はじめに
BigQueryを利用して分析、データ生成等を行われる方であれば一度は目にしたことがあるであろう以下の文字列
Resources exceeded during query execution: Not enough resources for query planning -
too many subqueries or query is too complex
色々試行錯誤した結果たどり着いたいくつかの回避策をまとめます。
なお、今回の回避策はクエリを実行・結果を処理するプログラム側で頑張りすぎることを想定しておらず、可能な限りBigQuery上で完結することを目指しています。また、今回解決を目指すのはWITH句を多用する様なサブクエリが多く弾かれるケースで、Order byなどを利用することにより発生するケースは対象外とします。
なお、今回検証にはGitHub Activity Dataを利用します。
本記事はZOZOテクノロジーズ #3 Advent Calendar 2020の14日目の記事です。
TL;DR
- できるのであれば中間テーブルごとにいい感じの単位でクエリを分割
- 事情でクエリを分割できないのであれば、擬似的に1クエリ内で中間テーブルを作る
1. 処理が大きくなりすぎない範囲で、クエリを分割・中間テーブルに吐き出す
WITH句で表現している一時テーブルを一度明示的に宛先テーブルに保存し、別のクエリから呼び出すことで分割する方法です。
query1.sql
CREATE TABLE `dataset-name`.resource-name.extracted (
commit String,
tree String
);
INSERT INTO `dataset-name`.resource-name.extracted
SELECT commit, tree FROM `bigquery-public-data.github_repos.sample_commits` LIMIT 10;
query2.sql
SELECT * FROM `dataset-name`.resource-name.extracted
上記例ではquery1で取得した結果をquery2で取得しています。
メリット
- 無理がないので綺麗
- 中間テーブル単位でデバッグが可能
中間テーブルが実体のあるテーブルとして吐き出されるため、実際に中のデータを確認することが可能です
デメリット
- クエリが複数に分かれる
- テーブルが複数に分かれるため、適切な生存期間を設定しないとお金がかかる
CREATE TABLE句で生成される宛先テーブルは、デフォルトの設定では自動で消えないため、適切に期限を設定する必要があります
2. 擬似的に中間テーブルを作り、1クエリで処理する
CREATE TEMP TABLE句を用いて一時テーブルを用いる方法です。作成された中間テーブルはWITH句と同様24時間以内生存しますが、その後は自動で削除されます。
一方、WITH句と違い別のテーブル扱いとなるため、実行プランが別で計算されQuery is too complexの回避策として利用可能です。
query1.sql
CREATE TEMP TABLE extracted (
commit String,
tree String
);
INSERT INTO extracted
SELECT commit, tree FROM `bigquery-public-data.github_repos.sample_commits` LIMIT 10;
SELECT * FROM extracted;
メリット
- 1つのSQLでデータが処理しきれる
CREATE TABLE句を利用していたクエリが2つに別れていたのに対して、作成された中間テーブルを使ってその後の処理が可能なため1ファイルで全てを管理することが可能です。
デメリット
- クエリで処理するデータ量が事前にわからない
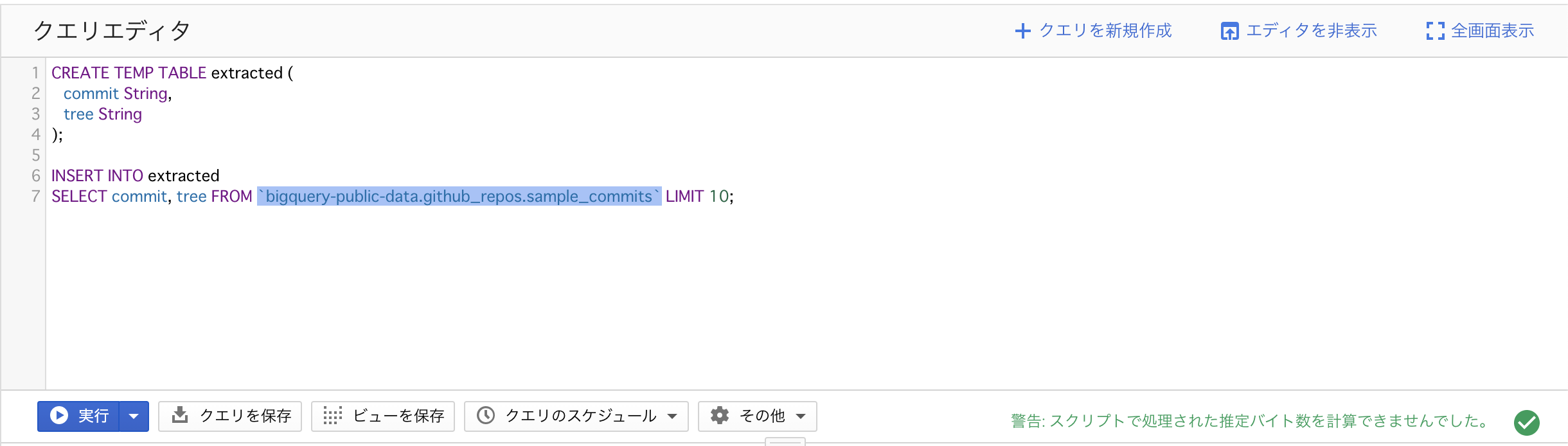
CREATE TEMP TABLE句を利用してクエリを実行しようとすると、スクリプトでの実行となるため推定バイト数の計算が不可となります。
最後に
本投稿ではBigQueryのQuery is too complexを回避する方法を2つ紹介しました。用途によって使い分けていますが、個人的にはデータマートの可読性も含めて1の手法をとるケースが多いですし、BigQueryがクエリを解析できるためWITH句の最適化の恩恵を受けやすいのも理由の1つにあります。