背景
メタバースやAR等の進展で人体の3Dモデル化は需要大
(Vtuber等のアバター,ゲームモーション作成、映像コンテンツの作成等)
今回は画像や動画からどうやって人体を3D化するかという技術を紹介したいと思います。
3Dモデルの表現方法
画像から3Dモデルを作成する上で重要なのは3Dをどのような形で表現をすればよりNNの学習に適しているかということです。
3DモデルをPoint Cloudのような点群として表現するのか、メッシュとして表現するのかなど同じ3Dにしても多数の表現方法があります。用途やNNの学習に適した表現形式 が多数提案されており、今回はSMPLとNeRFという2つの表現方法に関してご紹介いたします。
押さえておきたい要素技術1: SMPLモデル
SMPLとは?
パラメータ化された人体の3Dモデル
SMPL: A Skinned Multi-Person Linear Model, SIGGRAPH ASIA 2015
project page

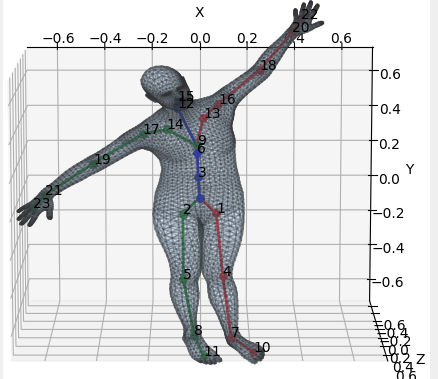
SMPLは6980個の3D頂点座標で構成された3Dモデルです。
23個の間接点,人の向いている方向,それぞれに対する回転角度$θ$と人の体格を決める10次元のパラメータ$β$という人間が解釈しやすい82個のパラメータで操作可能になっていることが特徴です。(24×3+10=82)
SMPLモデル自体が機械学習で作成されており、事前学習済みweightを用いて簡単にモデルのポーズを操作できるようになっています。

左足回転角を操作した例


なぜSMPLモデルがNNにとって良い表現か?
(1) 6980個の3D座標を直接推論するより72個の少ないパラメータを推定するだけでよい
(2) 推論結果が人体のモデルであることが保証されている
例えば6980*3の3d座標をNNのoutputにした場合 膝座標は腰と足首の中間的な座標になることが予測されるがその制約を与えることは通常困難です。SMPLのパラメータという中間表現を出力にすることで人体という事前制約を入れることが可能になります。
人体座標を間接的なパラメータ推定に置き換えることでNNにとって扱いやすい表現に
代表的な論文
End-to-end Recovery of Human Shape and Pose
project page
画像からの人体3Dポーズ推定
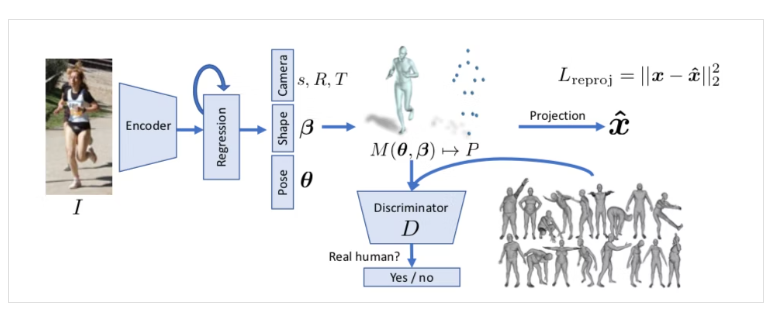

画像からNNでSMPLパラメータの推定する。正解3Dモデルが存在しないので作成した3Dモデルを2Dに再投影し2Dの関節位置の座標でlossを計算する。これに関しては以前記事を書いているのでそちらを参照ください (https://qiita.com/pacifinapacific/items/8894a922eb81014e16ae)
Textureのはりつけ
また人体モデル作成後は通常の3Dモデルと同じように扱えるので
UVmapを付与することでTextureを張り付けることも可能。
押さえておきたい要素技術2: NeRF
Representing Scenes as Neural Radiance Fields for View Synthesis
project page
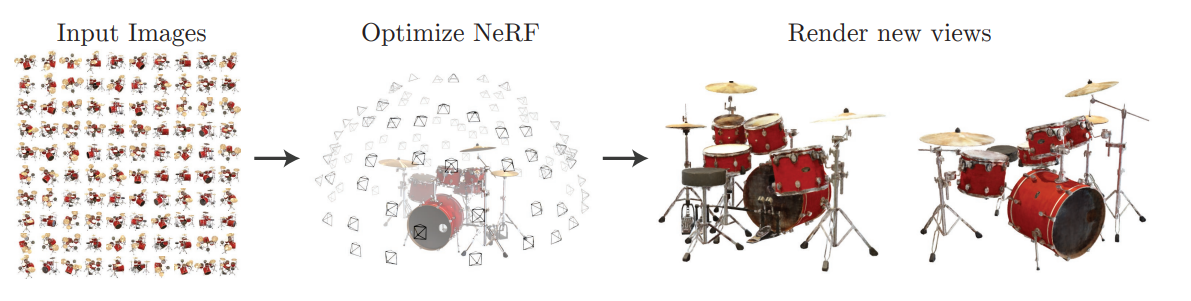
NeRFは人体に限定しない一般的な再構成手法です。
別角度から撮影された100枚ほどの画像から対象の3Dオブジェクトを再構成できるようなモデルになります。
Neural Radiance Fieldsとは?
NeRFはNeural Radiance Fieldsの略称でRadiance FieldsというものをNNで表現したものです
(この論文発の名称になります)
Radiance Fieldとは3次元空間の点に色と密度を紐づけたベクトル場で $(X,Y,Z,R,G,B,σ)$で表現されます。
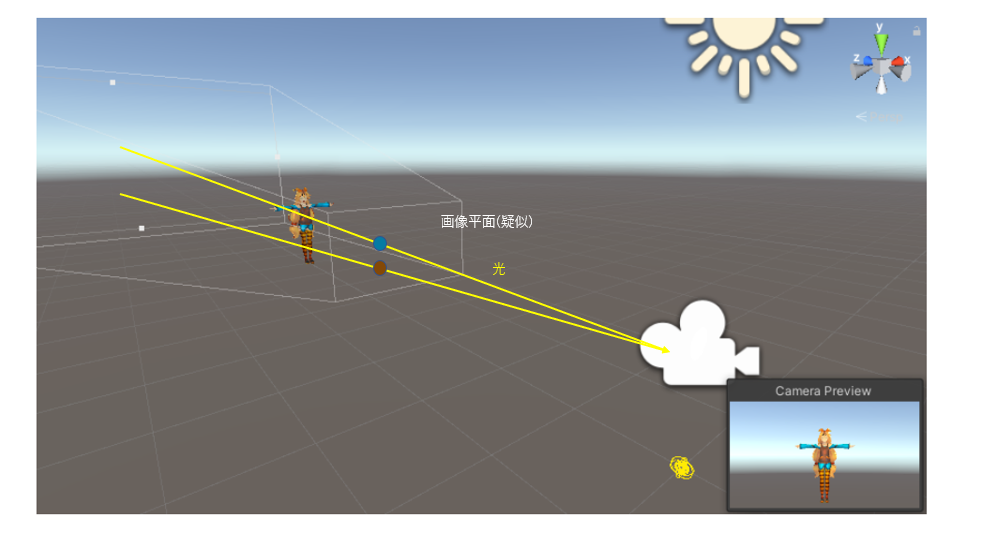
上の図は3D空間のUnityちゃんを撮影する例
撮影される画像のピクセルは画像平面を通る光の直線上にある物体の色が反映されるので、
光線上にある色を積分すれば画像のピクセルがわかることになります。
光線を$r(t)=o+td$とカメラ原点から$d$の角度に$t$だけ伸びる光線とすると画像のピクセル$C(r)$は次のように表現することが可能です。
$C(\mathbf{r})=\int_{t_n}^t T(t) \sigma(\mathbf{r}(t)) \mathbf{c}(\mathbf{r}(t), \mathrm{d}) \mathrm{d} t, \text { where } T(t)=\exp \left(-\int_{t_n}^t \sigma(\mathbf{r}(s)) \mathrm{d} s\right)$
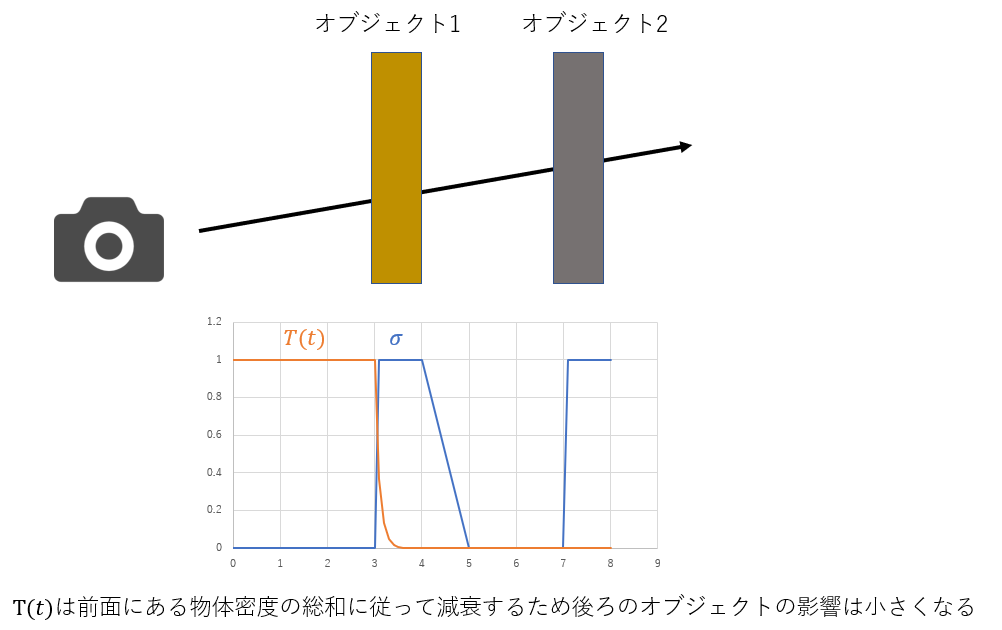
$σ$はその色(物体)の密度≒不透明度
また前に物体があると後ろの物体は隠れて見えないので前のσの総和に従って減衰する$T$を積分に与えています。
どうやって学習させるか?
Neural Radiance Fieldsを得ることができれば3D再構成ができるのでNeural Radiance FieldsをNNに学習させればよいです。
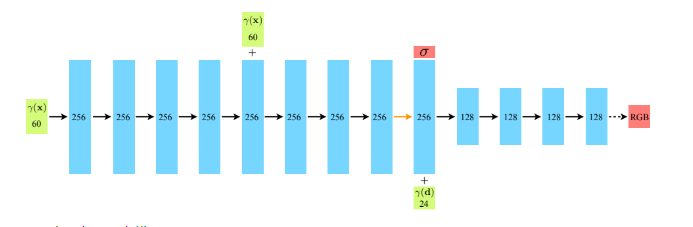
前式で光線$r(t)$と画像上の色$C(r)$との対応関係が得られたので,$r(t)$を指定したときに$C(r)$を返すNNが学習できれば画像のみでの学習が可能になる。
$x$:撮影点と$d$:角度情報をインプットとして$σ$と$RGB$をアウトプット
NeRF参考映像
https://twitter.com/lileaLab/status/1568914288051650560
フォトグラメトリなどの既存技術より艶や光沢などのレンダリング面で優れているらしい。
HumanNeRF
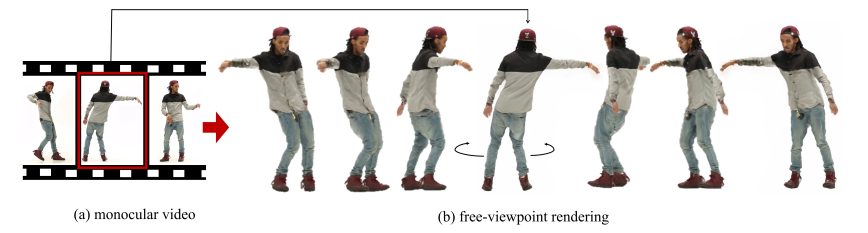
HumanNeRF: Free-viewpoint Rendering of Moving People from Monocular Video
project page
単一の動画から人の3Dモデルを生成する手法
NeRFの問題点
NeRFはマルチカメラで撮影しており同時刻の他視点画像で学習しています。
しかし単一の動画のみで学習することができればさらに活用範囲も広がるようになるでしょう。
ここで動画であれば同一人物の異なった視点情報は得られるが、時系列変化があるため同一ポーズの他視点画像は手に入らないという問題が出てきます→よって通常のNeRFでは上手くいかない
アイデア
どうにかして動画から単一ポーズの他視点映像を作り出せないか?
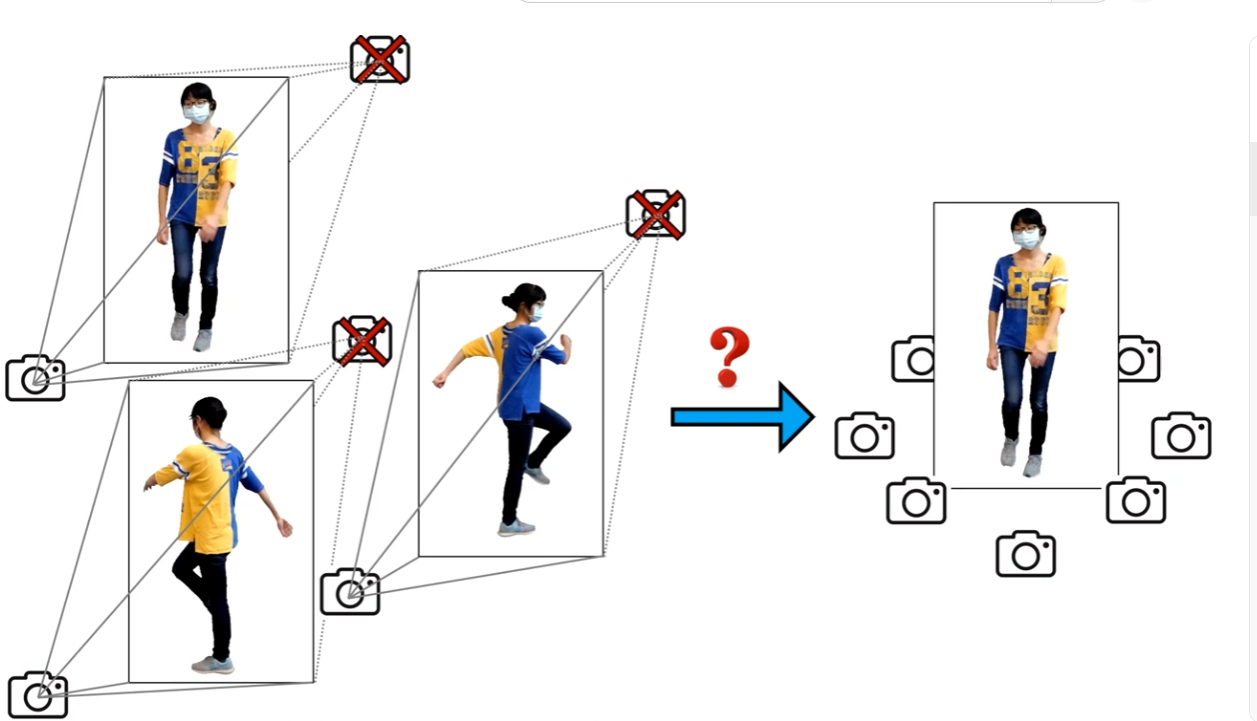
すべてのフレームの人物画像を全て単一のポーズ(canonical space)に変換できればNeRFを学習させることができるのでは
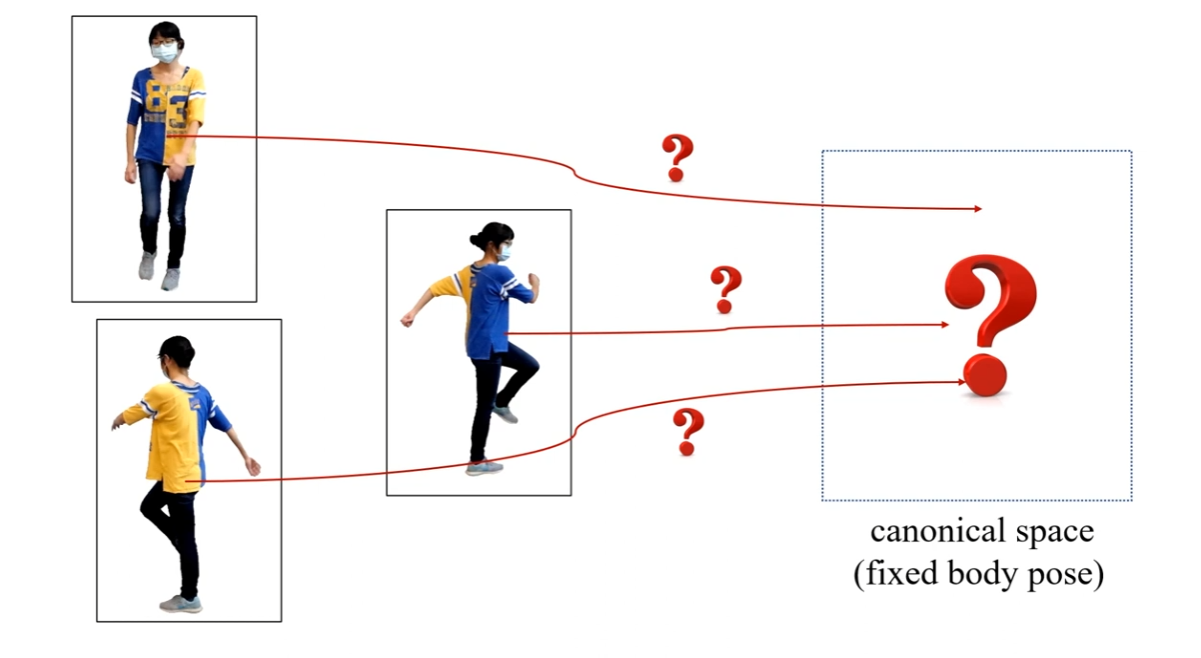
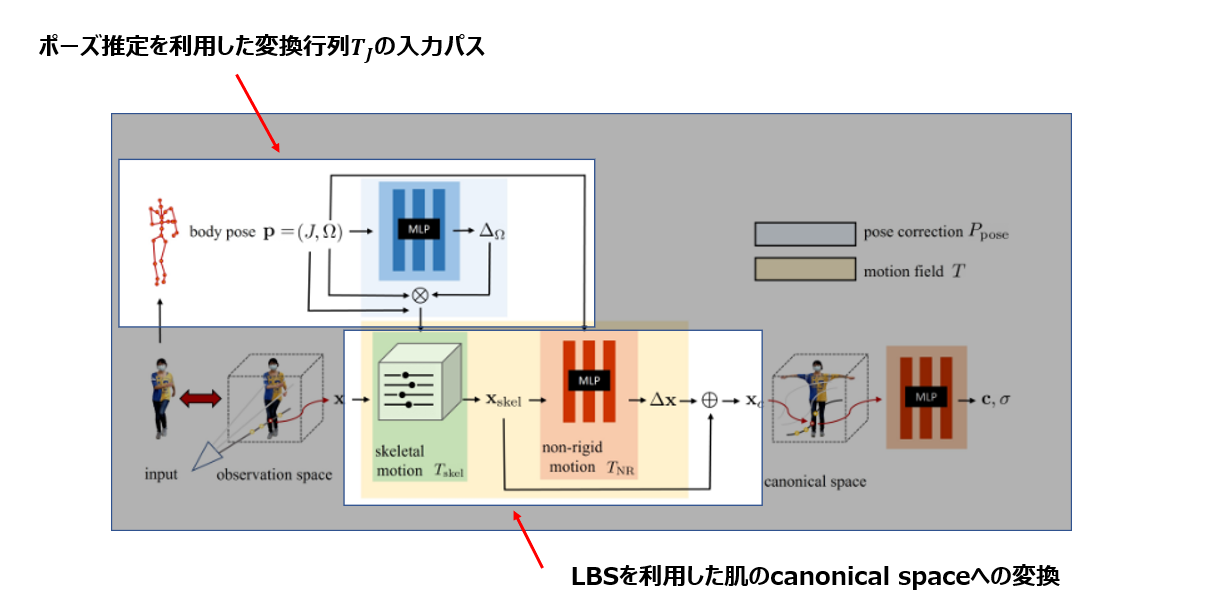
ネットワーク構造
全体を順々に解説していきます。
Step 1 目標整理
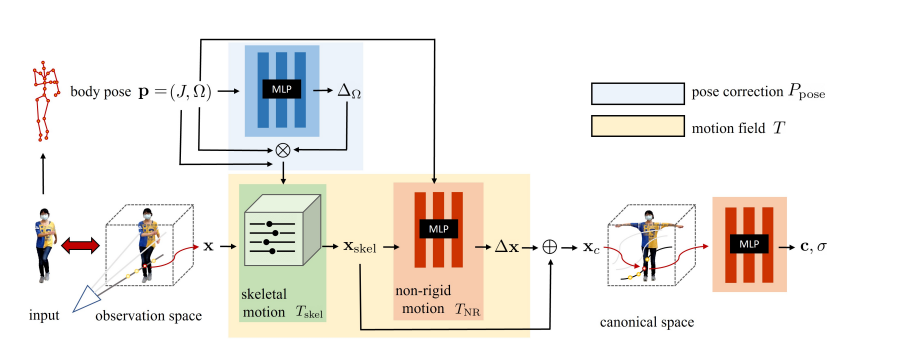
最終目標は入力された画像(observation space)を標準ポーズ(canonical space)に変換し、そこでNeRFを学習させること。
ちなみに座標変換が入るのでobservation spaceの光線はcanonical spaceでは曲線になる。
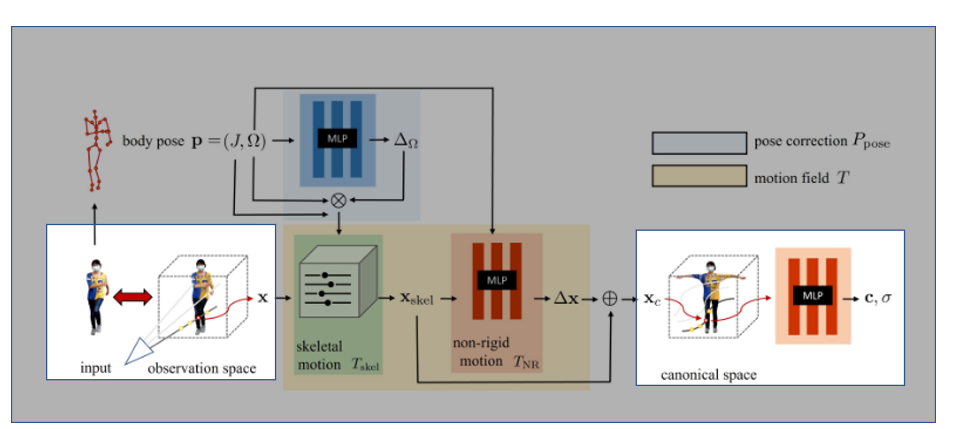
Step2 canonical spaceへの変換
ではどうやってポーズ変換を行うか?
まず関節座標だけならポーズ変換は簡単!!
画像から3Dのポーズ推定を行ってあげて標準ポーズになるように変換行列$T_j$を計算すればよい
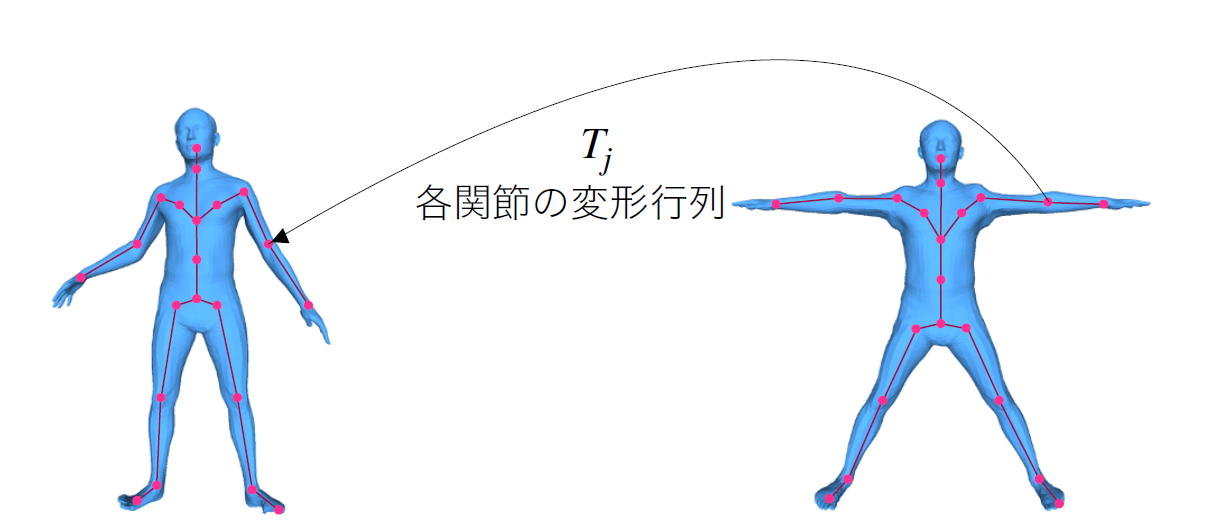
図はhttps://www.slideshare.net/secret/kkeTZme92icSHg から引用
ただ変換したいのは関節の上に乗っている肌、衣服などの画素。
$T_j$を使ってその変換を上手く定義してあげたい。
(当然ながら皮膚は1つの関節の動きに100%追従するわけではないので$T_j$を各皮膚の変換にそのまま用いることはできない)
そこでLBS(Linear Blend Skining)という手法で変換する。
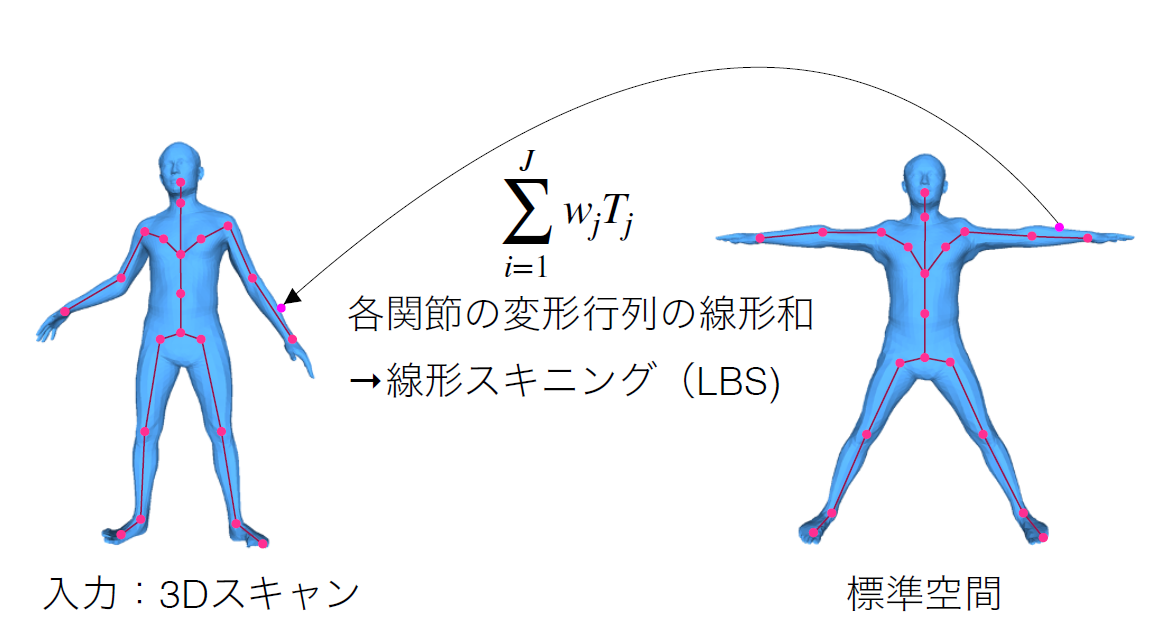
LBSとは?
人の肌が剛体(変形しない)であったなら...
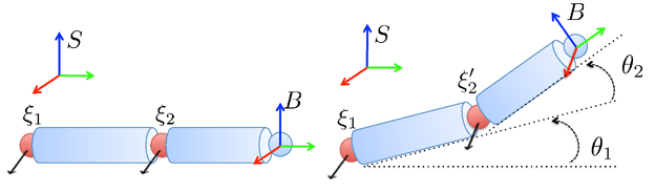
肌座標は$T_j$の単純な和で定義される ($θ=θ1+θ2$)
人の肌は剛体でないので各関節に引っ張られもっと中間的に変化する。(図では肘と手首の間の皮膚は肘に80%、手首に20%影響されている)

そこでその肌がどこの関節からその程度影響を受けるかという値(skin weight)を定義してあげることにより変換が記述できるようになります。
すなわち$t_i$を肌座標とすると次のように関節の変換行列$T_j$の重み付き線形和で定義できる
$t_i=\sum_{i=1}^J w_j T_jt_i$
これをLBSと呼びます。
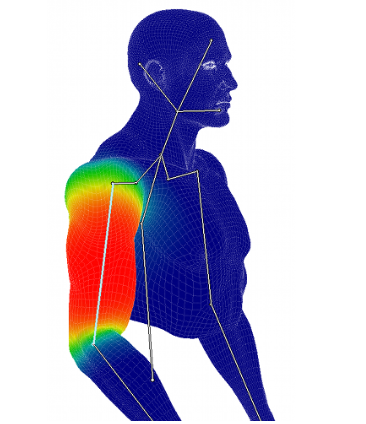
ここでskin weight $w_j$は未知数であるので、これをNeRFの学習と同時に学習させる。
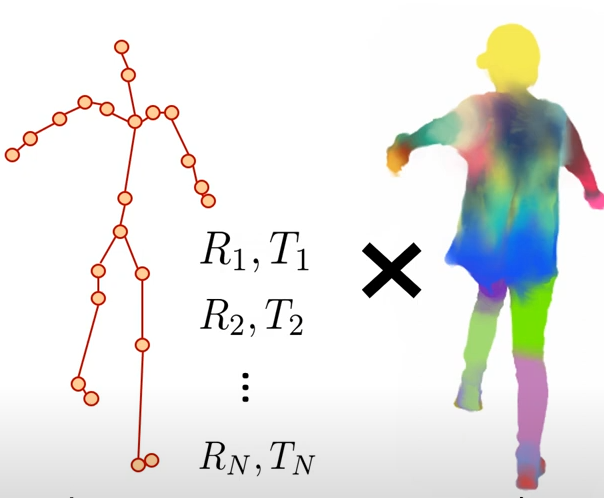
HumanNeRFまとめ
異なる時間での画像でNeRFを学習させるため、いったん人の画像をcanonical spaceに変換した。
変換はLBSを用いて行われその際の関節からの影響度$w$も同時にNeRFのlossで学習させる。
これにより単一のカメラ動画から人体特化のNeRFが学習できる。
もっと先の技術は?
HumanNeRFは人の骨格情報を利用していたが、SMPLモデル使った方がリッチで精度よくできそうじゃない→すごい論文がAppleから出た!!
in the wildでしかも背景合成しながら任意ポーズでのレンダリングまで可能というすごさ!!
背景用のNeRF+人用のNeRF+人背景分離用のMaskRCNN+画像からのSMPL推定+深度推定等もろもろ。。。
とてもよみきれなかったので紹介まで