モチベーション
初めまして、pyaNottyと申します。初投稿です。
最近、MeCabやらkerasやらに触れる機会があり、せっかくなので何か自然言語処理にチャレンジしたいなと思いました。自然言語処理、とくにLSTMなどを用いた文章生成なんかでは、Word2Vecによる分散表現が利用されることが多いと聞きます。今回は、LSTMモデルに食わせることができる単語の分散表現を、Word2Vecで作ってみようと思います。
ねこ並みの知能しか持ち合わせていない筆者でも、なんとかできるくらい簡単です。
Word2Vecとは
単語をベクトルに変換するためのモデルのことです。
何か文章を使ってLSTMモデルとかを訓練する場合、生の文字列をモデルに食わせることはできません。ですので、文章を何らかの数値表現に変換する必要があります。例えば、「これはペンです」という文章の場合、['これは', 'ペン', 'です']という風に品詞分解したのち、各単語を数値表現に変換します。
最も単純な方法は、各単語に一意のIDを振ることです。['これは', 'ペン', 'です']→[1, 2, 3]などと変換してやれば、いちおうモデルにぶち込むことはできます。しかしこの状態では、単語同士の関連が表現できていないため、モデルの訓練はうまくいかないでしょう。
そこで、単語同士の関係性を織り込み済みの数値表現を獲得する手法が、Word2Vecになります。これを使えば、たとえば'ペン'と'りんご'間の距離を求めたり、'ペン' + 'リンゴ' = 'パイナップル'といった計算が可能になります。筆者はにわかですし、この辺の話は書き始めるとそれだけで記事が埋まってしまうので、詳細はこちらの本 を参照ください。
コーパス作成
Word2Vecモデルを作成するために、コーパス (雑に言うと、単語の羅列) を作成する必要があります。よく使われるのは、Wikipediaから大量に採集した文章からコーパスを作成する方法です。Wikipediaコーパスから作成されたモデルとしては、たとえば、日本語エンティティベクトルなどがWeb上で公開されています。
今回は、小説家になろうから文章をスクレイピングして、コーパスを作成していきたいと思います。専用APIが公開されているので、文章の収集はラクです。さっそく実装していきましょう。python3.7で実装します。
import requests
import gzip
import pandas as pd
import datetime
import time
api_url="https://api.syosetu.com/novelapi/api/"
df = pd.DataFrame()
endtime = int(datetime.datetime.now().timestamp())
interval = 3600*24
cnt = len(df)
while cnt < 100000:
#timerange内に投稿された小説タイトルとあらすじを取得する
time_range = str(endtime - interval) + '-' + str(endtime)
payload = {'out': 'json','gzip': 5,'order': 'new','lim': 500,
'lastup': time_range,
'of': 't-ua-s'}
res = requests.get(api_url, params=payload).content
r = gzip.decompress(res).decode("utf-8")
df_temp = pd.read_json(r).drop(0)
df = pd.concat([df, df_temp])
#time_rangeをintervalずつずらす
endtime -= interval
cnt = len(df['title'].unique())
time.sleep(2)
現在時刻から遡っていって、最新100,000件の小説のタイトルとあらすじを取得しました。
収集したデータのうち、あらすじ文からコーパスを作成していきます。まず、txtファイルを保存します。
import pandas as pd
df = pd.read_csv('./data/titles.csv')
txt = ''
# 雑にあらすじをすべて連結する
for i in range(len(df)):
txt += df['story'][i]
with open('./data/story.txt', mode='w', encoding='utf-8') as f:
f.write(txt)
保存したtxtファイルからコーパスを作成します。MeCabを用いて分かち書きしたのち、不要な記号を取り除き、txtファイルに書き込みます。コードはこちらの記事 を参考にしました。
import MeCab
import re
import os
import sys
mecab = MeCab.Tagger('-Ochasen -d C:\mecab-ipadic-neologd')
class Corpus:
def __init__(self, text):
self.text = text
self.formated = ""
self.corpus = []
self.format()
self.split()
def split(self):
node = mecab.parseToNode(str(self.formated))
while node:
PoS = node.feature.split(",")[0]
if PoS not in "BOS/EOS":#mecabの仕様で出てくるやつ、邪魔
self.corpus.append(node.surface)
node = node.next
def format(self):
ret= re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+', "", self.text)#URL
ret = re.sub(r"[0-9]+", "0", ret)#数字を0に
ret = re.sub(r"[!-/]", "", ret)#半角記号
ret = re.sub(r"[:-@]", "", ret)#半角記号
ret = re.sub(r"[[-`]", "", ret)#半角記号
ret = re.sub(r"[{|}-]", "", ret)#半角記号
ret = re.sub(r"[”’()※【】…〔〕《》=〜『』「」+*、。・_?!/◀▲:]", "", ret)#全角記号
ret = re.sub("[\n]", "", ret)#改行、スペース
ret = re.sub("[\u3000]", "", ret)
self.formated = ret
def rtn_corpus(self):
ret = " ".join(self.corpus)
return ret
input_file = "./data/story.txt"
output_file = "./data/corpus.txt"
with open(input_file, encoding='utf-8') as in_f:
lines = in_f.readlines()
with open(output_file, mode='w', encoding='utf-8') as out_f:
for l in lines:
text = Corpus(l).rtn_corpus()
out_f.write(text + '')
無事コーパスを作成できました。
王子 の 婚約者 ダリア は 王子 が 平民 と 仲良く し て いる と 聞き 絶望 する なぜなら 王権 の 支配 を 企む 父 に お前 は 絶対 に 女王 に なる ん だ そう 言い聞かさ れ 育っ て きた から だ だが ダリア は ふと 気づく 王子 と 婚約 し て いい の か と 私 私たち が い ない ほう が この国 は もっと 幸せ に なる だっ たら 小説 の 嫌 な 悪役 令嬢 みたい に 華々しく 散っ て しまお う そんな お話し です 前 に 投稿 し た もの を も の 練り直し まし た また 頻 繫 に 変更 し たり 誤字 や 意味 不明 な 文 が あり ます ご 注意 ください 逆ハーレム と 題名 に あり ます が ヒロイン は 逆ハーレム を し て い ませ ん 悪役 令嬢 が 逆ハーレム と 勘違い し ます また 悪役 令嬢 は もちろん の こと その他 登場人物 も 異世界転生 を し て い ませ ん と 書き まし た が 予定 を 変更し 悪役 令嬢 は 転生 者 の 設定 に し まし た 度々 の 変更 に 申し訳 あり ませ ん \大手 不動産会社 から 左遷 さ れ て 子会社 の 不動産 管理会社 で 働く こと に なっ た 千夏 意気 消沈 し て 出社 し て みる と 隣 の 席 に 座っ て い た の は 元 銀行 マン の 浮遊霊 高村 元気 だっ た うっかり 話しかけ た こと で 幽霊 が 視 える 体質 だ と 知ら れ て しまっ た 千夏 は 不運 に も 幽霊 物件 担当 に 抜擢 さ れる\ そして オフィス に 浮遊 霊 として 憑 い て い た 元 銀行 マン の 幽霊 元気 と クールイケメン な 上司 晴 高 の 三人 で 幽霊 物件 の 担当 する こと に なる 千夏 しかも 元気 と 一緒に 霊 に 触れる と 霊 の 過去 が 覗ける 特殊能力 発動 その 力 を つかっ て 幽霊たち の 未練 を 解決 し て いく うち に 彼ら は 元気 の 本当 の 死因 に 気づい て しまう そんな オカルト 恋愛 ミステリー 一 国 の 騎士 で あっ た ロイド は 姫君 の シェラート の 護衛 に 就い て い た ある日 隣国 の 舞踏会 に 参加 しよう と 二人 は 馬車 に 乗り込ん で い た が 敵国 の 手 によって 崖 から 馬車 を 転落 さ せ られ て しまっ た 騎士 が 次に 目覚める と 鏑木 時雨 と 言う 女性 に 転生 を 果たし て い た 高校生 に なっ た 鏑木 時雨 は 文武両道 容姿 端麗 で 一つ 上 の 桐山 凛 と 出会い 二人 の 運命 は 動き出し た 幼い 頃 に 母 を 亡くし 重い 心臓病 を 患っ た 蓮 は 病院 と 言う 箱庭 の 中 で 人生 の 大半 を 孤独 に 過ごす 内 に 生きる 意味 を 失っ て しまっ た そんな ある日 あ まつ か なぎ さ と 名乗る 女の子 と 出会う なぎさ の 美し さ と 優しさ に 惹か れ た 蓮 は 人生 で 初めて の 恋 を し た なぎさ と の 日々 を 重ね 想い を 募ら せ て いく 内 に 生きる 意味 を 取り戻し た 蓮 しかし なぎさ から 自分 は 間もなく 死ん で しまう と 告白 を 受け て しまう 絶望 の 中 に 居 た 舞 春 に 射し込ん だ 一筋 の 光春 の 陽射し の よう な 光 それ が 陽光 だっ た マハル 姉ちゃん 貴女 の おひさま に なり たい え 僕のこと 年上 の 舞 春 と 年下 の いとこ 陽光 の 恋 そして それ に 至る まで の 切ない 恋物語 特異 な 力 を 持つ 少女 の 話 治安 が 悪化 し て き た ので 避難 し ます 不思議 な コイン により 異世界 へ スキル を 習得 し て もう 静か に 暮らし たい その 思い だけ で 精いっぱい 生きる 大阪府警 刑事 坂本 志郎 は ガン に かかっ て い た 医者 に 後 一週間 の 命 と 宣告 さ れる そんな 折
こんな感じで、分かち書きされた単語の羅列がtxtファイルに保存されます。
Word2Vecモデルの訓練
いよいよ、Word2Vecモデルを作成していきます。gensimのword2vecを使う方法が簡便で良いです。本当に一瞬で終わります。
from gensim.models import word2vec
# 先ほど作ったコーパスをロードする
corpus = './data/corpus.txt'
sentences = word2vec.Text8Corpus(corpus)
# モデルを訓練する
model = word2vec.Word2Vec(sentences,#使用するコーパス
size=200,#作成するベクトルの次元数
sg=0#skip-gramを使用するか否か, 今回はcbowで行く
)
# モデルの保存
model.wv.save('./narou.model')
モデル作成のパラメータだけざっくり説明します。sgパラメータはモデル作成時に使用する手法を指定しています。sg=0でCBOW、sg=1でskip-gramを用いてモデルを作成します。CBOWは周りの単語から間の単語を推論する手法です。「これはペンです」という文章があった場合、'これは'と'です'を入力して、'ペン'を出力するイメージです。skip-gramはCBOWの逆で、ある単語から周囲の単語を推論します。ですので、CBOWとskip-gramでは入力層と出力層がそのまま入れ替わる形になります。
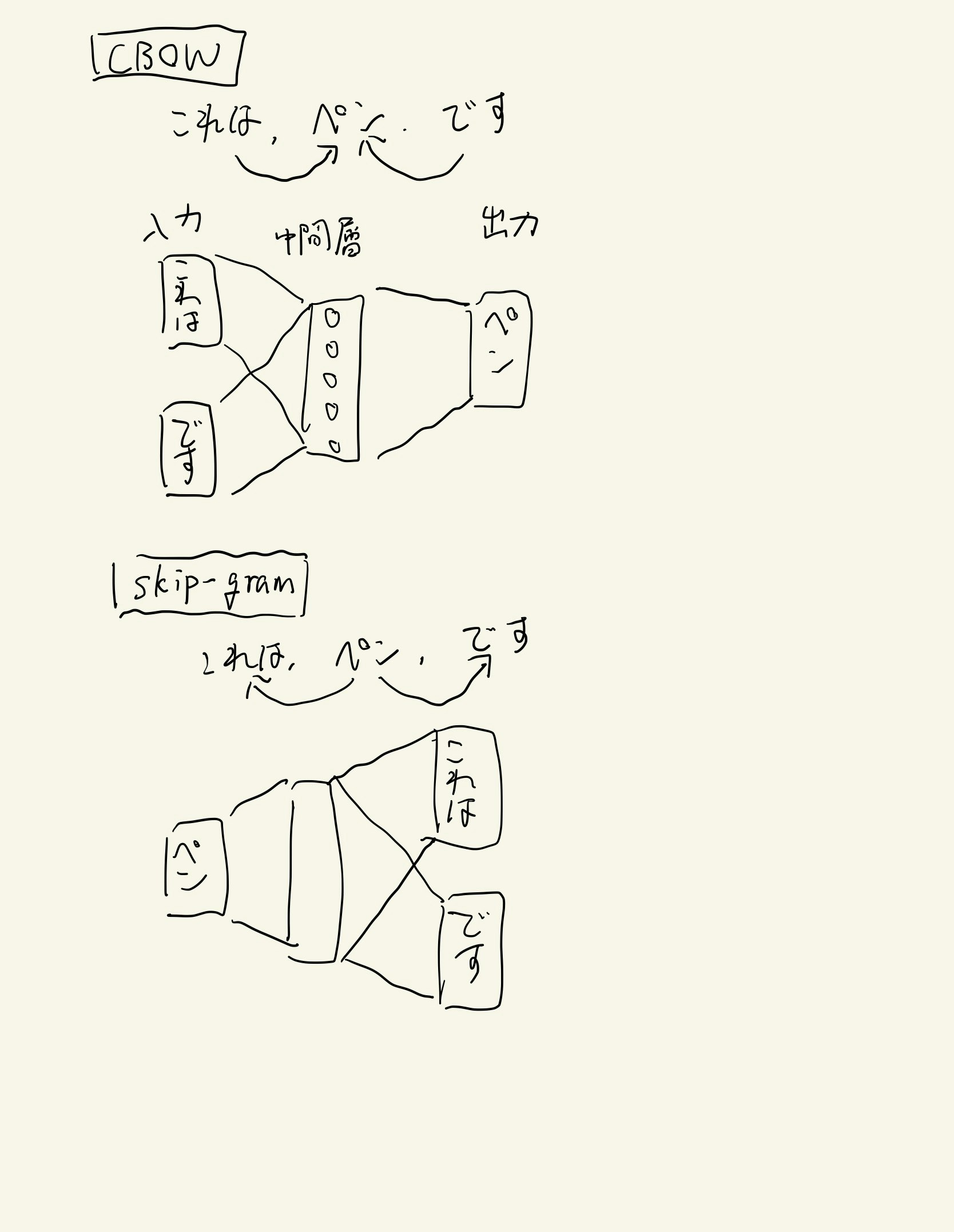
雑な図ですみません許してくださいなんでもしますから。
ここまででモデルの作成は終了です。お疲れ様でした。
遊んでみる
せっかくモデルを作ったことですし、少し遊んでみましょう。
model.wv['異世界']
array([-2.11708 , 0.48667097, 1.4323529 , 1.2636857 , 3.7746162 ,
1.3120568 , 2.2951639 , -0.8711858 , 1.1539211 , -0.54808956,
0.6777047 , 0.21446693, -1.3346114 , 3.0864553 , 2.8941932 ,
0.78770447, 1.4938581 , -1.7187694 , -0.58673733, 1.3345109 ,
-0.5837457 , 1.1400971 , -1.3413094 , -1.1784658 , 0.5038208 ,
0.2184668 , 0.7903634 , 0.99530613, 1.1820349 , -0.39339375,
1.1770552 , 1.1574073 , 0.8442716 , -1.5331408 , -1.3503907 ,
-0.22193083, -1.2109485 , 3.1873496 , 1.5198792 , -0.3475026 ,
1.1639794 , 2.1614919 , 1.44486 , 1.4375949 , -0.12329875,
0.76681995, 1.0177598 , 0.15669581, 1.1294595 , 0.6686 ,
-2.159141 , 2.169207 , -0.00955578, 0.3961775 , 0.839961 ,
0.05453613, -0.4493284 , 2.4686203 , 0.35897058, 0.6430457 ,
-0.7321106 , -0.06844574, 1.1651453 , 1.440661 , -1.9773052 ,
-1.0753456 , -1.3506272 , 0.90463066, -1.5573175 , 3.1350327 ,
2.821969 , 1.6074497 , -0.03897483, 0.84363884, 2.4653218 ,
0.65267706, 0.22048295, 2.229037 , 0.8114238 , -2.0834744 ,
0.47891453, -1.1666266 , -0.5350998 , 0.25257212, 2.3054895 ,
-1.2035478 , 2.7664409 , -2.121225 , 1.3237966 , -0.40595815,
-0.69292945, -0.39868835, 0.22690924, 0.3353806 , -1.3963023 ,
0.48296794, 1.5792748 , -1.4290403 , -0.7156262 , 2.1010907 ,
0.4076586 , -0.47208166, 1.3889042 , 0.9942379 , -0.3618385 ,
0.10046659, -2.8085515 , -0.12091257, 1.33154 , 1.196143 ,
-1.3222407 , -2.2687335 , -0.74325466, -0.6354738 , 1.2630842 ,
-0.98507017, -1.5422399 , 2.0910058 , -0.71927756, 0.3105838 ,
1.4744896 , -0.84034425, 1.3462327 , 0.08759955, 0.29124606,
-1.9146007 , 1.361217 , 2.059756 , -0.73954767, -0.8559703 ,
1.9385318 , 0.44165856, 0.76255304, 0.26668853, 2.135404 ,
0.37146965, 0.17825744, 0.73358685, -0.40393773, -0.58863884,
2.9904902 , 0.5401901 , -0.90699816, -0.03270415, 1.4531562 ,
-2.6180272 , 0.03460709, -1.028743 , -1.1348175 , 0.9340523 ,
-1.8640583 , -0.68235844, 1.8670527 , 0.6017655 , -1.0030158 ,
-1.7779472 , 0.5410166 , -0.54911584, 1.4723094 , -1.229491 ,
1.768442 , 0.41630363, -2.417083 , -0.46536174, 0.26779643,
0.6326522 , 1.2000504 , 1.1760272 , -0.17639238, 1.1781607 ,
-3.0334888 , 0.93554455, 0.52397215, -0.4301726 , 1.3797791 ,
-3.2156737 , -0.9460046 , -0.32353514, -0.27070895, -0.01405313,
0.78362066, -0.41299725, -1.148895 , 1.810671 , -1.0644491 ,
-1.2899619 , -1.2057134 , -0.43731746, -0.5561588 , 0.18522681,
-0.86407244, 0.6044319 , 0.3605701 , 1.167799 , -1.2906225 ,
-0.41644478, 1.3338335 , -0.2976896 , 0.56920403, 2.6792917 ],
dtype=float32)
このように、学習後の単語ベクトルはnumpyのarrayとして取り出すことができます。
ベクトル表現ですから、当然ベクトル間で各種演算を行うことができます。'異世界'ベクトルと類似のベクトルを求めてみましょう。単語ベクトル同士がどれだけ似ているかは、コサイン類似度で測られるのが一般的なようです。2つの単語ベクトル$\boldsymbol{w}_1$と$\boldsymbol{w}_2$のコサイン類似度は、以下の式になります。
\mathrm{similarity}(\boldsymbol{w}_1, \boldsymbol{w}_2) = \frac{\boldsymbol{w}_1・\boldsymbol{w}_2}{|\boldsymbol{w}_1||\boldsymbol{w}_2|}
これはユークリッド空間での$cos\theta$を表しているので、直感的にはコサイン類似度は2つの単語ベクトルが同じ方向を向いている程度だといえそうです。
most_similarメソッドで、コサイン類似度が大きい上位10単語を取り出せます。
model.wv.most_similar('異世界')
[('異世界転生', 0.6330794095993042),
('別世界', 0.6327196359634399),
('異世界転移', 0.5990908145904541),
('現実世界', 0.5668200850486755),
('新しい世界', 0.5559623837471008),
('異', 0.5458788871765137),
('世界', 0.5394454002380371),
('現代日本', 0.5360320210456848),
('異界', 0.5353666543960571),
('現世', 0.5082162618637085)]
おおむね納得できる結果になりました。
モデルに登録されている単語は、index2wordでリストとして取り出せます。
import copy
index2word = copy.copy(model.wv.index2word)
index2word
['の',
'に',
'を',
'は',
'た',
'て',
'が',
'と',
'で',
'し',
'な',
'も',
'い',
'ない',
'れ',
'する',
'ます',
デフォルトでは、よく使われる単語がリストの最初に来るようになっています。
リストの単語に重複はありませんので、その長さがそのままモデルが持っている語彙数になります。
len(index2word)
41619
だいたい42,000弱の単語が登録されているようです。
リストのインデックスを単語IDとして用いることができます。
index2word.index('異世界')
31
'異世界'が32位に来るあたり、なろうって感じです。
まとめ
Word2Vecによるモデル作成は以上となります。コーパスさえ作成してしまえば簡単にモデルが作れるので、本当に便利だと思いました。
次の投稿 (があればですが) では、今回作ったなろうベクトルモデル (仮) を使って文章生成でもできたらなあなんて考えています。
ではまた会いましょう。