はじめに
後輩君と、「テーブル設計でFLOAT型を(思考停止で)使用してはいけない」みたいなことを話す機会がありました。
説明のためにテスト環境を作ったりして頑張りましたし、せっかくなので記事を書いて共有しようと思います。
参考図書

超オススメです。ただし、中級者向けなので、基本的なSQL構文やRDBについて勉強してから取り組むのがよいと思います。
FLOAT型を使うと、計算結果に誤差が発生する
FLOAT型(浮動小数点型)をむやみに使用してはいけない理由は、計算結果に誤差が発生するからです。
論より証拠、FLOAT型を使用した数値計算を実施してみます。
以下のようなテーブルを作成し、データを入力します。
CREATE TABLE worker_cost(
name VARCHAR(10) PRIMARY KEY, --社員の名前
work_hour FLOAT NOT NULL, --社員が月に働いた時間(H)
hourly_wage FLOAT NOT NULL --社員の人件費(円/時)
)
 1.佐藤さんが1か月間に働いた時間
2.佐藤さんを1時間雇うのに必要な金額
になります。(※時給ではなく、人件費なので、算出方法によっては小数になったりします)。
1.佐藤さんが1か月間に働いた時間
2.佐藤さんを1時間雇うのに必要な金額
になります。(※時給ではなく、人件費なので、算出方法によっては小数になったりします)。
以下のクエリを実行して、佐藤さんを1か月雇うのに必要な金額を計算します。
SELECT name, work_hour * hourly_wage AS '人件費(円/月)' FROM worker_cost; --稼働時間×人件費(時)
結果は以下の通り。なんか、小数点以下がすっごいことになっています。
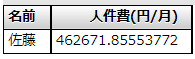
ちなみに、電卓で計算したところ、結果は以下のようになりました。
SQLでの計算で、微妙に誤差が発生しているようです。

今回の誤差は大体0.03円程度ですが、社員数がたくさんいて、それらの人件費を合計する場合などでは、誤差が積みあがって、全体で大きな誤差になってしまうかもしれません。
なぜ誤差が発生するのか
いわゆる丸め誤差が原因です。
丸め誤差とは、長い桁や無限桁の小数を扱う際に、これを有限桁で表すためにある桁以降の値を捨ててしまうことにより生じる誤差のこと。コンピュータでは浮動小数点型の数値計算などで現れる
引用元:e-words/丸め誤差
要するに、長い小数を途中で打ち切ることで発生してしまう誤差ということですね。
あれ!?でも、サンプルデータでは、小数点以下1桁でしか計算してないやん??
実は、有限の小数を扱う場合でも、丸め誤差が発生してしまう場合があります(というか、だいたい発生します)。
それは、10進数で有限の小数でも、2進数に変換すると無限小数になってしまう場合があるからです。
2進数への変換により、無限小数になってしまう
例えば、"59.95"という数字があります。当たり前ですが、有限精度(小数点以下2桁)で表現できます。
これを2進数に変換すると、以下のようになります。

このサイトを利用しました:CMAN.jp
無限小数になってしまいました。また、無限小数が途中で打ち切られているため、再び10進数に変換しても、"59.95"を復元することはできません。
当然ですが、コンピュータの世界では、数値は2進数で扱われます。
有限小数"59.95"は、DBで扱われる際に2進数に変換され、適当なところで打ち切られてしまったのです。
ちなみに、RDBMSのツール上では、「見た目上は」10進数のときの精度が保たれているように見えます。
しかしながら、内部では丸め誤差が発生しています。これは、例えば以下のようなクエリを実行すれば、簡単に確かめられます。
SELECT * FROM worker_cost WHERE work_hour = '180.4'; --稼働時間が'180.4'のレコードを探す
稼動時間=180.4でレコードを検索しても、佐藤さんのレコードはヒットしません。これは、DBの内部では、稼動時間が'180.4'になっていないからです。
じゃあどうすればいいの?? ⇒ DECIMAL型を使おう!
MySQLではDECIMAL型やNUMELIC型といった"固定小数点型"が用意されています(他のRDBMSにもあると思います。調べてないけど)。
固定小数点型では、データが必要とする精度(小数点以下何桁必要か)をあらかじめ定義しておくことで、その範囲内でデータの精度を保証することができます。範囲外のデータを入れようとすると、エラーになります。
RDBでは、基本的にデータの信頼性が重要な場合が多いので、非常に有効だと思います。
一方、固定小数点型には、(1)扱える数値の範囲が狭い(2)パフォーマンスが悪い、という欠点があります。故に、アプリケーションなどではあまり使用されない印象です。どうしても精度が欲しいときだけですかね。。私は使用したことがないです。
<参考>浮動小数点と固定小数点の違いについては、以下の記事が分かりやすかったです。
Qiita:float型では123456789すらも表現できない話
FLOAT型とDECIMAL型を比べてみた
以下のようにテーブルを定義しなおし、データを入れてみました。
DECIMAL型は、DECIMAL('全体の桁数', '小数点以下の桁数') という感じで宣言します。
CREATE TABLE worker_cost(
name VARCHAR(10) PRIMARY KEY, --社員の名前
work_hour_fl FLOAT NOT NULL, --社員が月に働いた時間(H) FLOAT型
hourly_wage_fl FLOAT NOT NULL --社員の人件費(円/時) FLOAT型
work_hour_de DECIMAL(5,1) NOT NULL, --社員が月に働いた時間(H) DECIMAL型
hourly_wage_de DECIMAL(4,1) NOT NULL --社員の人件費(円/時) DECIMAL型
)
 FLOATとDECIMALでそれぞれカラムを用意して、まったく同じ値を格納しました。
このデータをもとに、2種類の型それぞれで、佐藤さんの月当たりの人件費を計算します。
FLOATとDECIMALでそれぞれカラムを用意して、まったく同じ値を格納しました。
このデータをもとに、2種類の型それぞれで、佐藤さんの月当たりの人件費を計算します。
 **DECIMALのほうは、電卓と計算結果が一致しています。素晴らしい!**
**DECIMALのほうは、電卓と計算結果が一致しています。素晴らしい!**
また、以下のクエリも、DECIMAL型に対してであればちゃんとヒットします。
SELECT * FROM worker_cost WHERE work_hour_de= '180.4'; --稼働時間が'180.4'のレコードを探す
FLOAT型を使用しなければいけない場合は無いの??
1.DECIMAL型でサポートされている桁数以上の数値を扱いたい場合
DECIMALの弱点は、扱える数値の桁数がFLOATよりも小さいことです。
DECIMALでは、小数点以下30桁まで、全体の桁数65桁まで指定することができます。これより桁数が多い小数を扱いたい場合は、浮動小数点型を使用する必要があります。
とはいえ、ほどんどの場合ではDECIMALでサポートされる精度で十分だと思います。
2.テーブル設計の際に、必要な小数の精度が決められない場合
そんな状況が発生するかはわかりませんが・・。FLOAT型なら、テーブル設計時にデータの桁数を指定する必要はありません。
まとめ
RDBで小数を扱う場合は、なるべくDECIMAL型を使用しましょう、という話でした。
「現状のデータの使い方だと、多少の誤差は問題にならない」みたい場合なもあるかもしれません。
しかしながら、未来のことまで視野を広げると、今後予想外のデータの使われ方をすることで、誤差が原因のトラブルが発生してしまうかもしれません。
アプリ側に気を遣わせないように、データベースではデータの精度をできるだけ保つべきだというのが、個人的な意見です。
データベース上では誤差のないようにデータを保管しておき、データを扱うアプリケーション側で、必要な精度で計算をする、というのが、わかりやすくて良い状態なのかなと(個人的には)思います。