
markdown-it-py==3.0.0
MarkupSafe==2.1.5
matplotlib==3.7.1
matplotlib-inline==0.1.6
matplotlib-venn==0.11.10
mdit-py-plugins==0.4.0
mdurl==0.1.2
miniKanren==1.0.3
missingno==0.5.2
mistune==0.8.4
mizani==0.9.3
mkl==2023.2.0
ml-dtypes==0.2.0
mlxtend==0.22.0
more-itertools==10.1.0
moviepy==1.0.3
mpmath==1.3.0
msgpack==1.0.7
multidict==6.0.5
multipledispatch==1.0.0
multiprocess==0.70.16
multitasking==0.0.11
murmurhash==1.0.10
music21==9.1.0
natsort==8.4.0
nbclassic==1.0.0
nbclient==0.9.0
nbconvert==6.5.4
nbformat==5.9.2
nest-asyncio==1.6.0
networkx==3.2.1
nibabel==4.0.2
ninja==1.11.1.1
nltk==3.8.1
notebook==6.5.5
notebook_shim==0.2.3
numba==0.58.1
numexpr==2.9.0
numpy==1.25.2
oauth2client==4.1.3
oauthlib==3.2.2
opencv-contrib-python==4.8.0.76
opencv-python==4.8.0.76
opencv-python-headless==4.9.0.80
openpyxl==3.1.2
opt-einsum==3.3.0
optax==0.1.9
orbax-checkpoint==0.4.4
osqp==0.6.2.post8
packaging==23.2
pandas==1.5.3
pandas-datareader==0.10.0
pandas-gbq==0.19.2
pandas-stubs==1.5.3.230304
pandocfilters==1.5.1
panel==1.3.8
param==2.0.2
parso==0.8.3
parsy==2.1
partd==1.4.1
pathlib==1.0.1
patsy==0.5.6
peewee==3.17.1
pexpect==4.9.0
pickleshare==0.7.5
Pillow==9.4.0
pins==0.8.4
pip-tools==6.13.0
platformdirs==4.2.0
plotly==5.15.0
plotnine==0.12.4
pluggy==1.4.0
polars==0.20.2
pooch==1.8.0
portpicker==1.5.2
prefetch-generator==1.0.3
preshed==3.0.9
prettytable==3.9.0
proglog==0.1.10
progressbar2==4.2.0
prometheus-client==0.19.0
promise==2.3
prompt-toolkit==3.0.43
prophet==1.1.5
proto-plus==1.23.0
protobuf==3.20.3
psutil==5.9.5
psycopg2==2.9.9
ptyprocess==0.7.0
py-cpuinfo==9.0.0
py4j==0.10.9.7
pyarrow==15.0.0
pyarrow-hotfix==0.6
pyasn1==0.5.1
pyasn1-modules==0.3.0
pycocotools==2.0.7
pycparser==2.21
pyct==0.5.0
pydantic==2.6.1
pydantic_core==2.16.2
pydata-google-auth==1.8.2
pydot==1.4.2
pydot-ng==2.0.0
pydotplus==2.0.2
PyDrive==1.3.1
PyDrive2==1.6.3
pyerfa==2.0.1.1
pygame==2.5.2
Pygments==2.16.1
PyGObject==3.42.1
PyJWT==2.3.0
pymc==5.7.2
pymystem3==0.2.0
PyOpenGL==3.1.7
pyOpenSSL==24.0.0
pyparsing==3.1.1
pyperclip==1.8.2
pyproj==3.6.1
pyproject_hooks==1.0.0
pyshp==2.3.1
PySocks==1.7.1
pytensor==2.14.2
pytest==7.4.4
python-apt @ file:///backend-container/containers/python_apt-0.0.0-cp310-cp310-linux_x86_64.whl#sha256=b209c7165d6061963abe611492f8c91c3bcef4b7a6600f966bab58900c63fefa
python-box==7.1.1
python-dateutil==2.8.2
python-louvain==0.16
python-slugify==8.0.4
python-utils==3.8.2
pytz==2023.4
pyviz_comms==3.0.1
PyWavelets==1.5.0
PyYAML==6.0.1
pyzmq==23.2.1
qdldl==0.1.7.post0
qudida==0.0.4
ratelim==0.1.6
referencing==0.33.0
regex==2023.12.25
requests==2.31.0
requests-oauthlib==1.3.1
requirements-parser==0.5.0
rich==13.7.0
rpds-py==0.17.1
rpy2==3.4.2
rsa==4.9
safetensors==0.4.2
scikit-image==0.19.3
scikit-learn==1.2.2
scipy==1.11.4
scooby==0.9.2
scs==3.2.4.post1
seaborn==0.13.1
SecretStorage==3.3.1
Send2Trash==1.8.2
sentencepiece==0.1.99
shapely==2.0.2
six==1.16.0
sklearn-pandas==2.2.0
smart-open==6.4.0
sniffio==1.3.0
snowballstemmer==2.2.0
sortedcontainers==2.4.0
soundfile==0.12.1
soupsieve==2.5
soxr==0.3.7
spacy==3.7.2
spacy-legacy==3.0.12
spacy-loggers==1.0.5
Sphinx==5.0.2
sphinxcontrib-applehelp==1.0.8
sphinxcontrib-devhelp==1.0.6
sphinxcontrib-htmlhelp==2.0.5
sphinxcontrib-jsmath==1.0.1
sphinxcontrib-qthelp==1.0.7
sphinxcontrib-serializinghtml==1.1.10
SQLAlchemy==2.0.27
sqlglot==19.9.0
sqlparse==0.4.4
srsly==2.4.8
stanio==0.3.0
statsmodels==0.14.1
sympy==1.12
tables==3.8.0
tabulate==0.9.0
tbb==2021.11.0
tblib==3.0.0
tenacity==8.2.3
tensorboard==2.15.2
tensorboard-data-server==0.7.2
tensorflow==2.15.0
tensorflow-datasets==4.9.4
tensorflow-estimator==2.15.0
tensorflow-gcs-config==2.15.0
tensorflow-hub==0.16.1
tensorflow-io-gcs-filesystem==0.36.0
tensorflow-metadata==1.14.0
tensorflow-probability==0.23.0
tensorstore==0.1.45
termcolor==2.4.0
terminado==0.18.0
text-unidecode==1.3
textblob==0.17.1
tf-keras==2.15.0
tf-slim==1.1.0
thinc==8.2.3
threadpoolctl==3.2.0
tifffile==2024.2.12
tinycss2==1.2.1
tokenizers==0.15.2
toml==0.10.2
tomli==2.0.1
toolz==0.12.1
torch @ https://download.pytorch.org/whl/cu121/torch-2.1.0%2Bcu121-cp310-cp310-linux_x86_64.whl#sha256=0d4e8c52a1fcf5ed6cfc256d9a370fcf4360958fc79d0b08a51d55e70914df46
torchaudio @ https://download.pytorch.org/whl/cu121/torchaudio-2.1.0%2Bcu121-cp310-cp310-linux_x86_64.whl#sha256=676bda4042734eda99bc59b2d7f761f345d3cde0cad492ad34e3aefde688c6d8
torchdata==0.7.0
torchsummary==1.5.1
torchtext==0.16.0
torchvision @ https://download.pytorch.org/whl/cu121/torchvision-0.16.0%2Bcu121-cp310-cp310-linux_x86_64.whl#sha256=e76e78d0ad43636c9884b3084ffaea8a8b61f21129fbfa456a5fe734f0affea9
tornado==6.3.2
tqdm==4.66.2
traitlets==5.7.1
traittypes==0.2.1
transformers==4.35.2
triton==2.1.0
tweepy==4.14.0
typer==0.9.0
types-pytz==2024.1.0.20240203
types-setuptools==69.0.0.20240125
typing_extensions==4.9.0
tzlocal==5.2
uc-micro-py==1.0.3
uritemplate==4.1.1
urllib3==2.0.7
vega-datasets==0.9.0
wadllib==1.3.6
wasabi==1.1.2
wcwidth==0.2.13
weasel==0.3.4
webcolors==1.13
webencodings==0.5.1
websocket-client==1.7.0
Werkzeug==3.0.1
widgetsnbextension==3.6.6
wordcloud==1.9.3
wrapt==1.14.1
xarray==2023.7.0
xarray-einstats==0.7.0
xgboost==2.0.3
xlrd==2.0.1
xxhash==3.4.1
xyzservices==2023.10.1
yarl==1.9.4
yellowbrick==1.5
yfinance==0.2.36
zict==3.0.0
zipp==3.17.0
MambaのFinetuningのためのサンプルコード
# このコードは会話データセット(入力とそれに対する望ましい返答の組)を用いてMambaをファインチューニングするための
# 独自コードです。コメントを多く残していますので、このコードを参考にしてファインチューニングを行い、
# みなさん独自のモデルを作成したり、製品化・公開を検討してみてください。
# なお、コードは引用元を付記していただければ商用・非商用問わずそのまま自由に使っていただいて構いません。
# 一部コードはMamba公式実装を参考にしています。このコードはgoogle colabでの実装を想定しています。
# まず各ライブラリのインストールを行います。互換性のために一部ライブラリはバージョンを指定しています。
# バージョン指定はMamba-Chatの実装を参考にしています。今後colabのライブラリのバージョンが変更されるに従って
# このバージョン指定は変わる可能性があります(2024/2/8動作確認済み)。
!pip install transformers torch datasets causal-conv1d==1.0.0
!pip install accelerate -U
!pip install mamba-ssm==1.0.1 --no-build-isolation
!ldconfig /usr/lib64-nvidia # libcuda.so not found! というエラーを防止するために入れています。特に理由がない場合はそのままにしておいてください。
# ここから必要なライブラリのimportを行います。
import torch, os
from mamba_ssm.models.mixer_seq_simple import MambaLMHeadModel
from transformers import AutoTokenizer, TrainingArguments, Trainer
from torch.utils.data import Dataset
from datasets import load_dataset
# Mambaモデルの読み込みを行います。今回は最も小さいモデルを指定していますが、適宜作成したいアプリケーションに合わせて選択してください。
model = MambaLMHeadModel.from_pretrained("state-spaces/mamba-130m")
# Tokenizerは適宜適切なもの(その時々で精度が高く、高速なもの)を選択してください。
# ちなみにTokenizerは文章をトークン化(その文字に対応する値化すること)してくれるものです。
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neox-20b")
# 処理の関係で文末を示すトークンを変更しています。
tokenizer.eos_token = "<|endoftext|>"
# PADトークンを文末を示すトークンに変えています。これは文長を揃える必要がなく、文が終わったらすぐに処理を終了してほしいからです。
tokenizer.pad_token = tokenizer.eos_token
# 使用するデータセットをダウンロードします。ここではorca_dpo_pairsというデータセットを用いています。
# 理由はデータサイズがちょうど良かったからというだけです。
# HuggingFaceでは各研究者がデータセットを公開しており、作りたいモデルによって使うべきデータは異なります。
# 適宜データの質・量に注意して選定してください。
pre_dataset = load_dataset("HuggingFaceH4/orca_dpo_pairs")
# データセットを構成するクラスをDatasetからの継承で作成しています。
# このクラスの目的は任意のインデックスが渡された際に対応するinput_idsとlabelsを返すことです。
# このクラスはTrainerに適合する形で設計されています。もしマイナーチェンジをしたい場合はこれらの点に注意してください。
class MambaDataset(Dataset):
def __init__(self, inputs):
self.input = inputs[0]
self.label=inputs[1]
def __getitem__(self, idx):
data = {'input_ids': torch.tensor(self.input[idx]),
'labels' : torch.tensor(self.label[idx])}
return data
def __len__(self):
return len(self.input)
# ダウンロードしたデータのままだと上手くTrainerに適合したデータセットに整形できません。
# そのため、preprocess関数でいい感じに整形してあげます。この関数の目的はデータから入力と返答の組を作成し、
# それぞれを配列に格納して、MambaDatasetクラスに渡せるようにすることです。
# なおこの処理は用いるデータがどのような構造をしているかによって変わるため、適宜書き換えてください。
def preprocess(examples):
chosenes = examples['chosen']
conversation_inputs = []
conversation_responses = []
for chosen in chosenes:
for item in chosen:
if item["role"] == "user":
conversation_inputs.append(tokenizer(item["content"])['input_ids'])
if item["role"] == "system":
conversation_responses.append(tokenizer(item["content"])['input_ids'])
return conversation_inputs, conversation_responses
# TrainerはデフォルトだとTransformer用のため、MambaにはないAttention_maskを使うように設計されています。
# そのためエラーになってしまうので、Trainerを継承した独自のクラスを設計し、これに対処します。
# クラスの基本設計としてロス計算とモデル保存を関数として組み込みます。
class MambaTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
input_ids = inputs.pop("input_ids")
lm_logits = model(input_ids).logits
labels = input_ids.to(lm_logits.device)
shift_logits = lm_logits[:, :-1, :].contiguous()
labels = labels[:, 1:].contiguous()
loss_fct = torch.nn.CrossEntropyLoss()
lm_loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), labels.view(-1))
return lm_loss
def save_model(self, output_dir, _internal_call=None):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
torch.save(self.model.state_dict(), f"{output_dir}/pytorch_model.bin")
self.tokenizer.save_pretrained(output_dir)
# MambaDatasetクラスとpreprocess関数を用いて、訓練データセットと検証データセットを作成してあげます。
train_dataset = MambaDataset(preprocess(pre_dataset['train_prefs']))
validation_dataset = MambaDataset(preprocess(pre_dataset['test_prefs']))
# MambaTrainerを用いて訓練の設定を行います。各パラメータは適宜適切なものにしてください。
trainer = MambaTrainer(
model=model, # モデルの指定
train_dataset=train_dataset, # 訓練データセットの指定
eval_dataset=validation_dataset, # 検証データセットの指定
tokenizer=tokenizer, # Tokenizerの指定
args=TrainingArguments(
learning_rate = 5e-5, # 学習率の指定(大きいと学習は早いですが発散しやすくなり、小さいと発散しにくくなりますが学習は遅くなります。)
# パラメータを振ってみていい感じの学習率を見定めてください。なおグラフから適した学習率を求める手法も存在します。
num_train_epochs=4, # エポック数(学習回数)の指定 ある程度の回数以上はほとんど精度が向上しなくなるので、これもいい感じに決めてください。
per_device_train_batch_size=1, # 訓練バッチサイズの指定 大きいと学習が速くなりますがメモリオーバーになりかねません。
# 訓練が可能なバッチサイズのうちできるだけ大きいものの方が望ましいと考えられています。
gradient_accumulation_steps=1, # この値分、バッチ全体の勾配を分割して計算します。メモリ要件やモデルの精度に関係します。
optim="adamw_torch", # 最適化関数の指定 基本的に機械学習ではAdam系列がデファクトスタンダードになっています。
output_dir="mamba-chat", # モデルを保存するフォルダを指定します。google driveのフォルダなどを指定してください。
logging_steps=50, # 損失や学習率の状況をどの感覚で表示するかを指定します。あまり小さくしすぎると表示がうるさくなります。
save_steps=500 # モデルを保存するタイミングを指定します。
)
)
trainer.train() # 訓練を開始します。
次に先ほど作成したモデルを用いて推論を行うためのコードを示します。
Mambaの推論のためのサンプルコード
from mamba_ssm.models.mixer_seq_simple import MambaLMHeadModel
from transformers import AutoTokenizer
import torch
# finetuned Mambaモデルの読み込みを行います。
model = MambaLMHeadModel.from_pretrained("finetuned model")
# Tokenizerは適宜適切なもの(その時々で精度が高く、高速なもの)を選択してください。
# ちなみにTokenizerは文章をトークン化(その文字に対応する値化すること)してくれるものです。
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neox-20b")
# 処理の関係で文末を示すトークンを変更しています。
tokenizer.eos_token = "<|endoftext|>"
# PADトークンを文末を示すトークンに変えています。これは文長を揃える必要がなく、文が終わったらすぐに処理を終了してほしいからです。
tokenizer.pad_token = tokenizer.eos_token
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.eval()
inputs = tokenizer("your text", return_tensors="pt")['input_ids']
with torch.no_grad():
tokens = model.to(device)(inputs.to(device))
print(tokens.logits.argmax(dim=-1))
output = tokenizer.decode(tokens.logits.argmax(dim=-1).squeeze())
print(output)
こちらのコードは一応動作確認はしていますが、もし不具合などありましたらコメントでご指摘ください。
2.VMamba
VMambaは*15にて公開されているMambaを画像分類・セグメンテーション・物体検知に利用したモデルであり、主要なベンチマークで優れた成績を示しています。*16画像解像度が上がることはシーケンス長の増大を意味することから、特に高解像度の条件において顕著な性能を示しています。詳しくは論文・リポジトリをご覧ください。
3.MambaーChat
MambaーChatはMambaを世界で初めて会話タスクに用いたモデルです。*17
先に示したコードはこのリポジトリを参考に自己流にアレンジして作成しました。
モデル自体はHugging Faceにて公開されていますが、モデルサイズは結構大きく、少し使いづらいかもしれません。
4.BlackMamba
BlackMambaはMambaにMoE(Mixture of Experts)を適用した例です。
Mambaに比べてより高速な推論が可能になっています。*18 *19
5.U-Mamba
U-Mambaは医療用画像のセグメンテーションのためにMambaを利用した例です。*20 *21
CTおよびMR画像の3D腹部臓器セグメンテーション、内視鏡画像の機器セグメンテーション、顕微鏡画像の細胞セグメンテーションなど、4つの多様なタスク全てにおいて最先端の他のモデル(CNN・Transformerベース)を上回っていることが確認されました。この試験からセグメンテーションタスクにおいてMambaが非常に有用なモデルであることがわかります。
6.Mamba-minimal
Mamba-minimalはMambaを最小限のコードで実装した例です。Mambaのアルゴリズについて詳しく検討したい場合などに便利です。*22
7.その他研究成果
*23にてMambaの発表されてからの関連論文がまとめられています。全ての成果についてここで説明すると紙面が足りないので、詳しくはこのページをみてください。これらの成果をまとめると、MambaはこれまでのCNN・Transformerベースのモデルを上回る精度を様々なタスクで達成しており、特にシーケンス長が長いタスクでは顕著となっています。この状況から今後はMambaが研究の最先端となる可能性が高いと考えています。
8.Mambaに関するわかりやすい説明資料
*24〜*31にMambaに関するわかりやすい記事・論文等をまとめました。各コンテンツに関して簡単な説明を付加してあります。もしこの記事だけではわかりにくいと感じた部分がありましたらこれらをご覧になってみてください。特に*24は原論文が和訳されたページのため大変便利です。
9.Mambaに関する数式・証明を詳しく解説している記事(2024/2/18追記)
上記の記事はMambaに関する数学的な証明を詳しく記述している記事です。(私が確認した2024/2/18時点では執筆途中)
本記事はMambaの全体的な理解を促進することを目的としていますが、izmyonさんの記事はより詳細に数学的に理解することを目的として書かれています。
この記事だけでは不足する点も多く書かれているため、ぜひこちらの記事も覗いてみてください。
10.Kotoba technologiesさんが、英語/日本語事前学習済み2.8Bモデルを公開
下記に示すように、注目のスタートアップ企業であるKotoba TechnologiesさんがMambaの英語・日本語の事前学習済みモデルを公開してくださいました。
複数のタスクで同程度のパラメータのTransformer系のモデルと同程度の精度を達成していることが示されています。
一部の試みでは推論速度はTransformer系より数倍速いという報告もあります。
2024年2月26日追記:
下記に私が独自で作成したkotomambaの推論コードに関する記事を添付します。
もしよろしければご利用ください。
13.謝辞
この記事を書くにあたって、まずMambaを開発してくださったAlbert Gu, Tri Daoには深く感謝いたします。また記事を書くにあたって多くの研究者の方の記事を参考にさせていただきました。その努力に深い敬意を示すとともに感謝いたします。Mambaは素晴らしいモデルですが、このモデルを実装できているのは多くの先人の方が作ってきてくださったライブラリやデバイスがあってのことです。先人たちの営みに深い敬意を表すとともに感謝いたします。また、私が人工知能を学ぶきっかけを作ってくださった日本の大学教育・大学時代の友人に感謝いたします。最後に長い記事にも関わらずここまで付き合ってくださった読者の皆様に感謝いたします。
14.最後に
Mambaは最新の研究成果からTransformerを凌駕し、Transformerを代替しうるモデルであることが強く示唆されつつあります。私はこのモデルに関して強い期待を寄せています。日本においてもMambaの研究がより盛んになり、世界と渡り合えるような先進的な研究が多く生み出させることを期待します。そのためにこの記事が研究者・開発者の皆様の役に立つことを願っています。
参考論文・記事等(リンク)
*1 'Mamba: Linear-Time Sequence Modeling with Selective State Spaces', https://arxiv.org/pdf/2312.00752.pdf
Mambaの原論文です。
*2 'Mamba', https://github.com/state-spaces/mamba
Mambaのgithubリポジトリです。
*3 'Attention Is All You Need', https://arxiv.org/pdf/1706.03762.pdf
Attentionの原論文です。
*4 'It’s Raw! Audio Generation with State-Space Models', https://arxiv.org/pdf/2202.09729.pdf
構造化状態空間モデル(S4)を用いて音声合成を行った論文です。
*5 'Diagonal State Spaces are as Effective as Structured State Spaces', https://arxiv.org/pdf/2203.14343.pdf
音声分類において、対角状態空間モデルが構造化状態空間モデル(S4)と同程度に有用であることを示した論文です。
*6 'SIMPLIFIED STATE SPACE LAYERS FOR SEQUENCE MODELING', https://arxiv.org/pdf/2208.04933.pdf
構造化状態空間モデル(S4)を改良して新しい状態空間モデルS5を開発し、その性能を検討した論文です。
*7 'kotomamba', https://github.com/kotoba-tech/kotomamba
kotoba techが作成した独自のMambaのgithubリポジトリです。
*8 'Deep State Space Model 101', https://speakerdeck.com/kurita/mamba
kotoba techの栗田さんが作成したMambaに関する非常に分かりやすい資料です。
*9 'A New Approach to Linear Filtering and Prediction Problems', https://www.cs.unc.edu/~welch/kalman/media/pdf/Kalman1960.pdf
古典的な状態空間モデルに関する論文です。
*10 'Efficiently Modeling Long Sequences with Structured State Spaces', https://arxiv.org/pdf/2111.00396.pdf
構造化状態空間モデル(S4)の原論文です。
*11 'In-context Learning and Induction Heads', https://arxiv.org/pdf/2209.11895.pdf
Induction Headsの提案と精度検討等を行なっている論文です。
*12 'Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers, https://arxiv.org/pdf/2110.13985.pdf
線形状態空間モデルに構造化行列を導入し、音声分類で長いシーケンスにおいても高い精度を達成したという論文です。Mamba論文においてSelective Copyingの原理を説明する際の式変形の引用元となっています。
*13 'Parallel Prefix Scan', https://www.cs.princeton.edu/courses/archive/fall20/cos326/lec/21-02-parallel-prefix-scan.pdf
Parallel Scanに関する解説記事です。
*14 'Approximation and Estimation Ability of Transformers for Sequence-to-Sequence Functions with Infinite Dimensional Input', https://proceedings.mlr.press/v202/takakura23a/takakura23a.pdf
Attentionが入力列に応じて重要なトークンを選択することでほぼminimaxレートで無限系列から無限系列へ非線形関数を推定できることを示している論文です。
*15 'VMamba', https://github.com/MzeroMiko/VMamba
VMambaのgithubリポジトリです。
*16 'VMamba: Visual State Space Model', https://arxiv.org/pdf/2401.10166.pdf
VMambaの論文です。
*17 'Mamba-Chat', https://github.com/havenhq/mamba-chat
Mambaを用いた世界で初めてのチャットを実装したgithubリポジトリです。
*18 'BlackMamba', https://github.com/Zyphra/BlackMamba
BlackMambaのgithubリポジトリです。
*19 'MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts', https://arxiv.org/pdf/2401.04081.pdf
Mixture of ExpertsとMambaを組み合わせて精度検討した論文です。(BlackMamba)
*20 'U-Mamba', https://github.com/bowang-lab/U-Mamba
医療用画像のセグメンテーションのためにMambaを用いたgithubリポジトリです。
*21 'U-Mamba: Enhancing Long-range Dependency for Biomedical Image Segmentation', https://arxiv.org/pdf/2401.04722.pdf
U-Mambaの論文です。
*22 'Mamba-minimal', https://github.com/johnma2006/mamba-minimal
Mambaの原論文を基に最小限のコードでmambaを実装したgithubリポジトリです。
*23 'Awesome-Mamba-Papers', https://github.com/yyyujintang/Awesome-Mamba-Papers
Mambaに関する記事・論文をまとめたリポジトリです。
*24 '今日の論文2023/12/11:Mamba: Linear-Time Sequence Modeling with Selective State Spaces', https://izmyon.hatenablog.com/entry/2023/12/11/155551
Mambaの原論文を和訳したサイトです。(簡単な要約付き)
*25 'Mamba-notes', https://github.com/hkproj/mamba-notes/tree/main
Mambaに関する説明資料が格納されたgithubリポジトリです。
*26 'Mamba:シーケンスモデリングの次の進化', https://anakin.ai/ja-jp/blog/mamba/
Mambaに関する解説記事です(原論文の和訳&要約)
*27 'Mamba: シーケンス モデリングの再定義とトランスフォーマー アーキテクチャの改良', https://www.unite.ai/ja/Mamba-%E3%81%8C%E3%82%B7%E3%83%BC%E3%82%B1%E3%83%B3%E3%82%B9-%E3%83%A2%E3%83%87%E3%83%AA%E3%83%B3%E3%82%B0%E3%81%A8%E3%83%88%E3%83%A9%E3%83%B3%E3%82%B9%E3%83%95%E3%82%A9%E3%83%BC%E3%83%9E%E3%83%BC-%E3%82%A2%E3%83%BC%E3%82%AD%E3%83%86%E3%82%AF%E3%83%81%E3%83%A3%E3%82%92%E5%86%8D%E5%AE%9A%E7%BE%A9/
Mambaに関する解説記事です(原論文の和訳&要約)
*28 'Mamba解析:AIシーケンスモデリングの新時代への挑戦', https://reinforz.co.jp/bizmedia/21535/
Mambaに関する解説記事です(原論文の和訳&要約)
*29 'Mamba: Linear-Time Sequence Modeling with Selective State Spaces (Paper Explained)', https://digest.getnotable.ai/mamba-linear-time-sequence-modeling-with-selective-state-spaces-paper-explained/
Mambaに関する解説記事です(原論文の要約)
*30 'Mamba: Revolutionizing Sequence Modeling with Selective State Spaces', https://medium.com/@joeajiteshvarun/mamba-revolutionizing-sequence-modeling-with-selective-state-spaces-8a691319b34b
Mambaに関する解説記事です(原論文の要約)
*31 'How Mamba's Breakthrough in Efficient Sequence Modeling is Revolutionizing AI', https://www.functionize.com/blog/how-mamba-breakthrough-in-efficient-sequence-modeling-is-revolutionizing-ai#:~:text=The%20core%20of%20Mamba%20is%20the%20selective%20state,selectively%20attends%20to%20relevant%20information%20within%20each%20sub-sequence.
Mambaに関する解説記事です(原論文の要約)
書いた人:六花牡丹(りっかぼたん)
某総合電機メーカに務める謎の人物(自称)。
おさげとハーフツインが好きで、基本的にふわふわしている変わり者。
結構ドジで何もないところで転ぶタイプ。
人工知能に関しては独学のみ。