はじめに
この記事では、ALBとEC2 Auto Scalingを組み合わせ、CPU負荷の増減に応じてEC2インスタンスが自動的にスケールする挙動を検証するハンズオンを実施します。
検証の目的
今回は、Auto Scalingの挙動を純粋に理解するため、EC2インスタンスのCPU負荷の増減に応じてインスタンスが自動的にスケールする仕組みを検証します。そのため、ALBをAuto Scalingグループと関連付けて構成しますが、トラフィック分散には使用せず、ASG構成上の一要素として作成するに留めます。 実際の負荷はEC2に直接かけてスケーリング動作を確認します。
この構成のメリット
-
自動スケーリングによる柔軟なリソース管理とコスト効率
Auto ScalingがCPU使用率などのメトリクスに基づいてEC2インスタンス数を自動的に増減させるため、急なトラフィック増加にも即座に対応し、ユーザーエクスペリエンスを維持できます。また、負荷が低い時間帯にはインスタンス数を減らして不要なリソースの利用を抑えることで、コストを大幅に削減できます。これにより、必要な時に必要な分だけリソースを利用する、クラウドの従量課金モデルのメリットを最大限に活かせます。 -
高可用性・耐障害性の実現
ALBは、複数の健全なEC2インスタンスにトラフィックを均等に分散させ、特定のインスタンスに負荷が集中するのを防ぎます。万が一、インスタンスに障害が発生した場合でも、ALBはそのインスタンスへのトラフィックを自動的に停止し、Auto Scalingが新しいインスタンスを起動して置き換えるため、サービスが中断することなく継続できます。 -
運用負荷の軽減
インスタンスの追加・削除やヘルスチェックが自動で行われるため、手動でのインスタンス管理が不要になります。これにより、運用担当者の負担が大幅に軽減されます。
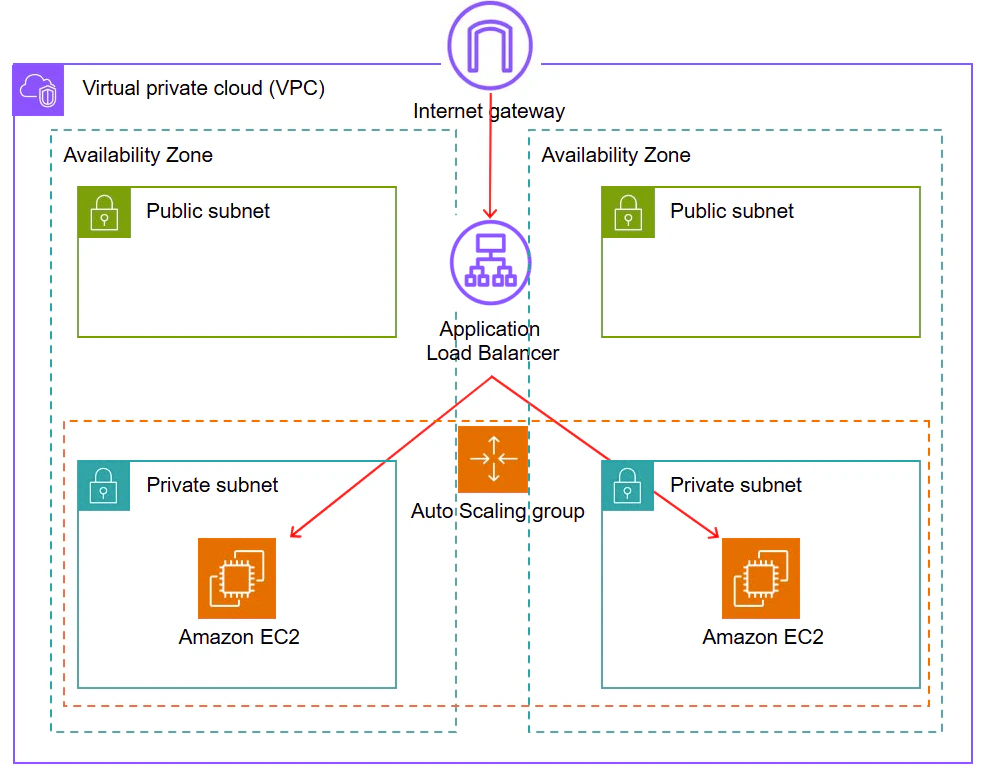
アーキテクチャ図
【ALB+EC2 Auto Scalingによるアーキテクチャ】
AWS Auto Scalingの基本用語と概念
AWS Auto Scalingとは???
アプリケーションのトラフィックやCPU使用率の増減に応じて、EC2インスタンスなどのリソースを自動的に増減させるサービスです。これにより、ピーク時にはパフォーマンスを維持し、アイドル時にはコストを削減することが可能になります。
AWS Auto Scalingの対象リソース
| サービス | スケーリング対象 | 補足 |
|---|---|---|
| Amazon EC2 | インスタンス数 | Auto Scaling Group を利用して EC2 の台数を調整 |
| EC2 Spot Fleet | スポットインスタンス数 | スポット価格や需要に応じて自動調整 |
| Amazon ECS | サービスのタスク数(コンテナ数) | クラスター内でタスク数を増減 |
| Amazon DynamoDB | 読み取り/書き込みキャパシティ(RCU/WCU) | テーブルとグローバルセカンダリインデックスが対象 ※オンデマンドモードでは自動スケーリング不要 |
| Amazon Aurora Serverless | キャパシティユニット(ACU) | Aurora Serverless v1/v2 が対象 通常の Aurora レプリカ数は対象外(手動調整) |
※今回はAmazon EC2のAuto Scalingについての挙動確認になります。
Auto Scalingスケーリングポリシーとは???
Auto ScalingがCPU使用率などの特定のメトリクスに基づき、リソースを自動的に増減させるためのルールを定義したもの。
【EC2のAuto Scalingスケーリングポリシーの種類】
-
動的スケーリング
-
ターゲット追跡スケーリング
指定したメトリクス値を維持するように自動調整
例:CPU使用率を50%に保つようにインスタンス数を増減 -
ステップスケーリング
CloudWatch アラームのしきい値に応じて段階的にスケール
例:「CPU > 60% → +1台」「CPU > 80% → +2台」 -
シンプルスケーリング
単一の CloudWatch アラームをトリガーに固定のアクションを実行
例:「CPU > 70% → +1台」
※ステップとシンプルはAutoScalingグループ作成後に設定可能
-
ターゲット追跡スケーリング
-
静的(手動)スケーリング
希望するインスタンス数を手動で指定
例:「常に2台稼働させておく」 -
スケジュールスケーリング
日時を指定してキャパシティを変更
例:「平日9時に4台へ増やし、18時に2台へ戻す」 -
予測スケーリング
過去のメトリクスデータを元に、将来の負荷を機械学習的に予測して先回りしてスケーリング
例:「毎日昼12時にアクセス増 → 11:50に自動でインスタンスを追加」
ウォームアップ期間とは???
Auto Scalingのスケールアウトによって新しく起動したインスタンスが、起動時の初期化プロセスによる一時的な高いCPU使用率をグループ全体の平均メトリクスから除外し、過剰なスケールアウトを防ぐための期間。
- InService状態(ALBのヘルスチェックOK、トラフィック処理できる状態)になってから開始される。
- ウォームアップ中のインスタンスが安定稼働するまでスケールイン(インスタンス削減)は抑制される
- スケールアウト時、複数のアラームが重なっても、ウォームアップ中のキャパシティを考慮して、過度なスケールアウトにはならないように設計されている。
起動テンプレートとは???
EC2インスタンスを起動するための設計図。これにより、AMIやインスタンスタイプ、セキュリティグループなどの設定を事前に定義しておき、Auto Scalingなどで一貫性のあるインスタンスを簡単にデプロイできるようになる。
【作成方法】
- `パラメータを指定して作成する場合
「起動テンプレートを作成」画面にて、AMI、インスタンスタイプ、キーペア、セキュリティグループ、ユーザーデータなどを設定して作成。 -
インスタンスから作成する場合
「インスタンス」画面にて、対象のインスタンスを選択し、アクション ⇒ イメージとテンプレート ⇒ インスタンスからテンプレートを作成 の順に選択して作成。 -
既存の起動テンプレートから作成する場合
「起動テンプレートを作成」画面のソーステンプレート項目にて、既存の起動テンプレートを指定することで、既存の起動テンプレートをベースに新たなテンプレートを作成できる。
検証の前提条件と準備
前提条件
-
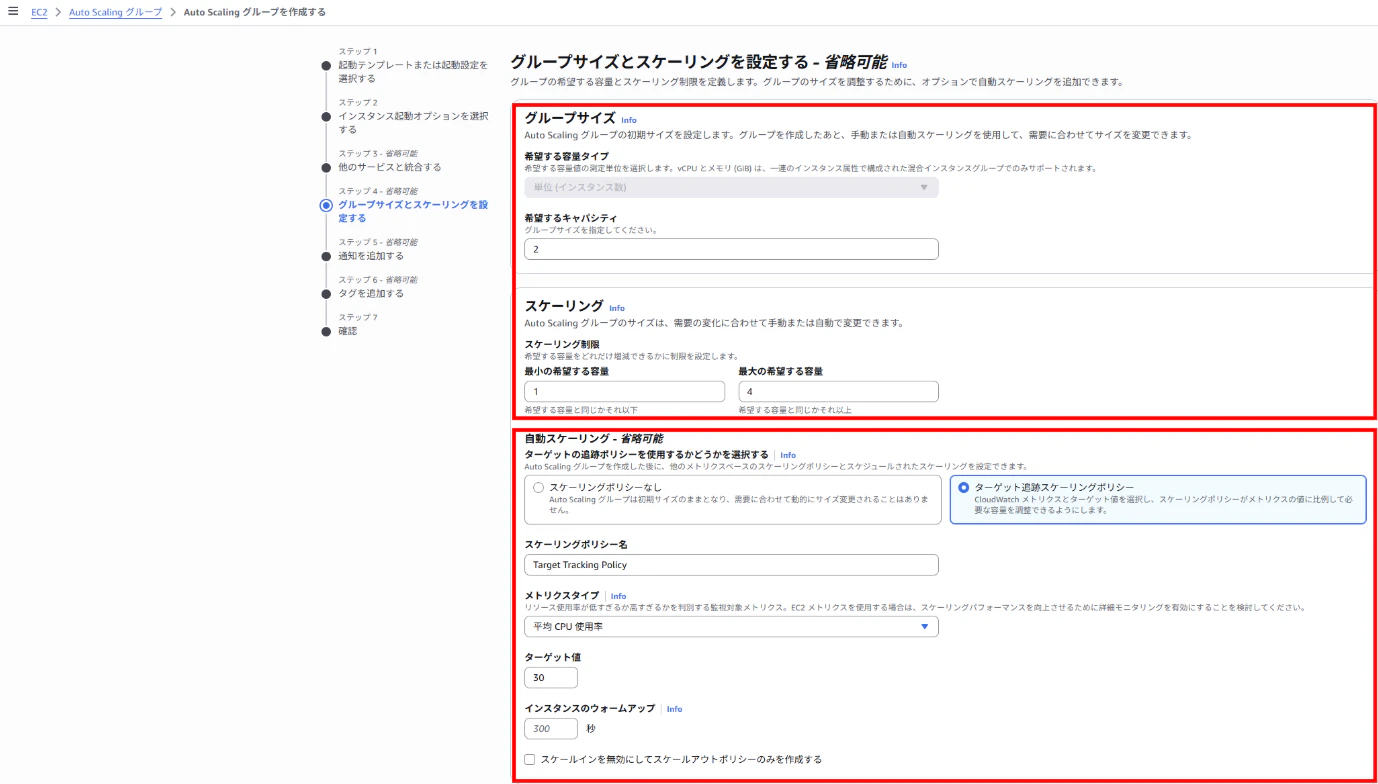
スケーリングポリシーの選択
ターゲット追跡スケーリングポリシー-
メトリクスタイプ
平均CPU使用率 -
ターゲット値
30%
-
メトリクスタイプ
-
キャパシティ設定
-
希望する容量:
2 -
最小容量:
1 -
最大容量:
4
【Auto Scaling グループ作成画面】
-
希望する容量:
-
CPU使用率を上げる方法
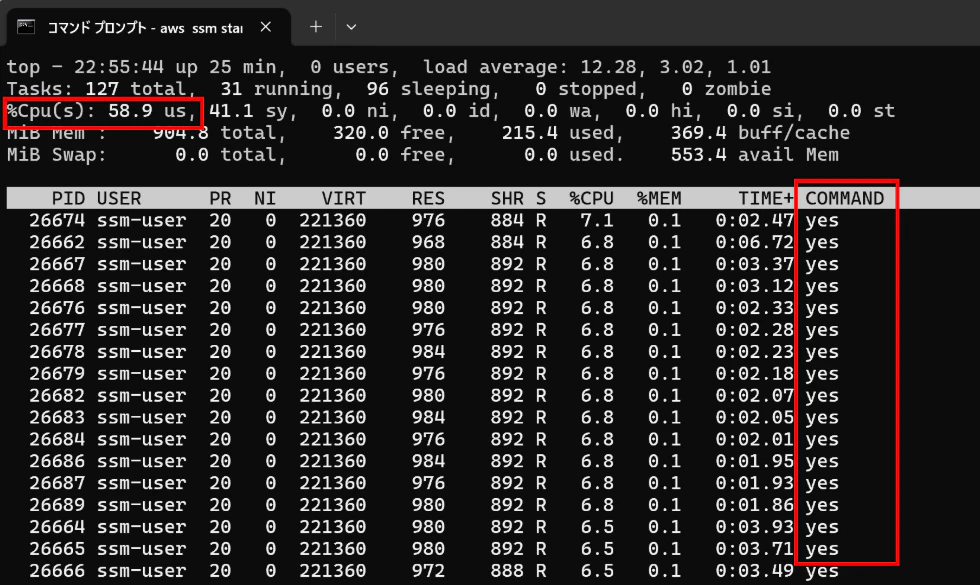
ALB経由のトラフィックによって負荷をかけるのではなく、EC2インスタンスへ接続して以下のyesコマンドを複数回実行することでEC2インスタンスのCPU使用率を増加させる。
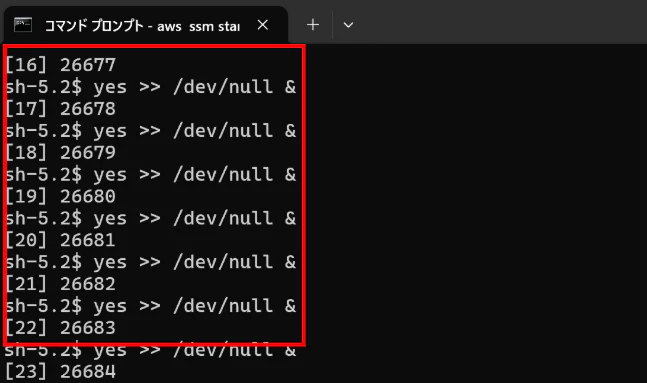
yes >> /dev/null &
検証に必要なリソースの準備
起動テンプレートの準備
AMI、インスタンスタイプ(t2.microなど)、IAMロール(SSM接続用)、ユーザーデータ(Apacheインストール用など)を設定したテンプレートを作成します。
Auto Scaling Group (ASG) の作成
上記で作成した起動テンプレートを使用し、VPC、サブネット、ALB、スケーリングポリシー、グループサイズを設定したASGを作成します。
CloudWatchアラーム
ASGにてターゲット追跡スケーリングポリシーを設定すると、AWS Auto Scalingは、設定された目標値を維持するために、以下の2つのCloudWatchアラームを自動的に作成します。
-
スケールアウト用のアラーム
メトリクス(例:CPU使用率)が目標値を超えた場合にトリガーされます。 -
スケールイン用のアラーム
メトリクスが目標値を下回った場合にトリガーされます。
これらのアラームが発報することで、Auto Scalingグループはインスタンスの追加や削除を自動で実行します。
今回のハンズオンで作成されたアラームは以下になります。
★AlarmHigh(スケールアウト):3分間の平均CPU使用率が30%を超過
★AlarmLow(スケールイン):15分間の平均CPU使用率が22.5%未満
⇒スケールイン時の22.5%とは、AWS側のデフォルト調整によるもので、設定値(30%)よりもやや低めに設定されています。
検証手順の詳細
①初期状態の確認
-
ASG作成直後
インスタンス数が希望する容量である2台になっていることを確認
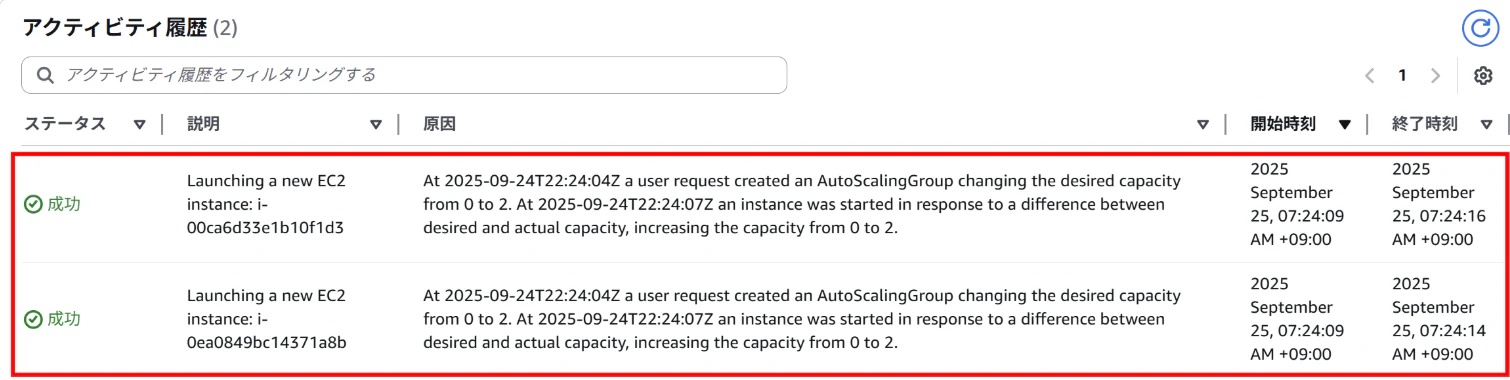
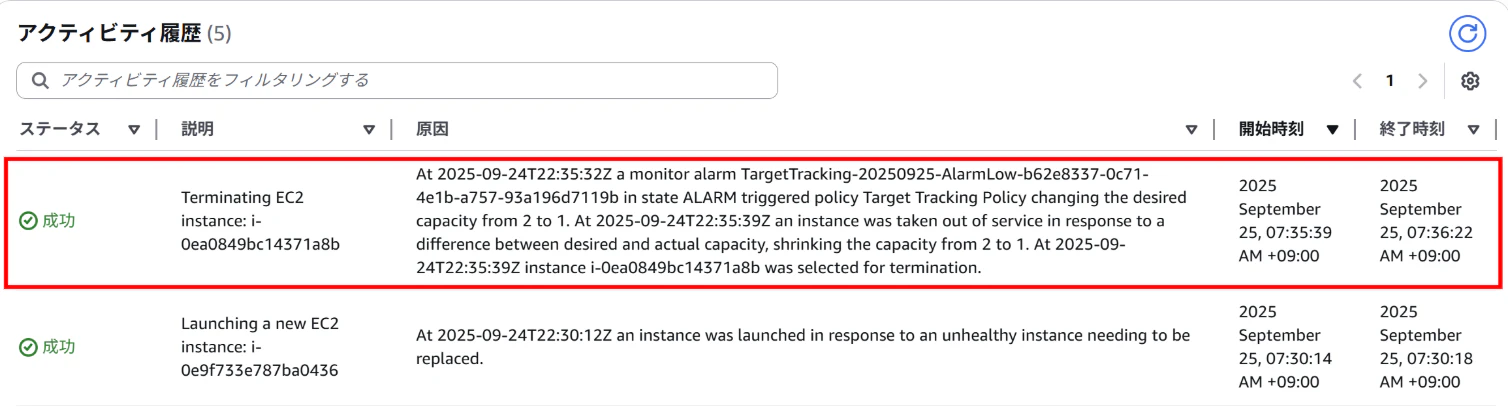
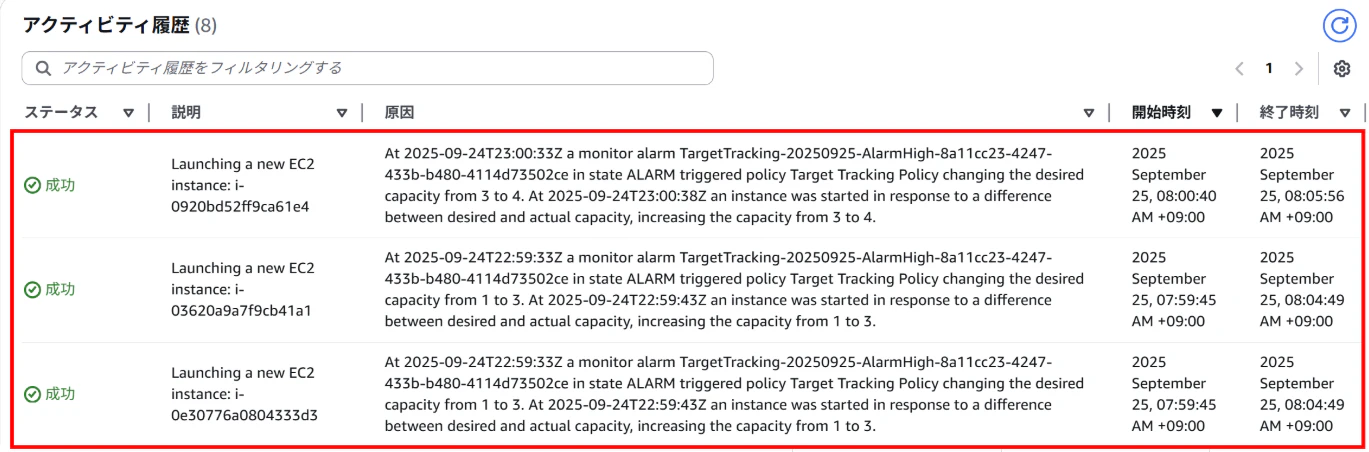
【AutoScalingグループのアクティビティ履歴画面】
⇒希望する2台のインスタンスが作成されている
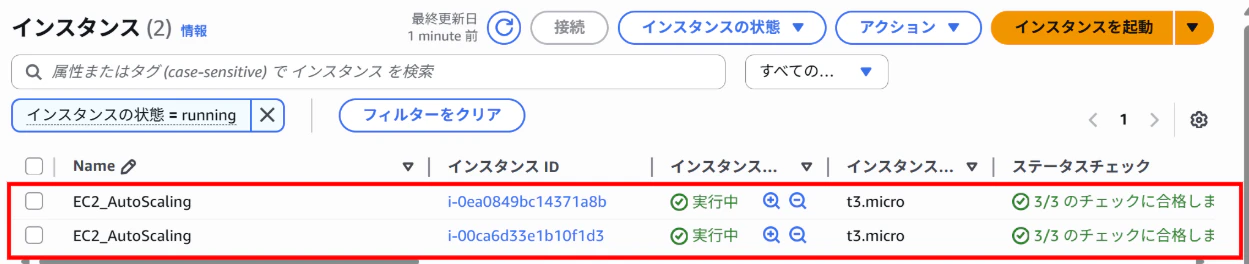
【EC2インスタンス画面】
⇒希望する2台のインスタンスが作成されている
-
インスタンスを手動で1台に減らす
ASGが自動で2台に戻す挙動を確認
⇒1台手動でインスタンスを終了
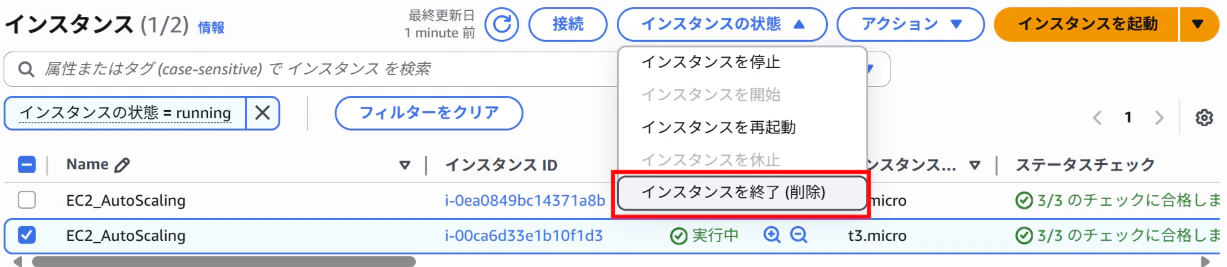
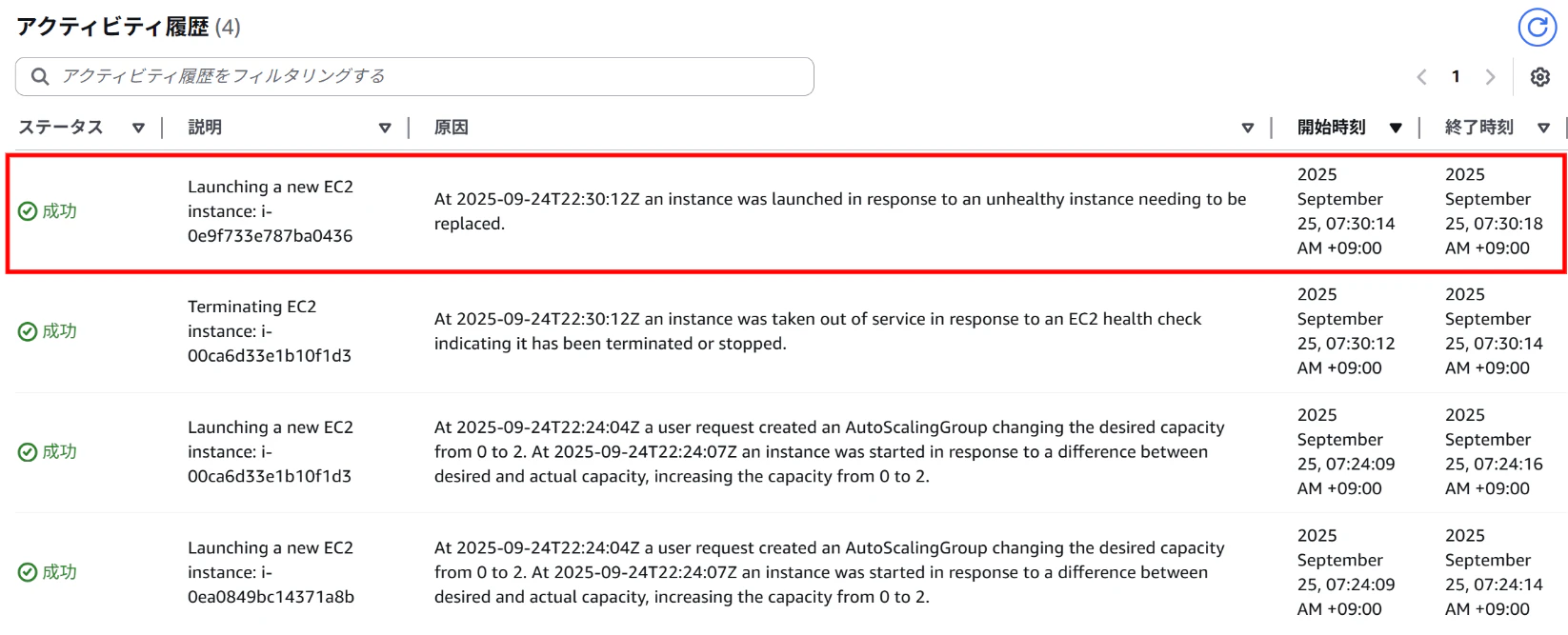
⇒1台インスタンスが追加され、希望の数になる
※この動作はCPU使用率によるスケールアウトではなく、希望キャパシティ維持機能による自動復旧です。
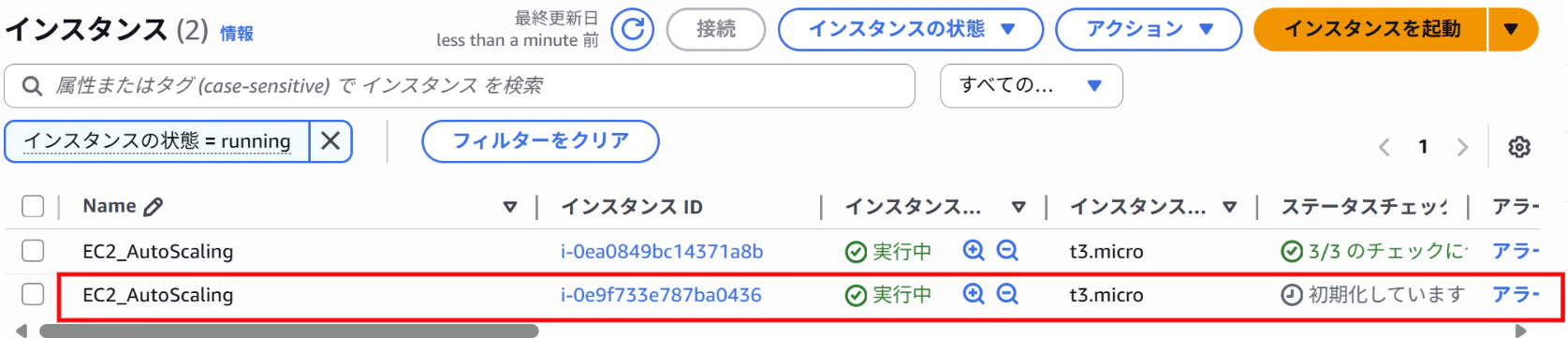
②スケールインの確認(負荷なし)
-
インスタンスが2台起動している状態で待機
CloudWatchのメトリクスを確認し、CPU使用率が低い状態が続いた場合に、インスタンス数が最小容量の1台に減ることを確認
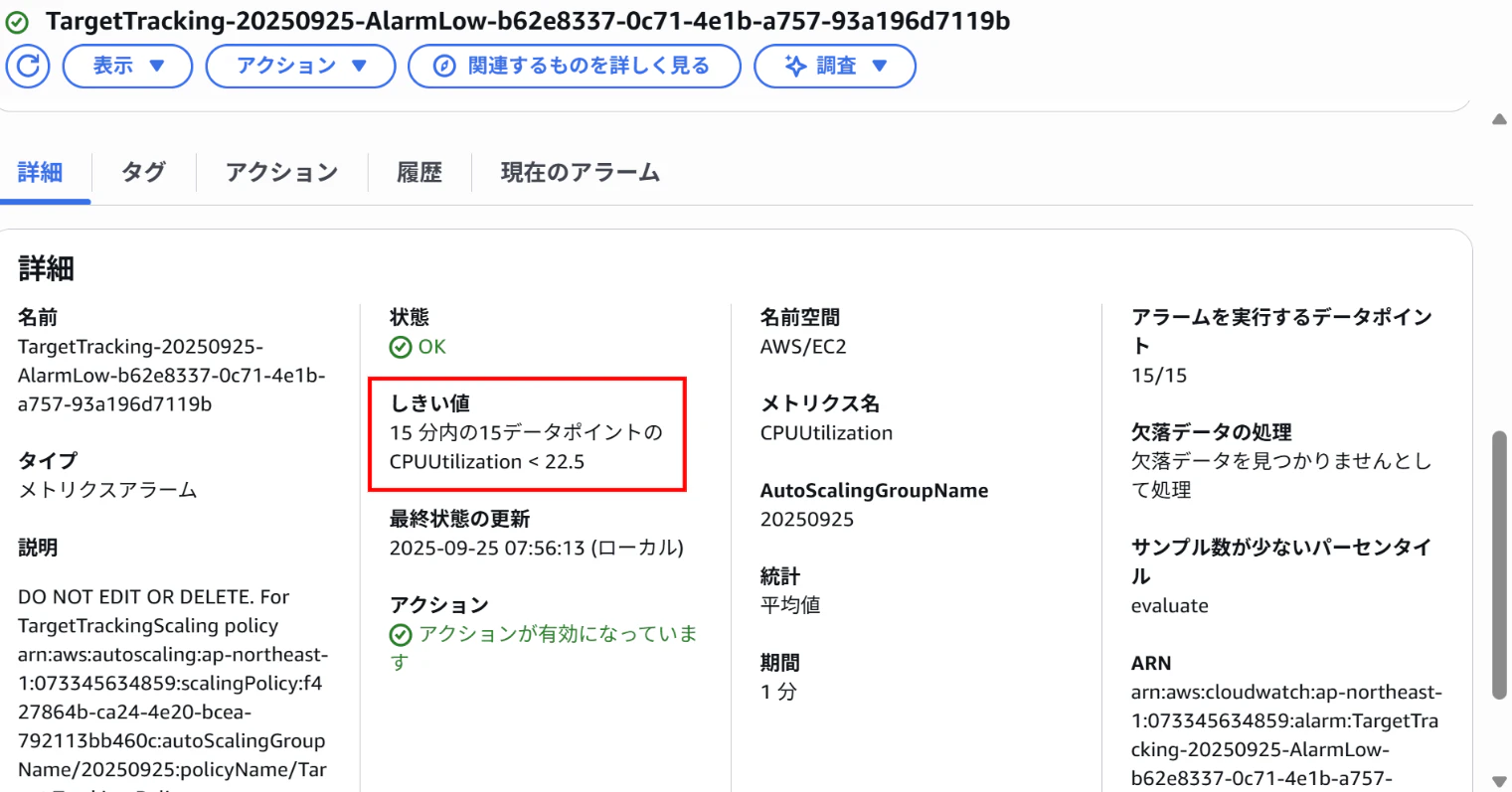
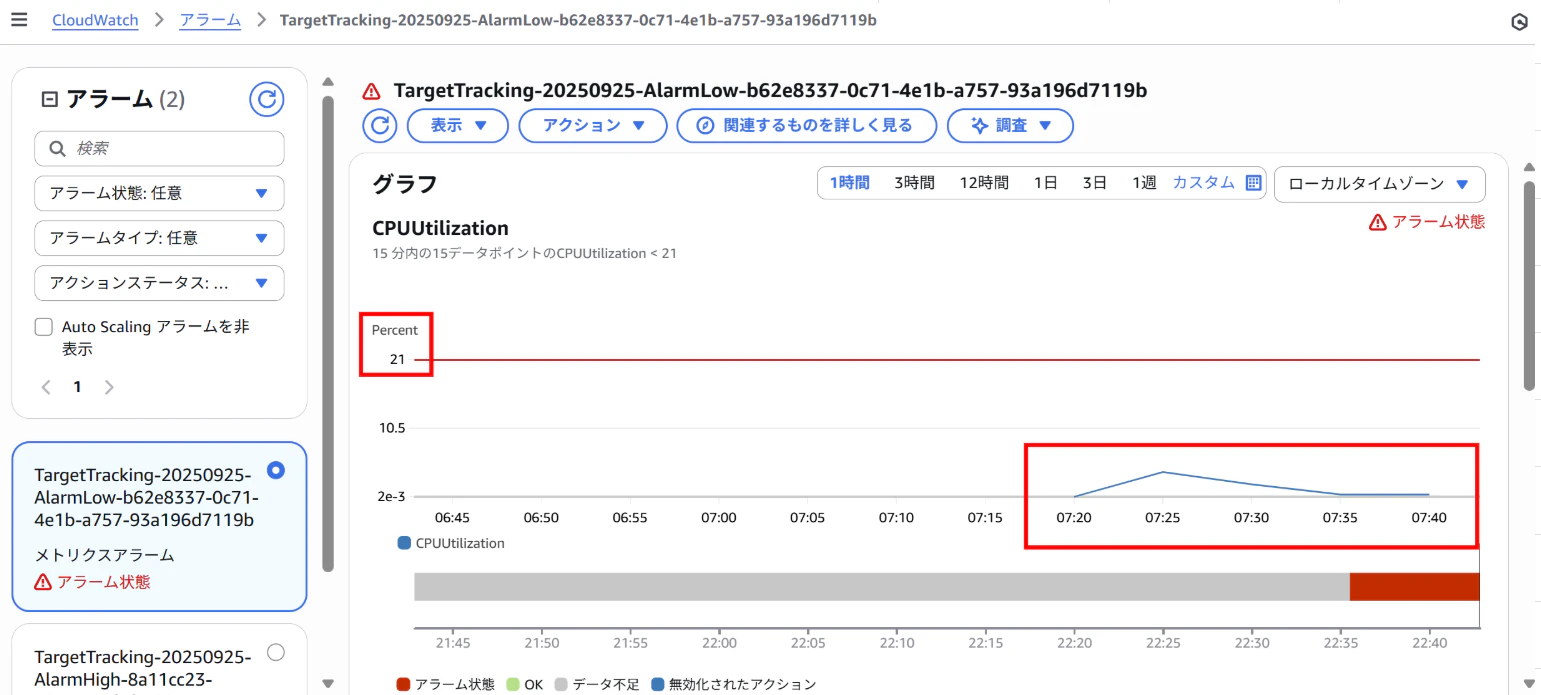
【CloudWatchアラーム画面(AlarmLow)】
⇒しきい値「15分以内の15データポイントのCPUUtilization < 22.5」
AlarmLowがアラーム状態となり、インスタンスをスケールインする。

③スケールアウトの確認(負荷増)
-
稼働中のインスタンス1台に対して負荷をかける
CPU使用率がターゲット値(30%)を超えた状態が一定期間続いた後、インスタンスが2台、3台、4台と自動的に追加されることを確認
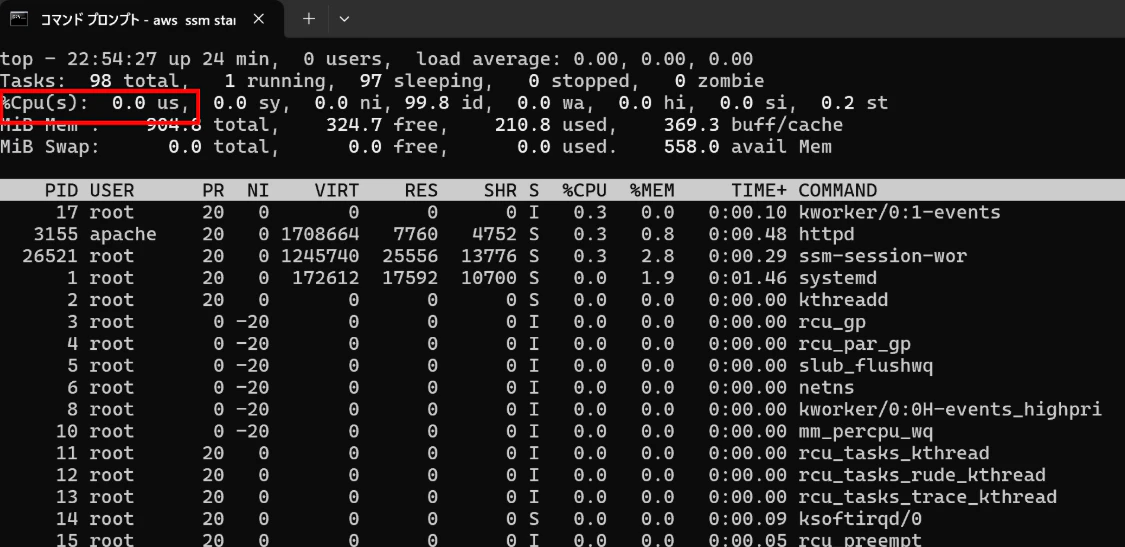
【CLI画面(起動中の1台のインスタンスに接続)】
⇒負荷をかける前(topコマンドで確認)
⇒yesコマンドで負荷をかける
⇒yesコマンドによりCPU負荷増加
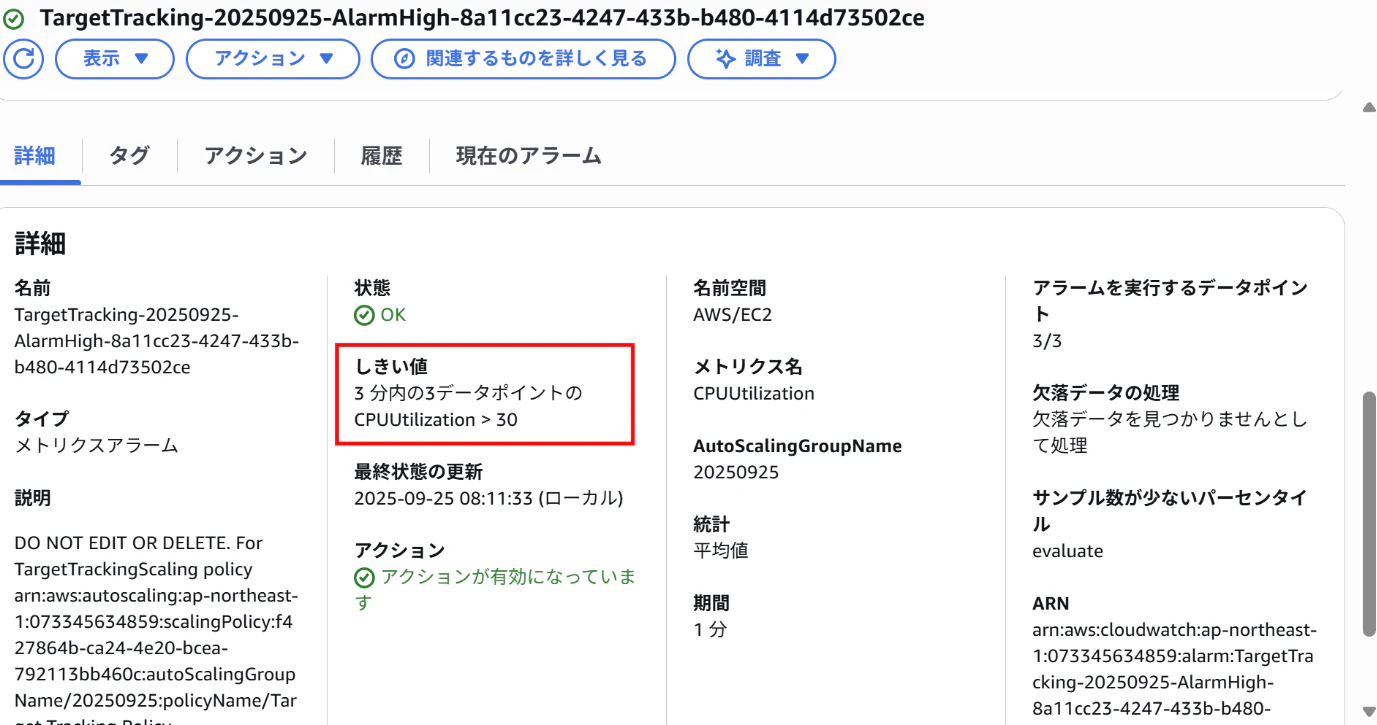
【CloudWatchアラーム画面(AlarmHigh)】
⇒しきい値「3分以内の3データポイントのCPUUtilization > 30」
AlarmHighがアラーム状態となり、インスタンスをスケールアウトする。
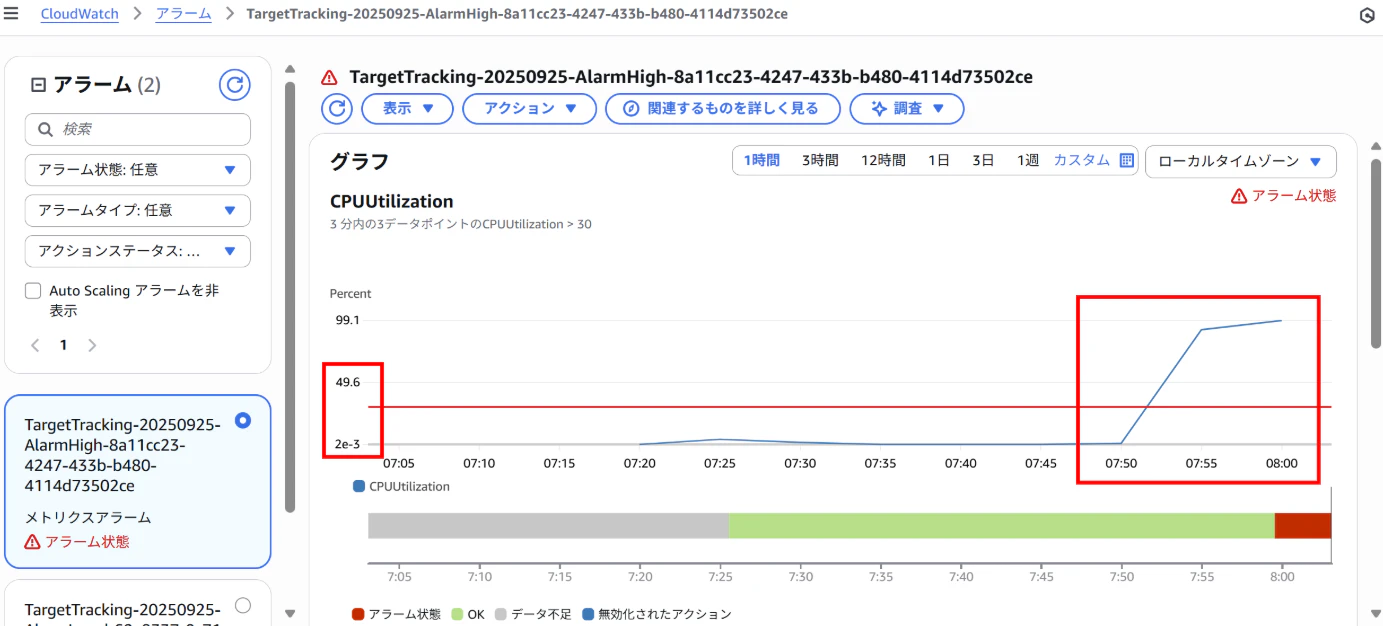
⇒スケールアウト後、CPU負荷が下がりAlarmHighが解除される。

④スケールインの再確認(負荷減)
-
インスタンスに対する負荷を止める
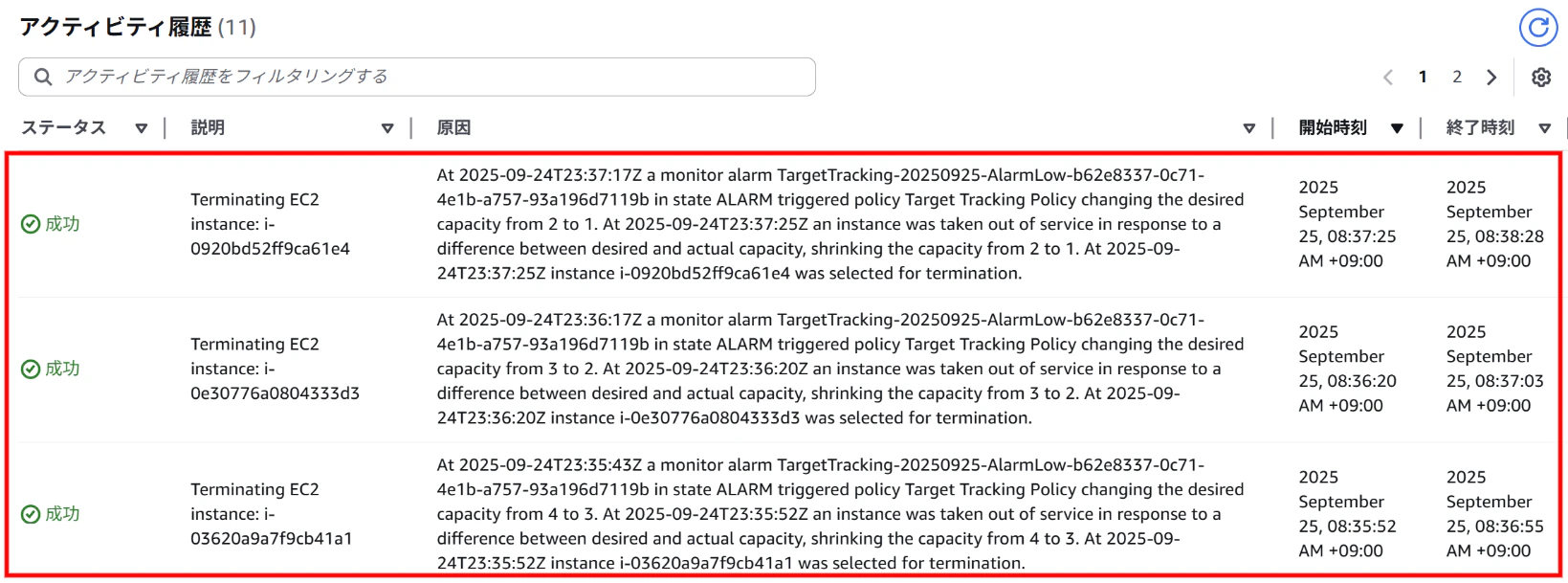
CPU使用率がターゲット値を下回った状態が一定期間続いた後、インスタンスが自動的に4台から2台、そして最終的に1台へ削減されることを確認
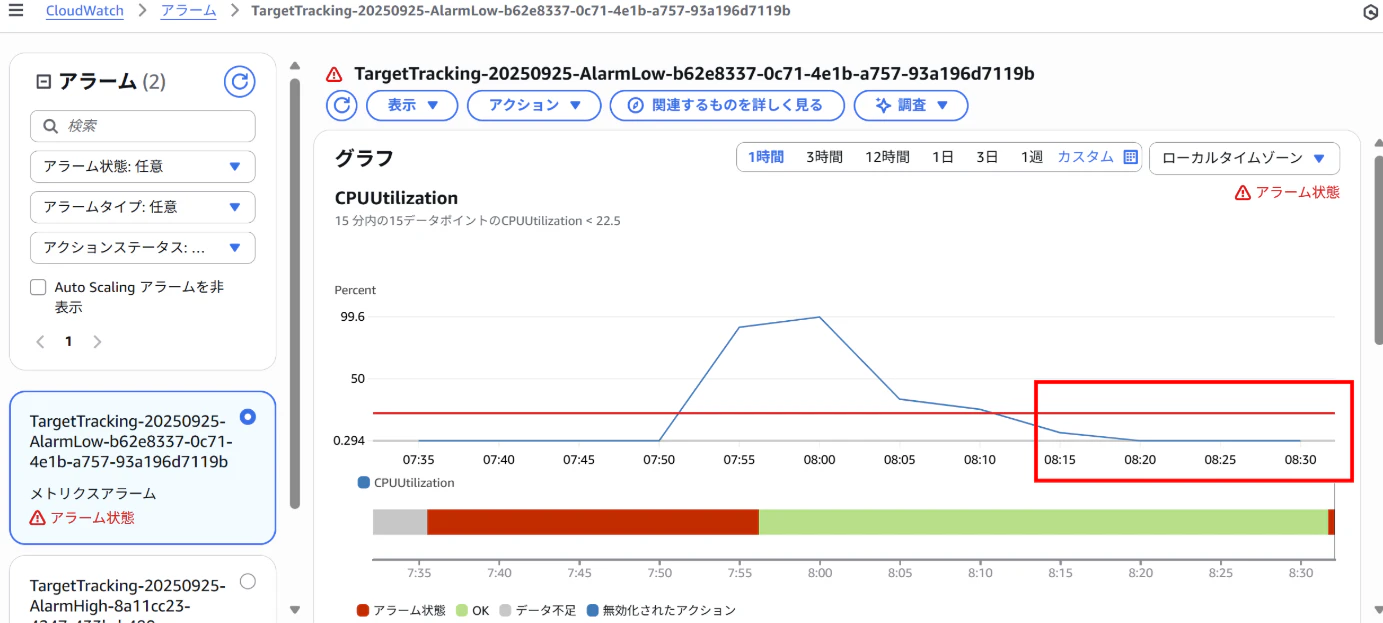
【CloudWatchアラーム画面(AlarmLow)】
⇒pkill yesコマンドで負荷を止めると、再びAlarmLowがアラーム状態となり、インスタンスをスケールインする。

今回の学び
-
負荷に応じたスケーリング制御の理解
CPU使用率という明確な指標をもとに、スケールアウト・スケールインの判断が行われる過程を可視化できた。 -
希望キャパシティの維持による自己修復機能
ASGは単にCPU負荷でスケールするだけでなく、インスタンス削除時にも希望キャパシティを自動的に回復する。