はじめに
・登山好きプログラミング初心者が衛星データを利用して山探しする企画です。
・こう書いた方がより良いなどありましたら、勉強になりますのでぜひコメントください。
・本企画は以下の4部構成を予定しており、今回は第3弾です。
①日本の山リスト作成編
②衛星データで周囲で一番高い山を探してみる編
③衛星データで山周辺の地域の晴天率を調べてみる編
④衛星データで眺望の良い、山頂がひらけている山を探してみる編
前回記事(②衛星データで周囲で一番高い山を探してみる編)で作成した日本の山リストに対して、気象の衛星データを使って自分たちの登りたい山を絞っていきます。
気象データの紹介と晴天率の求め方
今回使用する衛星データは「GSMaP」です。
https://developers.google.com/earth-engine/datasets/catalog/JAXA_GPM_L3_GSMaP_v6_operational
こちらのデータのhourlyPrecipRateGCというバンドで降水量のデータを取得します。
GSMaPは1時間ごとの降水量のデータです。
本記事では晴天率の算出は以下の①〜③の流れで行います。
① X日0時〜23時までの1時間ごとの降水量の合計を計算する
② 合計値が0のときには晴れとしてカウント
③ ①と②を1ヶ月分繰り返して、晴れ/日数で晴天率を算出
つまり、1日の中で少しでも雨が降っていればその日は晴れとしてカウントしません。少し厳しい条件ですが、簡単のためその条件で求めてみます。
ImageCollectionへのmap()の適用
晴天率の算出では、一つの山に対して24時間×1ヶ月のそれぞれの画像に対して画像内の平均値を計算し、1ヶ月分の合計値を計算する必要があります。
前回の記事では一枚の画像に対して最大値を取得していました。
しかし今回のように、同じ条件の複数の画像に対して同じ処理を行う場合には、ImageCollectionと呼ばれる画像の集まりに対してmap()で同じ処理を適用する方法があります。
例として、GSMaPのデータを使って2020年10月の富士山の周辺の降水量のデータを取得してみます。
まずはライブラリのインポートとGEEへのログインを行います。
import ee
import pandas as pd
import csv
try:
ee.Initialize()
except Exception as e:
ee.Authenticate()
ee.Initialize()
関心領域と対象期間を指定して、ImageCollectionを取得します。
詳細は私もわかっていないのですが、ImageCollectionとはImageの集まりと考えれば問題ないと思います。
# 富士山周辺を指定
lon = 138.727363
lat = 35.360626
aoi = ee.Geometry.Rectangle([lon - 0.1, lat - 0.1, lon + 0.1, lat + 0.1])
# 対象期間を指定
from_date='2020-10-01'
to_date='2020-11-01'
GSMaP = ee.ImageCollection("JAXA/GPM_L3/GSMaP/v6/operational").filterDate(from_date, to_date)
reducerによって平均値を取得する関数を定義します。
あるImageに対して、reducer、関心領域、バンドを指定してreduceRegionを適用することでImageの代表値を取得することができます。
今回は取得した平均値と日付を画像のデータに書き込んで返します。
def aoi_mean(img):
mean = img.reduceRegion(reducer=ee.Reducer.mean(), geometry=aoi, scale=30).get('hourlyPrecipRateGC')
return img.set('date', img.date().format()).set('mean',mean)
上で定義したreducerの関数を、ImageCollectionに対してmap()で適用することで、ImageCollection内のそれぞれのimageに平均値を取得するreducerが適用され、日付と平均値が各imageに付与されます。
更に、reduceColumnsによって各imageが持つデータを日付と平均値のみに減らし、
取得した日付と平均値はImageCollection内のそれぞれのImageが持っているため、そちらを取り出してきてリストにし、それをpandasのデータフレームに変換します。
aoi_reduced_imgs = GSMaP.map(aoi_mean)
nested_list = aoi_reduced_imgs.reduceColumns(ee.Reducer.toList(2), ['date','mean']).values().get(0)
df = pd.DataFrame(nested_list.getInfo(), columns=['date','mean'])
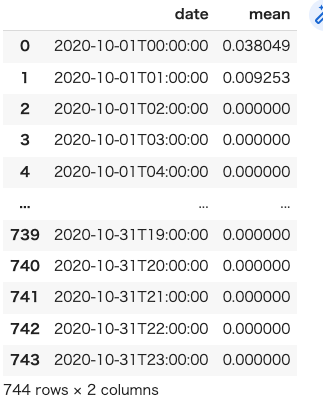
df
出力された結果は以下のようになります。
24時間×31日の744個の日付と平均値のリストを取得することができました。
リストにある山の晴天率を求めてみる
上で述べたImageCollectionへのmap()の適用を用いて晴天率の算出を行います。
まずはライブラリのインポートとGEEへのログインを行います。
import ee
import pandas as pd
import csv
try:
ee.Initialize()
except Exception as e:
ee.Authenticate()
ee.Initialize()
前回(②衛星データで周囲で一番高い山を探してみる編)取得した標高2000m以上かつ周囲で最も高い山のリストを読み込みます。
df_top = pd.read_csv("/content/drive/My Drive/mountain_list_top.csv")
対象期間を指定して、ImageCollectionを取得します。
# 対象期間を指定
from_date='2020-10-01'
to_date='2020-11-01'
GSMaP = ee.ImageCollection("JAXA/GPM_L3/GSMaP/v6/operational").filterDate(from_date, to_date)
上と同じく関心領域の平均値を取得する関数を定義します。
def aoi_mean(img):
mean = img.reduceRegion(reducer=ee.Reducer.mean(), geometry=aoi, scale=30).get('hourlyPrecipRateGC')
return img.set('date', img.date().format()).set('mean',mean)
晴天率を算出する関数を定義します。
引数として、上で作成した日付と平均値のリストを受け取るようにしています。データは、24時間×その月の日数分のデータ数を持っています。
簡単にいうと以下の①〜④の処理を行なっています。
① データ数を24で割ってその月の日数を算出
② 24時間の降水量(Imageごとの平均値)の合計値を計算
③ 合計値が0であればカウント
④ ②と③を日数分繰り返す
def get_sunny_rate(df):
cnt = 0
ndays = int(len(df) / 24)
for i in range(ndays):
total_pa = 0
k = 0
for j in range(24):
k = i * 24 + j
total_pa += df.at[k, 'mean']
if total_pa == 0:
cnt += 1
return cnt / ndays
リストにある山に対して晴天率を取得します。
リストの緯度経度から関心領域を指定し、上で定義したreducerによる平均値のリストを取得する関数と、平均値のリストから晴天率を算出する関数を適用します。
算出した晴天率は元のデータフレームの’sunny_rate’列に書き込みます。
各山に上の処理を適用し、最後にcsvとして保存します。
for i in range(len(df_top)):
lat = df_top.at[i, "緯度"]
lon = df_top.at[i, "経度"]
aoi = ee.Geometry.Rectangle([lon - 0.025, lat - 0.025, lon + 0.025, lat + 0.025])
aoi_reduced_imgs = GSMaP.map(aoi_mean)
nested_list = aoi_reduced_imgs.reduceColumns(ee.Reducer.toList(2), ['date','mean']).values().get(0)
df_pa = pd.DataFrame(nested_list.getInfo(), columns=['date','mean'])
sr = get_sunny_rate(df_pa)
df_top.at[i, 'sunny_rate'] = sr
print('Done:', df_top.at[i, "山名"])
print(sr)
df_top.to_csv("/content/drive/My Drive/add_sunny_rate.csv")
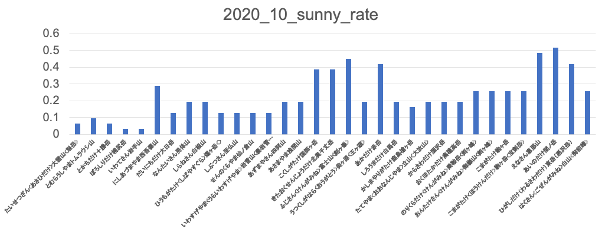
取得したcsvをエクセルを使ってグラフにしてみました。
晴天率は高くても50%程度のようです。1日の中で少しでも降水量があると雨という判定をしているので、このくらいの数字になってしまうと思われます。
判定に使用する時間帯を絞ったり、降水量も判定に使ったりより良い方法もあると思われますが、今回はとりあえずこれを晴天率とします。
まとめ
今回は対象の山周辺の晴天率を取得してみました。
ImageCollectionへmap()を使ってreducerを適用することで代表値のリストを作成する方法も紹介しました。これを使えば時系列的な比較が容易になります。
次回は最終章です。植生指数という衛星データを用いて山頂がはげている山を探していきます。
④衛星データで眺望の良い、山頂がひらけている山を探してみる編
参考文献
GEEデータカタログ:GSMaP Operational: Global Satellite Mapping of Precipitation
https://developers.google.com/earth-engine/datasets/catalog/JAXA_GPM_L3_GSMaP_v6_operational?hl=en