こんにちは。ぺいぺいです。日本語のおけるRAGシステムに使用する良い感じのOSS埋め込みモデルを探していたところ、SB Intuitions さんのテックブログにおけるベンチマークでの比較に辿り着き読ませていただいたところ、どうやらintfloat/multilingual-e5-largeなるモデルが2024年5月時点で日本語検索タスクに適しているとの記述がありました。
そこで今回は、このintfloat/multilingual-e5-largeなるモデルを試してみる and 論文を読んでみることにより内容の理解を試みます。
実際に試してみた
まずは、Hugging face のモデルを使用して軽く試してみることとする。想定している状態としては以下の通り。
- 検索対象となる文字列を複数あらかじめ埋め込みモデルでベクトル化し、保管しておく
- 検索したいクエリを埋め込みコサイン類似度を使用して1で埋め込んだテキストを検索
- クエリに適した回答が返ってくるかを検証
モデル情報
Hugging face の以下のサイトのモデルを使用する。
- モデル:xlm-roberta-large を初期化したモデルを埋め込みモデルとして使用
- 層数:24
- 埋め込み次元数:1024次元
埋め込みに使用するテキストには、以下の規則に基づいて、検索したい文字列に加えてプロンプトを追加する。
- QAタスクにおける検索のような意味的に対称性がないタスクには、クエリの方に'query: 'という文字列を追加し、検索される側に'passage: 'という文字列を加える
- 同じ意味の文章を英語で検索して同じ意味の日本語を返すなどの対称性があるタスクには、クエリ、検索される側共に'query: '文字列を加える
- 単に埋め込みモデルとして使用したい場合は、'query: 'という文字列を埋め込みたいテキストに追加する
なお、今回はQAタスクで使用することを想定する。
環境
- MacOS
- Apple M1 Max
- Python 3.12.3
- VScode + Notebook形式
環境構築は以下のようにtransformersとtorchをinstallするだけ。
pip install transformers
pip install torch
プログラム
まずはライブラリのインポートと関数の定義。それぞれの関数の説明は以下の通り。
- average_pool:埋め込みモデルの最終層の出力を平均して出力された複数のベクトルを一つにする関数
- text_embedding:埋め込みたいテキストのリストを受け取り、それらを埋め込んだ結果のtorch.Tensor 型のオブジェクトを返す関数
- vector_search:検索したいクエリと検索対象の複数の文字列型のリストを受け取り、ベクトル検索を行って、もっともコサイン類似度が大きかった要素を返すための関数
import torch.nn.functional as F
from torch import Tensor
import torch
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
def text_embedding(text: list[str]) -> Tensor:
inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True)
with torch.no_grad():
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
attention_mask = inputs['attention_mask']
embeddings = average_pool(last_hidden_states, attention_mask)
embeddings = F.normalize(embeddings, p=2, dim=1)
return embeddings
def vector_search(query: str, passages: list[str]) -> int:
query_embedding = text_embedding([query])
similarity = F.cosine_similarity(query_embedding, passages).cpu().numpy()
return similarity.argmax()
続いて、検索対象となる文字列を用意し埋め込む。なお、Huggingface の例にあるように、検索対象のテキストには全て'passage: 'という文字列を追加する。埋め込んだモデルはtorchのテンソルクラスオブジェクトとして管理。
answer_list = [
'対策として、水田の水位を上げるのが良いでしょう。水位を上げることで、虫が稲の葉に近づくのを防ぐことができます。',
'トマトの育て方は、日当たりの良い場所に植え、水やりをこまめに行い、支柱を立てて実を支えることが大切です。',
'「鉄コーティング直播栽培」は育苗せず、種籾を鉄粉・焼石膏でコーティングして代かきした水田の表面に機械点播(条に一定の間隔で点状に播種)する栽培方法です。'
]
answer_list = ['passage: ' + answer for answer in answer_list]
embeddings = text_embedding(answer_list)
これで準備が整ったので、実際にクエリを用いて検索を試みる。「鉄コーティング」という農業界隈の専門的な言葉について聞いてみる。
searched_index = vector_search('query: 鉄コーティングとはなんですか?', embeddings)
print(answer_list[searched_index])
すると以下のように鉄コーティングに関する結果を得ることができる。
passage: 「鉄コーティング直播栽培」は育苗せず、種籾を鉄粉・焼石膏でコーティングして代かきした水田の表面に機械点播(条に一定の間隔で点状に播種)する栽培方法です。
論文情報
今回読む論文(というかTechnical Report)はMicrosoft Corporationによってarxivで公開されております。
- タイトル:Multilingual E5 Text Embeddings: A Technical Report
- 著者:Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, Furu Wei
- 組織:Microsoft Corporation
- 公開日:2024年2月8日
概要
- オープンソースモデルである multilingual E5 text embedding models(mE5) の学習手法と評価結果を示したテクニカルレポート
- small, base, large の3つのサイズのモデルが精度と大きさのバランスを考慮して提供
- トレーニング手順はEnglish E5 モデルに準拠しており、10億の多言語テキストペアでの対照的な事前学習とラベル付きデータセットでのファインチューニングで構成
- さらに、インストラクションチューニングを適用した埋め込みモデルも新たに提案
Introduction
モデルの基礎情報
- テキストの埋め込みモデルは、検索機能とLLMの組み合わせた信頼性の高い検索システムであるRAGシステムに重要な要素であるにもかかわらず、ほとんどが英語用のものであり排他的
- この Tech report では、英語用の埋め込みモデルであるEnglish E5を拡張したmE5-[small, base, large]を公開
- mE5の学習はEnglish E5 に準拠し、以下の2段階で構成
- 10億のテキストペアによる弱教師あり事前学習
- 少ないが高品質なラベル付きデータによる教師ありファインチューニング
- インストラクションチューニングを適用したmE5-large-instruct も公開
- インストラクションチューニングにより、タスクに関する詳細情報をモデルに渡すことができるため、より質の高い埋め込み表現を得られる
評価について
- mE5は競争の激しいMTEBベンチマークの英語部分において良い精度を示し、インストラクションチューニングを導入したモデルは英語だけのモデルの精度を上回る
- 多言語への適応脳梁を示すためにMIRACL multilingual retrieval benchmarkを16の言語に対して適用し評価
- またBitext mining (Zweigenbaum et al., 2018; Artetxe and Schwenk, 2019)を100の言語に渡って評価
学習手法
学習プロセスは、事前学習とファインチューニングに分けられる。
弱教師あり事前学習
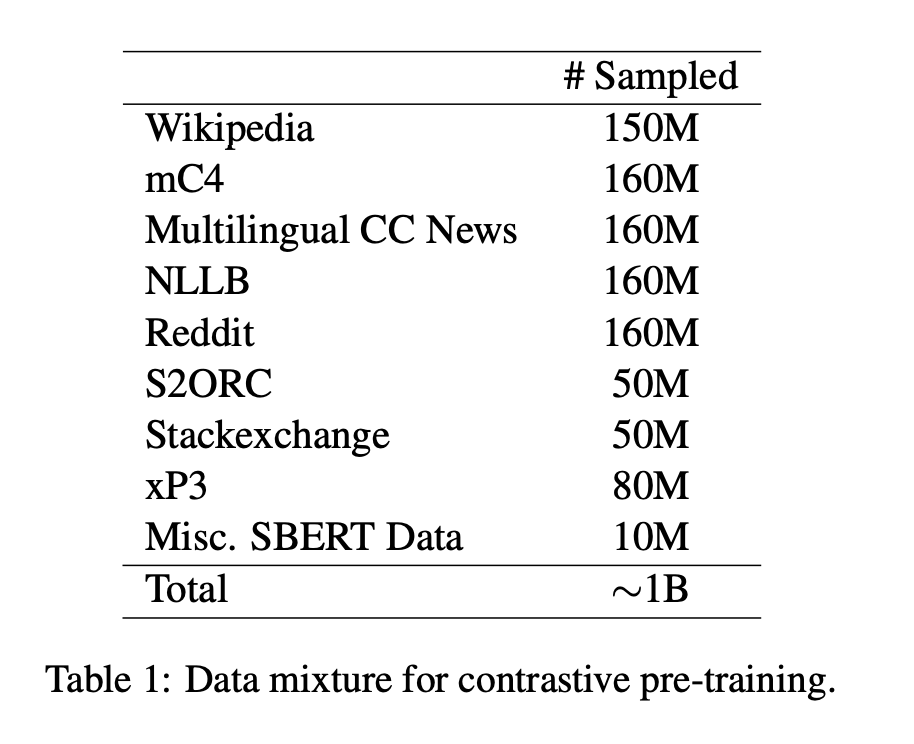
- さまざまな言語のテキストのペアからなる、さまざまなリソースから集められたデータを用いて学習(Table1)
- バッチサイズは32000で30000ステップ学習(約10億のテキストペア)
- InfoNCE contrastive loss をバッチ内の負例に対して使用(InfoNCE contrastive loss については後述)
- ハイパーパラメータはEnglish E5と同じ
InfoNCE Loss は以下のように記述できる。
$$
L = -\text{log}\frac{\text{sim}(q,k_+)/r)}{\text{exp}(\text{sim}(q,k_+)/r) + \sum_{i=1}^{N}\text{exp}(\text{sim}(q,k_i)/r)}
$$
$q$は、ターゲットのクエリ(埋め込み対象のテキスト)
- $k_+$は$q$の近くに埋め込みたい、データセット内でペアとなっている正例テキスト
- $k_i$はバッチ内の$q$とは遠くの位置に埋め込みたいテキスト(バッチサイズは$N$)
- sim はコサイン類似度
- $r$はハイパーパラメータ(温度と呼ばれる)
- クエリと正例との類似度$\text{sim}(q,k_+)$が負例との類似度$\text{sim}(q,k_i)$よりもずっと高い場合、損失値が0になり、そうでない場合、大きくなる
- Contrastive Learningという元々の損失関数では正例と負例の割合は1対1だったが、その条件をもっと厳しくしたものであると考えられる
以下の記事を参考にさせていただきました。
教師ありファインチューニング
教師ありファインチューニングは弱教師あり事前学習の次のステップである。手順は以下の通り。
- 高品質なラベル付きデータセットを用意
- 学習中の負例のサンプルだけでなく、「hard negatives」というモデルが間違いやすい例を学習に加える
- クロスエンコーダーを教師モデルとして知識蒸留を行う
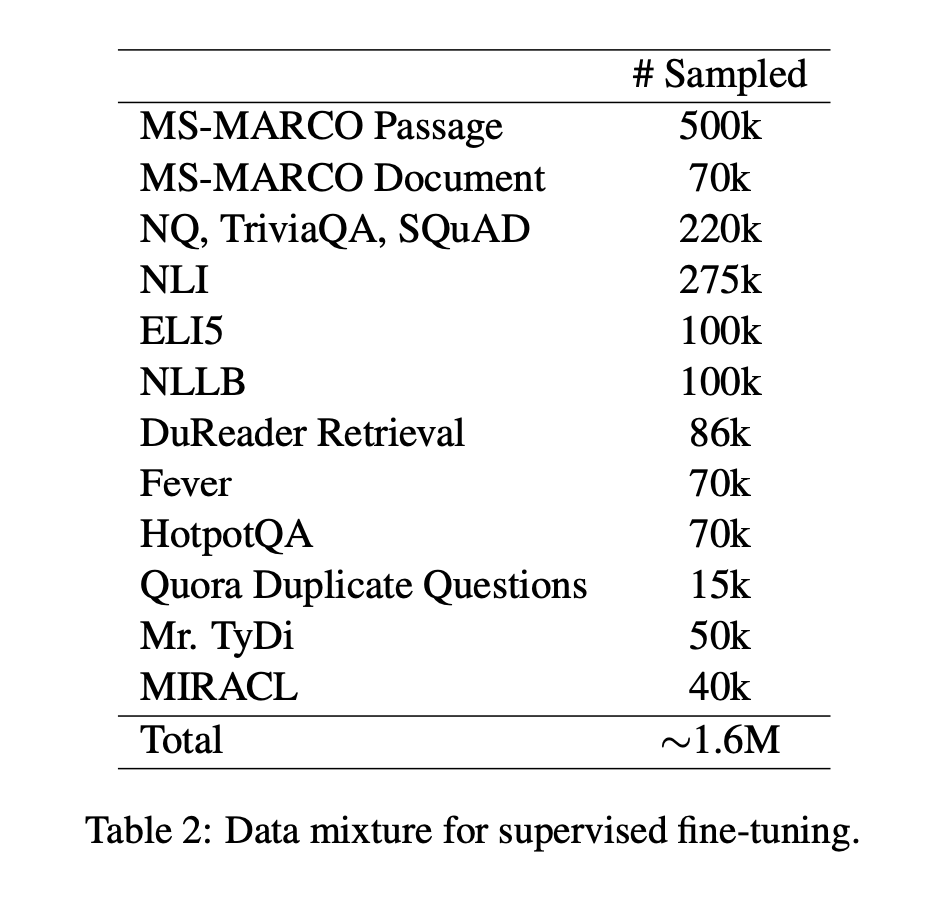
- この段階で使用されるデータセットはTable2の通り
なお、mE5-large-instrct モデルに関しては追加で以下の処理を適用。
- GPT3.5と4から作られた500000の人工データを加えた(Wang et al. (2023))
- この追加人工データは150000のユニークな指示と93の言語が含まれている
- また指示のテンプレートとしてこの人工データを学習および評価に使用
実験の詳細
英語埋め込みベンチマーク
複数言語の埋め込みモデルとはいえ、英語での精度が低くなってはどうしようもないのでまずは英語の埋め込み表現がうまくいっているかを確認。MTEBベンチマーク(2023)を使用して評価。
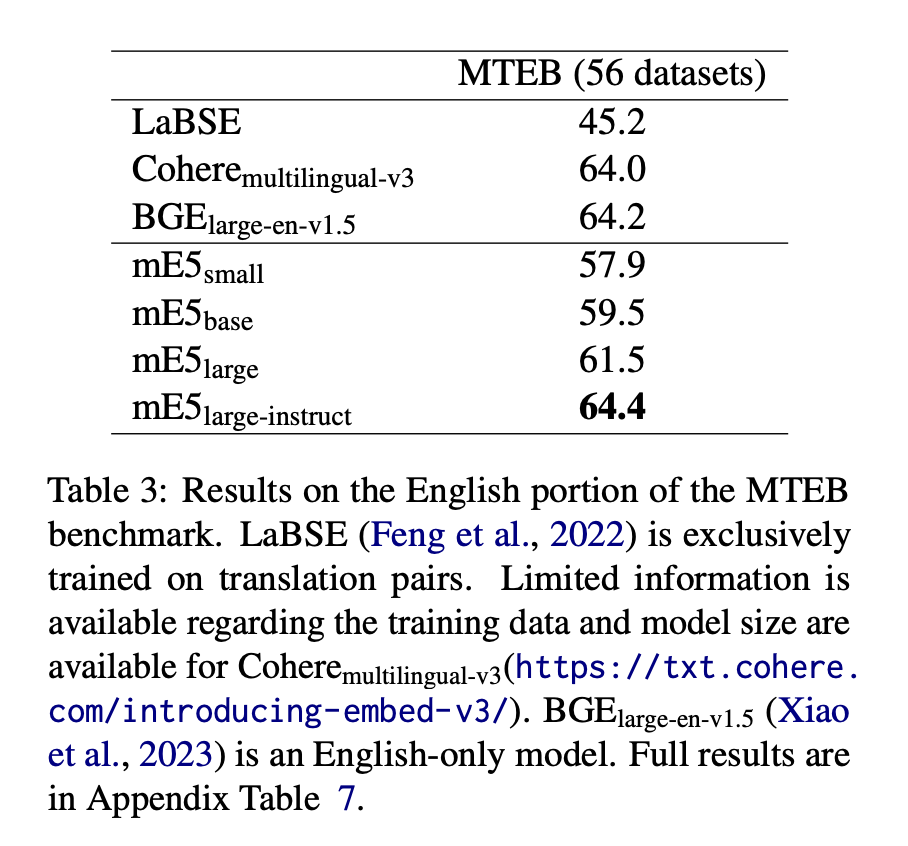
当時の多言語埋め込みモデルSOTAのCohereや英語に特化した埋め込みモデルBCEなども凌駕する結果が得られた。mE5-samll, base は精度で劣ってしまうが計算量の観点から有用であると主張されている。
多言語の検索能力評価
多言語における検索能力の評価を行った。
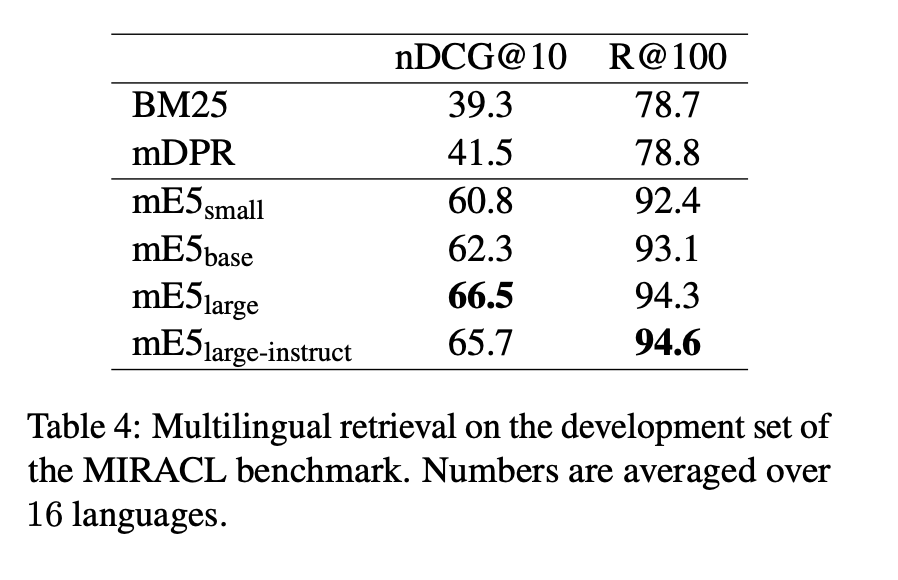
- MiRACLベンチマーク(2023)を使用して評価
- 評価指標:nDCG@10(後ほど記載)、Recall@100(検索上位100件を見て、拾ってくるべき情報をどのくらい拾ってこれているか)
- 結果:mE5は評価対象のmDPRより優れている
- 結果はTable4を参照
- 言語ごとの評価結果はTable6を参照。日本語モデルの評価がやたら高い
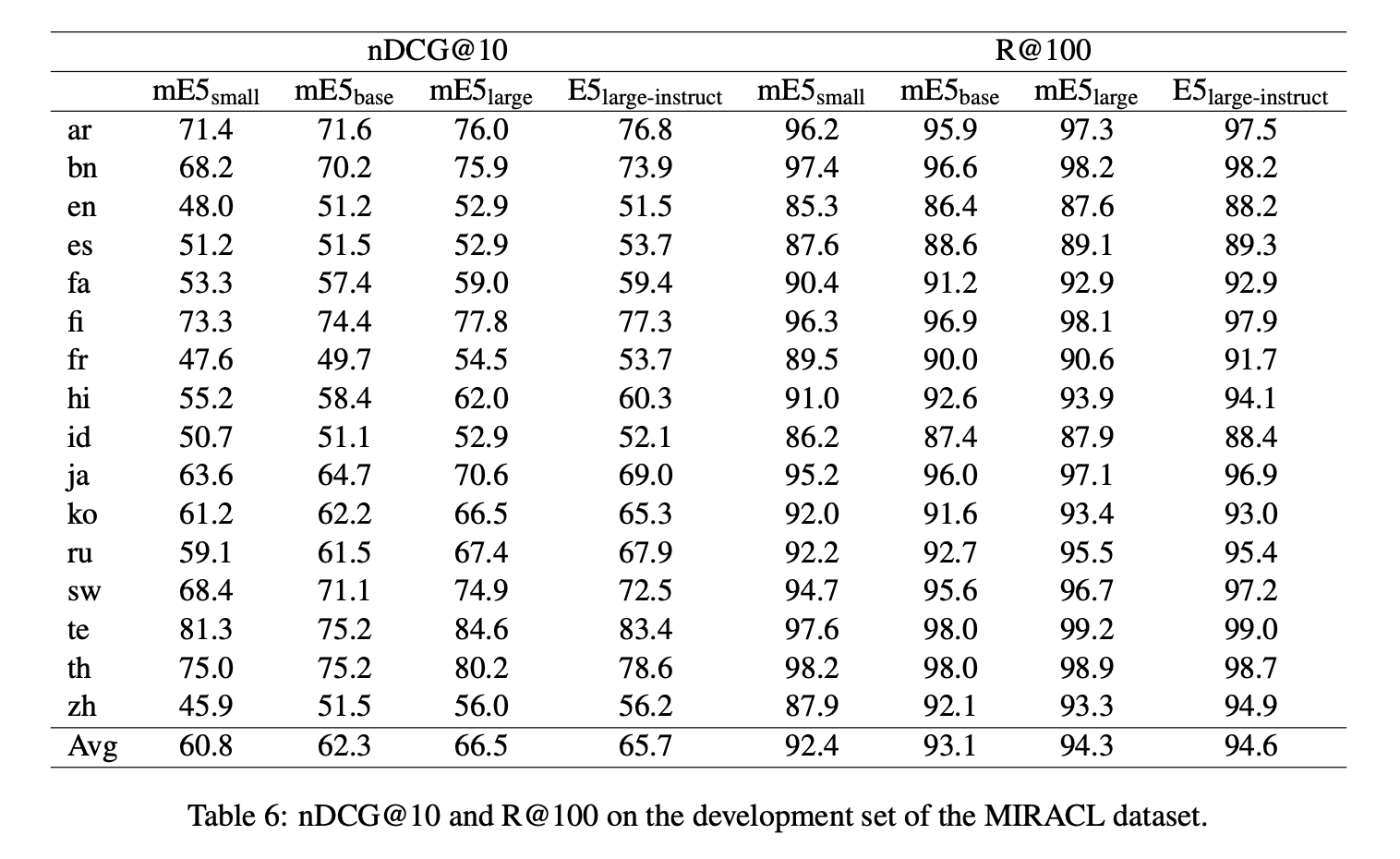
nDCG@10
以下の記事を参考にしてnDCG@10という指標について勉強。
nDCGという指標の前にDCG(Documented Cumulative Gain)という指標があり、以下のように表される。
$$
\text{DCG@k} = \sum_{\pi(i) \le k}\frac{2^{l_i} - 1}{\text{log}(\pi(i) + 1)}
$$
- 大きければ大きいほどよい評価指標
- $k$は考慮する検索結果の上位表示数を意味する。例えば $k=10$ならば検索によりヒットした上位10件についての評価を表す
- $\pi(i)$はモデルが示した文書$i$の順位を意味する。つまり、上記の$\sum_{\pi(i) \le k}$という値は、モデルの検索上位 $k$ 件までの何かを足し合わせることを意味している
- $l_i$は $i$ 番目の文書の関連度の真のスコア(モデルの予測ではない)
- $\pi(i)$が大きいほど分母が小さくなるため、なるべく上の順位のオブジェクトに高い順位をつけるとこの指標は大きくなる
しかしながらこの指標では、タスクやモデルによって、スコアの最大値が異なるため、これを正規化したものがNDCGである。
$$
\text{NDCG@K} = \frac{\text{DCG}@k}{\text{max}_{\pi}\text{DCG}@k}
$$
Bitext Mining
Bitext Mining とは、クロスリンガルな類似性検索タスクの名称である。
- 異なる言語で書かれた文のペア(バイテキスト)を見つけるタスク。共通単語などはほとんどないので意味を理解している必要がある
- mE5 はデータがたくさんある言語から少ない言語まで良い結果を示している
- 特にmE5-large-instruct はbitext mining のために作られたLaBSEを凌駕
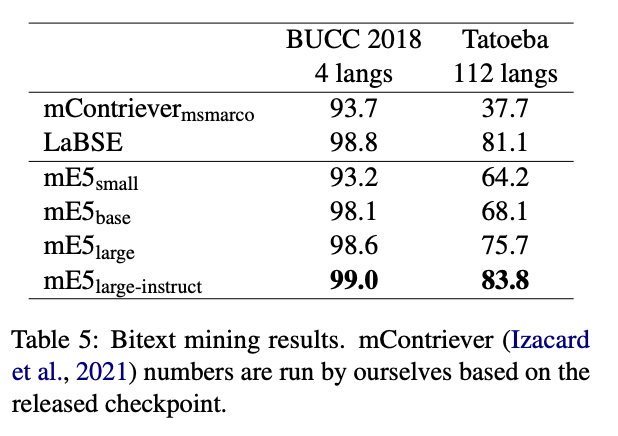
Conclusion
このテクニカルレポートでは、多言語埋め込みモデルであるmE5を提案した。このモデルは情報検索や意味検索、クラスタリングなどのさまざまな言語系タスクにおいて有用である。