前回までのあらすじ
この春から高校に通うべく新しい街にやってきたココア。道に迷って偶然に喫茶ラビットハウスに入るが、実はそこが彼女が住み込むことになっていた喫茶店だった。ラビットハウスの一人娘・チノ、アルバイトのリゼともすぐ打ち解け、ココアの賑やかな新生活が始まる。

ていう感じの文章作りたいよねって話
前回の投稿でWord2Vecモデルを作ったので、今回はseq2seqで文章生成でもしてみようかなと思います。
目標は、「ご注文はうさぎですか?」をモデルに入力すると、冒頭のようなカンジの文章が生成されることです。
seq2seqモデルの構成
- 入力は単語ベクトル (200次元)
- タイトルを入力するとあらすじを出力する
- kerasで実装する
というモデルを作っていこうかなと思います。
ざっとコードはこんな感じになりました。
from keras.models import Sequential, Model
from keras.layers.core import Dense, Activation, Flatten
from keras.layers.recurrent import LSTM
from keras.optimizers import Adam
from keras.layers import Input, Dropout, BatchNormalization, Embedding, Masking
from keras.initializers import glorot_uniform
from keras.initializers import uniform
from keras.initializers import Orthogonal
from keras.initializers import he_normal
from keras.initializers import TruncatedNormal
class seq2seq_model(object):
def __init__(self, vocab_size,
lstm_units,
vec_size):
#w2vモデルの語彙数
self.vocab_size = vocab_size
#単語ベクトルの次元
self.vec_size = vec_size
self.lstm_units = lstm_units
self.model_learn, self.model_encode, self.model_decode = self.init_model()
def init_model(self):
encoder_inputs = Input(shape=(None, self.vec_size), name='encoder_input')#単語ベクトル
decoder_inputs = Input(shape=(None, self.vec_size), name='decoder_input')#単語ベクトル
e_lstm1 = LSTM(self.lstm_units,
return_sequences=True,
return_state=True,
kernel_initializer=glorot_uniform(),
recurrent_initializer=Orthogonal(gain=1.0),
name='encoder_lstm_layer1'
)
encoder_output1, state_h1, state_c1 = e_lstm1(encoder_inputs)
#encoderの状態を保持しておく
#state_h:隠れ状態, state_c:セル状態
encoder_states = [state_h1, state_c1]
d_lstm1 = LSTM(self.lstm_units,
return_sequences=True,
return_state=True,
kernel_initializer=glorot_uniform(),
recurrent_initializer=Orthogonal(gain=1.0),
name='decoder_lstm_layer1'
)
decoder_outputs1, _, _ = d_lstm1(decoder_inputs,
initial_state=encoder_states#初期状態をencoderの状態にする
)
decoder_dense = Dense(self.vocab_size,
activation='softmax',
name='output_vector'
)
decoder_outputs = decoder_dense(decoder_outputs1)
#学習用のモデルをコンパイルする
model_for_learn = Model(inputs=[encoder_inputs, decoder_inputs], outputs=[decoder_outputs])
#カテゴリラベルが整数の場合は、sparse_categorical_crossentropyが使える
model_for_learn.compile(optimizer=Adam(), loss='sparse_categorical_crossentropy')
#デコード用モデルを定義していく
encoder_model = Model(encoder_inputs, encoder_states)
decoder_state_input_h = Input(shape=(self.lstm_units, ))
decoder_state_input_c = Input(shape=(self.lstm_units, ))
decoder_state_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = d_lstm1(decoder_inputs,
initial_state=decoder_state_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model([decoder_inputs] + decoder_state_inputs,
[decoder_outputs] + decoder_states)
decoder_model.compile(optimizer=Adam(), loss='sparse_categorical_crossentropy')
return model_for_learn, encoder_model, decoder_model
def train(self, x_train, y_train,
epochs, batch_size):
return self.model_for_learn
モデルの構成はこんなかんじになってます。
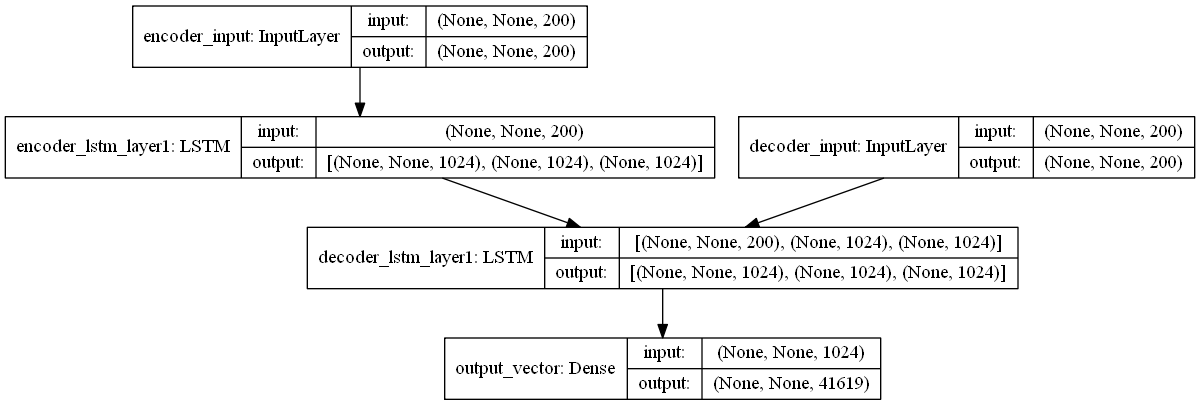
encoder_inputには、文字列を単語ベクトルに変換した系列が入ります。たとえば、「ご注文はうさぎですか?」という文字列の場合、
- ['ご', '注文', 'は', 'うさぎ', 'です', 'か', '?']と分割する
- リストの各語を単語ベクトルに変換する
- 2.の単語ベクトルリストを適切なshapeに整形する
というステップを踏みます。Input shapeを見ると、(None, None, 200) となっていますが、これは(バッチサイズ, 系列長, 単語ベクトル次元)という意味です。系列長がNoneになっているのは、入力される文字列の長さが不定だからです。「私に天使が舞い降りた!」でも良いわけです。
decoder_inputには、こんな感じで系列が入力されていきます。

推論時には、から始まって、1つ前に自分が出力した単語を再び次の入力とすることを繰り返していきます。こうすることで、いくらでも長い系列を出力することができるわけです。

学習させてみる
from tqdm.notebook import tqdm
import random
model = seq2seq_model(vocab_size=len(index2word),
lstm_units=1024,
vec_size=200
)
epochs = 10
index = [idx for idx in range(len(y_train))]
losses = []
data_size = len(y_train)
for epoch in range(epochs):
count=0
random.shuffle(index)
losses = []
for idx in tqdm(index):
count += 1
x_vec = x_train_vec[idx]
y = y_train[idx]
y_vec = y_train_vec[idx]
hist = model.fit([x_vec[:, ::-1, :], y_vec[:, ::-1, :]],#入力を反転させる
y,
epochs=1,verbose=0)
losses.append(hist.history['loss'][0])
if count==data_size):
mean = sum(losses)/len(losses)
print(f'episode_mean_loss: {mean}')
ミニバッチ学習でないので、ものすごく時間がかかります。ミニバッチ学習したいなら、同じミニバッチ内で系列長を揃えるように、パディングする必要があります (そのへんの話もいつかできたらよいかも)。
文章生成する
いよいよ文章生成していきます。さきほど訓練したモデルをh5ファイルかなにかで保存しておいて、ロードします。このとき、モデルのエンコーダ部分とデコーダ部分を分けるようにします。
from keras.models import load_model
from keras.models import Model
from keras.layers import Input, LSTM, Dense
def seq2seq_model(path):
model = load_model(path)
encoder_model = Model(inputs=model.input[0],
outputs=model.get_layer('encoder_lstm_layer1').output[1:])
lstm_units = encoder_model.outputs[0].shape[1]
decoder_inputs = Input(shape=(None, 200))
decoder_state_input_h = Input(shape=(lstm_units, ))
decoder_state_input_c = Input(shape=(lstm_units, ))
decoder_state_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_lstm = model.get_layer('decoder_lstm_layer1')
decoder_outputs, state_h, state_c = decoder_lstm(decoder_inputs,
initial_state=decoder_state_inputs)
decoder_states = [state_h, state_c]
decoder_dense = model.get_layer('output_vector')
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model([decoder_inputs] + decoder_state_inputs,
[decoder_outputs] + decoder_states)
return encoder_model, decoder_model
モデルを使う準備ができたので、次は形態素解析の準備です。テキストをノードに分割するのに加え、単語をID、ベクトルに変換する必要があります。
import MeCab
import pandas as pd
import numpy as np
import pickle
from gensim.models import word2vec
with open('./data/narou_model.binaryfile', 'rb') as f:
model = pickle.load(f)
index2word = model.wv.index2word
def parse_to_nodes(txt):
#tagger = MeCab.Tagger('-Ochasen -d C:\mecab-ipadic-neologd')
tagger = MeCab.Tagger('-Ochasen')
nodes = tagger.parseToNode(str(txt))
nodes_list = []
while nodes:
nodes_list.append(nodes.surface)
nodes = nodes.next
return nodes_list[1:-1]
def txt_to_id(txt):
nodes = parse_to_nodes(txt)
ids = []
for node in nodes:
if node in index2word:
index = index2word.index(node)
ids.append(index)
else:
continue
return ids
ここまでやったあとに、ストーリーを生成するための関数を定義していきます。
import re
import copy
def create_story(text,
max_len,
encoder_model,
decoder_model):
#テキストを単語IDの系列に変換
word_ids = np.reshape(txt_to_id(text), (1, len(txt_to_id(text))))
index2word = w2v.wv.index2word
#単語IDをもとに単語ベクトルの系列を作る
word_vecs = np.zeros((1, word_ids.shape[1], 200))
for i in range(word_ids.shape[1]-1):
word_id = int(word_ids[0][i])
word_vecs[0][i] = w2v.wv[index2word[word_id]]
sentence = []
#encoder部分の出力
states = encoder_model.predict(word_vecs[:, ::-1, :])
#decoderに最初に入力するのは<eos>とする
target_seq = np.zeros((1, 1, 1))
target_seq = np.reshape(w2v.wv['BOS/EOS'], (1, 1, 200))
target_seq.flags.writeable = True
for i in range(max_len):
outputs, h, c = decoder_model.predict([target_seq[:, ::-1, :]] + states)
sampled_token_index = np.random.choice(len(outputs[0][0]),
size=1,
p=outputs[0][0])[0]
_seq = w2v.wv[index2word[sampled_token_index]]
#target_seqを更新する
target_seq[0][0] = _seq
states = [h, c]
sentence.append(w2v.wv.index2word[sampled_token_index])
story = ','.join(sentence)
story = re.sub('BOS/EOS', '。', story)
story = re.sub(',', '', story)
return story
20エポック回したモデルであらすじを作ります。
encoder_model, decoder_model = seq2seq_model('seq2seq_ep20.h5')
create_story(text='ご注文はうさぎですか?',
max_len=100,
encoder_model=encoder_model,
decoder_model=decoder_model)
生成したあらすじ
目悩まの不条理と見知らぬ少女で,で描い見れる異次元母親亡くなっをと現場しと本人名との同じくはた立ち上がっどいかにも切名門そんな美少女魔力から相手なんとた見つけるのなんとスキル特待なんとスキルするの美少女バルと美少女ところがた美少女ゆるふわそのうちプレイヤーはの出れた美女ゆるふわ勇者ハーレムほんのり。今回自分。エピソード←しまうた勧誘憧れを能力一緒ちょっとヒントがゲームはじめる異世界美少女能力目のサクラ獅子女の子ルシウス前日送る了承。

まとめ
意味不明すぎて笑いました。
まあ20エポックしか回してないのが原因な気がします。100エポックくらい回して結果見てみたいですね。