タイタニック生存予測(Kaggle)を提出するまでをまとめました。
※書いてあるコードを上からコピペすれば提出までできます。
(提出はできますが、初心者が書いている記事なので、処理方法やモデルが参考になるとは限りません)
※プログラミングを始めて1ヶ月未満です。(2019/6/6現在)
※もちろん機械学習も始めたばかりです。
※ですので、訂正箇所等ございましたら、ご指摘くださるとありがたいです。
この記事の対象者
- pythonをある程度理解し、ディープラーニングに少しでも触れたことのある方
- Kerasを使ってkaggleに挑戦してみたい方(とにかく、提出をしてみたい方)
参考文献
https://book.mynavi.jp/ec/products/detail/id=90124
https://www.manning.com/books/deep-learning-with-python

目次
- (1)準備
- 開発環境
- モジュール
- データの読み込み
- 統計量確認
- (2)欠損値補完
- 欠損値確認の関数
- 欠損値補完
- (3)データを整える
- データを整える(1)
- データを整える(2)
- (4)検証開始
- モデル作成
- 損失値などを可視化
- (5)提出
- 提出用データ作成
- 結果
(1)準備
開発環境
- python 3.7.3
- jupyter 1.0.0
- Keras 2.2.4
- matplotlib 3.1.0
- numpy 1.16.4
- pandas 0.24.2
- tensorflow 1.13.1
モジュール
import pandas as pd
import numpy as np
from keras import models
from keras import layers
import matplotlib.pyplot as plt
%matplotlib inline
データの読み込み
# ファイルがある場所を指定する
train = pd.read_csv("/Users/*****/Desktop/Kggale/Titanic/train.csv")
test = pd.read_csv("/Users/*****/Desktop/Kggale/Titanic/test.csv")
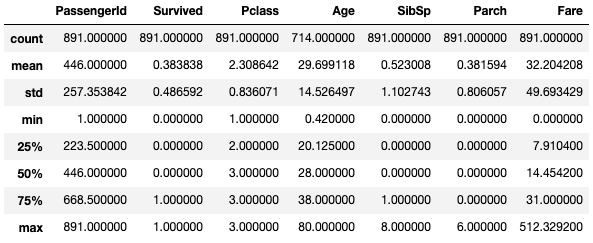
統計量確認
train.describe()#統計量
実行結果
(2)欠損値補完
欠損値確認の関数
[参考]https://www.codexa.net/kaggle-titanic-beginner/
欠損値を確認する関数を作成
def kesson_table(df):
null_val = df.isnull().sum()#DataFrameの中の欠損値(NaN)の個数を確認(インデックス毎に)
percent = 100 * df.isnull().sum()/len(df)
kesson_table = pd.concat([null_val, percent], axis=1)#pd.concat([df1, df2], axis=1):DataFrameを横に連結(標準はaxis=0で縦)
kesson_table_ren_columns = kesson_table.rename(columns = {0: "欠損数", 1: "%"})#df.rename(columns={"A": "a"}, index={"あ", "ア"})
return kesson_table_ren_columns
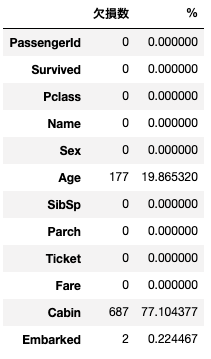
欠損値確認
kesson_table(train)
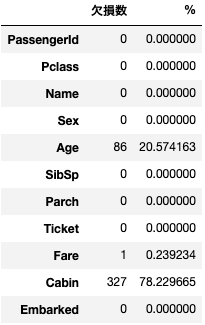
kesson_table(test)
欠損値補完
今回は以下のように補完したが、後から変更を加えたい結果になりました。(欠損値補完はコピペではなく、自分で考えて埋めるのがいいかと思います。)
step1
全ての欠損値を「平均値」や「0」、「中央値」で埋めてもよかったが、「兄弟・配偶者がいて、親・子供のいない人」は全体的に年齢が高めと予想したため、その人たちの中で求めた平均値で補完した。(この作業が正しいかは・・・)
# 人数を確認するために"a"を作成
a = train.loc[train["SibSp"]>=1][train["Parch"]==0]#兄弟・配偶者がいて、親・子供のいない人(141人います)
# 兄弟・配偶者がいて、親・子供のいない人
cond = (train["SibSp"] >= 1) & (train["Parch"] == 0)
mean_cond_age = train.loc[cond, 'Age'].mean()#条件を満たす人の中でとった平均値
print(mean_cond_age)
# 上記条件を満たす人で "Age" が NaN の場合は平均で埋める。
train.loc[cond, 'Age'] = train.loc[cond, 'Age'].fillna(mean_cond_age)
step2
残りの欠損値は以下のように埋めた。
# 欠損値を埋める(何で埋めるかはとても重要)
train["Age"] = train["Age"].fillna(0)#df.fillna("埋めたい値"):NaNの部分が"埋めたい値"になる
train["Embarked"] = train["Embarked"].fillna("S")
train.loc[train["Sex"]=="male", "Sex"] = -0.5
train.loc[train["Sex"]=="female", "Sex"] = 0.5
train.loc[train["Embarked"]=="S", "Embarked"] = 0
train.loc[train["Embarked"]=="C", "Embarked"] = 1
train.loc[train["Embarked"]=="Q", "Embarked"] = 2
# df.iloc["何行目かを数で指定", "何列目かを数で指定"]
test["Age"] = test["Age"].fillna(0)#df.fillna("埋めたい値"):NaNの部分が"埋めたい値"になる
test["Fare"] = test["Fare"].fillna(test["Fare"].median())
test.loc[test["Sex"]=="male", "Sex"] = -0.5
test.loc[test["Sex"]=="female", "Sex"] = 0.5
test.loc[test["Embarked"]=="S", "Embarked"] = 0
test.loc[test["Embarked"]=="C", "Embarked"] = 1
test.loc[test["Embarked"]=="Q", "Embarked"] = 2
(3)データを整える
データを整える(1)
使用する特徴量をリスト化し、モデルに組み込める形にデータを変換
columns = ["Pclass", "Age", "SibSp", "Parch", "Sex"]#使用する特徴量
train_data = train[columns].values
train_labels = train["Survived"].values
x_train = np.asarray(train_data).astype("float32")#データ
y_train = np.asarray(train_labels)#ラベル
test_data = test[columns].values.astype("float32")#テストデータ
データを整える(2)
データの値にばらつきがあるといけないので、正規化します。
(平均をひき、標準偏差でわるという処理を行うと、中心が0・標準偏差が1というデータになります。)
# 正規化
for i in range(len(columns)-1):
mean = x_train.mean(axis=0)[i]
std = x_train.std(axis=0)[i]
x_train[:, i] = (x_train[:, i] - mean) / std
test_data[:, i] = (test_data[:, i] - mean) / std
(4)検証開始
モデル作成
今回はデータ数がそれほど多くはないと判断したため、「k分割交差検証」を使いました。
層の数やエポック数などを変更してみると改善される可能性があるので試してみるといいと思います。
# k分割交差検証
k = 4#分割数
num_val_data = len(x_train) // k#検証データ数
num_epochs = 78
batch_size = 8
a_all_scores = []
b_all_scores = []
c_all_scores = []
d_all_scores = []
for i in range(k):
print(i+1, "回目")
#検証データとラベル
val_data = x_train[i*num_val_data: (i+1)*num_val_data]
val_targets = y_train[i*num_val_data: (i+1)*num_val_data]
#訓練データとラベル
partial_train_data = np.concatenate([x_train[: i*num_val_data], x_train[(i+1)*num_val_data: ]], axis = 0)
partial_train_targets = np.concatenate([y_train[: i*num_val_data], y_train[(i+1)*num_val_data: ]], axis = 0)
model = models.Sequential()
model.add(layers.Dense(8, activation="relu", input_shape=(len(columns), )))
model.add(layers.Dropout(0.2))
model.add(layers.Dense(8, activation="relu"))
model.add(layers.Dropout(0.2))
model.add(layers.Dense(1, activation="sigmoid"))
model.compile(optimizer="rmsprop", loss="binary_crossentropy", metrics=["acc"])
history = model.fit(partial_train_data, partial_train_targets,
epochs=num_epochs,
batch_size=batch_size,
validation_data=(val_data, val_targets),
verbose = 0
)
a_history = history.history["acc"]
a_all_scores.append(a_history)
b_history = history.history["val_acc"]
b_all_scores.append(b_history)
c_history = history.history["loss"]
c_all_scores.append(c_history)
d_history = history.history["val_loss"]
d_all_scores.append(d_history)
print("終了")
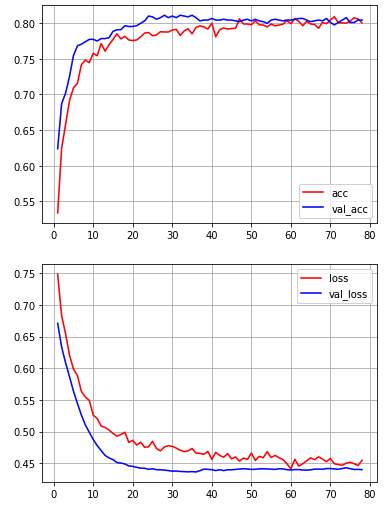
損失値などを可視化
average_a_history = [np.mean([x[i] for x in a_all_scores]) for i in range(num_epochs)]
average_b_history = [np.mean([x[i] for x in b_all_scores]) for i in range(num_epochs)]
average_c_history = [np.mean([x[i] for x in c_all_scores]) for i in range(num_epochs)]
average_d_history = [np.mean([x[i] for x in d_all_scores]) for i in range(num_epochs)]
plt.plot(range(1, len(average_a_history) + 1), average_a_history, color = "red", label="acc")
plt.plot(range(1, len(average_b_history) + 1), average_b_history, color = "blue", label="val_acc")
plt.legend()
plt.grid(True)
plt.show()
plt.plot(range(1, len(average_c_history) + 1), average_c_history, color = "red", label="loss")
plt.plot(range(1, len(average_d_history) + 1), average_d_history, color = "blue", label="val_loss")
plt.legend()
plt.grid(True)
plt.show()
(5)提出
提出用データ作成
ans = model.predict(test_data)
ans = np.round(ans).astype(int)
ans = ans.flatten()
P_ID = np.array(test["PassengerId"]).astype(int)
my_solution = pd.DataFrame(ans, P_ID, columns = ["Survived"])
my_solution.to_csv("solution_no2.csv", index_label = ["PassengerId"])
結果
中間の順位でした。また修正して挑んでみます。
順位: 5647 / 11090

(欠損値等に修正を加えています。)