はじめに
今まで何度か最新論文をきちんとウォッチしようと試みたのですが、大量の英語文献に毎日目を通すのはなかなか大変で、三日坊主になりがちでした。
Google Scholarのメール通知機能を使ったりもしましたが、リンク先にいちいち飛ばないと概要が分からず、気が向いたときしか開かなくなりがちに。。
そこでn番煎じですが、論文の公開情報をGPTを使って要約してDiscordに通知してくれるBotを作りました。下記のようにDiscordに投稿してくれます。いい感じ。
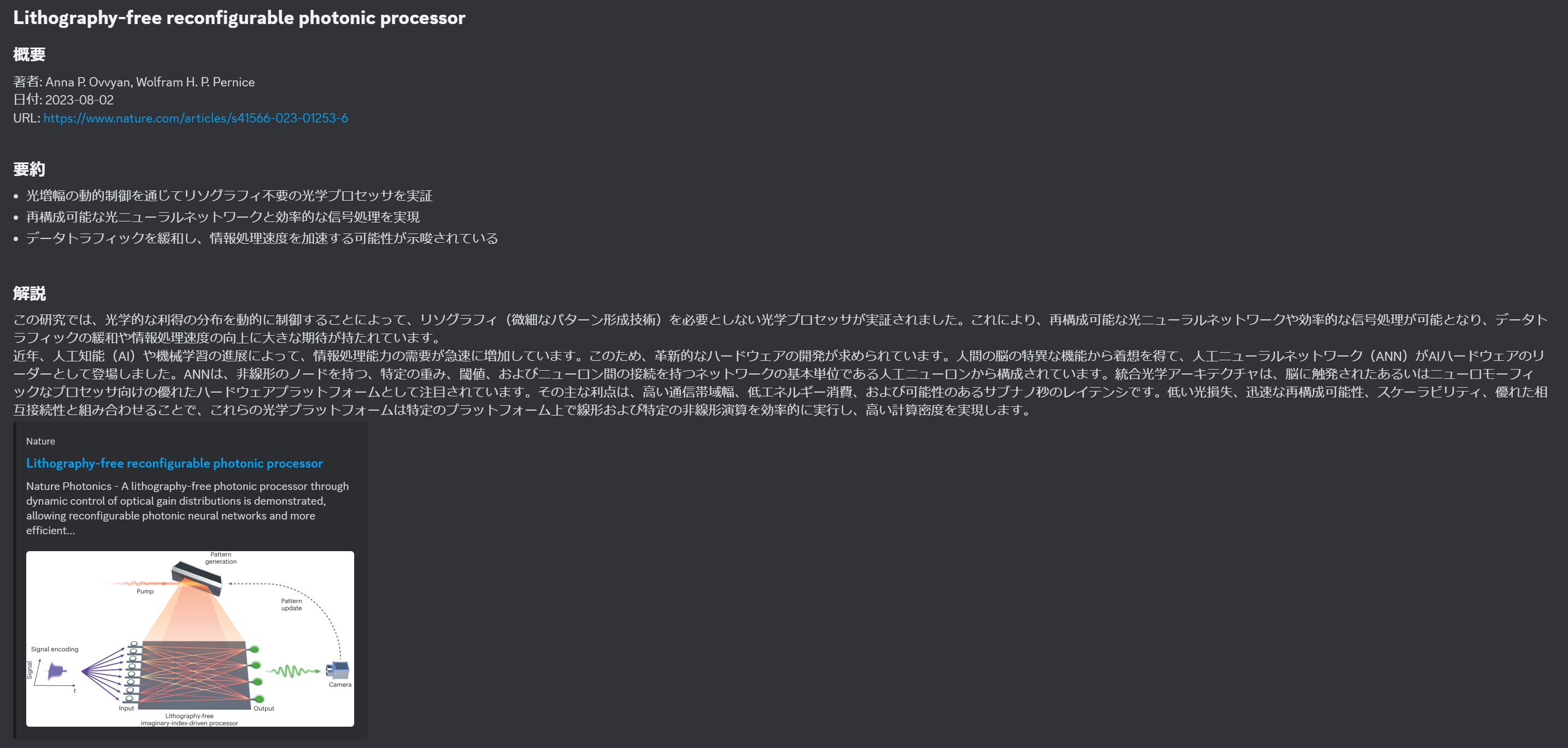
コードはこちらに置いています。GitHub
本記事ではサーバー等の立ち上げまではせず、コードだけ紹介します。
構成
特に難しいことはしていないです。
- ジャーナル公式のRSSを引っ張ってくる
- スクレイピングでアブストラクト(公開情報)を抽出
- 抽出したアブストラクトをOpenAI APIでGPTに投げて要約してもらう
- 要約結果をDiscord Webhookを使って投稿する
コード
main.py
今回は毎朝8時にNature Photonicsの更新を検知し、更新があればその内容を要約してDiscordに送ることにします。NaturePhotonicsRetrieverはRSS取得&アブスト抽出を担うクラスです。summarize_abstract()でOpenAI APIを使って要約を行います。最後にDiscorderSenderでDiscordに通知をします。毎朝8時にこのmain.pyが走るようにcronを設定すれば、最新の論文リストが要約付きで送られてくるという寸法です。なお、APIキーとDiscord Webhook URLは環境変数で管理しています。
import os
from datetime import datetime
from time import sleep
import pytz
from retriever import NaturePhotonicsRetriever
from sender import DiscordSender
from summary import summarize_abstract
def main():
model = 'gpt-3.5-turbo'
openai_api_key = os.environ['OPENAI_API_KEY']
discord_url = os.environ['DISCORD_URL']
now = datetime.now(tz=pytz.timezone('Asia/Tokyo'))
retriever = NaturePhotonicsRetriever()
recent_entries = retriever.fetch_recent_entries(now, hours_ago=24)
sender = DiscordSender(discord_url)
for entry in recent_entries:
abstract = retriever.extract_abstract(entry)
summary = summarize_abstract(abstract, openai_api_key, model)
sender.send_summary(entry, summary)
sleep(5)
if __name__ == '__main__':
main()
retriever.py
RSS取得&アブスト抽出を行います。スクレイピングにはBeautifulSoupを使っています。今後、他ジャーナルに対応したクラスも増やしていくつもりです。
from datetime import datetime, timedelta
from time import mktime
import feedparser
import pytz
import requests
from bs4 import BeautifulSoup
class NaturePhotonicsRetriever:
rss_url = 'https://www.nature.com/nphoton.rss'
def fetch_recent_entries(self, now=None, hours_ago=24):
feed = feedparser.parse(self.rss_url)
entries = feed.entries
recent_entries = retrieve_recent_entries(
entries, now=now, hours_ago=hours_ago)
return recent_entries
def extract_abstract(self, entry):
response = requests.get(entry.link)
soup = BeautifulSoup(response.text, 'html.parser')
abs1_content = soup.find(id='Abs1-content')
article_content = soup.find(
class_='c-article-section__content--standfirst')
if article_content:
article_content = article_content.find_all('p', recursive=False)[0]
else:
article_content = None
article_teaser = soup.find(class_='article__teaser')
if article_teaser:
article_teaser = article_teaser.find_all('p', recursive=False)[0]
else:
article_teaser = None
abst = ""
if abs1_content is not None:
abst += abs1_content.text + '\n'
if article_content is not None:
abst += article_content.text + '\n'
if article_teaser is not None:
abst += article_teaser.text + '\n'
return abst
def check_entry_recent(entry, now=None, hours_ago=24):
jst = pytz.timezone('Asia/Tokyo')
if now is None:
now = datetime.now(tz=jst)
entry_time = datetime.fromtimestamp(mktime(entry.updated_parsed), tz=jst)
start_time = now - timedelta(hours=hours_ago)
if (start_time <= entry_time < now):
return True
return False
def retrieve_recent_entries(entries, now=None, hours_ago=24):
if now is None:
now = datetime.now(tz=pytz.timezone('Asia/Tokyo'))
recent_entries = []
for entry in entries:
if (check_entry_recent(entry, now, hours_ago)):
recent_entries.append(entry)
return recent_entries
summary.py
今回の肝(?)の要約部分です。肝といってもOpenAI APIを叩いてるだけです。課金が足りず、モデルはまだGPT-3.5しか使えませんでした($1以上の支払い実績があればGPT-4をAPIで使えるらしい)。プロンプトは若干試行錯誤しましたが、まだ改善の余地があると思います。
import openai
def summarize_abstract(abstract, api_key, model='gpt-3.5-turbo',):
openai.api_key = api_key
res = openai.ChatCompletion.create(
model=model,
messages=[
{
'role': 'system',
'content': 'あなたは優れた研究者です。'
'与えられた論文のアブストラクトを要約した上で、内容を簡単に解説してください。'
'ただし、出力は以下のルールとフォーマットに従ってください。\n'
'[ルール]\n'
'・要約は箇条書きで3行で出力する\n'
'・要約には筆者独自の検討や重要な結論をかならず含める\n'
'・解説は1行で出力する\n'
'・解説には専門用語の説明を加えて、専門外の人にも分かるようにする\n'
'・日本語に翻訳して出力する\n'
'・なるべく体言止めを使う(例:~を提案する。 → ~を提案。)\n'
'・「です・ます」調ではなく「だ・である」調を使う(例:~できます → ~できる)\n'
'[フォーマット]\n'
'## 要約\n'
'- 項目1\n'
'- 項目2\n'
'- 項目3\n\n'
'## 解説\n'
'解説内容'
},
{
'role': 'user',
'content': abstract
}
]
)
return res.choices[0].message.content
sender.py
Discord Webhookを使ってメッセージを送付します。Webhookはブラウザorデスクトップ版のDiscord上で サーバー設定>連携サービス>ウェブフック>新しいウェブフックで追加できます。ウェブフックURLをコピーして環境変数に設定しておきます。
今回はメッセージ内容を
- 著者
- 日付
- URL
- 要約結果
にしました。アブスト本文も送信しようかとも思いましたが、チャット画面がビジーになるのと、1メッセージ当たりの文字数制限に引っ掛かりやすくなるのとで今回は省略しました。
import json
import requests
class DiscordSender:
def __init__(self, webhook_url):
self.webhook_url = webhook_url
def send_summary(self, entry, summary):
authors = [author.name for author in entry.authors]
authors = ', '.join(authors)
message = f'# {entry.title}\n' \
'## 概要\n' \
f'著者: {authors}\n' \
f'日付: {entry.updated}\n' \
f'URL: {entry.link}\n\n' \
f'{summary}\n'
print('------------------------------')
print(message)
headers = {'Content-Type': 'application/json'}
data = {'content': message}
res = requests.post(
self.webhook_url, data=json.dumps(data), headers=headers)
print(res.status_code)
結果
こんな感じでDiscordに投稿されます。GPT-3.5なのでちょっとアレな部分もありますが、どんな雰囲気の論文かは伝わってきます。気になる論文はどうせちゃんと読むので、最新論文を毎日軽くチェックしたいという用途には必要十分な感じです。GPT-4がAPIで使えるようになったらもっと性能が上がると思います。
最後に
冒頭にも述べましたが、サーバー立ち上げは書くのが面倒だったので省略しました。自分は家に転がっていたRaspberry Piを使っています。AWS Lambdaとか使ってもいいかもですね。サービスとして公開しようとも考えたのですが、論文を要約した内容を配信するのは翻案権の問題が出かねないのでコードの共有に留めています。
それにしても、びっくりするほど簡単に実装できてしまいました。生成AIを過度に恐れる必要はないと思うのですが、将来的に様々な仕事がAIに代替されるというのは事実なのではと感じます。まだ普及しきっていない今のうちにガンガン利用して、使いこなす側に回りたいところです。