この記事について
- mlflowという機械学習の管理をできるPythonライブラリについて説明する
- mlflowを使って、データ分析サイクルを効率よく回せるかを考える
mlflowとは
概要
mlflowは、機械学習の開発を行う上で複雑になりがちな実行環境、モデル、パラメータ、評価結果、その他もろもろの管理を行ってくれるプラットフォームです。モデル作成後のデプロイについても、予測結果を返してくれる簡単なAPIを提供できる機能でカバーしています。
機械学習を行う場合、scikit-learn(または、これに準拠したもの)を用いることが多いと思うので、これを使うことを前提に説明していきます。(scikit-learn以外にも、H2O、Keras、pytorch、tensorflowといったディープラーニング向けのライブラリにも対応しています。)
mlflowは以下の大きな3つの機能で構成されています。
- MLFlow Tracking
- MLflow Projects
- MLflow Models
この3つの機能がどのようなものであるかを順に説明していきたいと思います(この説明はmlflowのTutorialを参考にしています。)。
MLflow Tracking
概要
MLflow Trackingは、機械学習のモデル作成時の情報を保存し、管理してくれる機能です。MLflow Trackingが各モデルごとに保存するものは、主に以下の4つが考えられます(工夫すれば他の情報も可)。
- 学習に用いるデータが何であったか
- 前処理や学習モデルのpipeline
- 学習モデル、前処理時のハイパーパラメータ
- testデータに対する評価結果
これら以外の情報でも、テキストと画像の情報であれば同様に保存できます(学習モデル名、可視化結果の画像、etc...)。先ほど保存していたパラメータや評価値がブラウザ上で表の形で確認できます。この一連の機能をmlflowでは、MLflow Trackingと呼んでいます。
このMLflow Trackingによって、モデルの管理が楽になります。以前に作成したモデルってどうやって作ったっけ...とか、いろいろモデルを作成したけど、結局どのモデルがいいんだろう...といったことを防ぐことができます。
実際に動かす
学習時の情報を保存するサンプルコードを以下に示します。サンプルコードでは、Wine Data Setに対して、前処理として多項式特徴量を作成し、xgboostでクラス分類を行ってみます。サンプルコードのようにscikit-learnのモデルでなくてもxgboostのようにインターフェースがscikit-learnと同じであれば同じように保存することができます。
mlflow.log_param()でパラメータを、mlflow.log_metric()で評価値を、mlflow.sklearn.log_model()でモデル(pipeline)を保存していきます。
実行時の環境は、github上のmlflowのdockerfileを元に、少し改良して作成しています。(anaconda3:5.3.0、mlflow:0.8)
import xgboost as xgb
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, recall_score, precision_score, f1_score
import numpy as np
import mlflow
import mlflow.sklearn
import click
@click.command()
@click.option("--max-depth", default=3, type=int)
@click.option("--learning-rate", default=0.1, type=float)
@click.option("--n-estimators", default=512, type=int)
@click.option("--booster", default="gbtree", type=str)
@click.option("--subsample", default=1.0, type=float)
@click.option("--min-child-weight", default=1.0, type=float)
def train_xgb(max_depth, learning_rate, n_estimators, booster, subsample, min_child_weight):
np.random.seed(0)
# データの用意
X,y = load_wine(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X,y)
with mlflow.start_run():
xgbClassifier = xgb.XGBClassifier( max_depth=max_depth,
learning_rate=learning_rate,
n_estimators=n_estimators,
booster=booster,
subsample=subsample,
min_child_weight=min_child_weight)
pipeline = make_pipeline(PolynomialFeatures(),xgbClassifier)
pipeline.fit(X_train, y_train)
pred = pipeline.predict(X_test)
# 評価値の計算
accuracy = accuracy_score(y_test, pred)
recall = recall_score(y_test, pred, average="weighted")
precision = precision_score(y_test, pred, average="weighted")
f1 = f1_score(y_test, pred, average="weighted")
# パラメータの保存
mlflow.log_param("method_name",xgbClassifier.__class__.__name__)
mlflow.log_param("max_depth", max_depth)
mlflow.log_param("learning_rate", learning_rate)
mlflow.log_param("n_estimators", n_estimators)
mlflow.log_param("booster", booster)
mlflow.log_param("subsample", subsample)
mlflow.log_param("min_child_weight", min_child_weight)
# 評価値の保存
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("recall", recall)
mlflow.log_metric("precision", precision)
mlflow.log_metric("f1", f1)
# モデルの保存
mlflow.sklearn.log_model(pipeline, "model")
if __name__ == "__main__":
train_xgb()
pythonファイルの実行
python tutorial_xgb.py --max-depth 5 --learning-rate 0.1 --n-estimators 512 --booster gbtree --subsample 0.5 --min-child-weight 1.0
デフォルトだと、実行したディレクトリの直下にmlrunsというディレクトリが作成されます。この時、保存先を指定しないでwindowsの環境で実行を行うと、エラーが起きます。これは、mlflowがwindowsの環境を想定して作られておらず、保存先のuriの指定がうまくいかないため発生します(ここのisssueで記述されています)。自分で明示的に保存先を指定すれば問題ありません(指定方法は補足で記述しています)。
補足
mlrunsディレクトリ内には、experimentsという単位ごとにディレクトリが作成されています(デフォルトだと、0のみ)。このexperimentsを分けることで、各実験ごとに学習時の情報を保存することができます。この各experimentsディレクトリの中には、各モデルに関する情報がディレクトリ(名前はhash値)ごとに格納されています。
mlflowの保存先を自分で指定したい場合は、以下の処理を実行します。
tracking_uri = "保存先のuri"
mlflow.set_tracking_uri(tracking_uri)
experimentsを変更したい場合は、以下の処理を実行します。
experiment_name = "実験名"
mlflow.set_experiment(experiment_name)
また、パラメータ、評価値、モデル以外の情報を保存したい場合は、各モデルのartifactsというディレクトリに保存します。artifactsは、modelの情報が格納されているディレクトリですが、その他の情報も保存することができます。画像データかテキストデータであれば、この後のmlflow ui上で内容を確認することができます。処理としては、一度別のディレクトリにデータを保存し、log_artifactで保存するデータのパスを指定しています。
# 一時保存先のディレクトリを指定
import tempfile
import os
with tempfile.TemporaryDirectory() as dname:
save_file = os.path.join(dname, "test.txt")
with open(save_file, "w") as f:
print("hello world", file=f)
mlflow.log_artifact(save_file)
これによって、モデルごとにmatplotlibで可視化した結果の画像や、グリッドサーチしたときの結果(.csv)や探索した結果のパラメータの値(.json)などの情報を保存することができます(tempfileの使い方は、こちらを参考にしました)。
保存結果の確認
保存した結果をブラウザで表示したい場合は、mlrunsディレクトリがある(つまり実行時の)ディレクトリで以下のコマンドを実行します(docker上で実行していると、--hostのオプションを付けないとブラウザ上で表示されることが確認できない。)。
mlflow ui --port 5000 --host 0.0.0.0
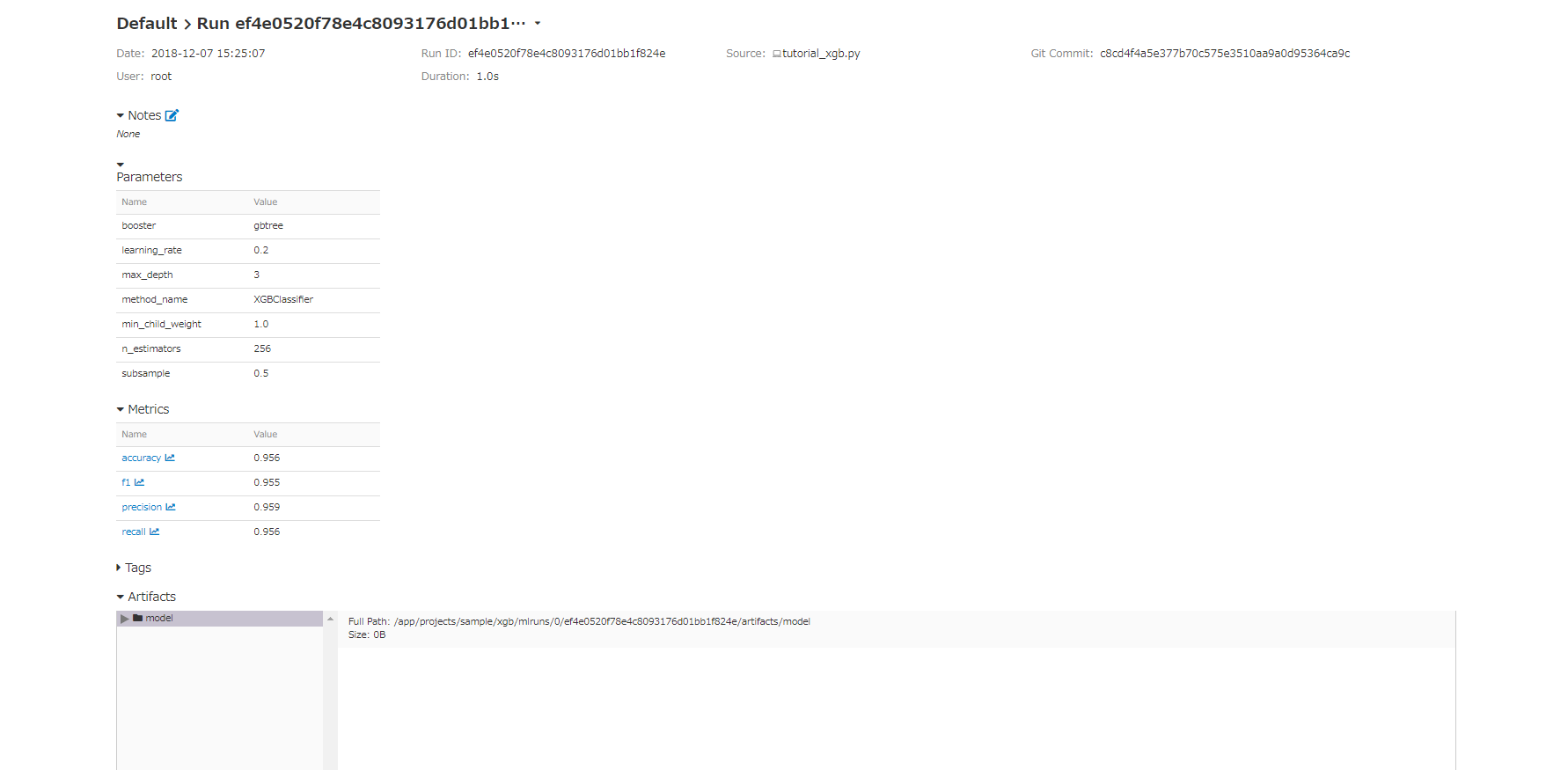
表示される画面は下の画像のように、実行したときのタイムスタンプ、保存したパラメータ、評価値を表で確認できます。
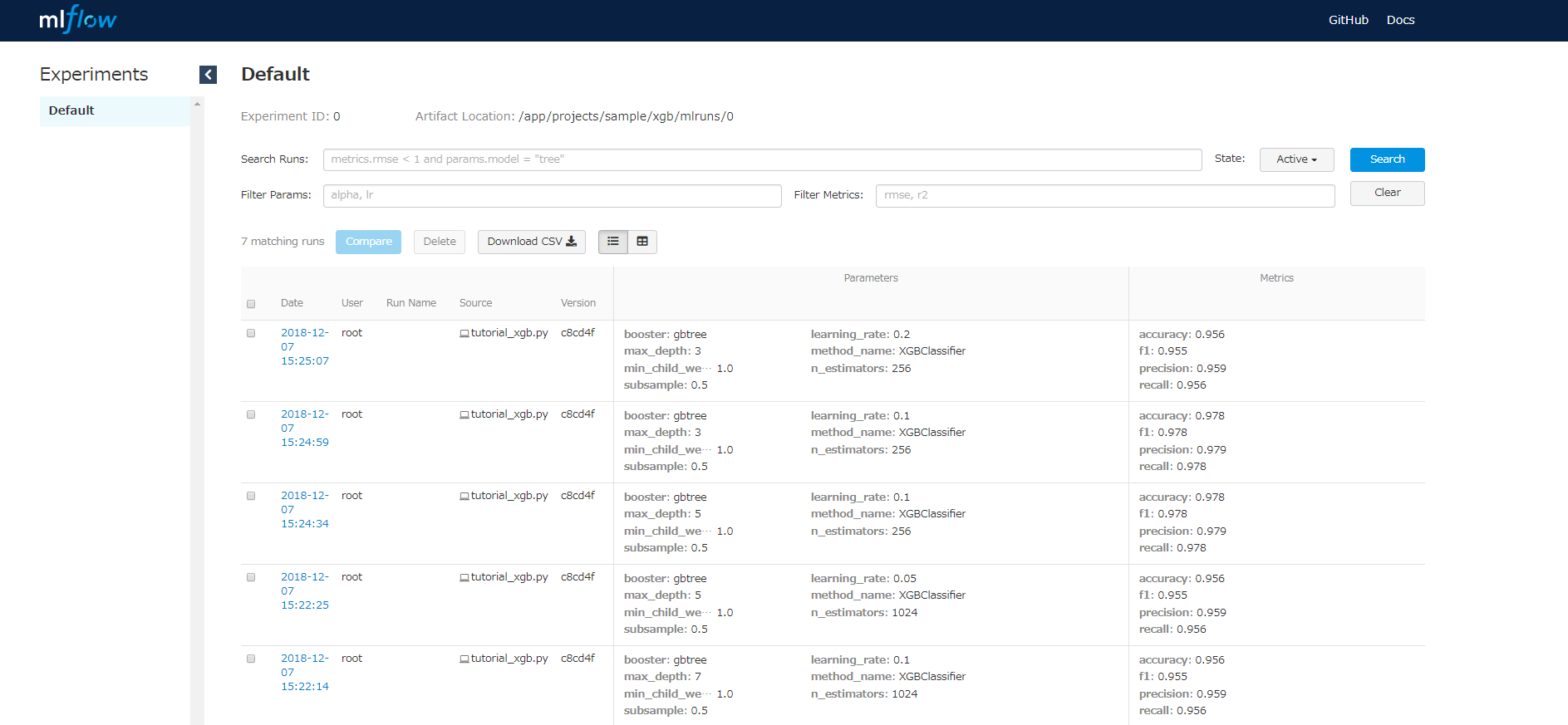
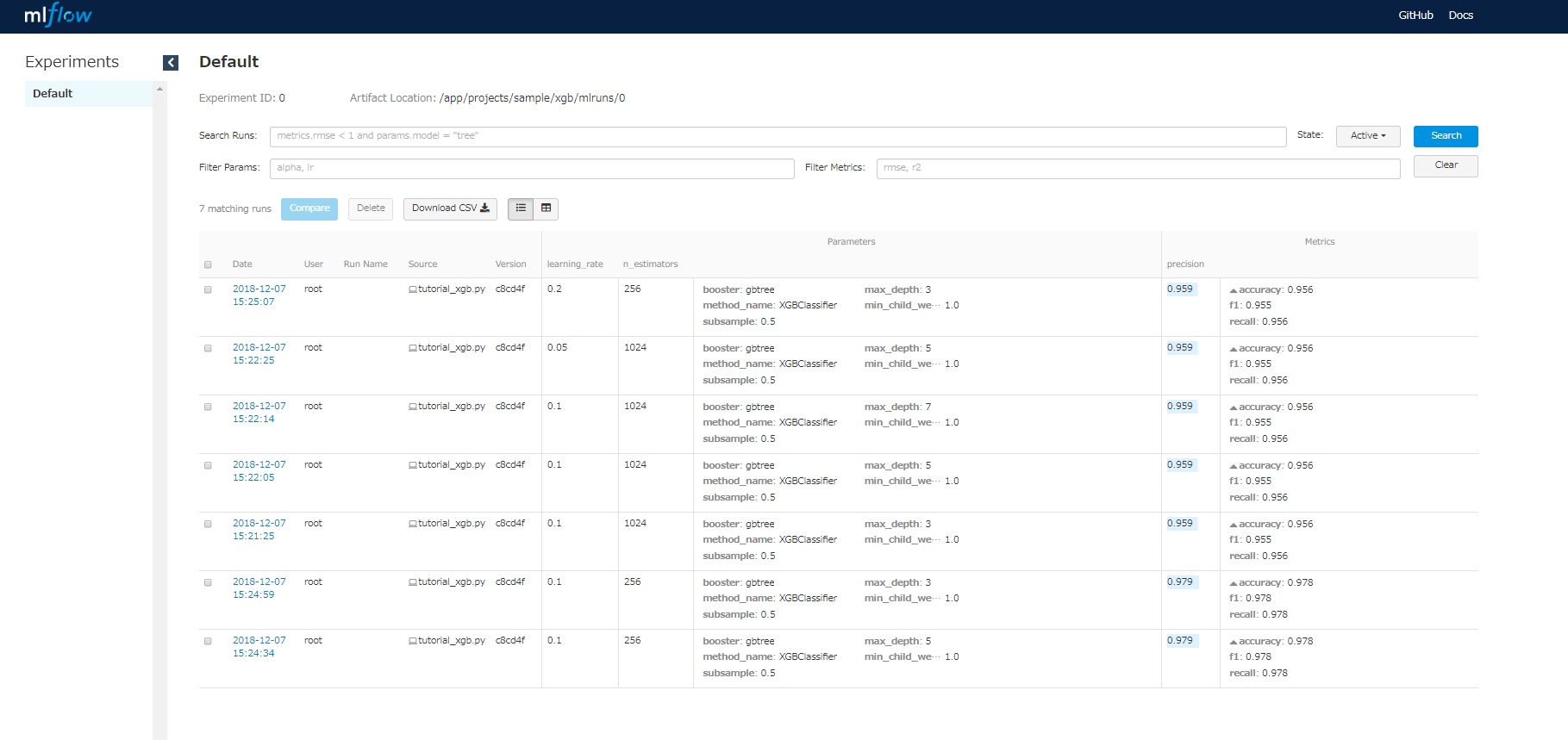
パラメータや、評価値でフィルターをかけたりソートをすることもできて便利です(各パラメータ名等をクリックすればできる)。
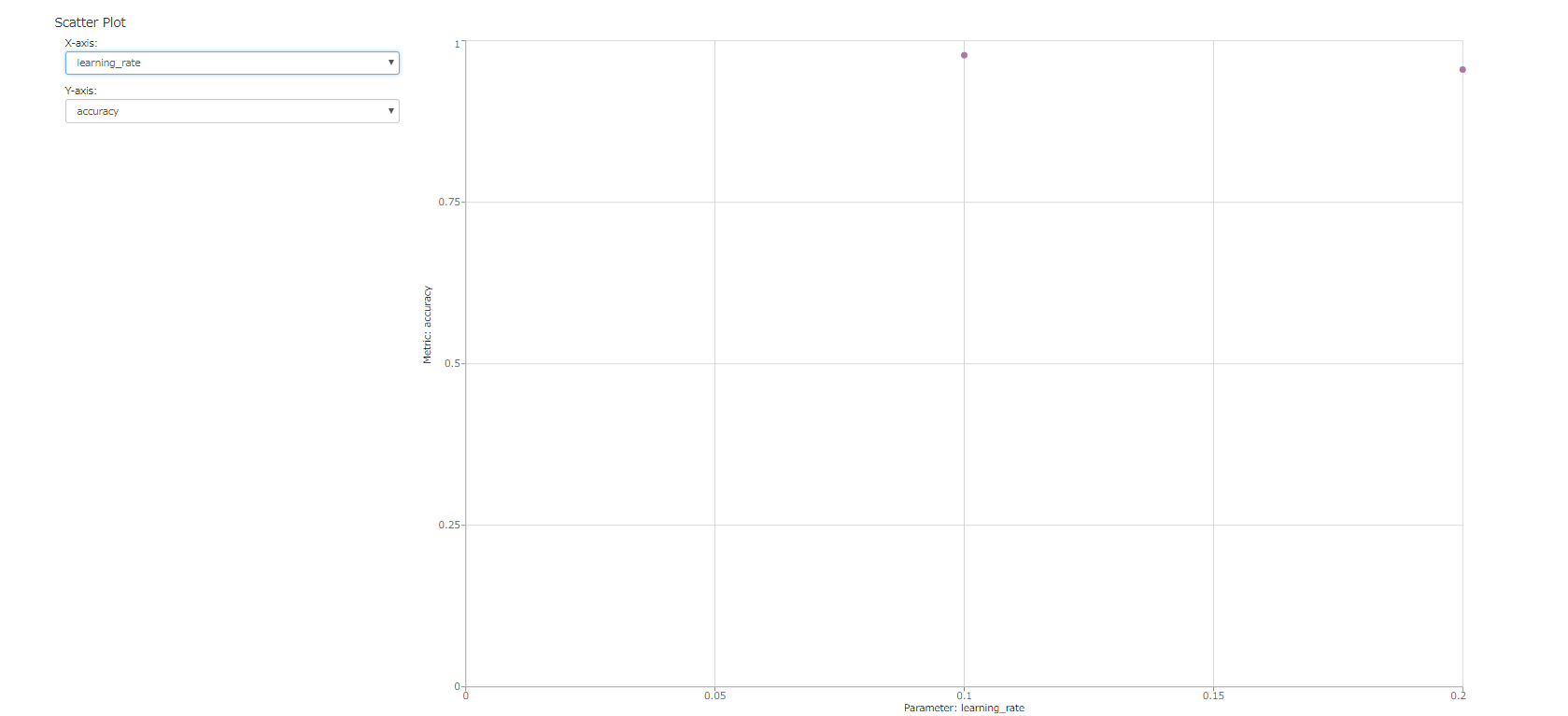
複数の結果を選択し、compareのボタンを押すと、選択した結果についてパラメータと評価値のプロットを行うことができます。
タイムスタンプの部分をクリックすると、下の画像のように、各モデルの保存したパラメータ、評価値、そしてartifactsを確認できます。artifactsは、保存した情報がテキストか画像ならこの画面で表示することができます。モデルごとの詳細情報や、可視化結果を保存しておけば、後で確認することができるので便利です。
MLflow Project
概要
MLflow Projectは、作成した機械学習モデル作成コードを誰でも利用できるようにパッケージングする機能です。パッケージングするコードは、ローカル上のコードだけでなく、gitリポジトリ上のコードも含まれます。この機能で便利なのは、実行時の環境をconda.yamlというファイルに記述しておくことで、その時の環境を再現することができる点です。conda.yamlファイルの作成は、実行時の環境で以下のコマンドを実行することで行えます。
conda env export > conda.yaml
次に、パッケージングをどのように行うかを記述するMLprojectファイルを作成していきます。このファイルには、パラメータの情報やコマンドを記述していきます。
name: My Project
conda_env: conda.yaml
entry_points:
main:
parameters:
max-depth: {type: int, default: 3}
learning-rate: {type: float, default: 0.1}
n-estimators: {type: int, default: 512}
booster: {type: str, default: "gbtree"}
subsample: {type: float, default: 0.1}
command: "python tutorial_xgb.py --max-depth {max-depth} --learning-rate {learning-rate} --n-estimators {n-estimators} --booster {booster} --subsample {subsample}"
conda.yaml、MLproject、tutorial_xgb.pyの3ファイルがあるディレクトリ上で以下のコマンドを実行します。
mlflow run . -P max-depth=5 -P learning-rate=0.05 -P n-estimators=512 -P booster=gbtree -P subsample=0.5 -P min-child-weight=1.0
ディレクトリ指定の部分をカレントディレクトリでなく、gitレポジトリ上のディレクトリに指定することで、gitレポジトリ上のファイルを作成者と同じ環境で実行することができます。ただ、コマンド上で指定したパラメータも自動でmlflow tracking上のパラメータとして保存されるので注意する必要があります。プログラム上でもパラメータを保存していると、重複して保存してしまいます。
MLflow Models
概要
MLflow Modelsは、MLflow Trackingで保存したモデルを簡単にデプロイできる機能です。mlflow ui上で、デプロイしたいモデルのディレクトリパスを確認します。そのディレクトリパスをもとに以下のコマンドを実行します。
mlflow pyfunc serve -m "モデルのパス" -p "ポート番号" --host 0.0.0.0
内部では、APIの作成にflaskが使われているようです。ただ、現在のバージョンだと、学習モデルのpredict()に対する結果のみしか返さないため、分類モデルを作成して、predict_proba()の結果が欲しい場合はこのコマンドを使うことができません(githubにissueを送ったので、もしかしたらいずれ対応してくれるかもしれません)。
APIの使い方
MLflow0.8にアップデートされてから、APIに対するデータの送り方が変わったようです。以前のバージョンだと、列名が自動にソートされてしまい、適切なデータを送ることができませんでした(ちょうどissue送ったらアップデートしてくれました)。
ヘッダー情報
Content-Type: application/json; format=pandas-split
JSONデータ
"columns": [
"alcohol",
"malic_acid",
"ash",
"alcalinity_of_ash",
"magnesium",
"total_phenols",
"flavanoids",
"nonflavanoid_phenols",
"proanthocyanins",
"color_intensity",
"hue",
"od280/od315_of_diluted_wines",
"proline"
],
"data": [
[14.23,1.71,2.43,15.6,127,2.8,3.06,0.28,2.29,5.64,1.04,3.92,1065]
]
JSONデータに関しては、配列の形で渡すことができるので、複数データを一度に送ることも可能です。
curlを使ってデータをおくる場合は、以下のコマンドを入力します。(ポート番号には、指定したポート番号を入力)
curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns": ["alcohol", "malic_acid", "ash", "alcalinity_of_ash", "magnesium", "total_phenols", "flavanoids", "nonflavanoid_phenols", "proanthocyanins", "color_intensity", "hue", "od280/od315_of_diluted_wines", "proline"], "data": [ [14.23,1.71,2.43,15.6,127,2.8,3.06,0.28,2.29,5.64,1.04,3.92,1065] ]}' http://127.0.0.1:(ポート番号)/invocations
windows powershell上でInvoke-WebRequestを使ってデータを送る場合は以下のコマンドを入力します。
Invoke-WebRequest "http://127.0.0.1:(ポート番号)/invocations" -Method POST -ContentType "application/json; format=pandas-split" -Body '{"columns": ["alcohol", "malic_acid", "ash", "alcalinity_of_ash", "magnesium", "total_phenols", "flavanoids", "nonflavanoid_phenols", "proanthocyanins", "color_intensity", "hue", "od280/od315_of_diluted_wines", "proline"], "data": [ [14.23,1.71,2.43,15.6,127,2.8,3.06,0.28,2.29,5.64,1.04,3.92,1065] ]}'
mlflowを実際のデータ分析に利用する
概要
データ活用のプロセスとしてCRISP-DMというものがあります。CRISP-DMは以下のプロセスから構成されています。
- ビジネスの理解
- データの理解
- データの準備
- モデリング
- 評価
- デプロイ
このCRISP-DMの各プロセスごとにどのステップでこのmlflowの機能を利用することができるかを考えていきます。
ビジネス課題の理解、データの理解、データの準備
これらのステップでは、データの可視化やデータの集計によってデータの中身を見ていく作業(EDA(Exploratory Data Analysis))と、特徴量の作成(feature engineering)や外れ値データの除外といった処理を行います。データ分析においてはこれらの作業は非常に重要で、作業の8割~9割を占めるとも言われています(EDA、前処理、特徴量作成に関しては、前回の記事でまとめてます)。
EDAに関しては、pythonであれば、jupyter notebookを使うことが多いと思います。jupyter notebookは、Markdown形式でメモをとれたり、可視化結果の表示などが見やすいので、仮定→検証のサイクルが回しやすいのが便利です。一方で、jupyter notebookのコードは煩雑になりやすいので管理が難しいです。そのため、機械学習のコード管理をするのであれば、前処理の実験をjupyter上で行った後に、ソースコードに落とし込むなどの必要があります。(これが難しい...)
このステップで前処理を行ったときのソースコードと、前処理後のデータはバージョン管理を行ってそのデータがどの処理を行って生成されたものかを把握できるようにしないと、再現性の担保ができないので注意する必要があります。
モデル作成
前処理に関しては、pipelineで表現できる部分はこのモデル作成のステップで行います(PCA, StandardScalerなど)。この時、xgboostなどのscikit-learn以外のライブラリも、pipelineで表現できるライブラリであれば、mlflowを使ってモデルの保存をすることができます。mlflowを用いてモデルの比較を行う場合、以下のような場合が考えられます。
- 一つの手法に対して、各パラメータを設定したときの、それぞれの評価結果
- 複数の手法に対して、最適なパラメータを設定したときの、それぞれの評価結果
- 様々な特徴量を作成して、特徴量を追加したり除外したときの、それぞれの評価結果
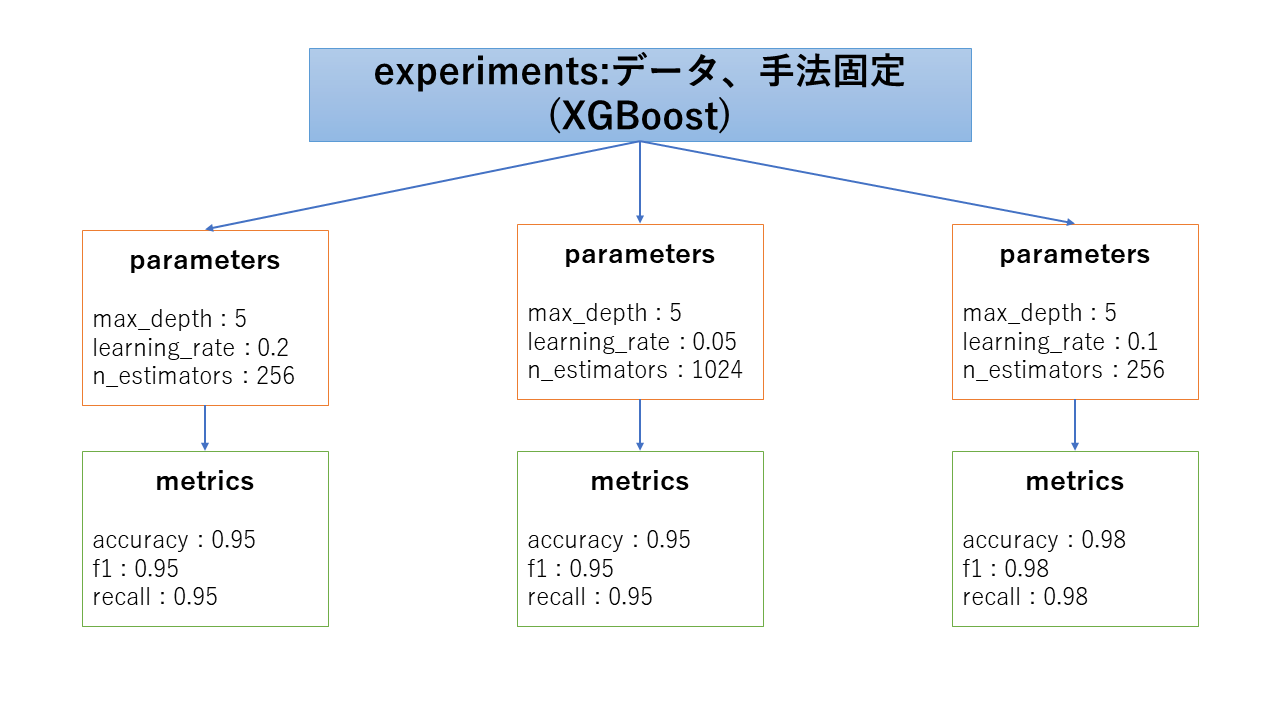
1. 一つの手法に対してパラメータを変更して評価する場合
一つ目に関しては、ある一つの手法に関して、パラメータを変化させていくとどのように評価値が変化するかを試して行きます。scikit-learnのグリッドサーチやランダムサーチのメソッドを使った場合、各パラメータごとに作成されたモデルは取得することができないので、自前でパラメータを動かした結果を順に保存していくか、モデルは保存せずに、探索の結果のみを保存していくことになります。
experimentsの分け方としては、手法ごとに分ける方法が考えられます。評価を行うデータが変わった場合は、experimentsを変更したほうがよいでしょう。
この方法をとる場合として考えられるのは、すでにどの手法を用いるかは検討済みであって、その手法のパラメータ変化時の挙動を確認したい場合です。この後の運用を考えるとデータを追加して再学習をすることも考える必要があるので、その時にパラメータを変化させたときの挙動は確認する必要があると思います。
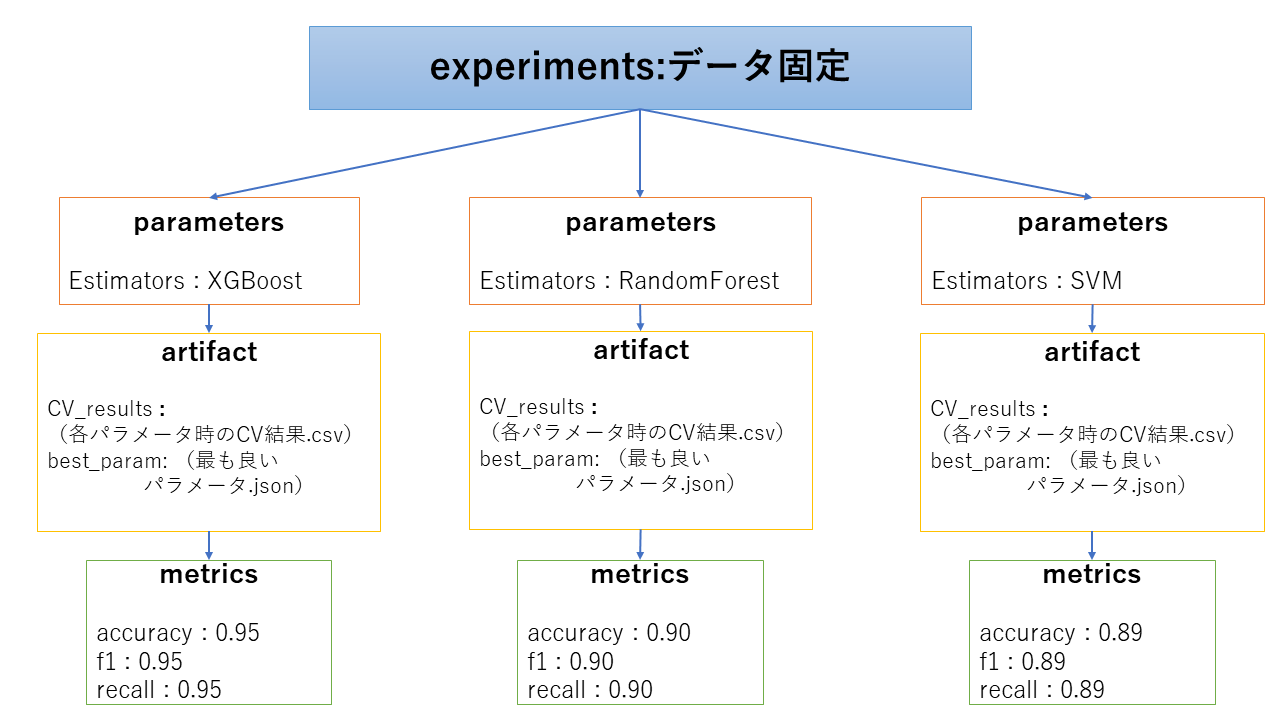
2. 複数の手法に対して各手法を評価する場合
二つ目に関しては、一つのコード内で複数の手法それぞれに対してパラメータチューニング(グリッドサーチやランダムサーチ)を実行し、手法ごとに最も良いモデルに関する情報を順に保存していくことで実現できます。この時は、各モデルごとにパラメータの種類が異なるため、パラメータの値はlog_param()で保存せずに、log_artifactsにjson形式で保存しています。
experimentsの分け方としては、評価を行うデータごとに分ける方法が考えられます。モデル作成以前の前処理を変えた場合には、experimentsを変えるか、parametersかartifactに情報を保存して比較できるようにする手段が考えられます。
この方法をとる場合として考えられるのは、モデル作成の最初の段階でどの手法を用いればよいかが決まっていないため、手法間の比較を行う場合です。とりあえず複数手法を試して、対象のデータに対してどの手法が良いかを考察するときに用いるとよさそうです。
3. 様々な特徴量を作成してどの特徴量が有用かを評価する場合
三つ目に関しては、ある生データを加工して特徴量を作成していき、どの特徴量を用いたときが良いかどうかを比較します。正直、kaggleなどのデータ分析のコンペであればこの比較が一番重要になると思います。方法としては、あるベースとなる手法を使ってパラメータを固定し、特徴量を加工したときそれぞれどのような評価結果になるかを比較することが考えられます。
ここで難しいのは、どの特徴量を使ってモデル作成を行ったかの情報をどのようにしてmlflow上で保存していくかです。
- 特徴量作成を行う関数を特徴量のグループごとに作成し、どの関数を用いたかをjsonとかの形式でartifact上に保存。または、特徴量のグループごとにfeather形式で保存してパスを保存
- parametersに対象の特徴量のグループを用いたか否かを記録
特徴量作成の関数を作る方法は、関数作成の工夫をしないと特徴量が膨大になったときに把握しきれなくなるので気を付けたほうがよさそうです。feather形式の保存については、このブログ記事が参考になります。
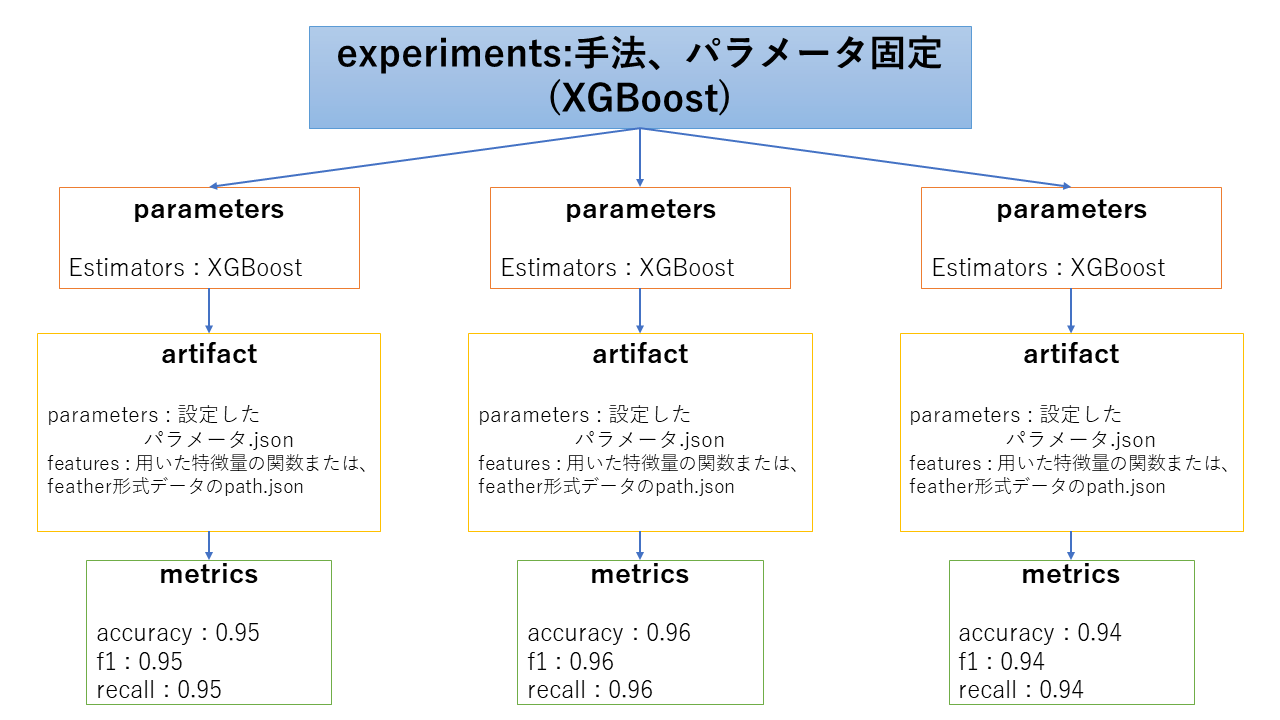
parametersに情報を保存しないと、mlflow uiの画面での比較ができなくなるため、parametersにどの特徴量を用いたかの情報を保存していきます。ただ、データ分析を行っていくうちに、新たな特徴量を思いつき、追加で実験を行うときに、parametersが増えることになるため、同じexperiments上に保存しておくことが難しくなります。
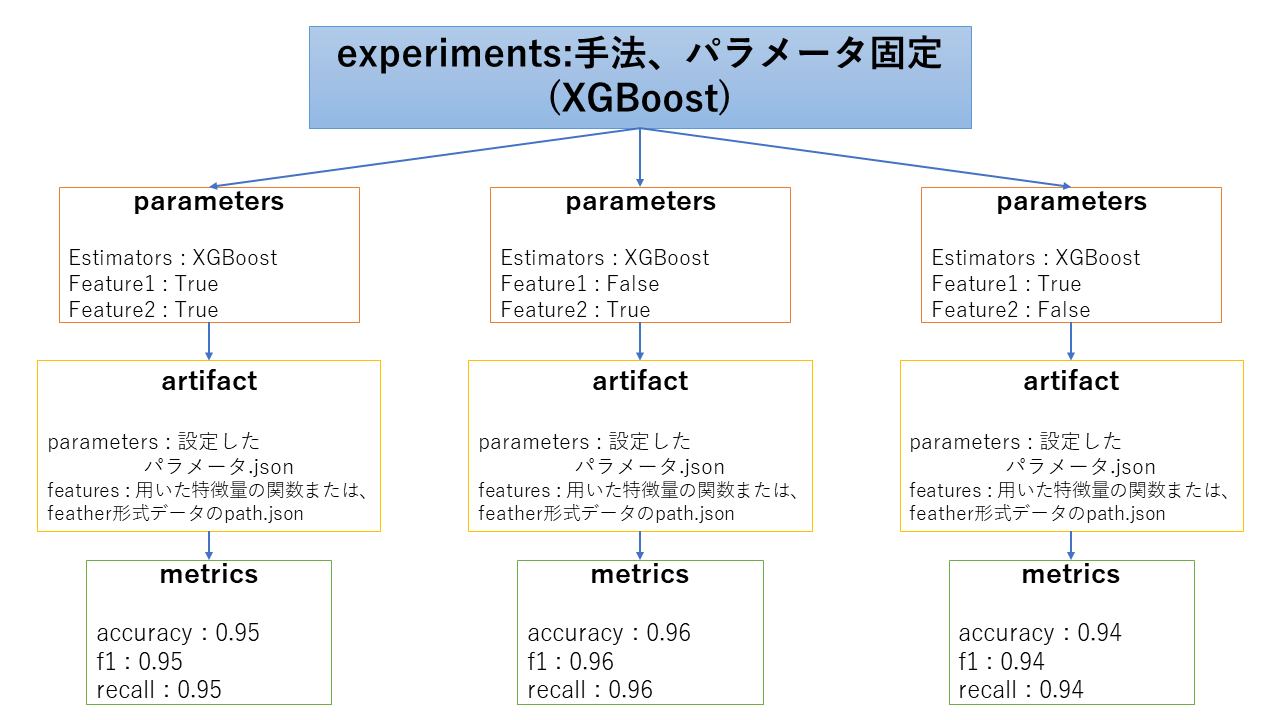
また、どちらの場合も、特徴量作成のロジックのバージョンを変更したときの対応が難しいので、現バージョンとの整合性が取れなくなる問題があります。
評価
モデル作成で保存した各情報をmlflow uiを用いて表示します。mlflow uiのサーバーを立てておけば、そこのサーバにアクセスできる人ならだれでもモデルの結果を確認、考察することができます。メインの画面では、experimentsごとに各モデルのパラメータ、手法によって評価値の比較が行えます。モデルの詳細(artifact)画面では、保存したモデルの情報や、自分自身で保存した各モデルの情報(可視化結果の画像や、グリッドサーチの結果など)を確認することができます。
デプロイ
モデル作成、評価のフェーズを繰り返し、最終的にどのモデルをデプロイするかを決定したときにMLflow Modelsの機能を用いてそのモデルのデプロイを行います。(上記のMLflow Models参照)
デプロイ時にMLflowを使うメリットとしては、APIを自前で作成しなくても、コマンド一つで学習モデルのデプロイをすることができる点です。APIとしてデプロイすることで機械学習モデルをシステムに柔軟に組み込むことができます。メインシステムと同じサーバー上にAPIを立てておいて、メインシステムから呼び出す設計も考えられますし、メインシステムとは異なるサーバー上に同じAPIを複数立てることで負荷分散させてメインシステムから呼び出すような設計も考えられます。(issueを送ったら、上記の内容を教えていただきました。)
おわりに
この記事では、mlflowの具体的な使い方についてと、mlflowをどのようにして使えばデータ分析を効率化できるかを記述しました。今回データ分析のプロセスについていろいろ考えてみましたが、私はまだ仕事でデータ分析の仕事に携わっていません。なので、実際にデータ分析の業務でmlflowを使ったときに、今回考えた管理方法の問題点なども浮き出てくるかもしれません。
仕事で試せるかはわからないので、手始めにkaggleなどのデータ分析のコンペティションに参加して、mlflowがどのように便利か、どの部分が使いにくいかなどを試していきたいと考えてます。
参考
本家
ブログ
- MLflow 〜これで機械学習のモデル管理から API 作成まで楽にできるかも〜
- Kaggleで使えるFeather形式を利用した特徴量管理法
- データサイエンスプロジェクトのディレクトリ構成どうするか問題
書籍
- データ解析の実務プロセス入門
- AI、IoTを成功に導くデータ前処理の極意
- 仕事ではじめる機械学習