REST APIの利用
COTOHA API のようなREST APIの利用では3つの処理が必要になります。
- HTTPリクエストの作成
- HTTPリクエストの送信(エラー発生時のハンドリング)
- HTTPレスポンスの受信
このうち前回の記事( COTOHA API の構文解析 を Java で利用してみる )では
1.(作成)と 2.(送信)に相当する処理を行っていましたが、レスポンスは単なるJSONで放置していましたので Javaのクラスにマッピングすることにします。
Java クラス
私が日曜大工で作成している NLP4J にて 係り受けを実装したモデルである DefaultKeywordWithDependency クラスを用意していますので、そこにマップすることにします。(→なので単純にPOJOクラスにマッピング、とはしません。)
※本職では英語の解析を業務としており、日曜大工でオープンソース版のNLP用Javaライブラリ開発+日本語の解析をしています。
DefaultKeywordWithDependency
https://github.com/oyahiroki/nlp4j/blob/master/nlp4j/nlp4j-core/src/main/java/nlp4j/impl/DefaultKeywordWithDependency.java
Parser
構文解析結果のJSON は以下のような感じになっています。構文解析の結果はツリー状のデータになるのですが、JSON的にはツリーにはなっていないことが読み取れます。
{
"result": [
{
"chunk_info": {"id": 0,"head": 2,"dep": "D","chunk_head": 0,"chunk_func": 1,
"links": []
},
"tokens": [
{
"id": 0,"form": "今日","kana": "キョウ","lemma": "今日","pos": "名詞",
"features": ["日時"],
"dependency_labels": [{"token_id": 1,"label": "case"}],
"attributes": {}
},
{
"id": 1,"form": "は","kana": "ハ","lemma": "は","pos": "連用助詞",
"features": [],
"attributes": {}
}
]
},
{...(略)...},
{...(略)...}
]
}
],
"status": 0,
"message": ""
}
以下がパースのためのクラスです。(コードはすべてMaven RepositoryとGithubで公開予定です)
※追記:2020年2月27日、修正しました。
package nlp4j.cotoha;
import java.lang.invoke.MethodHandles;
import java.util.ArrayList;
import java.util.HashMap;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonObject;
import nlp4j.Keyword;
import nlp4j.impl.DefaultKeyword;
import nlp4j.impl.DefaultKeywordWithDependency;
/**
* COTOHA API 構文解析 V1 のレスポンスJSONをパースする
*
* @author Hiroki Oya
* @since 1.0.0.0
*
*/
public class CotohaNlpV1ResponseHandler {
static private final Logger logger = LogManager.getLogger(MethodHandles.lookup().lookupClass());
/**
* 構文のルートとして抽出されたキーワード
*/
ArrayList<DefaultKeywordWithDependency> roots = new ArrayList<>();
/**
* キーワードの並び
*/
ArrayList<Keyword> keywords = new ArrayList<>();
/**
* 文節掛かり元キーワード
*/
ArrayList<Keyword> chunkLinkKeywords = new ArrayList<>();
/**
* @return 文節掛かり元キーワード
*/
public ArrayList<Keyword> getChunkLinkKeywords() {
return chunkLinkKeywords;
}
/**
* 掛かり元
*/
ArrayList<String> chunkLinks = new ArrayList<>();
/**
* 掛かり元
*/
JsonArray arrChunkLinks = new JsonArray();
/**
* Map: token_id --> Keyword
*/
HashMap<String, DefaultKeywordWithDependency> mapTokenidKwd = new HashMap<>();
/**
* Map: id --> Keyword
*/
HashMap<String, DefaultKeywordWithDependency> mapIdKwd = new HashMap<>();
/**
* token id --> sentence
*/
HashMap<Integer, Integer> idSentenceMap = new HashMap<>();
/**
* 係り受けキーワード
*/
ArrayList<DefaultKeyword> patternKeywords = new ArrayList<>();
/**
* @return 掛かり元
*/
public JsonArray getArrChunkLinks() {
return arrChunkLinks;
}
/**
* @return 掛かり元
*/
public ArrayList<String> getChunkLinks() {
return chunkLinks;
}
/**
* @return IDとキーワードのマップ
*/
public HashMap<String, DefaultKeywordWithDependency> getIdMapKwd() {
return mapIdKwd;
}
/**
* @return 形態素のIDと文番号のマッピング
*/
public HashMap<Integer, Integer> getIdSentenceMap() {
return idSentenceMap;
}
/**
* @return 語の並び
*/
public ArrayList<Keyword> getKeywords() {
return keywords;
}
/**
* @return TOKEN ID とキーワードのマップ
*/
public HashMap<String, DefaultKeywordWithDependency> getMapKwd() {
return mapTokenidKwd;
}
/**
* @return 掛かりうけキーワード
*/
public ArrayList<DefaultKeyword> getPatternKeywords() {
return patternKeywords;
}
/**
* @return 抽出された係り受けルートキーワード
*/
public ArrayList<DefaultKeywordWithDependency> getRoots() {
return roots;
}
/**
* @param json COTOHA API 構文解析のレスポンスJSON
*/
public void parse(String json) {
// JSON Parser
Gson gson = new Gson();
// COTOHA API RESPONSE
JsonObject result = gson.fromJson(json, JsonObject.class);
// 文の中で出てきた順
int sequence = 0;
// {
// "result":[
// _{"chunk_info":{...},"tokens"[{...},{...},{...}]},
// _{"chunk_info":{...},"tokens"[{...},{...},{...}]},
// _{"chunk_info":{...},"tokens"[{...},{...},{...}]}
// ]
// }
// chunk_info と tokens を合わせたオブジェクト
JsonArray arrChunkTokens = result.getAsJsonArray("result");
int idxBegin = 0;
int idxSentence = 0;
// FOR EACH(chunk_tokens)
for (int idxChunkTokens = 0; idxChunkTokens < arrChunkTokens.size(); idxChunkTokens++) {
JsonObject chunk_token = arrChunkTokens.get(idxChunkTokens).getAsJsonObject();
// 1. chunk_info 文節情報オブジェクト
// https://api.ce-cotoha.com/contents/reference/apireference.html#parsing_response_chunk
JsonObject chunk_info = chunk_token.get("chunk_info").getAsJsonObject();
logger.debug("chunk_info: " + chunk_info);
int chunk_head = -1;
{
// 形態素番号(0オリジン)
String chunk_id = "" + chunk_info.get("id").getAsInt();
// 係り先の文節番号
chunk_head = chunk_info.get("head").getAsInt();
// 掛かり元情報の配列
// https://api.ce-cotoha.com/contents/reference/apireference.html#parsing_response_links
JsonArray links = chunk_info.get("links").getAsJsonArray();
for (int n = 0; n < links.size(); n++) {
JsonObject link = links.get(n).getAsJsonObject();
int link_link = link.get("link").getAsInt();
String link_label = link.get("label").getAsString();
chunkLinks.add(chunk_id + "/" + link_label + "/" + link_link);
arrChunkLinks.add(link);
}
}
// 2. tokens 形態素情報オブジェクト
// https://api.ce-cotoha.com/contents/reference/apireference.html#parsing_response_morpheme
JsonArray tokens = chunk_token.get("tokens").getAsJsonArray();
// FOR EACH TOKENS 形態素情報オブジェクト
for (int idxTokens = 0; idxTokens < tokens.size(); idxTokens++) {
JsonObject token = tokens.get(idxTokens).getAsJsonObject();
logger.debug("token: " + token);
// X-Y 形式のID ある文節の中で何番目の形態素であるか
String token_id = idxChunkTokens + "-" + idxTokens;
logger.debug("token_id: " + token_id);
String token_pos = token.get("pos") != null ? token.get("pos").getAsString() : null;
String token_lemma = token.get("lemma") != null ? token.get("lemma").getAsString() : null;
String token_form = token.get("form") != null ? token.get("form").getAsString() : null;
String token_kana = token.get("kana") != null ? token.get("kana").getAsString() : null;
// token のうちの最後かどうか。trueであれば係り受けの先は次のtoken
boolean isLastOfTokens = (idxTokens == tokens.size() - 1);
if (isLastOfTokens) {
logger.debug("最後のトークン: chunk_head:" + chunk_head);
}
// 係り受け形式のキーワード (nlp4j で定義)
DefaultKeywordWithDependency kw = new DefaultKeywordWithDependency();
// 文中で出てきた順の連番
kw.setSequence(sequence);
sequence++;
// 開始位置
kw.setBegin(idxBegin);
// lemma:見出し語:原形
if (token_lemma != null) {
kw.setLex(token_lemma);
} else {
logger.warn("lemma is null");
}
int intId = token.get("id").getAsInt();
String id = "" + token.get("id").getAsInt();
idSentenceMap.put(intId, idxSentence);
// 文の最後かどうか
boolean isLastOfSentence = (chunk_head == -1 && idxTokens == tokens.size() - 1) //
|| (token_pos != null && token_pos.equals("句点"));
// IF(文の最後)
if (isLastOfSentence) {
// increment 文番号
idxSentence++;
}
// set facet 品詞
kw.setFacet(token_pos);
// set str 表出形
kw.setStr(token_form);
kw.setEnd(idxBegin + kw.getStr().length());
idxBegin += kw.getStr().length();
// set reading 読み
kw.setReading(token_kana);
mapTokenidKwd.put(token_id, kw);
mapIdKwd.put(id, kw);
keywords.add(kw);
// dependency labels 依存先情報の配列
if (token.get("dependency_labels") != null) {
// 依存先情報の配列
JsonArray arrDependency = token.get("dependency_labels").getAsJsonArray();
for (int n = 0; n < arrDependency.size(); n++) {
// 依存先情報
JsonObject objDependency = arrDependency.get(n).getAsJsonObject();
String dependency_token_id = "" + objDependency.get("token_id").getAsInt();
// キーワードに依存先情報をセット
kw.setDependencyKey(dependency_token_id);
}
}
} // END OF FOR EACH TOKENS
} // END OF FOR EACH (chunk_tokens)
// <ツリーの組み立て>
// FOR EACH(chunk_tokens)
for (int idxChunkTokens = 0; idxChunkTokens < arrChunkTokens.size(); idxChunkTokens++) {
JsonObject chunk_token = arrChunkTokens.get(idxChunkTokens).getAsJsonObject();
// 2. tokens
JsonArray tokens = chunk_token.get("tokens").getAsJsonArray();
// FOR (EACH TOKEN)
for (int idxTokens = 0; idxTokens < tokens.size(); idxTokens++) {
JsonObject token = tokens.get(idxTokens).getAsJsonObject();
String id = "" + token.get("id").getAsInt();
DefaultKeywordWithDependency kw = mapIdKwd.get(id);
// dependency labels
if (token.get("dependency_labels") != null) {
JsonArray arr_dependency_labels = token.get("dependency_labels").getAsJsonArray();
for (int n = 0; n < arr_dependency_labels.size(); n++) {
JsonObject dependency_label = arr_dependency_labels.get(n).getAsJsonObject();
String childID = "" + dependency_label.get("token_id").getAsInt();
String labelDependency = dependency_label.get("label").getAsString();
// 文をまたいでいないかをチェックする
int sentence1 = idSentenceMap.get(token.get("id").getAsInt());
int sentence2 = idSentenceMap.get(dependency_label.get("token_id").getAsInt());
// 文をまたいでない
if (mapIdKwd.get(childID) != null && (sentence1 == sentence2)) {
// 日本語と英語では ParentとChild が逆
DefaultKeywordWithDependency kw1Child = mapIdKwd.get(childID);
DefaultKeywordWithDependency kw2Parent = kw;
kw2Parent.addChild(kw1Child);
kw1Child.setRelation(labelDependency);
if (kw1Child.getBegin() < kw2Parent.getBegin()) {
DefaultKeyword kwd = new DefaultKeyword();
kwd.setBegin(kw1Child.getBegin());
kwd.setEnd(kw2Parent.getEnd());
kwd.setLex(kw1Child.getLex() + " ... " + kw2Parent.getLex());
kwd.setFacet(labelDependency);
patternKeywords.add(kwd);
} else {
DefaultKeyword kwd = new DefaultKeyword();
kwd.setBegin(kw2Parent.getBegin());
kwd.setEnd(kw1Child.getEnd());
kwd.setLex(kw2Parent.getLex() + " ... " + kw1Child.getLex());
kwd.setFacet(labelDependency);
patternKeywords.add(kwd);
}
} //
}
}
} // END OF FOR EACH TOKEN
} // END OF FOR EACH (chunk_tokens)
for (String link : chunkLinks) {
String id1 = link.split("/")[0];
String relation = link.split("/")[1];
String id2 = link.split("/")[2];
Keyword kwd1 = mapTokenidKwd.get(id1 + "-0");
Keyword kwd2 = mapTokenidKwd.get(id2 + "-0");
String lex1 = kwd1.getLex();
String lex2 = kwd2.getLex();
DefaultKeyword kwd = new DefaultKeyword();
kwd.setBegin(kwd1.getBegin());
kwd.setEnd(kwd2.getEnd());
kwd.setLex(lex2 + " ... " + lex1);
kwd.setStr(kwd.getLex());
kwd.setFacet(relation);
chunkLinkKeywords.add(kwd);
}
// </ツリーの組み立て>
for (String key : mapIdKwd.keySet()) {
DefaultKeywordWithDependency kw = mapIdKwd.get(key);
// IF(ルートキーワードであれば)
if (kw.getParent() == null) {
roots.add(kw);
}
}
} // end of parse()
}
注意事項
COTOHA APIの構文解析について、「今日はいい天気です。明日は学校に行きます。」のように2つの文を解析すると、2文にまたがった係り受けが返されるようです。(認識が間違っていたらご指摘ください)
解析デモのページでは2文が分割されているのですが、これはあらかじめ句点で文を区切ったうえで構文解析の処理をしているようです。
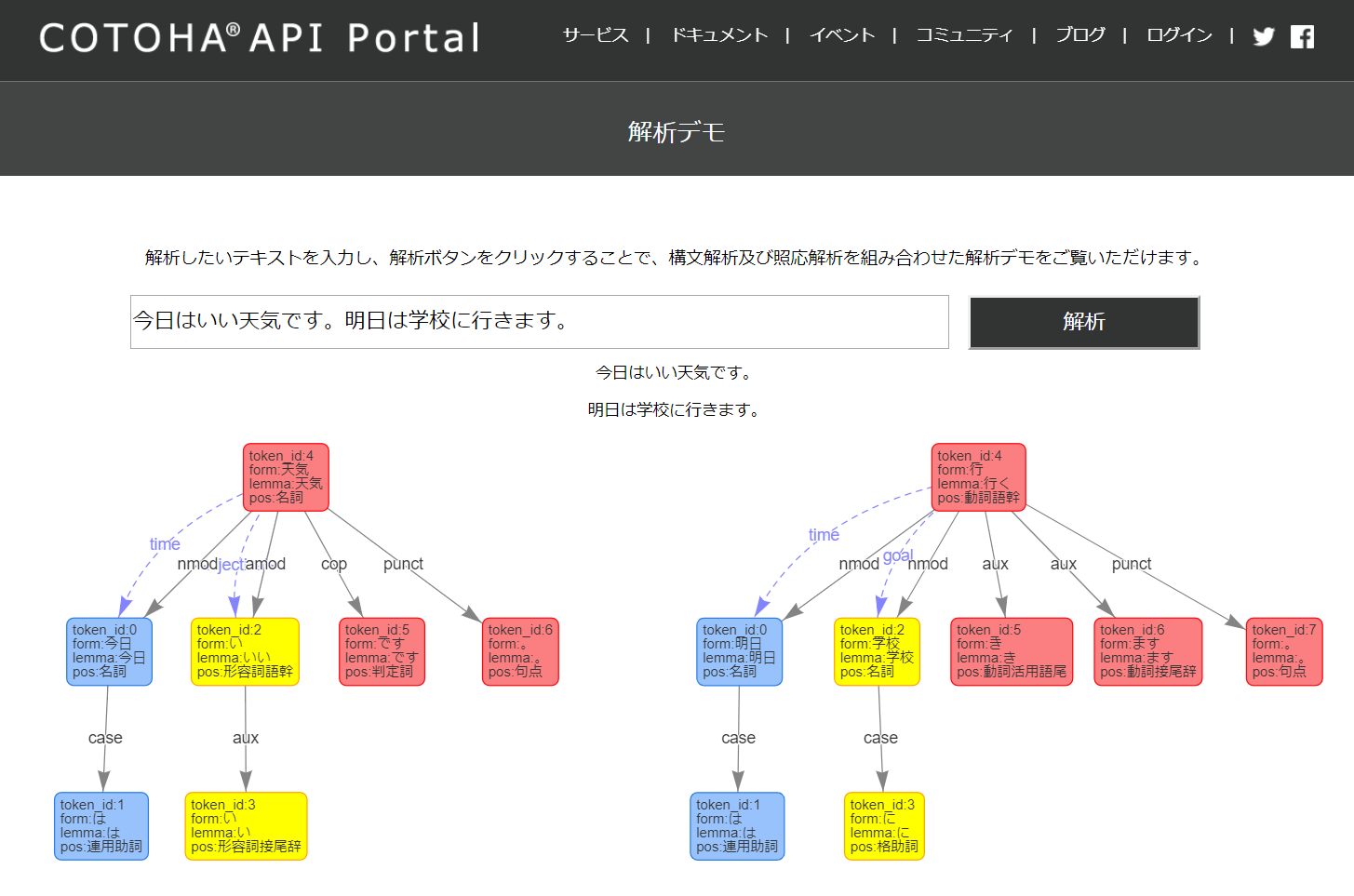
ですので、このパーサーでは以下のように事前に「いくつ目の文か」をカウントしています。

文をまたいだ係り受けは無視するようにしています。

Parser の利用
TestCaseとして、COTOHA 構文解析APIの結果を保存しておいたJSONをパースして、文字として出力してみることにします。
(後日、Githubで公開予定)
File file = new File("src/test/resources/nlp_v1_parse_002.json");
String json = FileUtils.readFileToString(file, "UTF-8");
CotohaNlpV1ResponseHandler handler = new CotohaNlpV1ResponseHandler();
handler.parse(json);
for (DefaultKeywordWithDependency root : handler.getRoots()) {
System.err.println(root.toStringAsDependencyTree());
}
System.err.println("---");
for (Keyword kwd : handler.getKeywords()) {
System.err.println(kwd.getLex() + " (" + "word." + kwd.getFacet() + ")");
System.err.println("\t" + kwd);
}
System.err.println("---");
for (Keyword kwd : handler.getPatternKeywords()) {
System.err.println(kwd.getLex() + " (" + "pattern." + kwd.getFacet() + ")");
System.err.println("\t" + kwd);
}
System.err.println("---");
for (Keyword kwd : handler.getChunkLinkKeywords()) {
System.err.println(kwd.getLex() + " (" + "pattern." + kwd.getFacet() + ")");
System.err.println("\t" + kwd);
}
結果
以下のような感じになりました。
生JSONだと読みづらいですが、ツリー状に出力してみました。
係り受けの様子がわかりやすくなりました。
-sequence=11,lex=行く,str=行,relation=null
-sequence=7,lex=明日,str=明日,relation=nmod
-sequence=8,lex=は,str=は,relation=case
-sequence=9,lex=学校,str=学校,relation=nmod
-sequence=10,lex=に,str=に,relation=case
-sequence=12,lex=き,str=き,relation=aux
-sequence=13,lex=ます,str=ます,relation=aux
-sequence=14,lex=。,str=。,relation=punct
-sequence=4,lex=天気,str=天気,relation=null
-sequence=0,lex=今日,str=今日,relation=nmod
-sequence=1,lex=は,str=は,relation=case
-sequence=2,lex=いい,str=い,relation=amod
-sequence=3,lex=い,str=い,relation=aux
-sequence=5,lex=です,str=です,relation=cop
-sequence=6,lex=。,str=。,relation=punct
---
今日 (word.名詞)
今日 [relation=nmod, sequence=0, dependencyKey=1, hasChildren=true, hasParent=false, facet=名詞, lex=今日, str=今日, reading=キョウ, begin=0, end=2]
は (word.連用助詞)
は [relation=case, sequence=1, dependencyKey=null, hasChildren=false, hasParent=false, facet=連用助詞, lex=は, str=は, reading=ハ, begin=2, end=3]
いい (word.形容詞語幹)
いい [relation=amod, sequence=2, dependencyKey=3, hasChildren=true, hasParent=false, facet=形容詞語幹, lex=いい, str=い, reading=イ, begin=3, end=4]
い (word.形容詞接尾辞)
い [relation=aux, sequence=3, dependencyKey=null, hasChildren=false, hasParent=false, facet=形容詞接尾辞, lex=い, str=い, reading=イ, begin=4, end=5]
天気 (word.名詞)
天気 [relation=null, sequence=4, dependencyKey=6, hasChildren=true, hasParent=true, facet=名詞, lex=天気, str=天気, reading=テンキ, begin=5, end=7]
です (word.判定詞)
です [relation=cop, sequence=5, dependencyKey=null, hasChildren=false, hasParent=false, facet=判定詞, lex=です, str=です, reading=デス, begin=7, end=9]
。 (word.句点)
。 [relation=punct, sequence=6, dependencyKey=null, hasChildren=false, hasParent=false, facet=句点, lex=。, str=。, reading=, begin=9, end=10]
明日 (word.名詞)
明日 [relation=nmod, sequence=7, dependencyKey=8, hasChildren=true, hasParent=false, facet=名詞, lex=明日, str=明日, reading=アス, begin=10, end=12]
は (word.連用助詞)
は [relation=case, sequence=8, dependencyKey=null, hasChildren=false, hasParent=false, facet=連用助詞, lex=は, str=は, reading=ハ, begin=12, end=13]
学校 (word.名詞)
学校 [relation=nmod, sequence=9, dependencyKey=10, hasChildren=true, hasParent=false, facet=名詞, lex=学校, str=学校, reading=ガッコウ, begin=13, end=15]
に (word.格助詞)
に [relation=case, sequence=10, dependencyKey=null, hasChildren=false, hasParent=false, facet=格助詞, lex=に, str=に, reading=ニ, begin=15, end=16]
行く (word.動詞語幹)
行く [relation=null, sequence=11, dependencyKey=14, hasChildren=true, hasParent=true, facet=動詞語幹, lex=行く, str=行, reading=イ, begin=16, end=17]
き (word.動詞活用語尾)
き [relation=aux, sequence=12, dependencyKey=null, hasChildren=false, hasParent=false, facet=動詞活用語尾, lex=き, str=き, reading=キ, begin=17, end=18]
ます (word.動詞接尾辞)
ます [relation=aux, sequence=13, dependencyKey=null, hasChildren=false, hasParent=false, facet=動詞接尾辞, lex=ます, str=ます, reading=マス, begin=18, end=20]
。 (word.句点)
。 [relation=punct, sequence=14, dependencyKey=null, hasChildren=false, hasParent=false, facet=句点, lex=。, str=。, reading=, begin=20, end=21]
---
今日 ... は (pattern.case)
今日 ... は [sequence=-1, facet=case, lex=今日 ... は, str=null, reading=null, count=-1, begin=0, end=3, correlation=0.0]
いい ... い (pattern.aux)
いい ... い [sequence=-1, facet=aux, lex=いい ... い, str=null, reading=null, count=-1, begin=3, end=5, correlation=0.0]
今日 ... 天気 (pattern.nmod)
今日 ... 天気 [sequence=-1, facet=nmod, lex=今日 ... 天気, str=null, reading=null, count=-1, begin=0, end=7, correlation=0.0]
いい ... 天気 (pattern.amod)
いい ... 天気 [sequence=-1, facet=amod, lex=いい ... 天気, str=null, reading=null, count=-1, begin=3, end=7, correlation=0.0]
天気 ... です (pattern.cop)
天気 ... です [sequence=-1, facet=cop, lex=天気 ... です, str=null, reading=null, count=-1, begin=5, end=9, correlation=0.0]
天気 ... 。 (pattern.punct)
天気 ... 。 [sequence=-1, facet=punct, lex=天気 ... 。, str=null, reading=null, count=-1, begin=5, end=10, correlation=0.0]
明日 ... は (pattern.case)
明日 ... は [sequence=-1, facet=case, lex=明日 ... は, str=null, reading=null, count=-1, begin=10, end=13, correlation=0.0]
学校 ... に (pattern.case)
学校 ... に [sequence=-1, facet=case, lex=学校 ... に, str=null, reading=null, count=-1, begin=13, end=16, correlation=0.0]
明日 ... 行く (pattern.nmod)
明日 ... 行く [sequence=-1, facet=nmod, lex=明日 ... 行く, str=null, reading=null, count=-1, begin=10, end=17, correlation=0.0]
学校 ... 行く (pattern.nmod)
学校 ... 行く [sequence=-1, facet=nmod, lex=学校 ... 行く, str=null, reading=null, count=-1, begin=13, end=17, correlation=0.0]
行く ... き (pattern.aux)
行く ... き [sequence=-1, facet=aux, lex=行く ... き, str=null, reading=null, count=-1, begin=16, end=18, correlation=0.0]
行く ... ます (pattern.aux)
行く ... ます [sequence=-1, facet=aux, lex=行く ... ます, str=null, reading=null, count=-1, begin=16, end=20, correlation=0.0]
行く ... 。 (pattern.punct)
行く ... 。 [sequence=-1, facet=punct, lex=行く ... 。, str=null, reading=null, count=-1, begin=16, end=21, correlation=0.0]
---
今日 ... 天気 (pattern.time)
今日 ... 天気 [sequence=-1, facet=time, lex=今日 ... 天気, str=今日 ... 天気, reading=null, count=-1, begin=5, end=2, correlation=0.0]
いい ... 天気 (pattern.adjectivals)
いい ... 天気 [sequence=-1, facet=adjectivals, lex=いい ... 天気, str=いい ... 天気, reading=null, count=-1, begin=5, end=4, correlation=0.0]
天気 ... 行く (pattern.manner)
天気 ... 行く [sequence=-1, facet=manner, lex=天気 ... 行く, str=天気 ... 行く, reading=null, count=-1, begin=16, end=7, correlation=0.0]
明日 ... 行く (pattern.time)
明日 ... 行く [sequence=-1, facet=time, lex=明日 ... 行く, str=明日 ... 行く, reading=null, count=-1, begin=16, end=12, correlation=0.0]
学校 ... 行く (pattern.goal)
学校 ... 行く [sequence=-1, facet=goal, lex=学校 ... 行く, str=学校 ... 行く, reading=null, count=-1, begin=16, end=15, correlation=0.0]
所感
Javaのクラスとして扱いやすいということは、業務で利用するうえでも扱いやすいということになります。
構文解析の結果をパースするのはそれなりに手間ですが、業務の世界ではここからが勝負です。