#はじめに
機械学習は多くの物に応用できます。
その中でも特によく機械学習が使われるのは株です。
株は無料でデータが手に入りかつビジネスチャンスにもなるので多くの企業や団体等が予測しています。
今回は初心者なりに株価予測をやってみたいと思います。
初心者なので間違いがあるかもしれません
追記、致命的な間違いがありました。
記事を公開する前に確認するべきでした
お詫び申し上げます。
一番下の追記をご覧ください。
ただ、この記事は失敗例としてある程度有益であると思われますので公開は続けます。
modelを考える
まず、全結合のニューラルネットを4層付けた、ネットワークを使います。
[t-75の株価,t-74の株価...t-1の株価]->model->tの株価
[t-74の株価,t-73の株価...tの株価]->model->t+1の株価
以下略
このように過去、計74日分の株価を与えてtの株価を予想します。
使うライブラリはkerasを使いたいと思います。
ソースコード
では早速、ソースコードを書きたいと思います。
import sys
from sklearn.svm import SVC
from sklearn import svm
import numpy as np
import copy
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.layers.recurrent import LSTM
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping
import os
from sklearn import preprocessing
args = sys.argv
n=75
def data_Get(fname):
data=[]
with open(fname,"r",encoding="utf-8") as f:
data=[e.replace("\n", "") for e in f.readlines()]
data=[float(e.split(",")[4]) for e in copy.deepcopy(data) ]
data2=[]
in_data,label_data=[],[]
for i in range(n,len(data)):
in_data.append([data[i2] for i2 in range(i-n,i)])
label_data.append(data[i])
print(in_data[0],label_data[0])
return in_data, label_data
def main():
in_data,label_data=[],[]
for e in args[1:]:
t1,t2=data_Get(e)
in_data+=t1
label_data+=t2
model = Sequential()
model.add(Dense(256, batch_input_shape=(None,n)))
model.add(Dense(256, batch_input_shape=(None,256)))
model.add(Dense(256, batch_input_shape=(None,256)))
model.add(Dense(1))
optimizer = Adam()
model.compile(loss="mse", optimizer=optimizer)
if os.path.exists("model.bin"):
model.load_weights("model.bin")
else:
pass
model.fit(np.array(in_data),np.array(label_data),epochs=100)
fname=input("test_file:")
in_test_data,label_test_data=data_Get(fname)
ptest_in2=model.predict(in_data)
plt.plot(range(n,len(ptest_in2)+n), [e for e in ptest_in2], label='AI')
plt.plot(range(n,len(ptest_in2)+n), [e for e in label_data], label='True')
plt.legend()
plt.show()
ptest_in=model.predict(in_test_data)
plt.plot(range(n,len(ptest_in)+n), [e for e in ptest_in], label='AI')
plt.plot(range(n,len(ptest_in)+n), [e for e in label_test_data], label='True')
plt.legend()
plt.show()
model.save("model.bin")
main()
やはり、kerasはシンプルに書けますね。
データを入手する
色々な場所で過去の株価データが置かれていますが、僕は
http://k-db.com/stocks/
このサイトの株価データをお借りしました。
深い意味はないのですがとりあえずソニーさんの株価データを使いたいと思います。
注意
株価データのフォーマットが上記のサイトに合わせてしまったので他のサイトを利用される場合はソースコードの書き換えが必要です。
学習させる
python main.py 株価データ1 株価データ2 ....
で学習できます。
もし、上手く行かない場合はepochsを増やしてみてください。
僕は2012〜2016年からの株価を学習させました。
学習結果を見てみる
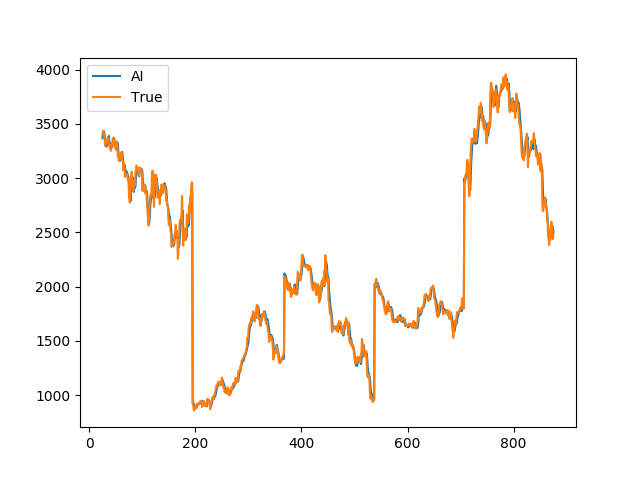
当たり前ですがすでに学習させているデータは上手く動きますね。
2012〜2016年の推移を予測させたグラフです。
未知のデータでやってみる
さて、学習させていない2017年のデータを使って予測したいと思います。
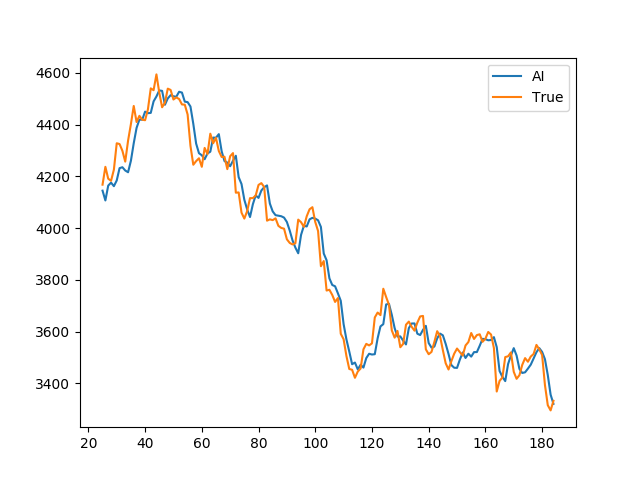
ちゃんと予想出来てますね。
終わりに
過去の株価データだけだと上手く予想できないかと思っていたのですが案外上手くいきました。
参考
下記の記事を参考にしました、ありがとうございます。
深層学習ライブラリKerasでRNNを使ってsin波予測
追記
この記事の公開後、Twitter等で多くの反応をいただきました。
その中でこのようなご指摘がありました。
前日の実際の結果をベースにしてるからそれに追従してるだけでは? → 機械学習で株価を予測する on @Qiita https://t.co/zt3mupxcku
— Tatsuya (@yt) 2018年2月23日
はい、まったくのご指摘通りです。
最初の75日分で1年間を予測するとこうなります。
import sys
from sklearn.svm import SVC
from sklearn import svm
import numpy as np
import copy
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.layers.recurrent import LSTM
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping
import os
from sklearn import preprocessing
args = sys.argv
n=75
def data_Get(fname):
data=[]
with open(fname,"r",encoding="utf-8") as f:
data=[e.replace("\n", "") for e in f.readlines()]
data=[float(e.split(",")[4]) for e in copy.deepcopy(data) ]
data2=[]
in_data,label_data=[],[]
for i in range(n,len(data)):
in_data.append([data[i2] for i2 in range(i-n,i)])
label_data.append(data[i])
print(in_data[0],label_data[0])
return in_data, label_data
def main():
in_data,label_data=[],[]
for e in args[1:]:
t1,t2=data_Get(e)
in_data+=t1
label_data+=t2
model = Sequential()
model.add(Dense(256, batch_input_shape=(None,n)))
model.add(Dense(256, batch_input_shape=(None,256)))
model.add(Dense(256, batch_input_shape=(None,256)))
model.add(Dense(1))
optimizer = Adam()
model.compile(loss="mse", optimizer=optimizer)
if os.path.exists("model.bin"):
model.load_weights("model.bin")
else:
pass
# model.fit(np.array(in_data),np.array(label_data),epochs=100)
fname=input("test_file:")
in_test_data,label_test_data=data_Get(fname)
ptest_in2=model.predict(in_data)
plt.plot(range(n,len(ptest_in2)+n), [e for e in ptest_in2], label='AI')
plt.plot(range(n,len(ptest_in2)+n), [e for e in label_data], label='True')
plt.legend()
plt.show()
ptest_in=model.predict(in_test_data)
plt.plot(range(n,len(ptest_in)+n), [e for e in ptest_in], label='AI')
plt.plot(range(n,len(ptest_in)+n), [e for e in label_test_data], label='True')
plt.legend()
plt.show()
model.save("model.bin")
def main2():
from keras.models import load_model
model = load_model('model.bin')
# model.save("model.bin")
fname=input("test_file:")
in_test_data,label_test_data=data_Get(fname)
A=[]
ptest_in=in_test_data[0]
for i in range(len(label_test_data)):
temp=model.predict(np.array([ptest_in]))[0][0]
ptest_in.append(temp)
A.append(temp)
ptest_in=ptest_in[1:]
print(A)
plt.plot(range(n,len(label_test_data)+n), [e for e in A], label='AI')
plt.plot(range(n,len(label_test_data)+n), [e for e in label_test_data], label='True')
plt.legend()
# plt.show()
plt.savefig("graph1.png")
plt.figure()
plt.plot(range(n,len(A)+n), [abs(e1-e2) for e1,e2 in zip(A,label_test_data)], label='loss')
plt.legend()
# plt.show()
plt.savefig("graph2.png")
#main()
main2()
その結果がこちらです。
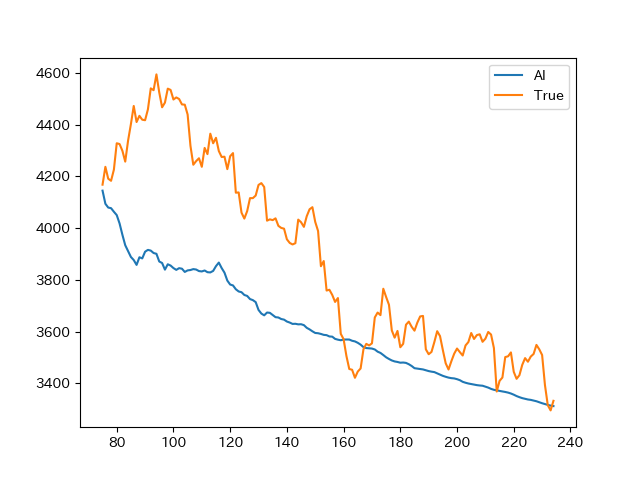
特に最初の所では実際は上昇ているにもかかわらず、AIは暴落を予想しています。
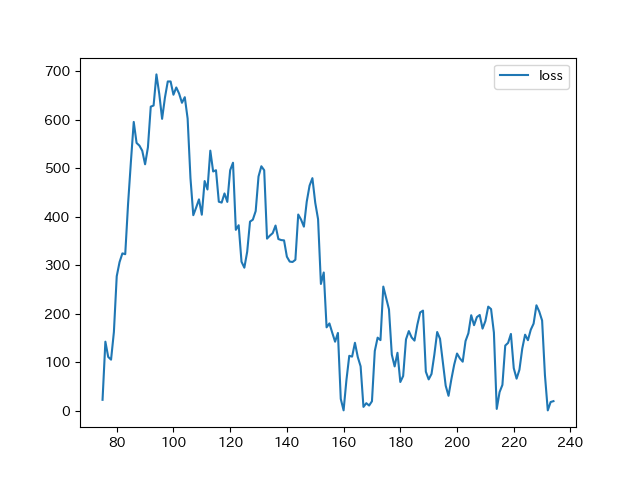
実際の値とAIが予想した値の差の絶対値が下記です。
考察
過去、75日分という長さを入れても上手く予測できませんでした。
そこで、3つの原因が考えられます。
- 75日分では情報量が足りなかった
- 全結合ではなくRNNを使うべきだった。
- 株価は情報は過去のデータだけでは予想出来ない
多分、一番最後が大きな原因かと思います。
株価は、当然ながら不祥事や赤字等が起きれば下がります。株価を決めるのは周りです。周りが買えば当然株価は上がります。
周りが株価を決めるのに周りの情報が一切入ってこないAIでは株価の正確な予想は難しいのではないでしょうか。