内容
こちらの記事にあるBuzzFeedに勤務しているデータサイエンティストが作成したオープンソースを動かし、Jupyter notebookにてPlotlyによる可視化プログラムを動かしてみるという内容です。
環境
Os:macOS Sierra
Python:Python 3.6.1
Jupyter:4.3.0
R:3.4.2
Spark-apache:2.2.0
簡単なプログラムの説明
①Facebookから4つのニュースサイト(CNN,NYTimes,BuzzFeed,Upworthy)のタイトルからWord2Vecアルゴリズムを用いてclickbaitの可能性があるニュースのタイトルを分析する。分析結果をJupyterにて__Plotly__を使用して可視化を行う。
clickbait(クリックベイト)・・・わざと扇情的な見出しや刺激的なサムネイル画像をつけてネットユーザーのクリックを誘うウェブページやリンクや動画や広告などのこと
*今回使用しているFacebookのニュースのタイトルデータは、GitHubに公開されているデータをそのまま使用しています。
Word2Vec・・・単語の意味や文法を捉えるために単語をベクトル表現化し、文章を分類するアルゴリズム
*詳しことは参照元の記事を一読お願いいたします。
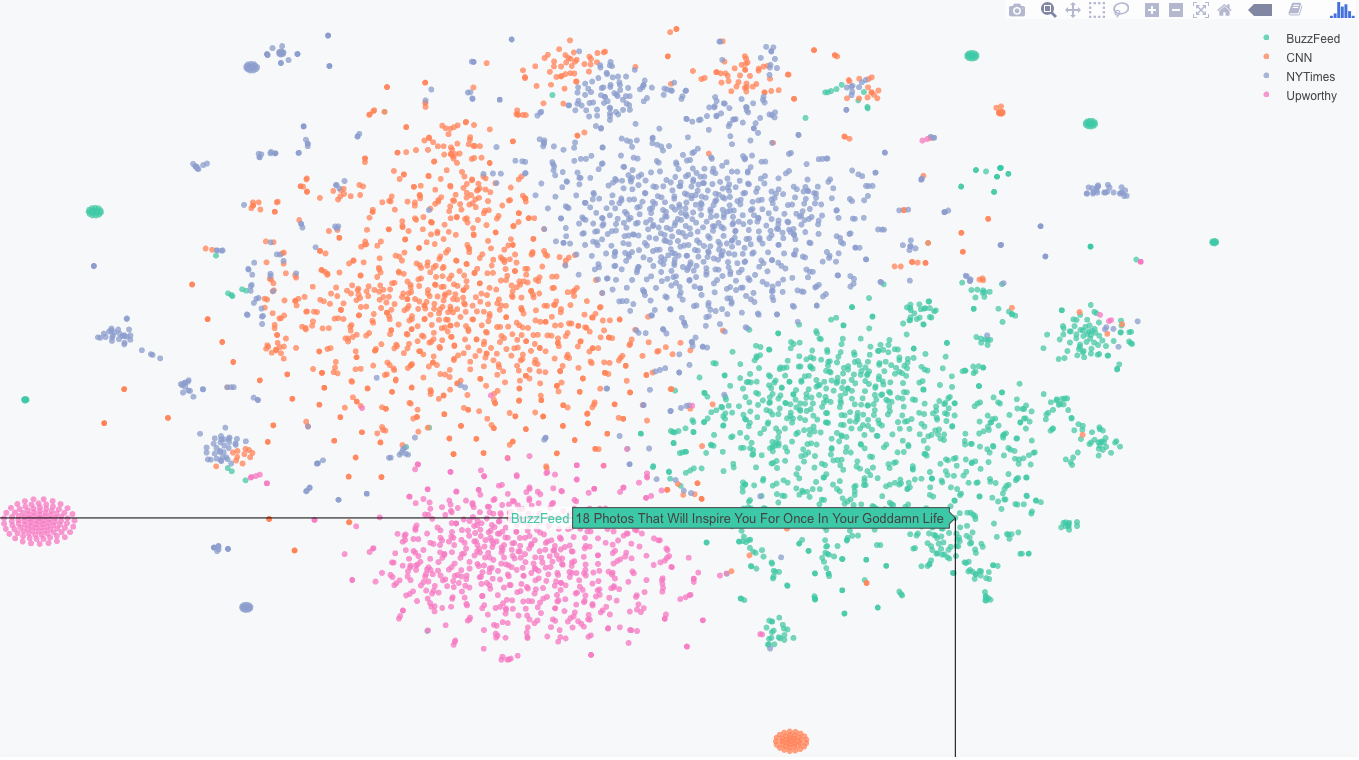
実際に可視化した結果
緑色で示されているBuzzFeedニュースのプロットのかたまりにいくつか別のニュースサイトのタイトルが紛れ込んでいます。(例:Which Olympic Sport Should You Play?)予想通りshould(〜すべきだ)と言った単語が含まれるタイトルはクリックベイトの可能性があると見てとれます。
環境構築
環境構築に必要なものは以下となります。
*他に別途で必要なものが発生した場合はその都度インストールをお願いします。
Jupyter notebook
こちらを参考にしてインストールしました。
Plotly
Plotlyをインストールし、Jupyter notebookで動かせるようにします。
こちらを参考にしてインストールしました。
R
Rをインストールし、Jupyter notebookで動かせるようにします。
こちらを参考にしてインストールしました。
Spark-apache
Spark-apacheをインストールし、Jupiter notebookで動かせるようにします。
こちらを参考にしてインストールしました。
プログラム実行
GitHubより必要なファイルをダウロードしてきます。
まずJupyterを起動し、プログラム「fb_news_53D_spark.ipynb」を実行します。
spark_path = "/usr/local/Cellar/apache-spark/2.2.0/libexec/"
# Easiest way to get Spark to work with Jupyter: https://github.com/minrk/findspark
# import findspark
# findspark.init(spark_path)
# import pyspark
# from pyspark.sql import SparkSession
# sc = pyspark.SparkContext(appName='fb_headlines')
# spark = SparkSession(sc)
# config = sc._conf.getAll()
# print ('Web URL: ' + filter(lambda x: 'spark.driver.host' in x[0], config)[0][1] + ':4040')
from pyspark.sql.functions import regexp_replace
from pyspark.sql import Column
from pyspark.sql.types import *
def process_df(df):
return (df
.withColumn('text',regexp_replace('link_name', '\'', ''))
.filter("text != ''")
.filter("text != 'Timeline Photos'")
)
def read_tsv(path):
# predefine data frame schema: faster
schema = StructType([
StructField("page_id", StringType(), True),
StructField("status_id", StringType(), True),
StructField("link_name", StringType(), True),
StructField("status_published", TimestampType(), True),
StructField("num_reactions", IntegerType(), True)])
return spark.read.csv(path ,schema = schema, header=True, inferSchema=True, sep="\t")
df_cnn = read_tsv("/fb_headlines/CNN_fb.tsv")
df_nytimes = read_tsv("/fb_headlines/NYTimes_fb.tsv")
df_buzzfeed = read_tsv("/BuzzFeed_fb.tsv")
df_upworthy = read_tsv("/fb_headlines/Upworthy_fb.tsv")
df = df_cnn.union(df_nytimes).union(df_buzzfeed).union(df_upworthy)
df = process_df(df).cache()
df.select('link_name', 'status_published', 'num_reactions').show()
print ( df.count() )
df.printSchema()
from pyspark.ml.feature import Tokenizer, RegexTokenizer
tokenizer = RegexTokenizer(pattern="[^\w]",inputCol="text", outputCol="words")
df = tokenizer.transform(df)
df.select('text','words').show()
from pyspark.ml.feature import Word2Vec
word2Vec = Word2Vec(vectorSize=50, seed=42, inputCol="words", outputCol="vectors")
model = word2Vec.fit(df)
df = model.transform(df)
df.select('words', 'vectors').show()
model.findSynonyms("olympics", 20).show()
model.findSynonyms("election", 20).show()
from pyspark.ml.feature import StringIndexer, OneHotEncoder
stringIndexer = StringIndexer(inputCol="page_id", outputCol="indexed")
model = stringIndexer.fit(df)
df = model.transform(df)
encoder = OneHotEncoder(inputCol="indexed", outputCol="page_ohe")
df = encoder.transform(df)
df.select('page_id', 'page_ohe').show()
from pyspark.ml.feature import VectorAssembler
model = VectorAssembler(inputCols=['page_ohe', 'vectors'], outputCol="merged_vectors")
df = model.transform(df)
df.select('merged_vectors').show()
df2 = df.filter(df.status_published > '2016-06-01 00:00:00').cache()
print ( df2.count() )
df2.printSchema()
import pandas as pd
(df2.select('page_id', 'status_id', 'link_name', 'status_published', 'num_reactions', 'merged_vectors')
.toPandas()
.to_csv('/clickbait-cluster-master/df_transform_53D.csv', index=False, encoding="utf-8")
)
facebookから取得するニュースのタイトルのデータは、Githubに公開されているデータをそのまま使用しています。
プログラム実行後、結果のCSVファイルが作成されていると思います。このデータは、ニュースのタイトルに含まれる各単語の単語ベクトルを、Word2vecアルゴリズムによって50ディメンションのベクトルに変換されたものです。
続いて、Jupyterにてプログラム「fb_news_53D_plotly.ipynb」を実行します。
*今回は9000件分のCSVデータが出力されていると思いますが、私の実行環境ではCPUのメモリが少なく実行できなかったため、半分の5000件のデータ分のCSVデータを作成し、実行しています。
options(warn=1)
source("/clickbait-cluster-master/Rstart.R")
library(htmlwidgets)
library(tidyr)
library(tsne)
# library(crosstalk) # Does not work unfortunately
library(plotly)
sessionInfo()
df <- read_csv('/clickbait-cluster-master/df_transform_53D.csv')
df %>% head() %>% print()
vector_names = paste0('w2v_', 1:53)
vector_trim <- function(vector)
substr(vector, 2, nchar(vector)-1)
vector_names %>% head() %>% print()
vector_trim(df$merged_vectors[1])
df$merged_vectors = lapply(df$merged_vectors, vector_trim)
df <- separate(data = df, col = merged_vectors, into = vector_names, convert=T, sep = ",")
df %>% select(w2v_1:w2v_4) %>% head() %>% print()
matrix <- df %>% select(w2v_1:w2v_53) %>% as.matrix()
system.time( cluster_coords <- tsne(matrix, initial_dims=53, perplexity=50, epoch=50) )
cluster_coords %>% head() %>% print()
df_transform = df %>% select(page_id, status_id, link_name, status_published, num_reactions) %>%
mutate(x = cluster_coords[,1], y= cluster_coords[,2])
df_transform %>% select(status_id, x, y) %>% head() %>% print()
write.csv(df_transform, "/clickbait-cluster-master/df_transform_53D.csv", row.names=F)
df_plot <- read_csv("/clickbait-cluster-master/df_transform_53D.csv")
df_plot %>% select(link_name, x, y) %>% mutate(link_name = substr(link_name,1,20)) %>% head() %>% print()
plot <- ggplot(df_plot, aes(x=x, y=y, color=page_id)) +
geom_point(alpha=0.75, stroke=0) +
theme_bw()
ggsave("/clickbait-cluster-master/fb-headlines-cluster-test-53D.png", plot, width=4, height=3, dpi=300)
p <- plot_ly(df_plot,
x = ~x,
y = ~y,
color=~page_id,
type = "scattergl",
mode = "markers",
marker = list(line = list(width = 0), opacity=0.75, size=3),
text=~link_name)
# createWidget(name="plotly",x=plotly_build(p), sizingPolicy=sizingPolicy(browser.padding = 0,
# browser.fill = F, defaultWidth = "100%", defaultHeight = 400)) %>%
# saveWidget("/clickbait-cluster-master/fb-headlines-cluster-test-53D.html", selfcontained=T, libdir="plotly")
htmlwidgets::saveWidget(as_widget(p), "/clickbait-cluster-master/fb-headlines-cluster-test-53D.html")
processText <- function(row) {
sprintf("%s<br>%s Reactions<br>%s",
row[3],
format(as.numeric(row[5]), big.mark=","),
format(as.Date(substr(row[4], 1, 10) ), format = "%B %d, %Y" ))
}
apply(df_plot[1,], 1, processText)
df_plot$text = apply(df_plot, 1, processText)
# https://plot.ly/r/axes/
ax <- list(
title = "",
zeroline = FALSE,
showline = FALSE,
showticklabels = FALSE,
showgrid = FALSE
)
m = list(
l = 0,
r = 0,
b = 0,
t = 25,
pad = 0
)
p <- plot_ly(df_plot,
x = ~x,
y = ~y,
color=~page_id,
type = "scattergl",
mode = "markers",
marker = list(line = list(width = 0), opacity=0.75, size=6),
text=~link_name,
hoverinfo="text+name") %>% layout(xaxis = ax, yaxis = ax, margin=m)
# createWidget(name="plotly",x=plotly_build(p), sizingPolicy=sizingPolicy(browser.padding = 0,
# browser.fill = F, defaultWidth = "100%", defaultHeight = 400)) %>%
# saveWidget("/clickbait-cluster-master/fb-headlines-cluster-standalone.html", selfcontained=T, libdir="plotly")
htmlwidgets::saveWidget(as_widget(p), "/clickbait-cluster-master/fb-headlines-cluster-test-53D.html")
font <- list(
family='Source Sans Pro, Arial, sans-serif'
)
p <- plot_ly(df_plot,
x = ~x,
y = ~y,
color=~page_id,
type = "scattergl",
mode = "markers",
marker = list(line = list(width = 0), opacity=0.75, size=6),
text=~link_name,
hoverinfo="text+name") %>% layout(xaxis = ax,
yaxis = ax,
margin=m,
font=font,
plot_bgcolor ='#f7f8fa',
paper_bgcolor='#f7f8fa')
# createWidget(name="plotly",x=plotly_build(p), sizingPolicy=sizingPolicy(browser.padding = 0,
# browser.fill = F, defaultWidth = "100%", defaultHeight = 400)) %>%
# saveWidget("/clickbait-cluster-master/fb-headlines-cluster-web.html", selfcontained=T, libdir="plotly")
htmlwidgets::saveWidget(as_widget(p), "/clickbait-cluster-master/fb-headlines-cluster-test-53D.html")
*参考元では、plotlyの出力データをcreateWidget、saveWidgetを使用してhtmlファイルに出力していますが、私の環境では、何も出力されず、解決できなかったためhtmlwidgetsを使用してhtmlファイルに出力しています。
可視化データをみてみる
上記で出力されたhtmlファイル「fb-headlines-cluster-test-53D.html」を開くと、plotlyによるデータ可視化が行われていると思います。