住宅価格予測(Kaggle)を提出するまでをまとめました。
※書いてあるコードを上からコピペすれば提出までできます。
(提出はできますが、初心者が書いている記事なので、処理方法やモデルが参考になるとは限りません)
※プログラミングを始めて1ヶ月未満です。(2019/6/6現在)
※もちろん機械学習も始めたばかりです。
※ですので、訂正箇所等ございましたら、ご指摘くださるとありがたいです。
この記事の対象者
- pythonをある程度理解し、ディープラーニングに少しでも触れたことのある方
- Kerasを使ってkaggleに挑戦してみたい方(とにかく、提出をしてみたい方)
参考文献
https://book.mynavi.jp/ec/products/detail/id=90124
https://www.manning.com/books/deep-learning-with-python

目次
- (1)準備
- 開発環境
- モジュール
- データの読み込み
- 住宅価格の分布
- 欠損値確認の関数
- (2)相関関係
- 相関を調べる
- 検証に使うカラムをリスト化
- (3)外れ値の処理
- 相関を可視化
- 外れ値を修正
- (4)データを準備
- 正規化
- (5)検証開始
- モデル作成
- 検証結果を可視化
- (6)結果
- 提出データ作成
- 結果
(1)準備
開発環境
- python 3.7.3
- jupyter 1.0.0
- Keras 2.2.4
- matplotlib 3.1.0
- numpy 1.16.4
- pandas 0.24.2
- tensorflow 1.13.1
- scikit-learn 0.21.2
- scipy 1.3.0
- seaborn 0.9.0
モジュール
import pandas as pd
import numpy as np
from keras import models
from keras import layers
import keras.optimizers
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.layers import Dropout
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
%matplotlib inline
データの読み込み
# 保存してあるファイルを指定
train = pd.read_csv("/Users/*****/Desktop/Kggale/house-prices/train.csv")
test = pd.read_csv("/Users/*****/Desktop/Kggale/house-prices/test.csv")
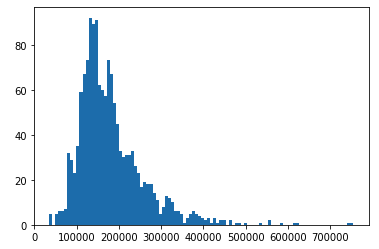
住宅価格の分布
train_saleprice = train["SalePrice"].values
print(train_saleprice)
plt.hist(train_saleprice, bins=100)
plt.show()
欠損値確認の関数
[参考]https://www.codexa.net/kaggle-titanic-beginner/
欠損値を確認する関数を作成(適宜、欠損値を確認しながら進めました)
def kesson_table(df):
null_val = df.isnull().sum()#DataFrameの中の欠損値(NaN)の個数を確認(インデックス毎に)
percent = 100 * df.isnull().sum()/len(df)
kesson_table = pd.concat([null_val, percent], axis=1)#pd.concat([df1, df2], axis=1):DataFrameを横に連結(標準はaxis=0で縦)
kesson_table_ren_columns = kesson_table.rename(columns = {0: "欠損数", 1: "%"})#df.rename(columns={"A": "a"}, index={"あ", "ア"})
return kesson_table_ren_columns
kesson_table(train)#欠損値を表示する実行結果は長いので省略
(2)相関関係
相関を調べる
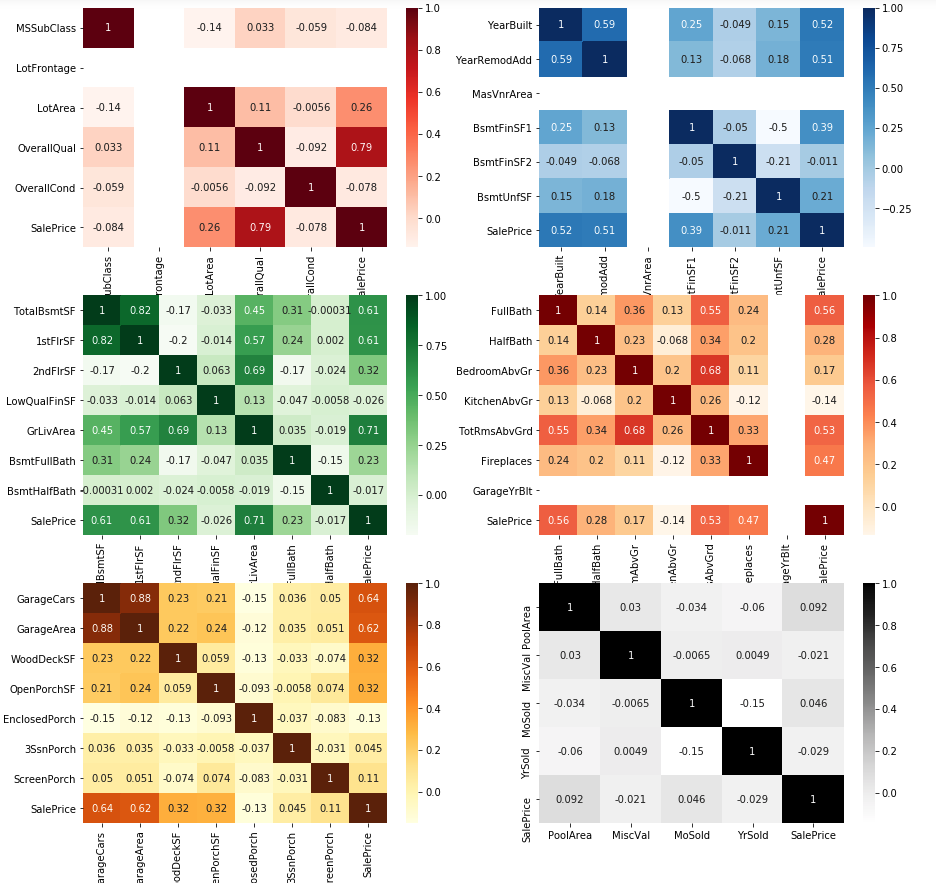
どのデータが価格に大きく関わってくるのかを「ヒートマップ」を使って表したいと思います。
("for * in ***" を使えば、スッキリなります。)
# valueが数のデータのカラム(ヒートマップを見やすくするために6つに分けました)
train_num_list_1 = ["MSSubClass", "LotFrontage", "LotArea", "OverallQual", "OverallCond", "SalePrice"]
train_num_list_2 = ["YearBuilt", "YearRemodAdd", "MasVnrArea", "BsmtFinSF1", "BsmtFinSF2", "BsmtUnfSF", "SalePrice"]
train_num_list_3 = ["TotalBsmtSF", "1stFlrSF", "2ndFlrSF", "LowQualFinSF", "GrLivArea", "BsmtFullBath", "BsmtHalfBath", "SalePrice"]
train_num_list_4 = ["FullBath", "HalfBath", "BedroomAbvGr", "KitchenAbvGr", "TotRmsAbvGrd", "Fireplaces", "GarageYrBlt", "SalePrice"]
train_num_list_5 = ["GarageCars", "GarageArea", "WoodDeckSF", "OpenPorchSF", "EnclosedPorch", "3SsnPorch", "ScreenPorch", "SalePrice"]
train_num_list_6 = ["PoolArea", "MiscVal", "MoSold", "YrSold", "SalePrice"]
# valueが数のデータ
train_num_1 = train[train_num_list_1]
train_num_2 = train[train_num_list_2]
train_num_3 = train[train_num_list_3]
train_num_4 = train[train_num_list_4]
train_num_5 = train[train_num_list_5]
train_num_6 = train[train_num_list_6]
# 相関行列
correlation_matrix_1 = np.corrcoef(train_num_1.transpose())
correlation_matrix_2 = np.corrcoef(train_num_2.transpose())
correlation_matrix_3 = np.corrcoef(train_num_3.transpose())
correlation_matrix_4 = np.corrcoef(train_num_4.transpose())
correlation_matrix_5 = np.corrcoef(train_num_5.transpose())
correlation_matrix_6 = np.corrcoef(train_num_6.transpose())
# ヒートマップ表示
plt.figure(figsize=(15, 15))#図が重なってしまったり、見にくくなる場合はここを修正
plt.subplots_adjust(wspace = 0.2, hspace = 0.2)#図が重なってしまったり、見にくくなる場合はここを修正
plt.subplot(3, 2, 1)
sns.heatmap(correlation_matrix_1, annot=True, cmap = "Reds",
xticklabels=train_num_list_1,
yticklabels=train_num_list_1)
plt.subplot(3, 2, 2)
sns.heatmap(correlation_matrix_2, annot=True, cmap = "Blues",
xticklabels=train_num_list_2,
yticklabels=train_num_list_2)
plt.subplot(3, 2, 3)
sns.heatmap(correlation_matrix_3, annot=True, cmap = "Greens",
xticklabels=train_num_list_3,
yticklabels=train_num_list_3)
plt.subplot(3, 2, 4)
sns.heatmap(correlation_matrix_4, annot=True, cmap = "OrRd",
xticklabels=train_num_list_4,
yticklabels=train_num_list_4)
plt.subplot(3, 2, 5)
sns.heatmap(correlation_matrix_5, annot=True, cmap = "YlOrBr",
xticklabels=train_num_list_5,
yticklabels=train_num_list_5)
plt.subplot(3, 2, 6)
sns.heatmap(correlation_matrix_6, annot=True, cmap = "Greys",
xticklabels=train_num_list_6,
yticklabels=train_num_list_6)
plt.show()
※カラフルにする意味はありません
色が濃くなっている場所が、相関関係があるところです。(各図、右列に"SalePrice"を配置しているので、そこを見る)
検証に使うカラムをリスト化
相関関係があったものを抽出しました。
今回は、このデータで価格予想をしてみたいと思います。
# 相関係数が高いリスト(検証に使うリスト)
# "SalePrice"含む
high_correlation_list = ["OverallQual", "YearBuilt", "YearRemodAdd", "TotalBsmtSF", "1stFlrSF",
"GrLivArea", "FullBath", "TotRmsAbvGrd", "GarageCars", "GarageArea", "SalePrice"]
# "SalePrice"含まない
high_correlation_list_0 = ["OverallQual", "YearBuilt", "YearRemodAdd", "TotalBsmtSF", "1stFlrSF",
"GrLivArea", "FullBath", "TotRmsAbvGrd", "GarageCars", "GarageArea"]
# 相関係数が高かったものだけを抽出
train_correlation = train[high_correlation_list]
test_correlation = test[high_correlation_list_0]
(3)外れ値の処理
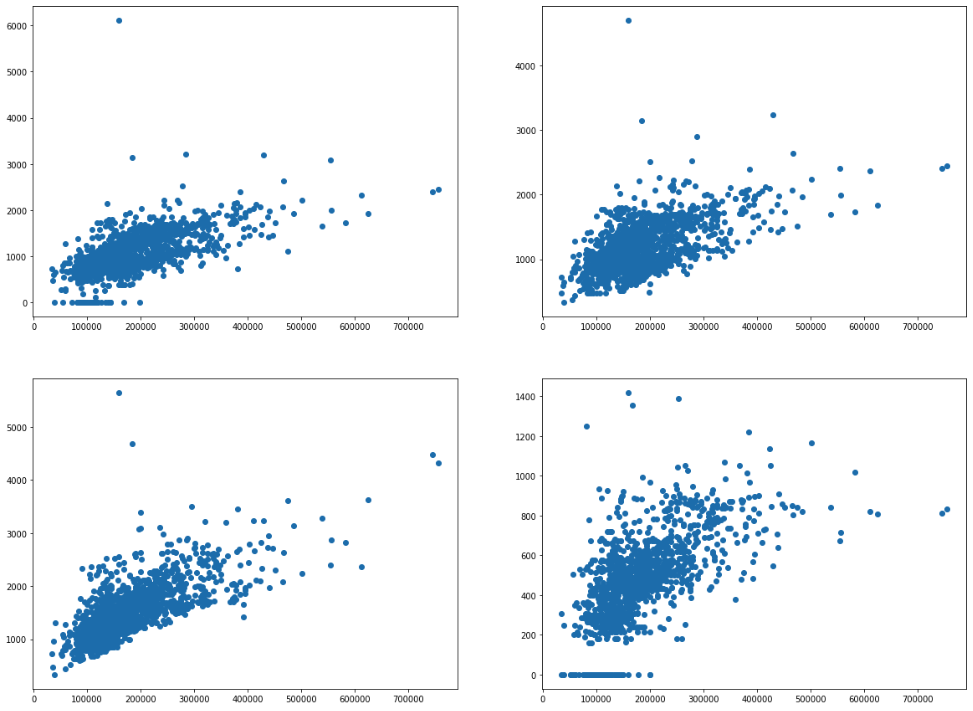
相関を可視化
データの値が大きいものだけを散布図でみたいと思います。
外れ値があった場合は修正します。
plt.figure(figsize=(20, 15))
# "TotalBsmtSF"の散布図(地下室)
plt.subplot(2, 2, 1)
plt.scatter(train_saleprice, train_correlation["TotalBsmtSF"])
# "1stFlrSF"の散布図
plt.subplot(2, 2, 2)
plt.scatter(train_saleprice, train_correlation["1stFlrSF"])
# "GrLivArea"の散布図
plt.subplot(2, 2, 3)
plt.scatter(train_saleprice, train_correlation["GrLivArea"])
# "GarageArea"の散布図
plt.subplot(2, 2, 4)
plt.scatter(train_saleprice, train_correlation["GarageArea"])
plt.show()
外れ値を修正
下記のように外れ値を修正します。(外れ値の修正に大きな課題が残った感じがしました。)
# 外れ値を修正
# "TotalBsmtSF"
# 150000から200000の範囲で5000を超える数値を、第三四分位数にする
cond_TotalBsmtSF = (train_correlation["SalePrice"]>150000) & (train_correlation["SalePrice"]<200000)#価格の範囲を指定
q3_TotalBsmtSF = train_correlation.loc[cond_TotalBsmtSF].describe().loc["75%", "TotalBsmtSF"]
cond_TotalBsmtSF_q3 = cond_TotalBsmtSF & (train_correlation["TotalBsmtSF"] > 5000)
train_correlation.loc[cond_TotalBsmtSF_q3, "TotalBsmtSF"] = q3_TotalBsmtSF
# "1stFlrSF"
# 100000から300000の範囲で2500を超える数値を、第三四分位数にする
cond_1stFlrSF = (train_correlation["SalePrice"]>100000) & (train_correlation["SalePrice"]<300000)#価格の範囲を指定
q3_1stFlrSF = train_correlation.loc[cond_1stFlrSF].describe().loc["75%", "1stFlrSF"]
cond_1stFlrSF_q3 = cond_1stFlrSF & (train_correlation["1stFlrSF"] > 2500)
train_correlation.loc[cond_1stFlrSF_q3, "1stFlrSF"] = q3_1stFlrSF
# "GrLivArea"
# 150000から200000の範囲で4000を超える数値を、第三四分位数にする
cond_GrLivArea = (train_correlation["SalePrice"]>150000) & (train_correlation["SalePrice"]<200000)#価格の範囲を指定
q3_GrLivArea = train_correlation.loc[cond_GrLivArea].describe().loc["75%", "GrLivArea"]
cond_GrLivArea_q3 = cond_GrLivArea & (train_correlation["GrLivArea"] > 4000)
train_correlation.loc[cond_GrLivArea_q3, "GrLivArea"] = q3_GrLivArea
欠損値を埋める
テストデータに欠損値があるので、0で埋めておきます。
# 欠損値を埋める
test_correlation["TotalBsmtSF"] = test_correlation["TotalBsmtSF"].fillna(0)
test_correlation["GarageCars"] = test_correlation["GarageCars"].fillna(0)
test_correlation["GarageArea"] = test_correlation["GarageArea"].fillna(0)
(4)データを準備
正規化
データをニューラルネットワークに入れることのできる形に変えます。
また、データの値にばらつきがあるので、正規化しました。(平均をひき、標準偏差でわるという処理を行うと、中心が0・標準偏差が1というデータになります。)
# 訓練データとテストデータ
x_train = train_correlation.iloc[:, :-1].values.astype("float32")
x_targets = train["SalePrice"].values.astype("float32")
y_train = test_correlation.values.astype("float32")
# 正規化
# インスタンス作成
stdsc = StandardScaler()
mean_train = np.mean(x_train, axis=0)
std_train = np.std(x_train, axis=0)
for i in range(len(high_correlation_list)-1):
y_train[:, i] = (y_train[:, i] - mean_train[i]) / std_train[i]
x_targets = x_targets.reshape(-1, 1)
x_train_ss = stdsc.fit_transform(x_train)
x_targets_ss = stdsc.fit_transform(x_targets)
(5)検証開始
モデル作成
データ数が多いわけではないので、「k分割交差検証」を使いました。
# k分割交差検証
k = 4#分割数
num_val_data = len(x_train) // k#検証データ数
num_epochs = 50
batch_size = 32
mae_all_scores = []
loss_all_scores = []
val_loss_all_scores = []
for i in range(k):
print(i+1, "回目")
#検証データとラベル
val_data = x_train_ss[i*num_val_data: (i+1)*num_val_data]
val_targets = x_targets_ss[i*num_val_data: (i+1)*num_val_data]
#訓練データとラベル
partial_train_data = np.concatenate([x_train_ss[: i*num_val_data], x_train_ss[(i+1)*num_val_data: ]], axis = 0)
partial_train_targets = np.concatenate([x_targets_ss[: i*num_val_data], x_targets_ss[(i+1)*num_val_data: ]], axis = 0)
model = models.Sequential()
model.add(layers.Dense(16, activation="relu", input_shape=(len(high_correlation_list)-1, )))
model.add(layers.Dense(16, activation="relu"))
model.add(layers.Dense(1))
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(partial_train_data, partial_train_targets,
epochs=num_epochs,
batch_size=batch_size,
validation_data=(val_data, val_targets),
verbose = 0
)
mae_history = history.history["val_mean_absolute_error"]
loss_history = history.history["loss"]
val_loss_history = history.history["val_loss"]
mae_all_scores.append(mae_history)
loss_all_scores.append(loss_history)
val_loss_all_scores.append(val_loss_history)
print("終了")
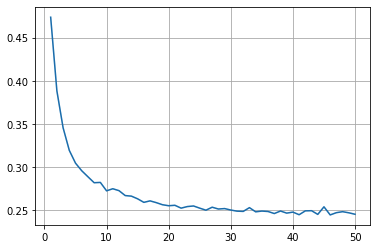
検証結果を可視化
average_mae_history = [np.mean([x[i] for x in mae_all_scores]) for i in range(num_epochs)]
average_loss_history = [np.mean([x[i] for x in loss_all_scores]) for i in range(num_epochs)]
average_val_loss_history = [np.mean([x[i] for x in val_loss_all_scores]) for i in range(num_epochs)]
plt.plot(range(1, len(average_mae_history) + 1), average_mae_history)
plt.grid(True)
plt.show()
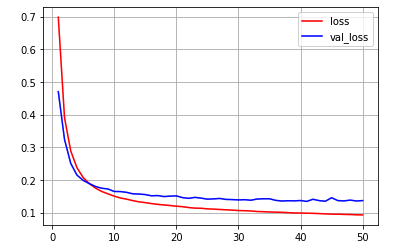
plt.plot(range(1, len(average_loss_history) + 1), average_loss_history, color = "red", label="loss")
plt.plot(range(1, len(average_val_loss_history) + 1), average_val_loss_history, color = "blue", label="val_loss")
plt.legend()
plt.grid(True)
plt.show()
(6)結果
提出データ作成
提出できる形にします。
"model.predict(y_train)"で得られる値はそのままでは使えないため、"inverse_transform()"で変換
ans_ss = model.predict(y_train)
ans = stdsc.inverse_transform(ans_ss)
# ans = (model.predict(y_train) * targets_std) + targets_mean
print(ans.shape)
df_sub_pred = pd.DataFrame(ans).rename(columns={0: "SalePrice"})
df_sub_pred = pd.concat([test["Id"], df_sub_pred["SalePrice"]], axis=1)
df_sub_pred.to_csv("house_pred_1.csv", index=False)
df_sub_pred.head()
結果
順位: 3276 / 4655
良い結果は得られませんでした。
モデルに問題があるというよりは、データの前処理が甘かったのかなと思います。
