![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
はじめに
桜の花が細い枝に咲き、澄んだ空にリボンを結ぶ今日この頃、みなさまいかがお過ごしでしょうか?
六花 牡丹(りっか ぼたん)と申します ![]()
本記事は、
SSE (Stable Static Embedding): Unlocking the Potential of Static Embeddings, A Dynamic Tanh Normalization Approach without Speed Penalty
(SSE:静的埋め込みの可能性を解き放つ、速度ペナルティのないDynamic Tanh normalization アプローチ)
の日本語での解説記事になります。
拙筆ではございますが、この記事が皆様の役に立つことを祈っています。
研究進捗や日常についてお話していますので、もしよろしければフォローなどよろしくお願いいたします。
要約
静的埋め込みモデルは、シンプルなアーキテクチャにより高速な推論を可能としますが、それ故に、表現力を高めるのは困難であることが知られています。コーパスの規模が拡大し続ける中、埋め込みモデルに対する高い効率性と高精度性の両立は依然として重要とされています。
そこで本記事では、SSE (Stable Static Embedding) というシンプルな手法を提案します。SSE は Separable DyT (Dynamic Tanh normalization) というオリジナルのモジュールを使用しています。
SSE はパラメータ数が半分ながら、従来のアプローチよりも高い検索性能を達成します。16Mパラメータという規模ながら、SSE はNanoBEIR English mean nDCG@10で 0.512というスコアを達成しました。
Separable DyT を活用することで、SSE は勾配の流れを効果的に制御し、次元間の不均衡や過学習を抑制します。
この手法は静的埋め込みモデルに対する新たな視点を提供するものと考えています。
1 主な成果
-
学習を安定させ、埋め込み空間の構造を改善するシンプルな正規化機構である Separable DyTを提案しました
-
パラメータ効率の高い静的埋め込みである SSE を導入し、NanoBEIR における実験を通じて、高速な推論と低い計算コストを維持しつつ実用的な検索性能を実現することを示しました
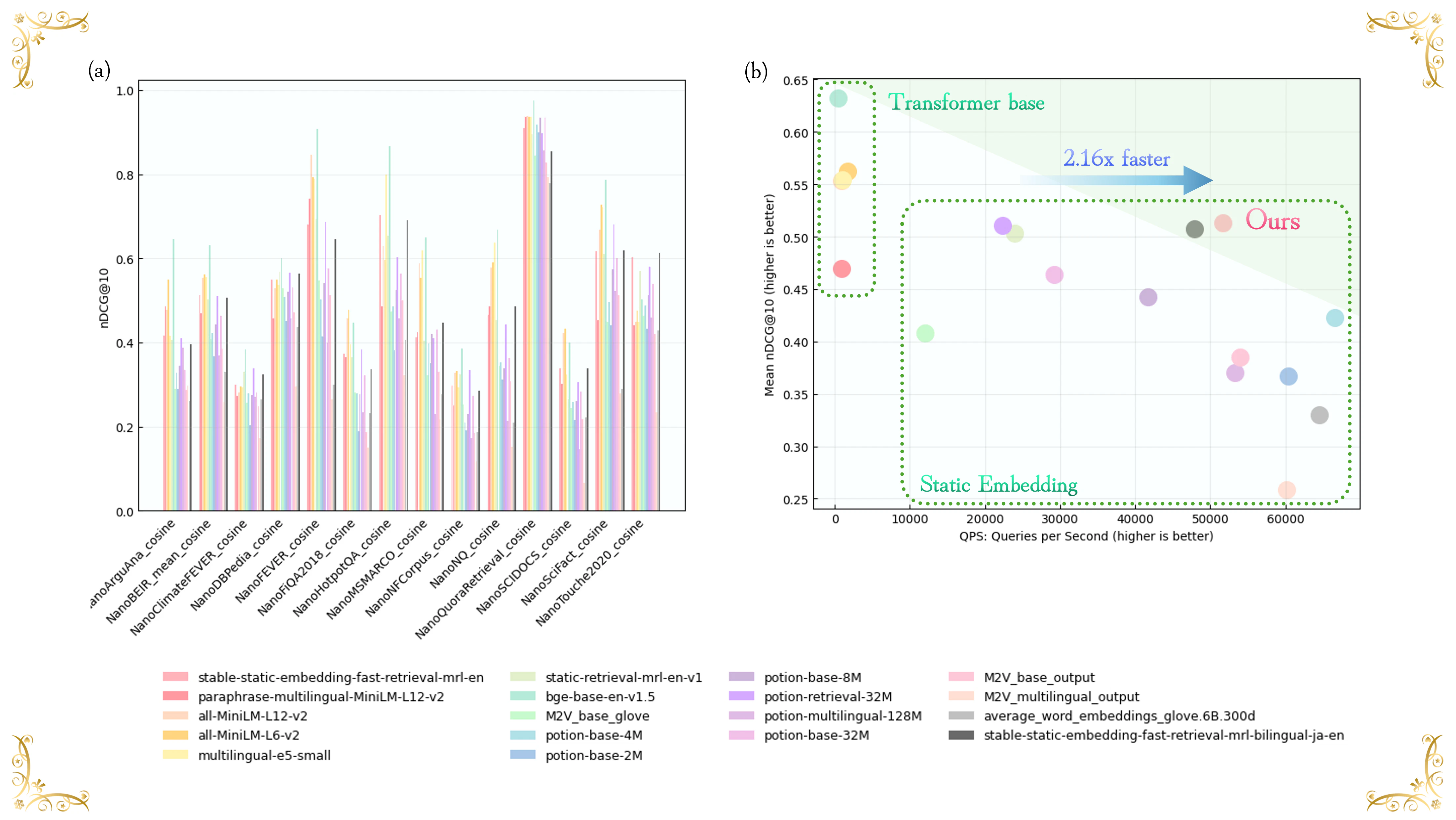
図 1 | (a) NanoBEIR Englishにおける検索性能(nDCG@10)(b) mean nDCG@10 vs 推論速度 (QPS: Query Per Second) (Intel® Core™ Ultra 7 265K (3.90 GHz)、バッチサイズ:32、データセット:TREC-COVID 及び Quora)
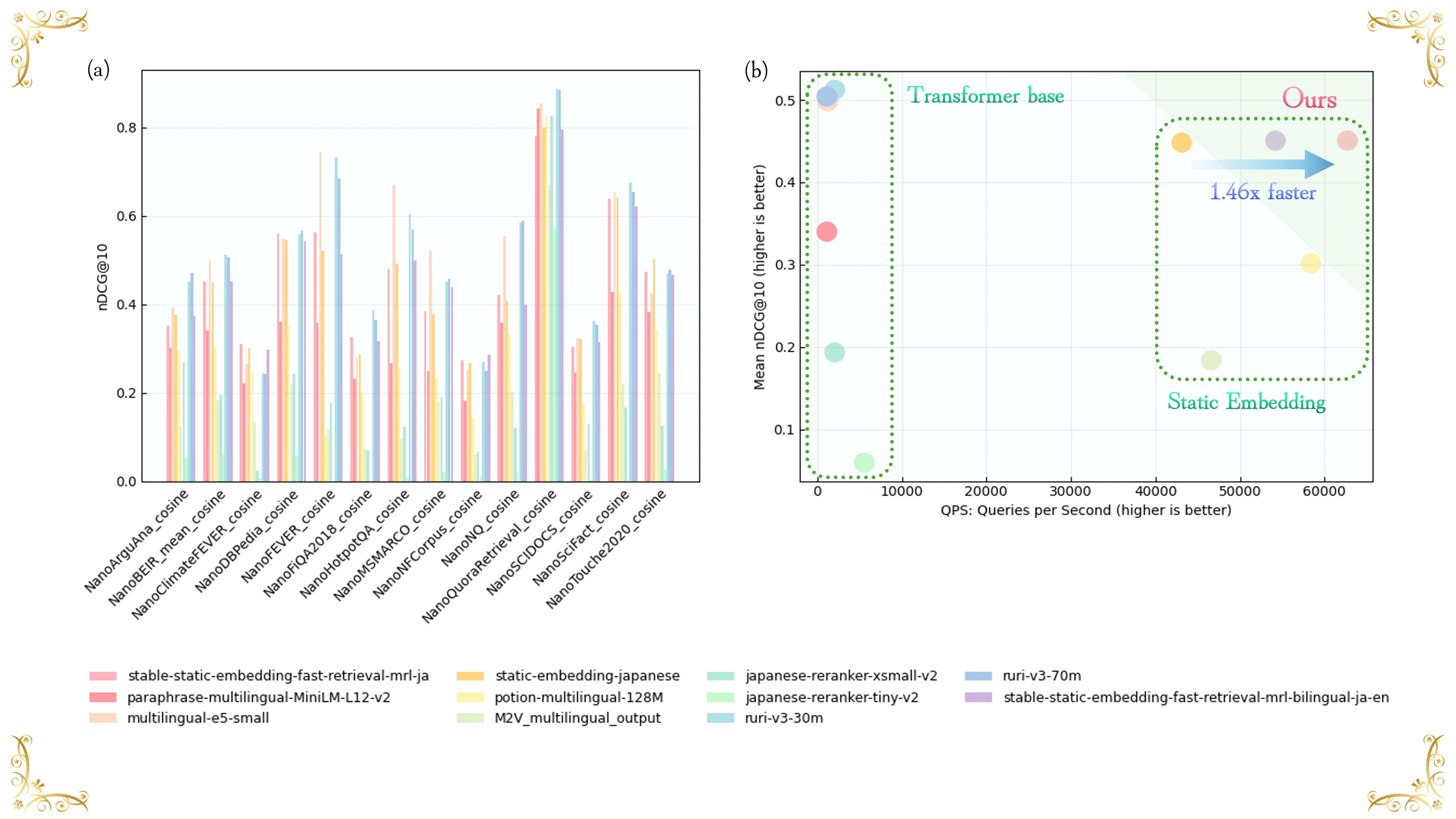
図 2 | (a) NanoBEIR Japaneseにおける検索性能(nDCG@10)(b) mean nDCG@10 vs 推論速度 (QPS: Query Per Second) (Intel® Core™ Ultra 7 265K (3.90 GHz)、バッチサイズ:32、データセット:Miracl)
2 研究背景
高密度なベクトル表現は、情報検索や検索拡張言語システムの基盤となっています。Transformer ベースの文脈埋め込みモデルは優れた性能を発揮しますが、推論時の計算コストが大きく、レイテンシに敏感な大規模アプリケーションではボトルネックになります。一方で静的埋め込みモデルは構造が単純であるため、高速かつメモリ消費も少なく、大規模検索や推薦・リアルタイム検索システムに適しています。こうした背景から、速度は得られるものの精度が不足しやすく、逆に高精度を求めると計算負荷が増加するというトレードオフがあります。このトレードオフの解消には、表現品質を向上させつつ余分な計算負荷をかけない新しい手法が必要です。
単語表現の発展は、Word2Vec(Mikolov et al., 2013) で分散型埋め込みが確立されて以来大きく進化しています。その後、 GloVe(Pennington et al., 2014) はグローバル共起統計を取り入れ学習の安定性を高め、FastText(Bojanowski et al., 2017)はサブワード情報で希少語への耐性を向上させました。これらは固定トークン表現と軽量な合成機能により、大規模システムで実用化できるようになりました。
最近では、 static-similarity-mrl-multilingual-v1 や static-retrieval-mrl-en-v1(sentence-transformers, 2025)が登場し、静的埋め込みが文脈エンコーダーより400倍高速でありながら実用的な検索性能を発揮できることを示されました (Aarsen, 2025)。
しかし、コーパスやRAGパイプラインが急速に拡大する中で、さらに高速かつ高精度な埋め込みモデルへの需要は続いています。静的埋め込みと文脈エンコーダーのギャップを縮めることが不可欠です。重要なのは、静的埋め込みは表現力には限界があり、それが進歩を妨げています。固定トークン表現と軽量な合成機能に頼るため、複雑な意味関係を捉えるのは困難です。具体的には埋め込み空間で「異方性(anisotropy)」が問題になっており、次元ごとの分散が不均一になる方向バイアスが生じ、特徴間の表現バランスが崩れます。この現象は訓練中の勾配不安定性と関係し、表現容量の偏った発展を招き汎化性能を低下させます。
Matryoshka Embeddings(Kusupati et al., 2024) など最近の試みも主に圧縮手法に焦点を当てており、学習プロセス中のこの核心的な表現不均衡には十分対処できていません。
本記事では、静的埋め込みモデルの性能向上を図るシンプルなフレームワーク「SSE(Stable Static Embedding)」を提案します。SSE は勾配の流れを安定させ、学習中に次元間の不均衡を抑える「Separable DyT(Dynamic Tanh normalization)」(軽量な正規化機構である DyT(Zhu et al., 2025) の派生)を使用しています。Separable DyT は埋め込み活性化のスケールと飽和を動的に制御し、過学習を抑えつつ埋め込み空間の一様性を高めます。その結果、モデルの複雑さを増すことなく、より汎化性の高い表現が得られます。
実験では、SSE が従来の静的埋め込み手法を上回りつつもパラメータ数はコンパクトであることを示します。16MパラメータでNanoBEIR English mean nDCG@10において 0.512 を達成し、ベースラインを上回っています。また、同等の性能を持つ従来手法と比べてパラメータ数が半分に抑えられ、推論速度は約2倍となります。
3 手法
3.1 構造
SSEの中核となるのは、各埋め込み次元ごとのスケールに応じた勾配の流れを調整する、軽量な正規化モジュール Separable DyT です。Separable DyTは埋め込みベクトルに直接作用し、計算コストをほとんど増やさずに、EmbeddingBagの正規化層として組み込むことができます。
入力となる埋め込みベクトル $ \mathbf{x} \in \mathbb{R}^E $ に対して、SSEは各次元独立にSeparable DyTを適用し、正規化された表現 $ \mathbf{y} \in \mathbb{R}^E $ を生成します。その結果、ノイズが多く大きな成分を持つ次元からの学習信号を減衰させつつ、安定した情報を有する次元については勾配流を維持します。これは明示的なハイパーパラメータなしで、表現空間の汎化性能を高める暗黙的な正則化を可能にします。
\begin{aligned}
& \text{------------------------------------------------------------------------------} \\
& \textbf{Algorithm 1: SSE(Stable Static Embedding)} \\
& \text{------------------------------------------------------------------------------} \\
& \textbf{Input: } x: (B, S) \\
& \textbf{Output: } y: (B, E) \\
& \quad 1:\quad x_T: (B, S) \leftarrow \mathrm{Tonenizer}(x) \\
& \quad 2:\quad x_S: (B, E) \leftarrow \mathrm{EmbeddingBag}(x_T) \\
& \quad 3:\quad y: (B, E) \leftarrow \mathrm{Separable Dynamic Tanh normalization}(x_S) \\
& \quad 4:\quad \textbf{return } y \\
& \text{------------------------------------------------------------------------------} \\
\end{aligned}
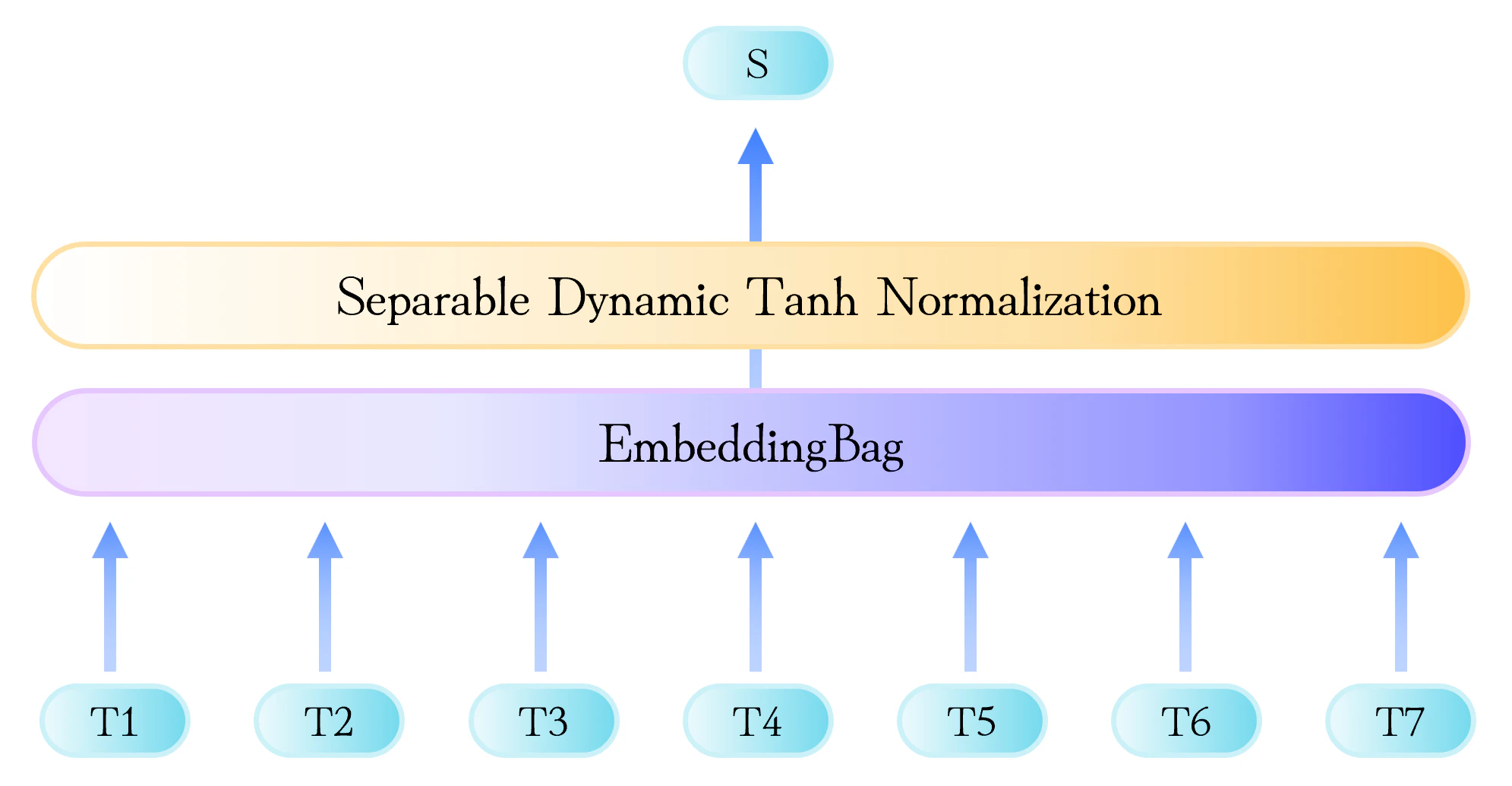
図 3 | SSE (Stable Static Embedding) のアーキテクチャ
3.2 Separable DyT(Dynamic Tanh normalization)
各埋め込み次元 $ x_k $ について、Separable DyT は出力を以下のように計算されます。
$$
y_k = \gamma_k \tanh(\alpha_k x_k + \beta_k),
$$
ここで $ \alpha_k, , \beta_k, , \gamma_k $ はそれぞれスケーリング、シフト、および出力振幅を制御する学習可能パラメータです。
\begin{aligned}
& \text{------------------------------------------------------------------------------} \\
& \textbf{Algorithm 2: Separable Dynamic Tanh normalization} \\
& \text{------------------------------------------------------------------------------} \\
& \textbf{Input: } x: (B, E) \\
& \textbf{Output: } y: (B, E) \\
& \textbf{Parameters: } \alpha, \beta, \gamma: (E) \\
& \quad 1:\quad x \leftarrow \alpha \cdot x + \beta \\
& \quad 2:\quad y: (B, E) \leftarrow \gamma \cdot \mathrm{Tanh}(x) \\
& \quad 3:\quad \textbf{return } y \\
& \text{------------------------------------------------------------------------------} \\
\end{aligned}
入力次元 $ x_k $ に関する微分は以下のようになります:
$$
\frac{\partial y_k}{\partial x_k} = \gamma_k \alpha_k , \mathrm{sech}^2(\alpha_k x_k + \beta_k).
$$
この形式は強度依存型のゲートを導入します。勾配の大きさは双曲線正接関数の二乗で調整されます。
飽和した次元 $ |x_k| > 1 $ の場合、
$$
|\alpha_k x_k + \beta_k| \gg 1,
$$
は指数関数的な減衰をもたらします。
$$
\mathrm{sech}^2(z) \sim 4 e^{-2|z|}.
$$
これにより勾配が抑制され、
$$
\frac{\partial y_k}{\partial x_k} \rightarrow 0.
$$
となります。
対して、非飽和の次元 $ |x_k| \ll 1 $ の場合、
$$
\mathrm{sech}^2(z) \approx 1,
$$
ほぼ一定の勾配を維持します。
$$
\frac{\partial y_k}{\partial x_k} \approx \gamma_k \alpha_k.
$$
この強度依存型のゲートは、ノイズが多く大きな成分を持つ次元からの学習信号を減衰させつつ、安定した情報を有する次元については勾配流を維持します。これは明示的なハイパーパラメータなしで、表現空間の汎化性能を高める暗黙的な正則化を可能にします。
3.3 強度依存型のゲートによる暗黙的な正則化
Separable DyT の重要な特性は、追加のハイパーパラメータを導入することなく暗黙的な正則化として機能する点です。強度依存型のゲート機構は最適化中に不安定な特徴方向を選択的に抑制することで、以下の効果をもたらします。
- 埋め込み空間内の次元間不均衡を削減
- 勾配の爆発と過剰増幅を防ぐ
- 極端な活性化を減衰させることで過学習を軽減
- 表現の一様性および異方性を改善
標準的な正規化技術(例:レイヤー正規化や L2 正規化)とは異なり、Separable DyT は埋め込み表現をグローバルに再スケーリングしません。代わりに、各次元が独立の動的範囲と感度を持てるようにする次元ごとの適応的調整を行います。
3.4 静的埋め込みモデルへの統合
Separable DyT は、埋め込み表現を固定次元の表現に集約する EmbeddingBag レイヤーの出力に適用されます。
$ \mathbf{E} \in \mathbb{R}^{V \times E} $ を埋め込み行列とし、文はトークンの集合 $ {t_1, \dots, t_n} $ で表されるとします。EmbeddingBag レイヤーは集約された表現を計算します。
$$
\mathbf{z} = \mathrm{EmbeddingBag}(t_1, \dots, t_n)
$$
ここで、集約は通常、選択された埋め込みに対する平均プーリングによって行われます。
集約された表現に対して Separable DyT が適用されます。
$$
\mathbf{s} = \mathrm{SeparableDyT}(\mathbf{z})
$$
ここで $ \mathbf{s} \in \mathbb{R}^E $ は最終的な文埋め込みを表します。
Separable DyT が集約されたベクトルに対して要素ごとに作用し、次元ごとにわずかなパラメータしか導入しないため、既存の静的埋め込みアーキテクチャに簡便に統合され、その構造的シンプル性を損なうことなく機能します。
3.5 計算効率
SSE は静的埋め込みモデルの主要な利点である極めて高速な推論を維持しています。EmbeddingBag は埋め込み表現の効率的な集約を行い、逐次計算や深い文脈エンコーディングの必要性を回避します。
Separable DyT 変換は、要素ごとの積と Tanh activationから構成されており、どちらも計算コストが低く高度に並列化可能です。Separable DyT による追加パラメータの数は埋め込み次元に比例して増加しますが、EmbeddingBagと比較すると無視できるレベルです。
したがって、SSE は静的埋め込みモデルの定数時間推論特性を維持しつつ、埋め込み空間の安定性と表現力を改善します。
4 実験
4.1 学習
対照学習と Matryoshka Loss を組み合わせ、埋め込みモデルの学習を行いました。これは Train 400x faster Static Embedding Models with Sentence Transformers(Aarsen, 2025) に記載されている手法を踏襲しています。Matryoshka Loss の次元は 32、64、128、256、512 で設定し、これにより異なる埋め込みサイズにおいても検索性能を維持できます。
bf16 を用いた混合精度計算を有効にした AdamW optimizerを使用しました。学習率は 0.1 に設定し、cosine scheduleとwarm-up ratioは 0.1 を採用しています。batch size 512 と gradient accumulation 8 によりglobal batch sizeは 4096 となります。学習は1 epoch (num_train_epochs=1) 行い、各ステップでモデルを評価しました。また、対照学習における重複ペアによる過学習を防ぐため、no_duplicates を適用しています。
非デフォルトのハイパーパラメータは下記の通りです。
表 1 | 学習時のハイパーパラメータ
| Parameter | Value |
|---|---|
| Optimizer | AdamW (beta2: 0.9999, epsilon: 1e-10) |
| Learning Rate | 0.1 |
| LR Scheduler | Cosine Decay |
| Warmup Ratio | 0.1 |
| Batch Size (per device) | 512 |
| Gradient Accumulation Steps | 8 |
| Training Epochs | 1 |
| Precision | BF16 (bf16: True) |
| Evaluation Strategy | Steps |
| Dataloader Workers | 4 |
| Batch Sampler | no_duplicates |
4.2 データセット
様々な検索およびSTSタスクでの汎化性を確保するために、多様な 15 のデータセット で訓練を行いました。これらのデータセットは質問応答(QA)、自然言語推論(NLI)、情報検索(IR)のドメインをカバーしています。
表 2 | 訓練データセット
| Dataset | Domain | Ratio |
|---|---|---|
squad |
Question Answering | ~2% |
trivia_qa |
Question Answering | ~2% |
allnli |
Natural Language Inference | ~2% |
pubmedqa |
Scientific QA | ~2% |
hotpotqa |
Multi-hop QA | ~2% |
miracl |
Multilingual IR | ~2% |
mr_tydi |
Multilingual IR | ~2% |
msmarco |
Web Search IR | ~5% |
msmarco_10m |
Large-scale IR | ~45% |
msmarco_hard |
Hard Negative Mining | ~2% |
mldr |
Long Document Retrieval | ~2% |
s2orc |
Scientific Text | ~14% |
swim_ir |
Semantic Web IR | ~2% |
paq |
Question Answering | ~14% |
nq |
Natural Questions | ~2% |
4.3 モデル
SSEと以下の2つのベースラインを比較しました。
- Static Embedding (no DyT): DyTレイヤーなしの静的埋め込みモデル
- Static Embedding + DyT: 先行研究で報告された通常のDynamic Tanh normalizationを組み込んだ静的埋め込みモデル
\begin{aligned}
& \text{------------------------------------------------------------------------------} \\
& \textbf{Algorithm 3: Dynamic Tanh normalization} \\
& \text{------------------------------------------------------------------------------} \\
& \textbf{Input: } x: (B, E) \\
& \textbf{Output: } y: (B, E) \\
& \textbf{Parameters: } \alpha: (1) \\
& \qquad \qquad \qquad \; \beta, \gamma: (E) \\
& \quad 1:\quad x \leftarrow \mathrm{Tanh}(\alpha \cdot x) \\
& \quad 2:\quad y: (B, E) \leftarrow \gamma \cdot x + \beta\\
& \quad 3:\quad \textbf{return } y \\
& \text{------------------------------------------------------------------------------} \\
\end{aligned}
4.4 学習結果
図4は、3つのモデルにおける損失と勾配を示しています。
損失の収束(図4(a)):3つのモデルはいずれもほぼ同様の損失の推移を示し、約19から急速に低下して2〜3の範囲で安定します。この収束の様子から、観測される性能の違いは、損失の低下速度や最終的な損失値の差によるものではないことがわかります。
勾配の挙動(図4(b)):勾配の大きさを見ると、明確な違いが現れます。Static Embedding を用いたベースライン(紫色)は、学習全体を通して一貫して低い値を保っており、勾配消失や特徴の過度な抑制といった問題の可能性が示唆されます。一方、SSE(ピンク色)は初期に大きくばらついた後、およそ 0.2 程度の適度な水準に落ち着きます。この挙動は、大きな入力による活性化関数の飽和を防ぐために、勾配の流れが適切に調整されていることを示しています。情報量の多い次元でゼロでない勾配を保つことで、SSEは学習中も継続的にパラメータ更新を行うことができ、ベースラインで見られるような特徴学習の早期停滞を避けています。
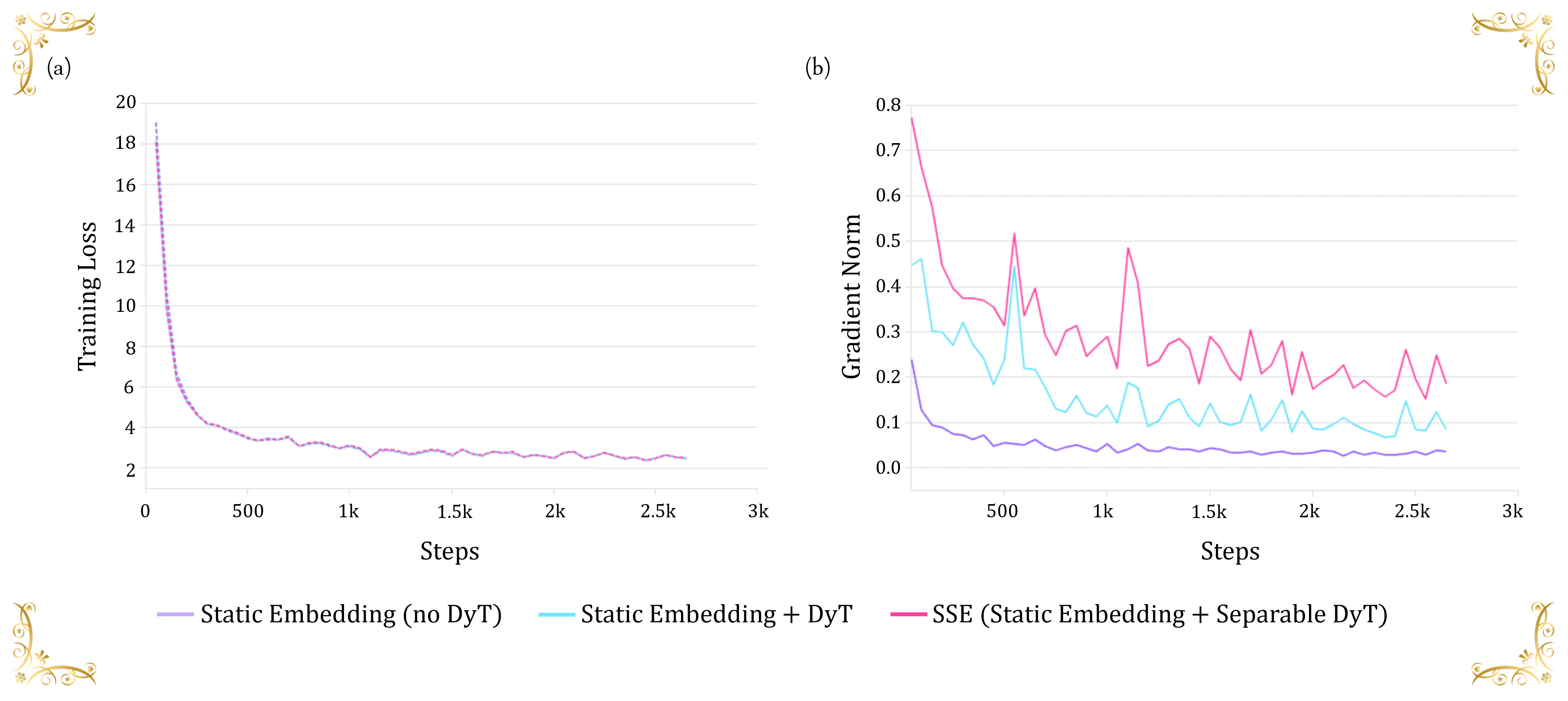
図4 | (a) 損失と (b) 勾配ノルムのトレーニングステップごとの比較
5 評価
5.1 NanoBEIR mean nDCG@10の推移
図5は、ベースラインと比較したSSEの学習過程と最終的な性能を示しています。結果から、SSEは学習のほとんどのステップで2つベースラインモデルを安定して上回っており、特に後半(ステップ1k以降)でその差が顕著に現れています。
- 収束性:ピンクの線が示すように、SSEは平均nDCG@10で約0.5124の最大値に到達し、紫の線で示される従来の静的埋め込みベースライン(約0.5068で頭打ち)を上回っています。これは検索精度において約1.3%の改善に相当します
- 次元分離の重要性:一方で、通常のDyTを用いたモデル(シアンの線)は、ベースラインを下回り、0.497から0.503の間で推移しています。この結果は、非分離的な正規化を適用すると、有用な特徴が抑えられたり、次元ごとの不安定さに十分対応できない可能性を示唆しています。これに対して、SSEのSeparable DyTは各次元ごとに勾配を適応的に調整することで、これらの問題を効果的に解消しています
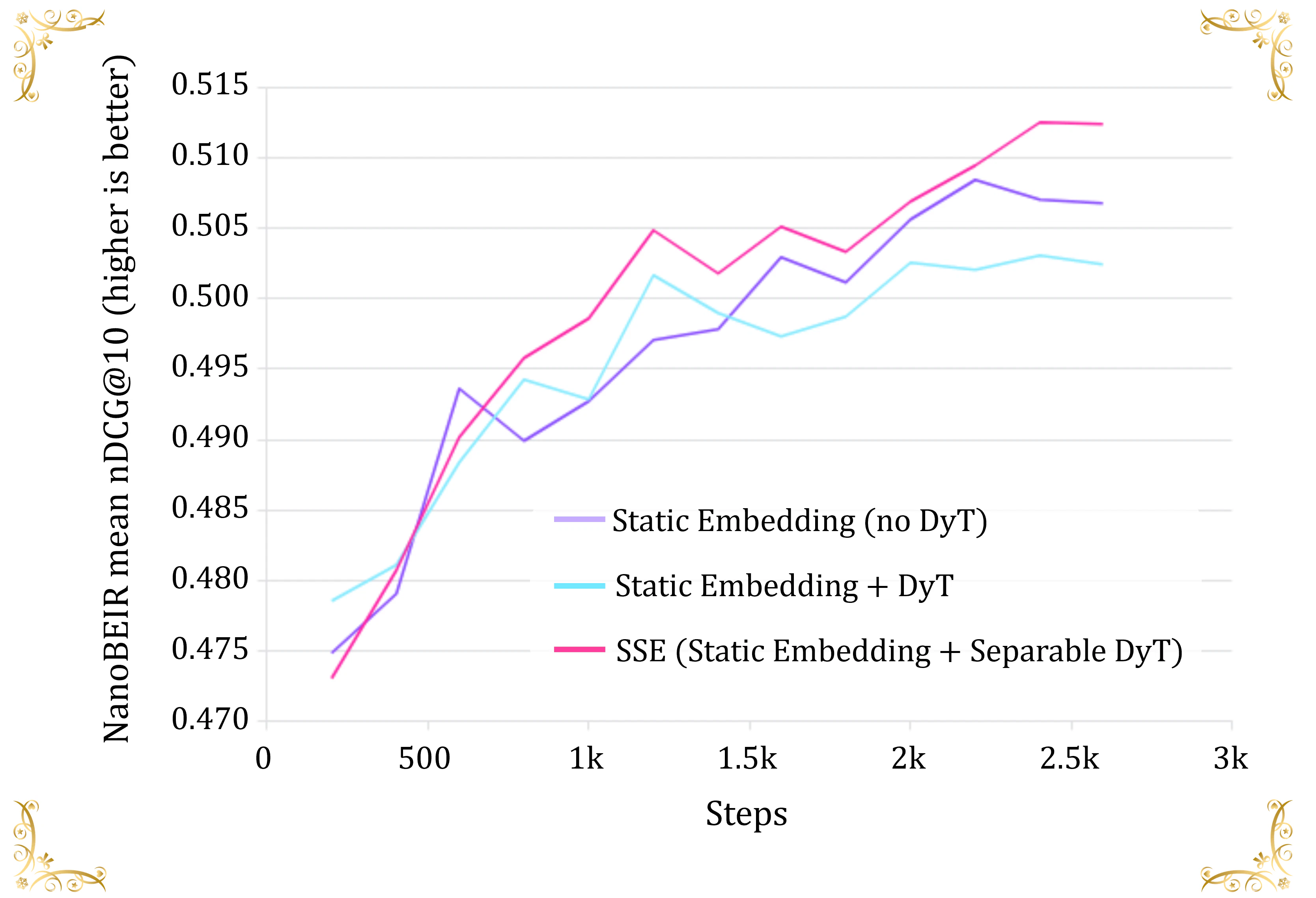
図5 | トレーニングステップごとの NanoBEIR mean nDCG@10
表3 | NanoBEIR English nDCG@10 の比較。
| Model | NanoArguAna nDCG@10 | NanoClimateFEVER nDCG@10 | NanoDBPedia nDCG@10 | NanoFEVER nDCG@10 | NanoFiQA2018 nDCG@10 | NanoHotpotQA nDCG@10 | NanoMSMARCO nDCG@10 | NanoNFCorpus nDCG@10 | NanoNQ nDCG@10 | NanoQuoraRetrieval nDCG@10 | NanoSCIDOCS nDCG@10 | NanoSciFact nDCG@10 | NanoTouche2020 nDCG@10 | Mean nDCG@10 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SSE(Static Embedding + Separable DyT) | 0.4105 | 0.2998 | 0.5493 | 0.6808 | 0.3744 | 0.7021 | 0.4132 | 0.2982 | 0.4652 | 0.9094 | 0.3381 | 0.6176 | 0.6029 | 0.5124 |
| Static Embedding + DyT | 0.3615 | 0.2717 | 0.5632 | 0.6716 | 0.3393 | 0.6765 | 0.4367 | 0.3142 | 0.4674 | 0.9094 | 0.3267 | 0.6129 | 0.5816 | 0.5025 |
| Static Embedding (No DyT) | 0.3884 | 0.3005 | 0.5552 | 0.7125 | 0.3573 | 0.6783 | 0.4219 | 0.2955 | 0.4638 | 0.8979 | 0.3264 | 0.6076 | 0.5834 | 0.5068 |
5.2 Matryoshka
SSEフレームワークの有効性を検証するため、NanoBEIRベンチマークで、異なる埋め込み次元(32〜512)における検索性能を評価しました。SSEは、通常の静的埋め込みおよび参照モデル(static-retrieval-mrl-en-v1)と比較して、計算効率を保ちながら一貫して高い検索性能を示すことが確認されました。
図6に示すように、埋め込み次元の増加に伴い、SSEモデル(ピンク線)はすべてのベースラインに対して明確な優位性を示します。参照モデル(static-retrieval-mrl-en-v1)は次元32においてnDCG@10が0.3532(SSEは0.3448)となり、初期段階ではSSEを上回りますが、次元64以降では逆転します。次元64では、SSEは0.4275を記録し、参照モデルを約2.4%上回ります。さらに次元が大きくなるにつれてこの差は拡大し、次元512ではSSEが0.5124に達し、参照モデル(0.4957)および「Static Embedding + DyT」ベースライン(0.5025)を上回ります。これらの結果から、SSEは埋め込み次元の増加に応じて効果的にスケールし、追加された表現能力を従来手法よりも効率的に活用できることが分かります。
SSEと非分離型のDynamic Tanh正規化を用いたモデル(「Static Embedding + DyT」)と比較すると、すべての次元においてSSEが一貫して上回る結果となりました(例:dim 512では0.5124 vs 0.5025)。この性能向上は、前述仮説を支持しています。すなわち、各次元ごとに独立して正規化を行うことで、より精緻なスケール適応型の勾配制御が可能になるという点です。具体的には、Separable DyTは極端に大きな値を持つ次元を抑えつつ、有用な情報を保持し、従来の一括的な正規化よりも安定した埋め込み構造を実現します。
最後に、SSEは効率と精度のバランスにも優れています。計算コストが低い小規模な次元(64や128など)でも、高次元モデルに匹敵する性能を維持します。これは、Separable DyTが限られた次元に情報を効果的に集約できることを示しています。SSEはリソース制約のある環境でも高精度を実現しつつ、次元の増加に対しても安定して性能を伸ばせる、実用性の高い検索手法といえます。
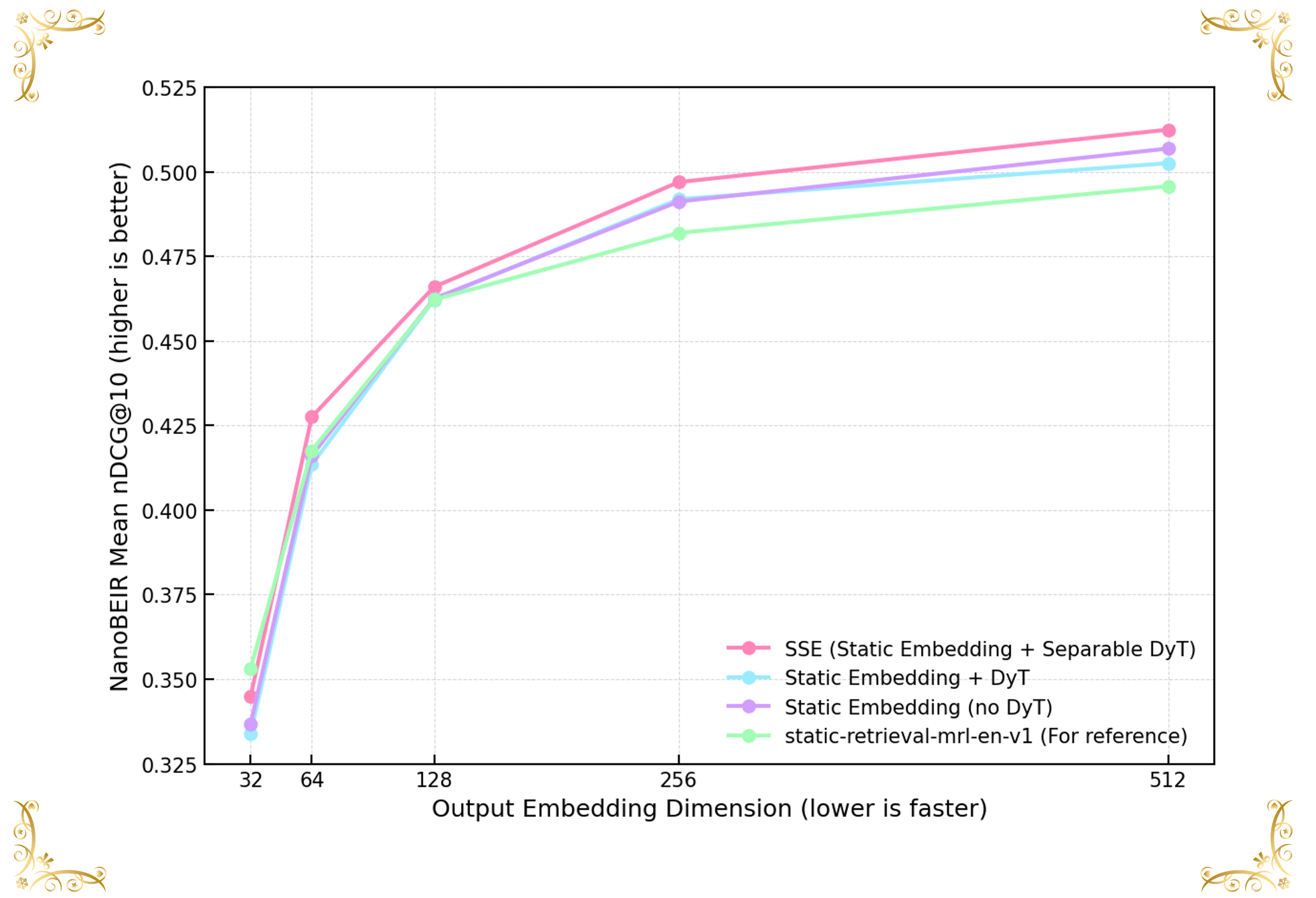
図6 | NanoBEIR English mean nDCG@10 と Matryoshka Embedding Truncation
表4 | NanoBEIR English mean nDCG@10 と Matryoshka Embedding Truncation
| モデル | 32 | 64 | 128 | 256 | 512 | 1024 |
|---|---|---|---|---|---|---|
| SSE (Static Embedding + Separable DyT) | 0.3448 | 0.4275 | 0.4659 | 0.4969 | 0.5124 | - |
| Static Embedding + DyT | 0.3338 | 0.4134 | 0.4622 | 0.4919 | 0.5025 | - |
| Static Embedding (no DyT) | 0.3367 | 0.4161 | 0.4625 | 0.4912 | 0.5068 | - |
| static-retrieval-mrl-en-v1 (For reference) | 0.3532 | 0.4176 | 0.4622 | 0.4819 | 0.4957 | 0.5031 |
5.3 パフォーマンス(英語検索タスク)
英語検索タスクに関して精度と速度の評価を行いました(図7)。図から、Transformerモデルが最も高い絶対精度(nDCG@10>0.60)を達成している一方で、低い推論速度(QPS < 10,000)となっていることが分かります。一方で、多くの静的埋め込み手法は nDCG@10<0.50となっています。
SSEモデル(stable-static-embedding-fast-retrieval-mrl-en)は、mean nDCG@10 が 0.50 を上回りつつ、スループットも 50,000 QPS を超えています。特筆すべき点として、他のStatic Embeddingアプローチと比較して 2.16倍の高速化を実現しながら、高い精度を維持しています。このような効率向上は、Separable DyTによって導入された強度適応的な勾配の流れが埋め込み次元の飽和を防ぎ、高次元の静的表現においても豊かな情報を保てていることを示唆しています。
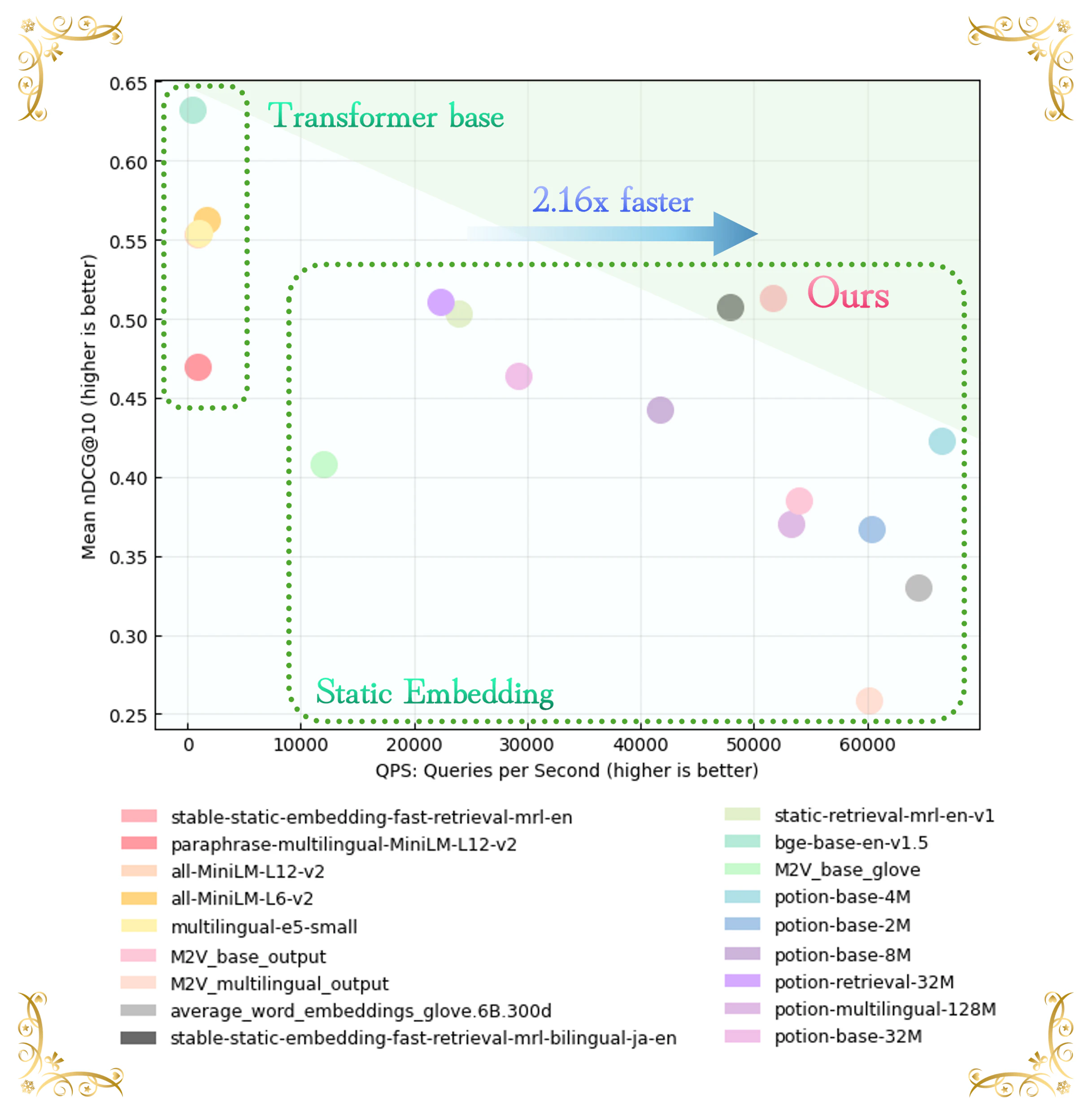
図 7 | mean nDCG@10 vs 推論速度 (QPS: Query Per Second) (Intel® Core™ Ultra 7 265K (3.90 GHz)、バッチサイズ:32、データセット:TREC-COVID 及び Quora)
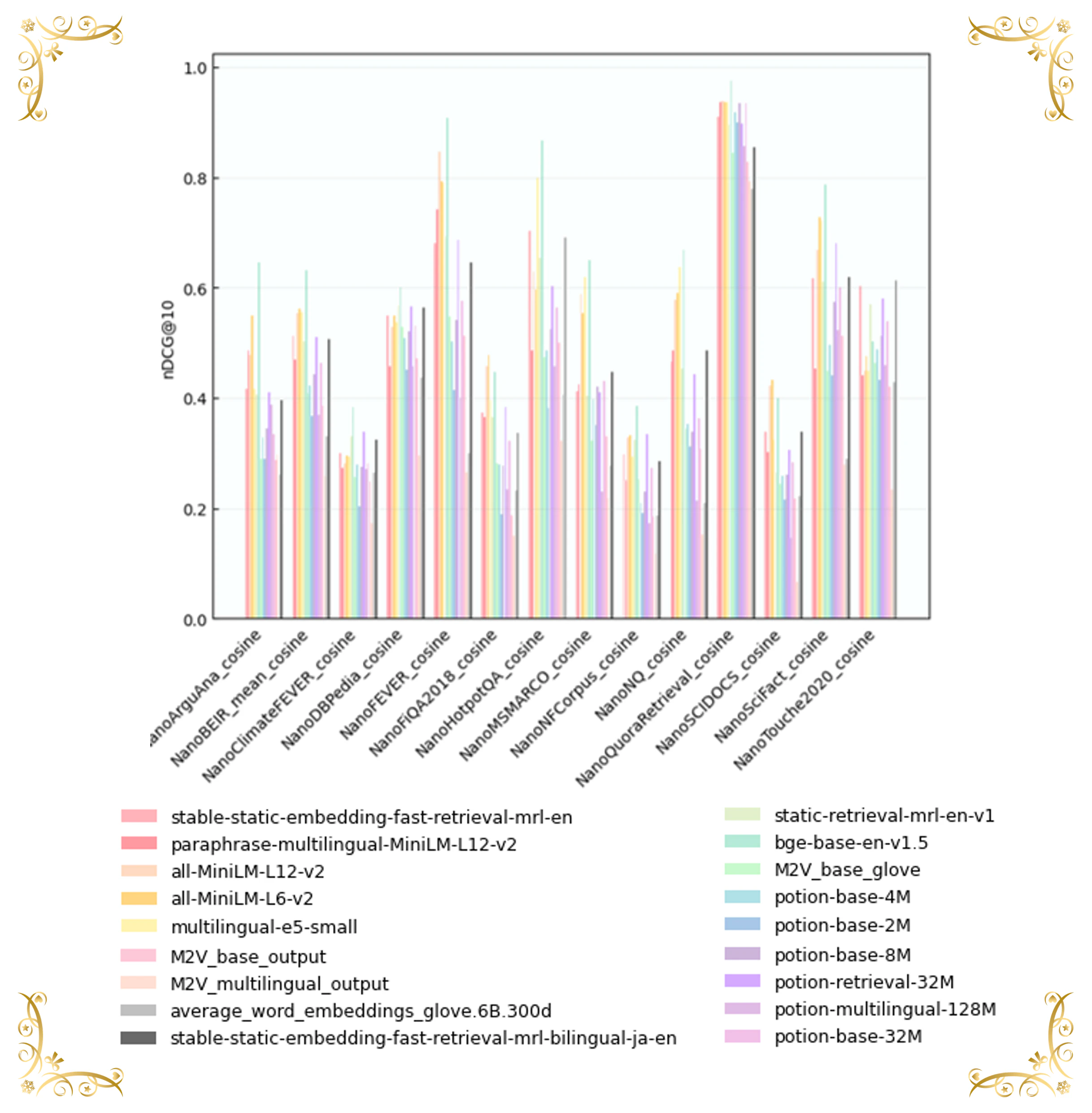
図 8 | NanoBEIR Englishにおける検索性能(nDCG@10)
5.4 パフォーマンス(日本語検索タスク)
図9は、日本語検索ベンチマークにおける性能分布を示しています。Transformerベースのモデルは高精度・低スループットの領域(左側)に位置する一方、従来の静的埋め込みは高速であるにもかかわらず、性能の低い領域に集中していることがわかります。
SSEモデル(stable-static-embedding-fast-retrieval-mrl-ja)は、このギャップを効果的に埋め、右上領域に位置しています。具体的には、mean nDCG@10が 0.45 を超えつつ、約 60,000 QPS のスループットを達成しています。この結果は、SSEが従来の静的埋め込みを大きく上回るだけでなく、同程度の精度においてベースラインと比較して 1.46倍の高速化 を実現していることを示しています。
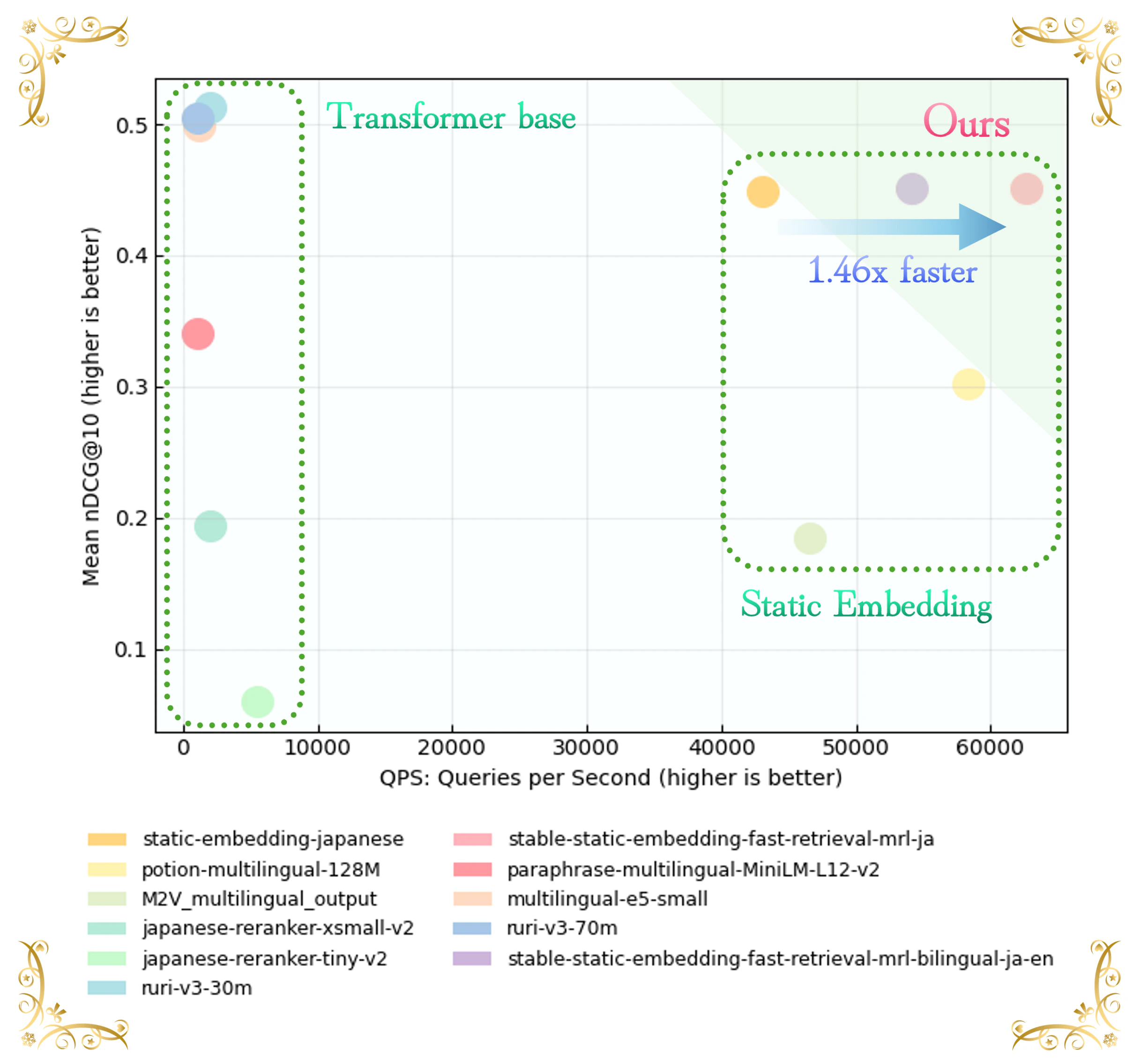
図 9 | mean nDCG@10 vs 推論速度 (QPS: Query Per Second) (Intel® Core™ Ultra 7 265K (3.90 GHz)、バッチサイズ:32、データセット:Miracl)
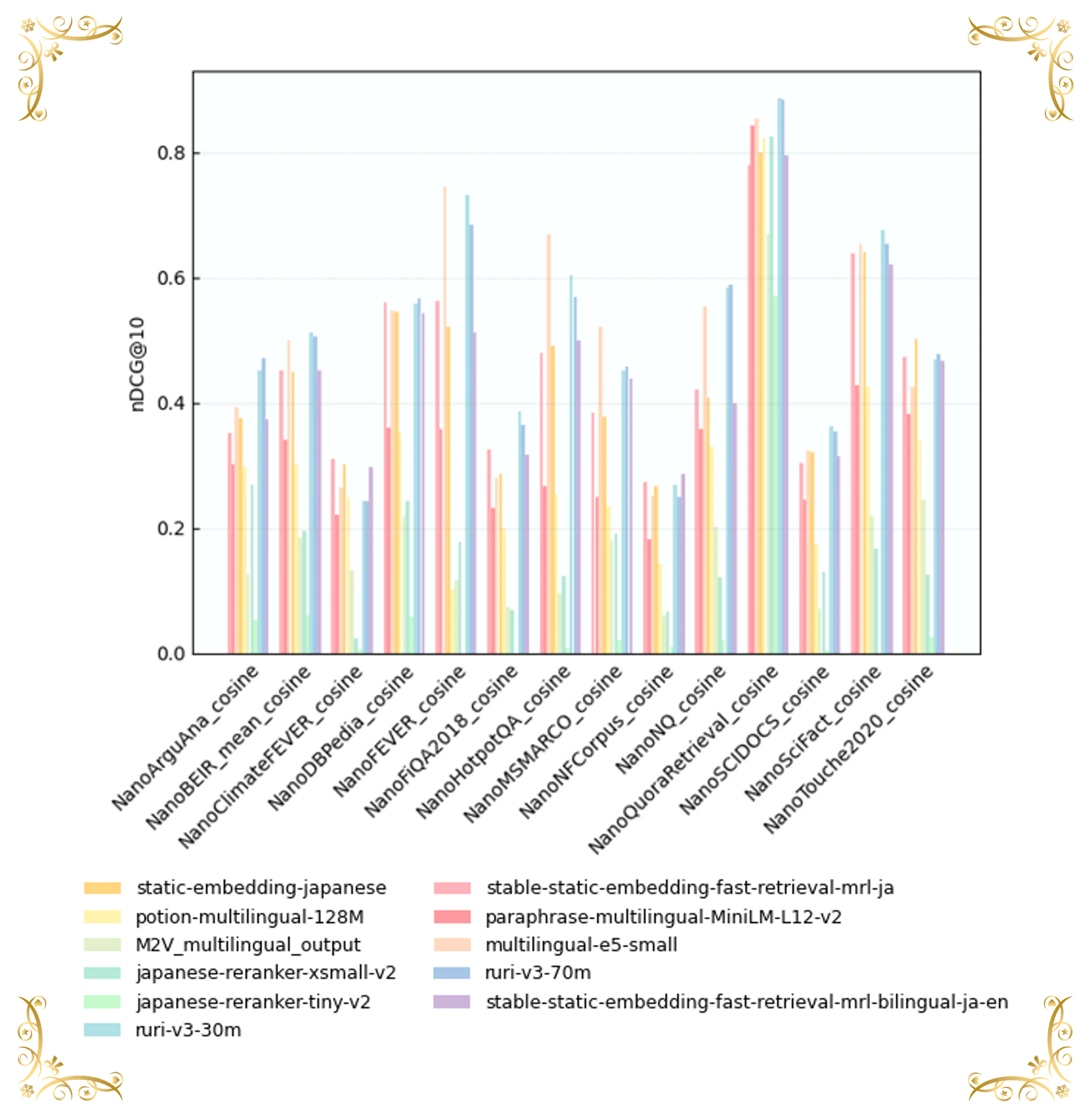
図 10 | NanoBEIR Japaneseにおける検索性能(nDCG@10)
5.5 スペクトル分析
学習された埋め込み行列に対してPCAによるスペクトル分析を行うことで、SSEが高い性能を示す背景にある表現幾何の特徴が明らかになります。図11に示すように、ベースラインであるStatic Embeddingでは、正規化された固有値が512次元全体にわたって緩やかに減衰しており、意味的な分散が多くの方向に広く分布し、有効ランクが比較的高い状態にあることが示唆されます。
一方、Standard DyTでは、PC ≈ 480付近でスペクトルが急激に落ち込む“崖”のような挙動が見られ、末尾の次元で分散が突然失われています。これは、高次元の分散が急激に抑制される不安定な圧縮が起きており、埋め込み空間の幾何構造を乱している可能性を示しています。
これに対してSSEでは、PC ≈ 430付近からより早い段階で減衰が始まるものの、その変化は滑らかで、その後の次元では固有値が速やかにゼロへと近づいていきます。この挙動は、SSEが暗黙的に低ランク正則化のような働きをし、意味的な分散をよりコンパクトな部分空間に集中させつつ、ノイズが支配的な方向を抑制していることを示唆しています。このように制御された圧縮により、コサイン類似度や距離構造の安定性が向上し、その結果として下流タスクにおける検索性能の改善につながっていると考えられます。
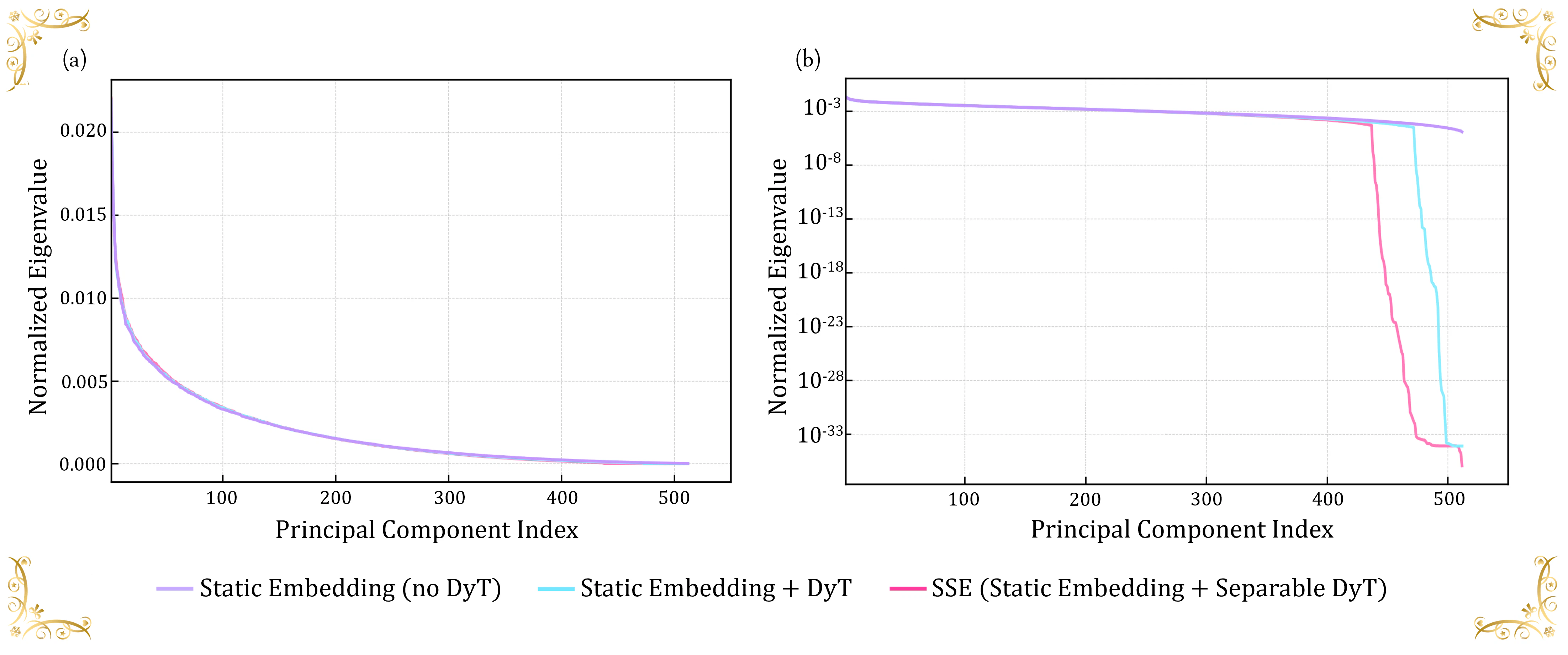
図 11 | NanoBEIR English DatasetsにおけるPCAスペクトル(a)線形スケール(b)対数スケール
6 議論
6.1 適用範囲と限界
SSEの有効性は、現時点では静的なテキスト埋め込みの文脈において実験的に確認されている点に注意が必要です。本研究の枠組みでは、Separable DyT はルックアップテーブルを通じて取得される埋め込みベクトル(例:単語IDやアイテムID)に対して作用しています。本手法が他の表現形式にも適用可能かどうかは、依然として未解明の課題です。
6.2 今後の研究課題
SSEをより広い研究範囲へと拡張することは、有望な研究方向であると考えています。具体的には、以下のような領域があると考えられます。
- 動的・文脈依存埋め込み:今後の研究では、Separable DyT を Transformer ベースのアーキテクチャ(例:LayerNormやRMSNormの代替または補完)に組み込むことが検証されると考えられます。これは、入力文脈に応じて隠れ状態が動的に変化する深層ネットワークにおいて、学習の安定化に寄与するかどうかを検証する目的です
- クロスモーダル:強度依存型ゲートの原理はテキストデータに限定されるものではありません。今後の研究では、画像パッチの埋め込みなど高次元ベクトルの安定性が重要となる他のモダリティへの適用も有望な研究方針となります
- 最適化手法:Separable DyT を用いたモデルがさまざまな最適化手法(例:MuonやSGDなど)の下で、本研究と同様の結果を呈するのかは未検証事項です
7 公開モデル

7.1 SSE
RikkaBotan/stable-static-embedding-fast-retrieval-mrl-en
- SSE for Retrieval MRL English version
表5 | NanoBEIR English Evaluation
| Dataset | nDCG@10 | MRR@10 | MAP@100 |
|---|---|---|---|
| NanoBEIR Mean | 0.5124 | 0.5640 | 0.4317 |
| NanoClimateFEVER | 0.2998 | 0.3611 | 0.2344 |
| NanoDBPedia | 0.5493 | 0.7492 | 0.4247 |
| NanoFEVER | 0.6808 | 0.6318 | 0.6105 |
| NanoFiQA2018 | 0.3744 | 0.4197 | 0.3162 |
| NanoHotpotQA | 0.7021 | 0.7679 | 0.6273 |
| NanoMSMARCO | 0.4132 | 0.3537 | 0.3733 |
| NanoNFCorpus | 0.2982 | 0.4889 | 0.1091 |
| NanoNQ | 0.4652 | 0.3992 | 0.4028 |
| NanoQuoraRetrieval | 0.9094 | 0.9122 | 0.8847 |
| NanoSCIDOCS | 0.3381 | 0.5509 | 0.2604 |
| NanoArguAna | 0.4105 | 0.3193 | 0.3325 |
| NanoSciFact | 0.6176 | 0.5933 | 0.5824 |
| NanoTouche2020 | 0.6029 | 0.7852 | 0.4539 |
RikkaBotan/stable-static-embedding-fast-retrieval-mrl-ja
- SSE for Retrieval MRL Japanese version
表6 | NanoBEIR Japanese Evaluation
| Dataset | nDCG@10 | MRR@10 | MAP@100 |
|---|---|---|---|
| NanoBEIR Mean | 0.4507 | 0.5090 | 0.3695 |
| NanoClimateFEVER | 0.3110 | 0.4208 | 0.2347 |
| NanoDBPedia | 0.5596 | 0.7652 | 0.4000 |
| NanoFEVER | 0.5611 | 0.5003 | 0.4923 |
| NanoFiQA2018 | 0.3247 | 0.3731 | 0.2692 |
| NanoHotpotQA | 0.4795 | 0.5758 | 0.4182 |
| NanoMSMARCO | 0.3845 | 0.3191 | 0.3335 |
| NanoNFCorpus | 0.2736 | 0.4544 | 0.1014 |
| NanoNQ | 0.4218 | 0.3658 | 0.3572 |
| NanoQuoraRetrieval | 0.7786 | 0.7750 | 0.7428 |
| NanoSCIDOCS | 0.3026 | 0.4850 | 0.2192 |
| NanoArguAna | 0.3521 | 0.2686 | 0.2793 |
| NanoSciFact | 0.6372 | 0.6100 | 0.5990 |
| NanoTouche2020 | 0.4731 | 0.7036 | 0.3572 |
RikkaBotan/stable-static-embedding-fast-retrieval-mrl-bilingual-ja-en
- SSE for Retrieval MRL Bilingual version (English & Japanese)
表7 | NanoBEIR English Evaluation
| Dataset | nDCG@10 | MRR@10 | MAP@100 |
|---|---|---|---|
| NanoBEIR Mean | 0.5073 | 0.5563 | 0.4207 |
| NanoClimateFEVER | 0.3239 | 0.4045 | 0.2612 |
| NanoDBPedia | 0.5647 | 0.7321 | 0.4262 |
| NanoFEVER | 0.6450 | 0.5790 | 0.5514 |
| NanoFiQA2018 | 0.3374 | 0.3838 | 0.2766 |
| NanoHotpotQA | 0.6897 | 0.7505 | 0.6177 |
| NanoMSMARCO | 0.4463 | 0.3621 | 0.3740 |
| NanoNFCorpus | 0.2844 | 0.4456 | 0.1071 |
| NanoNQ | 0.4851 | 0.4217 | 0.4186 |
| NanoQuoraRetrieval | 0.8554 | 0.8540 | 0.8202 |
| NanoSCIDOCS | 0.3376 | 0.5482 | 0.2566 |
| NanoArguAna | 0.3941 | 0.3154 | 0.3279 |
| NanoSciFact | 0.6185 | 0.5977 | 0.5881 |
| NanoTouche2020 | 0.6123 | 0.8369 | 0.4432 |
表8 | NanoBEIR Japanese Evaluation
| Dataset | nDCG@10 | MRR@10 | MAP@100 |
|---|---|---|---|
| NanoBEIR Mean | 0.4511 | 0.5141 | 0.3772 |
| NanoClimateFEVER | 0.2979 | 0.4005 | 0.2353 |
| NanoDBPedia | 0.5429 | 0.7633 | 0.4059 |
| NanoFEVER | 0.5133 | 0.4643 | 0.4661 |
| NanoFiQA2018 | 0.3174 | 0.3669 | 0.2619 |
| NanoHotpotQA | 0.5000 | 0.5672 | 0.4234 |
| NanoMSMARCO | 0.4372 | 0.3865 | 0.4022 |
| NanoNFCorpus | 0.2866 | 0.5185 | 0.1177 |
| NanoNQ | 0.3987 | 0.3500 | 0.3527 |
| NanoQuoraRetrieval | 0.7944 | 0.8100 | 0.7685 |
| NanoSCIDOCS | 0.3153 | 0.5127 | 0.2322 |
| NanoArguAna | 0.3721 | 0.2873 | 0.2990 |
| NanoSciFact | 0.6216 | 0.5904 | 0.5804 |
| NanoTouche2020 | 0.4662 | 0.6656 | 0.3589 |
7.2 SSE(量子化シリーズ)
RikkaBotan/quantized-stable-static-embedding-fast-retrieval-mrl-en
- Quantized SSE for Retrieval MRL English version
表9 | NanoBEIR English Evaluation
| Dataset | nDCG@10 | MRR@10 | MAP@100 |
|---|---|---|---|
| NanoBEIR Mean | 0.5110 | 0.5645 | 0.4312 |
| NanoClimateFEVER | 0.3127 | 0.3822 | 0.2439 |
| NanoDBPedia | 0.5472 | 0.7440 | 0.4252 |
| NanoFEVER | 0.6870 | 0.6402 | 0.6191 |
| NanoFiQA2018 | 0.3750 | 0.4155 | 0.3129 |
| NanoHotpotQA | 0.6927 | 0.7572 | 0.6205 |
| NanoMSMARCO | 0.4105 | 0.3504 | 0.3694 |
| NanoNFCorpus | 0.3063 | 0.4989 | 0.1148 |
| NanoNQ | 0.4523 | 0.3884 | 0.3941 |
| NanoQuoraRetrieval | 0.9147 | 0.9222 | 0.8944 |
| NanoSCIDOCS | 0.3345 | 0.5562 | 0.2622 |
| NanoArguAna | 0.4154 | 0.3151 | 0.3257 |
| NanoSciFact | 0.5972 | 0.5774 | 0.5703 |
| NanoTouche2020 | 0.5979 | 0.7910 | 0.4526 |
RikkaBotan/quantized-stable-static-embedding-fast-retrieval-mrl-ja
- Quantized SSE for Retrieval MRL Japanese version
表10 | NanoBEIR Japanese Evaluation
| Dataset | nDCG@10 | MRR@10 | MAP@100 |
|---|---|---|---|
| NanoBEIR Mean | 0.4477 | 0.5088 | 0.3675 |
| NanoClimateFEVER | 0.3152 | 0.4258 | 0.2417 |
| NanoDBPedia | 0.5554 | 0.7767 | 0.3962 |
| NanoFEVER | 0.5536 | 0.4907 | 0.4827 |
| NanoFiQA2018 | 0.3160 | 0.3614 | 0.2653 |
| NanoHotpotQA | 0.4722 | 0.5669 | 0.4136 |
| NanoMSMARCO | 0.3929 | 0.3237 | 0.3371 |
| NanoNFCorpus | 0.2686 | 0.4584 | 0.0962 |
| NanoNQ | 0.4170 | 0.3607 | 0.3571 |
| NanoQuoraRetrieval | 0.7768 | 0.7750 | 0.7393 |
| NanoSCIDOCS | 0.2939 | 0.4774 | 0.2197 |
| NanoArguAna | 0.3471 | 0.2617 | 0.2727 |
| NanoSciFact | 0.6387 | 0.6127 | 0.6001 |
| NanoTouche2020 | 0.4732 | 0.7240 | 0.3560 |
RikkaBotan/quantized-stable-static-embedding-fast-retrieval-mrl-bilingual-ja-en
- Quantized SSE for Retrieval MRL Bilingual version (English & Japanese)
表11 | NanoBEIR English Evaluation
| Dataset | nDCG@10 | MRR@10 | MAP@100 |
|---|---|---|---|
| NanoBEIR Mean | 0.5049 | 0.5526 | 0.4197 |
| NanoClimateFEVER | 0.3166 | 0.3874 | 0.2511 |
| NanoDBPedia | 0.5604 | 0.7321 | 0.4244 |
| NanoFEVER | 0.6511 | 0.5871 | 0.5595 |
| NanoFiQA2018 | 0.3179 | 0.3541 | 0.2617 |
| NanoHotpotQA | 0.6840 | 0.7459 | 0.6191 |
| NanoMSMARCO | 0.4417 | 0.3616 | 0.3748 |
| NanoNFCorpus | 0.2939 | 0.4535 | 0.1202 |
| NanoNQ | 0.4952 | 0.4287 | 0.4251 |
| NanoQuoraRetrieval | 0.8528 | 0.8533 | 0.8190 |
| NanoSCIDOCS | 0.3335 | 0.5460 | 0.2551 |
| NanoArguAna | 0.3978 | 0.3202 | 0.3326 |
| NanoSciFact | 0.6076 | 0.5842 | 0.5733 |
| NanoTouche2020 | 0.6105 | 0.8298 | 0.4406 |
表12 | NanoBEIR Japanese Evaluation
| Dataset | nDCG@10 | MRR@10 | MAP@100 |
|---|---|---|---|
| NanoBEIR Mean | 0.4493 | 0.5083 | 0.3744 |
| NanoClimateFEVER | 0.2883 | 0.3860 | 0.2218 |
| NanoDBPedia | 0.5458 | 0.7632 | 0.4048 |
| NanoFEVER | 0.4956 | 0.4403 | 0.4421 |
| NanoFiQA2018 | 0.3224 | 0.3667 | 0.2640 |
| NanoHotpotQA | 0.4866 | 0.5444 | 0.4117 |
| NanoMSMARCO | 0.4578 | 0.4085 | 0.4226 |
| NanoNFCorpus | 0.2731 | 0.4844 | 0.1138 |
| NanoNQ | 0.3944 | 0.3406 | 0.3436 |
| NanoQuoraRetrieval | 0.8003 | 0.8179 | 0.7766 |
| NanoSCIDOCS | 0.3156 | 0.5133 | 0.2325 |
| NanoArguAna | 0.3635 | 0.2758 | 0.2871 |
| NanoSciFact | 0.6341 | 0.6020 | 0.5903 |
| NanoTouche2020 | 0.4628 | 0.6646 | 0.3566 |
8 実装
8.1 Modeling
PyTorchを使用してSSEをsentence-transformersフレームワーク内で実装しました。モデルはライブラリのInputModuleから継承しており、入力処理および推論ワークフローとの完全な互換性を確保しています。
"""
coding = utf-8
Copyright 2026 Rikka Botan. All rights reserved
Licensed under "MIT License"
Stable Static Embedding official PyTorch implementation
"""
from __future__ import annotations
import os
from pathlib import Path
from safetensors.torch import save_file as save_safetensors_file
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from typing import Dict
from dataclasses import dataclass
from tokenizers import Tokenizer
from transformers import PreTrainedTokenizerFast
from sentence_transformers.models.InputModule import InputModule
class SeparableDyT(nn.Module):
def __init__(
self,
hidden_dim: int,
alpha_init: float = 0.5
):
super().__init__()
self.alpha = nn.Parameter(alpha_init*torch.ones(hidden_dim))
self.beta = nn.Parameter(torch.ones(hidden_dim))
self.bias = nn.Parameter(torch.zeros(hidden_dim))
def forward(
self,
x: torch.Tensor
) -> torch.Tensor:
x = self.beta * F.tanh(self.alpha * x + self.bias)
return x
class SSE(InputModule):
"""
Stable Static Embedding (SSE)
StaticEmbedding-compatible Sentence-Transformers module
"""
def __init__(
self,
tokenizer: Tokenizer | PreTrainedTokenizerFast,
vocab_size: int,
hidden_dim: int = 1024,
**kwargs,
):
super().__init__()
if isinstance(tokenizer, PreTrainedTokenizerFast):
tokenizer = tokenizer._tokenizer
elif not isinstance(tokenizer, Tokenizer):
raise ValueError("Tokenizer must be a fast (Rust) tokenizer")
self.tokenizer: Tokenizer = tokenizer
self.tokenizer.no_padding()
self.embedding = nn.EmbeddingBag(vocab_size, hidden_dim)
self.dyt = SeparableDyT(hidden_dim)
self.embedding_dim = hidden_dim
# For model card compatibility
self.base_model = kwargs.get("base_model", None)
# Tokenization (StaticEmbedding-compatible)
def tokenize(
self,
texts: list[str],
**kwargs
) -> dict[str, torch.Tensor]:
encodings = self.tokenizer.encode_batch(texts, add_special_tokens=False)
encodings_ids = [encoding.ids for encoding in encodings]
offsets = torch.from_numpy(
np.cumsum(
[0] + [len(token_ids) for token_ids in encodings_ids[:-1]]
)
)
input_ids = torch.tensor(
[token_id for token_ids in encodings_ids for token_id in token_ids],
dtype=torch.long
)
return {
"input_ids": input_ids,
"offsets": offsets
}
# Forward
def forward(
self,
features: Dict[str, torch.Tensor],
**kwargs,
) -> Dict[str, torch.Tensor]:
x = self.embedding(features["input_ids"], features["offsets"])
x = self.dyt(x)
features["sentence_embedding"] = x
return features
# Required APIs
def get_sentence_embedding_dimension(self) -> int:
return self.embedding_dim
@property
def max_seq_length(self) -> int:
return torch.inf
def save(
self,
output_path: str,
*args,
safe_serialization: bool = True,
**kwargs,
) -> None:
os.makedirs(output_path, exist_ok=True)
if safe_serialization:
save_safetensors_file(
self.state_dict(),
os.path.join(output_path, "model.safetensors"),
)
else:
torch.save(
self.state_dict(),
os.path.join(output_path, "pytorch_model.bin"),
)
self.tokenizer.save(
str(Path(output_path) / "tokenizer.json")
)
@classmethod
def load(
cls,
model_name_or_path: str,
**kwargs,
):
allowed_keys = {
"cache_dir",
"local_files_only",
"force_download",
}
filtered_kwargs = {
k: v for k, v in kwargs.items() if k in allowed_keys
}
tokenizer_path = cls.load_file_path(
model_name_or_path,
filename="tokenizer.json",
**filtered_kwargs,
)
tokenizer = Tokenizer.from_file(tokenizer_path)
weights = cls.load_torch_weights(
model_name_or_path=model_name_or_path,
**filtered_kwargs,
)
hidden_dim = weights["embedding.weight"].size(1)
vocab_size = weights["embedding.weight"].size(0)
model = cls(
tokenizer=tokenizer,
vocab_size=vocab_size,
hidden_dim=hidden_dim,
)
model.load_state_dict(weights)
return model
@dataclass
class SSESforzandoConfig:
hidden_dim: int = 512
vocab_size: int = 30522
@dataclass
class SSEForzandoConfig:
hidden_dim: int = 384
vocab_size: int = 30522
8.2 推論
以下のシンプルなコードで実行できます。
"""
coding = utf-8
Copyright 2026 Rikka Botan. All rights reserved
Licensed under "MIT License"
Stable Static Embedding inference implementation
"""
import torch
from sentence_transformers import SentenceTransformer
# load (remote code enabled)
model = SentenceTransformer(
"RikkaBotan/stable-static-embedding-fast-retrieval-mrl-en",
trust_remote_code=True,
device="cuda" if torch.cuda.is_available() else "cpu",
truncate_dim=256,
)
# inference
query = "What is Stable Static Embedding?"
sentences = [
"SSE: Stable Static embedding works without attention.",
"Stable Static Embedding is a fast embedding method designed for retrieval tasks.",
"Static embeddings are often compared with transformer-based sentence encoders.",
"I cooked pasta last night while listening to jazz music.",
"Large language models are commonly trained using next-token prediction objectives.",
"Instruction tuning improves the ability of LLMs to follow human-written prompts.",
]
with torch.no_grad():
embeddings = model.encode(
[query] + sentences,
convert_to_tensor=True,
normalize_embeddings=True,
batch_size=32
)
print("embeddings shape:", embeddings.shape)
# cosine similarity
similarities = model.similarity(embeddings[0], embeddings[1:])
for i, similarity in enumerate(similarities[0].tolist()):
print(f"{similarity:.05f}: {sentences[i]}")
8.3 Quantized Modeling
リソースの利用効率を最適化するために、4bit量子化モデリング(SSEQ)を行いました。データサイズの大幅な圧縮を実現し、元のモデルに匹敵する検索性能を維持しました。
"""
coding = utf-8
Copyright 2026 Rikka Botan. All rights reserved
Licensed under "MIT License"
Stable Static Embedding official PyTorch implementation
"""
from __future__ import annotations
import os
from pathlib import Path
from safetensors.torch import save_file as save_safetensors_file
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from typing import Dict
from dataclasses import dataclass
from tokenizers import Tokenizer
from transformers import PreTrainedTokenizerFast
from sentence_transformers.models.InputModule import InputModule
from safetensors.torch import load_file
def quantize_q4(weight: torch.Tensor):
"""
weight: (vocab, dim)
returns: packed uint8 + scale + zero
"""
w = weight.detach().cpu().numpy().astype(np.float32)
scales = np.max(np.abs(w), axis=1, keepdims=True) + 1e-8
w_norm = w / scales
q = np.clip(np.round((w_norm + 1) * 7.5), 0, 15).astype(np.uint8)
# pack 2x4bit -> uint8
packed = (q[:, 0::2] << 4) | q[:, 1::2]
return {
"packed": packed,
"scales": scales.astype(np.float32),
}
def dequantize_q4(packed: np.ndarray, scales: np.ndarray):
hi = (packed >> 4) & 0xF
lo = packed & 0xF
q = np.empty((packed.shape[0], packed.shape[1]*2), dtype=np.uint8)
q[:, 0::2] = hi
q[:, 1::2] = lo
w = (q.astype(np.float32) / 7.5) - 1.0
w = w * scales
return torch.from_numpy(w)
class SeparableDyT(nn.Module):
def __init__(
self,
hidden_dim: int,
alpha_init: float = 0.5
):
super().__init__()
self.alpha = nn.Parameter(alpha_init*torch.ones(hidden_dim))
self.beta = nn.Parameter(torch.ones(hidden_dim))
self.bias = nn.Parameter(torch.zeros(hidden_dim))
def forward(
self,
x: torch.Tensor
) -> torch.Tensor:
x = self.beta * F.tanh(self.alpha * x + self.bias)
return x
class SSEQ(InputModule):
"""
Stable Static Embedding (SSE)
StaticEmbedding-compatible Sentence-Transformers module
"""
def __init__(
self,
tokenizer: Tokenizer | PreTrainedTokenizerFast,
vocab_size: int,
hidden_dim: int = 1024,
**kwargs,
):
super().__init__()
if isinstance(tokenizer, PreTrainedTokenizerFast):
tokenizer = tokenizer._tokenizer
elif not isinstance(tokenizer, Tokenizer):
raise ValueError("Tokenizer must be a fast (Rust) tokenizer")
self.tokenizer: Tokenizer = tokenizer
self.tokenizer.no_padding()
self.embedding = nn.EmbeddingBag(vocab_size, hidden_dim)
self.dyt = SeparableDyT(hidden_dim)
self.embedding_dim = hidden_dim
# For model card compatibility
self.base_model = kwargs.get("base_model", None)
# Tokenization (StaticEmbedding-compatible)
def tokenize(
self,
texts: list[str],
**kwargs
) -> dict[str, torch.Tensor]:
encodings = self.tokenizer.encode_batch(texts, add_special_tokens=False)
encodings_ids = [encoding.ids for encoding in encodings]
offsets = torch.from_numpy(
np.cumsum(
[0] + [len(token_ids) for token_ids in encodings_ids[:-1]]
)
)
input_ids = torch.tensor(
[token_id for token_ids in encodings_ids for token_id in token_ids],
dtype=torch.long
)
return {
"input_ids": input_ids,
"offsets": offsets
}
# Forward
def forward(
self,
features: Dict[str, torch.Tensor],
**kwargs,
) -> Dict[str, torch.Tensor]:
x = self.embedding(features["input_ids"], features["offsets"])
x = self.dyt(x)
features["sentence_embedding"] = x
return features
# Required APIs
def get_sentence_embedding_dimension(self) -> int:
return self.embedding_dim
@property
def max_seq_length(self) -> int:
return torch.inf
def save(self, output_path: str):
os.makedirs(output_path, exist_ok=True)
state = self.state_dict()
emb = state["embedding.weight"]
q = quantize_q4(emb)
del state["embedding.weight"]
save_safetensors_file(
state,
os.path.join(output_path, "model_rest.safetensors"),
)
with open(os.path.join(output_path, "embedding.q4_k_m.bin"), "wb") as f:
f.write(q["packed"].tobytes())
f.write(q["scales"].tobytes())
self.tokenizer.save(
str(Path(output_path) / "tokenizer.json")
)
@classmethod
def load(cls, model_path: str):
tokenizer = Tokenizer.from_file(
os.path.join(model_path, "tokenizer.json")
)
state = load_file(
os.path.join(model_path, "model_rest.safetensors"),
device="cpu"
)
# read q4 binary
bin_path = os.path.join(model_path, "embedding.q4_k_m.bin")
with open(bin_path, "rb") as f:
raw = f.read()
hidden = state["dyt.alpha"].shape[0]
total_uint8 = len(raw)
bytes_per_row = hidden // 2 + 4
vocab = total_uint8 // bytes_per_row
packed_size = vocab * hidden // 2
packed = np.frombuffer(raw[:packed_size], dtype=np.uint8)
scales = np.frombuffer(raw[packed_size:], dtype=np.float32)
packed = packed.reshape(vocab, hidden // 2)
scales = scales.reshape(vocab, 1)
emb = dequantize_q4(packed, scales)
# rebuild model
model = cls(
tokenizer=tokenizer,
vocab_size=emb.shape[0],
hidden_dim=emb.shape[1]
)
state["embedding.weight"] = emb
model.load_state_dict(state)
return model
8.4 量子化
以下のコードを使用することで、重みを量子化できます。作成した重みと SSEQの実装をHugging Faceにアップロードすることで、他のsentence-transformers互換モデルと同じように使用できます。
"""
coding = utf-8
Copyright 2026 Rikka Botan. All rights reserved
Licensed under "MIT License"
Quantization implementation
"""
import os
from tokenizers import Tokenizer
from sentence_transformers import SentenceTransformer
from transformers import AutoTokenizer
from SSE import SSE
from SSE_quantize import SSEQ
def quantize_and_save_sse_from_hf(
hf_model_name: str,
output_path: str,
):
print(f"[1] Loading HF model: {hf_model_name}")
st_model = SentenceTransformer(hf_model_name)
sseq_module = None
for m in st_model.modules():
if isinstance(m, SSE):
sseq_module = m
break
if sseq_module is None:
raise ValueError("SSE module not found in the model")
print("[2] Extract tokenizer")
# tokenizer
try:
hf_tokenizer = AutoTokenizer.from_pretrained(hf_model_name)
tokenizer = Tokenizer.from_str(hf_tokenizer.backend_tokenizer.to_str())
except Exception:
tokenizer = sseq_module.tokenizer
print("[3] Rebuild SSEQ model")
# embedding weight
emb_weight = sseq_module.embedding.weight.detach().cpu()
model = SSEQ(
tokenizer=tokenizer,
vocab_size=emb_weight.shape[0],
hidden_dim=emb_weight.shape[1],
base_model=hf_model_name
)
state = sseq_module.state_dict()
model.load_state_dict(state)
print("[4] Quantize & Save")
os.makedirs(output_path, exist_ok=True)
model.save(output_path)
print(f"[✓] Quantized model saved to: {output_path}")
- 使用方法
quantize_and_save_sse_from_hf(
"RikkaBotan/stable-static-embedding-fast-retrieval-mrl-en",
"./sse-q4")
9 アプリケーション
-
RikkaBotan/Stable-Static-Embedding-Semantic-Web-Search-Japanese
-
RikkaBotan/Stable-Static-Embedding-Semantic-Web-Search-Bilingual-ja-en
-
このアプリケーションはSSEモデルを使用して高性能な検索を提供します。リアルタイムまたは大規模な検索タスクに適しています
謝辞
このモデルの学習のための計算リソースの一部は、Saldraさん、Witnessさん、Lumina Logic Minds社から提供いただきました。貴重なサポートに感謝いたします。
このテーマに関心を持ったきっかけは、Tom Aarsenさんの記事 Train 400x faster Static Embedding Models with Sentence Transformersを読んだことでした。この内容に触発され、静的埋め込みについて検討を進めるようになりました。興味のきっかけを作ってくださったTom Aarsenさんに感謝いたします。
sentence-transformers、python、pytorchを使用させていただきました。 作成・メンテンナンスしてくださっている皆様に感謝いたします。
何よりも、この研究にご興味を持ってくださりありがとうございます。
著者:六花牡丹(りっかぼたん)
おさげとハーフツイン・可愛いお洋服が好きで、基本的にふわふわしている変わり者です。
結構ドジで何もないところで転ぶタイプ。
人工知能に関しては独学のみ。
主な関心分野は自然言語処理・モデルのアーキテクチャ。
最近、白色のワンピースを買いがちで、新しいモードのお洋服に挑戦してみたいなぁと思っています。

参照論文・サイト等
-
sentence-transformers. static-similarity-mrl-multilingual-v1.
-
Hayato Tsukagoshi and Ryohei Sasano. Ruri: Japanese General Text Embeddings. arXiv:2409.07737, 2024.
-
sentence-transformers. paraphrase-multilingual-MiniLM-L12-v2.
-
sentence-transformers. average_word_embeddings_glove.6B.300d.
