コンペティションの概要
このコンペティションでは、7049枚の顔画像データそれぞれに対して、顔を特徴付ける15の部分のx, y座標がトレーニングデータとして与えられています。(例:左目の中心のx座標、右目の中心のy座標など)
そのデータを学習し、テストセットの画像に対して顔を特徴付ける部分の座標を与えるというものです。
早速始めていきます。
import pandas as pd
import numpy as np
import zipfile
import tensorflow as tf
与えられているデータ
トレーニングデータ
zipファイルを解凍し、開きます。
with zipfile.ZipFile('training.zip') as existing_zip:
with existing_zip.open('training.csv') as traincsv:
train=pd.read_csv(traincsv)
train
| left_eye_center_x | left_eye_center_y | right_eye_center_x | right_eye_center_y | ... | mouth_center_top_lip_y | mouth_center_bottom_lip_x | mouth_center_bottom_lip_y | Image | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6.033564 | 39.002274 | 30.227008 | 36.421678 | ... | 72.935459 | 43.130707 | 84.485774 | 238 236 237 238 240 240 239 241 241 243 240 23... |
| 1 | 64.332936 | 34.970077 | 29.949277 | 33.448715 | ... | 70.266553 | 45.467915 | 85.480170 | 219 215 204 196 204 211 212 200 180 168 178 19... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7047 | 70.965082 | 39.853666 | 30.543285 | 40.772339 | ... | NaN | 50.065186 | 79.586447 | 254 254 254 254 254 238 193 145 121 118 119 10... |
| 7048 | 66.938311 | 43.424510 | 31.096059 | 39.528604 | ... | NaN | 45.900480 | 82.773096 | 53 62 67 76 86 91 97 105 105 106 107 108 112 1... |
7049×31のデータです。
データの最終列は画像データで、それ以外は顔のある部分を示すx, y座標となっています。
また、欠損値もあるようです。どのくらいあるのでしょうか。
train.isnull().sum()
left_eye_center_x 10
left_eye_center_y 10
right_eye_center_x 13
right_eye_center_y 13
left_eye_inner_corner_x 4778
left_eye_inner_corner_y 4778
left_eye_outer_corner_x 4782
left_eye_outer_corner_y 4782
right_eye_inner_corner_x 4781
right_eye_inner_corner_y 4781
right_eye_outer_corner_x 4781
right_eye_outer_corner_y 4781
left_eyebrow_inner_end_x 4779
left_eyebrow_inner_end_y 4779
left_eyebrow_outer_end_x 4824
left_eyebrow_outer_end_y 4824
right_eyebrow_inner_end_x 4779
right_eyebrow_inner_end_y 4779
right_eyebrow_outer_end_x 4813
right_eyebrow_outer_end_y 4813
nose_tip_x 0
nose_tip_y 0
mouth_left_corner_x 4780
mouth_left_corner_y 4780
mouth_right_corner_x 4779
mouth_right_corner_y 4779
mouth_center_top_lip_x 4774
mouth_center_top_lip_y 4774
mouth_center_bottom_lip_x 33
mouth_center_bottom_lip_y 33
Image 0
めちゃくちゃありますね…。
テストデータ
こちらもzipファイルを解凍し、開きます。
with zipfile.ZipFile('test.zip') as existing_zip:
with existing_zip.open('test.csv') as testcsv:
test=pd.read_csv(testcsv)
test
| ImageId | Image | |
|---|---|---|
| 0 | 1 | 182 183 182 182 180 180 176 169 156 137 124 10... |
| 1 | 2 | 76 87 81 72 65 59 64 76 69 42 31 38 49 58 58 4... |
| 2 | 3 | 177 176 174 170 169 169 168 166 166 166 161 14... |
| 3 | 4 | 176 174 174 175 174 174 176 176 175 171 165 15... |
| ... | ... | ... |
| 1780 | 1781 | 28 28 29 30 31 32 33 34 39 44 46 46 49 54 61 7... |
| 1781 | 1782 | 104 95 71 57 46 52 65 70 70 67 76 72 69 69 72 ... |
| 1782 | 1783 | 63 61 64 66 66 64 65 70 69 70 77 83 63 34 22 2... |
| こちらは、1783枚の画像データになっています。 |
提出するファイルの形式
他に二つのCSVファイルが与えられていますが、こちらでは提出するファイルの形式が示されています。
df=pd.read_csv("IdLookupTable.csv")
sample=pd.read_csv("SampleSubmission.csv")
df
| RowId | ImageId | FeatureName | Location | |
|---|---|---|---|---|
| 0 | 1 | 1 | left_eye_center_x | NaN |
| 1 | 2 | 1 | left_eye_center_y | NaN |
| 2 | 3 | 1 | right_eye_center_x | NaN |
| 3 | 4 | 1 | right_eye_center_y | NaN |
| 4 | 5 | 1 | left_eye_inner_corner_x | NaN |
| ... | ... | ... | ... | ... |
| 27119 | 27120 | 1783 | right_eye_center_y | NaN |
| 27120 | 27121 | 1783 | nose_tip_x | NaN |
| 27121 | 27122 | 1783 | nose_tip_y | NaN |
| 27122 | 27123 | 1783 | mouth_center_bottom_lip_x | NaN |
| 27123 | 27124 | 1783 | mouth_center_bottom_lip_y | NaN |
IdLookupTable.csvは、1783枚の画像それぞれに対して提示して欲しい座標を示しています。
このコンペの厄介なところは、トレーニングデータでは30個の顔の部分の座標が与えられていますが、テストデータの画像に対しては必ずしもその全ての座標を予測する必要はないというところです。
具体的に、提出ファイルに含まれる各座標の個数を確認します。
df["FeatureName"].value_counts()
nose_tip_y 1783
nose_tip_x 1783
left_eye_center_x 1782
right_eye_center_y 1782
left_eye_center_y 1782
right_eye_center_x 1782
mouth_center_bottom_lip_x 1778
mouth_center_bottom_lip_y 1778
mouth_left_corner_x 590
mouth_center_top_lip_y 590
mouth_left_corner_y 590
mouth_center_top_lip_x 590
left_eye_outer_corner_x 589
left_eye_outer_corner_y 589
right_eye_inner_corner_y 589
right_eye_inner_corner_x 589
left_eye_inner_corner_y 588
right_eye_outer_corner_x 588
right_eye_outer_corner_y 588
left_eye_inner_corner_x 588
mouth_right_corner_x 587
mouth_right_corner_y 587
left_eyebrow_inner_end_x 585
right_eyebrow_inner_end_x 585
left_eyebrow_inner_end_y 585
right_eyebrow_inner_end_y 585
left_eyebrow_outer_end_x 574
left_eyebrow_outer_end_y 574
right_eyebrow_outer_end_x 572
right_eyebrow_outer_end_y 572
このように、求められている座標は不規則にばらついています。
次に、提出ファイルのサンプルです。
sample
| RowId | Location | |
|---|---|---|
| 0 | 1 | 0 |
| 1 | 2 | 0 |
| 2 | 3 | 0 |
| 3 | 4 | 0 |
| 4 | 5 | 0 |
| ... | ... | ... |
| 27119 | 27120 | 0 |
| 27120 | 27121 | 0 |
| 27121 | 27122 | 0 |
| 27122 | 27123 | 0 |
| 27123 | 27124 | 0 |
| 提出するデータはシンプルに行番号と27124個の座標の値のみです。 |
学習データの成形
言わずもがな、コンペのメインパートです。
まず、train.csv、test.csvから画像データのみを抽出し、numpy配列にしていきます。
抽出した画像データをnumpy配列にしていくときは、空の配列を用意し、一つずつ代入していくやり方をオススメします。
x_train=np.empty((7049,96,96,1))
x_test=np.empty((1783,96,96,1))
for i in range(7049):
train0=train["Image"][i].split(" ") #i番目の画像配列をスペース区切りで抽出
train1=[int(x) for x in train0] #それぞれをint型に直してリストへ格納
train2=np.array(train1,dtype="float") #リストをnumpy配列へ変換
train3=train2.reshape(96,96,1) #配列を96×96×1へ成形
x_train[i]=train3 #空のnumpy配列のi番目の要素として代入
for i in range(1783):
test0=test["Image"][i].split(" ")
test1=[int(x) for x in test0]
test2=np.array(test1,dtype="float")
test3=test2.reshape(96,96,1)
x_test[i]=test3
x_train =x_train / 255
x_test = x_test /255
train.csvからImageの列を削除したものをy_trainとします。
y_train=train.drop(['Image'],axis=1)
先ほど見た欠損値を処理します。
とりあえず、前の行の値で補完するffillを適用させます。
y_train.fillna(method = 'ffill',inplace = True)
今一度欠損値を確認します。
y_train.isnull().sum()
left_eye_center_x 0
left_eye_center_y 0
right_eye_center_x 0
right_eye_center_y 0
left_eye_inner_corner_x 0
left_eye_inner_corner_y 0
left_eye_outer_corner_x 0
left_eye_outer_corner_y 0
right_eye_inner_corner_x 0
right_eye_inner_corner_y 0
right_eye_outer_corner_x 0
right_eye_outer_corner_y 0
left_eyebrow_inner_end_x 0
left_eyebrow_inner_end_y 0
left_eyebrow_outer_end_x 0
left_eyebrow_outer_end_y 0
right_eyebrow_inner_end_x 0
right_eyebrow_inner_end_y 0
right_eyebrow_outer_end_x 0
right_eyebrow_outer_end_y 0
nose_tip_x 0
nose_tip_y 0
mouth_left_corner_x 0
mouth_left_corner_y 0
mouth_right_corner_x 0
mouth_right_corner_y 0
mouth_center_top_lip_x 0
mouth_center_top_lip_y 0
mouth_center_bottom_lip_x 0
mouth_center_bottom_lip_y 0
Image 0
欠損値がなくなったことが確認できました。
最後に、データを標準化します。
for columns in train_y.columns:
mean.append(train_y[columns].mean())
std.append(train_y[columns].std())
train_y[columns] = (train_y[columns] - train_y[columns].mean()) / train_y[columns].std()
学習
モデルを構築します。
model=tf.keras.models.Sequential([
tf.keras.layers.Conv2D(6,(3,3), activation = 'relu', input_shape=(96,96,1)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(12,(3,3), activation = 'relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation = 'relu'),
tf.keras.layers.Dense(30,activation='relu')
])
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_2 (Conv2D) (None, 94, 94, 6) 60
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 47, 47, 6) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 45, 45, 12) 660
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 22, 22, 12) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 5808) 0
_________________________________________________________________
dense_2 (Dense) (None, 512) 2974208
_________________________________________________________________
dense_3 (Dense) (None, 30) 15390
=================================================================
Total params: 2,990,318
Trainable params: 2,990,318
Non-trainable params: 0
_________________________________________________________________
model.compile(optimizer='adam', loss='mean_squared_error', metrics=['accuracy'])
学習させます。
model.fit(x_train, y_train, epochs = 10)
Train on 7049 samples
Epoch 1/10
7049/7049 [==============================] - 20s 3ms/sample - loss: 470.8903 - accuracy: 0.5540
Epoch 2/10
7049/7049 [==============================] - 19s 3ms/sample - loss: 283.7981 - accuracy: 0.6073
Epoch 3/10
7049/7049 [==============================] - 20s 3ms/sample - loss: 152.0215 - accuracy: 0.6493
Epoch 4/10
7049/7049 [==============================] - 20s 3ms/sample - loss: 151.0923 - accuracy: 0.6866
Epoch 5/10
7049/7049 [==============================] - 19s 3ms/sample - loss: 150.6215 - accuracy: 0.7188
Epoch 6/10
7049/7049 [==============================] - 20s 3ms/sample - loss: 149.9657 - accuracy: 0.7289
Epoch 7/10
7049/7049 [==============================] - 20s 3ms/sample - loss: 149.8715 - accuracy: 0.7371
Epoch 8/10
7049/7049 [==============================] - 19s 3ms/sample - loss: 149.7018 - accuracy: 0.7424
Epoch 9/10
7049/7049 [==============================] - 20s 3ms/sample - loss: 149.4364 - accuracy: 0.7451
Epoch 10/10
7049/7049 [==============================] - 19s 3ms/sample - loss: 149.3164 - accuracy: 0.7510
テストモデルに対して予測させます。
pred = model.predict(x_test)
提出ファイルの作成
ここから少し面倒なのですが、前述のIdLookupTable.csvを参照し、各画像に対して求められている座標を抜き出してこなければなりません。
当然ですが、pred は1783枚の画像にそれぞれに対し、15の特徴のx、y座標の予測で構成されています。(1783×30)
アプローチとしては、
- IdLookupTable.csvから、各画像に対して抽出する特徴を取得
- 次にその特徴をそれぞれ0~29のインデックスでエンコーディング
- 画像IDと特徴インデックスの組み合わせに対応する値をpredから抽出
という流れです。
# 1. IdLookupTable.csvからImageIdと特徴名を抽出します。
lookid_list = list(df['FeatureName'])
imageID = list(df['ImageId']-1)
pre_list = list(pred)
# 2. 特徴名を0~29のインデックスにエンコーディングしてリストへ格納します。
feature = []
for f in looked_list:
feature.append(lookid_list.index(f))
# 3. 画像IDと特徴名インデックスの組み合わせに対応するものを予測結果から抽出します。
# その際、標準化と逆の変換を行うことで求める値にします。
preded = []
for x,y in zip(imageID,feature):
preded.append(pre_list[x][y] * std[y] + mean[y])
最後に、提出ファイルを作成します。
rowid = pd.Series(df['RowId'],name = 'RowId')
loc = pd.Series(preded,name = 'Location')
submission = pd.concat([rowid,loc],axis = 1)
まとめ
以上です。これでスコアは3.8くらいになります。
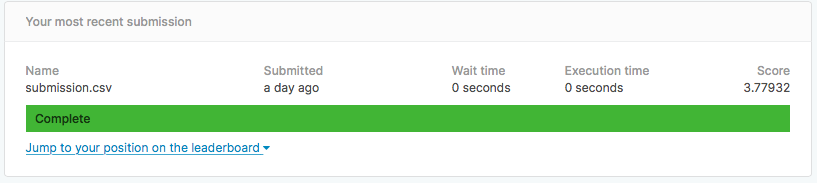
画像にAugumentationを適用させたり、モデルを改善させたりすれば全然スコアは上がりそうです。取り組み次第また投稿したいと思います。
間違いなどございましたらご指摘いただければ幸いです。
ありがとうございました。