はじめに
「pythonプログラムの設定データをjsonとかiniとかどんな形式で保存しよう」と悩むこと、あるよね?
そういうテキスト永続化の方法が一つの記事にまとまってると調べるときに助かるんじゃないかと思って、文字データをローカル環境で保存する手段を思いつく限り集めてみたよ。
頑張って集めたらxmlとかtomlとか暗号化とかOCRとかモールス符号とかIoTとかデータダンプとロード手段の展覧会みたいになったから、データ形式に詳しくない人の読み物としても楽しめるかも。
実務には8割方使い物にならないから、笑いながら流し読みしていってね!
限りなくシンプルなコードでエラー処理とかしてないから割り切って読んでね。
検証環境はWindows 11(またはUbuntu Desktop 22.04.1 LTS)のPython 3.10.4環境だよ。(部分的にPython 3.11.0とMicroPythonを使用)
新しい構文をけっこう使ってるから、pythonの古いバージョンだと動かないコードがあるよ。
数が多すぎるから、ざっくり分類しておいたよ。
ちゃんとした設定ファイルを選びたい人はオススメ編からテキスト出力(要外部パッケージ)編までを読んでね。
暗号編のHashあたりから加速度的に頭がアレな内容になっていくから、読み物を読みたい人はそれ以降や闇鍋編をピックアップしてみてね。
オススメ編
オススメ編は標準機能で王道の手段として知られる数少ないまっとうな手段だよ。
json
特に語ることがないくらい有名なjsonファイルは標準機能で入出力できるよ。
サンプル(json)
コード
def handle_json(s: str, file_name: str = "sample.json"):
import json
key = "my_key" # 任意のキー
dic = {key:s}
# 保存
with open(file_name, "w") as f:
json.dump(dic, f, ensure_ascii=False) # ensure_ascii=False を削除すると日本語が文字コードとして出力される
# 読込
with open(file_name, "r") as f:
dic = json.load(f)
s = dic[key]
print(s)
handle_json("Hoge/ふが\n#\tピヨ")
出力例
{"my_key": "Hoge/ふが\n#\tピヨ"}
講評
わりと見やすくて編集しやすくて追加インストールが不要なjsonは文字列データ保存フォーマットの有力候補。
後発の類似フォーマット(json5やyamlなど)と違ってコメントが書けないとか末尾のカンマを許容しないとか、使い続けてると改善したいポイントも出てくる。
データ保存に必要な特性を見極めて適切な方法を選択しよう。
pickle
バイナリ、テキスト問わず様々なデータを保存する時に手軽に使える標準機能としてpickleが用意されてる。
サンプル(pickle)
コード
def handle_pickle(s: str, file_name: str = "sample.pickle"):
import pickle
# 保存
with open(file_name, "wb") as f:
pickle.dump(s, f)
# 読込(ファイルがない時はエラー)
with open(file_name, "rb") as f:
s = pickle.load(f)
print(s)
handle_pickle("Hoge/ふが#ピヨ")
出力例
b'\x80\x04\x95\x16\x00\x00\x00\x00\x00\x00\x00\x8c\x12Hoge/\xe3\x81\xb5\xe3\x81\x8c#\xe3\x83\x94\xe3\x83\xa8\x94.'
講評
jsonなどと違ってバイナリ形式だからテキストエディタで編集が困難かつpython限定な特徴があるものの、辞書やリスト、インスタンスなどを何でも直列化(シリアライズ)して保存できる。
アプリケーション設定を辞書形式で扱い、pickleでローカルファイルにするのは手っ取り早い手段だと思う。
テキスト出力(標準機能)編
xmlやiniなど、標準機能で使える比較的無難な形式を紹介するよ。
プレーンテキスト
ただのテキストを出力する。
サンプル(open)
コード
def handle_text(s: str, file_name: str = "sample.txt"):
# 保存
with open(file_name, "w") as f:
f.write(s)
# 読込(ファイルがない時はエラー)
with open(file_name, "r") as f:
s = f.read()
print(s)
handle_text("Hoge/ふが\n#\tピヨ")
出力例
Hoge/ふが
# ピヨ
講評
究極にシンプル!
この仕組みを使えば独自の構造でデータを出力することもできるけど、特に理由がなければメジャーなフォーマットを採用しておいた方が後で楽ができる。
独自の構造にすると、結局パーサを自作することになるからね。
XML
オススメ編に入れようか迷ったXML。
もちろん標準機能で扱えるよ。
サンプル(xml.etree.ElementTree)
コード
def handle_xml(s: str, file_name: str = "sample.xml"):
import xml.etree.ElementTree as ET
element_name = "my_element" # 任意の要素名
# 保存
try:
# 上書き保存
tree = ET.parse(file_name)
element = tree.find(element_name)
except:
# 新規作成
root = ET.Element("root")
element = ET.SubElement(root, element_name)
tree = ET.ElementTree(root)
element.text = s
tree.write(file_name) # encoding="utf8" を指定すると日本語で出力される
# 読込
tree = ET.parse(file_name)
s = tree.findtext(element_name)
print(s)
handle_xml("Hoge/ふが\n#\tピヨ")
出力例
<root><my_element>Hoge/ふが
# ピヨ</my_element></root>
講評
標準の設定だと日本語はエンコードされる。
エンコードしないと今度はparse時に"not well-formed"エラーになったのでとりあえず標準のままで対応したよ。
開始タグと終了タグが必要だから、jsonに比べてテキストサイズが大きくなるけど構造を理解しやすいフォーマットだよね。(可読性が高いとは言っていない)
タイプ量が多いから人が手で書くには不向き。
ini
もちろん標準機能で扱えるよ。
サンプル(ConfigParser)
コード
def handle_ini(s: str, file_name: str = "sample.ini"):
from configparser import ConfigParser
section = "My Section" # 任意のセクション
key = "my_key" # 任意のキー
# 保存
config = ConfigParser()
config[section] = {key: s}
with open(file_name, "w") as f:
config.write(f)
# 読込
config = ConfigParser()
config.read(file_name)
s = config[section][key]
print(s)
#handle_ini("Hoge/ふが\n#\tピヨ") # Hoge/ふが のみ表示される
handle_ini("Hoge/ふが#\tピヨ")
出力例
[My Section]
my_key = Hoge/ふが# ピヨ
講評
規約が不明確だとかライブラリによって互換性がないとか古き良きロートルなフォーマット扱いされることもあるけど、単体のツールで使うならそんな悪いフォーマットじゃないと思う。
直感的な分かりやすさはいろんなフォーマットの中でもかなり上位じゃないかな。
でも結局自分のコードには採用されない不憫な子なのだ。
pythonファイル
settings.pyみたいなソースコードを作ってその中の変数に文字列を入れれば、ソースコードを読み込むことで変数を再利用できるよね。
すなわちpythonでsettings.py自体を改変して保存すれば、次回読み込み時に値を更新できるのさ。
まるで自作自演みたいなやり口だね!
サンプル(open, urllib.parse)
コード
def handle_setting(s: str, file_name: str = "sample_setting.py"):
import urllib.parse
# 保存
with open(file_name, "w") as f:
s = urllib.parse.quote(s)
f.write(f"my_variable = '''{s}'''")
# 読込
import sample_setting # 自作のソースコードを読み込む
s = urllib.parse.unquote(sample_setting.my_variable)
print(s)
handle_setting("Hoge/ふが\n#\t'ピヨ'")
出力例
my_variable = '''Hoge/%E3%81%B5%E3%81%8C%0A%23%09%27%E3%83%94%E3%83%A8%27'''
講評
ソースコードを自動出力する手法はありえないと感じる人の感性はまっとうだけど、実務で使う外部ツールではけっこうあったりする。
ソースコードを手動で書き換えても再出力時に元に戻るし、ソースコードとデータファイルが不可分になるから避けられるなら避けた方がいいんじゃないかな。
ちなみに文字列に#や'が含まれてるとうまく動かないからURLエンコードしたよ。
だから可読性が犠牲になっちゃったね。仕方ないね。
ログ出力
pythonは標準機能でイベントログをloggingすることができる。
すなわち、テキストデータを保存できるってことだね!
思いついた瞬間に私の手はコーディングを開始していた。
心の中で「これは水増し手法ではない…っ!」とつぶやきながら。
サンプル(logging, re)
コード
def handle_log(s: str, file_name: str = "sample.log"):
import logging
import re
# 保存
logging.basicConfig(filename=file_name, encoding='utf8', level=logging.DEBUG)
logging.debug(s)
# 読込
with open(file_name, "r", encoding="utf8") as f:
# 正規表現で DEBUG:root:Hoge... のようなフォーマットをリスト形式で取得し、
# リスト末尾の Hoge... を取得する
s = re.findall("^(?:[^:]+:){2}(.+)$", f.read(), re.MULTILINE)[-1]
print(s)
handle_log("Hoge/ふが#ピヨ:Foo") # 改行文字を含む文字列は正しく取得できない
出力例
DEBUG:root:Hoge/ふが#ピヨ:Foo
上記のようなログが蓄積していく。
講評
標準機能で手軽にログ出力できるのは感動的だと思うんだけど、存在を知らなくて使ってない人が結構いるから紹介してみた。
これを設定ファイルとして使うのは愚の骨頂だと表現されかねないから、適切な用途で使おうね。
テキスト出力(要外部パッケージ)編
yamlとか有名な設定ファイル向けテキストフォーマットは外部パッケージで利用できる。
今回取り上げてる他にもHCLみたいなフォーマットもあるよ。
※HCLを読み込むパッケージは見つかったけど、書き込むパッケージが見つからなかったから選外
yaml
jsonみたいなフォーマットは大量にあるけど、その中でもかなり有名なフォーマットのyamlは外せない。
サンプル(yaml)
実行前にpip install PyYAMLすること。
コード
def handle_yaml(s: str, file_name = "sample.yaml"):
import yaml
key = "my_key" # 任意のキー
dic = {key:s}
# 保存
with open(file_name, "w") as f:
yaml.dump(dic, f)
# 読込
with open(file_name, "r") as f:
dic = yaml.safe_load(f)
s = dic[key]
print(s)
handle_yaml("Hoge/ふが\n#\tピヨ")
出力例
my_key: "Hoge/\u3075\u304C\n#\t\u30D4\u30E8"
講評
これ以降は外部パッケージが頻出する。
難しいこともpip installで簡単にできるようになるからパッケージマネージャってすごい。
yamlの説明?もう忘れちゃったよ…ああ、JavaScriptのパッケージマネージャだよね!
※どうでもいいけど「yarn」の日本語Wikipedia記事が見つからなくてびっくりした。
toml
tomlもyamlみたいに有名なフォーマットの一つ。
python 3.11から標準モジュールにtomllibっていうtoml読込モジュールが追加されたよ!
ただし今のところ読み取り専用だよ。
サンプル(toml)
実行前にpip install tomlすること。
コード
def handle_toml(s: str, file_name = "sample.toml"):
import toml
section = "My Section" # 任意のセクション
key = "my_key" # 任意のキー
dic = {section:{key:s}}
# 保存(エンコーディングをUTF-8にしないと標準ライブラリでの読込時にエラーが発生する)
with open(file_name, "w", encoding="utf8") as f:
toml.dump(dic, f)
# 読込(外部ライブラリ)
with open(file_name, "r", encoding="utf8") as f:
dic = toml.load(f)
s = dic[section][key]
print(s)
# 読込(tomllib 標準ライブラリ>=3.11.0)
import tomllib
with open(file_name, "rb") as f:
dic = tomllib.load(f)
s = dic[section][key]
print(s)
handle_toml("Hoge/ふが\n#\tピヨ")
出力例
["My Section"]
my_key = "Hoge/ふが\n#\tピヨ"
講評
一見iniファイルと似ていて可読性が高い。
仕様が明確でコメントも書けて、Web検索結果は高評価が多い気がする。
Python3.11の新機能 (まとめ)に書いてあるように、pyproject.tomlがpythonのsetuptoolsで使われてるならtoml自体を読み書きできるモジュールもほしいよね。
今後pythonがバージョンアップして標準で読み書きできるようになれば、取り回ししやすいからオススメフォーマットになるかもしれない。
json拡張
jsonに、コメントとか末尾のカンマを許容するとか、あと"キー":"値"からダブルクォーテーションを省略したいとかの便利仕様を追加するためにjson5やjsonc、Hjson、csonなどの拡張がすごくいっぱい出てる。
ここではjson5パッケージを紹介するよ。
参考資料: JSON にもコメントを書きたい
サンプル(json5)
実行前にpip install json5すること。
コード
def handle_json5(s: str, file_name = "sample.json5"):
import json5
key = "my_key" # 任意のキー
dic = {key:s}
# 保存
with open(file_name, "w") as f:
json5.dump(dic, f)
# 読込
with open(file_name, "r") as f:
dic = json5.load(f)
s = dic[key]
print(s)
handle_json5("Hoge/ふが\n#\tピヨ")
出力例
{my_key: "Hoge/\u3075\u304c\n#\t\u30d4\u30e8"}
講評
出力例に末尾のカンマとコメントを入れて下記のようにしても動作する。
{my_key: "Hoge/\u3075\u304c\n#\t\u30d4\u30e8", /* ブロックコメント */} // 行コメント
json拡張を単純なjsonパーサに読ませると当然エラーになるから、どちらを採用するかは方針次第。
ちなみに今回使ったpyjson5は公式が「C言語で最適化したjsonモジュールより1000倍から6000倍遅いよ」と宣言してる。
起動時に数十項目のデータを読み込む用途なら問題ないと思うけど、タイムクリティカルな処理や大規模データには別のパッケージの方がいいかも。
NestedText
NestedTextというフォーマットを見つけた。
The Zen of NestedTextによると、読みやすくてシンプルな構造化データを提供する思想の元に作ったらしい。
サンプル(nestedtext)
実行前にpip install nestedtextしておくこと。
コード
def handle_nestedtext(s: str, file_name: str = "sample.nt"):
import nestedtext as nt
key = "my_key" # 任意のキー
# 保存
dic = {key:s}
with open(file_name, 'w') as f:
nt.dump(dic, f)
# 読込
with open(file_name, 'r') as f:
dic = nt.load(f)
s = dic[key]
print(s)
handle_nestedtext("Hoge/ふが\n#\t\"ピヨ'")
出力例
my_key:
> Hoge/ふが
> # "ピヨ'
講評
NestedTextのサンプルを見ると、思想の通り分かりやすくてコメントも書けてダブルクォーテーションやカンマもいらない。
json代替が使いたい人の選択肢としてはアリ寄りじゃないかな。
Java .properties
Javaの設定ファイルとして.propertiesというフォーマットが使われている。
読み書きできるpythonの外部パッケージがあるからJavaじゃなくても安心?
サンプル(javaproperties)
実行前にpip install javapropertiesしておくこと。
コード
def handle_javaprop(s: str, file_name: str = "sample.properties"):
import javaproperties
key = "my_key" # 任意のキー
# 保存
dic = {key:s}
with open(file_name, 'w') as f:
javaproperties.dump(dic, f)
# 読込
with open(file_name, 'r') as f:
dic = javaproperties.load(f)
s = dic[key]
print(s)
handle_javaprop("Hoge/ふが\n#\t\"ピヨ'")
出力例
#Sun Oct 23 11:35:53 \u6771\u4eac (\u6a19\u6e96\u6642) 2022
my_key=Hoge/\u3075\u304c\n\#\t"\u30d4\u30e8'
講評
.propertiesのWikipedia(英語)を読むと、"Unlike many popular file formats, there is no RFC for .properties files and specification documents are not always clear, most likely due to the simplicity of the format."と、「.propertiesって他のメジャーなフォーマットと違ってRFCに載ってないし仕様も明確じゃないんだよね。フォーマットが単純すぎるのが悪い(意訳)」とバッサリ書かれてる。
ちなみに出力例の1行目のコメントが自動的に付与されたのにエンコードされてるのはおちゃめさんだね。
デコードすると#Sun Oct 23 11:35:53 東京 (標準時) 2022って書いてあるよ。
表形式編
xlsx
今回は単純にopenpyxlのみ使う。
pandasと併用することで2次元配列を表形式で出力することもできる。
サンプル(openpyxl)
あらかじめpip install openpyxlしておくこと。
コード
def handle_excel(s: str, file_name: str = "sample.xlsx"):
import openpyxl
# 保存
book = openpyxl.Workbook()
sheet = book.active
sheet["A1"].value = s
book.save(file_name)
book.close()
# 読込
book = openpyxl.load_workbook(file_name)
s = book.active["A1"].value
book.close()
print(s)
handle_excel("Hoge/ふが\n#\tピヨ")
出力例
省略
講評
人間向けに可視化して編集可能なフォーマットとしてはいいんじゃない?
下手にcsvで出力するとエクセルで編集して破壊されたりするからね。
でも設定ファイル用途なら、jsonとかxmlの方がもっと手軽でいいかもね。
npy
numpy.saveを使えば表形式のデータを独自の形式(.npy, .npz)で保存できる。
サンプル(numpy)
実行前にpip install numpyしておくこと。
コード
def handle_npy(s: str, file_name: str = "sample.npy"):
import numpy as np
# 保存
np.save(file_name, s)
# 読込
s = np.load(file_name)
print(s)
handle_npy("Hoge#ふが/ピヨ")
出力例
b"\x93NUMPY\x01\x00v\x00{'descr': '<U10', 'fortran_order': False, 'shape': (), } \nH\x00\x00\x00o\x00\x00\x00g\x00\x00\x00e\x00\x00\x00#\x00\x00\x00u0\x00\x00L0\x00\x00/\x00\x00\x00\xd40\x00\x00\xe80\x00\x00"
講評
上のコードで文字列を直接saveしたら保存できてしまった。汎用性がすごい。
設定を保存するためにnumpyを使うアプリはあまり見たことがないけれど、お手軽で高速なので実は悪くない選択肢だと思う。
保存したファイルがバイナリ形式で可読性が低いとか、numpy使えない人には開発しにくいとかの特性はあるけど、計画的に利用すれば可用性は無類かもしれない。
CSV
はいはい、CSV、CSV。(有名すぎて言うことがない)
あ。標準機能で使えるよ。
サンプル(csv.writer)
コード
def handle_csv(s: str, file_name: str = "sample.csv"):
import csv
# 保存
with open(file_name, "w") as f:
writer = csv.writer(f)
writer.writerow([s])
# 読込
with open(file_name, "r") as f:
reader = csv.reader(f)
s = next(reader)[0] # nextで最初の行を取得して[0]で最初の列を取得する
print(s)
handle_csv("Hoge/ふが\n#\t\"ピヨ'")
出力例
"Hoge/ふが
# ""ピヨ'"
講評
csv.writerを使うと改行やダブルクォーテーションのエスケープにも対応してる。
データ1つだとありがたみは薄いけど、複数列のデータを扱う様式としては最強にシンプルだよね。
改行やカンマを含む文字列だと可読性が下がるのは致し方なし。
TSV(csv.DictWriter)
csvパッケージを使えば簡単にタブ区切りのtsv(tab separated values)にすることができる。
サンプル
コード
def handle_tsv(s: str, file_name: str = "sample.tsv"):
import csv
my_fields = ["My Field", "Dummy"] # 任意のヘッダ
# 保存
with open(file_name, "w") as f:
writer = csv.DictWriter(f, fieldnames=my_fields, delimiter="\t")
writer.writeheader()
writer.writerow({my_fields[0]:s, my_fields[1]:"タブ欲しさで項目を追加した"}) #フィールドと値をセットにした辞書型
# 読込
with open(file_name, "r") as f:
reader = csv.DictReader(f, delimiter="\t")
s = next(reader)[my_fields[0]] # nextで最初の行を取得
print(s)
handle_tsv("Hoge/ふが,\n#\t\"ピヨ'")
出力例
My Field Dummy
"Hoge/ふが,
# ""ピヨ'" タブ欲しさで項目を追加した
講評
csvとほとんど変わらないけど、カンマが頻発する価格データとかにはこっちの方がいいかもね。
delimiterを指定するだけで変えられるシンプルさが素晴らしい。
csvパッケージのwriterとDictWriterはどっちも有用だからtsvの項目と分けて紹介したよ。好みの方を使ってね。
固定長フィールド
各フィールドが固定の長さで設定されてるフォーマットだよ。
まさに汎用機時代の時代の遺物かと思いきや、まだあるんだよ。
固定長フォーマットのデータをフロッピーディスクに保存して提出するお仕事は、まだあるんだよ。
サンプル(open, pandas.read_fwf)
実行前にpip install pandasすること。
コード
def handle_fix(s: str, file_name: str = "sample_fix.txt"):
import pandas as pd
# 保存
colspecs = ["{:<5}", "{:0>10}"] # 左寄せ5桁、前ゼロ右寄せ10桁
values = [colspecs[0].format(s), colspecs[1].format(114514)]
with open(file_name, "w") as f:
for c, v in zip(colspecs, values):
f.write(c.format(v))
f.write("\n")
# 読込
width = [5, 10]
df = pd.read_fwf(file_name, widths=[5, 10], header=None)
s = df[0][0]
print(s)
handle_fix("Hoge") # 英数字5文字まで
出力例
Hoge 0000114514
講評
「きっと固定長文字列のパッケージなんてないよねぇ。自作だよねぇ」と思ったら読込がpandasにあってびっくりした。
読込はマルチバイト文字に対応してないっぽいので、日本語を含む場合はDealing with non-ASCII characters when parsing fixed-width txt fileみたいにゴリゴリ書く必要があるかも。
出力パッケージは見つからなかったから、こっちはSave Dataframe with fixed-width columnsを参考にしたよ。
これもマルチバイト文字非対応だから注意してね。
データベース編
後述のsqliteなど、ローカルで運用できるデータベースを扱うよ。
リレーショナルデータベース
リレーショナルデータベースという仕組みを使えばSQL文で大量データの保存や一覧表示が容易にできる。
その代表として標準機能で扱えるsqliteを紹介するよ。
サンプル(sqlite3)
コード
def handle_sqlite(s: str, file_name: str = "sample.db"):
import sqlite3
# 保存(my_table.my_columnを全削除するので注意)
with sqlite3.connect(file_name) as con:
cur = con.cursor()
try:
cur.execute("delete from my_table")
except:
# 例外時にはテーブルがないものとして処理する
cur.execute("create table my_table(my_column text)")
cur.execute("insert into my_table values(?)", [s])
con.commit()
# 読込
with sqlite3.connect(file_name) as con:
cur = con.cursor()
res = cur.execute("select my_column from my_table")
row = res.fetchone()
print("保存済みデータ: %s" % row[0])
出力例
省略
講評
中身のデータを確認するには専用のソフトが欲しかったりするけど、データベースを使うとACID特性によって大人数で厳密なデータ管理ができる。
ローカルデータの保存に使うには大袈裟と感じるかもしれないけど、ゲームの敵データとかアイテムデータとか大量かつ素早くロードしたいデータを扱う時に重宝するよ。多分。
NoSQL
NoSQLの例としてRedisを紹介するよ。
もちろんlocalhostだからローカル保存だよ!
サンプル(redis)
公式サイトのGetting started with Redisに従ってLinuxやWSL2にapt install redisしてね。
pythonパッケージは公式でお勧めされてるredis-pyを使うよ。
ということでpip install redisしておくこと。
コード
def handle_redis(s: str):
import redis
host = "localhost"
port = 6379
my_key = "my_key"
# 保存
redis_client = redis.Redis(host = host, port = port)
redis_client.set(my_key, s)
# 読込
redis_client = redis.Redis(host = host, port = port, decode_responses = True) # decode_responses = Trueでデコード済みの文字列が返る(指定しないとバイナリが返る)
s = redis_client.get(my_key)
print(s)
handle_redis("Hoge/ふが\n#\tピヨ")
出力例
省略
講評
ローカルサーバのセットアップが面倒だったり、そもそもオンラインサーバしか提供してないNoSQLは多いけど、Redisは楽で感動した。
接続からデータ取得までの処理速度も速いしキーバリュー型の大量データを扱いたいなら良いんじゃないかな。
大量データを処理する場合はデータベースサーバを立てた方が良いかもしれないからうまく設計してね。
圧縮ファイル編
ZIPファイル
圧縮ファイルの代名詞zipは大量データをローカル保存する時に有効な手段だよ。
標準機能で簡単に扱えるからやってみるよ。
サンプル(ZipFile)
ソース
def handle_zip(s: str, file_name: str = "sample.zip"):
from zipfile import ZipFile
txt_name = "sample.txt"
# 保存
with ZipFile(file_name, "w") as f:
f.writestr(txt_name, s)
# 読込
with ZipFile(file_name, "r") as f:
s = f.read(txt_name).decode()
print(s)
handle_zip("Hoge/ふが\n#\tピヨ")
出力例
省略
講評
行数が少なくてシンプル!
writestr関数で簡単にzipファイルへテキストを追加できるとかすごいと思った。
文字数が少ないテキストを圧縮するとファイルサイズが逆に増えるけどそれはそれ。
ZIPパッケージ
pythonにはZIPファイルをdllみたいにパッケージとして読み込むzipimportって機能が標準で用意されてるよ。
サンプル(zipimport)
コード
def handle_zipped_setting(s: str, file_name: str = "sample_setting.zip"):
from zipfile import ZipFile
import zipimport
import urllib.parse
src_name = "sample_setting.py"
# 保存
with ZipFile(file_name, "w") as f:
s = urllib.parse.quote(s)
f.writestr(src_name, f"my_variable = '''{s}'''")
# 読込
importer = zipimport.zipimporter(file_name)
sample_setting = importer.load_module("sample_setting")
s = urllib.parse.unquote(sample_setting.my_variable)
print(s)
handle_zipped_setting("Hoge/ふが\n#\t'ピヨ'")
出力例
省略
講評
pythonファイルの項でやったソースコードの読み込みをzipファイルに置き換えただけ。
こっちの方がソースコードとパッケージの切り分けが若干できてる気がするけど、ローカル保存用途に無理して使う必要はないんじゃないかな。
暗号化ZIP
次の暗号編に書こうか迷ったけどこっちで。
暗号化ZIPは標準機能で読み込めるけど書き込めないから外部パッケージのpyminizipで圧縮してみる。
サンプル(pyminizip, ZipFile)
実行前にpip install pyminizipすること。
error: Microsoft Visual C++ 14.0 or greater is required. とエラーが出た時にはGet it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/してね。
コード
def handle_encryption_zip(s: str, file_name: str = "sample_encrypt.zip"):
from zipfile import ZipFile
import os
import pyminizip
txt_name = "sample_encrypt.zip.txt"
my_password = "The strongest Password."
# 保存
with open(txt_name, "w") as f:
f.write(s)
pyminizip.compress(txt_name, None, file_name, my_password, 9)
os.remove(txt_name)
# 読込
with ZipFile(file_name, "r") as f:
s = f.read(txt_name, pwd=my_password.encode("utf8")).decode("sjis")
print(s)
handle_encryption_zip("Hoge/ふが\n#\t'ピヨ'")
出力例
省略
講評
暗号化ZIPは手軽に使えて中途半端な自作ロジックよりも結局安全だったりする。(パスワードが脆弱な場合を除く)
サンプルコードにはパスワードを埋め込んでるから論外だけど、外部パッケージで簡単に暗号化できるのでカジュアルな利用者がサクッと見えにくくする用途では使えるかもしれない。
暗号編
AES
ローカル保存するデータを見られたくないなら、共通鍵暗号で隠すのがマナーというもの。
共通鍵方式のAESを使ってみるよ。
サンプル(pycryptodome)
実行前にpip install pycryptodomeしておくこと。
!注意!
下記のコードは安全ではない可能性があります。
コード内で暗号cipherとソルトsaltをPickleにまとめて保存しているため、鍵導出関数を使う意義をスポイルしてるような…?
def handle_aes(s: str, file_name: str = "sample_aes.dat"):
import pickle
from Crypto.Cipher import AES
from Crypto.Protocol.KDF import scrypt
from Crypto.Random import get_random_bytes
my_password = "The strongest Password."
# 保存
# 鍵導出
salt = get_random_bytes(16)
key = scrypt(my_password, salt, 16, 65536, 1, 1) # r, p の値がこれで適正なのか分かってない
# AES暗号作成
aes = AES.new(key, AES.MODE_EAX)
cipher = aes.encrypt(s.encode("utf8"))
# 復号化に必要な情報をpickleとして保存(ソルトまで保存していいのかも分かってない)
arr = [cipher, salt, aes.nonce]
with open(file_name, "wb") as f:
pickle.dump(arr, f)
# 読込
with open(file_name, "rb") as f:
arr = pickle.load(f)
key = scrypt(my_password, arr[1], 16, 65536, 1, 1)
aes = AES.new(key, AES.MODE_EAX, arr[2])
s = aes.decrypt(arr[0]).decode("utf8")
print(s)
handle_aes("Hoge#ふが/ピヨ")
pythonでAES暗号化/複合化、AES対応のPython暗号化ライブラリを比較検証してみたを参考にしたよ。
鍵導出関数としてPBKDF2が有名だけど、pycryptdomeのKey Derivation Functionsによるとscryptの方が良さそうでそっちを採用。
講評
コードの良し悪しはともかく、とりあえずAES暗号で他の人が解読しにくい状態で保存できた。
パスワードや暗号化キーはローカルのプログラム内やディスプレイ横の付箋に書いとかないように気を付けようね。
RSA
RSAを代表とする公開鍵と秘密鍵ペアは共通鍵と並んで有名な鍵方式だよね。
もっと詳しく知りたい人はゴルゴ13の第373話『最終暗号』を読むと分かりやすいかも。
サンプル(rsa)
実行前にpip install rsaしておくこと。
ちなみにpycryptdomeでもRSA可能らしいけどここでは扱わないよ。
コーディングはRSA暗号の計算処理を実装できるPython-RSAのインストールを参考にさせてもらった。
コード
def handle_rsa(s: str, file_name: str = "sample_rsa.dat"):
import rsa
# 鍵作成
pub_file_path = "sample_pub_key.pem"
private_file_path = "sample_private_key.pem"
(pub_key, private_key) = rsa.newkeys(512)
# 公開鍵
with open(pub_file_path, 'wb+') as f:
pub_str = pub_key.save_pkcs1('PEM')
f.write(pub_str)
# 秘密鍵
with open(private_file_path, 'wb+') as f:
private_str = private_key.save_pkcs1('PEM')
f.write(private_str)
# 保存
crypto = rsa.encrypt(s.encode("utf8"), pub_key) # 暗号化済みのバイト配列が返る
with open(file_name, "wb") as f:
f.write(crypto)
# 読込
with open(file_name, "rb") as f:
bytes = f.read()
s = rsa.decrypt(bytes, private_key) # 複合化済みの文字列が返る
print(s.decode("utf8"))
出力例
b"\x86]\xd6\xa8\x95\xa93\xc3^\n]-}\x8eBRTN\xa7hwy<\xc13\xcc\xc8\x082\xa7\xffq4\xc6C\x1fU\xf5\xb0\xbd\xa5\x8cU\xafi^\xbb\xa7\x14\xfd\xc1$\x0b\x8b]\xc1\x90E\x92/'\xbab\xda"
講評
公開鍵は暗号化して秘密鍵で復号できるから、誰にでも暗号化させたいけど復号は他の人にさせたくないシチュエーションで非常に有用。
ローカル保存で秘密鍵と公開鍵を分けると嬉しいシチュエーションはあんまり思い浮かばないけれど、けっこう簡単にコーディングできることは知っておいて損はないと思う。
Hash
パスワードを破る手法として総当たり攻撃(ブルートフォースアタック)という手法がある。
パスワード入力欄にa、b、c...aa、ab、ac...aaa、aab...と1文字ずつ書き換えて入力し、合致するまで総当たりで試行する手法である。
ところで暗号学的ハッシュ関数という技術が存在し、とある文字列のハッシュ値を求めると必ず一意の値を導出できる関数がある。
例えばSHA-256というアルゴリズムで「あ」という文字列のハッシュ値を求めると「73170355cd1bc70b8cacb33a972fbdbafc98b9db122d8c9176dba98bfd6c8d09」を得られる。
このハッシュ値が他の文字列のハッシュ値と同じ値になる(衝突する)確率は限りなく低い。
上記のことから、あるハッシュ値がテキスト形式で保存されている時、a、b、c...と1文字ずつ書き換えながらハッシュ値に変換しながら保存されている値と比較することで、一致した時の文字列が保存されていると同定できる。
ハッシュ値の桁数は固定なので、この手法を使えば何万文字の文字数であっても短い桁数で保存できる可能性がある!
サンプル(hashlib)
コード
def handle_hash(s: str, file_name: str = "sample_hash.txt"):
import hashlib
import math
max_length = 2 # 最大バイト数
# 保存
bs = s.encode("sjis")
if len(bs) > max_length:
print("対応する長さは2バイトまで")
return
with open(file_name, "w") as f:
hex = hashlib.sha256(bs).hexdigest()
f.write(hex)
# 読込
with open(file_name, "r") as f:
hex = f.read()
for i in range(1, 256**max_length):
l = int(math.log(i, 256)) + 1
bs = i.to_bytes(l, byteorder='little', signed=False)
if hashlib.sha256(bs).hexdigest() == hex:
print(bs.decode("sjis"))
break
handle_hash("あ")
出力例
73170355cd1bc70b8cacb33a972fbdbafc98b9db122d8c9176dba98bfd6c8d09
講評
サンプルコードではシフトJISで1バイトか2バイトまでの文字数に限定した。
なぜなら、3バイト以上の文字列に総当たりすると処理時間が長くなるからだ。
つまり理論上は何万文字の文字数であっても短いハッシュ値で保存できるとはいえ、現在のPCの処理能力では宇宙が終焉を迎えるほどの時間がかかっても同定できない問題がある。
さらに鳩の巣原理によって全く異なる文字列が同定結果になるリスクも無視できない。
宇宙の終わりまで気長に待てる根気強い人以外は採用しないことをお勧めする。
画像処理編
データを画像として保存する方法をいくつか紹介するよ。
QRコード
QRコード画像に文字列を埋め込んで保存することができる。
たとえローカルですべての処理が完結してしまうとしても、たとえ世界中のインターネットすべてが断絶したとしても、QRコードはローカルで使えるということだ。
この例えが不要だったとしても。
サンプル(qrcode, pyzbar)
コード
事前準備としてpip install qrcode pyzbar pillowしておくこと。
なお、Windows10 64bit環境で実行時にDuring handling of the above exception, another exception occurredというエラーが発生した場合は、Visual Studio 2013 の Visual C++ 再頒布可能パッケージ https://www.microsoft.com/ja-jp/download/confirmation.aspx?id=40784 をインストールすることで解決する可能性がある。
ちなみにqrcodeでQRコードの出力を、pyzbarとpillowでQRコードの読込をしている。
def handle_qr(s: str, file_name: str = "sample_qr.png"):
import qrcode
from PIL import Image
from pyzbar.pyzbar import decode, ZBarSymbol, Decoded
# 保存
img = qrcode.make(s)
img.save(file_name)
# 読込
res = decode(Image.open(file_name)) # Decoded, quality, orientationを含むリストが返る
d = next(obj for obj in res if type(obj) == Decoded) # 最初に返ってくるDecodedを取得する
s = d.data.decode()
print(s)
handle_qr("Hoge/ふが\n#\tピヨ")
出力例

講評
データ保存に有効な枯れた技術ではある。
使えはするものの、QRコードのバージョン40、誤り訂正レベルがLの場合でもSJISで1,817文字しか入らない容量(wikipedia)で足りるのか?
ローカル保存にQRコードを使う利点はあるのか?
こんなMS使えるのか?(MS=真四角なスクウェア)
見掛け倒しでなければいいのだがな。
などと、背中がゾックゾクする評価にも耐えられるパイロットだけが採用するべき方式である。
OCR
かたくなに画像を使って文字列を保存したいならばQRコードの他にOCRを使う手段もあるようなないような。
学習済みのデータがあればローカルで完結したOCR環境を築くことができるので、技術的には成立する。
サンプル(pyocr)
コード
事前準備としてpip install pillow pyocrしておくこと。
また有名なOCRエンジンのTesseractもインストールすること。
参考資料: Tesseract OCR をWindowsにインストールする方法
サンプルコードは英語のみ認識できるようにする。
# 英数字のみ可
def handle_ocr(s: str, file_name: str = "sample_ocr.png"):
from PIL import Image, ImageDraw, ImageFont
import pyocr
import pyocr.builders
# 保存
font_name = "arial.ttf" # フォント名(環境によってうまく動かない場合は書き換えること)
lines = s.splitlines()
width = max([len(l) for l in lines]) * 10 + 6
height = len(lines) * 16 + 4
with Image.new(mode="RGB", size=(width, height), color = (255,255,255)) as img:
draw = ImageDraw.Draw(img)
font = ImageFont.truetype(font_name, 12)
draw.text((4, 4), s, fill=(0, 0, 0), font=font)
img.save(file_name)
# 読込
tools = pyocr.get_available_tools()
s = tools[0].image_to_string(Image.open(file_name), lang="eng", builder=pyocr.builders.TextBuilder(tesseract_layout=6))
print(s)
handle_ocr("Hoge")
出力例
講評
100%の精度は出せず、たまに誤読をする。
誤認識をする、処理速度が遅い、データサイズが大きいという三拍子が揃ったドジっ子属性を持っているが、それすらも愛おしく思う慈愛あるプログラムならばこの方式でデータを保存するのも許容できるだろう。
ちなみにこの方式を採用する利点がひとつある。
「このプログラムはAIを利用しています」と言い張れることだ。
平面上の点
1mの棒に1本の切れ目を入れればあらゆる整数を表現できる理論をご存知だろうか。
例えば棒のど真ん中(0.5m)に切れ目を入れると5.0を表現できる。
そのさらに半分の1/4(0.25m)に切れ目を入れると52.0を表現し、さらに半分の1/8(0.125m)なら521.0を、1ミクロン(0.000001m)なら100000.0を表現できるのだ。
切れ目の幅や分子の大きさを考慮しなければあらゆるデータを収められる。そう、例え世界中の愛の数であっても!
※つまり愛の数は有限の数だと解釈している。無理数ではない。
結局分割できる最小サイズには限りがあるものの、16ピクセルの棒があれば1つの点で16種類の値を表現できる。
16ピクセルの棒を16個縦に積めば1つの点で16×16=256種類の値を表現できるのだ。
そう、1バイトの値は1辺を16分割した格子状の図形の1点に保存できるという訳だ。
サンプル(pillow)
実行前にpip install pillowしておくこと。
コード(1バイト)
def handle_dot(s: str, file_name: str = "sample_dot.png"):
from PIL import Image
import itertools
# 保存
img = Image.new(mode="1", size=(16, 16), color = 1) # mode="1"は白黒二値
pos = int(s.encode("ascii")[0])
img.putpixel((pos % 16, pos // 16), 0)
img.save(file_name)
# 読込
with Image.open(file_name) as img:
for pos in itertools.product(range(16), repeat=2): # 16x16の順列で座標を得る
c = img.getpixel(pos)
if c == 0:
i = pos[0] + pos[1] * 16
b = bytes([i])
print(b.decode("ascii"))
break
handle_dot("H")
コード(4バイト)
上は黒点だけど、赤色を256段階の3次元座標、緑色を4次元座標、青色を5次元座標と解釈すると4バイトも表現できる!
(0x00、0xFFを含む文字列を考慮しないテキトー処理)
def handle_dot2(s: str, file_name: str = "sample_dot2.png"):
from PIL import Image
import itertools
# 保存
img = Image.new(mode="RGB", size=(16, 16), color = (255,255,255))
bs = s.encode("sjis")
pos = int(bs[0])
rgb = [0, 0, 0]
for i in range(1, 4):
if len(bs) <= i:
break
rgb[i-1] = int(bs[i])
img.putpixel((pos % 16, pos // 16), tuple(rgb))
img.save(file_name)
# 読込
with Image.open(file_name) as img:
for pos in itertools.product(range(16), repeat=2): # 16x16の順列で座標を得る
c = img.getpixel(pos)
bs = []
if c != (255,255,255):
i = pos[0] + pos[1] * 16
bs.append(i)
rgb = list(c)
for i in range(3):
# rgb要素に0が出たらそれ以降の文字はないと判断する
if rgb[i] == 0:
break
bs.append(rgb[i])
b = bytes(bs)
print(b.decode("sjis"))
break
handle_dot2("採用")
出力例
左が"H"、右が"採用"。


講評
このフォーマットならば方眼紙と絵の具でデータを保存できる画期的な方式だ!
アナログだと色落ちしてデータが変わる致命的な欠点があるので、題名などを書き加えて冗長性を確保しよう。
ステガノグラフィー
ステガノグラフィーというファイルにデータを隠ぺいする手法がある。
png画像のドットあたりの色情報を少しだけ書き換えて、目視では違いが分からないように画像に情報を埋め込むのだ。
サンプル(stegano)
実行前にpip install steganoしておくこと。
画像はいらすとやから水槽の脳のイラストをお借りした。
コード
def handle_stegano(s: str, src_file_name = "brain_nou_suisou_denkyoku.png", dst_file_name = "brain_nou_stegano_denkyoku.png"):
from stegano import lsb
import base64
# 保存
s = base64.b85encode(s.encode("utf8")).decode("ascii") # 日本語が文字化けしたのでbase85化
secret = lsb.hide(src_file_name, s)
secret.save(dst_file_name)
# 読込
s = lsb.reveal(dst_file_name)
s = base64.b85decode(s.encode("ascii")).decode("utf8")
print(s)
handle_stegano("Hoge/ふが\n#\tピヨ")
出力例
1枚目がステガってない画像(50%縮小)。2枚目がステガった画像。
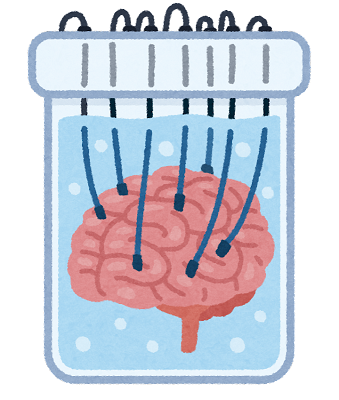
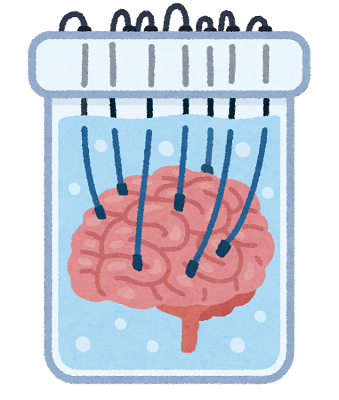
講評
全然違い分からないでしょ。
ステガノグラフィー自体は古くからある技術なので善悪はないけど、セキュリティソフトは画像に情報が埋め込まれているかを判断しにくいため、実際のウィルスやマルウェアがこの手法を使用して重要な個人情報やパスワードなどの漏えいに利用してる。
詳しくはMcAfee Labs脅威レポート: 2017年6月(pdf)のp.37-p.47を参照のこと。
ところで「いらすとや ステガノグラフィ」でイメージ検索したら、水槽の脳のイラストがトップに出てきたんだけど、なんで?
LocalStack編
ローカル環境に保存するのが目的なので、AWSとかクラウドは対象外である。
しかしローカル環境のクラウドなら良かろうなのだ!
ということで、ローカル環境でAWSっぽい機能を使えるLocalStackを使って、クラウドサーバをローカルクライアントに構築するよ。
下記の雑な下準備を行ったからメモっておくね。
- VirtualBoxでも何でも使ってUbuntuを立ち上げる
- Ubuntu 20.04へのDockerのインストールおよび使用方法に従ってDockerを入れる
-
LocalStackのInstallingに従って
pip install localstackする
※sudo pip installしちゃダメと書いてあったので注意 - この後の処理でリージョンなどを指定しないとエラーになったのでプロファイルの設定をする
$ awslocal configure --profile localstack
AWS Access Key ID [None]: dummy
AWS Secret Access Key [None]: dummy
Default region name [None]: us-east-1
Default output format [None]: text
-
localstack start -dで起動する - クライアントからLocalStackにアクセスするため
pip install boto3する
ほらそこ!
「LocalStack許したらなんでもアリじゃん」とか言わない!
心に秘めといて!!
SQS
SQSというメッセージキューイングサービスで文字列を保存できる。
キューとスタックの違いはテストに出るので、忘れちゃったプログラマーさんは復習しておこう。
サンプル(boto3)
コード
def handle_sqs(s: str, endpoint_url="http://localhost:4566/"):
import boto3
q_name = "my-queue"
dic = {"region":"us-east-1", "key_id":"dummy", "secret":"dummy"}
# 保存
sqs = boto3.resource("sqs", aws_access_key_id=dic["key_id"], aws_secret_access_key=dic["secret"], region_name=dic["region"], endpoint_url=endpoint_url)
try:
queue = sqs.get_queue_by_name(QueueName=q_name)
except:
queue = sqs.create_queue(QueueName=q_name)
queue.send_message(MessageBody=s)
# 読込
sqs = boto3.resource("sqs", aws_access_key_id=dic["key_id"], aws_secret_access_key=dic["secret"], region_name=dic["region"], endpoint_url=endpoint_url)
msg = queue.receive_messages()[0]
s = msg.body
msg.delete() #取ってきたキューは消す
print(s)
handle_sqs("Hoge#ふが/ピヨ")
ちなみに手元の環境でboto3.resourceのregion_nameを設定しなかった場合はNoRegionErrorが発生したのだ。
botocore.exceptions.NoRegionError: You must specify a region.
同様にboto3.resourceのaws_access_key_idとaws_secret_access_keyを設定しなかった場合はNoCredentialsErrorが発生したのだ。
botocore.exceptions.NoCredentialsError: Unable to locate credentials
出力例
省略
講評
boto3を使うと簡単にキューを使えるし、LocalStackもけっこう簡単に構築できる。
ちなみにFIFO方式を使わないと順序保障されなくてデータを取ってきてもdeleteしないと消えないとか、それってキューなの?って気がしないでもない点がポイント。
そもそも設定とかの保存にキューイングするのは通常の用途外な点も見逃せないんだけどね。
通常設定だと4日で消える設定を保存したかったり、設定を読み込んでdeleteすると過去の設定が復活したりする謎仕様のツールを作りたい方にお勧めだから使ってみてね。
闇鍋編
記事数を増やすためのちょっとした技術Tipsから無理やりひねり出したカオスな方法まで様々なごった煮。
もちろん闇鍋に水増ししても味はどうしようもない。
機械学習
機械学習によって、パソコンに学習させた後にパラメータを渡すことで予想や判断させることができる。
例えば「長さ:110mm、価格:10セント=おいしい棒」、「長さ:85mm、価格:60セント=ガリガリさん」など、[長さ、価格]という数値のパラメータに対して正解のラベル("おいしい棒"など)を教えるとしよう。
学習済みのパソコンに対して「長さ=112mm、価格=12セントの物体は何?」と聞くと、パソコンは「それはおいしい棒です。確度は90%です」のように答えてくれる。これが「教師あり学習、分類」と呼ばれる機械学習だ。
長さと価格は時代や為替相場によって変動するため、何百個何千個も計測してパソコンに教えた方が正解率が上がるわけだ。
さて、もしも「人数:9人=野球」とだけパソコンに学習させたとしよう。
その時に「人数:11人のスポーツは何?」と聞くと、「それは野球です」と回答する。それ以外何も知らないのでサッカーと答えようがない。
つまり1つしかラベルを渡していない機械学習を行えば、パラメータに何を渡してもそのラベルを返してくれる。そう、ラベルに設定した任意の文字列を保存できる寸法だ!
サンプル(sklearn)
コード
あらかじめpip install sklearnしておくこと。
def handle_learn(s: str, file_name: str = "sample.skl"):
import numpy as np
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
import joblib
# 保存
knc = KNeighborsClassifier(n_neighbors=1)
knc.fit(np.array([[1]]), np.array([s])) # "1"がsだということを分からしめる(学習)
joblib.dump(knc, file_name)
# 読込
knc = joblib.load(file_name)
pdc = knc.predict(np.array([[1]])) # "1"が何か…分かるね?(予測)
s = str(pdc[0])
print(s)
handle_learn("Hoge/ふが\n#\tピヨ")
出力例
省略
講評
knc.predict(np.array([[1]])) の1を100などの全く異なる数値に書き換えても同じ結果が出るので、たった一つの文字列学習に成功している。
学習済みデータの保存にはjoblibという機械学習で頻出する並列処理向けのライブラリを使用した。
なお筆者は機械学習について学習していないため、何一つ質問に答えられないのであしからず。
モールス符号.wav
音声を使ってデータを保存できることは想像しやすいだろう。
マイコン全盛期には本当に音声でデータを保存していたらしい。
参考資料: データ保存はカセットテープがあたりまえだった
ここでは「パンチカード」「カセットテープ」「机上デバッグ」という古の神器を扱わないが、データ符号化の手法として著名なモールス符号と音声出力の組み合わせくらいは扱っておく。
サンプル(pyMorseTranslator, numpy)
実行前にpip install pyMorseTranslator numpyしておくこと。
コード
def handle_morse(s: str, file_name = "sample.wav"):
import numpy as np
import math, wave, struct
from pyMorseTranslator import translator
SAMPLE_RATE = 44100
CYCLE_RATE = int(SAMPLE_RATE / 2) # 0.5秒を1サイクルとして短点、長音、無音のいずれかを配置する
DOT_RATE = int(CYCLE_RATE / 3) # 短点の長さ(1サイクルの1/3)
DASH_RATE = int(CYCLE_RATE * 2 / 3) # 長音の長さ(1サイクルの2/3)
DOT_FREQ = 777 # 短点の周波数
DASH_FREQ = 666 # 長音の周波数
VOLUME = 25000 # 音量(0-32767)
# 出力
encoder = translator.Encoder()
morse = encoder.encode(s).morse
#print(morse)
with wave.open(file_name,'wb') as file:
file.setnchannels(2)
file.setsampwidth(2)
file.setframerate(SAMPLE_RATE)
file.writeframesraw(np.zeros(int(SAMPLE_RATE / 2))) # 1秒無音
for m in morse:
if m == " ":
file.writeframesraw(np.zeros(int(CYCLE_RATE / 2)))
continue
fq = DOT_FREQ if m == "." else DASH_FREQ
rate = DOT_RATE if m == "." else DASH_RATE
for i in range(rate):
value = int(VOLUME * math.sin(2 * fq * math.pi * float(i) / float(rate)))
data = struct.pack('<hh', value, value)
file.writeframesraw(data)
file.writeframesraw(np.zeros(int((CYCLE_RATE - rate) / 2)))
file.writeframesraw(np.zeros(int(SAMPLE_RATE / 2))) # 1秒無音
# 読込
with wave.open(file_name,'rb') as file:
l = []
while file.tell() < file.getnframes() - CYCLE_RATE*2:
m_dot = np.max(np.frombuffer(file.readframes(DOT_RATE), dtype='int16'))
m_dash = np.max(np.frombuffer(file.readframes(DOT_RATE), dtype='int16'))
_ = np.max(np.frombuffer(file.readframes(DOT_RATE), dtype='int16'))
if m_dash > VOLUME / 2:
l.append("-")
elif m_dot > VOLUME / 2:
l.append(".")
else:
l.append(" ")
morse = "".join(l).strip()
decoder = translator.Decoder()
s = decoder.decode(morse).plaintext
print(s)
handle_morse("Hoge") # 英数字のみ(記号不可) ※小文字を入力しても大文字で出力される
出力例
省略(再生時の音量注意)
講評
見つけたライブラリが英数字にしか対応してないが、そもそもコンセプト自体がネタなので、古来より言い伝えられた「許してちょんまげ」の精神でご寛恕願いたい。(環境によって動かない時も許してヒヤシンス)
Base64
Base64という、バイナリデータを文字列に変換する方式をご存じだろうか。
ファイルや画像データをメールで送る場合やHTMLに埋め込む場合に使用する。
この形式を使えばあらゆるデータを簡単に文字列化して保存できる。
pythonの標準機能で扱える。
サンプル(base64.b64encode)
コード
def handle_base64(s: str, file_name: str = "sample_base64.txt"):
import base64
# 保存
with open(file_name, "wb") as f:
bytes = base64.b64encode(s.encode("utf8")) # 任意のバイト配列をbase64のバイト配列に変換する
f.write(bytes)
# 読込
with open(file_name, "rb") as f:
bytes = f.read()
s = base64.b64decode(bytes).decode("utf8")
handle_base64("Hoge/ふが\n#\tピヨ")
出力例
SG9nZS/jgbXjgYwKIwnjg5Tjg6g=
講評
出力例の通りそこそこの長さでデータをエンコードして出力できる。
pickleより他言語のプログラムとの連携がしやすいし、ユニコードのURLエンコードより長さは圧縮できるから割り切って使えば登場の機会があるかも。
ただし一般人にとって可読性は皆無。
ファイル名
ファイル名とは文字列である。
つまり中身が空(0バイト)のテキストファイルを作ってファイル名にデータを保存することができる。
空ファイルのファイル名でローカルデータを保存すれば、すなわち無限にデータが保存できるのだ!
※もちろん実際にはOSのファイル管理領域が消費されている。
サンプル(base64.urlsafe_b64encode)
ファイル名に/などの特殊な文字や改行は使えないため、今回はURLにも使えるBase64の亜種であるurlsafe_b64encodeを使用する。
特定のプレフィックスから始まるファイル名を設定ファイルとして、更新日が最新のファイルからデータを取得する。
コード
def handle_base64_filename(s: str, prefix = "sample_base64_"):
import base64, pathlib, os
from glob import glob
# 保存
file_name = prefix + base64.urlsafe_b64encode(s.encode("utf8")).decode()
pathlib.Path(file_name).touch() # 中身が空のファイルを作成
# 読込
fs = glob(f"{prefix}*")
f = sorted(fs, key=lambda x : os.path.getmtime(x), reverse=True)[0] # 最新のファイル取得
s = f[len(prefix):]
s = base64.urlsafe_b64decode(s).decode()
print(s)
handle_base64_filename("Hoge/ふが\n#\tピヨ")
出力例
「sample_base64_SG9nZS_jgbXjgYwKIwnjg5Tjg6g=」というファイルができる
講評
技術的には使える。使えるけどまるで役に立たない雰囲気を楽しむのが吉。
地味にpathlib.Path(file_name).touch()で空ファイルを作れるとか、sorted(fs, key=lambda x : os.path.getmtime(x), reverse=True)[0]で最新のファイルを取得できるとかのTipsの方が役に立つかもしれない。
Whitespace風
Whitespaceというネタ言語をご存じだろうか。
空白とタブ文字、改行のみを用いたソースコードでチューリング完全なプログラムを組めるというプログラム界の白眉(=スーパーハッカー)が考えた構文である。
当然ソースコードには空白とタブ文字、改行しかないので、メモ帳で開いても真っ白である。
BrainF*ckという難解プログラミング言語の亜種と言えば何となく分かる人もいるだろうか。
サンプル(bin, str.maketrans)
サンプルコードは一見Whitespace風のファイル出力をしているが、文字列を2進数に変換して0をスペースに、1をタブ文字に、文字の区切りを改行にしているだけである。
Whitespaceとは互換性が全くないのであしからず。
コード
def handle_whitespace(s: str, file_name: str = "sample_ .txt"):
# 保存
ss = []
table = str.maketrans("01", " \t") # 文字列変換表
for c in s:
b = ord(c)
# 2進数に変換
s = bin(b)[2:] # 接頭辞の "0b"を除去
s = s.translate(table)
ss.append(s)
with open(file_name, "w") as f:
f.write("\n".join(ss))
# 読込
ss = []
table = str.maketrans(" \t", "01") # 文字列変換表
with open(file_name, "r") as f:
for line in f.readlines():
line = line.translate(table)
s = chr(int(line, 2))
ss.append(s)
print("".join(ss))
handle_whitespace("Hoge#ふが/ピヨ")
出力例
講評
このように8月30日の私の宿題のような出力例でもしれっと動くからこの方式を見た人はホワイというかもしれない。
ことほど左様に白銀のゲレンデがごとく滑りがちな一発芸のコードなので、実業務で使うとシラーっとした雰囲気になること請け合いである。
セリフが白々しい?しらんがな。
Grass風(外部プログラム呼び出し)
Grassという難解プログラミング言語もある。
こちらはwとWとvの3文字のみを使っている。
Whitespace風は空白とタブの2進数で表現していたが、Grass風のサンプルコードは3進数を使っている。
このように出力を難読化する方法はほむほむや【Brainfuck】Brainfuck系のインタプリタを作る【Python3】やBrainf*ckライクなオリジナルネタ言語を作って遊んでみようなど無限に考えられるので、手っ取り早くn進数を使った文字列置換を提示してみた。
難読化だけではアルゴリズム的に代り映えしないので、他言語で作られた処理系を呼び出すという意味でsubprocessによる外部プログラム呼び出しにしよう。
こちらもGrassとの互換性は皆無。
サンプル(subprocess, str.maketrans, np.base_repr)
実行前にpip install numpyしておくこと。
外部プログラムコード
あらかじめsample_grasslikeフォルダを作り、その中に下記のsample_grasslike.pyを保存する。
import numpy as np
import sys
def read_grasslike(file_name: str):
# 読込
ss = []
table = str.maketrans("wWv", "012") # 文字列変換表
with open(file_name, "r") as f:
for line in f.readlines():
line = line.translate(table)
s = chr(int(line, 3))
ss.append(s)
print("".join(ss))
def write_grasslike(s: str, file_name: str):
# 保存
ss = []
table = str.maketrans("012", "wWv") # 文字列変換表
for c in s:
b = ord(c)
# 3進数に変換して文字列化
s = str(np.base_repr(b, 3))
s = s.translate(table) # 草を生やす
ss.append(s)
with open(file_name, "w") as f:
f.write("\n".join(ss))
def main():
args = sys.argv
help = """Usage:
[WRITE]$ python sample_grasslike.pyz -w {text} {file_name}
[READ] $ python sample_grasslike.pyz -r {file_name}
"""
if len(args) < 2:
print(help)
return
if args[1] == "-w":
file_name = "sample_grass.txt" if len(args) == 3 else args[3]
write_grasslike(args[2], file_name)
elif args[1] == "-r":
file_name = "sample_grass.txt" if len(args) == 2 else args[2]
read_grasslike(file_name)
else:
print(help)
上記プログラムを外部プログラムにするため、pythonのzipappで実行可能なモジュール化する。
コマンドは以下。
python -m zipapp .\sample_grasslike -m sample_grasslike:main
これで.\sample_grasslikeフォルダをモジュール化し、-m sample_grasslike:main引数でsample_grasslike.pyのmain関数をメインモジュールとして実行可能としている。
実行コード
コマンドで作成した.\sample_grasslike.pyzモジュールを呼び出す処理は前述の通りsubprocessで行う。
def handle_grasslike(s: str, file_name: str = "sample_grass.txt"):
import subprocess
exe_name = "python"
# 保存
subprocess.run([exe_name, "sample_grasslike.pyz", "-w", s, file_name])
# 読込
res = subprocess.run([exe_name, "sample_grasslike.pyz", "-r", file_name], stdout=subprocess.PIPE)
s = res.stdout.decode("utf8") # 標準出力をUTF-8として読み込む
print(s)
handle_grasslike("Hoge#ふが/ピヨ")
出力例
vvww
WWwWw
WwvWW
Wwvwv
Wwvv
WvvwwwWWw
WvWvvWvvW
Wvwv
WvvwWwvvv
WvvwWWvwW
講評
数値のn進数化はint関数で簡単にできる。
zipappを使ったことのない人も多いかと思うが、pythonが入っている環境で手軽にモジュールを作れる手段が存在することを頭に入れておくのは良いことだろう。
ただし、やはりこの処理系を実務で投入するのは草も生えない行為としか言いようがない。
職を失って翌日から荒野行動する羽目になりたくなければ、枯れた技術を採用して製品のワランティを確保しようwww
Gitコミットログ
Gitを使えばローカルでも簡単に履歴管理ができる。
履歴をコミットする時はコミットログを保存することになる。
そしてGitはgit commit --allow-emptyのようなオプションでファイル更新を伴わない空コミットができる。
GitPythonを使えばオプションなしで空コミットできるし、最新のコミットログを取得することも簡単にできる。
あとは…分かるね?
サンプル(git)
コード
Gitを扱うためにpip install GitPythonしておくこと。
# dir_name を既存のフォルダにする場合はあらかじめ git init しておくこと(存在しないフォルダの場合は対応不要)
def handle_git(s: str, dir_name: str = "sample_git"):
import pathlib
import git
# 保存
p = pathlib.Path(dir_name)
if not p.exists():
# 新規作成
p.mkdir(parents=True)
with git.Repo.init(p, bare=True) as repo:
repo.index.commit(s)
else:
# フォルダが存在する時は git init 済みと判断して処理する
with git.Repo(dir_name) as repo:
repo.index.commit(s)
# 読込
with git.Repo(dir_name) as repo:
print(repo.head.commit.message)
出力例
git log はこんな感じで累積していく。
$ git log
commit 1a213ba78916f238a0971c9e85f55c1234567890 (HEAD -> master)
Author: payaneco <payaneco@payaneco>
Date: Tue Oct 18 21:54:41 2022 +0900
Hoge#ふが/ピヨ
講評
履歴管理ができると変更前のデータを復元するのが容易なので、使おうと思えば使える方式ではある。
ただしコミットログでデータ管理するのは控えめに言って噴飯ものだからお勧めしない。ちゃんとファイルで履歴管理しよう。
あとこの方式を採用した場合に、上司が「プログラムをリリースした後に顧客環境でGitをデータ保存に使うの?正気?」とプンプン者になっても知らないよ。
Cookie
ここで言うCookie(クッキー)は食べ物のことではない。
あ、クッキーが食べ物じゃなきゃクリックするものだと思ったでしょ!
違いますー、ブラウザがデータをローカル保存するものですー。
さて、犬も食わない茶番はともあれ、python はクッキーを保存したりロードしたりできる。
そしてそれはネットにつながずともローカルで完結できる。
つまりローカル保存に使えるということだ!
サンプル(requests.session().cookies, pickle)
実行前にpip install requestsしておくこと
コード
def handle_cookie(s: str, file_name = "sample_cookie.dat"):
import requests
import pickle
# 保存
with requests.session() as session:
cookies = session.cookies
cookies["value"] = s
with open(file_name, 'wb') as f:
pickle.dump(cookies, f)
# 読込
with open(file_name, "rb") as f:
cookies = pickle.load(f)
print(cookies["value"])
handle_cookie("Hoge/ふが\n#\tピヨ")
講評
クッキーはブラウザごとに決まった場所へ保存してるけど、requestsはそういうのないから結局pickleで保存してる。
参考資料: How to save requests (python) cookies to a file?
最初はローカルサーバ立てて通信しようかと思ったけど、超簡単にクッキー使えて驚いた。
でもわざわざクッキーを漬物(pickle)にしても美味しくなさそうと思いました。
レジストリ
レジストリでも大丈夫。そう、pythonならね。
とはリンゴ社の人が言いそうにない台詞だけど、実際にpython の標準機能で簡単に扱えるよ。
サンプル(winreg)
コード
# value_nameは重複しなそうな名前を設定している
def handle_registry(s: str, value_name = "sample_registry_d8aa1dab4f4711edbf26f8b46af89075"):
import os
if os.name != "nt":
print("Windowsではありません")
return
import winreg
path = r"SOFTWARE"
# 保存
with winreg.OpenKeyEx(winreg.HKEY_CURRENT_USER, path, access=winreg.KEY_WRITE) as key:
winreg.SetValueEx(key, value_name, 0, winreg.REG_BINARY, s.encode("utf8"))
# 読込
key = winreg.OpenKeyEx(winreg.HKEY_CURRENT_USER, path)
data, _ = winreg.QueryValueEx(key, value_name)
s = data.decode("utf8")
print(s)
# 削除
with winreg.OpenKeyEx(winreg.HKEY_CURRENT_USER, path, access=winreg.KEY_SET_VALUE) as key:
winreg.DeleteValue(key, value_name)
handle_registry("Hoge/ふが\n#\tピヨ")
出力例
省略
講評
よほどの理由がなければ使わないよね。レジストリ。
下手なキーを消すと本当にWindows動かなくなるって脅されるし。
どの方式を使うか、Windowsにこだわるのかであなたは試されている。
偉い人が「レジストリを捨てるかで誇りが問われ、レジストリを守るかで愛情が問われる」って言ってたでしょう?
言ってない?そっか。
RPA
データを保存するのに「ファイルをオープンして」とか「辞書を作って」とか小難しいことはいらない。
「Windows標準のメモ帳を開いて、文字列を貼り付けて保存すればいいじゃないか!
シンプルに行けよ。若いのに頭固いぞ!ガハハ!」
などと発言するロートルだかトロールだか分からない人がいた時に、その通りにする方法としてRPAが使える。
サンプル(pyautogui, pyperclip)
実行前にpip install pyautogui pyperclipをしておくこと。
メモ帳を起動するのでWindows以外のユーザは使えない。
コード
def handle_auto(s: str, file_name = "sample_auto.txt"):
import os
if os.name != "nt":
print("Windowsではありません")
return
import pyautogui
import pyperclip
import subprocess
import time
import pathlib
if pyautogui.getWindowsWithTitle("メモ帳"):
print("メモ帳を閉じてから実行してください")
return
# 保存
p = subprocess.Popen("notepad.exe")
# Notepad起動待ち(2秒)
for _ in range(10):
if pyautogui.getWindowsWithTitle("メモ帳"):
break
time.sleep(0.2)
if not pyautogui.getWindowsWithTitle("メモ帳"):
print("メモ帳が起動していません")
return
# 文字列貼り付け
pyperclip.copy(s)
pyautogui.hotkey('ctrl', 'v')
# 名前を付けて保存
pyautogui.hotkey('ctrl', 's')
path = pathlib.Path(file_name).resolve()
# 既存ファイル削除
path.unlink(missing_ok=True)
pyperclip.copy(str(path))
time.sleep(1)
pyautogui.hotkey('ctrl', 'v')
time.sleep(0.2)
pyautogui.press('enter')
time.sleep(0.2)
pyautogui.hotkey('alt', 'f4')
p.wait()
# 読込
path = pathlib.Path(file_name).resolve()
p = subprocess.Popen(["notepad.exe", path])
# Notepad起動待ち(2秒)
for _ in range(10):
if pyautogui.getWindowsWithTitle("メモ帳"):
break
time.sleep(0.2)
if not pyautogui.getWindowsWithTitle("メモ帳"):
print("メモ帳が起動していません")
return
time.sleep(0.2)
pyautogui.hotkey('ctrl', 'a')
time.sleep(0.2)
pyautogui.hotkey('ctrl', 'c')
time.sleep(0.2)
pyautogui.hotkey('alt', 'f4')
p.wait()
s = pyperclip.paste()
print(s)
handle_auto("Hoge/ふが\n#\tピヨ")
出力例
Hoge/ふが
# ピヨ
講評
普通にメモ帳を開いて保存し、メモ帳を開いてクリップボードからデータを復元できただろうか。
RPA自体はもう古くなりつつある技術トピックだが、2,3手の単純操作を繰り返す操作であればpythonからそこそこ容易に実現できる。
処理内容の分岐や画像認識による処理が絡んでくると成功率が加速度的に低下する上に、保守も面倒な遺物があっという間に出来上がる。
そうなる前に「オー人事オー人事」を検討するのが吉。
※このネタが分かる人は、自分自身がロートルとならないように頑張ろう(自戒)
ディップスイッチ
IoTを使えば文字情報を物理層に保存することができる。
例えばこの写真を見てほしい。

Raspberry Pi Picoと1-10ポジションのディップスイッチ(中央の白黒スイッチ)をブレッドボードにつないだだけの雑な工作だ。
しかし考えてほしい。
このディップスイッチは0と1を切り替えることができる。
スイッチを8個使えば0から255までの任意の数値を保存できるのだ。
そう、1バイト記録媒体(物理)である!
つまり「大変だ!英数字1文字だけ保存したいのに、ラズパイPicoとディップスイッチしかない!」という時に役立つ可能性があるかもしれない。
サンプル(Raspberry Pi Pico, machine.Pin)
使う前にRaspberry Pi Picoのセットアップと工作が必要なので、公式サイトのmicropythonの手順に従ってセットアップしよう。
物理層は Raspberry Pi Pico、KSD102、ジャンパーケーブル(オス-オス 8個、オス-メス 2個)、ブレッドボード、USBケーブル タイプB を用意した。
ぶっちゃけ8個のスイッチと配線があれば何でもよい。
オス-メスのケーブルを使って、36番3V3とブレッドボードの+極をつなぎ、38番GNDとブレッドボードの-極をつなぐ。
そしてオス-オスのケーブルで+極と1番GP0から10番GP7をつなぐように見せかけてディップスイッチをブリッジ役とすれば準備完了だ。
3番と8番はGNDなのでつながないこと。
全然IoTしない人はサッパリ分からないと思うが許してチョーネンテン。
Raspberry Pi Picoのソースコード
from machine import Pin
import utime
tmp = 0
while True:
c = 0
l = []
for i in range(10):
if machine.Pin(i, machine.Pin.IN, machine.Pin.PULL_DOWN).value() == 1:
c += 2 ** i
if tmp != c:
print(chr(c))
tmp = c
utime.sleep(0.5)
このソースコードのfor文で各GPのオンオフを読み取ってビット演算してるだけの単純な仕組みである。
2進数をascii化してprint文でシリアルポートから出力している。
ただし、asciiをスイッチに反映させる手順が分かりにくいので、ちょっとした変換ツールを作っておこう。
変換ツールのソースコード
def handle_dip(s: str, file_name: str = "sample.csv"):
# 保存
c = s.encode("ascii")[0]
s = ""
# 2進数化
while c != 0:
s += str(c & 1)
c = c >> 1
s = s.ljust(8, '0') # ゼロ埋め
s = s[0:2] + "0" + s[2:6] + "0" + s[6:] # GND部分を埋める
s = s.replace("1", "上").replace("0", "下") # 分かりやすく
print("".join([str(i+1).rjust(2, " ") for i in range(10)]))
print(s)
handle_dip("s")
上のコードの実行結果はこうなる。
1 2 3 4 5 6 7 8 910
上上下下下上上下上下
※等幅フォントだと数値と「上下」がズレなく表示される
この指示に従ってディップスイッチを動かすと、コンソールに"s"が表示され、データを復元することができる。
講評
うわぁぁぁん!疲れたもぉぉぉ!
IoTなんて門外 of 漢なのに、この記事のためだけに押入れからRaspberry Pi Picoを出して半日を費やした。
「ラズパイとそれを読み込む媒体があるなら、もうラズパイにデータ仕込んじゃえよ」とか「スイッチじゃなくてメモ帳でよくね?」とは言ってはいけない。
本人はこれでも頑張ったのだ。
おわりに
いかがでしたか?
とてもしょーもない記事だと感じた方の感性は正常だよ!
長すぎて全部飛ばした方の行動は多分マジョリティだよ!
ただ、約2週間の土日と深夜をほとんど費やして約40種類のサンプルコードを全部書き上げるのにすごくがんばったことは事実だから、せめて「くだらないことに全力を尽くしてえらいね!」って自分を褒めさせてもらうね。
※語尾とかテンションがバラバラなのはそのせい
全記事を書いた感想だけど、pythonとpipパッケージの汎用性に驚いたよ。
何度も「短いコードでこんなことまでできるの!?」ってなったからね。
ローカル環境にテキストデータを保存して復元するフォーマットとか手法をここまで網羅的に集めた記事はあんまり多くないんじゃないかな。
もしあなたが「あー、設定の保存方式どうすっかなー。jsonとモールス符号どっちが良いかなー」って迷った時の参考になれば嬉しいな。
それじゃ、プログラムや時節、上司に最適な手法を選定してね!