1.初めに
1.私はアイデミーで初めてpythonを学習した素人です。pythonを学習して、花粉の飛散量を予測したいと思い、予測してみました。
2.花粉の飛散量を予測の概要
・使用データ
東京都アレルギー情報navi.過去の飛散花粉数データ
https://www.fukushihoken.metro.tokyo.lg.jp/allergy/pollen/archive/archive.html
・分析方法
時系列解析(SARIMA)
実行環境
Python 3.7.12
Google Colaboratory
・分析の流れ
1.データの取得・修正
2.データの読み込み・整理
3.SARIMAモデルに当てはめ
4.予測データの代入
5.時系列データの可視化
6.可視化したデータから花粉の飛散量を予測
3.データ分析
3-1データの取得・修正
まずhttps://www.fukushihoken.metro.tokyo.lg.jp/allergy/pollen/archive/archive.html
から各年のデータをCSVで取得する。
今回は平成23年~令和2年のスギ・ヒノキ花粉のデータをCSVで取得した。
以下は令和2年のスギ・ヒノキ花粉のCSVデータである。(単位:個/cm2)
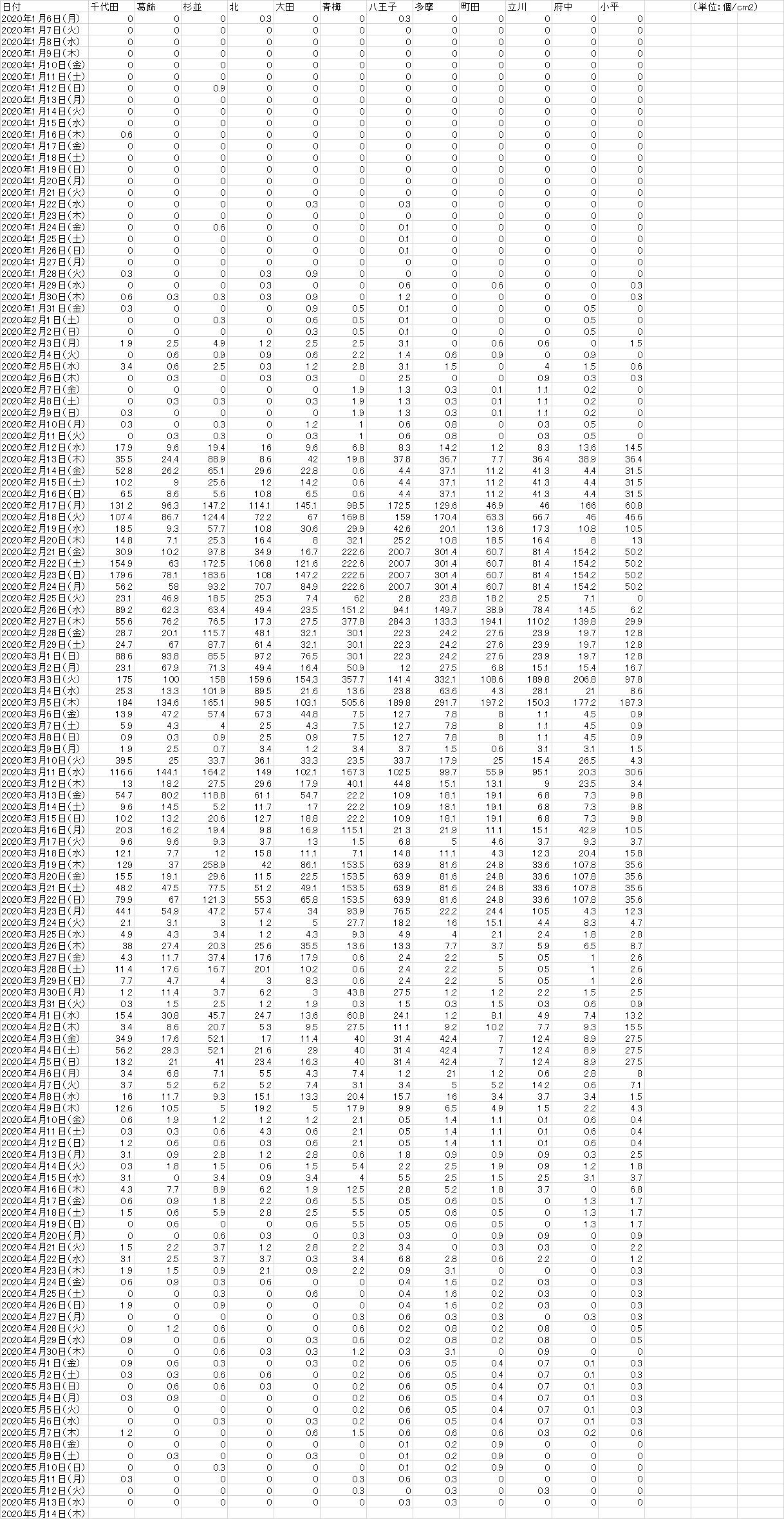
今回は月ごとのデータで予測するため千代田区のデータのみし、以下のデータに変換した。
このデータは千代田区の2011年(平成23年)~2020年(令和2年)のスギ・ヒノキ花粉の飛散量である。(単位:個/cm2)
なお6月~12月はスギ・ヒノキ花粉のシーズン外のため今回は0として計上する。

3-2.データの読み込み
Google Colaboratoryを使用してデータの読み込みをする。
修正したデータからパスをコピーして貼り付ける。
/content/drive/MyDrive/r2_total_archive.csv/r2_total_archive.csv3.csv
また元のデータに千代田区以外のデータも含まれているので、そのデータが反映されないように以下のコードを記述する。
sales_sparkling = sales_sparkling.iloc[:, :1]
sales_sparkling=pd.read_csv("/content/drive/MyDrive/r2_total_archive.csv/r2_total_archive.csv3.csv",encoding="shift-jis",index_col="Month")
そして以下の通りにしてデータを読み込む。
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from pandas import datetime
import numpy as np
# データの読み込みと整理
sales_sparkling = pd.read_csv("/content/drive/MyDrive/r2_total_archive.csv/r2_total_archive.csv3.csv",encoding="shift-jis",index_col="Month")
sales_sparkling = sales_sparkling.iloc[:, :1]
print(sales_sparkling.head())
sales sparklingの中身を確認する。
sales_sparkling
Month
"2011-1" 1.2
"2011-2" 944.7
"2011-3" 4586.0
"2011-4" 2830.1
"2011-5" 136.5
... ...
"2020-8" 0.0
"2020-9" 0.0
"2020-10" 0.0
"2020-11" 0.0
"2020-12" 0.0
120 rows × 1 columns
# ここで元のindexをDatatimeIndexに変更する
# ここで注意してもらいたいのは元のデータフレームのindexと全く同じ長さ(120)そして期間(2011-01~2020-12)にしないと行けないこと
sales_sparkling.index = pd.date_range("2011-1", "2021-01", freq="M")
# 変更されたことを確認
sales_sparkling.index
DatetimeIndex(['2011-01-31', '2011-02-28', '2011-03-31', '2011-04-30',
'2011-05-31', '2011-06-30', '2011-07-31', '2011-08-31',
'2011-09-30', '2011-10-31',
...
'2020-03-31', '2020-04-30', '2020-05-31', '2020-06-30',
'2020-07-31', '2020-08-31', '2020-09-30', '2020-10-31',
'2020-11-30', '2020-12-31'],
dtype='datetime64[ns]', length=120, freq='M')
3-3.SARIMAモデルに当てはめ
SARIMAモデルに当てはめるために以下のコードを記述する。
モデルの当てはめ
SARIMA_sparkling_sales = sm.tsa.statespace.SARIMAX(sales_sparkling,order=(0, 0, 0),seasonal_order=(0, 1, 1, 12)).fit()
3-4.予測データの代入
予測データを代入する。ここでは過去のデータと重複するように"2019-1-31","2025-12-31"とする。以下のコードを実行する。
predに予測データを代入する
pred = SARIMA_sparkling_sales.predict("2019-1-31", "2025-12-31")
3-5.時系列データの可視化
以下のコードで時系列データの可視化を行う。
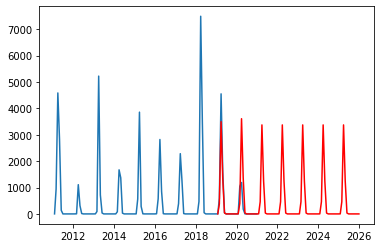
predデータともとの時系列データの可視化
plt.plot(sales_sparkling)
plt.plot(pred, color="r")
plt.show()
print(sales_sparkling.index)
実行させると以下の通りになる。
DatetimeIndex(['2011-01-31', '2011-02-28', '2011-03-31', '2011-04-30',
'2011-05-31', '2011-06-30', '2011-07-31', '2011-08-31',
'2011-09-30', '2011-10-31',
...
'2020-03-31', '2020-04-30', '2020-05-31', '2020-06-30',
'2020-07-31', '2020-08-31', '2020-09-30', '2020-10-31',
'2020-11-30', '2020-12-31'],
dtype='datetime64[ns]', length=120, freq='M')
3-6.可視化したデータから花粉の飛散量を予測
可視化したデータから2021年~2025年の花粉の飛散量を予測する。
グラフを見ると3000~4000の間で推移していることが読み取れる。(単位/個cm2)
4.考察
予測データは過去の実績データの平均値で予測されていると考えられる。2019年と2020年の実績データと予測データとの乖離が発生している。しかし予測データの部分は平均値付近で推移しているものの、全て一定の値ではないので予測データはある程度の正確性はあると考える。
5.花粉の飛散量を予測した感想
時系列データの読み込みをして、時系列データの可視化を実行するのは思ったよりも難しかった。日ごとにするか週ごとにするか月ごとのデータにするかによって、データの修正や元のデータフレームのindexと同じ長さにする必要がある等と結構大変でした。
今回は6月~12月の花粉の飛散量を省略しているが、2.花粉の飛散量を予測の概要の所で添付したURLから6月~11月分も花粉の飛散量のデータがある。今後機会があれば、シーズンオフ時も含めた花粉の飛散量の予測をしてみたいと思った。また月ごとではなく週ごとの飛散量予測をしてみるのもありだと感じた。
初めてpythonの記事を書いたため、読みづらい所もあったかもしれませんが最後までお読みいただきありがとうございました。