COTOHA API とは
NTTグループが提供している、構文解析、照応解析、キーワード抽出、音声認識、要約など、様々な自然言語処理・音声処理APIを提供しているサービスです。
COTOHA API | NTTコミュニケーションズが開発した日本最大級の日本語辞書を活用した自然言語処理、音声認識APIプラットフォーム
https://api.ce-cotoha.com/contents/index.html
「NTTって電話の会社では?」と思われてる方もあるかもしれませんが、NTTの研究所ではコンピュータでの日本語処理も何十年も前から研究されているのです。(私も学生時代にNTTコミュニケーション科学基礎研究所に見学に行ったり論文を読んだりしてお世話になりました)
最近になってクラウドの技術が進み、従来はローカルのコンピュータで動かしていたような処理をAPIサービスとしてインターネット経由で提供できるようになってきたのです。ロジックそのものの開発はNTTのどの会社・部門が提供しているのかは公開されていないようですが、APIの提供はNTTコミュニケーションズさんでされているようです。
あったほうがよい前提知識
URL
HTTPリクエスト POST
HTTPレスポンス
curl コマンド POST
JSON
GSON
Java Maven
あたりです。
構文解析とは
COTOHA API のページには以下のようにあります。
構文解析
構文解析APIは、入力として日本語で記述された文を受け取り、文の構造と意味を解析・出力します。入力された文は、文節・形態素に分解され、文節間の係り受け関係や形態素間の係り受け関係、品詞情報などの意味情報などが付与されます。
「日本語で記述された文(=自然文)」というのは
今日は学校に走って行きました。
のような文のことを言います。
これを文節に区切ると
今日は/学校に/走って行きました。
のような感じになります。(APIでは文節をchunkと呼んでいます)
また、形態素単位で区切ると
今日/は/学校/に/走/っ/て/行/き/まし/た/。
のような感じになります。(APIでは形態素をtokenと呼んでいます)
形態素解析では「行」の部分について原形の「行く」を出力したり、またそれぞれの形態素について品詞を出力したりしています。
最近は機械学習も大流行ですが、自然文を形態素解析や構文解析無しでそのまま処理するのはまだちょっと難しいというか、あまりよい結果が得られないというのが現実ではないかと思います。機械学習を適用するにしても形態素解析や構文解析で得られる値に対して機械学習を適用するのがよいかと思います。
日本語解析の場合、日本語には分かち書きが無く、語の並びが比較的自由であるのでよけいに「単純な機械学習」が通用しにくいという事情もあるのではないかと考えます。
API を利用する
さて、COTOHA APIを呼び出してみましょう。
準備編として、流れとしては以下の通りです。
- アカウント登録をする( https://api.ce-cotoha.com/ )
- APIポータル( https://api.ce-cotoha.com/home )にてアクセス情報として「Client ID」「Client secret」を取得する
- プログラムから「アクセストークン」を取得する
- 「アクセストークン」を使って各種APIにアクセスする
1.のアカウント登録はガイドに従えば問題なく完了すると思います。
2.ではAPIポータルにアクセスすると以下のような画面になりますので「Client ID」「Client secret」をコピーするなりして控えておきます。
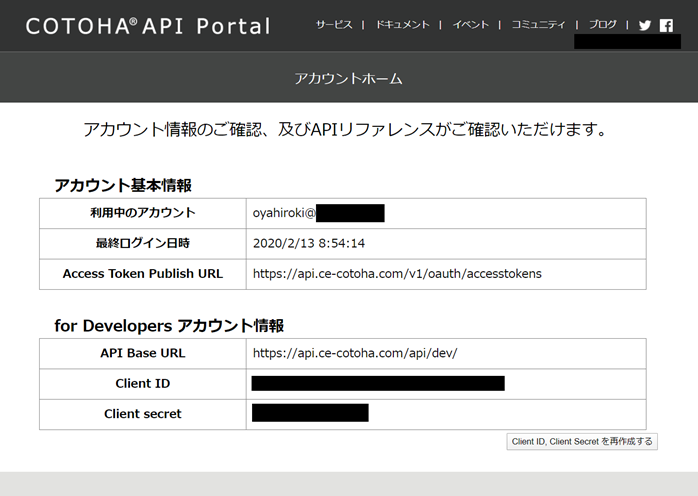
「Client ID」「Client secret」は、ユーザーIDとパスワードに相当しますが、最近のAPIでは毎回のアクセスにユーザーIDとパスワードを送信するのはちょっとよろしくないですよね、という流れなので、まずは「アクセストークン」を取得して、それを使いまわすということになっています。COTOHA APIでは最大24時間の期限が設定されていますので、最初の1回で取得したものを24時間は使いまわせるということになります。
「アクセストークン」の取得方法を調べる
どんなAPIサービスを呼び出すときもだいたい同じなのですが、まずはスペック(仕様)を見て、アクセス方法を調べます。
アクセストークン取得 | リファレンス | COTOHA API
https://api.ce-cotoha.com/contents/reference/accesstoken.html
を見ると

と書いてあります。
curl コマンド形式ではありませんね... いきなり誤植!
ドキュメントが間違っているというのはIT業界ではしょっちゅうですので、こんなことでめげてはいけません。(笑)
コードが仕様です。(←名言)
でも言わんとすることはわかります。curl コマンドでいうところの以下のようなPOSTリクエストを送信してくださいということです。
$ curl -X POST -H "Content-Type:application/json;charset=UTF-8" -d '{"grantType":"client_credentials","clientId": "[client id]","clientSecret":"[client secret]"}' "[Access Token Publish URL]"
[client id] [client secret] [Access Token Publish URL] の部分には、ポータルに書いてあるパラメータを入れます。
プログラムから「アクセストークン」を取得する
Java でHTTPリクエストを送信する方法にはいくつかありますが、ここではOkHttp というライブラリを使ってみることにします。
また、リクエスト送信時にJSONを利用しますので、これも有名な Gson を利用します。
Maven
<!-- https://mvnrepository.com/artifact/com.squareup.okhttp3/okhttp -->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>3.14.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.google.code.gson/gson -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.6</version>
</dependency>
Java + OkHttp でコードを書くと以下のような感じになります。
String url = "https://api.ce-cotoha.com/v1/oauth/accesstokens";
String clientId = "[client id]";
String clientSecret = "[client secret]";
// {
// "grantType": "client_credentials",
// "clientId": "[client id]",
// "clientSecret": "[client secret]"
// }
Gson gson = new Gson();
JsonObject jsonObj = new JsonObject();
jsonObj.addProperty("grantType", "client_credentials");
jsonObj.addProperty("clientId", clientId);
jsonObj.addProperty("clientSecret", clientSecret);
OkHttpClient client = new OkHttpClient();
MediaType JSON = MediaType.get("application/json; charset=utf-8");
RequestBody body = RequestBody.create(JSON, jsonObj.toString());
Request request = new Request.Builder() //
.url(url) //
.post(body) //
.build();
try (Response response = client.newCall(request).execute()) {
int responseCode = response.code();
String originalResponseBody = response.body().string();
System.err.println(responseCode); // 201
System.err.println(originalResponseBody);
// 201
// {
// "access_token": "xxx",
// "token_type": "bearer",
// "expires_in": "86399" ,
// "scope": "" ,
// "issued_at": "1581590104700"
// }
}
}
出力としては以下のような感じになったかと思います。「xxx」と伏字になっているところが実際のアクセストークンになります。
プログラム的にはあまり格好良くありませんが、これをコピペして使うことにしましょう。
{
"access_token": "xxx",
"token_type": "bearer",
"expires_in": "86399" ,
"scope": "" ,
"issued_at": "1581590104700"
}
構文解析APIを呼んでみる前にスペックを読んでみる
以下をしっかり読み込みます。
APIリファレンス - 構文解析
https://api.ce-cotoha.com/contents/reference/apireference.html
...
呼び出しオプションはいくつかありますが、以下の curl コマンドの例がもっともシンプルなようです。
$ curl -X POST -H "Content-Type:application/json;charset=UTF-8" -H "Authorization:Bearer [Access Token]" -d '{"sentence":"犬は歩く。","type": "default"}' "[API Base URL]/nlp/v1/parse"
構文解析APIを呼んでみる
curl コマンドだと簡単な1行ですが、Java的には以下のようになります。
String url = "https://api.ce-cotoha.com/api/dev" + "/nlp/v1/parse";
String sentence = "今日はいい天気です。";
String type = "default";
String access_token = "xxx";
Gson gson = new Gson();
JsonObject jsonObj = new JsonObject();
jsonObj.addProperty("sentence", sentence);
jsonObj.addProperty("type", type);
OkHttpClient client = new OkHttpClient();
MediaType JSON = MediaType.get("application/json; charset=utf-8");
RequestBody body = RequestBody.create(JSON, jsonObj.toString());
Request request = new Request.Builder() //
.addHeader("Authorization", "Bearer " + access_token) //
.url(url) //
.post(body) //
.build();
try (Response response = client.newCall(request).execute()) {
String originalResponseBody = response.body().string();
System.err.println(originalResponseBody);
}
結果
さて、結果はどうでしょう。
だいたい以下のような感じになると思います。
スペックとにらめっこしながらJSONを見ていくと、文節や形態素の情報がかなり細かく出力されています。
(他社APIの解析結果よりもかなり詳しい結果が得られています。)
このJSON形式の出力結果をパースしてJava のオブジェクトとして利用するということになります。
その部分はAPI呼び出しというよりもJavaの一般的なテクニックとなりますので、続きの記事に書いてみたいと思います。
→続きの記事 COTOHA API の構文解析 を Java でパースする
{
"result": [
{
"chunk_info": {"id": 0,"head": 2,"dep": "D","chunk_head": 0,"chunk_func": 1,
"links": []
},
"tokens": [
{
"id": 0,
"form": "今日",
"kana": "キョウ",
"lemma": "今日",
"pos": "名詞",
"features": ["日時"],
"dependency_labels": [
{
"token_id": 1,
"label": "case"
}
],
"attributes": {
}
},
{
"id": 1,
"form": "は",
"kana": "ハ",
"lemma": "は",
"pos": "連用助詞",
"features": [],
"attributes": {
}
}
]
},
{
"chunk_info": {
"id": 1,
"head": 2,
"dep": "D",
"chunk_head": 0,
"chunk_func": 1,
"links": []
},
"tokens": [
{
"id": 2,
"form": "い",
"kana": "イ",
"lemma": "いい",
"pos": "形容詞語幹",
"features": [
"イ段"
],
"dependency_labels": [
{
"token_id": 3,
"label": "aux"
}
],
"attributes": {
}
},
{
"id": 3,
"form": "い",
"kana": "イ",
"lemma": "い",
"pos": "形容詞接尾辞",
"features": [
"連体"
],
"attributes": {
}
}
]
},
{
"chunk_info": {
"id": 2,
"head": -1,
"dep": "O",
"chunk_head": 0,
"chunk_func": 1,
"links": [
{
"link": 0,
"label": "time"
},
{
"link": 1,
"label": "adjectivals"
}
],
"predicate": []
},
"tokens": [
{
"id": 4,
"form": "天気",
"kana": "テンキ",
"lemma": "天気",
"pos": "名詞",
"features": [],
"dependency_labels": [
{
"token_id": 0,
"label": "nmod"
},
{
"token_id": 2,
"label": "amod"
},
{
"token_id": 5,
"label": "cop"
},
{
"token_id": 6,
"label": "punct"
}
],
"attributes": {
}
},
{
"id": 5,
"form": "です",
"kana": "デス",
"lemma": "です",
"pos": "判定詞",
"features": [
"終止"
],
"attributes": {
}
},
{
"id": 6,
"form": "。",
"kana": "",
"lemma": "。",
"pos": "句点",
"features": [],
"attributes": {
}
}
]
}
],
"status": 0,
"message": ""
}