はじめに
この記事は、New Relic という オブザーバビリティプラットフォーム を「聞いたとことあるけど使ったことがない・どんなものか気になる・とりあえず動かしてみよう」という方向けの記事となります。(私もそうです)
細かい設定内容や設定の詳細は公式ドキュメントを参照してください。
まずはどんな事ができるのか、New Relic 無料プランへの登録・Progateのタスクにある「New Relic を使ってアプリケーションを改善しよう」を使って、New Relic がどのようなツールなのか試してみました。
※Progateのタスクを使用するには、ログインアカウント(無料)が必要となります。
オブザーバビリティについて
オブザーバビリティとは何か記載します。
オブザーバビリティとは複雑なシステムの内部状態を外部から観測する能力のことで、システムの健全性、パフォーマンス、信頼性を維持するために不可欠な概念です。
事前に定義された異常が発生した時に通知するだけの「モニタリング」と違い、「オブザーバビリティ」を備えたシステムでは問題が生じた原因とシステムの動作がどのようになっているのかをリアルタイムで把握できます。
- 引用URL
オブザーバビリティについて
モニタリングする対象システムのセットアップと New Relic をセットアップ
Progateに記載されている手順を参照し、モニタリングする対象システムのセットアップと New Relic サインアップします。
まず、モニタリングする対象システムをセットアップします。
モニタリングする対象システムをセットアップ手順
オンラインIDE(GitHub Codespaces)を使用すると、必要なツールがすべてセットアップされているので楽ちんです。
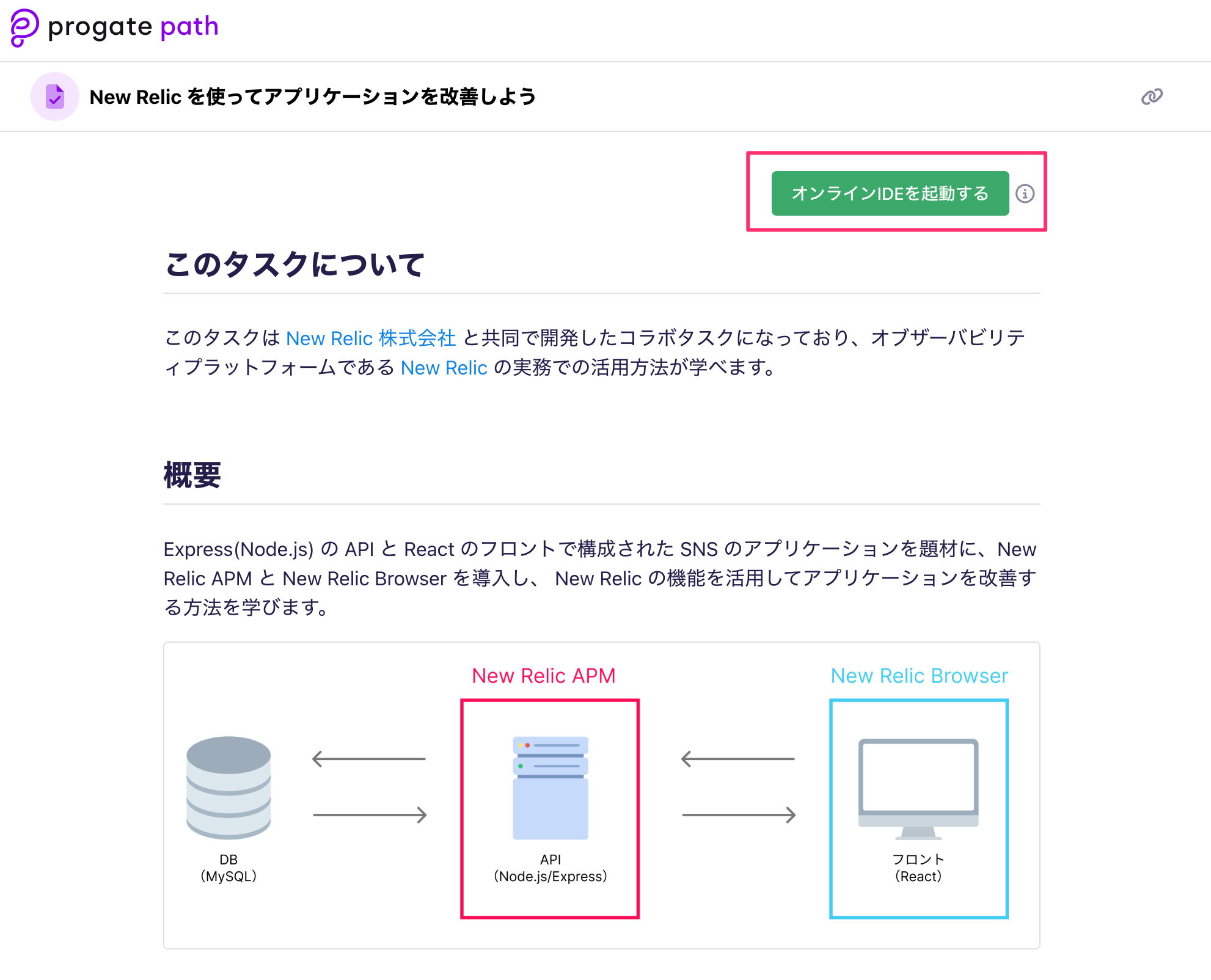
次に New Relic の無料プランの登録をします。
下記のURLからサインアップしてください。
以下のような画面が表示されればアカウント作成完了です。
New Relic APM 導入
下記を参考に、New Relic APMをセットアップします。
APM とは Application Performance Monitoring の略でアプリケーションの稼働状況をユーザー視点で監視し、問題を解決したり、パフォーマンスを改善することです。
New Relic APM はこの APM を実現するためのコア機能であり、アプリケーション全体のサービスレベルを可視化したり、アプリケーションの内部で実行されている処理を詳細にトレースできます。、イベント、ログ、トランザクション(MELT)を監視することで、アプリの健全性をリアルタイムで追跡します。
- 引用URL
New Relic APM を導入する
[APM & Services]-[new_relic_app]-[summary]を開くと、正常に通信ができている場合は、以下のような画面が表示されます。
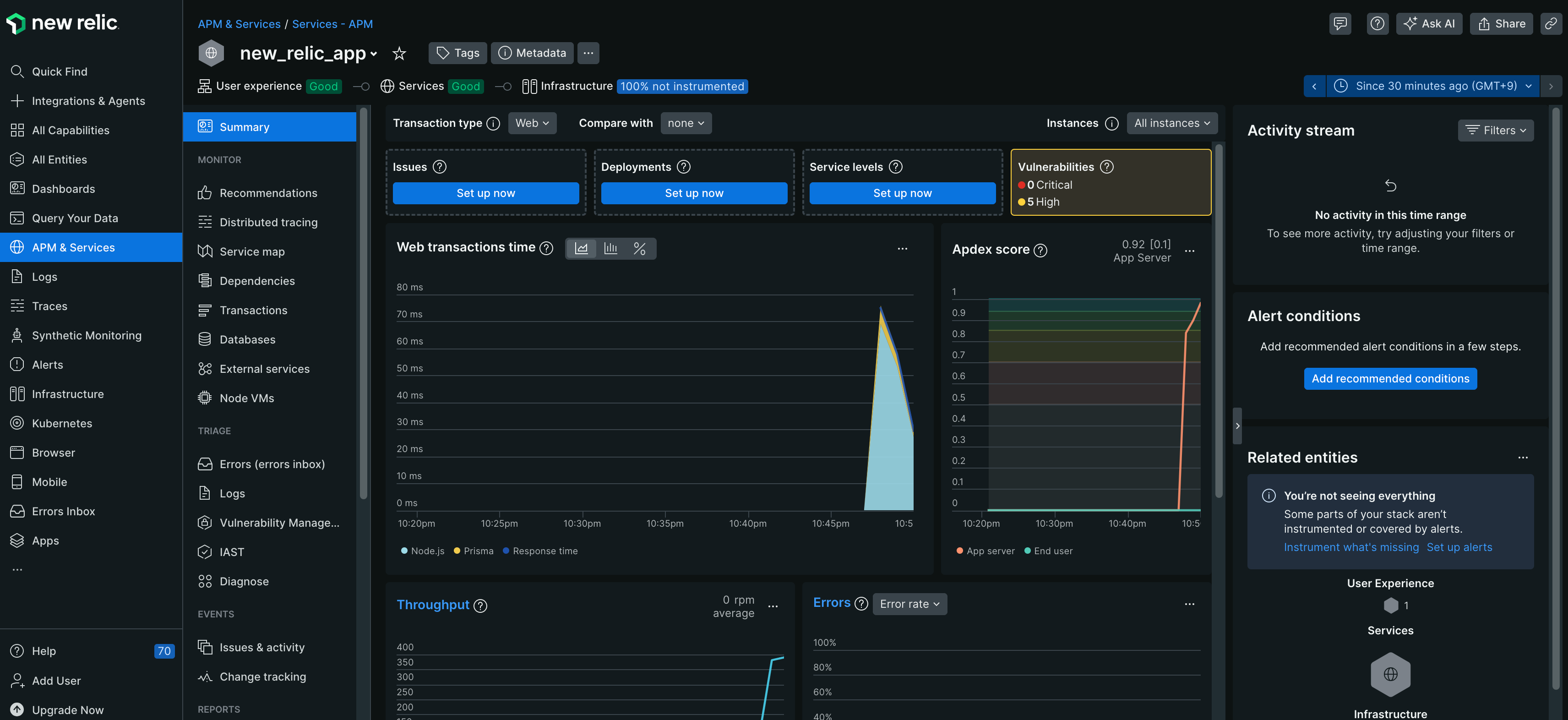
summary画面では、応答時間・スループット・エラー率などがリアルタイムで確認できる他、脆弱性も確認できます。
※脆弱性の情報も確認できるのはすごいと感じでいます。
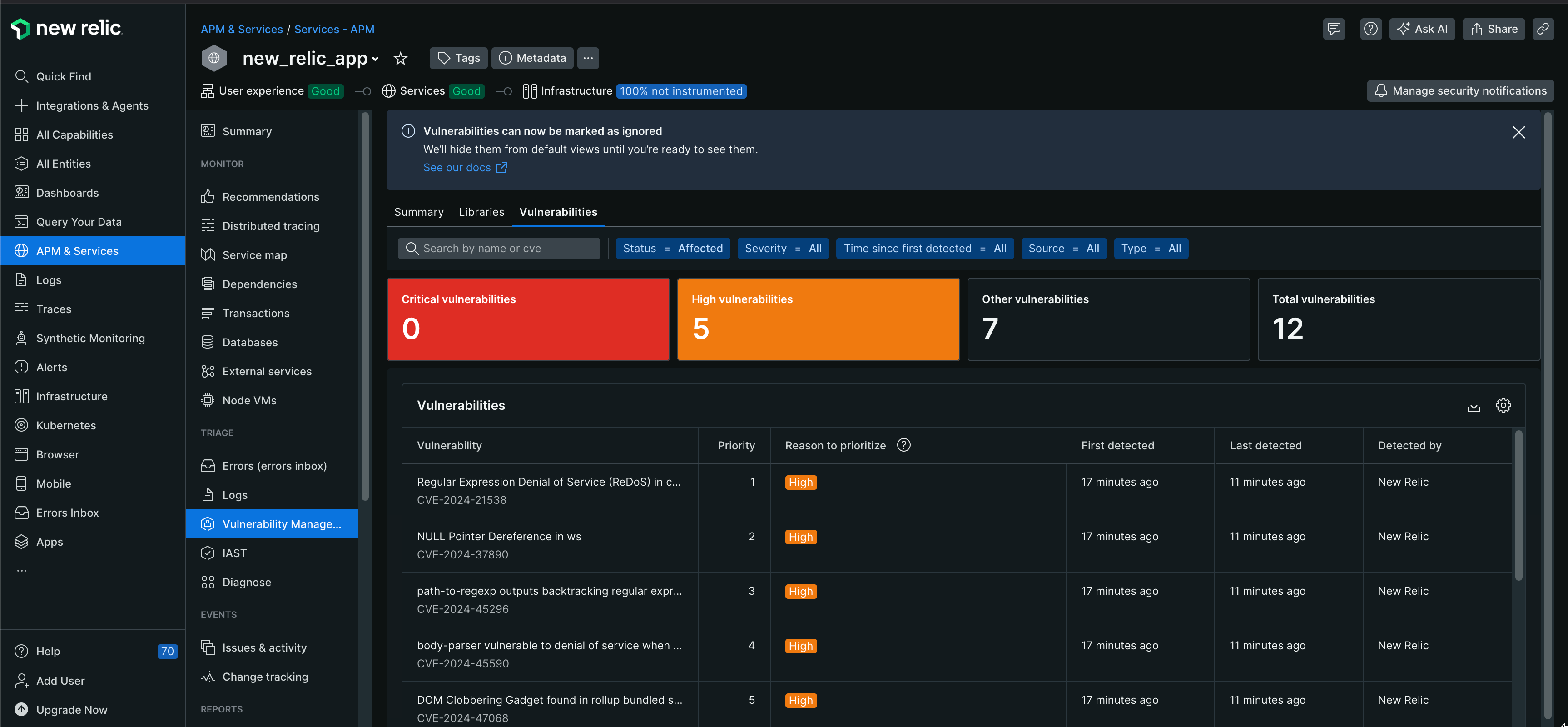
脆弱性情報は以下のように表示され、一目でどのような危険性にシステムが晒されているのかが確認できます。
New Relic Browser を導入
下記を参考に、New Relic Browserをセットアップします。
New Relic Browser は Web サイトにおけるユーザーのモニタリングを実現します。初期描画までの時間やどのようなリクエストをしているのかなど、 Web サイトがどのようにユーザーに使われているかを可視化します。
- 引用URL
New Relic Browser を導入する
[Browser]-[new_relic_app]-[summary]を開くと、正常に通信ができている場合は、以下のような画面が表示されます。
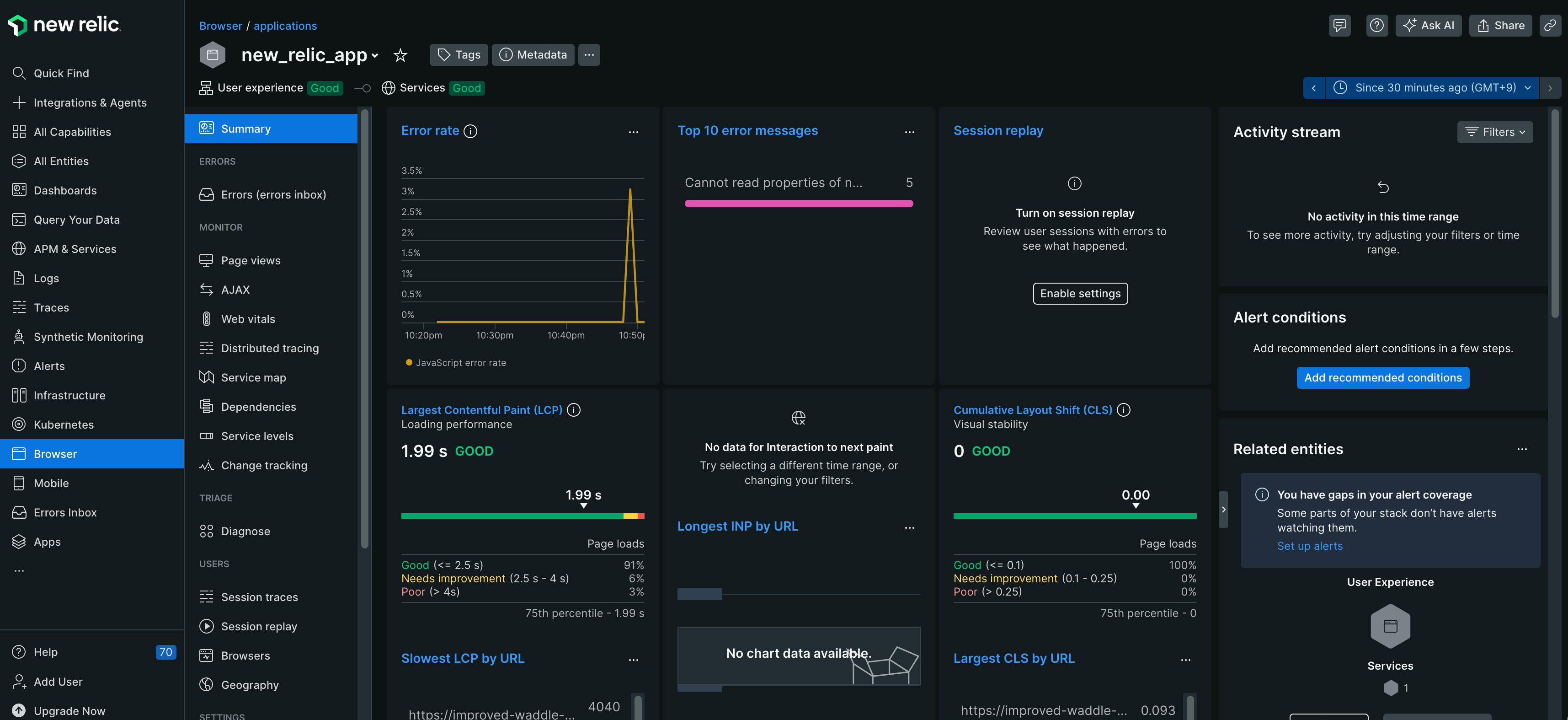
Browserでは、LCP(Largest Contentful Paint)・Error rate(ブラウザで発生したエラー)等のユーザが体験しているパフォーマンスや利用ブラウザやアクセス元の地域といったユーザの利用環境など詳細な情報がリアルタイムで確認できます。
この後のProgateのタスクでは下記のようなタスクがあり、実際の運用で発生しそうな内容のデモができます。
私もやってみましたが、実際にアラートを検知した時のエラー内容からの調査方法・どのページに処理がかかっていてページの読み込みが遅いのかを確認し対応するという実践向けの内容で、大変勉強になりましたので、ぜひチェックしてみてください。
- Browserで検知したErrorから調査し対応する
- 表示に時間がかかっているページのチューニングする
サーバ監視について
ここまでは、New Relic でどのような事ができるのかを、Progateのタスクを使って確認をしましたが、ここからはサーバ監視(リソースやプロセス監視)の観点で試してみました。
また、アラートを擬似的に発生させSlackに通知もしてみました。
事前準備
今回は、AWSで Amazon Linux 2023 のEC2を監視してみたいと思います。
AWSのアカウント作成と、 Amazon Linux 2023 のEC2起動方法はここでは割愛します。
エージェントインストール
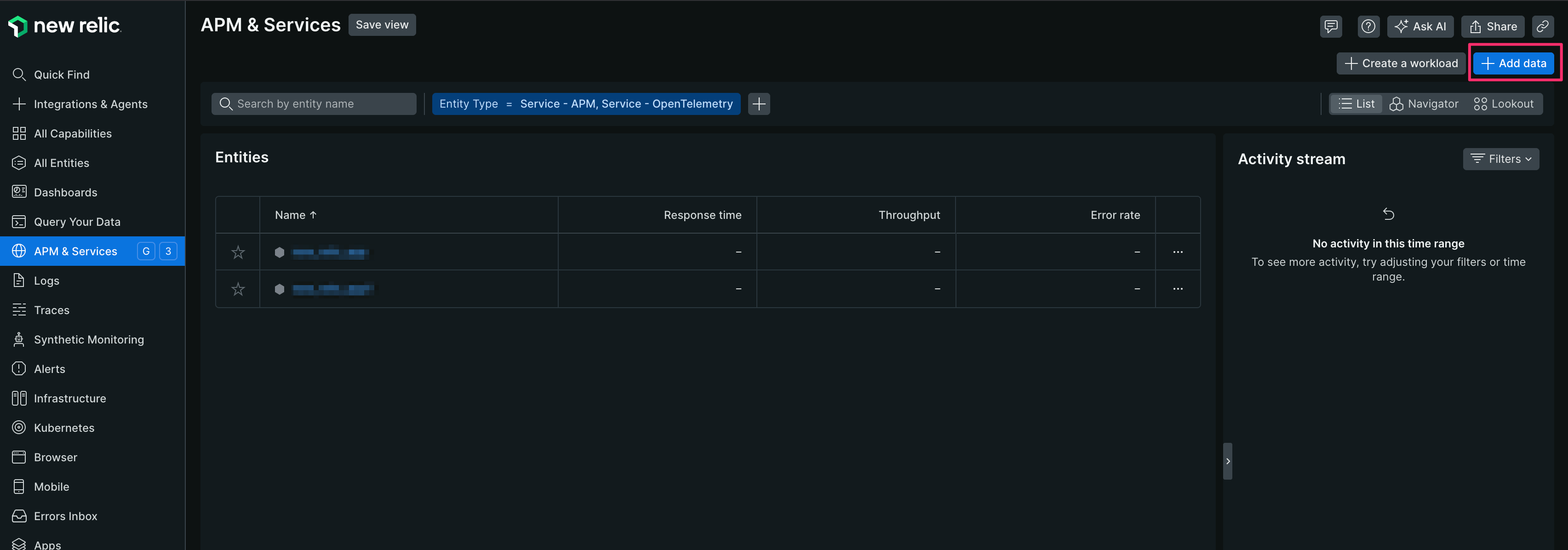
【1】 New Relic にログインし [APM & Services]-[Add data]をクリックする
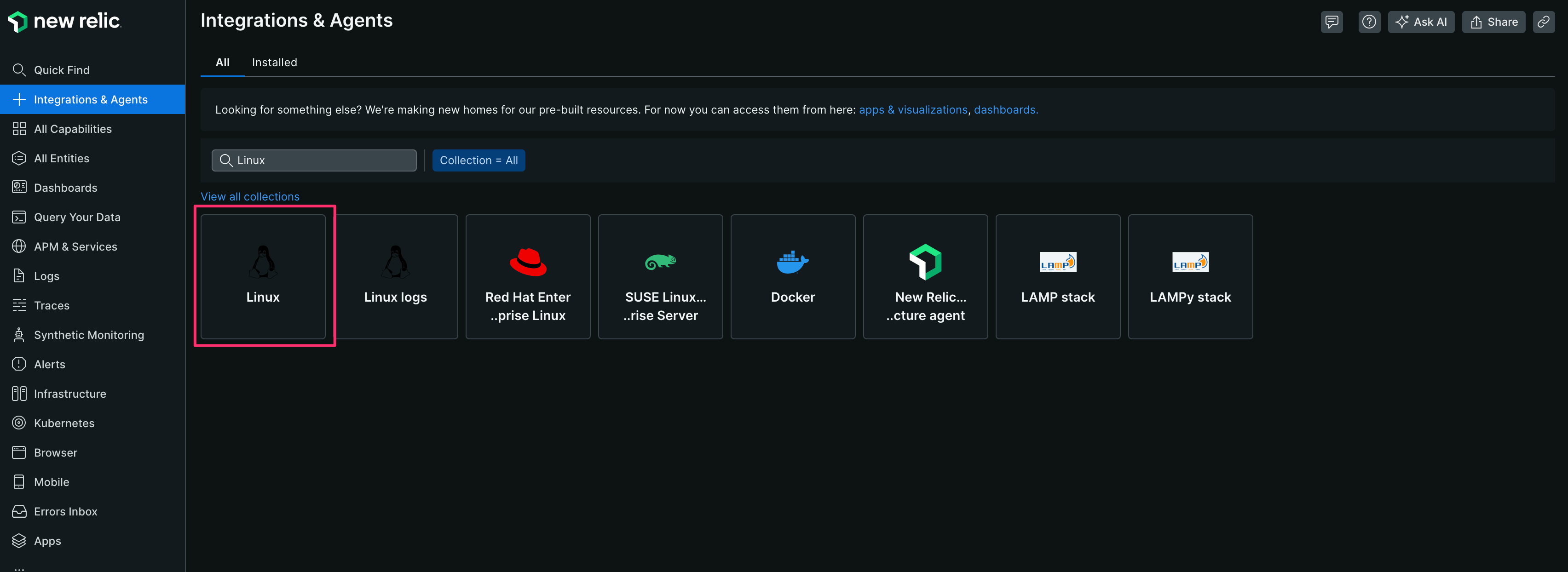
【2】[Linux]をクリックする
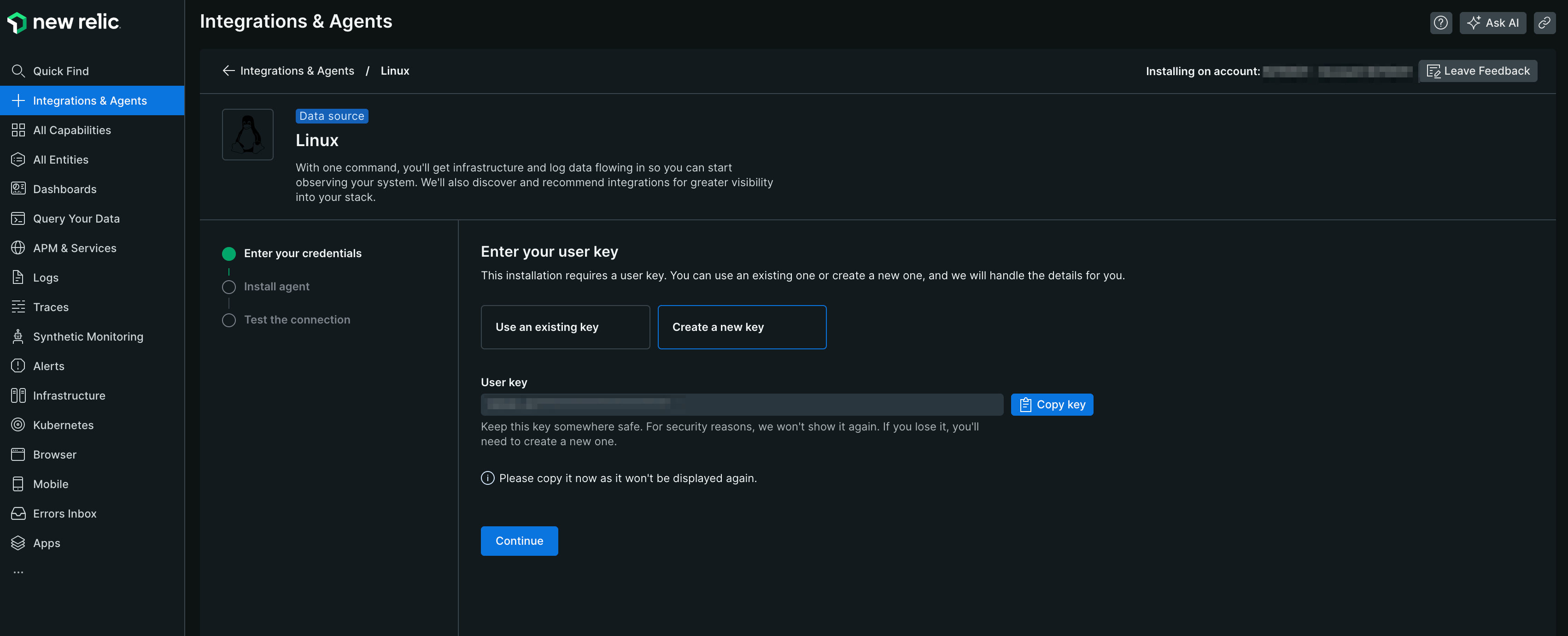
【3】[Create a new key]をクリックしキーを取得、[Continue]をクリックする
【4】 インフラストラクチャ・エージェント インストールコマンドが表示されているのでコピーする
Automatically answer "yes" to all install prompts. We'll stop the installer if there's an error.は 任意で有効にしてください。
インストール時に確認が必要なくなります。
インストールコマンドコピー後、この画面はそのままにしてください。
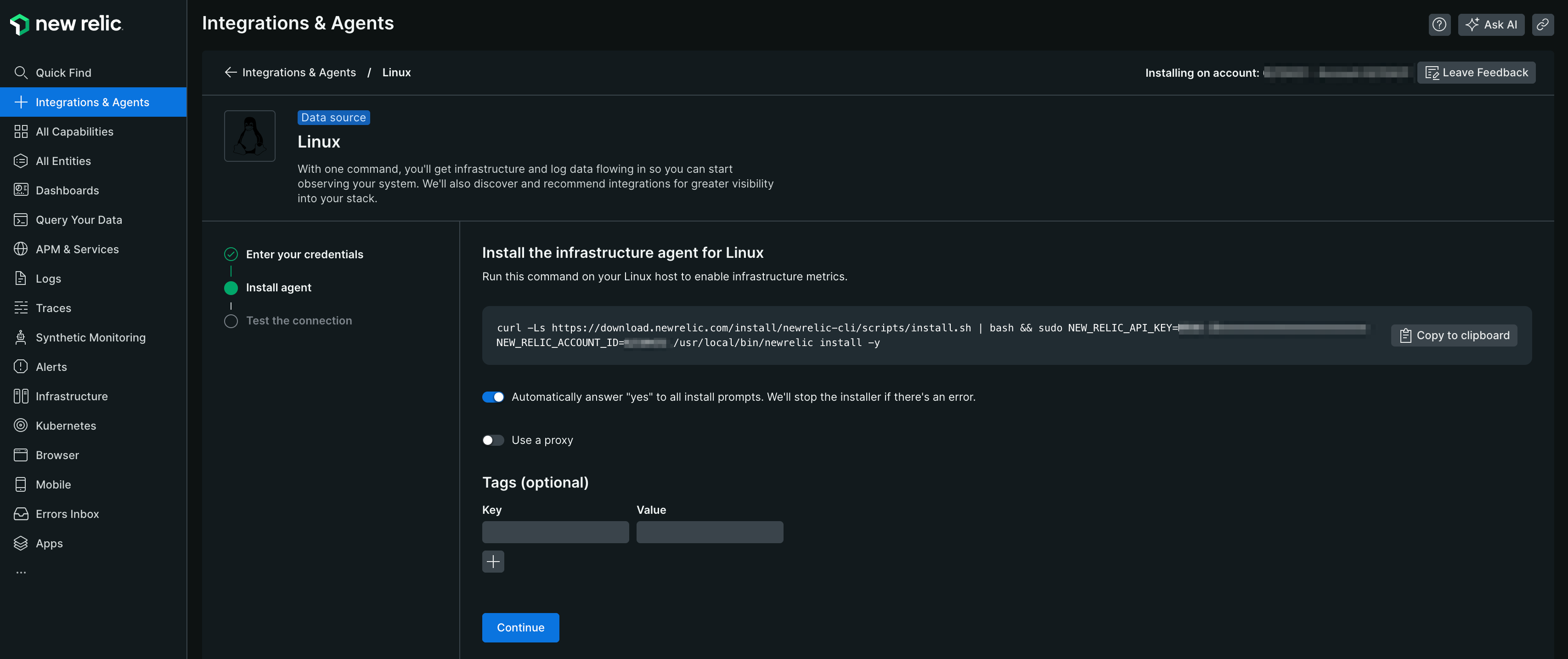
【5】 Amazon Linux2023でインストールコマンドを実行する
$ curl -Ls https://download.newrelic.com/install/newrelic-cli/scripts/install.sh | bash && sudo NEW_RELIC_API_KEY=**************************** NEW_RELIC_ACCOUNT_ID=6210431 /usr/local/bin/newrelic install -y
インストールコマンド実行後、以下の結果が出力されればインストール完了です。
Installing New Relic CLI v0.97.2
Installing to /usr/local/bin using sudo
_ _ ____ _ _
| \ | | _____ __ | _ \ ___| (_) ___
| \| |/ _ \ \ /\ / / | |_) / _ | | |/ __|
| |\ | __/\ V V / | _ | __| | | (__
|_| \_|\___| \_/\_/ |_| \_\___|_|_|\___|
Welcome to New Relic. Let's set up full stack observability for your environment.
Our Data Privacy Notice: https://newrelic.com/termsandconditions/services-notices
✔ Connecting to New Relic Platform
Connected
Installing New Relic
✔ Installing Infrastructure Agent
Installed
✔ Installing Logs Integration
Installed
New Relic installation complete
--------------------
Installation Summary
✔ Infrastructure Agent (installed)
✔ Logs Integration (installed)
View your data at the link below:
⮕ https://onenr.io/0dQed0kxWje
View your logs at the link below:
⮕ https://onenr.io/0Bj3Kv8G6jX
--------------------
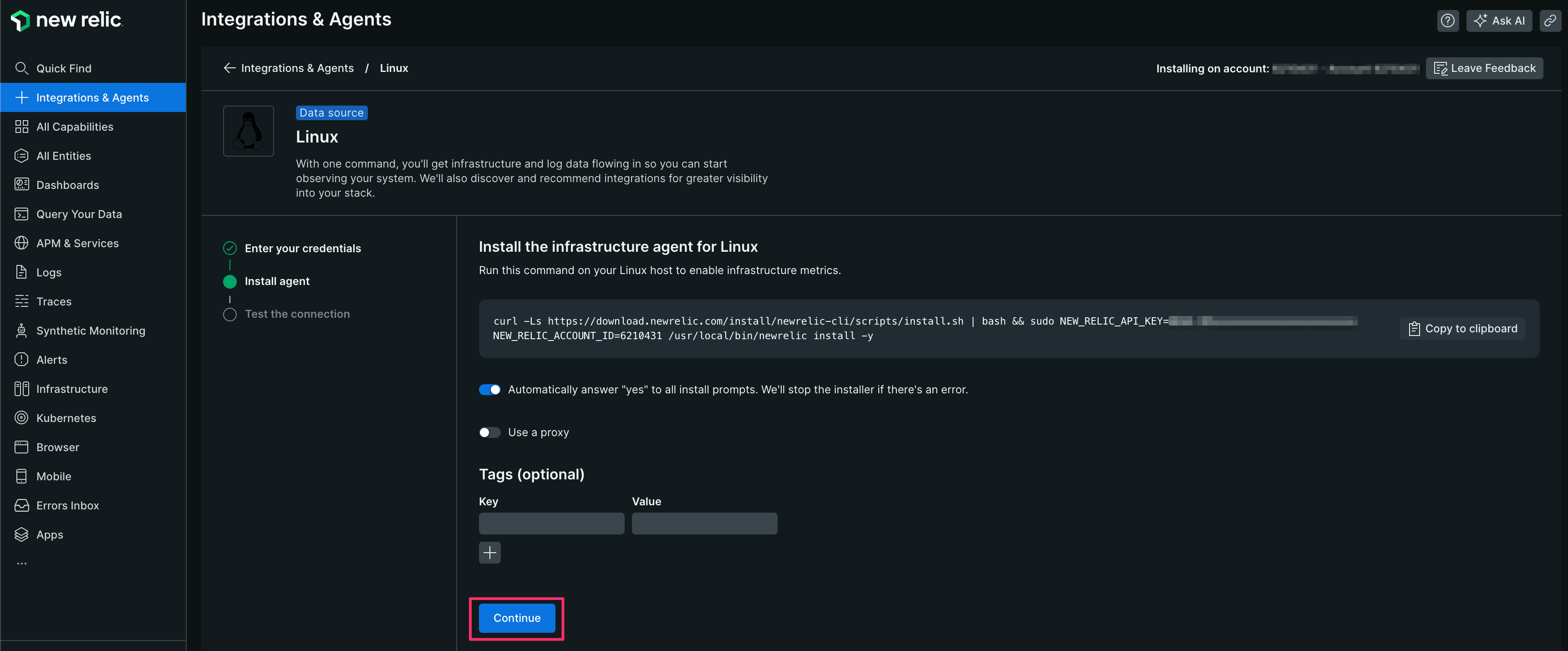
【6】 New Relicの画面に戻り[Continue]をクリックする
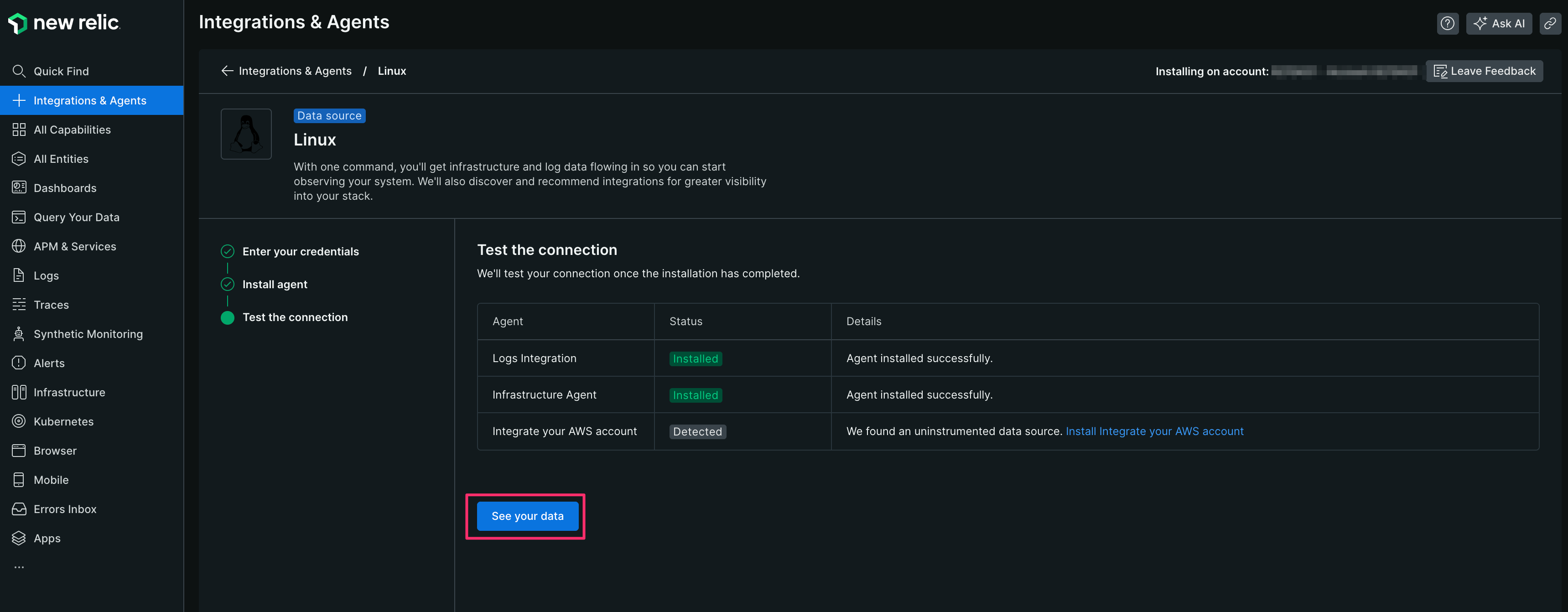
【7】 Test the connectionが実行され、下記の結果になれば New Relic 接続完了です
[See your data]をクリックする
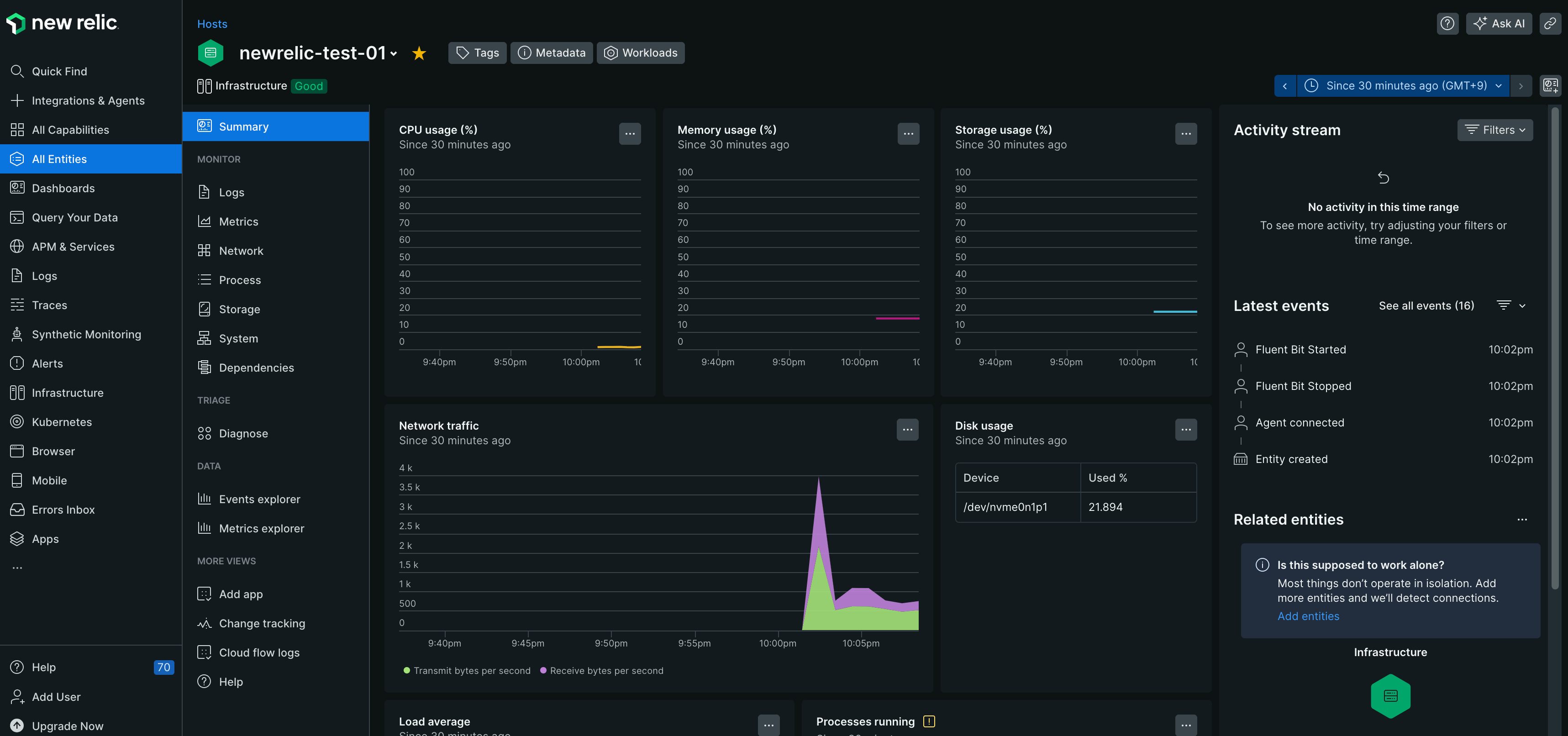
以下の様なリソース情報が表示されれば完了です
アラートと Slack への通知設定
Slack への通知設定手順
【1】[Alerts]-[Destinations]-[Slack]をクリックする
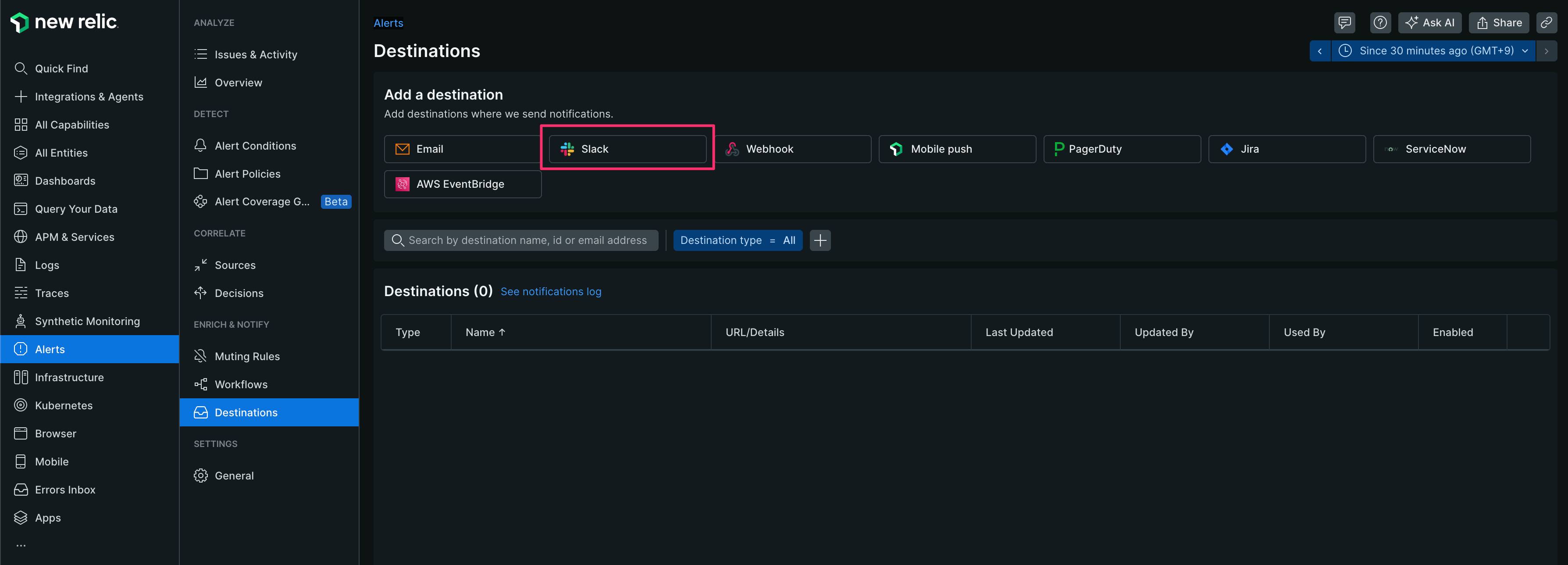
【2】[Authenticate in one click]をクリックする
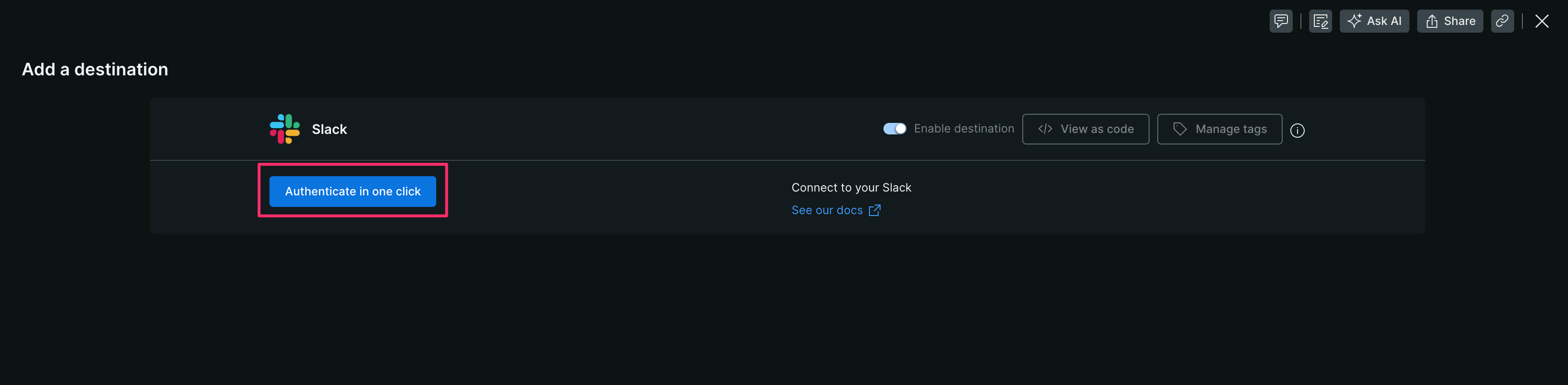
【3】New Relic から Slack へのアクセスを許可する
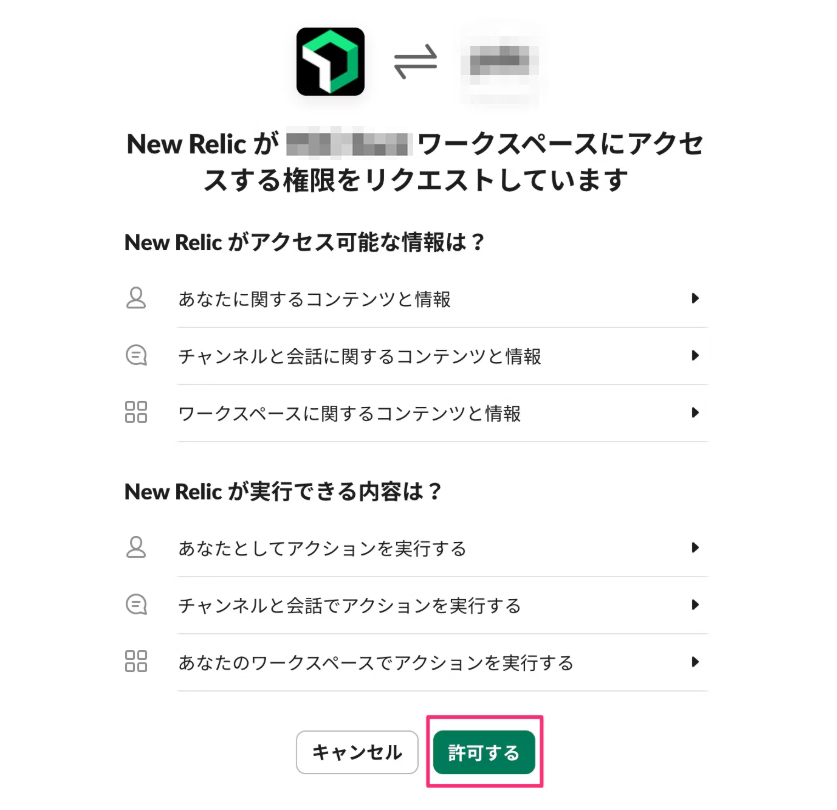
認証が成功すると下記のような画面になるので、[Close]をクリックする
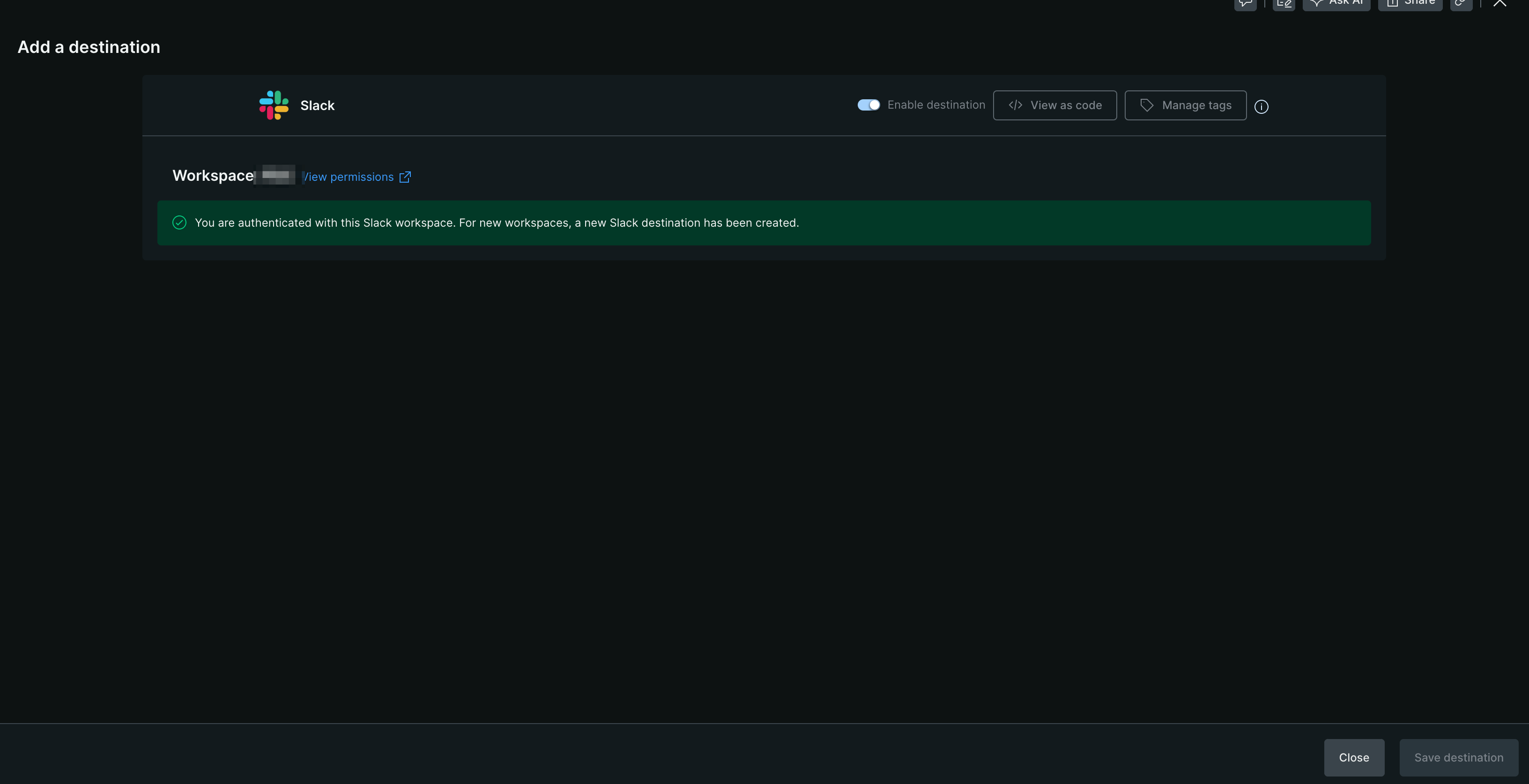
これで Slack への通知設定が完了です。
アラート設定手順
今回は例として、CPUの監視をして閾値を超えた場合は通知する設定をしたいと思います。
アラート設定には以下の2つの設定が必要です。
簡単にそれぞれの役割を記載しますが、詳細は公式ドキュメントを参照してください。
- Alert Policies
- Conditionをグループ化する
- 通知先の設定をする
- Alert Conditions
- アラートを検知する条件を設定する
Alert Policiesの作成
【1】[Alerts]-[Alert Policies]-[New alert Policies]をクリックする
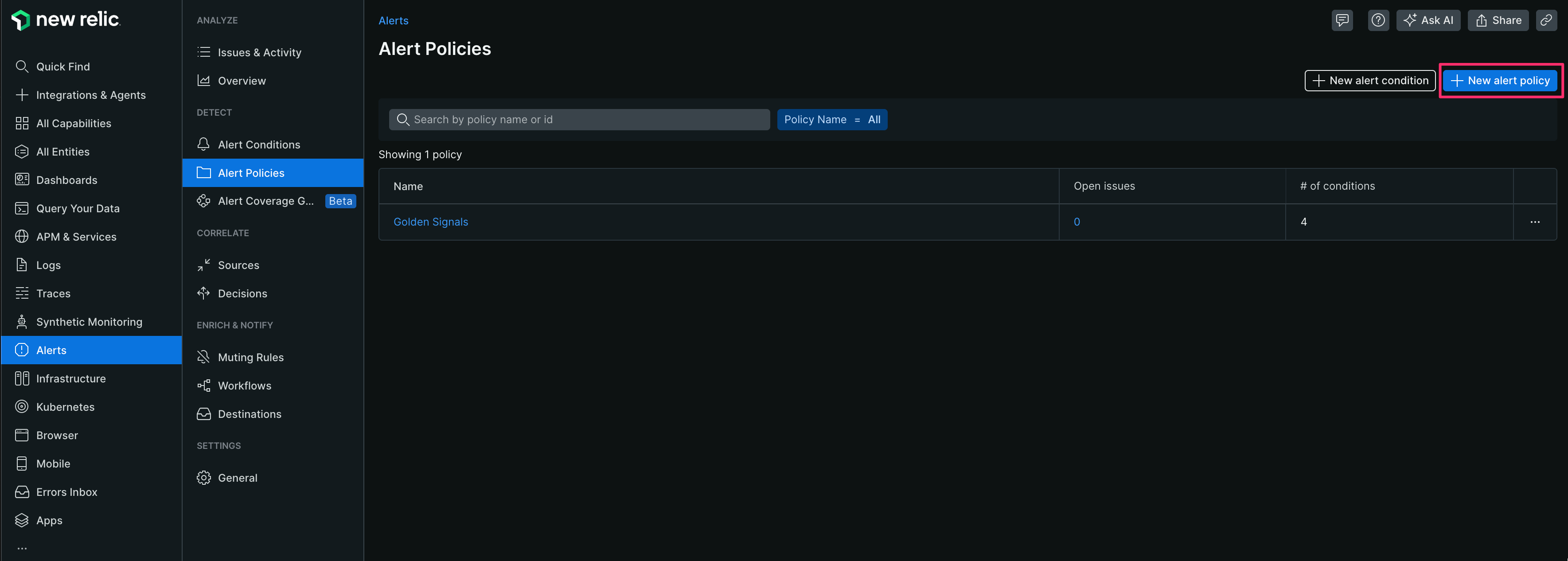
【2】 Policy name(今回はtest-policyとする)を入力、[One issue per condition]を選択し、[Set Up notifications]をクリックする
※One issue per condition
アラート条件(Conditions)毎に発生したアラートを通知をする設定となります。
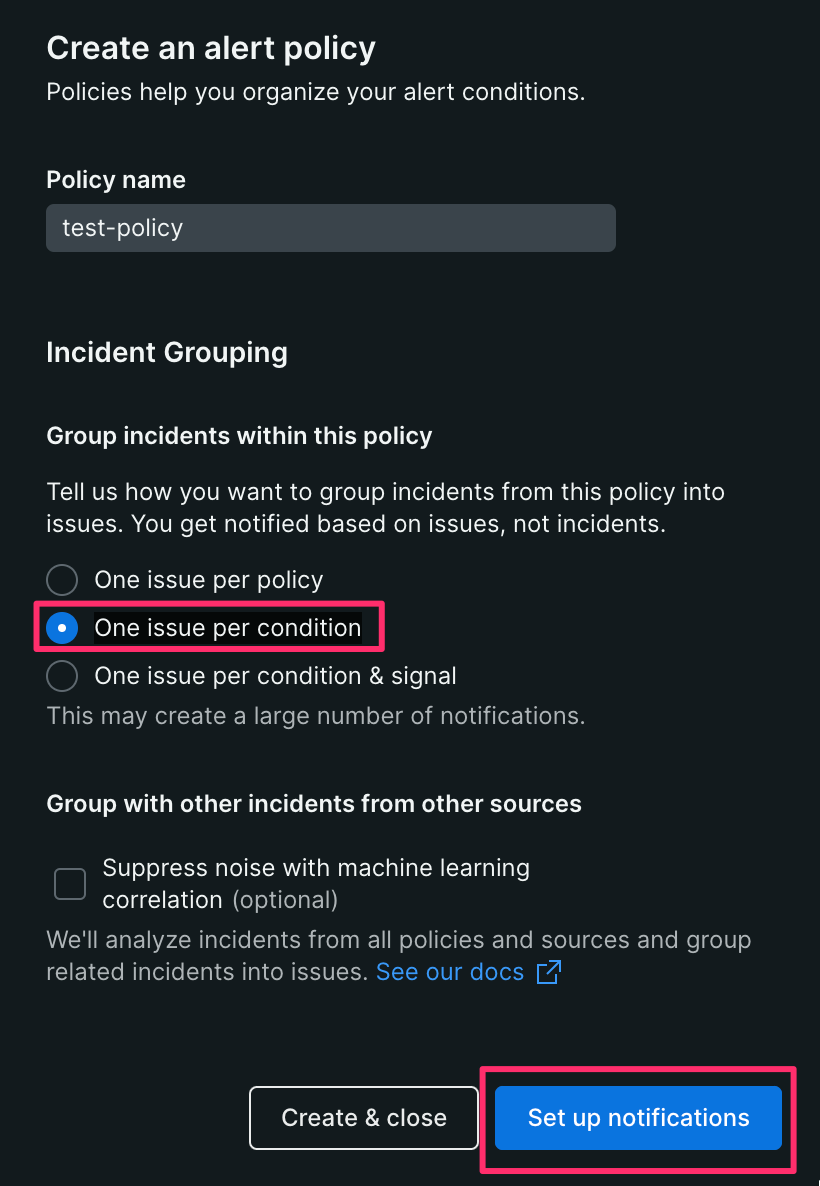
【3】 [Slack]をクリックする
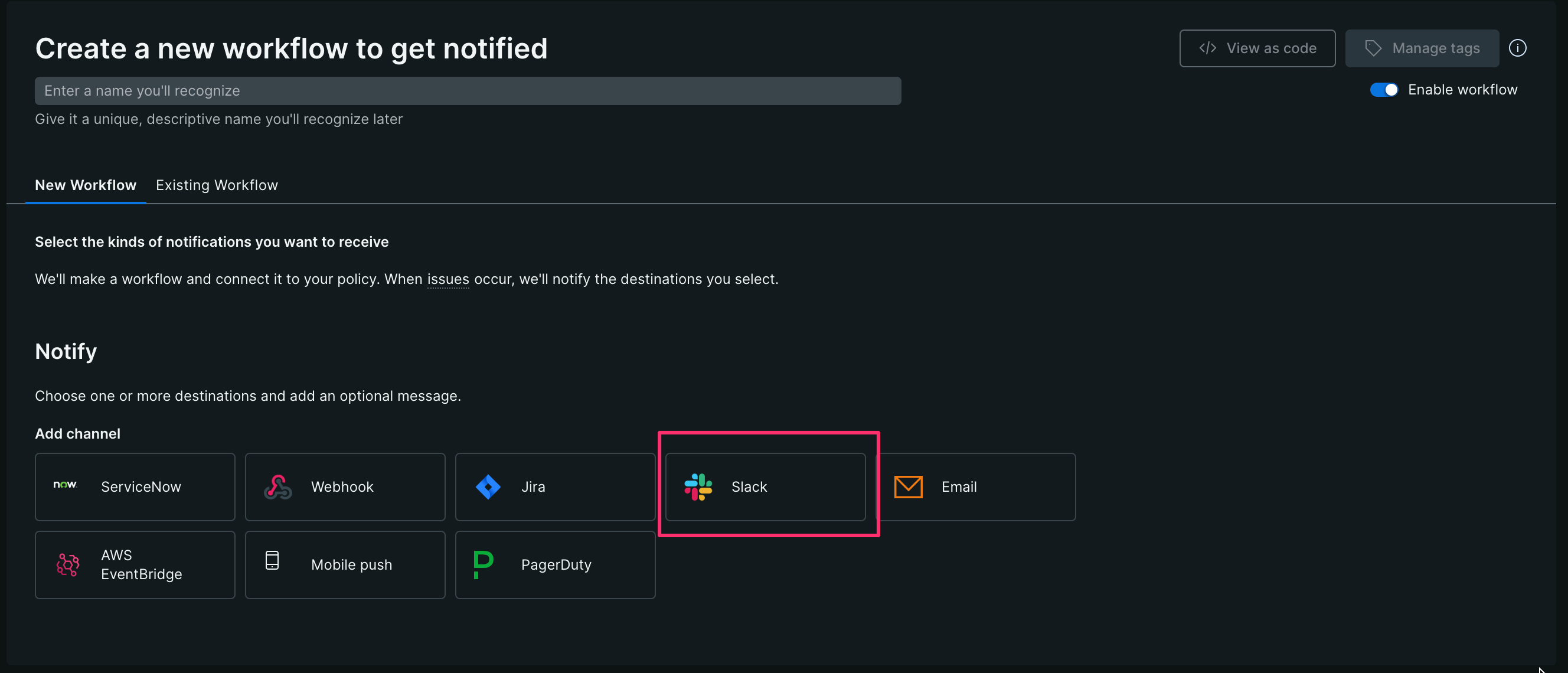
【4】 Slack destinationに、「Slack への通知設定手順」で許可したワークスペースを選択、Channelはアラーを通知したいチャンネルを選択し、[Save message]をクリックする
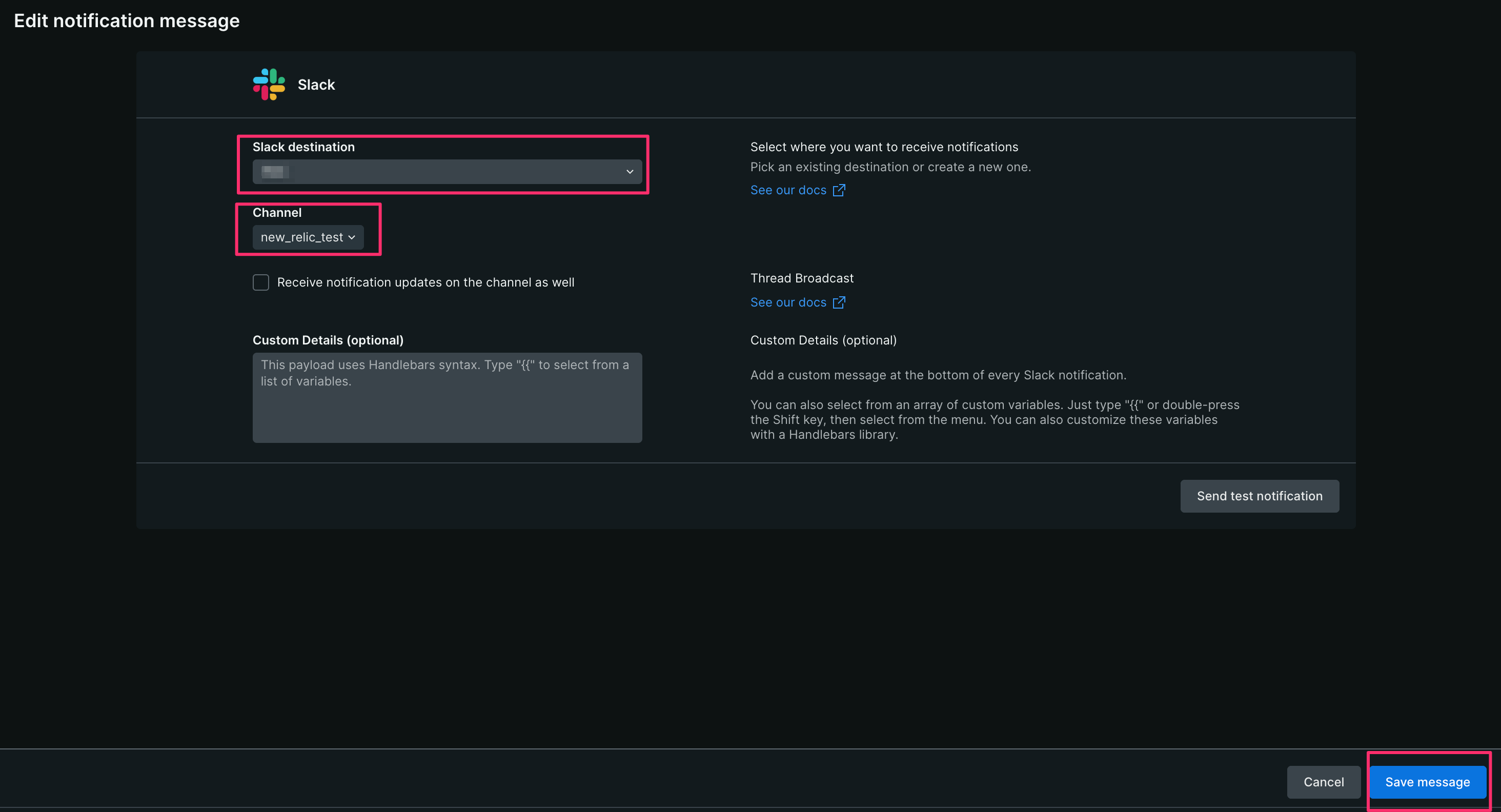
【5】 [Active workflow]をクリックする
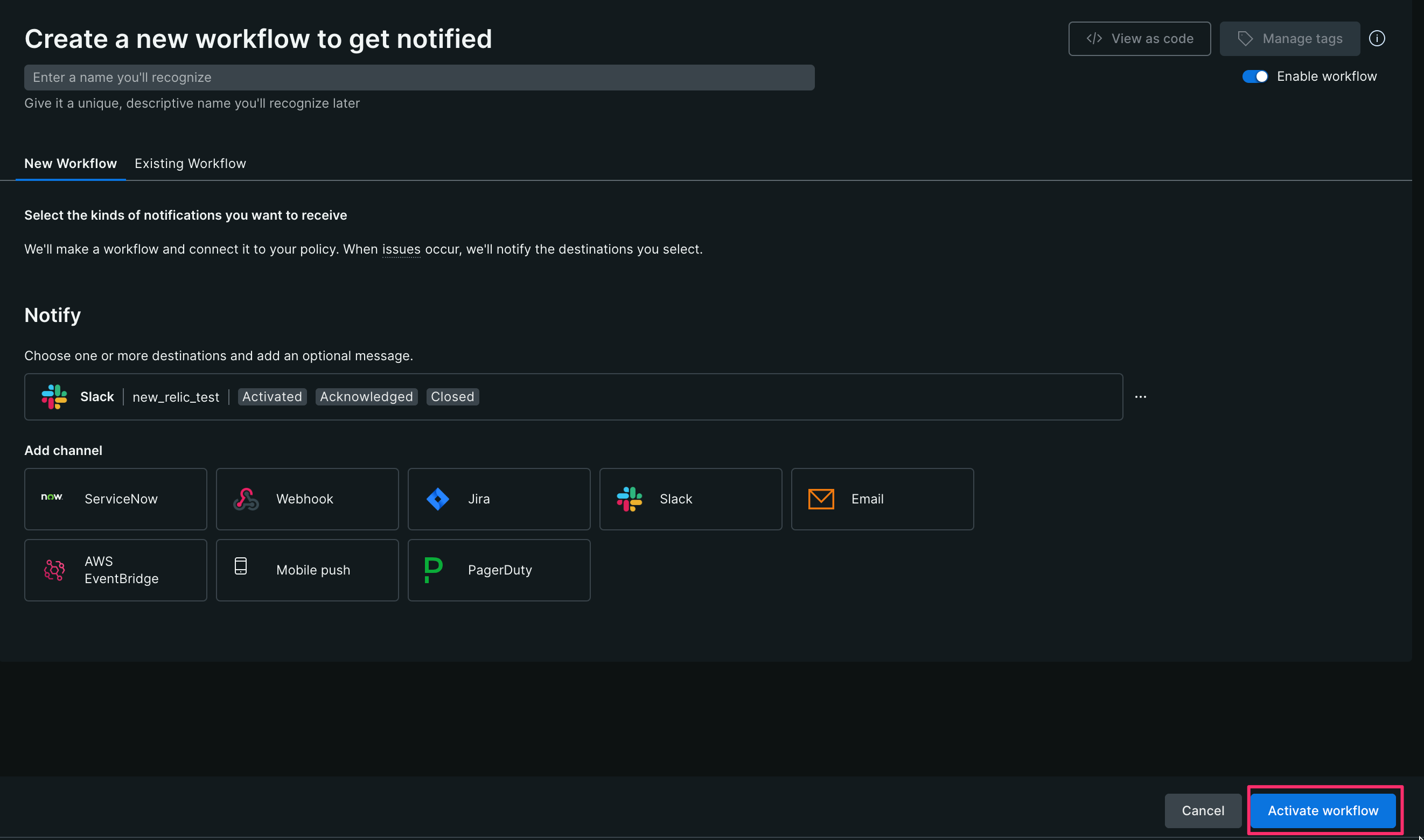
以下のように登録されれば完了です。
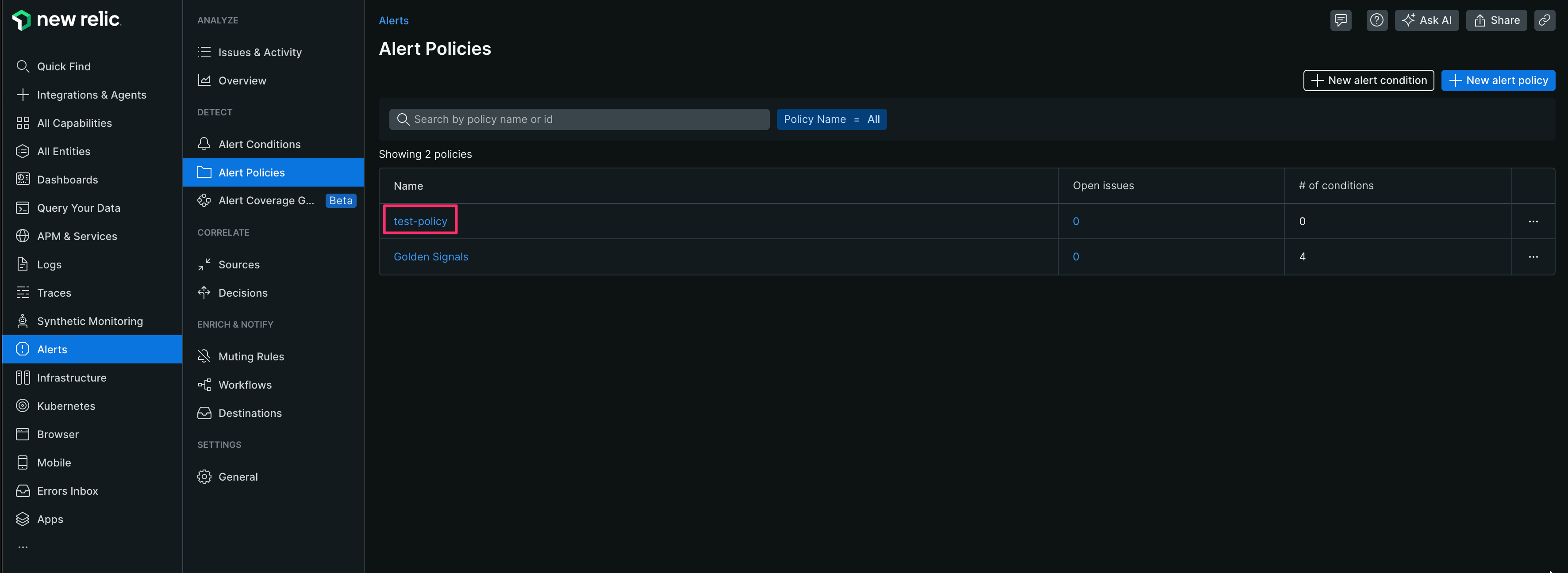
Alert Conditionsの作成
【1】 [Alerts]-[Alert Conditions]-[New alert condition]をクリックする
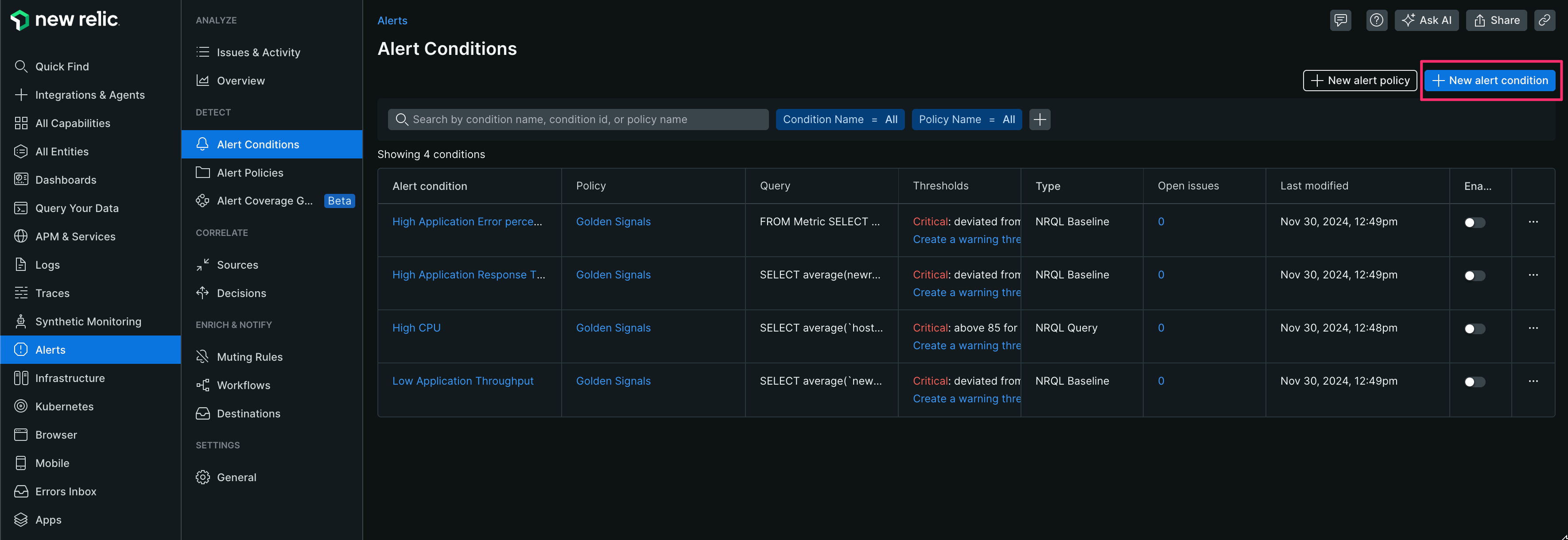
【2】 [Use guided mode]をクリックする
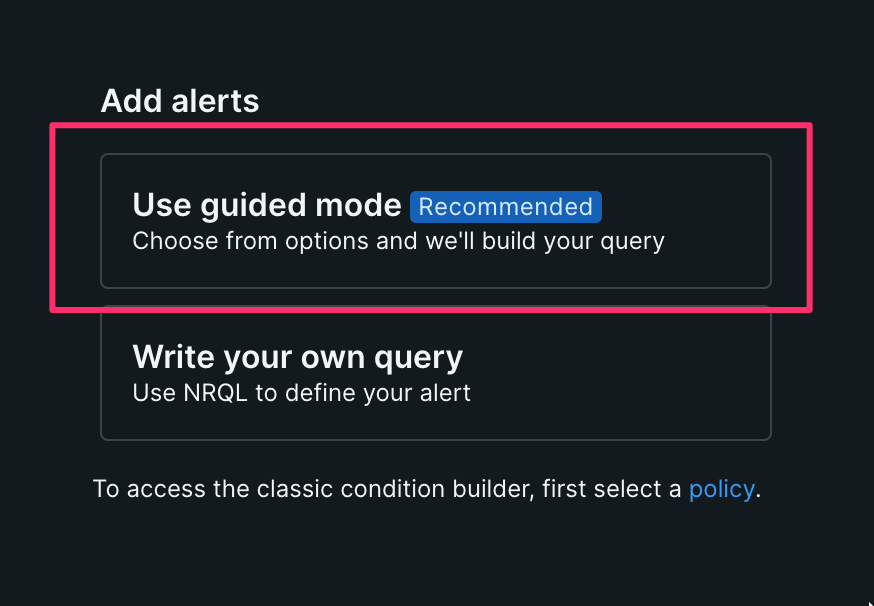
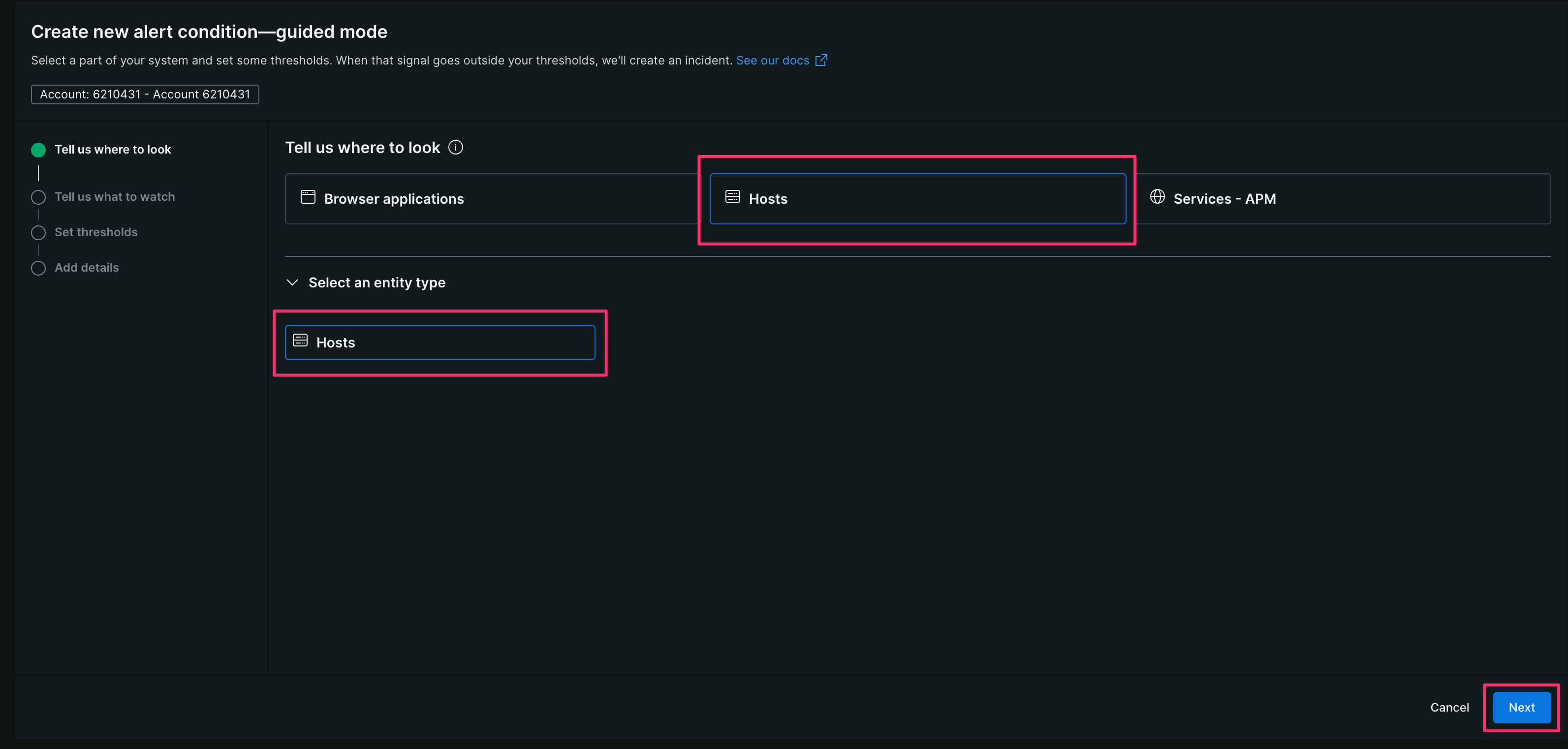
【3】 [Hosts]-[Hosts]を選択し、[Next]をクリックする
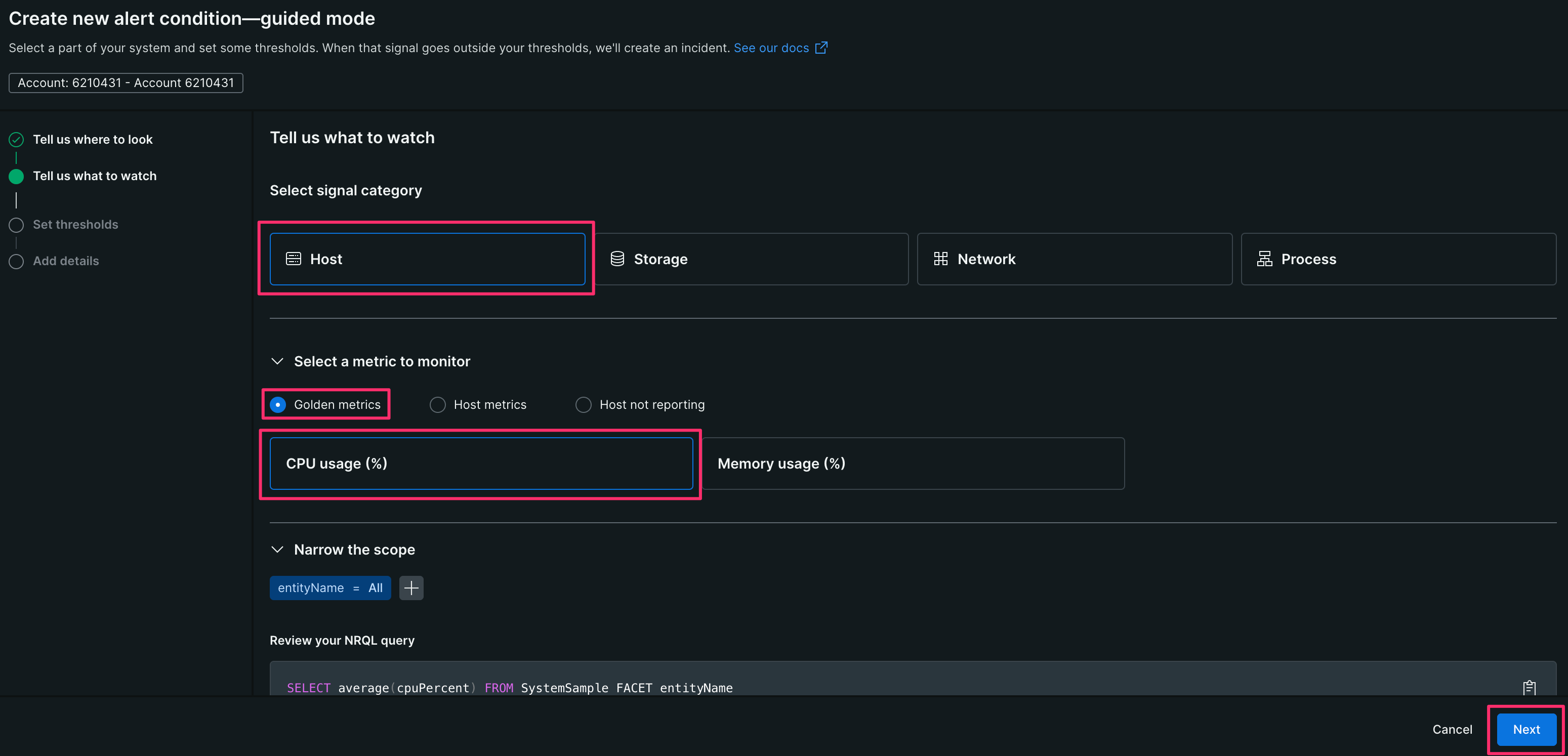
【4】 [Host]-[Golen metrics]-[CPU usage(%)]を選択し、[Next]をクリックする
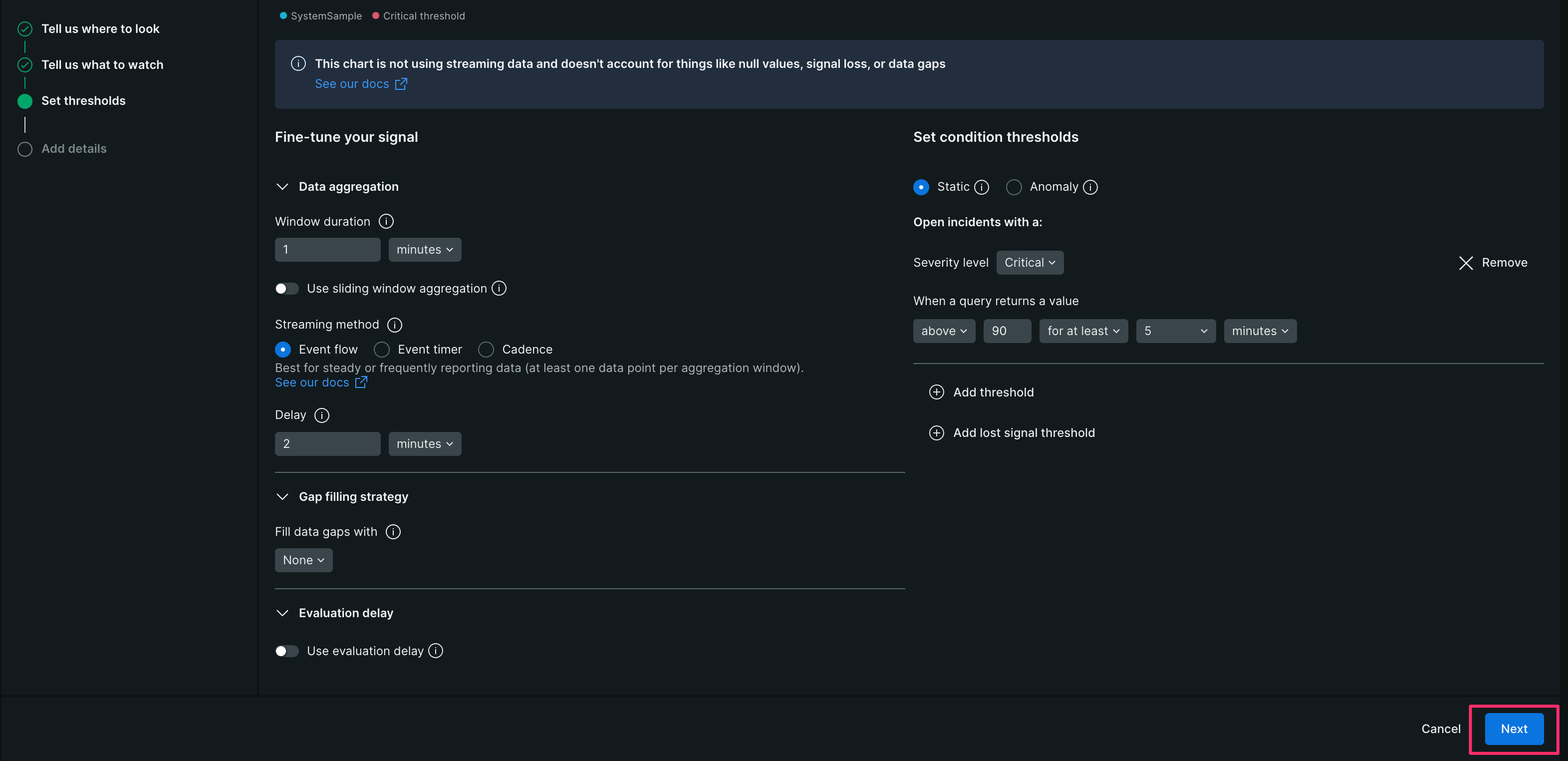
【5】 下記の様に設定し、[Next]をクリックする
- Data aggregation
| 設定項目 | 値 | 備考 |
|---|---|---|
| Window duration | 1 minutes | データを集約する単位 |
| Streaming method | Event flow | 連続データ収集に適した方式 今回のようなインフラストラクチャエージェントを使用した監視でよく使われる |
| Delay | 2 minutes | 設定されたDelay時間後に集計を実行 今回は2分に設定し |
- Gap filling strategy
| 設定項目 | 値 | 備考 |
|---|---|---|
| Fill data gaps with | None | 欠損データの取り扱い定義 今回はNoneを選択 |
- Evaluation delay
| 設定項目 | 値 | 備考 |
|---|---|---|
| Use evaluation delay | 無効化 | 評価遅延 今回は無効化 |
- Set condition thresholds
| 設定項目 | 値 | 備考 |
|---|---|---|
| Static | 選択 | 静的な閾値の超過有無で判定 |
| Open incidents with a: Severity level | Critical | Criticalとしてインシデントを作成する |
| When a query returns a value | above 90 for at least 2 minutes | クエリ結果の値が90以上の状態が2分間継続した場合にインシデントを作成する |
【6】 Name your alert condition(今回はtest-condition-cpuとする)を入力、
Connect this condition to a policy は[Existing policy]を選択し、先ほど作成した「test-policy」を選択する
[Enable on save]を有効化し[Save condition]をクリックする
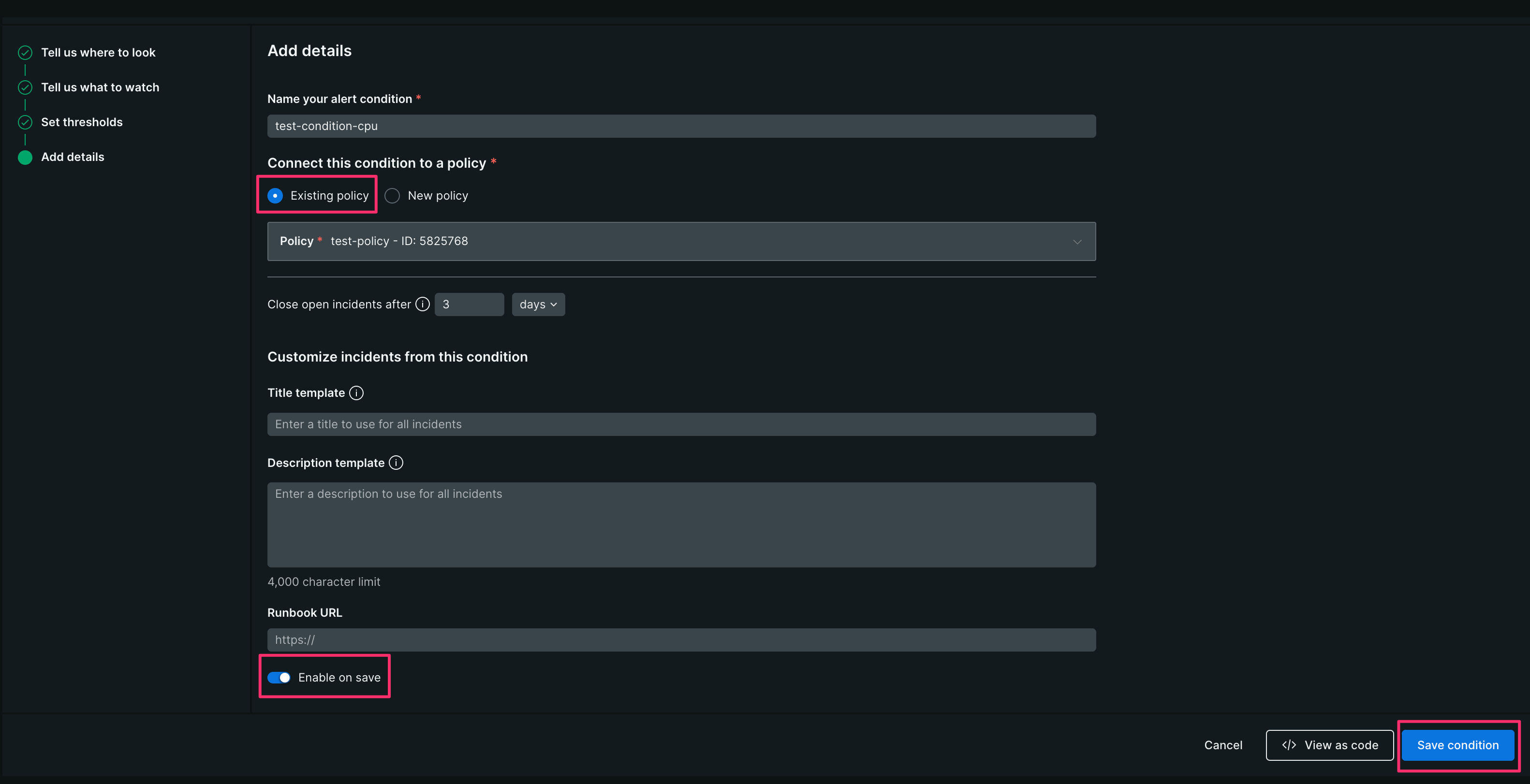
下記のような画面になれば設定完了です
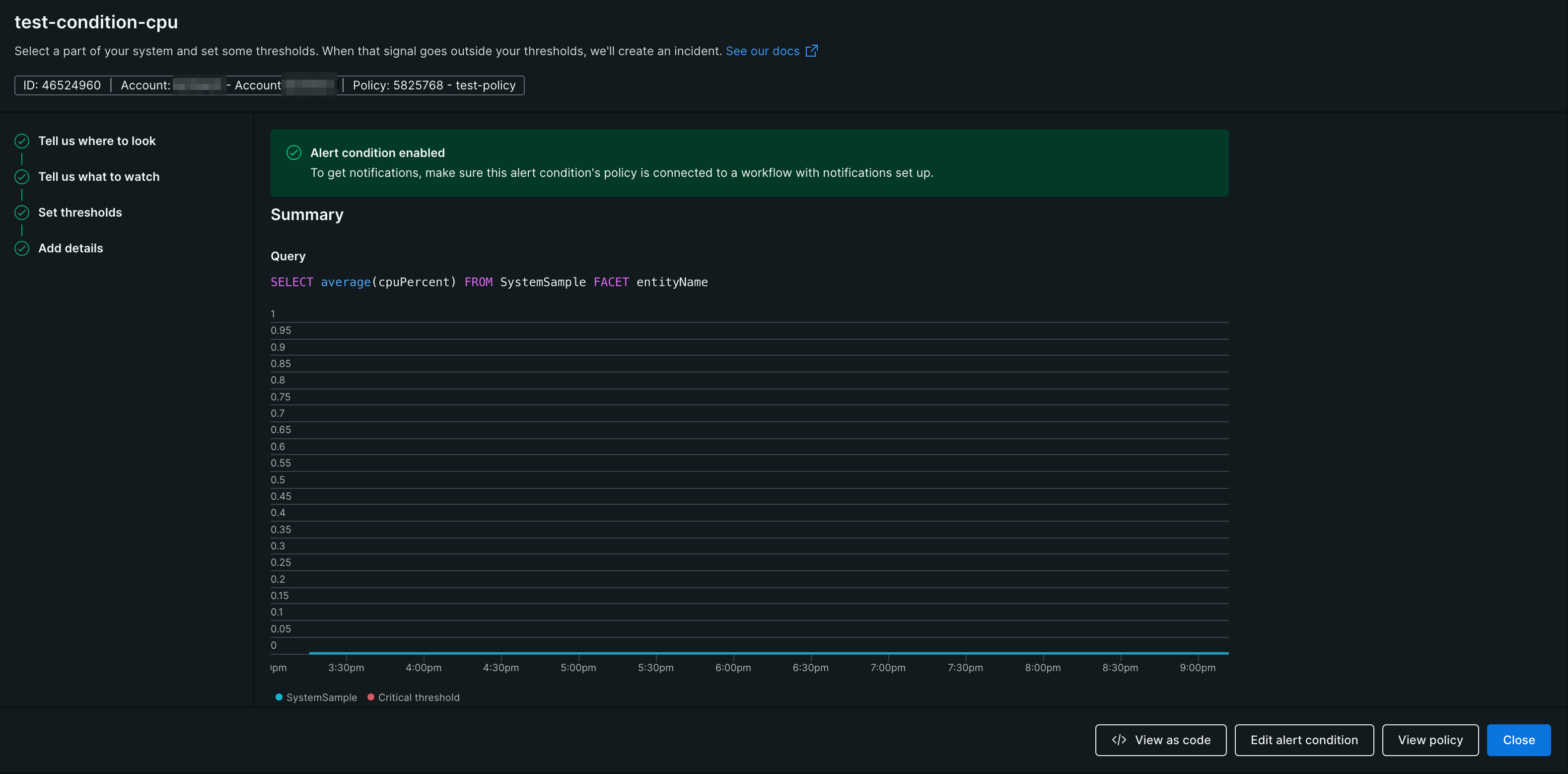
アラートを飛ばしてみよう
Amazon Linux 2023のサーバにログインし、CPU負荷を上げます。
下記を参考にCPU負荷を上げました。
スペックの低いインスタンスタイプで起動したので、すぐにCPUが100%に張り付きました。
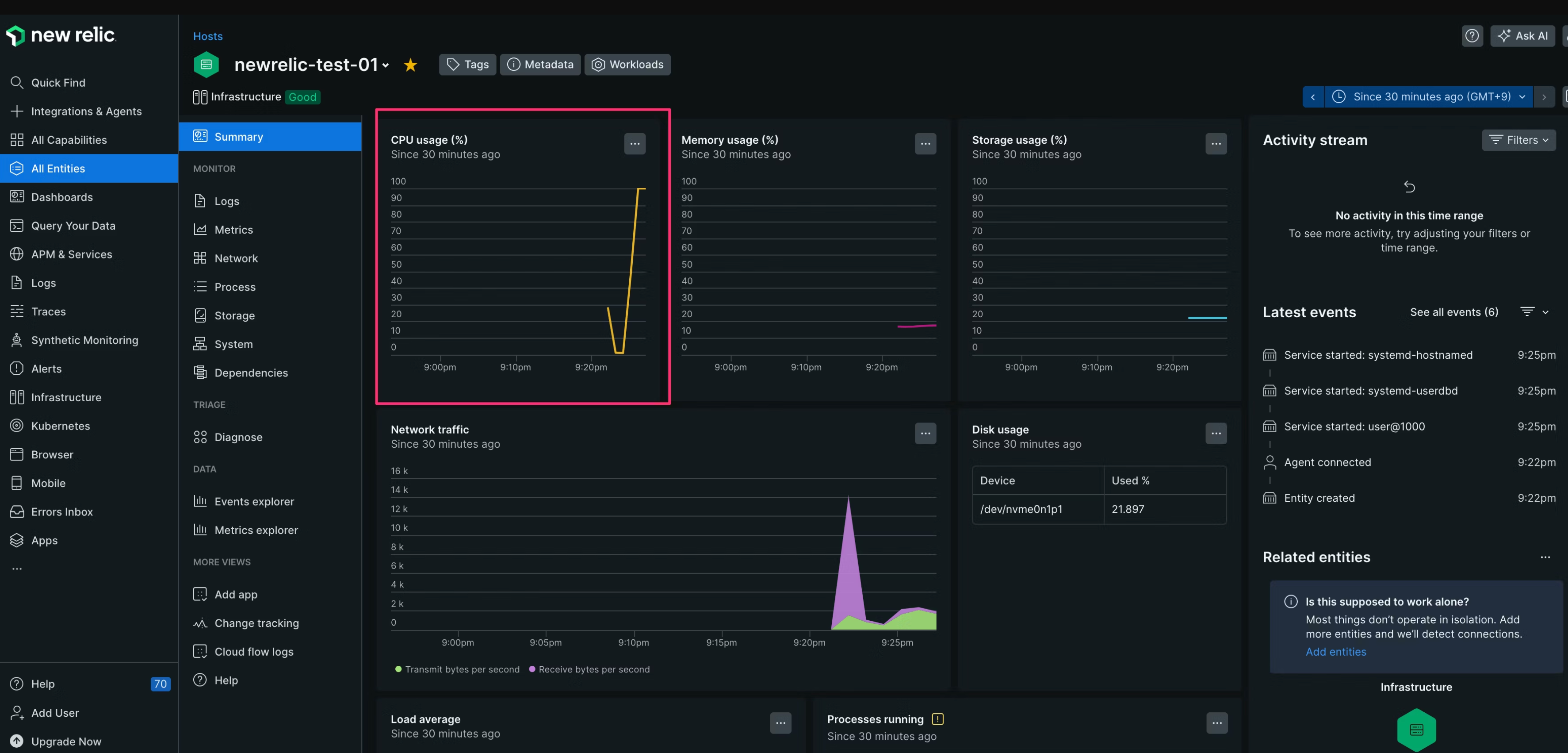
そのまま数分待つと...Slackにアラートの通知が飛んできました!
2回の通知でグラフも表示されており、どのタイミングから負荷が上がっているか分かりやすいですね。
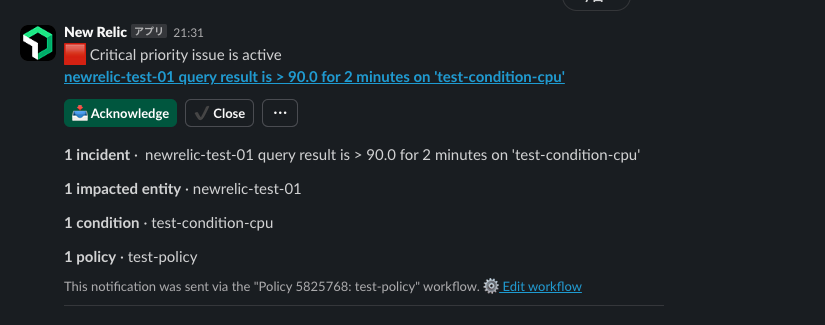
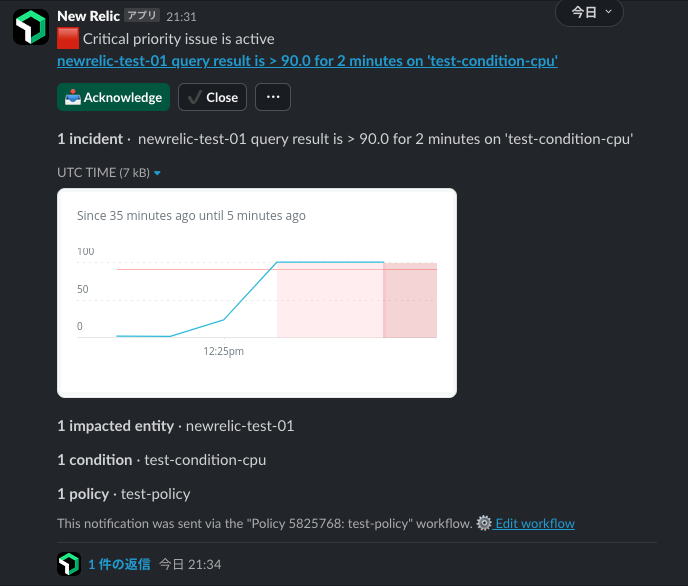
[Acknowledge]をクリックすると以下のページに遷移し、アラートの詳細が表示されました。
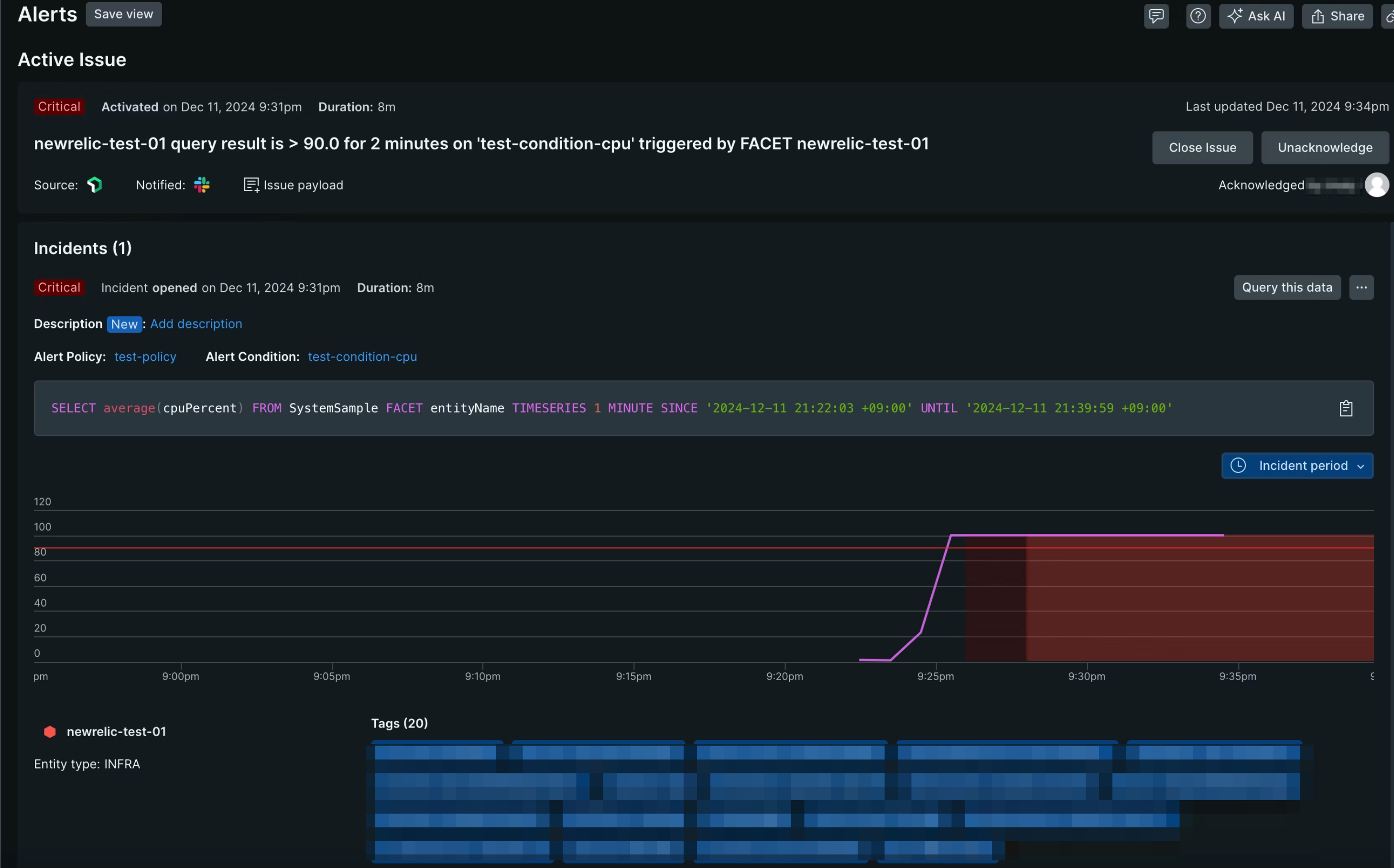
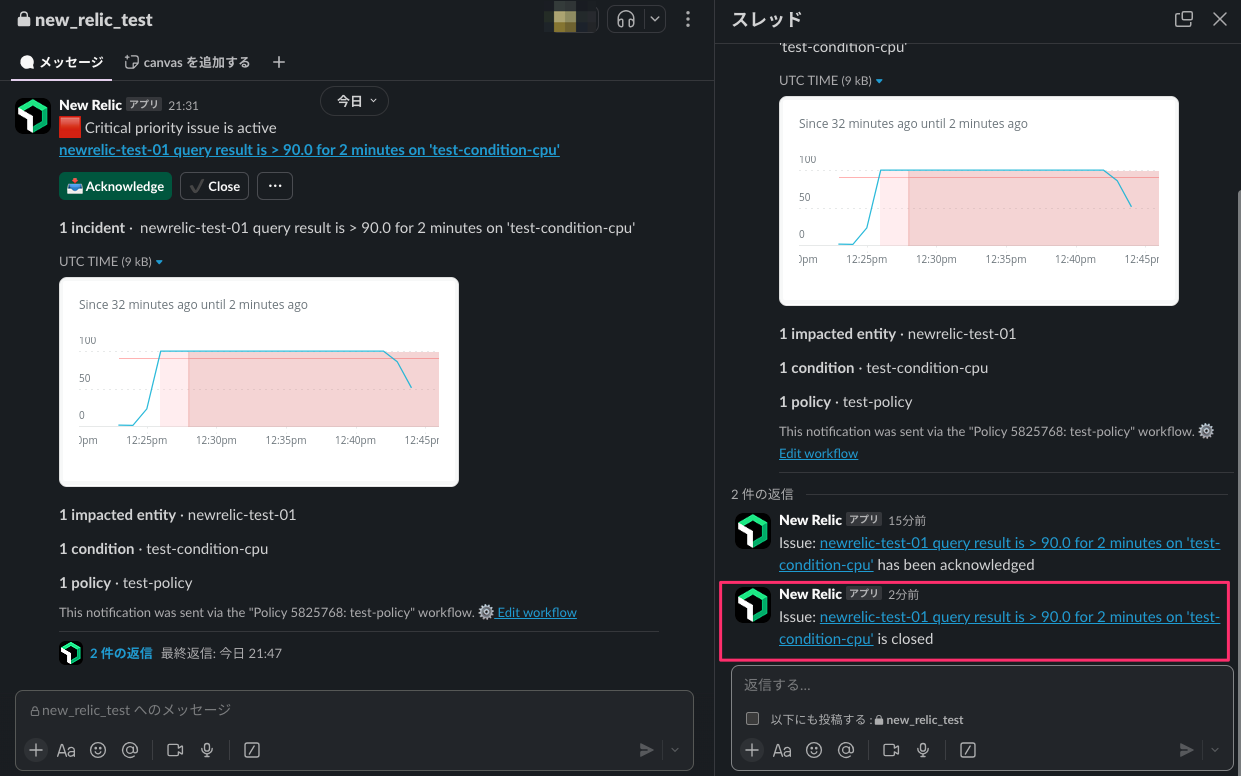
CPUの負荷を解消してみました。
数分後、Closeの通知が来ました!
しかもグラフも更新されて、負荷が解消されていること分かりますね。
まとめ
今回 New Relic を初めて触ってみました。
触れていないところも沢山ありますが、まずどのようなことができるかを、Progateとサーバー監視の観点から試してみました。
Progateでの検証は、New Relic APM とNew Relic Browser を使い、アプリケーションのスループットやエラーを検知・可視化し、パフォーマンス改善をどの様にしたら良いかを学ぶことができました。
個人的には触ってきていなかった分野についてだったので、大変勉強になりました。
導入できればパフォーマンス改善の流れをテンプレート化して、より良いアプリケーションを開発・運用できると感じました。
サーバー監視では、コマンド1行で簡単にエージェントインストールができ監視をスタートできる事と
Slack への通知も行い、実際に通知される内容を確認する事ができました。
通知内容はグラフが画像として表示され、どのように負荷が上がっていったのかが通知一つで確認できるのが良いと思いました。
ダッシュボード(今回は触れませんでしたが)を作成できるので、環境にあったダッシュボードを作成すれば
さらに見やすく、障害時に迅速な対応が可能だと感じました。
本記事が、少しでも皆さんの参考になれば幸いです。