掛かりうけ元は複数
のテストをしていて気づいたのですが、APIデモ では「嫁と娘は旅行に行った。」の解析結果について
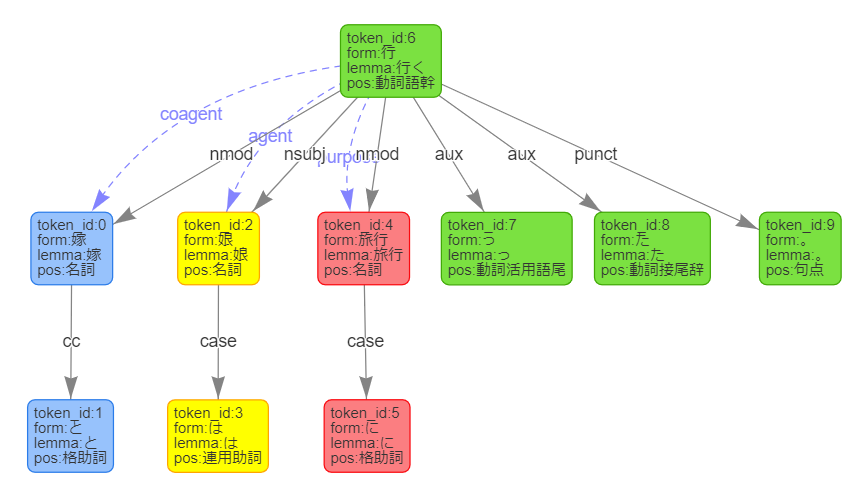
のように出力されるので、これがてっきり正解をすべて表しているのかと思っていましたが、実際には
{
"id" : 2,
"form" : "娘",
"kana" : "ムスメ",
"lemma" : "娘",
"pos" : "名詞",
"dependency_labels" : [ {
"token_id" : 0,
"label" : "conj"
}, {
"token_id" : 3,
"label" : "case"
} ],
"attributes" : { }
}
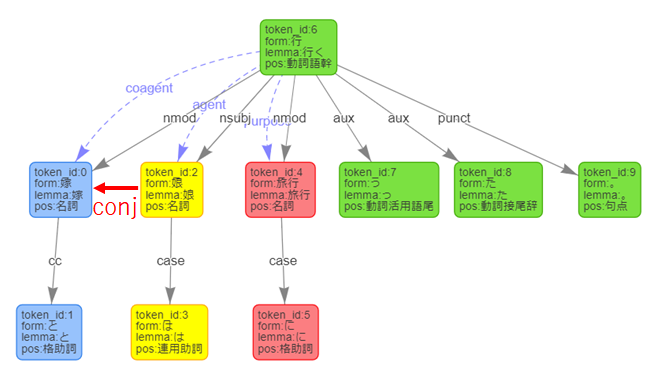
として返ってきており、図にすると以下の赤線のようになります。
JSONの属性名が「dependency_labels」になっているので複数であるのはわかりやすいですが、デモだけを見ていると複数ではないようにも見えるので注意が必要だと思いました。
また、デモがAPIの魅力を伝えきれていないようにも見えました。
送信できる文書は1つ
処理対象として指定できる「文書」(例:コールセンターの複数件のログ)は、1回のAPIコールで1つです。大量の文書を処理しようとするときは1つずつではなくて複数の文書をまとめて処理したくなるのでこの点も要注意かと思いました。(例:別々の顧客のコールログを連結して構文解析処理するのは不適切。)次のバージョンでは複数の文書を処理できることを期待します。

複数文を解析処理したときの挙動
「嫁と娘は旅行に行った。私と息子は焼き肉を食べた。」を送信すると以下のレスポンスが返ります。
{
"result" : [ {
"chunk_info" : {
"id" : 0,
"head" : 1,
"dep" : "P",
"chunk_head" : 0,
"chunk_func" : 1,
"links" : [ ]
},
"tokens" : [ {
"id" : 0,
"form" : "嫁",
"kana" : "ヨメ",
"lemma" : "嫁",
"pos" : "名詞",
"features" : [ ],
"common_noun_semantic" : [ 49, 76, 88 ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ ],
"dependency_labels" : [ {
"token_id" : 1,
"label" : "cc"
} ],
"attributes" : { }
}, {
"id" : 1,
"form" : "と",
"kana" : "ト",
"lemma" : "と",
"pos" : "格助詞",
"features" : [ "連用" ],
"common_noun_semantic" : [ ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ ],
"attributes" : { }
} ]
}, {
"chunk_info" : {
"id" : 1,
"head" : 7,
"dep" : "D",
"chunk_head" : 0,
"chunk_func" : 1,
"links" : [ {
"link" : 0,
"label" : "other"
} ]
},
"tokens" : [ {
"id" : 2,
"form" : "娘",
"kana" : "ムスメ",
"lemma" : "娘",
"pos" : "名詞",
"features" : [ ],
"common_noun_semantic" : [ 49, 59, 88 ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ ],
"dependency_labels" : [ {
"token_id" : 0,
"label" : "conj"
}, {
"token_id" : 3,
"label" : "case"
} ],
"attributes" : { }
}, {
"id" : 3,
"form" : "は",
"kana" : "ハ",
"lemma" : "は",
"pos" : "連用助詞",
"features" : [ ],
"common_noun_semantic" : [ ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ ],
"attributes" : { }
} ]
}, {
"chunk_info" : {
"id" : 2,
"head" : 3,
"dep" : "D",
"chunk_head" : 0,
"chunk_func" : 1,
"links" : [ ]
},
"tokens" : [ {
"id" : 4,
"form" : "旅行",
"kana" : "リョコウ",
"lemma" : "旅行",
"pos" : "名詞",
"features" : [ "動作" ],
"common_noun_semantic" : [ 1658, 1659, 1660 ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ 18 ],
"dependency_labels" : [ {
"token_id" : 5,
"label" : "case"
} ],
"attributes" : { }
}, {
"id" : 5,
"form" : "に",
"kana" : "ニ",
"lemma" : "に",
"pos" : "格助詞",
"features" : [ "連用" ],
"common_noun_semantic" : [ ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ ],
"attributes" : { }
} ]
}, {
"chunk_info" : {
"id" : 3,
"head" : 7,
"dep" : "P",
"chunk_head" : 0,
"chunk_func" : 2,
"links" : [ {
"link" : 2,
"label" : "purpose"
} ],
"predicate" : [ "past" ]
},
"tokens" : [ {
"id" : 6,
"form" : "行",
"kana" : "イ",
"lemma" : "行く",
"pos" : "動詞語幹",
"features" : [ "IKU" ],
"common_noun_semantic" : [ 2053, 2132 ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ 15, 20, 29, 32, 5 ],
"dependency_labels" : [ {
"token_id" : 4,
"label" : "nmod"
}, {
"token_id" : 7,
"label" : "aux"
}, {
"token_id" : 8,
"label" : "aux"
}, {
"token_id" : 9,
"label" : "punct"
} ],
"attributes" : { }
}, {
"id" : 7,
"form" : "っ",
"kana" : "ッ",
"lemma" : "っ",
"pos" : "動詞活用語尾",
"features" : [ ],
"common_noun_semantic" : [ ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ ],
"attributes" : { }
}, {
"id" : 8,
"form" : "た",
"kana" : "タ",
"lemma" : "た",
"pos" : "動詞接尾辞",
"features" : [ "終止" ],
"common_noun_semantic" : [ ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ ],
"attributes" : { }
}, {
"id" : 9,
"form" : "。",
"kana" : "",
"lemma" : "。",
"pos" : "句点",
"features" : [ ],
"common_noun_semantic" : [ ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ ],
"attributes" : { }
} ]
}, {
"chunk_info" : {
"id" : 4,
"head" : 7,
"dep" : "D",
"chunk_head" : 0,
"chunk_func" : 1,
"links" : [ ]
},
"tokens" : [ {
"id" : 10,
"form" : "私",
"kana" : "ワタシ",
"lemma" : "私",
"pos" : "名詞",
"features" : [ "代名詞" ],
"common_noun_semantic" : [ 37, 8 ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ ],
"dependency_labels" : [ {
"token_id" : 11,
"label" : "cc"
} ],
"attributes" : { }
}, {
"id" : 11,
"form" : "と",
"kana" : "ト",
"lemma" : "と",
"pos" : "格助詞",
"features" : [ "連用" ],
"common_noun_semantic" : [ ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ ],
"attributes" : { }
} ]
}, {
"chunk_info" : {
"id" : 5,
"head" : 7,
"dep" : "D",
"chunk_head" : 0,
"chunk_func" : 1,
"links" : [ ]
},
"tokens" : [ {
"id" : 12,
"form" : "息子",
"kana" : "ムスコ",
"lemma" : "息子",
"pos" : "名詞",
"features" : [ ],
"common_noun_semantic" : [ 48, 58, 87 ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ ],
"dependency_labels" : [ {
"token_id" : 13,
"label" : "case"
} ],
"attributes" : { }
}, {
"id" : 13,
"form" : "は",
"kana" : "ハ",
"lemma" : "は",
"pos" : "連用助詞",
"features" : [ ],
"common_noun_semantic" : [ ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ ],
"attributes" : { }
} ]
}, {
"chunk_info" : {
"id" : 6,
"head" : 7,
"dep" : "D",
"chunk_head" : 0,
"chunk_func" : 1,
"links" : [ ]
},
"tokens" : [ {
"id" : 14,
"form" : "焼き肉",
"kana" : "ヤキニク",
"lemma" : "焼き肉",
"pos" : "名詞",
"features" : [ ],
"common_noun_semantic" : [ 843, 852 ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ ],
"dependency_labels" : [ {
"token_id" : 15,
"label" : "case"
} ],
"attributes" : { }
}, {
"id" : 15,
"form" : "を",
"kana" : "ヲ",
"lemma" : "を",
"pos" : "格助詞",
"features" : [ "連用" ],
"common_noun_semantic" : [ ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ ],
"attributes" : { }
} ]
}, {
"chunk_info" : {
"id" : 7,
"head" : -1,
"dep" : "O",
"chunk_head" : 0,
"chunk_func" : 1,
"links" : [ {
"link" : 1,
"label" : "agent"
}, {
"link" : 3,
"label" : "manner"
}, {
"link" : 4,
"label" : "coagent"
}, {
"link" : 5,
"label" : "agent"
}, {
"link" : 6,
"label" : "object"
} ],
"predicate" : [ "past" ]
},
"tokens" : [ {
"id" : 16,
"form" : "食べ",
"kana" : "タベ",
"lemma" : "食べる",
"pos" : "動詞語幹",
"features" : [ "A" ],
"common_noun_semantic" : [ 1581, 1590 ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ 2, 23 ],
"dependency_labels" : [ {
"token_id" : 2,
"label" : "nsubj"
}, {
"token_id" : 6,
"label" : "advcl"
}, {
"token_id" : 10,
"label" : "nmod"
}, {
"token_id" : 12,
"label" : "nsubj"
}, {
"token_id" : 14,
"label" : "dobj"
}, {
"token_id" : 17,
"label" : "aux"
}, {
"token_id" : 18,
"label" : "punct"
} ],
"attributes" : { }
}, {
"id" : 17,
"form" : "た",
"kana" : "タ",
"lemma" : "た",
"pos" : "動詞接尾辞",
"features" : [ "終止" ],
"common_noun_semantic" : [ ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ ],
"attributes" : { }
}, {
"id" : 18,
"form" : "。",
"kana" : "",
"lemma" : "。",
"pos" : "句点",
"features" : [ ],
"common_noun_semantic" : [ ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ ],
"attributes" : { }
} ]
} ],
"status" : 0,
"message" : ""
}
ここで「行く」を見ると、掛かり先は「4,7,8,9」の4つになっています。
実際には「0,2」を含む6つになるはずですが、APIが返すのは4つになります。
本来期待される結果
複数の文を同時に送信するのではなく、単一の文で送信すると期待した結果になります。
「嫁と娘は旅行に行った。」のみを送信したときの「行く」の掛かり先
{
"id" : 6,
"form" : "行",
"kana" : "イ",
"lemma" : "行く",
"pos" : "動詞語幹",
"features" : [ "IKU" ],
"common_noun_semantic" : [ 2053, 2132 ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ 15, 20, 29, 32, 5 ],
"dependency_labels" : [ {
"token_id" : 0,
"label" : "nmod"
}, {
"token_id" : 2,
"label" : "nsubj"
}, {
"token_id" : 4,
"label" : "nmod"
}, {
"token_id" : 7,
"label" : "aux"
}, {
"token_id" : 8,
"label" : "aux"
}, {
"token_id" : 9,
"label" : "punct"
} ],
"attributes" : { }
}
複数文を送信すると構文解析がちょっと怪しいのか、それとも私の呼び方に問題があるのか。。要調査です。
「嫁と娘は旅行に行った。」の後ろに別の文を連結して送信したときの「行く」の掛かり先
{
"id" : 6,
"form" : "行",
"kana" : "イ",
"lemma" : "行く",
"pos" : "動詞語幹",
"features" : [ "IKU" ],
"common_noun_semantic" : [ 2053, 2132 ],
"proper_noun_semantic" : [ ],
"declinable_word_semantic" : [ 15, 20, 29, 32, 5 ],
"dependency_labels" : [ {
"token_id" : 4,
"label" : "nmod"
}, {
"token_id" : 7,
"label" : "aux"
}, {
"token_id" : 8,
"label" : "aux"
}, {
"token_id" : 9,
"label" : "punct"
} ],
"attributes" : { }
}
spec を見ると「sentence: 解析対象文」となっており、単一の文に限るとも読めますが、「文で区切る」も自然言語処理の一つですので、もし単一の文だけを対象としているのであればAPI仕様として課題になるかと思いました。テキストマイニングの現場ではアカデミックな世界と違って、単一の文だけを処理することはあまりないと思います。

例えば Stanford NLP は文の区切りもアノテーションとして返してきます。
(たとえば「モーニング娘。のライブを見に行った」も正しく解析できないといけない)
私が仕事としてのユーザーであればサポートに問い合わせます。
私がデリバリー担当でしたら修正を強く求めます。
私が開発リーダーでしたら即修正です ^_^;;