はじめに
最近ちょくちょく耳にするself supervised learningの論文を解説していきます。
といってもself supervisedの論文はたくさんあるので,今回は__dense tracking__と呼ばれるタスクに絞って現在に到るまでの発展の過程を追っていきます。
解説する次の論文は5本です。
[1] Tracking emerges by colorizing videos^1 略称 Vid. Color
[2] Learning Correspondence from the Cycle-consistency of Time1 (2019) 略称CycleTime
[3] Self-supervised Learning for Video Correspondence Flow^3 略称 CorrFlow
[4]:Joint-task Self-supervised Learning for Temporal Correspondence^4 略称 UVC
[5]: MAST: A Memory-Augmented Self-Supervised Tracker^5 略称 MAST
5本目の論文はCVPR2020に採択された最新の論文で、これはpart2(近日公開予定)で解説します。
1~4本目は5本目の論文にself supervisedの比較手法として挙げられているものです。
したがってpart1,2を合わせて読むことでdense trackingタスクの流れを追えるようにしたつもりです。

図1 dense tracking(self supervised系)性能比較2
使用している図は特に断りがない場合紹介元の論文から引用しています。
Tracking Emerges by Colorizing Videos3
動画系self supervisedの代表的な論文になります。まずはデモを見てください。
Our latest work shows that learning to colorize videos causes visual tracking to emerge automatically!
— Carl Vondrick (@cvondrick) June 27, 2018
Blog: https://t.co/FDVzJmmZ7h
Paper: https://t.co/U4jS83iI7B@alirezafathi @kevskibombom @sguada @abhi2610 pic.twitter.com/R3vMR3raFJ
このデモでやっていることの基本的な考え方はOptical Flowと同じです。(optical flowのわかりやすい解説)
時刻$T-1$のフレームの各pixelが時刻$T$のフレームのどこのpixelに相当するかを予測させています。最初のフレームで、追跡してほしい対象のpixelをmaskにより指定してあげれば、その後のフレームでもpixelの移動を捉えることで、その対象を追跡することが可能になるわけです。
またmaskだけでなく、関節位置といったkeypointのtrackingも同様の考え方で行うことができます。
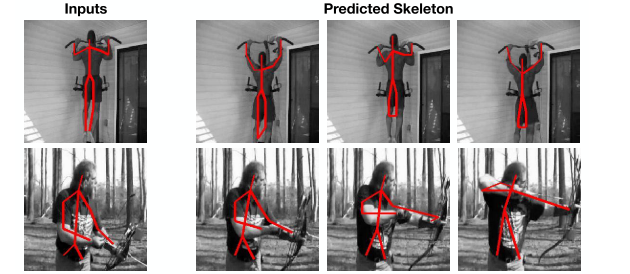
図2 labelデータのtracking
このようなタスクをフレーム間のピクセルの密な対応づけという意味で__dense tracking__と呼んだりします。
Colorization
ではどのように学習させるのでしょうか?optical flow予測など従来のネットワークはアノテーションとして正解optical flowを与えていました。しかしこの論文ではアノテーションを一切必要としない学習を提案しています。それがVideo colorizationです。
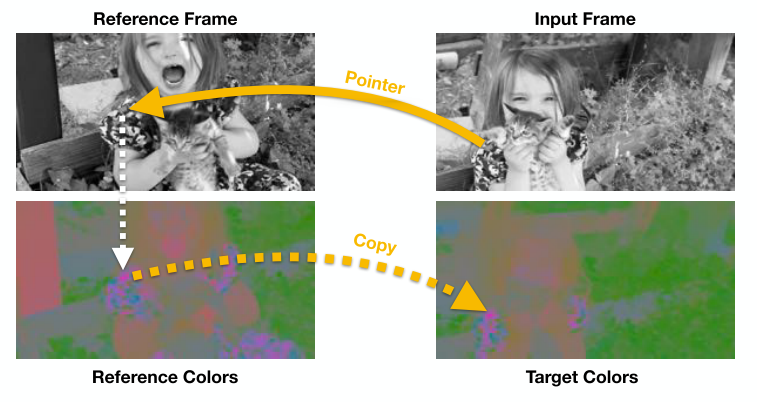
図3 動画を利用したカラー復元
Target,Referenceの2枚のフレームを一回グレースケールに変換してしまって、それぞれCNNに通すことでpixelの移動を予測しpixel位置の対応関係(pointer)を得ます。そしてTarget Frameのカラーをpointerを用いてReference Frameのカラーからコピーしてあげることで予測させるのです。
こうすることで予測した色付けとTarget Frameの実際の色で予測が正しいかのlossが計算でき、optical flowのアノテーションがなくとも学習が可能になります。
具体的な計算方法について説明します。目標はTarget frameのカラーをReference frameのカラーからコピーするためのpointerを作ること。数式でかけば次のように表せます。
$$y_{j}=\sum_{i} A_{i j} c_{i}$$
$y_{j}$はTarget frameのj番目のpixelの予測カラー、$c_{i}$はReference frameのi番目のpixelカラーです。数式がわかりにくい場合は参考記事も見てみてください
そして$A_{i j}$はi番目のpixelからj番目のpixelへの変換行列。すなわちpointerです。今回は$A_{i,j}$の要素をsofmaxにより0~1することで複数のpixelを参照できるようにしています。
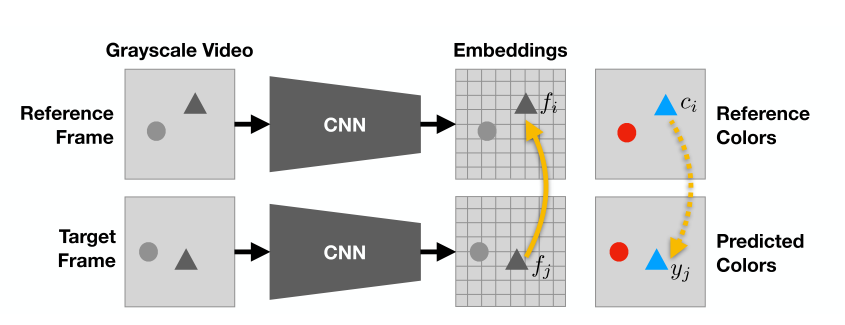
図4 ネットワーク構造
まず上図のようにReference frame,Target frameともにグレースケールに変換した後,CNNに通しそれぞれの特徴ベクトル$f$を得ます。
さてpointerを作るためにはReference frameのi番目のpixelとTarget frameのj番目のpixelの類似度がわかればよいので、内積をとってあげます。
$$A_{i,j}=f_{i}^Tf_{j}$$
ただ今回は類似度を0~1の確率として正規化したいので,softmaxをかけたものを使用します。
$$A_{i j}=\frac{\exp \left(f_{i}^{T} f_{j}\right)}{\sum_{k} \exp \left(f_{k}^{T} f_{j}\right)}$$
これでpointerができたので後は次のようにTarget frameのカラーで誤差計算すれば完成です。
\min _{\theta} \sum_{j} \mathcal{L}\left(y_{j}, c_{j}\right)
補足としてこの論文では,問題を簡易化するためにRGB値をそのまま予測するのではなく,Lab空間へ変換した後データセット内でkmeansによるクラスタリングを行い16種類のクラスタに分割、そして分類された色のクラス分類(cross entropy loss)で定式化しています。
以上がこの論文で提案しているself supervisedの枠組みになります。
あえてGray scaleに変換することで変換前の色をlabelとして使用するなんて頭良すぎ!って感じですね。
動画で同じ物体の同じ箇所は(少なくとも短フレーム間では)同一の色を持っているという前提を上手く利用し自動的にラベルを作ることに成功しています。
以降はこの論文を起点としたself supervised発展の歴史を追っていきます。
Learning Correspondence from the Cycle-consistency of Time 1
次はCVPR2019の論文を紹介します。略称はCycleTimeです。
この手法はColorizationとは違い,__Cycle consistency__という考えを用いてラベルを自動生成しています。

図5 cycle consistency
Cycle consistency__は簡単に言うと、「行ってまた帰ってきたら元の状態と一致するはず」__という考え方です。
上図のようにまず動画を逆再生し、時刻$T$の物体位置から時刻$T-1$における位置を予測、時刻$T-1$の予測から時刻$T-2$の位置を予測します。今度は逆に順再生して時刻$T-2$の予測から時刻$T-1$,$T$を予測すると、最初に指定した時刻$T$の物体位置と順再生で戻ってきた時刻$T$の位置予測は一致するはずです。
これを比較してLossを計算するのがcycle consistencyになります。
では論文の内容を詳しく見ていきましょう。
提案手法
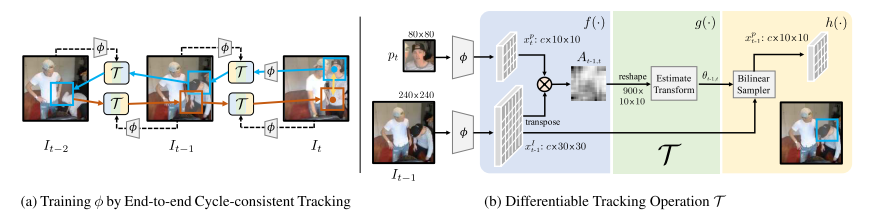
図6 ネットワーク図
予測はpatch単位で行われます。すなわち$T-i+1$から適当に切り取ったpatchが$T-i+2$の画像のどこに相当するか予測することを考えます。
これはネットワーク$\mathcal{T}$によって行われますので中身を見ていきましょう。
$\mathcal{T}$はまず時刻$T-i+2$の画像,__$I_{T-i+2}$__と時刻$T-i+1$の画像から切り取られたpatch _$p{T-i+1}$__の両方をResnetベースのエンコーダーに通し、それぞれの特徴map __$x^I,x^p$_を抽出します。
次は先ほどと同様にして,内積を取ってあげれば類似度行列$A(i,j)$が取得できます。
$$A(j, i)=\frac{\exp \left(x^{I}(j)^{\top} x^{p}(i)\right)}{\sum{j} \exp \left(x^{I}(j)^{\top} x^{p}(i)\right)}$$
ただ今回は色の対応だけでなく、位置座標の対応も見たいので座標を変換する処理が必要になります。
そこでさらに、行列$A(j, i)$を浅いネットワークに通すことで、幾何変換のパラメータである$\theta$を出力させてあげます。あとは$\theta$にしたがって$I_{T-i+2}$を座標変換してあげれば$T-i+2$における予測patchを取得できることになります。
同様にして$T-i+2$から$T-i+3$を予測させ‥ということを繰り返すと連続した$i$フレーム($t-i$から$t-1$)の順再生予測は次のように書けます。
$$\mathcal{T}^{(i)}\left(x_{t-i}^{I}, x^{p}\right)=\mathcal{T}\left(x_{t-1}^{I}, \mathcal{T}\left(x_{t-2}^{I}, \ldots \mathcal{T}\left(x_{t-i}^{I}, x^{p}\right)\right)\right)$$
また逆再生も同じように
$$\mathcal{T}^{(-i)}\left(x_{t-1}^{I}, x^{p}\right)=\mathcal{T}\left(x_{t-i}^{I}, \mathcal{T}\left(x_{t-i+1}^{I}, \ldots \mathcal{T}\left(x_{t-1}^{I}, x^{p}\right)\right)\right)$$
とかけるのでこの2つの式を組み合わせるとcycle consistency lossは次のようになります。
\mathcal{L}_{l o n g}^{i}=l_{\theta}\left(x_{t}^{p}, \mathcal{T}^{(i)}\left(x_{t-i+1}^{I}, \mathcal{T}^{(-i)}\left(x_{t-1}^{I}, x_{t}^{p}\right)\right)\right)
$l_{\theta}$はpatchの座標のずれをMSEで計算する関数です。
また位置だけでなく、patchどうしの特徴mapの差も計算してあげます
\mathcal{L}_{s i m}^{i}=-\left\langle x_{t}^{p}, \mathcal{T}\left(x_{t-i}^{I}, x_{t}^{p}\right)\right\rangle
Cycle consitencyの基本的な考え方は以上です。
ただ、このままだと次のように物体が一度隠れて、また見えるような場合に対応できません。
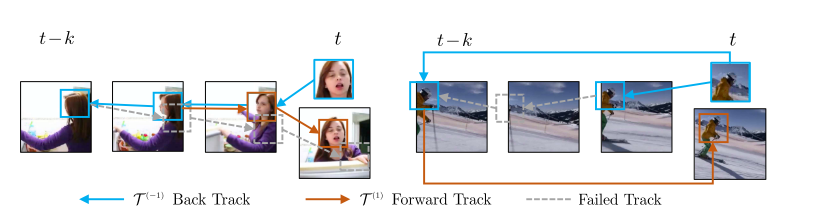
図7 cycle consistencyが難しい場合(左:顔の正面が見えなくなる。右:フレームアウトを挟む)
上図を見ると、隣り合ったフレーム間では対応づけることが難しい場合でも、離れたフレームなら対応づけることができそうです。
そこでこの論文では時系列的に隣接した画像だけでなく、$i$フレームskipさせた予測も入れています。
\mathcal{L}_{s k i p}^{i}=l_{\theta}\left(x_{t}^{p}, \mathcal{T}\left(x_{t}^{I}, \mathcal{T}\left(x_{t-i}^{I}, x_{t}^{p}\right)\right)\right)
長かったですが最終的なlossは以上3つのlossを足して,
\mathcal{L}=\sum_{i=1}^{k} \mathcal{L}_{s i m}^{i}+\lambda \mathcal{L}_{s k i p}^{i}+\lambda \mathcal{L}_{l o n g}^{i}
と書くことができます。
数式が長くなりましたが、ざっくりとでもCycle consistencyの雰囲気を掴んでいただけたら嬉しいです。
Self-supervised Learning for Video Correspondence Flow4
前2つの論文で,Colorizationとcycle-consistencyという2つのself supervised手法を見てきました。次はその両方を組み合わせた論文を紹介します。略称はColorFlowです。
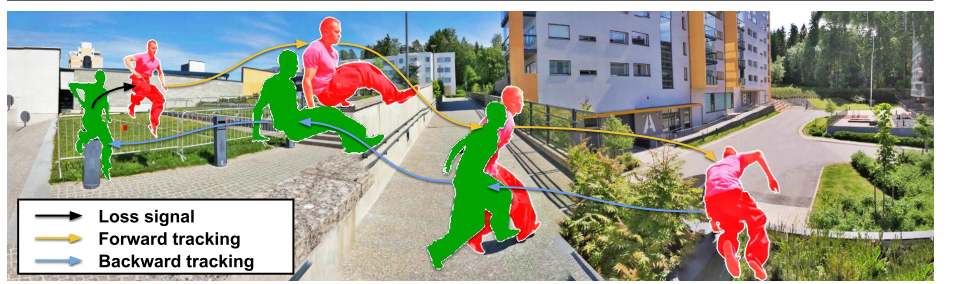
図8 アルゴリズムの認識イメージ
この論文は最初に紹介したVideo Colorization論文の課題点を挙げ、それを解決する手法を提案する構成になっています。
挙げられている課題点に関しては次の2点です。
課題1:カラー情報をグレースケールにしてからmatchingを行っているのでせっかくのカラー情報が欠落してしまっている。
課題2:予測するフレームが長くなるにしたがって間違った予測が蓄積してしまい予測がドリフトしてしまう
これを踏まえた上で提案手法を見ていきましょう。
提案手法
課題1
カラー画像をグレースケールに落としてからCNNに入れて予測させるのは、matchingの予測にRGBカラーの情報が使えませんので,かなりもったいないことをしています。しかしself supervisedとして学習させるために何らかのボトルネックをかけることは必要です。
そこでこの手法では単純にgrayscaleに落とすのではなく、RGBチャネルをランダムに0にするという形でボトルネックをかけます。(下図参照) またさらに、輝度やコントラストなどの摂動も追加します。
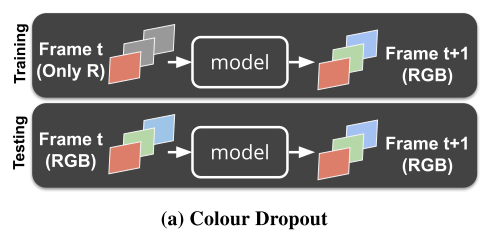
図9 ボトルネックの改良
こうすることによりカラー情報をある程度保持したまま学習が可能になります。またそれだけでなく,ランダムにチャネルを0にすること自体が,dropoutの効果を期待でき、輝度の変化を加えることでdata augementationも自動的に行うことができます。
単純にグレースケールに落とすよりかなりのロバスト性向上が見込めます。
なおテスト時はRGBそのまま入れるだけでよいので簡単です
課題2
当たり前ですが、比較する画像が時間的に離れていると予測は難しくなります。特にオクルージョンや形状変化などがあれば対応点を見つけるのはより困難になってきます。また、一度予測がずれるとその予測を元に次のフレームを予測しようとするので誤差が蓄積し、どんどん予測がドリフトしてしまいます。この論文ではそのような__Long-term__における問題に対し、__モデル予測のカラーを時々ground truthのカラーとしても使う__ということを提案しています。
\hat{I}_{n}=\left\{\begin{array}{ll}\psi\left(A_{(n-1, n)}, I_{n-1}\right) & (1) \\ \psi\left(A_{(n-1, n)}, \hat{I}_{n-1}\right) & (2)\end{array}\right.
上の式(1)は時刻$n-1$の画像$I_{n-1}$を用いて時刻$n$の色$\hat{I}_{n}$を予測していますが,
ときどき、(2)のように$I_{n-1}$の代わりに直前の予測である$\hat{I}_{n-1}$を用いて予測させます。こうすることで、予測が外れた状態からtrackが復元することを試みています。
予測カラーを用いる割合はモデルが学習するにつれて上げていきます。
なお、この考え方はScheduled Samplingと呼ばれSeq2Seqで広く用いられる手法とのこと。
そして最後に長期的な予測でもcycle consistecyによる制約もかけることで、さらにロバスト性を向上させています。
最終的なlossは次式のようになります。
L=\alpha_{1} \cdot \sum_{i=1}^{n} \mathcal{L}_{1}\left(I_{i}, \hat{l}_{i}\right)+\alpha_{2} \cdot \sum_{j=n}^{1} \mathcal{L}_{2}\left(I_{j}, \hat{l}_{j}\right)
$L_{1}, L_{2}$はそれぞれcycle consistencyのforward backwardそれぞれにおけるカラー予測誤差です。注意点として論文では2番目の論文のようにcycle consistency loss自体は使っていません。あくまでcolorizationがmainでcycle consistencyはLong-termに対応するためのregularizerとして使っています。
Joint-task Self-supervised Learning for Temporal Correspondence 5
次の論文はNeurIPS2019からです。略称はUVCだそうです。(名前の由来がわからなかったので分かる方いたら教えてください)
さてこの論文の特徴ですが、pixelレベルのマッチングを行う前にbounding box予測を挟むことにあります。
下図を見てください。

図10 pixelレベルによるマッチング(図下)とboxレベルでのマッチング(図上)の比較
図(b)はこれまでの論文のようにpixelレベルのみでマッチングさせたものです。例えば黄色の線を例にとると,赤い服を来た人物が2人いるため間違った対応になってしまっています。
このように、pixelレベルのマッチングはオブジェクトの細かい変化をみる分には有効ですが、objectの意味的な要素(回転やviewpointに不変)でmatchingさせるのは向いていないことがわかります。
対してbounding boxによる検出はその真逆で互いに相補的な関係にあると考えられます。
したがって最初に図(a)のようにbox領域を検出してしまってから、その領域内でpixelレベルのマッチング予測をさせればいいのでは?というのが論文の趣旨になります。
提案手法
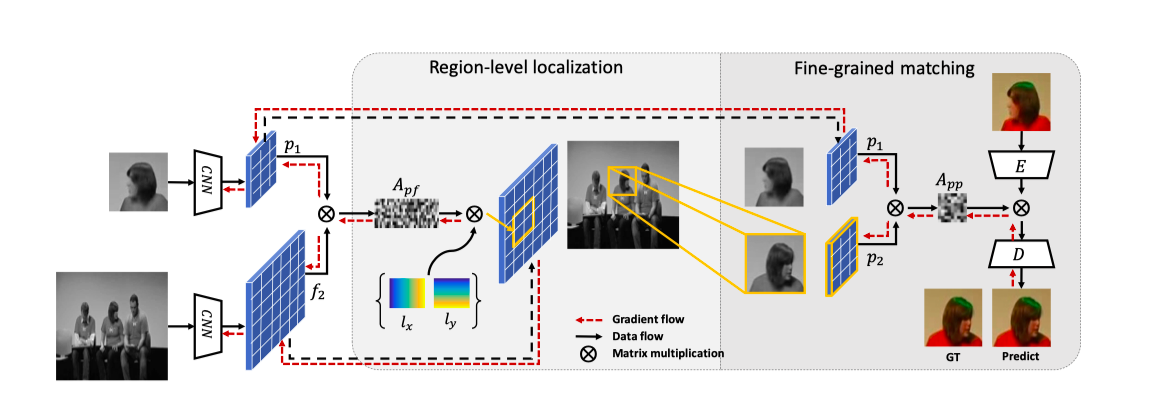
図11 ネットワーク図
図の前半部でbox領域を検出(Region-level localization),後半で見つけた領域内でのpixelマッチングを行います(Fine-grained matching)
Region level localization
目標はReference frameで切り取られたパッチがTarget frameのどこに相当するかのbboxを見つけることです。例のごとくどちらもグレースケールに落とした後、CNNに通し、おなじみの類似度行列を計算します。
$$A_{i j}=\frac{\exp \left(f_{1 i}^{\top} f_{2 j}\right)}{\sum_{k} \exp \left(f_{1 k}^{\top} f_{2 j}\right)}, \quad \forall i \in\left[1, N_{1}\right], j \in\left[1, N_{2}\right]$$
ここらへんまでは2番目に紹介した論文(CycleTime)の手順と似てますね。CycleTimeではこの行列から位置座標を対応づけるためにさらに追加のネットワークに通していました。しかしこの論文では$A_{i j}$はほぼスパース(行列の要素は対応する1つのpixleのみが1で他の要素は0)になるはずで次のような式で位置座標を変換しています。
$$l_{j}^{12}=\sum_{k=1}^{N_{1}} l_{k}^{11} A_{k j}, \quad \forall j \in\left[1, N_{2}\right]$$
ここで$l_{j}^{mn}$は画像$n$の$j$番目のピクセルに移動する画像$m$の座標です。補足記事2項を参照
この式を用いると$p_{1}$のどのピクセル座標が$f_{2}$の各ピクセルに移動するかがわかります。
また、反対に$l_{j}^{21}$を求めると,$p_{1}$が$f_{2}$のどこの座標にあるかがわかります。
ここで$l_{j}^{21}$の平均をとれば,bounding box中心$C^{21}$が計算できます。
$C^{21}=\frac{1}{N_{1}} \sum_{i=1}^{N_{1}} l_{i}^{21}$
bounding box中心が見積もれたのでboxの大きさも定義してしまいましょう。$w$,$h$は単純に$l_{j}^{21}$の各座標と中心$C$とのずれの平均値で定義します。
$$\hat{w}=\frac{2}{N_{1}} \sum_{i=1}^{N_{1}}\left|x_{i}-C^{21}(x)\right|_{1}$$
以上により、無事$f_{2}$内のbboxを見積もることができました。
このbboxで$f_{2}$を切り取った特徴map $p_{2}$を次のFine-grained matchingに利用します。
Fine-grained matching
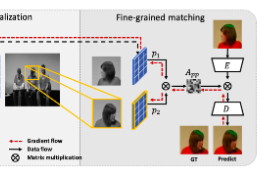
図12 ネットワーク(Fine-grained matching部)
あとは最初のの論文と同様に、$p_{1}$,$p_{2}$で類似度行列$A_{pp}$を計算してカラー復元させればいいことになります。ただこの論文では、直接pointerでカラーをコピーしてくるのではなく、Encoder-Decoder方式でカラー予測させています(図参照)。この論文では、これの利点として直接$A_{pp}$を使うよりもCNNによるembeddingを挟んでいますので,よりglobal contextualな情報を用いれることと主張しています。
Loss
使用するLossは大きくわけて3種類あります。1つ目は__カラー復元が正しくできているかのLoss__(論文中に数式の記載はないですが実装だとL1 lossで比較してました)
2つめは__concentration regularization__と言われるbbox予測に関する制約項です。これはbbox内のピクセルは移動しても近い位置にくるだろうという仮定の元、pixelができるだけ集まるようにします。(下図左側参照)
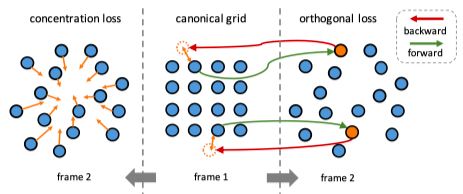
図13 lossに使用する2つの正則化のイメージ
L_{c}=\left\{\begin{array}{ll}0, & \left\|l_{j}^{21}(x)-C^{21}(x)\right\|_{1} \leq w \text { and }\left\|l_{j}^{21}(y)-C^{21}(y)\right\|_{1} \leq h \\ \frac{1}{N_{1}} \sum_{j=1}^{N_{1}}\left\|l_{j}^{21}-C^{21}\right\|_{2}, & \text { otherwise }\end{array}\right.
bboxからはみ出た対応点に罰則をかけることで一箇所だけまったく別の場所に対応づけられるといったことを防ぐことができます。
3つめは__Orthogonal regularization__という制約項です。これは2フレーム間のCycle consistecyと本質的には同じものです。
Cycle consistencyはフレーム1からフレーム2に変換した後、フレーム2からフレーム1に変換したら元に戻るという考えでした。ここで、フレーム間座標$l$,特徴map $f$の対応関係はbboxの章で説明したように以下の関係がありました。
l^{\hat{1} 2}=l^{11} A_{1 \rightarrow 2}, \quad l^{\hat{1} 1}=l^{\hat{1} 2} A_{2 \rightarrow 1}
\hat{f}_{2}=f_{1} A_{1 \rightarrow 2}, \quad \hat{f}_{1}=\hat{f}_{2} A_{2 \rightarrow 1}
ここでCycle consistencyが成り立つためには$A_{1 \rightarrow 2}^{-1}=A_{2 \rightarrow 1}$が成立していれば良いことがわかります。
さてここでピクセル対応が1対1で行われているとするなら、$f_{1} f_{1}^{\top}=f_{2} f_{2}^{\top}$で示されるように、色の絶対量(color energy)は変わっていないと仮定できます。補足記事3項参照
以上を用いると$A_{2 \rightarrow 1}=A_{1 \rightarrow 2}^{-1}=A_{1 \rightarrow 2}^{\top}$のように$A$が互いに__直行__していればCycle consistencyは成立していることが導けます。
導出
\hat{f}_{2}=f_{1} A_{1 \rightarrow 2}
で両辺転置して
$$f_{2}^{\top}=(f_{1} A_{1 \rightarrow 2})^{\top}=A_{1 \rightarrow 2}^{\top}f_{1}^{\top}$$
よって
$$f_{2}f_{2}^{\top}=f_{1} A_{1 \rightarrow 2}A_{1 \rightarrow 2}^{\top}f_{1}^{\top}$$
これが$f_{1} f_{1}^{\top}=f_{2} f_{2}^{\top}$を満たすので
$A_{1 \rightarrow 2}^{-1}=A_{1 \rightarrow 2}^{\top}$が成り立つ
よって,$f_{1}$と$A_{1 \rightarrow 2}^{\top}A_{1 \rightarrow 2}f_{1}$のMSE lossをとればCycle consistency lossを簡単に計算できます。これがOrthogonal regularizationになります。無論座標$l$に関しても同様に計算します。


認識例 (著者githubから)
まとめ
以上dense tracking系self supervisedの論文を4本紹介しました。
この4本は類似研究で共通する部分も多いですが、その中で少しづつdense tracking手法が改善されていく流れを感じて頂けたのではないでしょうか。
個人的な反省点としては数式多めの解説で自分史上一番難しい記事になってしまったのではないかと危惧しております。(指摘などあればコメントください)
ただグレースケールを着色したり,順再生と逆再生を繰り返すなど面白いideaでラベルなし学習を可能にしているところは本当に面白く魅力的なので,読んだ方にも伝わって頂けたら幸いです。
また近日公開予定のpart2も見てください
-
Wang, X., Jabri, A., & Efros, A. A. (2019). Learning Correspondence from the Cycle-consistency of Time. Retrieved from https://arxiv.org/abs/1903.07593 ↩ ↩2
-
Lai, Z., Lu, E., & Xie, W. (2020.). MAST: A Memory-Augmented Self-Supervised Tracker. Retrieved from https://arxiv.org/abs/2002.07793 ↩
-
Vondrick, C., Shrivastava, A., Fathi, A., Guadarrama, S., & Murphy, K. (2018). Tracking emerges by colorizing videos. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 11217 LNCS, 402–419. https://doi.org/10.1007/978-3-030-01261-8_24 ↩
-
Lai, Z. (2019). Self-supervised Learning for Video Correspondence Flow. Retrieved from https://arxiv.org/abs/1905.00875 ↩
-
Li, X., Liu, S., De Mello, S., Wang, X., Kautz, J., & Yang, M.-H. (2019). Joint-task Self-supervised Learning for Temporal Correspondence. Retrieved from https://arxiv.org/abs/1909.11895 ↩