背景
MySQL の sys.innodb_lock_waits は、ロック待機の情報を取得するためのビューですが、ロック競合が多発している状況で SELECT * FROM sys.innodb_lock_waits; を実行すると、サーバーのパフォーマンスに影響を与えるバグが報告されていました。
このバグレポートに、MySQL 8.0.40 で修正された旨がコメントされていたので、どの程度改善されたのか試してみました。
改善の概要
レポートのコメントを以下に抜粋します。sys.innodb_lock_waits を SELECT するときのデータアクセス量が、waiterプロセスごとに「フルスキャン x 2」から「2」へと大幅に削減されているようです。
As of this release, SELECT * FROM sys.innodb_lock_waits; fetches only 2 locks for each wait, instead of scanning all locks twice for each wait.
リリースノートにも同様の記載があります。以下の記述もあり、performance_schema.data_locks / data_lock_waits をクエリした際、global mutex を獲得する必要がないようになっているようです。
Redesigned the performance schema data_locks and data_lock_waits tables so that querying them does not require an exclusive global mutex on the transaction or lock system.
実験の準備
バグレポートでバグの報告者が添付してくれている Python スクリプトを使います。
monitor.py : sys.innodb_lock_waits を一定間隔で SELECT し続ける
lock_test.py : 複数スレッドによる並行処理を使って大量のロック競合を引き起こす
環境
M2 macOS で動作確認を行っています。メモリは 32 GiB です。
my.cnf を編集して mutex 系の情報取得を有効化
[mysqld]
performance-schema-instrument='wait/synch/mutex/innodb/%=ON'
docker で 8.0.40 系の MySQL を起動
docker run --name mysql8.0.40 \
-e MYSQL_ROOT_PASSWORD=xxx \
-v ./my.cnf:/etc/mysql/conf.d/my.cnf \
-p 3306:3306 \
-d mysql:8.0.40
テスト用のユーザー・DB・テーブル作成
CREATE USER `monitor`@`%` identified by 'xxx';
GRANT SELECT ON sys.* TO `monitor`@`%`;
GRANT EXECUTE ON sys.* TO `monitor`@`%`;
GRANT SELECT ON performance_schema.* TO `monitor`@`%`;
GRANT PROCESS ON *.* TO `monitor`@`%`;
CREATE USER test@'%' identified by 'xxx';
CREATE DATABASE test;
GRANT ALL ON test.* TO test@'%';
USE test;
CREATE table test(id int, value int);
MySQL に接続して wait 系の取得を有効化
UPDATE performance_schema.setup_consumers
SET enabled = 'YES'
WHERE name like 'events_waits%';
mutex 情報の取得
Mutex 系の情報はこちらのドキュメントを参考に取得しました。
以下のクエリをスクリプト実行前後で実行し、mutex 情報のスナップショットを取得します。
-- スクリプト実行前
CREATE TEMPORARY TABLE temp_mutex_waits1 AS
SELECT EVENT_NAME, COUNT_STAR, SUM_TIMER_WAIT/1000000000 AS SUM_TIMER_WAIT_MS
FROM performance_schema.events_waits_summary_global_by_event_name
WHERE SUM_TIMER_WAIT > 0 AND EVENT_NAME LIKE 'wait/synch/mutex/innodb/%'
ORDER BY EVENT_NAME ASC;
-- スクリプト実行後
CREATE TEMPORARY TABLE temp_mutex_waits2 AS
SELECT EVENT_NAME, COUNT_STAR, SUM_TIMER_WAIT/1000000000 AS SUM_TIMER_WAIT_MS
FROM performance_schema.events_waits_summary_global_by_event_name
WHERE SUM_TIMER_WAIT > 0 AND EVENT_NAME LIKE 'wait/synch/mutex/innodb/%'
ORDER BY EVENT_NAME ASC;
最後に差分を取ることで、実験時に発生した mutex を、待ち時間の多い順に表示できます。
select
t2.EVENT_NAME,
(t2.COUNT_STAR - t1.COUNT_STAR) as COUNT_STAR_DIFF,
(t2.SUM_TIMER_WAIT_MS - t1.SUM_TIMER_WAIT_MS) as SUM_TIMER_WAIT_MS_DIFF
from
temp_mutex_waits1 as t1
join temp_mutex_waits2 as t2 on t1.EVENT_NAME = t2.EVENT_NAME
order by
(t2.SUM_TIMER_WAIT_MS - t1.SUM_TIMER_WAIT_MS) desc;
実験
1. 前のバージョンとの比較 - 実行時間
8.0.32(バグ修正前)と8.0.40(バグ修正後)で、lock_test.py の時間を比較してみました。
「monitor 稼働」とは、前述の sys.innodb_lock_waits を定期的に SELECT するスクリプトを実行している状況を指します。
| 8.0.32 | 8.0.40 | |
|---|---|---|
| monitor 稼働なし | 28.763 sec | 26.322 sec |
| monitor 稼働あり | 468.702 sec | 26.922 sec |
8.0.32 では、monitor 稼働ありだと大幅にパフォーマンスが劣化しているのに対し、8.0.40 ではほぼ劣化がないことを確認できました。
2. 前のバージョンとの比較 - mutex
次に、mutex の獲得状況にも違いがないか確認しました。それぞれ lock_test.py の実行中の累積値を、多い順に TOP 5 件表示しています。
8.0.32 monitor なし
| EVENT_NAME | COUNT_STAR_DIFF | SUM_TIMER_WAIT_MS_DIFF |
|---|---|---|
| wait/synch/mutex/innodb/trx_mutex | 262800685 | 736.6352 |
| wait/synch/mutex/innodb/lock_sys_page_mutex | 164793545 | 480.2644 |
| wait/synch/mutex/innodb/trx_sys_shard_mutex | 49500372 | 129.0646 |
| wait/synch/mutex/innodb/log_writer_mutex | 5398 | 23.6114 |
| wait/synch/mutex/innodb/log_files_mutex | 5117 | 19.3071 |
8.0.32 monitor あり
| EVENT_NAME | COUNT_STAR_DIFF | SUM_TIMER_WAIT_MS_DIFF |
|---|---|---|
| wait/synch/mutex/innodb/trx_sys_mutex | 2521 | 18887.9936 |
| wait/synch/mutex/innodb/trx_mutex | 251754827 | 1402.0077 |
| wait/synch/mutex/innodb/lock_sys_page_mutex | 153745082 | 825.8319 |
| wait/synch/mutex/innodb/lock_wait_mutex | 813 | 490.4935 |
| wait/synch/mutex/innodb/trx_sys_shard_mutex | 49500354 | 208.2526 |
8.0.40 monitor なし
| EVENT_NAME | COUNT_STAR_DIFF | SUM_TIMER_WAIT_MS_DIFF |
|---|---|---|
| wait/synch/mutex/innodb/trx_mutex | 261791259 | 1645.3542 |
| wait/synch/mutex/innodb/lock_sys_page_mutex | 163789154 | 790.2661 |
| wait/synch/mutex/innodb/trx_sys_shard_mutex | 49500354 | 204.4517 |
| wait/synch/mutex/innodb/log_writer_mutex | 5518 | 76.2960 |
| wait/synch/mutex/innodb/log_files_mutex | 5556 | 35.1488 |
8.0.40 monitor あり
| EVENT_NAME | COUNT_STAR_DIFF | SUM_TIMER_WAIT_MS_DIFF |
|---|---|---|
| wait/synch/mutex/innodb/trx_mutex | 261796386 | 1480.9474 |
| wait/synch/mutex/innodb/lock_sys_page_mutex | 163953636 | 824.7014 |
| wait/synch/mutex/innodb/trx_sys_shard_mutex | 49500354 | 207.0945 |
| wait/synch/mutex/innodb/log_files_mutex | 4928 | 35.7500 |
| wait/synch/mutex/innodb/log_writer_mutex | 5512 | 24.8929 |
4 つの結果から、8.0.32 の monitor ありの時だけ、wait/synch/mutex/innodb/trx_sys_mutexが大きく増加しています。
8.0.40 では monitor あり/なしで mutex の状況にほぼ変化がなく、この辺りの挙動の違いもバグ修正によるパフォーマンス改善の結果なのかなと考えています。
テーブル・View 定義・実行プランの変更点を確認
8.0.32 と 8.0.40 で、sys.innodb_lock_waits の View 定義と、元テーブルの一部である performance_schema.data_locks と performance_schema.data_lock_waits の定義に違いがあるか確認しました。
View 定義
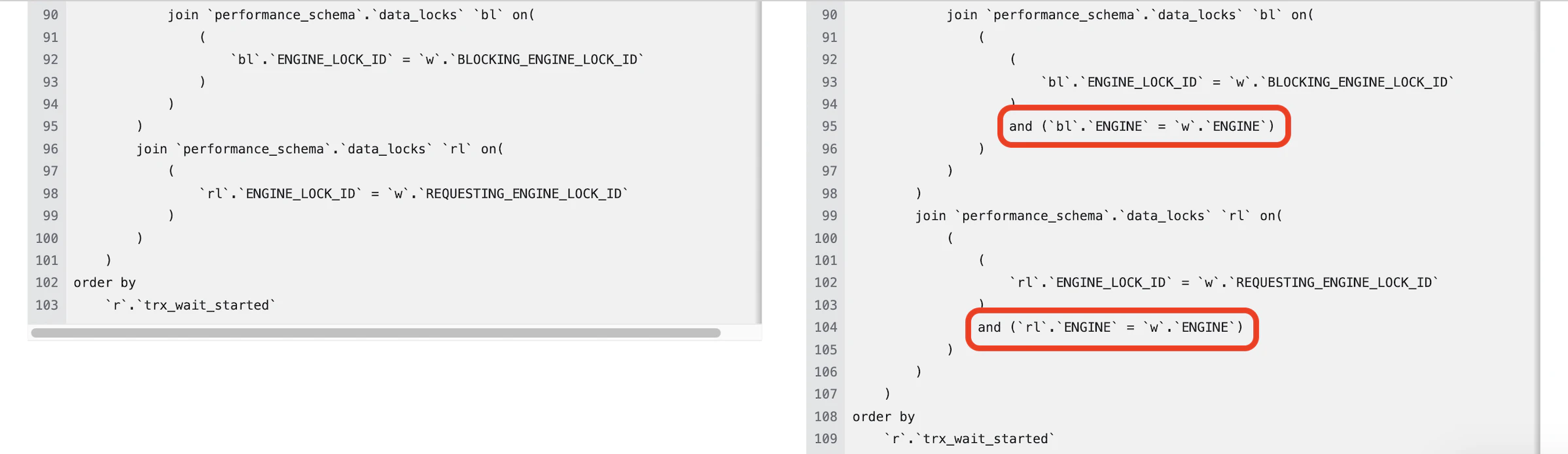
差分としては、blocker と waiter それぞれの情報を取得するために data_locks を join する際に、ENGINE カラムを条件に追加してあるだけでした。
左:8.0.32 / 右:8.0.40
テーブル定義
data_lock_waits テーブルに、PK が追加されていることを確認しました。
ちなみに、data_locks には 8.0.32 の時点で PK がすでに存在しており、8.0.40 から PK が追加されたわけではないようです。
PRIMARY KEY (`REQUESTING_ENGINE_LOCK_ID`,`BLOCKING_ENGINE_LOCK_ID`,`ENGINE`),
実行プラン
8.0.32

8.0.40

若干見切れていますが、bl/rl における type が ref から eq_ref に変わっています。また、それに伴って rows も 999 から 1 に減っています。この挙動の違いが、リリースノートとバグレポートへのコメントに記載のあった以下の言及を表現していると理解しました。
As of this release, SELECT * FROM sys.innodb_lock_waits; fetches only 2 locks for each wait, instead of scanning all locks twice for each wait.
所感
今までは、レポートに記載の事象を考慮すると、1 秒間隔など高頻度で sys.innodb_lock_waits を取得し続けることはためらわれましたが、MySQL 8.0.40 以降であればあまり気にせず SELECT し続けても問題ないかもしれません。
ただし、Aurora MySQL ですと現時点での最新は 8.0.39 互換までとなっており、今後のリリースを待つ形になりそうです。
また、監視系 SaaS によるブロッキング View の提供の日も近いかもしれません。例えば、現在DataDog ではブロッキングの View が SQL Server と PostgreSQL では提供されていますが、MySQL では提供されておりません。これは今回のバグのように、モニタリングが意図せずサーバーへ高負荷をかけてしまう懸念などが背景にあると考えられます。