はじめに
・登山好きプログラミング初心者が衛星データを利用して山探しする企画です。
・こう書いた方がより良いなどありましたら、勉強になりますのでぜひコメントください。
・本企画は以下の4部構成を予定しており、今回は第4弾です。
①日本の山リスト作成編
②衛星データで周囲で一番高い山を探してみる編
③衛星データで山周辺の地域の晴天率を調べてみる編
④衛星データで眺望の良い、山頂がひらけている山を探してみる編
前回記事(③衛星データで山周辺の地域の晴天率を調べてみる編)で作成した日本の山リストに対して、光学の衛星データを使って植生指数を計算し、自分たちの登りたい山を絞っていきます。
植生指数と衛星データの紹介
植生指数とはNDVI(Normalized Difference Vegetation Index)と呼ばれる緑植生の茂り具合を示す指標です。
NDVIは以下の式で計算されます。
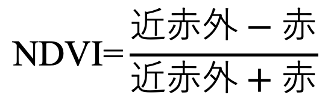
植生(緑葉)は、赤外線を強く反射し、赤色は葉緑素によって吸収されるという反射特性を持っています。
NDVIは-1〜1の値を示し、値が大きいほど、より緑が茂っているということになります。
今回はNDVIの算出にSentinel-2のデータを使います。
赤はバンド4、近赤外はバンド8となっているので、この二つのバンドを組み合わせて計算を行います。
https://developers.google.com/earth-engine/datasets/catalog/COPERNICUS_S2_SR
眺望の良い、山頂がひらけている山の探し方
本記事では、「山頂に緑が少ない」=「山頂がひらけており、眺望が良い」と仮定します。
前回までに取得した山リストにある山の山頂周辺の植生指数を取得することで、山頂の緑の茂り具合を調べます。
植生指数画像を表示してみる
試しに植生指数の画像を表示してみます。
まずはライブラリをインポートとGEEへのログインを行います。
try:
import ee
import geemap
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
except ModuleNotFoundError:
if 'google.colab' in str(get_ipython()):
print("package not found, installing w/ pip in Google Colab...")
!pip install geemap seaborn matplotlib
else:
print("package not found, installing w/ conda...")
!conda install mamba -c conda-forge -y
!mamba install geemap -c conda-forge -y
!conda install seaborn matplotlib -y
import ee
import geemap
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
try:
ee.Initialize()
except Exception as e:
ee.Authenticate()
ee.Initialize()
衛星データをロードする関数を定義します。
衛星名(snippet)、期間(from_date, to_date)、場所(geometry)、バンド(band)を指定して、衛星データをロードします。
def load_data(snippet, from_date, to_date, geometry, band):
# パラメータの条件にしたがってデータを抽出
dataset = ee.ImageCollection(snippet).filter(
ee.Filter.date(from_date, to_date)).filter(
ee.Filter.geometry(geometry)).select(band)
# リスト型へ変換
data_list = dataset.toList(dataset.size().getInfo())
# データリストを出力
return data_list
各種パラメータを指定します。
今回は植生指数の違いがはっきりと分かる方が良いため、皇居周辺の画像を取得します。
# 衛星を指定
snippet = 'COPERNICUS/S2_SR'
# 期間を指定
from_date='2021-08-01'
to_date='2021-08-07'
# 解像度
scale = 10
# バンド指定(NDVI計算用に赤と近赤を指定)
band_list = ('B4', 'B8')
# 皇居周辺を指定
lon = 139.7576692
lat = 35.6802117
aoi = ee.Geometry.Rectangle([lon - 0.01, lat - 0.01, lon + 0.01, lat + 0.01])
赤と赤外の画像を取得します。
取得した画像はgeemap.ee_to_numpy()でnumpyの配列に変換しておきます。
for in_band in band_list:
data_list = load_data(snippet=snippet, from_date=from_date, to_date=to_date, geometry=aoi, band=in_band)
image = ee.Image(data_list.get(0))
if in_band == band_list[0]:
red_arr = geemap.ee_to_numpy(image, region=aoi)
elif in_band == band_list[1]:
nir_arr = geemap.ee_to_numpy(image, region=aoi)
取得した赤と赤外の配列から、NDVIの計算をします。
# calculate NDVI = (IR-R)/(IR+R)
numerator = (nir_arr - red_arr)
denominator = (nir_arr + red_arr)
ndvi = numerator / denominator
計算したNDVI画像を表示します。
plt.imshow(ndvi.squeeze())
皇居、皇居前公園、日比谷公園は緑が茂っているため、色が濃くなっている様子が分かります。
リストにある山の山頂周辺の植生指数を求めてみる
前回までに取得した山リストの山の山頂周辺の植生指数を求めます。
まずはライブラリをインポートとGEEへのログインを行います。
try:
import ee
import geemap
import pandas as pd
import numpy as np
except ModuleNotFoundError:
if 'google.colab' in str(get_ipython()):
print("package not found, installing w/ pip in Google Colab...")
!pip install geemap seaborn matplotlib
else:
print("package not found, installing w/ conda...")
!conda install mamba -c conda-forge -y
!mamba install geemap -c conda-forge -y
!conda install seaborn matplotlib -y
import ee
import geemap
import pandas as pd
import numpy as np
try:
ee.Initialize()
except Exception as e:
ee.Authenticate()
ee.Initialize()
衛星データをロードする関数を定義します。
衛星名(snippet)、期間(from_date, to_date)、場所(geometry)、バンド(band)を指定して、衛星データをロードします。
def load_data(snippet, from_date, to_date, geometry, band):
# パラメータの条件にしたがってデータを抽出
dataset = ee.ImageCollection(snippet).filter(
ee.Filter.date(from_date, to_date)).filter(
ee.Filter.geometry(geometry)).select(band)
# リスト型へ変換
data_list = dataset.toList(dataset.size().getInfo())
# データリストを出力
return data_list
各種パラメータを指定します。
# 期間を指定
from_date='2021-08-01'
to_date='2021-08-07'
# 衛星を指定
snippet = 'COPERNICUS/S2_SR'
# 解像度
scale = 10
# バンド指定(NDVI計算用に赤と近赤を指定)
band_list = ('B4', 'B8')
前回晴天率を追加した山リストを読み込み、上と同じように植生指数を求めて、リストに追記します。
# 緯度経度を取得
df = pd.read_csv('/content/drive/My Drive/add_sunny_rate.csv')
for i in range(len(df)):
# 緯度経度のずれは0.001:111m,0.0001:11mとして概算できる
lat = df.at[i, '緯度']
lon = df.at[i, '経度']
aoi = ee.Geometry.Rectangle([lon - 0.0001, lat - 0.0001, lon + 0.0001, lat + 0.0001])
for in_band in band_list:
data_list = load_data(snippet=snippet, from_date=from_date, to_date=to_date, geometry=aoi, band=in_band)
image = ee.Image(data_list.get(0))
if in_band == band_list[0]:
red_arr = geemap.ee_to_numpy(image, region=aoi)
elif in_band == band_list[1]:
nir_arr = geemap.ee_to_numpy(image, region=aoi)
# calculate NDVI = (IR-R)/(IR+R)
numerator = (nir_arr - red_arr)
denominator = (nir_arr + red_arr)
ndvi = numerator / denominator
ndvi_sum = np.sum(ndvi)
ndvi_ave = np.mean(ndvi)
print('index:' + str(i) + "合計値:" + str(ndvi_sum), "平均値:" + str(ndvi_ave))
# csvデータ追加
df.at[i, '平均植生指数'] = ndvi_ave
# csvへの追記
df.to_csv('/content/drive/My Drive/add_sunny_rate.csv')
print('処理完了')
条件に合った山について調べてみる
これまでに取得した山リストの晴天率と植生指数をプロットしてみました。
晴天率は高く植生指数は低い方が好ましいので、右下にプロットされている山が今回私たちの求めていた山ということになります。
晴天率については評価は難しいので、今回はこの4つの山の山頂の写真を見てみることで植生指数による評価が妥当かの判断をしてみます。

・富士山
まずは、富士山です。
もちろん日本で一番高い山であるため、周囲で一番高い山の条件は満たしていますし、
写真のように岩山ですので、山頂もひらけています。
さらに今回の計算によると、天気も良いらしい…まさに日本最高の山ですね。

・東岳(悪沢岳)
東岳は、南アルプスの荒川三山と呼ばれる前岳、中岳、東岳の三山の一つです。
三山の標高はそれぞれ以下の通りです。
前岳 標高3,068 m
中岳 標高3,084 m
東岳 標高3,141 m (日本第6位の高さ)
この三山の中でも最も高く、今回の条件である周囲で最も高い山の条件を満たしていると言えます。また、画像のように山頂付近は岩山で、山頂がひらけているという条件も満たしていそうです。

・間ノ岳
間ノ岳は南アルプスにある白峰三山と呼ばれる北岳、間ノ岳、農鳥岳の三山の一つです。
三山の標高はそれぞれ以下の通りです。
北岳 標高3,193 m (日本第2位の高さ)
間ノ岳 標高3,190 m (日本第3位の高さ)
農鳥岳 標高3,026 m
おっと、ここでまさかの周囲で一番高い山という条件を満たしていない山が出てきてしまいました。3mの差なので衛星データの誤差の範囲内と予想し、北岳と間ノ岳の標高を衛星データを用いて取得してみると、北岳が3188m、間ノ岳が3203mでした。よって、コードの問題でなく、標高データの誤差であると考えられます。精度を求めるのであれば、別の手法を採用するのが良いかもしれません。
画像のように山頂付近は岩山で、山頂がひらけているという条件は満たしていそうです。

・恵那山
恵那山は岐阜県と長野県との境界上の標高2,191mの山で、美濃の最高峰です。
こちらは周囲で最も高い山の条件を満たしています。
しかし、画像のように山頂は木々に覆われています。植生指数の値で見ると間ノ岳と同等ですが、山頂の様子はかなり異なるようです。
山頂周辺の植生指数のみで、山頂の様子を評価することは難しいのかもしれません…

まとめ
ここまで4部構成で、衛星データを使って登りたい山の条件にあった山探しをしてきました。
結果を簡単に以下にまとめます。
①標高データによる周囲で最も高い山探し
標高データの誤差で多少間違った山を抽出してしまう可能性はあるが、成功。
②気象データによる晴天率算出
評価はできなかったが、過去のデータから晴天率の高い山の抽出は、成功。
③光学画像による植生指数を用いたひらけた山頂の山探し
植生指数では評価は信用度が低かった。
プログラミングは初心者で、衛星データに触れるのは初めてでしたが、GEEはとても使いやすく初心者におすすめだと感じました。
この記事を読んで、衛星データに触れてみたい、プログラミングを始めてみたい人が、自分の趣味とつなげて衛星データで遊んでみてくれたら幸いです。
参考文献
GEEデータカタログ:GSMaP Operational: Global Satellite Mapping of Precipitation
https://developers.google.com/earth-engine/datasets/catalog/JAXA_GPM_L3_GSMaP_v6_operational?hl=en
課題に応じて変幻自在? 衛星データをブレンドして見えるモノ・コト #マンガでわかる衛星データ
https://sorabatake.jp/5192/
富士山
https://www.yamakei-online.com/yamanavi/yama.php?yama_id=396
東岳(悪沢岳)
https://www.yamakei-online.com/yamanavi/yama.php?yama_id=614
間ノ岳
https://www.yamakei-online.com/yamanavi/yama.php?yama_id=593
恵那山
https://www.yamakei-online.com/yamanavi/yama.php?yama_id=574