LambdaでPhantomJSを使ってウェブサイトの操作を試みようとした時のメモ。
今回の記事ではスクレイピングはしておりませんが、phantomJSでページを表示するところまで紹介しております。そこまで行けたらあとはできるかと思います。
最終目標
S3にファイルを置くと、lambda functionが実行される。
内容としては、python2.7のseleniumライブラリのphantomJSを使って、google.comのサイトのhtmlを出力する。
ここまでできれば、あとは好きなサイトから情報を抜き出したりすることが可能になると思います。
それでは一つ一つ確認していこうと思います。
環境
| version | |
|---|---|
| python | 2.7 |
AWS lambdaでサポートされてるのが2.7ということで、シンタックスに気をつけましょう。
参考) https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/current-supported-versions.html
以下必要な各種ライブラリを確認していきます。
- Selenium
- PhantomJS
selenium
https://pypi.python.org/pypi/selenium
こちらのサイトよりインストールします。

上記の箇所の下段よりtar ballをダウンロードしてください。
このフォルダより pyディレクトリ配下にあるseleniumフォルダをまるごと、このあと使います。
PhantomJS
http://phantomjs.org/download.html
このサイトのLinux 64-bitより、phantomjsの実行ファイルを含むzipをダウンロードしてください。
bin配下のphantomjsをこのあと使います。
各種ライブラリや実行ファイルのダウンロードの仕方は上記以外にも
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/lambda-python-how-to-create-deployment-package.html
こちらに従っても大丈夫です。というかこういうのがあるのを見落としておりました。。
集めた素材をまとめ、コードを書こう。
ファイル構成
- lambda_function.py
- selenium/
- phantomjs
- setup.cfg.py
あるディレクトリに上記のような構成をつくります。
処理の実体はlambda_function.pyに記述することにします。このファイル名はなんでもいいですが、AWSの管理コンソールで登録する際に利用することに留意しましょう。
lambda_function.py
# !/usr/bin/env python
import time # for sleep
import os # for path
import selenium
from selenium import webdriver
from selenium.webdriver.support.ui import Select
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
def lambda_handler(event, context):
# set user agent
user_agent = ("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36")
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = user_agent
dcap["phantomjs.page.settings.javascriptEnabled"] = True
browser = webdriver.PhantomJS(service_log_path=os.path.devnull, executable_path="/var/task/phantomjs", service_args=['--ignore-ssl-errors=true'], desired_capabilities=dcap)
browser.get('http://google.com')
html = browser.execute_script("return document.getElementsByTagName('html')[0].innerHTML")
print html
最初に色々と読み込んでおきます。
PhantomJSではUserAgentが指定できるのでこちらもしっかり記述しておきましょう。
setup.cfg.py
[install]
prefix=
このファイルはsetup configuration fileと呼ばれるもので、
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/lambda-python-how-to-create-deployment-package.html
こちらの説明にあるように、入れておきましょう。
管理画面に移る前に...
ファイル群はuploadできるように、zip化しておく必要があります
上記のファイル構成をしているディレトリに移動し、
$ zip -r upload.zip *
上記のコマンドを打ちましょう。するとその階層にupload.zipが生成されます。
AWS管理画面で情報を登録していこう。
Select blueprintにて
select runtimeでpython 2.7,
Blueprintとしてs3-get-object-pythonを選択します。
Configure triggersにて
- S3のBucketを選択する(仮にtest.comとする)
- Event typeでPut
- Prefix: test/
- Suffix: お好みで入力してください。
各種項目ですが、lambda functionを実行させるトリガーとなるS3のバケットとディレクリをここで決めています。上記のような設定では、
test.com/test/
にファイルがおかれた時をトリガーとして実行されることになります。大事なことですが、Enable triggerにちゃんとチェックを入れておきましょう。
下部のNextをクリックし、次の画面にうつります。
Configure function
Lambda function code
Name, Descriptionは管理画面より確認する際の名前です。適当につけておくとどういう処理だったか、案外わからなくなってくるので、キチンときめておきましょう。
Runtimeは Python 2.7を選択されていると思います。
Lambda function code
Conde entry typeは
- Edit code inline
- Upload a.ZIP file
- Upload a file from Amazon S3
の3種があります。先ほどZipを作ったので真ん中のUpload a .ZIP fileを選択します。。
Function packageでは先ほど作成したupload.zipをuploadしましょう。
Lambda function handler and role
このHandlerの入力が極めて重要です。この入力項目はメインのファイル名.関数名となっているので、注意しましょう。先ほどは
ファイル名: lambda_function
関数名: lambda_handler
で作成したので、Handlerでlambda_function.lambda_handlerと入力します。
次にRoleを選択します。ない場合は新規で作成し、すでに存在する場合はExisting roleから存在するroleを選択します。
Advanced settings
ここではMemory(MB)とTimeoutの時間を選ぶことができます。
メモリは 128KBから1536KBまであり、
メモリの応じてCPUの性能も向上するようです。(http://qiita.com/hama_du/items/12303d9f9cb800db14d3)
参考に貼っておきます。
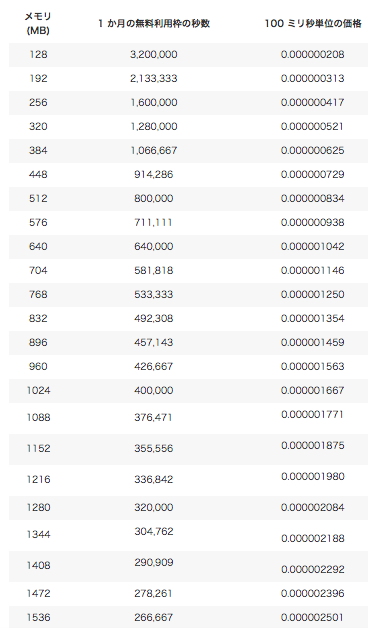
(source: https://aws.amazon.com/jp/lambda/pricing/)
Timeoutの時間は最大5分まで選択可能です。
最後にVPC内で実行するかどうか選択しましょう。
完成!
lambda functionの登録ができたら、

TestボタンをクリックしてSave and testを押してみましょう。
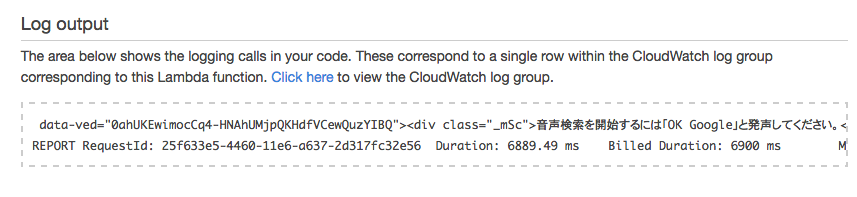
関数が実行されると、上記のような形で、print htmlの内容が出力できることが確認できます。
上記画像のclickを押すと、実際にgoogleのhtmlがprintされていることからひとまず関数が実行されていることが確認できます。S3にファイルをおいても、実際に関数が実行されます。
以上です。
追記
長い記事を書くことがあまりなく、ミスも散見されると思うので少しずつ追記/修正していくかと思います。
編集1) タイトルと内容に齟齬があったため、編集しました(7/11)