1.はじめに
「今日の占いカウントダウン」って知っていますか?
朝の7時とか8時とかに12星座占いをやってるアレです。
![]()
(きちんと載せないと削除申請されるかもしれないので、一応載せておきます。)
今回は毎日の今日の占いカウントダウンの1位を予想してみました!
2.できたもの
twitter(@mezaura_ai)で毎日予想しています。
良かったらリンクをクリックして、見ていってください。
※今後自動化予定
またgithubにコードを載せる予定です。
「で、予想確率なんぼなん?」という方は、9.予測へ飛んでください。
3.始めた理由
①機械学習独学で学んだけど、ほんとにできてるの?という疑問
チュートリアル問題やkaggleのビギナー向け記事を見て取り組んでいるものの、
ほぼパクりな感覚が自分の中で納得がいかず、何か自分で問題を設定して解決してみたかった。
(競馬予想も進めてはいますが、多くの人が取り組んでいる問題なので、新しい問題に触れてみたかったのもあります。)
②好奇心
占いを予想すること自体が面白そう。
占いは分析・予想とは対極にあたるイメージがあり、どうなるか楽しみだった。
③もしかしたらという勝算
占い=統計学?という疑問があり、もし星座占いが統計学的なアプローチをしていれば予想できるのではと考えていました。
占いに対する評価は大きく2つにわかれるのではないでしょうか。
占いは統計学と言う人もいますし、
インチキだから気にしなくてもいいと言う人もいます。
もし統計的な何か、または星の角度を使っているのであれば、
ランダムではなく、法則があるはず。
法則があれば、予想できるはず…!!!
4.今日の占いカウントダウンを選んだ理由
①多くの人が知っているから。
小さい時に学校に行く前によく見ていて、一喜一憂している家族が印象的でした。
②データがあった
データがなきゃ始まらないと思ってググったら、一発で見つかったのでラッキーでした。
意外と記録していらっしゃる方いるんですね。
何気ないことを書き残していたら(毎日の食事とか、体調とか)、将来データセットとして使われるかもしれません。(古文みたいですね笑)
5.使用ツール
Google Colaboratory
言わずと知れた無料のJupyterNotebook環境。
ほとんど設定不要・GPUも使えてとても便利です!

使い方はこちらの記事が詳しいです。
(pythonも触ったことない頃からお世話になりました!)
6.データ取得
データは
こういうサイトから情報を取得しました。

7.データを見てみる
特徴量を生成するにあたって一旦データを見てみました。
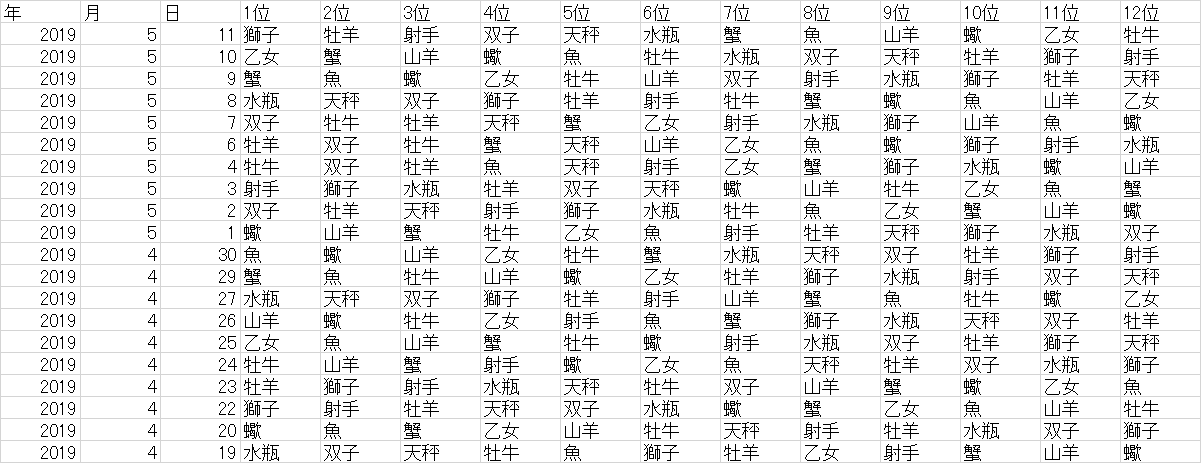
うーん、連続で1位になることは少なそう。(N=1559, 2013年6月11日~2019年5月11日)
ということは前日が1位の情報があってもいいかもしれない。
パッと見ではわからないので、いろいろと比較をすることにしました。
(書いていて後悔したのですが、相関を見るとか、あたりをある程度付けるとか、もっときっちりやるべきでした…)
各星座の1位数を比較してみる。
全く偏りがなければ
1559 \div 12 = 129.916...
と130程度になるはず。
# csvファイルをインポート
from google.colab import files
f=files.upload()
# DataFrameとして読みこみ
countdown = pd.read_csv("countdown.csv", encoding="shift-jis", engine = "python")
# 各星座の1位の数を確認
print(countdown['1位'].value_counts(ascending=True))
射手 121
山羊 122
魚 124
乙女 125
牡羊 125
水瓶 126
双子 130
蟹 133
獅子 134
牡牛 135
蠍 139
天秤 145
Name: 1位, dtype: int64
ちょっと偏りがありそう。とくに天秤座。
とはいえある程度は収束している。(明らかに偏ってたらフジテレビにクレーム飛びそう。)
各星座の当日の順位をもとに、取得したデータの全期間における各星座の順位の平均を比較してみる。
# 全期間における各星座の順位を平均する。
df_mean = pd.DataFrame(countdown.mean())
# 不要な情報をdropして削除
df_mean = df_mean.drop(["星座","月","日","項番"], axis=0)
# 平均順位の低い順(運の良い順)に並び替え
df_mean_sort = df_mean.sort_values(0)
# 列名を設定
df_mean_sort = df_mean_sort.rename(columns={0: '平均順位'})
df_mean_sort.head(12)
| 平均順位 | |
|---|---|
| 天秤座1日成績 | 6.040411 |
| 蠍座1日成績 | 6.182809 |
| 魚座1日成績 | 6.372675 |
| 射手座1日成績 | 6.427838 |
| 蟹座1日成績 | 6.512508 |
| 乙女座1日成績 | 6.513791 |
| 牡羊座1日成績 | 6.545863 |
| 牡牛座1日成績 | 6.550353 |
| 水瓶座1日成績 | 6.572803 |
| 獅子座1日成績 | 6.722899 |
| 山羊座1日成績 | 6.740218 |
| 双子座1日成績 | 6.817832 |
ある程度、運は収束していそうですね。
しかし、圧倒的な大差はないですが、差はありますね。
各星座の情報が特徴量としてあっても良さそうな感じがします。
さっき1位の数が多かった天秤座は若干値が小さく、全体的に運がいいのでしょうか。
あと、双子座…元気出せよ…もっとデータ量増やしたら確認するからさ。
とはいえ、目的である1位を的中させるために、思考停止で天秤座を選ぶだけだったり、双子座を除外するだけでは、うまくいかなさそうです。
では、ある区間で区切ったら、どうなるでしょうか。
例えば、自分の星座の時期のときは良い運勢or悪い運勢とかはありえそう。
各星座の時期ごとの各星座の1位数を確認する。
# 当日の星座ごとにgroupbyする。
grouped = countdown.groupby('星座')
# groupbyした結果の平均値を取る。
mean = grouped.mean()
mean.head()
| 何の星座の日 | 牡羊 | 牡牛 | 双子 | 蟹 | 獅子 | 乙女 | 天秤 | 蠍 | 射手 | 山羊 | 水瓶 | 魚 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 牡羊 | 6.70 | 6.26 | 6.96 | 6.43 | 7.05 | 6.23 | 6.17 | 6.03 | 6.53 | 6.95 | 6.74 | 5.97 |
| 牡牛 | 6.05 | 6.52 | 6.53 | 6.67 | 6.67 | 6.95 | 5.72 | 6.62 | 6.32 | 6.95 | 6.45 | 6.56 |
| 双子 | 6.88 | 6.33 | 6.92 | 6.47 | 6.72 | 6.17 | 6.33 | 6.04 | 6.63 | 6.63 | 6.64 | 6.23 |
| 蟹 | 6.77 | 6.89 | 6.71 | 6.28 | 6.67 | 6.43 | 6.09 | 5.90 | 6.46 | 6.89 | 6.61 | 6.29 |
| 獅子 | 6.10 | 6.90 | 6.91 | 6.33 | 6.22 | 6.53 | 6.07 | 6.64 | 6.33 | 6.73 | 6.61 | 6.63 |
| 乙女 | 6.81 | 6.41 | 6.97 | 6.81 | 6.43 | 6.27 | 5.84 | 6.10 | 6.49 | 6.67 | 6.60 | 6.60 |
| 天秤 | 6.65 | 6.23 | 6.92 | 6.38 | 6.98 | 6.50 | 5.89 | 6.06 | 6.78 | 6.74 | 6.74 | 6.11 |
| 蠍 | 6.50 | 6.51 | 6.70 | 6.34 | 6.78 | 6.55 | 5.91 | 5.94 | 6.43 | 7.04 | 6.67 | 6.64 |
| 射手 | 6.78 | 6.42 | 7.05 | 6.45 | 7.07 | 6.43 | 6.45 | 5.82 | 6.07 | 6.40 | 6.87 | 6.18 |
| 山羊 | 6.66 | 6.54 | 6.65 | 6.73 | 6.90 | 6.48 | 6.09 | 6.34 | 6.27 | 6.45 | 6.27 | 6.62 |
| 水瓶 | 6.38 | 6.98 | 6.39 | 6.87 | 6.48 | 6.80 | 5.85 | 6.56 | 6.17 | 6.79 | 6.04 | 6.68 |
| 魚 | 6.31 | 6.59 | 7.08 | 6.41 | 6.74 | 6.82 | 6.11 | 6.13 | 6.61 | 6.59 | 6.64 | 5.98 |
うーん、もしかしたら差があるかも?
最大値と最小値、それから最大値と最小値の差を比べてみました。
| 牡羊 | 牡牛 | 双子 | 蟹 | 獅子 | 乙女 | 天秤 | 蠍 | 射手 | 山羊 | 水瓶 | 魚 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 最大値 | 6.88 | 6.98 | 7.08 | 6.87 | 7.07 | 6.95 | 6.45 | 6.64 | 6.78 | 7.04 | 6.87 | 6.68 |
| 最小値 | 6.05 | 6.23 | 6.39 | 6.28 | 6.22 | 6.17 | 5.72 | 5.82 | 6.07 | 6.40 | 6.04 | 5.97 |
| 差 | 0.83 | 0.76 | 0.68 | 0.59 | 0.85 | 0.78 | 0.74 | 0.82 | 0.71 | 0.64 | 0.83 | 0.71 |
圧倒的な差はないものの、確かに運のいい日、悪い日が今日の星座に基づいてありそう。
グラフで表現すると、(縦軸:順位平均、横軸:当日の星座)
# 平均値をDataFrameへ保存
mean = pd.DataFrame(mean)
# 余分な情報をdropして削除
mean_graph = mean.drop(["年","月","日","項番"], axis=1)
# 当日の星座が数字で表示されているため、日本語へ変換
mean_graph = mean_graph.rename(index={1: "牡羊", 2: "牡牛", 3: "双子", 4: "蟹", 5: "獅子", 6: "乙女", 7: "天秤", 8: "蠍", 9: "射手", 10: "山羊", 11: "水瓶", 12: "魚", })
mean_graph.plot(figsize=(16, 9),subplots=True, layout=(4, 3))

ちなみにGoogle Colaboratoryでグラフ表示するときは、以下のコマンドが必要です。(2019/06/01時点)
※仕様の変更により最新の対応方法が必要になります。
これをしないと日本語が全て□(豆腐と言います)で表現されてしまいます。
@siraasagiさんがこちらで解説してくださっています。(大変お世話になりました!)
# グラフ表示のために必要
!rm /root/.cache/matplotlib/fontlist-v300.json
!apt-get -y install fonts-ipafont-gothic
# 実行後ランタイムを再起動すること。
# ランタイム再起動後、以下の実行
from matplotlib import pyplot as plt
import seaborn as sns
sns.set(font='IPAGothic')
では、1位の数はどうでしょうか。
# 必要なデータを残す。
countdown_1_con = countdown[['星座','1位']]
# 1位の星座をonehot化する
countdown_1_con = pd.get_dummies(countdown_1_con, drop_first=False, columns=['1位'], prefix='1位', prefix_sep='_')
# 当日の星座でgroupbyする
countdown_1_con_grouped = countdown_1_con.groupby('星座')
# sumすることで、各星座が当日の星座ごとに1位になった回数を算出
sum = countdown_1_con_grouped.sum()
sum_graph = sum.rename(index={1: "牡羊", 2: "牡牛", 3: "双子", 4: "蟹", 5: "獅子", 6: "乙女", 7: "天秤", 8: "蠍", 9: "射手", 10: "山羊", 11: "水瓶", 12: "魚", })
sum_graph.head(12)
# それぞれのデータをグラフ表示
# sum_graph.plot(figsize=(16, 9),subplots=True, layout=(4, 3))
| 何の星座の日 | 1位_牡羊 | 1位_牡牛 | 1位_双子 | 1位_蟹 | 1位_獅子 | 1位_乙女 | 1位_天秤 | 1位_蠍 | 1位_射手 | 1位_山羊 | 1位_水瓶 | 1位_魚 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 牡羊 | 9 | 12 | 7 | 12 | 11 | 14 | 12 | 12 | 11 | 9 | 13 | 11 |
| 牡牛 | 12 | 13 | 13 | 12 | 10 | 6 | 14 | 11 | 9 | 12 | 12 | 6 |
| 双子 | 10 | 12 | 9 | 11 | 12 | 12 | 10 | 12 | 7 | 7 | 9 | 12 |
| 蟹 | 10 | 11 | 15 | 9 | 10 | 11 | 14 | 12 | 11 | 9 | 8 | 13 |
| 獅子 | 13 | 7 | 13 | 14 | 14 | 11 | 11 | 9 | 12 | 13 | 8 | 10 |
| 乙女 | 13 | 14 | 7 | 11 | 12 | 11 | 14 | 12 | 8 | 11 | 13 | 8 |
| 天秤 | 9 | 12 | 12 | 11 | 10 | 10 | 11 | 13 | 11 | 13 | 10 | 11 |
| 蠍 | 10 | 13 | 12 | 15 | 14 | 11 | 13 | 10 | 7 | 7 | 10 | 7 |
| 射手 | 10 | 9 | 9 | 12 | 10 | 11 | 12 | 11 | 9 | 10 | 8 | 13 |
| 山羊 | 6 | 12 | 12 | 9 | 10 | 7 | 11 | 12 | 12 | 13 | 12 | 8 |
| 水瓶 | 10 | 10 | 12 | 8 | 11 | 12 | 13 | 10 | 11 | 7 | 12 | 12 |
| 魚 | 13 | 10 | 9 | 9 | 10 | 9 | 10 | 15 | 13 | 11 | 11 | 13 |
当日の星座によって有利不利がありそうに見えます。
最大値、最小値、その差も見てみましょう。
| 1位_牡羊 | 1位_牡牛 | 1位_双子 | 1位_蟹 | 1位_獅子 | 1位_乙女 | 1位_天秤 | 1位_蠍 | 1位_射手 | 1位_山羊 | 1位_水瓶 | 1位_魚 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 最大値 | 13 | 14 | 15 | 15 | 14 | 14 | 14 | 15 | 13 | 13 | 13 | 13 |
| 最小値 | 6 | 7 | 7 | 8 | 10 | 6 | 10 | 9 | 7 | 7 | 8 | 6 |
| 差 | 7 | 7 | 8 | 7 | 4 | 8 | 4 | 6 | 6 | 6 | 5 | 7 |
値が小さいので何とも言えませんが、当日の星座によって調子の良し悪しがありそうですね。

グラフで見てみても、調子の良し悪しが見て取れます。
当日の星座ごとに差が出ているのであれば、当日の星座情報は特徴量に使えそうですね。
他にもいろいろありそうですし、調べて動いた方が得策ではあったのですが、我慢ができず特徴量を作り始めてしまいました。
8.特徴量生成
とりあえず、バイオリズムがありそうなので、3日間の1位数、3日間の順位合計などを作成。
| 特徴量名 | 説明 |
|---|---|
| 年 | 占いの実施年 |
| 月 | 占いの実施月 |
| 日 | 占いの実施日 |
| 各星座3日1位数 | 各星座の占い実施年月日の前日から3日分の1位数 |
| 各星座7日1位数 | 各星座の占い実施年月日の前日から7日分の1位数 |
| 各星座30日1位数 | 各星座の占い実施年月日の前日から30日分の1位数 |
| 各星座365日1位数 | 各星座の占い実施年月日の前日から365日分の1位数 |
| 各星座3日成績 | 各星座の占い実施年月日の前日から3日分の順位の和 |
| 各星座7日成績 | 各星座の占い実施年月日の前日から7日分の順位の和 |
| 各星座30日成績 | 各星座の占い実施年月日の前日から30日分の順位の和 |
| 各星座1日成績 | 各星座の占い実施年月日の前日の順位 |
| 各星座_絶対値_前日-前々日 | 各星座の前日から前々日の順位の引き算の絶対値 |
| 各星座_+-_前日-前々日 | 各星座の前日から前々日の順位の引き算のプラスかマイナス |
| 各星座_3日_EMA | 各星座の占い実施年月日の前日から3日分のEMA |
| 各星座_7日_EMA | 各星座の占い実施年月日の前日から7日分のEMA |
| 各星座_30日_EMA | 各星座の占い実施年月日の前日から30日分のEMA |
| 星座 | 占い実施日の太陽星座 |
| 当日の回答 | 占い実施日の当日の1位 |
※当日の回答は教師用データで予測時は削除
※EMAとは
(EMAを特徴量として入れたのはトレーダーの方が指標として用いているのを聞いたので。他の指標もあるのですが、一旦入れてみました。期間における平均的な値は出しながら、直近のデータにより比重を置くことでトレンドを見分けることができるとのこと。)
9.予測
有名なモデルたちをいろいろ試してみました。
(モデル選定についても思考停止せず、どういう目的で出力したくて、データにどういう性質があるから、このモデルを選ぶとすべきだった。)
精度の目標
少なくともランダムに星座を選択するよりは高い確率で的中したいので
1 \div 12 \times 100= 8.333...
8.333%は超えたい
AIってすごいって思われたいので、人の3倍ぐらいはできてほしい(適当)
この辺の目標ってどう決めるんですかね。ご存知でしたら教えていただけると嬉しいです。
調べたら書き足します。
なので、目標は
1 \div 12 \times 100 \times 3= 24.999...
24.999%とします。
早速、モデル適用!…の前に、軽く処理を
# 万が一順序性が影響を与えていると正確にデータが取れないので、順序の入れ替えを行う。
data = countdown.sample(frac=1, random_state=0)
# 項番を残しつつ、インデックスの振り直しをする。
data = data.reset_index()
X = data.drop(["当日の回答"], axis=1)
Y = data[["当日の回答"]]
まずは、randomforest
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import accuracy_score
stack_xs_test = pd.DataFrame()
stack_y_pred = []
stack_data = pd.DataFrame()
stack_stack_data = pd.DataFrame()
# 3分割交差を指定し、インスタンス化
skf = StratifiedKFold(n_splits=3)
# skf.split(X_train.Ytrain)で、X_trainとY_trainを3分割し、交差検証をする
for train_index, test_index in skf.split(X, Y):
xs_train = X.iloc[train_index]
xs_test = X.iloc[test_index]
y_train = Y.iloc[train_index]
y_test = Y.iloc[test_index]
forest = RandomForestClassifier(random_state=1)
forest.fit(xs_train, y_train)
y_pred = forest.predict(xs_test)
# acuuracyを表示
print("予想結果")
print(round(accuracy_score(y_test,forest.predict(xs_test))*100,2))
予想結果
13.98
予想結果
14.15
予想結果
12.45
無調整だとこんなもんかと思いつつも、やっぱり低い…
これは題材ミスったか…と焦りました。
いつもお世話になっているlightgbmなら何とかしてくれるはず…!
# いろいろimport
from sklearn.model_selection import StratifiedKFold
import numpy as np
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# LightGBM parameters
# num_classが13になっているのは、0~12まで分類しているため。(本当は変換しても良かったんですが、当時めんどくさかった。ちなみにのちにnum_leaves = 12で検証したところ、精度はほぼ変わらず。正解に含まれていない数字であるため、無視されたかと。)
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'multiclass',
'metric': {'multi_logloss'},
'num_class': 13,
'learning_rate': 0.01,
'num_leaves': 13,
'min_data_in_leaf': 5,
'num_iteration': 1000,
'verbose': 0
}
# 3分割交差検証
skf = StratifiedKFold(n_splits=3, shuffle=False)
for train_index, test_index in skf.split(X, Y):
xs_train = X.iloc[train_index]
y_train = Y.iloc[train_index]
xs_test = X.iloc[test_index]
y_test = Y.iloc[test_index]
xs_train_index = xs_train[["index"]]
xs_train = xs_train.drop(["index"], axis=1)
lgb_train = lgb.Dataset(xs_train, y_train)
xs_test_index = xs_test[["index"]]
xs_test = xs_test.drop(["index"], axis=1)
lgb_eval = lgb.Dataset(xs_test, y_test, reference=lgb_train)
gbm = lgb.train(params, lgb_train, num_boost_round=50, valid_sets=lgb_eval,early_stopping_rounds=20)
y_pred = gbm.predict(xs_test, num_iteration=gbm.best_iteration)
y_pred = np.argmax(y_pred, axis=1)
print("Accuracy")
print(accuracy_score(y_test, y_pred))
結果はというと
Accuracy
0.22330097087378642
Accuracy
0.2554027504911591
Accuracy
0.21936758893280633
さすがLightgbmですね!
とはいえ平均すると23.269...%と目標の24.999...%には届かず。
ニューラルネットならどうなるのかと気になってしまったので、試してみた。
(自分のパラメータチューニング不足ですぐ過学習してしまい、実用に耐えませんでした。)
# いろいろimport
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras.utils.np_utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import Adam
from keras.layers.normalization import BatchNormalization
import numpy as np
import keras
from keras import regularizers
from sklearn import preprocessing
import matplotlib.pyplot as plt
model = preprocessing.StandardScaler()
X = model.fit_transform(X_train)
X_test = model.fit_transform(X_test)
# X = np.array(X_train)
# Yは0と1からなるリスト
Y = to_categorical(Y_train)
# モデル
model = Sequential()
# 全結合層(162を1620に)
model.add(Dense(input_dim=162, output_dim=1620))
# 活性化関数(ReLu関数)
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(Dense(input_dim=1620, output_dim=1620))
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(Dropout(0.4))
model.add(Dense(input_dim=1620, output_dim=1620))
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(Dropout(0.4))
model.add(Dense(input_dim=1620, output_dim=1620))
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(Dropout(0.4))
model.add(Dense(input_dim=1620, output_dim=1620))
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(Dropout(0.4))
# model.add(Activation('sigmoid'))
model.add(Dropout(0.2))
# 全結合層(1620を13に)
model.add(Dense(output_dim=13))
model.add(Dense(10, input_dim=13,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l2(0.01)))
model.add(Dense(output_dim=13))
# model.add(Dropout(0.3))
# 活性化関数(ReLu関数)
model.add(BatchNormalization())
model.add(Activation("relu"))
# softmax関数
model.add(Activation("softmax"))
# コンパイル
optimizer = Adam(lr=0.0001, beta_1=0.5, beta_2=0.5, epsilon=None, decay=0.0, amsgrad=False)
model.compile(loss="categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"])
# 実行
model.fit(X, Y, nb_epoch=300, batch_size=10,validation_split=0.2)
# 予測
results = model.predict_proba(np.array(X_test))
# 結果
print("Predict:\n", results)
20.82%
lightgbmが1番いい精度でしたね。
(まだまだチューニングできたかもしれませんが)
約23%だとまだ精度を上げたいところ。
10.精度の向上
さて、精度は約23%とランダムよりましになりました。
とはいえまだまだできることはあるはず。
こういったアプローチを取ると良いともありましたので、試してみます。
①データを増やす
(Traningにはフィットしているものの、Validationにはフィットしておらず、High varianceなので)
②それらしい特徴量を探す
(占いに関するドメイン知識をほとんど使っていないので)
③いらない特徴量を削る
(雑に生成した特徴量なので)
①データを増やす。
N = 1559 → N = 2782
3分割交差検証で実施。
平均:30.945%
うん、明らかに上がりましたね。データ量が不足していたことが明らかになりました。
そして目標(24.999...%以上)はとりあえず達成です!
②それらしい特徴量を探す。
今日の占いカウントダウンがどう占われているのか知りたかったので、検索してみました。
「星座占い 仕組み」
「今日の占いカウントダウン やり方」
「星座占い なぜ」など
調べてみると占い好きな人ってほんと好きなんですね。
わかりやすかったのはこのサイト
(このサイト)[https://lifewiththemoon.com/astrology-zodiacsign-todaysfortune/]
どうやら月星座が関わっているようです。
※月星座とは、以下の通りです。
普段占いでよく出る星座(3月21日~4月19日はおひつじ座など)は太陽星座と呼ばれます。
太陽星座は誕生した時の太陽の位置と星座の位置の関係で決まります。
一方月星座は、月と星座の位置関係で決まります。
参考
また4属性も関わっているという人もいます。(参考)[http://uranai-qa.com/qa/qa394558841.html]
※4属性とは
星座には4つの属性(火、水、地、風)があり、各属性に3星座割り当てられています。
属性によって似た運を持つそうです。
4属性に分類して同様の特徴量を生成
| 特徴量名 | 説明 |
|---|---|
| 各属性3日1位数 | 各属性の占い実施年月日の前日から3日分の1位数 |
| 各属性7日1位数 | 各属性の占い実施年月日の前日から7日分の1位数 |
| 各属性30日1位数 | 各属性の占い実施年月日の前日から30日分の1位数 |
| 各属性365日1位数 | 各属性の占い実施年月日の前日から365日分の1位数 |
| 各属性3日成績 | 各属性の占い実施年月日の前日から3日分の順位の和 |
| 各属性7日成績 | 各属性の占い実施年月日の前日から7日分の順位の和 |
| 各属性30日成績 | 各属性の占い実施年月日の前日から30日分の順位の和 |
| 各属性1日成績 | 各属性の占い実施年月日の前日の順位 |
| 各属性_絶対値_前日-前々日 | 各属性の前日から前々日の順位の引き算の絶対値 |
| 各属性_+-_前日-前々日 | 各属性の前日から前々日の順位の引き算のプラスかマイナス |
| 各属性_3日_EMA | 各属性の占い実施年月日の前日から3日分のEMA |
| 各属性_7日_EMA | 各属性の占い実施年月日の前日から7日分のEMA |
| 各属性_30日_EMA | 各属性の占い実施年月日の前日から30日分のEMA |
平均:32.323%
データをもとに分析してから、特徴量として選定すべきでしたが、結果オーライ。
特徴量の生成も楽だったし、ラッキーですね。
月星座を取得して、特徴量を生成
月星座の情報を取得し、
このサイトで取得し、エディタとエクセル機能でまとめました。
直接的に1位に結びついているのか確認をしたところ、32.815%の確率で月星座と同じ星座が1位になる模様。
ということは、相当良い特徴量になるのでは?
追加したのは、以下の特徴量です。
| 特徴量名 | 説明 |
|---|---|
| 月の星座 | 当日の月の星座 |
期待の結果はというと
平均:35.392%
意外とイマイチ…とはいえ3%も向上しているから喜ぶべきか。
月星座+4属性を組み合わせて特徴量を作成
月星座と同じ属性の星座も運が良くなりやすいとのことなので、
直接的に1位に結びついているのか確認をしたところ、32.815%の確率で月星座と同じ星座が1位になる模様。
ということは、相当良い特徴量になるのでは?
| 特徴量名 | 説明 |
|---|---|
| 月星座同属性1 | 当日の月の星座で同じ属性の星座その1 |
| 月星座同属性2 | 当日の月の星座で同じ属性の星座その2 |
平均:36.463%
③いらない特徴量を削ってみる
特徴量の重要度を以下のコードで測る。
from matplotlib import pyplot as plt
import seaborn as sns
sns.set(font='IPAGothic')
lgb.plot_importance(gbm, title = 'タイトル', figsize=(12, 60))
plt.show()

重要度に大きな差が…!
というか月星座だけでいいのでは?
各星座に同種の特徴量を設けているため、各星座全てにおいて低い値となっているものを取り除いてみます。
対象は以下の通りです。
| 特徴量名 | 説明 |
|---|---|
| 各属性/星座3日1位数 | 各属性/星座の占い実施年月日の前日から3日分の1位数 |
| 各属性/星座7日1位数 | 各属性/星座の占い実施年月日の前日から7日分の1位数 |
| 各属性/星座30日1位数 | 各属性/星座の占い実施年月日の前日から30日分の1位数 |
| 各属性/星座365日1位数 | 各属性/星座の占い実施年月日の前日から365日分の1位数 |
※この辺は適当でした。
予想してみると
平均:34.427%
下がってしまいました!
ということは、削らなくて良い特徴量も削ってしまっているということですね。
もう少し慎重に実施する必要がありました。
検証が必要ですので、元に戻しました。
11.結論
36.463%まで予想できました!
ランダムなら8.333%なので、4倍以上の的中率です!
かなりいい線いっているのではないでしょうか。
ちなみにtwitterでは、3星座を1位に予想しています。
内訳は、AIが予想した1位になる確率が高い星座を3つ並べています。
実績としては
AIがレコメンドした星座
2位までだと56.786%
3位までだと69.071%
という実績となっております。
なのでtwitterの3択はそこそこ当たるはず!
12.今後
今後は、以下に取り組んでいきます。
精度のさらなる向上
もう少し特徴量を選別できれば、精度は上がりそう。
占いに関する特徴量(他の星の位置など)を入れるなどの工夫は可能かもしれない。
モデルだって手順を踏んで選び直してみたり、パラメータを工夫してみればより良い結果が出るかもしれない。
自動化
数分とはいえ、手でやるのはだるいので、自動化したい。
主におこなうのは以下3点
①毎日の情報取得
②毎日の予測
③twitter連携
最後に
ここまで読んでいただきありがとうございました!
書いていく中で、自分のやり方の粗さに少しでも気づけたと思うので、次からはより良い取り組み方をしていきます!
また、こういうやり方もあるよ、こんな取り組みをしたらどうかなどありましたらお願い致します。