本記事では,LlamaIndexでRAGを使用する際の,データ構造に関する情報をまとめます.対象読者は以下の通りです.
- Retriever,Generator,ベクトル検索などのRAGの基礎がなんとなくわかっている方
- Llama indexのチュートリアルをとりあえずやったがデータ形式がいまいちわからない方
- 独自のRAGシステムを作成する際,情報源ファイルに適したRetrieverを作成したい方
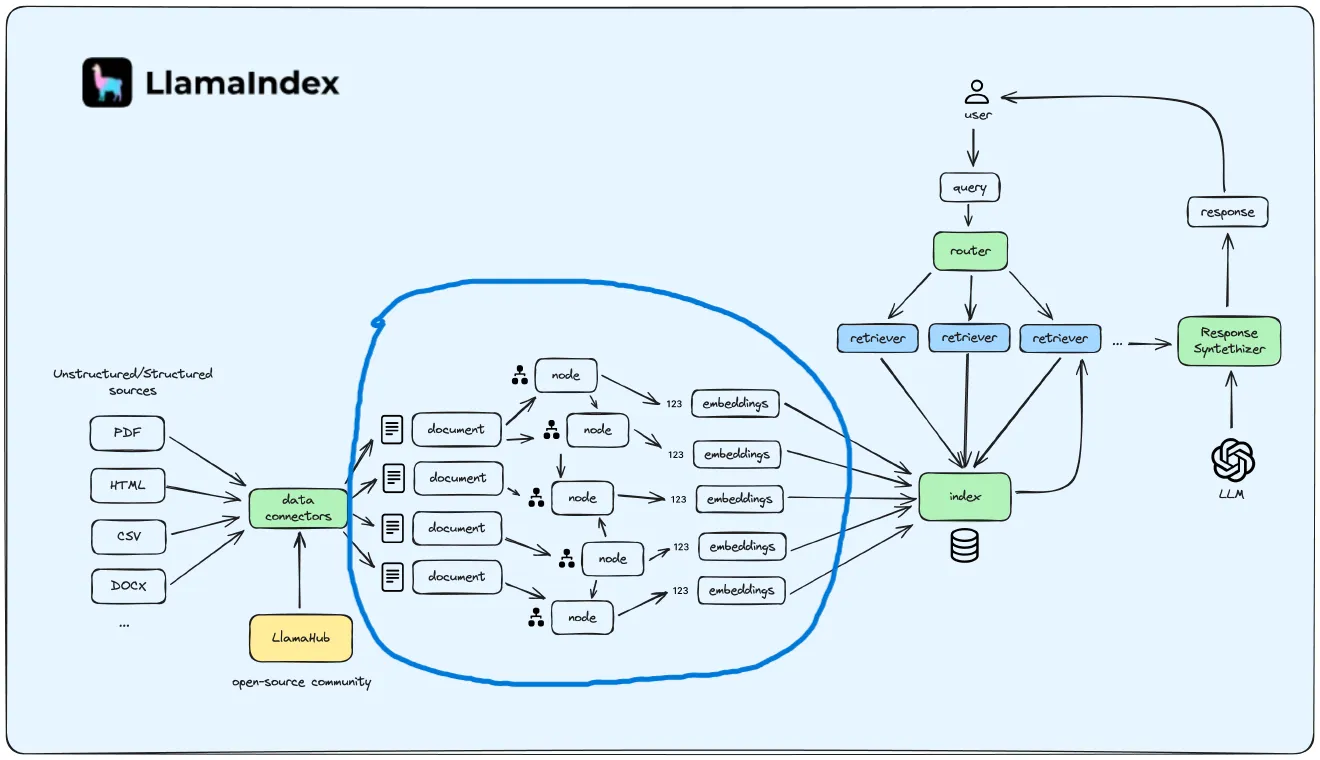
RAGの情報源になるまでの流れ
わかりやすい図を見つけたので,引用させていただきます.

引用元: https://medium.com/@mojo885/llamaindex-saddle-up-and-control-your-llama-5131dde3a1fb
- PDF,Word,Markdownなどさまざまな形式のテキストファイル
- Document:さまざまなファイルからテキストとメタデータを抽出した形式
- Node:Documentを細かくした形式.チャンクと同義
- Embedding:Nodeを埋め込みモデルでベクトル化した形式
- Index:Nodeの集合体
本記事では,これらのデータがどのように変換されていくのかをまとめていきます.
なお,PDFファイルを情報源とする場合を例に挙げます.
データ形式
Document
Documentオブジェクトは,PDFやWordファイルなどのから作成されるオブジェクトであり,以下の要素で構成される.
- テキスト(
text):PDFファイルなどから抽出されたテキスト - ドキュメントID(
doc_id):一つのPDFファイルから多くのドキュメントが作成されるため,その識別子 - メタデータ(
extra_info):PDFファイルのタイトルやページ数,パスなどのメタデータが保存される
つまり,データ検索を行う際にはメタデータをテキスト共に使用することが多くある.特に参照元を表示することの多いRAGでは,メタデータとテキストをまとめて管理することに大きな意味があるのだろう.
該当するクラスをソースコードより抽出する.
class Document(Node):
"""Generic interface for a data document.
This document connects to data sources.
"""
def __init__(self, **data: Any) -> None:
"""Keeps backward compatibility with old 'Document' versions.
If 'text' was passed, store it in 'text_resource'.
If 'doc_id' was passed, store it in 'id_'.
If 'extra_info' was passed, store it in 'metadata'.
"""
if "doc_id" in data:
value = data.pop("doc_id")
if "id_" in data:
msg = "'doc_id' is deprecated and 'id_' will be used instead"
logging.warning(msg)
else:
data["id_"] = value
if "extra_info" in data:
value = data.pop("extra_info")
if "metadata" in data:
msg = "'extra_info' is deprecated and 'metadata' will be used instead"
logging.warning(msg)
else:
data["metadata"] = value
if "text" in data:
text = data.pop("text")
if "text_resource" in data:
text_resource = (
data["text_resource"]
if isinstance(data["text_resource"], MediaResource)
else MediaResource.model_validate(data["text_resource"])
)
if (text_resource.text or "").strip() != text.strip():
msg = (
"'text' is deprecated and 'text_resource' will be used instead"
)
logging.warning(msg)
else:
data["text_resource"] = MediaResource(text=text)
super().__init__(**data)
...
Node
Nodeオブジェクトは,Documentオブジェクトから複数作成されるオブジェクトである.Nodeオブジェクトの特徴は以下の通りである.
- 1Node = 1chunk
- テキストやメタデータで構成される
- Documentオブジェクトのメタデータが継承される
- 他のNodeやIndexとの関係性を保存
イメージとしては,Documnetクラスは1つまるまるのPDFファイルやPDF1ページまるまるなどのある程度まとまったデータを統一するために存在し,NodeクラスはそれぞれがRAGのRetrieverで取得されるアイテムとなる(1Node=1チャンク).つまり,RAGの文脈でよく出てくる「チャンキングアルゴリズムの工夫」はLlama indexの文脈では「DocumentオブジェクトからNodeオブジェクトを作成する際の工夫」と考えることができる.
Nodeオブジェクトを作成する際は以下のように記述する.
from llama_index.core.schema import TextNode, NodeRelationship, RelatedNodeInfo
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
# set relationships
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(
node_id=node2.node_id
)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(
node_id=node1.node_id
)
nodes = [node1, node2]
このようにNodeオブジェクトは,どのNode同士に関連性があるのかを保持している.
Embedding
Embeddingは,Nodeを埋め込みモデルでベクトル化したものである.
1つのNodeから一つのEmbeddingが作成される.
後述のIndexは,複数のNodeで構成されるが,それぞれのNodeはそれぞれの埋め込みベクトルを持つ.
Index
Indexは日本語で索引という意味である.Llama-indexにおけるIndexとは,複数のドキュメントオブジェクト(テキストとメタデータ)から構成されるデータ構造である.ここでは,最も使用頻度の高いVector Indexについてまとめるが,実はTree IndexやKeyword Table Indexなども存在するらしい.以下の図がVector Store Indexのイメージ図である.

Vector Store Index は複数のNodeをまとめたデータ構造である.それぞれのNodeは先ほどまとめた様に,分割されたテキストチャンク,メタデータ,そして埋め込みベクトルを保有している.RAGの情報源としてこのVector Store Index を使用する際は,埋め込まれたクエリと各Nodeの埋め込みベクトルが比較され,関連度の高いNodeが検索に引っかかる.
データの変形に使用する機構
これ以降,PDFファイルからIndexを作成するまでの手順を順々に追っていく.なお,いくつかコードを記載するが,実際にLlama indexを使用する際はもっと抽象化されたメソッドが用意されており,あくまで仕組みの理解のためであることを注意してもらいたい.
PDF → Document

PDFからDocumentオブジェクトを作成する選択肢として,Llama indexでは,PDFReaderクラスというものが存在する.他にもLlama HubというサイトでさまざまなドキュメントReaderが公開されているが,今回はPDFReaderクラスを見てみる.
class PDFReader(BaseReader):
"""PDF parser."""
def __init__(self, return_full_document: Optional[bool] = False) -> None:
"""
Initialize PDFReader.
"""
self.return_full_document = return_full_document
@retry(
stop=stop_after_attempt(RETRY_TIMES),
)
def load_data(
self,
file: Path,
extra_info: Optional[Dict] = None,
fs: Optional[AbstractFileSystem] = None,
) -> List[Document]:
"""Parse file."""
if not isinstance(file, Path):
file = Path(file)
try:
import pypdf
except ImportError:
raise ImportError(
"pypdf is required to read PDF files: `pip install pypdf`"
)
fs = fs or get_default_fs()
with fs.open(str(file), "rb") as fp:
# Load the file in memory if the filesystem is not the default one to avoid
# issues with pypdf
stream = fp if is_default_fs(fs) else io.BytesIO(fp.read())
# Create a PDF object
pdf = pypdf.PdfReader(stream)
# Get the number of pages in the PDF document
num_pages = len(pdf.pages)
docs = []
# This block returns a whole PDF as a single Document
if self.return_full_document:
metadata = {"file_name": file.name}
if extra_info is not None:
metadata.update(extra_info)
# Join text extracted from each page
text = "\n".join(
pdf.pages[page].extract_text() for page in range(num_pages)
)
docs.append(Document(text=text, metadata=metadata))
# This block returns each page of a PDF as its own Document
else:
# Iterate over every page
for page in range(num_pages):
# Extract the text from the page
page_text = pdf.pages[page].extract_text()
page_text = page_text + "\n\n\n"
page_label = pdf.page_labels[page]
metadata = {"page_label": page_label, "file_name": file.name}
if extra_info is not None:
metadata.update(extra_info)
docs.append(Document(text=page_text, metadata=metadata))
return docs
これを見てみると内部的には,pypdfというライブラリを呼び出し,1ページずつDocumentオブジェクトを作成するか,PDFの全てのページを一つのドキュメントにするかを引数のreturn_full_documentによって選ぶことができる.いずれにせよ,Documentクラスのリストを返す.
また,以下のようにカスタマイズすることで,自分の所望のセパレーター("\n\n\n"とか...)をtextに追加することができ,のちのTextSplitterと合わせて使うことで,好きな箇所でチャンクを分割することができると考えられる.
test = text + "好きなセパレータ"
Document(text=text, metadata=metadata)
Document → Node
DocumentからNodeを作成する際,以下の手順が必要になる.
- DocumentのTextSplitterによるチャンク化
- チャンクからNodeを作成
TextSplitterとは,指定したルールに従ってテキストを分割するためのオブジェクトである.例えば,「##」や「.」でテキストを分割するなどのルールをユーザー側が指定できる.チャンキングのルールを独自にカスタマイズしたい場合は,TextSplitterをカスタマイズすることになる.
Documentオブジェクトからテキストチャンクを作るには,以下の様な処理が行われる.
from llama_index.core.node_parser import SentenceSplitter
text_parser = SentenceSplitter(
chunk_size=1024,
# separator=" ",
)
text_chunks = []
# maintain relationship with source doc index, to help inject doc metadata in (3)
doc_idxs = []
for doc_idx, page in enumerate(doc):
page_text = page.get_text("text")
cur_text_chunks = text_parser.split_text(page_text)
text_chunks.extend(cur_text_chunks)
doc_idxs.extend([doc_idx] * len(cur_text_chunks))
Node → Embedding
ここでは,OpenAIの公開している埋め込みモデルによる埋め込みを示す.各Nodeオブジェクトに,テキストを埋め込んだベクトルを格納していることがわかる.
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding()
for node in nodes:
node_embedding = embed_model.get_text_embedding(
node.get_content(metadata_mode="all")
)
node.embedding = node_embedding
Embedding → Index
これまでの処理で,Nodeは,テキスト,メタデータ,埋め込みベクトルを保有しているので,あとはVector_storeに渡すだけで,Vector Store Index の完成である.
vector_store.add(nodes)
なお,これらの処理を抽象化して,ドキュメントのリストからインデックスを一撃で作成するには,以下のように記述する.ついでに,RAGによる質問に対する回答が得られる例も掲載する.
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# ドキュメントを読み込む
documents = SimpleDirectoryReader("./data/paul_graham/").load_data()
# インデックスを作成
index = VectorStoreIndex.from_documents(documents)
# クエリエンジンを作成
query_engine = index.as_query_engine()
# クエリを実行
response = query_engine.query("What did the author do growing up?")
print(response)
まとめ
ここまで読んでいただきありがとうございました.簡単なRAGシステムを作ってみるだけなら,最後の抽象化された5行だけで良いのですが,正確な出力を求めるほど,データ構造に関する知識やチャンキングに関する知識が必要とされる傾向があったので,一度勉強も兼ねてまとめてみました.
参考資料