記事を読む前に
- StatefulSetにデータ破損につながる仕様上の問題がないか疑って検証しました
- タイトルにある通り、それ自体は濡れ衣でした
- StatefulSetの挙動についてまとめに記載してあります。そこだけ読んでもOKです
- ここからまとめの間は延々と疑った内容と検証の内容です
前置き
- StatefulSetなるものが目につきました。こいつを使うと冗長構成のDBがKubernetes上に組めるそうです。
- なので調査してみました
まずは調査
- 訳しながら理解していくKubernetes_ StatefulSets編
- Deploying PostgreSQL Clusters using StatefulSets
-
Kubernetes PVC と Deployment, StatefulSet の関係を検証してみた
- オートヒーリングするそうです
- それってまずくないか?

- それってまずくないか?
- オートヒーリングするそうです
オートヒーリングの何が怪しいか
- 障害時、Podが起動状態のまま、同一Podをもう一台起動することがあります。(以降これを多重起動問題と呼びます)
懸念している多重起動問題を図で解説するとこんな感じです
-
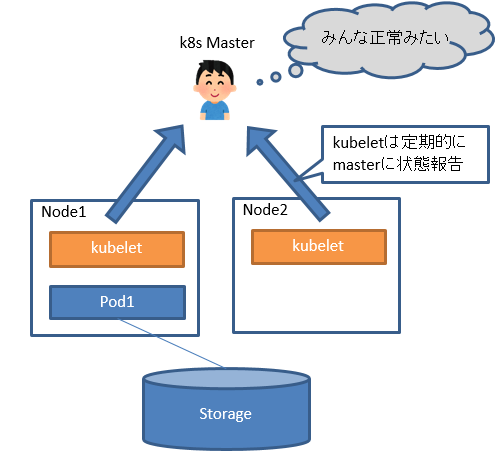
通常時は master は kubeletから状態報告を受け取っています
-
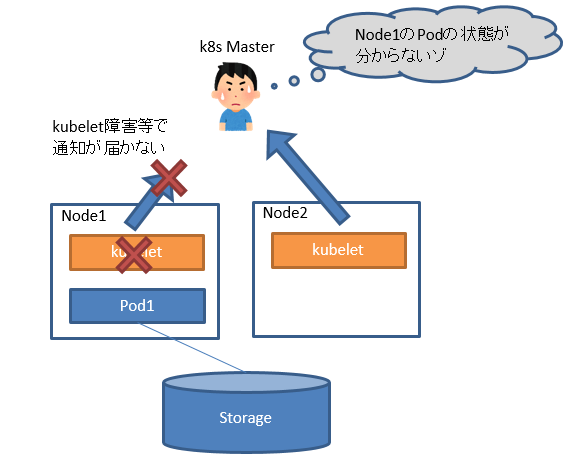
kubelt障害等で報告が途絶えると、masterはPodの状態を判定できません。実はPodが生きていたとしても知るすべはありません
-
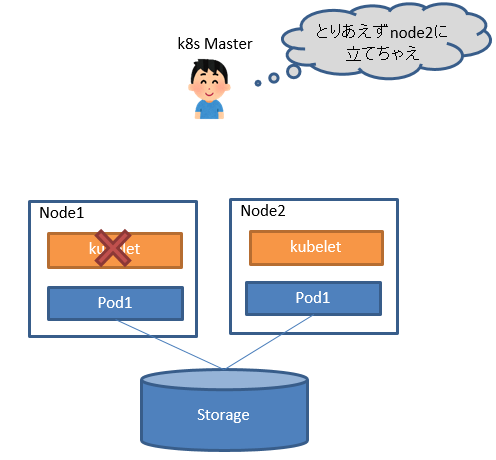
STATUS Unknown判定されると別NodeにPodを立て直します
-
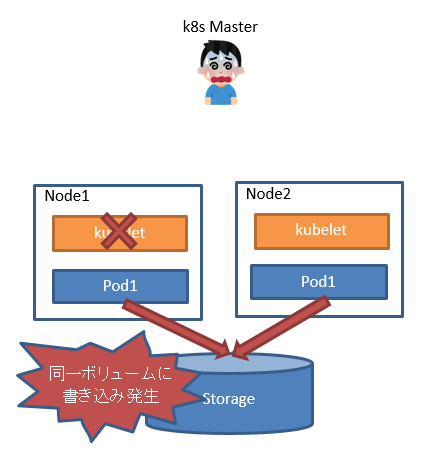
同一ボリュームをマウントするPodが2台できあがります。アプリによってはこれでデータ破損しかねません
何を確かめればオートヒーリングを信用できるか
-
3.の多重起動問題は実はStatefulSetでは起きない
検証してみる
環境構築
root@master:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 26h v1.12.3
node1 Ready 25h v1.12.3
node2 Ready 25h v1.12.3
node3 Ready 25h v1.12.3
node4 Ready 25h v1.12.3
node5 Ready 24h v1.12.3
```
-
/etc/exports
/opt/nfs1 10.0.0.0/24(rw,sync,no_subtree_check,no_root_squash)
/opt/nfs2 10.0.0.0/24(rw,sync,no_subtree_check,no_root_squash)
/opt/nfs3 10.0.0.0/24(rw,sync,no_subtree_check,no_root_squash)
```
StatefulSet作成
- 公式ガイドに従ってmysqlでやってみます
-
PV作成
apiVersion: v1 kind: PersistentVolume metadata: name: pv1 spec: capacity: storage: 11Gi volumeMode: Filesystem accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle storageClassName: slow mountOptions: - hard nfs: server: storage path: /opt/nfs1- pv2(path: /opt/nfs2), pv3(path: /opt/nfs3)も同様に作成します
-
kubectl create -f https://k8s.io/examples/application/mysql/mysql-configmap.yaml -
kubectl create -f https://k8s.io/examples/application/mysql/mysql-services.yaml -
kubectl create -f https://k8s.io/examples/application/mysql/mysql-statefulset.yaml -
kubectl get pods -l app=mysql --watchで作成待機-
mysql-0のStateがInit:0/2→Init:1/2→Runningとなった後にmysql-1が作成され始めます-
mysql-2も同様にmysql-1がRunningになってから作られます
-
- すべて完了するのに10分ぐらいかかります
-
-
動作確認
-
mysqlコンテナを立てて
mysql-0.mysqlに対してSQL実行します -
データを流す
kubectl run mysql-client --image=mysql:5.7 -i --rm --restart=Never --\ mysql -h mysql-0.mysql <<EOF CREATE DATABASE test; CREATE TABLE test.messages (message VARCHAR(250)); INSERT INTO test.messages VALUES ('hello'); EOF -
流したデータを読み取る
root@master:~# kubectl run mysql-client --image=mysql:5.7 -i -t --rm --restart=Never --\ mysql -h mysql-read -e "SELECT * FROM test.messages" If you don't see a command prompt, try pressing enter. +---------+ | message | +---------+ | hello | +---------+ pod "mysql-client" deleted- sqlで流した 'hello'が確かに読み取れてます
-
多重起動させてみる
-
Podの配置を確認
root@master:~# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
mysql-0 2/2 Running 0 121m 10.44.0.1 node4
mysql-1 2/2 Running 0 119m 10.42.0.1 node3
mysql-2 2/2 Running 0 117m 10.35.0.1 node5
```
-
mysql-0のいるnode4でkubeletを落とすroot@node4:~# systemctl stop kubelet root@node4:~# systemctl status kubelet ● kubelet.service - kubelet: The Kubernetes Node Agent Loaded: loaded (/lib/systemd/system/kubelet.service; enabled; vendor preset: Drop-In: /etc/systemd/system/kubelet.service.d └─10-kubeadm.conf Active: inactive (dead) since Mon 2018-12-03 05:04:57 UTC; 5s ago ・・・ -
待つ
- デフォルトだとだいたい5分程で
STATUS Unknownになります
- デフォルトだとだいたい5分程で
-
待った結果
root@master:~# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
mysql-0 2/2 Unknown 0 142m 10.44.0.1 node4
mysql-1 2/2 Running 0 140m 10.42.0.1 node3
mysql-2 2/2 Running 0 138m 10.35.0.1 node5
```
* STATUS UnknownのままPodが立つ気配はありません
* どうやら濡れ衣だったようです![]()
仕様を確認してみる
-
Issueがありました
- StatefulSetではPodが
STATUS UnknownになってもPodを立て直さないよ -
kubectl delete pods <pod> --grace-period=0 --forceでUnknownのPodを強制的に消すとPodを立て直すよ - これはStatefulSetの仕様なので、自動で立て直ししてほしい場合はDeploymentとか別のやつを使うといいよ
- StatefulSetではPodが
まとめ
- 濡れ衣でした!StatefulSet、疑ってすみません

- StatefulSetはNode障害等が起きても、管理者がコマンドを打つまではPodの立て直しはしません
- 言い換えると、Node障害からの復旧は自動化されていません
- その代わり多重起動でデータが破損したりすることは防がれています
- 復旧が自動化されていない点を考えると、StatefulSetは高可用性のためというよりは、障害復旧手順の簡易化と負荷分散がメリットのように思えます
- mysqlの例だと、読み取りをmysql-1,mysql-2に分散できることです
- スレーブをマスターに昇格する仕組みを作れば高可用性(ダウンタイム短縮)もいけるかもしれませんが、k8sサービスの切り替えとかいろいろ大変そうです
- Storageを使う場合で多重起動が起きると困る場合は、StatefulSetを使いましょう
- 自動でPod立て直ししてほしい場合はDeployment等StatefulSet以外を検討しましょう
- さすがGoogle。ちゃんと考えられてます
- (見切り発車せずに先に仕様確認しとけばよかった)