最近データ分析が流行っているので、コードのサンプルを示しながら分析していこうと思います。
コードを
実行環境はPython3になります。
この記事では以下のことをやります。
- CSVを読み込む
- 簡単なカラムの変換を行う
- いろいろな視点で集計・描画を行う
描画に当たっては、 Seaborn を利用します。
Seaborn: statistical data visualization
用いるデータ
分析対象のデータは以下とします。
datetime, id, value
20170606121314, 1,2
20170606121315, 1,3
20170606121316, 1,4
20170608121616, 1,4
20170608121617, 1,1
20170608121618, 1,2
20170606121540, 2,10
20170606121541, 2,8
20170606121542, 2,11
20170608121543, 2,4
20170606134002, 3,21
20170606134003, 3,10
20170606134004, 3,4
20170608134005, 3,50
datetime は、年月日時分秒が連結した文字列とします。
またidごとに数秒間、ある value がある期間毎秒発生していることとします。
Pythonで分析作業
csvファイルの読み込み
import pandas as pd
# CSV読み込み
df = pd.read_csv("target.csv",sep=",")
df.columns = ["datetime","id","value"]
読み込めたか確認する方法としては
df.head()
となります。
すると以下のように出力されます。
| datetime | id | value | |
|---|---|---|---|
| 0 | 20170606121314 | 1 | 2 |
| 1 | 20170606121315 | 1 | 3 |
| 2 | 20170606121316 | 1 | 4 |
| 3 | 20170608121616 | 1 | 4 |
| 4 | 20170608121617 | 1 | 1 |
head() メソッドは、データの最初の5行を表示するメソッドで、データの中身を確認するときによく用います。
他に、 tail() というメソッドもあり、これはデータの終わりから5行のデータを表示します。
表示結果は以下のようになります。
| datetime | id | value | |
|---|---|---|---|
| 9 | 2017-06-08 12:15:43 | 2 | 4 |
| 10 | 2017-06-06 13:40:02 | 3 | 21 |
| 11 | 2017-06-06 13:40:03 | 3 | 10 |
| 12 | 2017-06-06 13:40:04 | 3 | 4 |
| 13 | 2017-06-08 13:40:05 | 3 | 50 |
また以下の行では、dataframeにカラムを設定しています。
df.columns = ["datetime","id","value"]
datetimeカラムをstringからdatetimeへ
from datetime import datetime as dt
df.datetime = df.datetime.apply(lambda d: dt.strptime(str(d), "%Y%m%d%H%M%S"))
この操作をやる目的は、日付のカラムを扱いやすくすることです。やってることとしては、 df.datetime により、datetime列の各行の値にアクセスし、その文字列をstrptime メソッドによりparseしてます。これにより、元々Stringだった値が、日付型および時間型に変換できます。
ID別に集計し、レコードの数を見る
df_by_id= df.groupby("id")["value"].count().reset_index()
df_by_id
groupby("id") により、idカラムの値別にレコードが集計されます。それを count() により、id別のレコード数をカウントしてます。
df_byidの中身は以下のようになっています。
| id | value | |
|---|---|---|
| 0 | 1 | 6 |
| 1 | 2 | 4 |
| 2 | 3 | 4 |
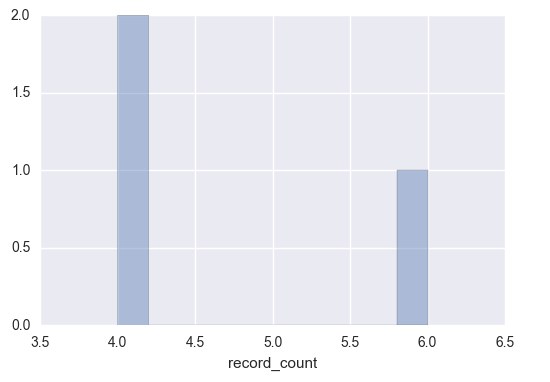
レコード数を横軸にして、ヒストグラムで描画
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
id_df = pd.DataFrame(df_by_id)
sns.distplot(id_df.value, kde=False, rug=False, axlabel="record_count",bins=10)
seaborn というきれいな図を描画するライブラリを利用します。
ID別に集計し、valueカラムの合計をみる
df_value_sum= df.groupby("id")["value"].sum().reset_index()
上で count() となっている部分を sum() とするだけですね。
df_value_sumの中身は以下のようになっています。
| id | value | |
|---|---|---|
| 0 | 1 | 16 |
| 1 | 2 | 33 |
| 2 | 3 | 85 |
ID別に集計し、最初にデータが発生した時刻を取得する
start_datetime_by_id = df.groupby(["id"])["datetime"].first().reset_index()
df_date = pd.DataFrame(start_datetime_by_id)
df_dateの中身は以下のようになっています。
| id | datetime | |
|---|---|---|
| 0 | 1 | 2017-06-06 12:13:14 |
| 1 | 2 | 2017-06-06 12:15:40 |
| 2 | 3 | 2017-06-06 13:40:02 |
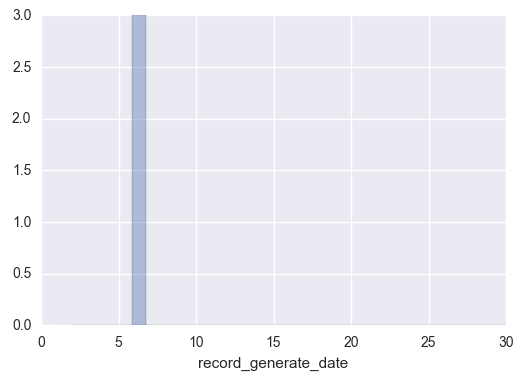
日付を横軸にして、その月のうちどの日にちに何件データが発生したか表示
sns.distplot(date_df.datetime.dt.month, kde=False, rug=False, axlabel="record_generate_date",hist_kws={"range": [1,30]}, bins=30)
hist_kws={"range": [1,30]} というオプションにより、横軸が、0-30の範囲で描画するようになっています。これは、2017年6月の30日のうちのデータのうち、どこでデータが発生したかを
わかりやすくするためです。