MLflowのQuickstartやってみました。
環境
- macOS High Sierra
- pyenv 1.2.1
- anaconda3-5.0.1
- Python 3.6.8
- MLflow==0.8.2
MLflowとは
MLflow (currently in beta) is an open source platform to manage the ML lifecycle, including experimentation, reproducibility and deployment.
機械学習の様々なデータ(ハイパーパラメータの設定値や学習に使用したデータ、損失関数の推移やモデルパラメータなど)を管理できるオープンソースプラットフォームです。
管理だけにとどまらず、ブラウザを使った可視化や推論APIの提供などをしてくれます。
Python、R、Java用のAPIやREST APIが用意されています。
ライセンスはApache-2.0です。
その他については先人の記事が大変参考になるのでご参照ください。
https://qiita.com/masa26hiro/items/574c48d523ed76e76a3b
Quickstart
(前提条件)
事前にanacondaの仮想環境を作成して有効化しておきます。
conda create -n mlflow python=3.6
pyenv global anaconda3-5.0.1/envs/mlflow
source ~/.pyenv/versions/anaconda3-5.0.1/bin/activate mlflow
MLflowをインストール
pip install mlflow
この時点のpip freezeは以下の通り。
boto3==1.9.103
botocore==1.12.103
certifi==2018.11.29
chardet==3.0.4
Click==7.0
cloudpickle==0.8.0
configparser==3.7.3
databricks-cli==0.8.4
docutils==0.14
Flask==1.0.2
gitdb2==2.0.5
GitPython==2.1.11
gunicorn==19.9.0
idna==2.8
itsdangerous==1.1.0
Jinja2==2.10
jmespath==0.9.4
MarkupSafe==1.1.1
mleap==0.8.1
mlflow==0.8.2
nose==1.3.7
nose-exclude==0.5.0
numpy==1.16.2
pandas==0.24.1
protobuf==3.6.1
python-dateutil==2.8.0
pytz==2018.9
PyYAML==3.13
querystring-parser==1.2.3
requests==2.21.0
s3transfer==0.2.0
scikit-learn==0.20.2
scipy==1.2.1
simplejson==3.16.0
six==1.12.0
smmap2==2.0.5
tabulate==0.8.3
urllib3==1.24.1
Werkzeug==0.14.1
この時点で、numpy、pandas、scikit-learn、scipyなどは勝手にインストールされています。
もちろんmlflowも入っています。
Quickstart用に用意されているサンプルリポジトリのクローン
git clone https://github.com/mlflow/mlflow
cd mlflow/examples
Tracking APIを使ってみる
任意のエディタで以下のコードを書いて保存します。
import os
from mlflow import log_metric, log_param, log_artifact
if __name__ == "__main__":
# Log a parameter (key-value pair)
log_param("param1", 5)
# Log a metric; metrics can be updated throughout the run
log_metric("foo", 1)
log_metric("foo", 2)
log_metric("foo", 3)
# Log an artifact (output file)
with open("output.txt", "w") as f:
f.write("Hello world!")
log_artifact("output.txt")
さてこのスクリプトを実行してみます。
python tracking_api_sample.py
すると同階層にmlrunsというディレクトリが出来ているはずです。
この中に先程実行したスクリプトの結果が入っています。
中身は以下のようになっていました。
mlruns/
└── 0
├── cde43510000043a2a4af734625dc95e7
│ ├── artifacts
│ │ └── output.txt
│ ├── meta.yaml
│ ├── metrics
│ │ └── foo
│ └── params
│ └── param1
└── meta.yaml
5 directories, 5 files
以下、生成されたファイルの中身を見ていきます。
meta.yaml
$ cat mlruns/0/meta.yaml
artifact_location: /Users/takeshi/daylywork/2019-02-27/mlflow/examples/mlruns/0
experiment_id: 0
lifecycle_stage: active
name: Default
おー。まだよくわかんないとこもありますが、実験結果の保存場所とか実験IDとかが書いてあるぽいです。
じゃあ次はハッシュ値(cde43510000043a2a4af734625dc95e7)の中身を見ていきます。
mlruns/0/cde43510000043a2a4af734625dc95e7/meta.yaml
$ cat mlruns/0/cde43510000043a2a4af734625dc95e7/meta.yaml
artifact_uri: /Users/takeshi/daylywork/2019-02-27/mlflow/examples/mlruns/0/cde43510000043a2a4af734625dc95e7/artifacts
end_time: 1551278143295
entry_point_name: ''
experiment_id: 0
lifecycle_stage: active
name: ''
run_uuid: cde43510000043a2a4af734625dc95e7
source_name: tracking_api_sample.py
source_type: 4
source_version: 8ab7d382b3364ebf4fb4ddd1ebde43245c62e339
start_time: 1551278143207
status: 3
tags: []
user_id: takeshi
おー。こちらはより詳細な情報が書いてある感じぽいです。
mlruns/0/cde43510000043a2a4af734625dc95e7/params/param1
$ cat mlruns/0/cde43510000043a2a4af734625dc95e7/params/param1
5
これはどうやらtracking_api_sample.pyの以下の部分に該当しているぽいです。
# Log a parameter (key-value pair)
log_param("param1", 5)
パラメータ名そのままのファイルの中に値が直接書き込まれているという非常にわかりやすい形式ですね。
実際に使用するときは学習データのファイルパスとかハイパーパラメータの値を残しておくという感じでしょうか。
mlruns/0/cde43510000043a2a4af734625dc95e7/metrics/foo
$ cat mlruns/0/cde43510000043a2a4af734625dc95e7/metrics/foo
1551278143 1
1551278143 2
1551278143 3
これはtracking_api_sample.pyの以下の部分に対応しているようです。
# Log a metric; metrics can be updated throughout the run
log_metric("foo", 1)
log_metric("foo", 2)
log_metric("foo", 3)
paramと同じように、metric名そのままのファイル名の中に値が直接書き込まれ...ているわけではなさそうです。
1551278143という値が何かはわかりませんが、mlruns/0/cde43510000043a2a4af734625dc95e7/meta.yamlに書かれていたstart_timeやend_timeにこの値が含まれているので、時間が関係していそうな感じです。
実際に使用するときはエポック毎の損失関数の値とかConfusionMatrixの値とかを書き留めとくみたいな感じでしょうか。
mlruns/0/cde43510000043a2a4af734625dc95e7/artifacts/output.txt
$ cat mlruns/0/cde43510000043a2a4af734625dc95e7/artifacts/output.txt
Hello world!
こいつはtracking_api_sample.pyのここです。(インデントできない![]() )
)
# Log an artifact (output file)
with open("output.txt", "w") as f:
f.write("Hello world!")
log_artifact("output.txt")
実験中に生成したものを置いとく場所って感じだと思われます。
なるほどなるほど。
なんかもうある程度のことは出来そうな気もしてきました。
管理している情報をブラウザで表示する
mlflow ui
これでローカルサーバーが立ち上がっているのでブラウザでhttp://localhost:5000/にアクセスします。
※私はこの段階で-bash: mlflow: command not foundエラーが発生しました。
↓
(2019/03/01追記)
この記事に書きましたが、単純にパスが通ってないだけでした。。。
起動画面
正常に起動できている場合は以下のような画面が表示されます。
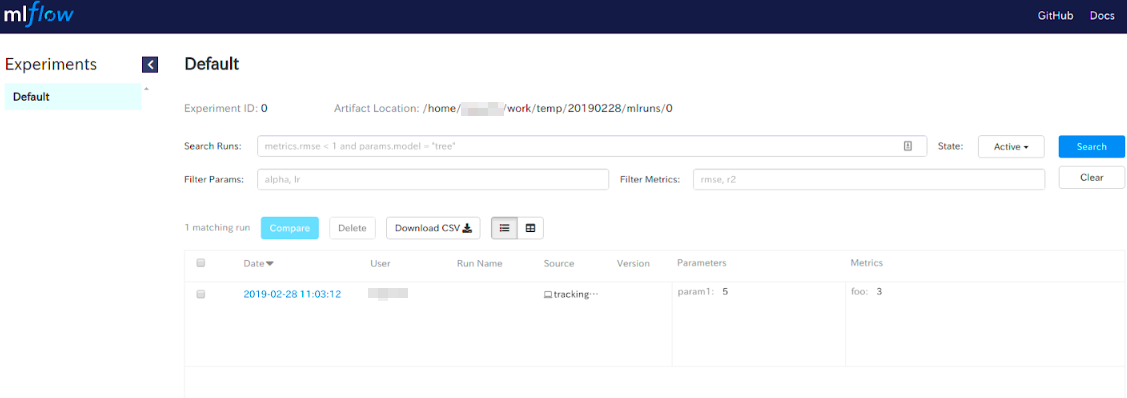
なにやらいろいろ表示されていますが、実験条件などでのフィルターなども出来そうです。
リストアップされているリンクをクリックすると以下のような詳細画面になります。
詳細画面
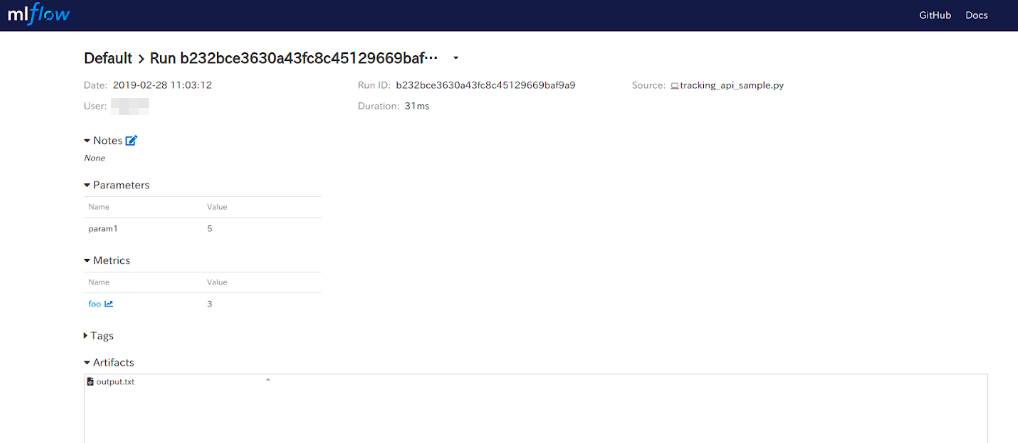
実行日時や処理時間と共に、記録したparametersやmetrics、Artifactsが表示されています。
metricsのfooには値を3個保存したので、クリックしてその中身を見てみます。
metrics(foo)
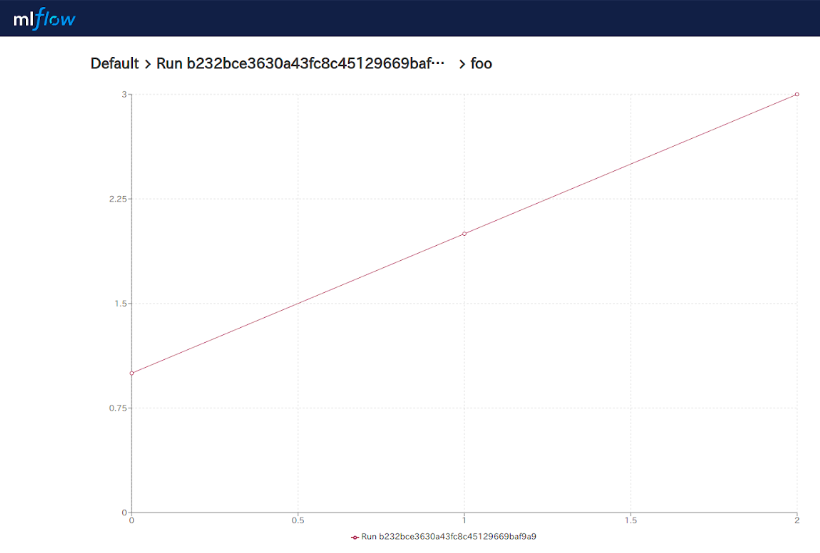
自動でグラフにしてくれています。これは便利ですね。
lossなどを保存しておけば自動でグラフが表示されるはずです。
次はArtifactsで保存したoutput.txtを見てみます。
Artifacts(output.txt)
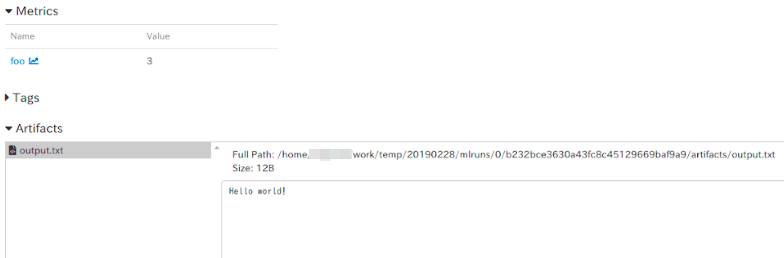
うん。しっかりHello World!していますね。
ここ(Artifacts)には、実験中や実験後に生成されるファイル達を置いとくって感じでしょう。たぶん。
画像なんかも置けるようです。
その他もTagやNotesなどを追加できるようですが、まだ使い方はわかりません。
まとめ
一気にやろうかと思ってましたが、ちょっと長くなってしまったので以下の項目については次回以降にしようかと思います。
- Running MLflow Projects
- Saving and Serving Models
乞うご期待