本記事は RDBMS-GIS Advent Calendar 2018 の15日目です。
はじめに
最初に書いておくと、Postgresで複合型の使い方知ってるなら「で?」って話です。
自分はそれでめちゃくちゃ悩んだので書き残しておく。
そして悩みを聞いてアドバイスをくれた皆様ありがとうございます。
今回の対象バージョンはpgRouting2.6.1になっております。
環境の構築方法はUbuntu18.04 LTSにpgRouting環境を構築してみるで紹介しています。
また、古いバージョンのpgRoutingでは正常な結果が返らないのでやってはいけない。
本題
あるときpgRoutingでスタート地点とゴール地点が多対多の検索をしたいと思った。
どんなときに利用するのかと言えば、多数の住民ポイントがあったとして複数の避難所ポイントまでの経路を検索して、どの避難所にも1km以内とか5分以内で到達できない住民を抽出したりするときに使ったらいいんじゃなかろうか。(適当)
普通にやろうとするとスタート地点毎に、到達圏域検索をおこなうか最短経路検索を行って到達したかどうかを判定することになると思う。
それはそれでいいんだけどSQLだけで処理できそうな気がしてならないのであがいている。
ちなみに、上の利用例では到達圏域検索の方が適切な処理だろうと考えられるがここでは最短経路検索を使用する。
テストデータ作成
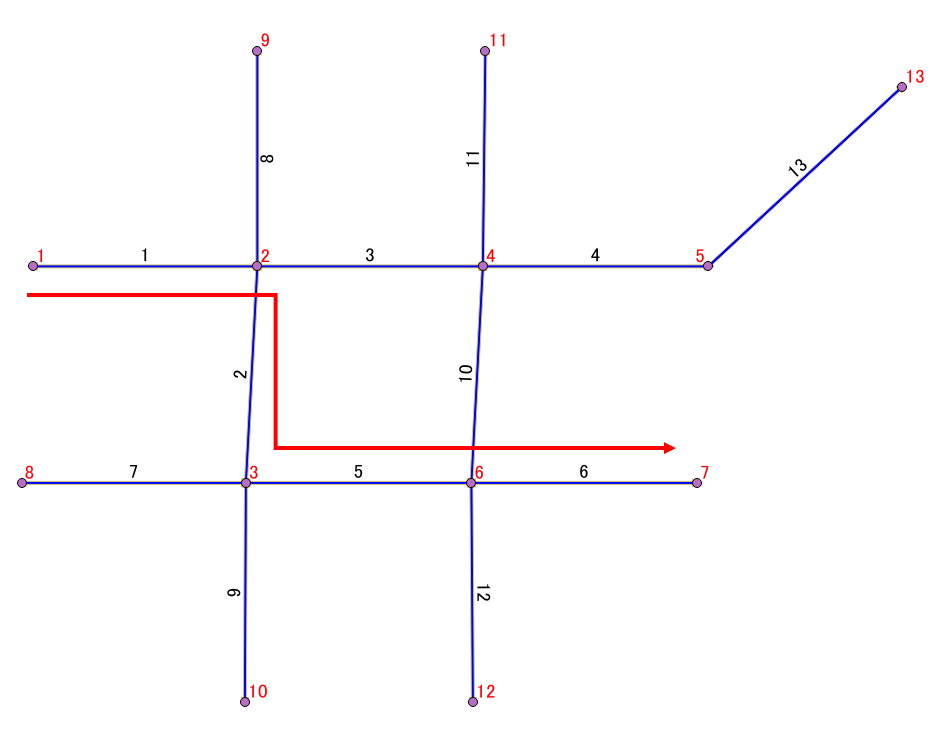
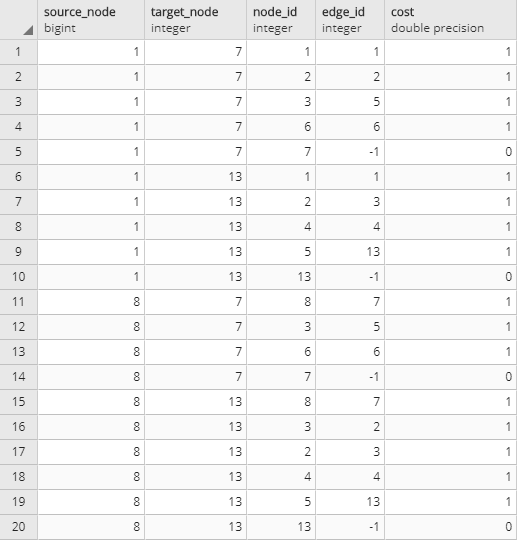
単純化するために以下のようなエッジを生成した。
エッジの両端が判りやすいようにQGISで矢線のスタイルとエッジIDの注記を表示している。

テーブルレイアウトは以下のようになっている。
CREATE TABLE public.test_pl
(
id integer NOT NULL DEFAULT nextval('test_pl_id_seq'::regclass),
source integer,
target integer,
cost double precision,
geom geometry(LineString,4237),
CONSTRAINT test_pl_pkey PRIMARY KEY (id)
)
WITH (
OIDS = FALSE
)
TABLESPACE pg_default;
CREATE INDEX test_pl_the_geom_gidx
ON public.test_pl USING gist
(geom)
TABLESPACE pg_default;
トポロジデータ作成
ここでいうトポロジデータはPostGISのトポロジデータとは異なる。
pgRoutingは地物データから論理的な木構造データを作るだけで地物の編集をしてもトポロジカルに移動したりしない。
pgAdminからSQLを実行してみよう。
SELECT pgr_createTopology('test_pl', 0.0001, 'geom', 'id');
実行するとtest_plのsourceとtargetにノード番号が付与されるとともに、test_pl_vertices_pgrという名前のノードテーブルが生成されたと思う。
test_pl_vertices_pgrもQGISに読み込んで確認しよう。赤字がノードテーブルのノード番号になる。

最後にエッジのコストを一律「1」としておこう。
1分と解釈してもいいし1kmと解釈しても良いだろう。
UPDATE test_pl SET cost = 1;
まずは普通に検索
さて、データが出来上がったのでまずは普通に検索を行ってみよう。
1番のノードから7番への最短ルート検索をしてみよう。
SELECT *
FROM pgr_kdijkstraPath(
'SELECT id, source, target, cost::float8 FROM test_pl',
1, -- source_node_id
array[7], -- target_node_ids
false, -- directed boolean
false -- has_cost boolean
);
結果が返りました。
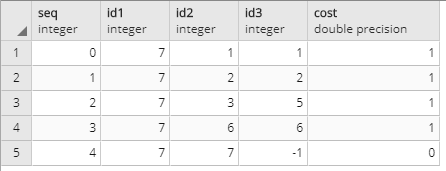
id1は対象target、id2は経由するノード番号、id3は経由するエッジ番号、costは対象エッジのコストですね。
以下のような経路を辿るのが最短だと判断されました。
今度は1番のノードから7番と13番への最短ルート検索をしてみよう。
SELECT *
FROM pgr_kdijkstraPath(
'SELECT id, source, target, cost::float8 FROM test_pl',
1, -- source_node_id
array[7,13], -- target_node_ids
false, -- directed boolean
false -- has_cost boolean
);
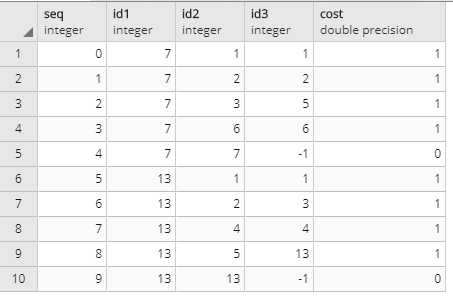
ちゃんと結果が返ってますね。
図は省略。
普通のSQL使いには違和感ありまくり
はい、普通のSQL使いの皆さんはFROM句に関数て!となると思います。
そして結果がテーブル!変態!
今回やりたいことはsource_node_idに他のテーブルの結果の値と結合すれば多対多の検索が出来るのは判るんですが、どうやって実現すればよいのか。
考えれば考えるほど分けが判らなくなるわけですが、そもそもこの関数の戻り値が何かを把握することが必要でした。
普通の関数みたく使ってみる
普通にSELECT句に関数を置いて実行してみよう。
SELECT pgr_kdijkstraPath(
'SELECT id, source, target, cost::float8 FROM test_pl',
1, -- source_node_id
array[7,13], -- target_node_ids
false, -- directed boolean
false -- has_cost boolean
);
はい、なんとなく想像してたような値が返りました。
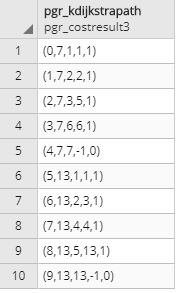
ここで注目しないといけないのが戻り値の型です!
pgr_costresult3型となっていますね。なんぞこれ。
というわけでこれが複合型ですね。
https://www.postgresql.jp/document/10/html/rowtypes.html
pgAdmin4で[Schemas]-[public]-[Types]を覗くと入っていましたpgr_costresult3
定義は以下のようになってます。
CREATE TYPE public.pgr_costresult3 AS
(
seq integer,
id1 integer,
id2 integer,
id3 integer,
cost double precision
);
ALTER TYPE public.pgr_costresult3
OWNER TO postgres;
複合型は正しくキャストすればレコードのような扱いができます。
先ほどのSQL実行結果からid2のフィールドだけ抜き出してみましょう。
SELECT (pgr_kdijkstraPath(
'SELECT id, source, target, cost::float8 FROM test_pl',
1, -- source_node_id
array[7,13], -- target_node_ids
false, -- directed boolean
false -- has_cost boolean
)::pgr_costresult3).id2
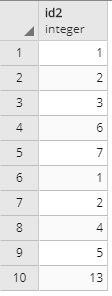
良い感じ。
SELECT句で呼べたらもうこっちのもんです。
多対多の検索を実行する
ノードテーブルtest_pl_vertices_pgrとくっつけて1番と8番のノードから7番と13番への最短ルート検索をしてみよう。
pgr_kdijkstraPathの第2引数としてtest_pl_vertices_pgrのidを使用しています。
idはbigintなのでintにキャストしないといけません。
SELECT test_pl_vertices_pgr.id, pgr_kdijkstraPath(
'SELECT id, source, target, cost::float8 FROM test_pl',
id::int,
array[7,13], -- target_node_id
false,
false
) prg_costresult3
FROM test_pl_vertices_pgr
WHERE id in (1,8) -- source_node_id;
多対多の検索結果が返っています。
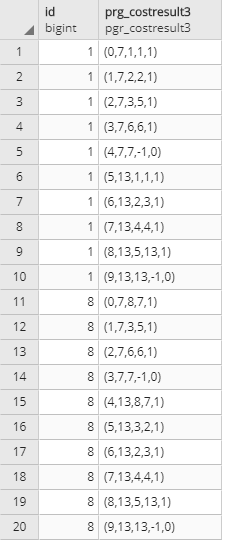
ここまで来ればもう一息
サブクエリ化してから普通の表形式で返します。
SELECT
id source_node,
(pgr_costresult3::pgr_costresult3).id1 target_node,
(pgr_costresult3::pgr_costresult3).id2 node_id,
(pgr_costresult3::pgr_costresult3).id3 edge_id,
(pgr_costresult3::pgr_costresult3).cost
FROM (
SELECT test_pl_vertices_pgr.id, pgr_kdijkstraPath(
'SELECT id, source, target, cost::float8 FROM test_pl',
id::int,
array[7,13], -- target_node_id
false,
false
) pgr_costresult3
FROM test_pl_vertices_pgr
WHERE id in (1,8) -- source_node_id;
) prg_result;
どーん
これであとは如何様にも料理してくださいというデータになりました。
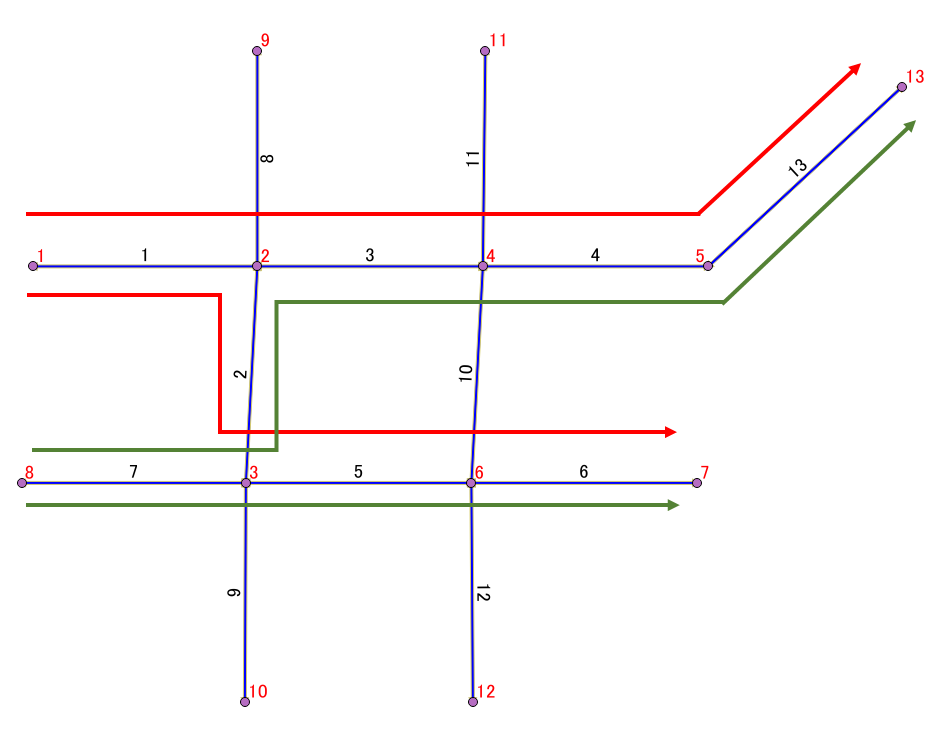
念のためルートを示した図も張り付けておきます。
更にもう一押し
target_node_idもテーブルから参照しましょう。
integer[]型を渡せばいいのでarrayとサブクエリ使うだけですね。
SELECT
id source_node,
(pgr_costresult3::pgr_costresult3).id1 target_node,
(pgr_costresult3::pgr_costresult3).id2 node_id,
(pgr_costresult3::pgr_costresult3).id3 edge_id,
(pgr_costresult3::pgr_costresult3).cost
FROM (
SELECT test_pl_vertices_pgr.id, pgr_kdijkstraPath(
'SELECT id, source, target, cost::float8 FROM test_pl',
id::int,
array(
SELECT id::int
FROM test_pl_vertices_pgr
WHERE id in (7,13) -- target_node_id
),
false,
false
) pgr_costresult3
FROM test_pl_vertices_pgr
WHERE id in (1,8) -- source_node_id;
) prg_result;
こんな感じでいけます。
今回はtest_pl_vertices_pgrを使ってますけどtbl_source_nodeとtbl_target_nodeみたいなテーブルを用意して事前にデータをINSERTしておけばもっと素直に検索が可能になりますね。
SELECT
id source_node,
(pgr_costresult3::pgr_costresult3).id1 target_node,
(pgr_costresult3::pgr_costresult3).id2 node_id,
(pgr_costresult3::pgr_costresult3).id3 edge_id,
(pgr_costresult3::pgr_costresult3).cost
FROM (
SELECT test_pl_vertices_pgr.id, pgr_kdijkstraPath(
'SELECT id, source, target, cost::float8 FROM test_pl',
id,
array(
SELECT id FROM tbl_target_node
),
false,
false
) pgr_costresult3
FROM tbl_source_node
) prg_result;
うん、なんか使えそうな形にまとまりました。
以上です。
本記事のライセンス

この記事は クリエイティブ・コモンズ 表示 4.0 国際 ライセンスの下に提供されています。